动作识别
Action Recognition
简介
动作识别的目标是识别出视频中出现的动作,通常是视频中人的动作。视频可以看作是由一组图像帧按时间顺序排列而成的数据结构,比图像多了一个时间维度。动作识别不仅要分析视频中每帧图像的内容,还需要从视频帧之间的时序信息中挖掘线索。动作识别是视频理解的核心领域,虽然动作识别主要是识别视频中人的动作,但是该领域发展出来的算法大多数不特定针对人,也可以用于其他视频分类场景。
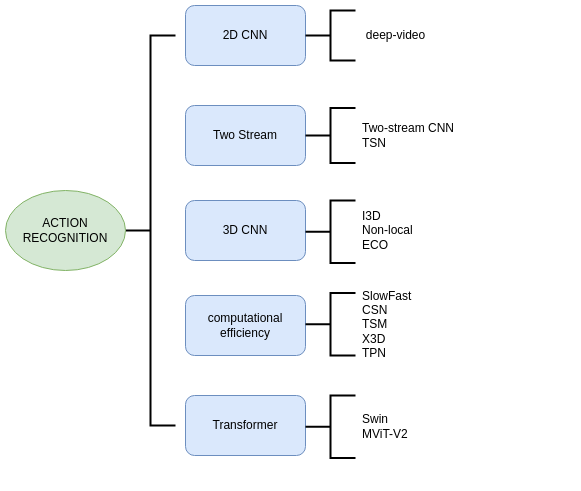
该领域的算法具体可以分为以下如下几类
数据集
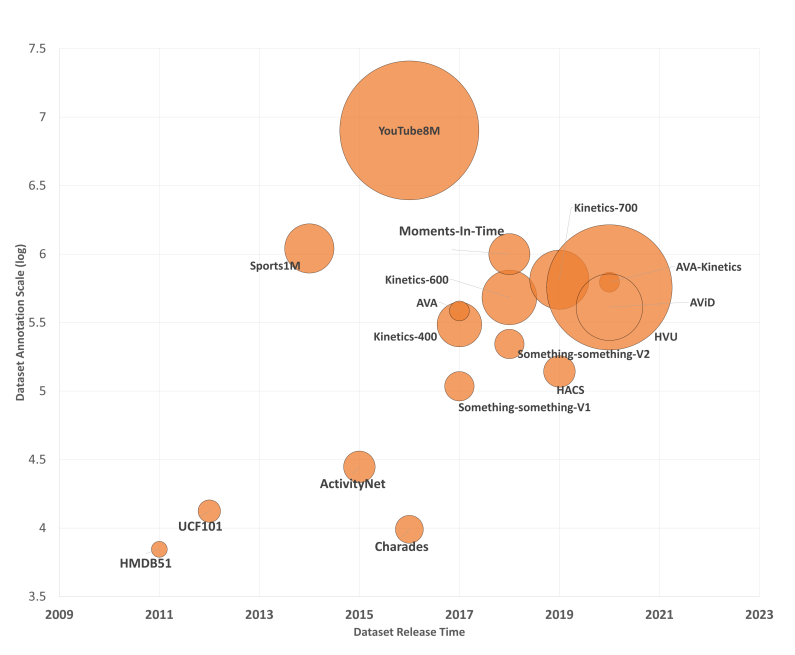
| datasets | num of classes | num of videos |
|---|---|---|
| ucf-101 | 101 | 13,320 |
| HMDB-51 | 51 | 6,849 |
| Kinetics | 400/600/700 | 200K/500K/650K |
| Sport-1M | 487 | 1,133,158 |
| Youtube-8M | 1000 | 230K |
| SomethingV2 | 174 | 220,847 |
挑战
在很长的一段时间内, 基于深度学习算法的动作识别算准确率不及或只能接近传统识别算法的准确率。动作识别面临的困难可概括为以下几点:
- 训练视频模型所需的计算量比图像大了一个量级,这使得视频模型的训练时长和训练所需的硬件资源相比图像大了很多,导致难以快速用实验进行验证和迭代;
- 早期的数据集如UCF-101规模较小, 制约了动作识别领域的发展;
- 学习视频中帧之间的时序关系,尤其是长距离的时序关系,本身就比较难。不同类型的动作变化快慢和持续时长有所不同,不同的人做同一个动作的方式也存在不同,同时相机拍摄角度和相机自身的运动也会对识别带来挑战;
- 一个视频之中往往有许多帧存在信息冗余,不是视频中所有的帧对于动作识别都有相同的作用;
- 网络结构设计缺少公认的方案, 在动作识别领域,同时存在多个网络设计理念,例如,帧之间的时序关系应该如何捕捉、使用 2D 卷积还是 3D 卷积、不同帧的特征应该如何融合等都还没有定论。
2D CNN
DeepVideo
2016📕 Large-scale Video Classification with Convolution Neural Networks
DeepVideo是深度学习在视频理解的最早应用,承接了巻积网络提取图像特征的成功经验
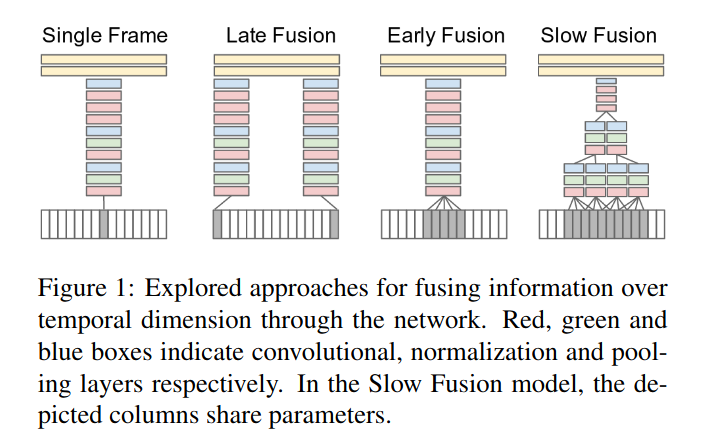
如上图所示, Single Frame就是是将单帧图像直接丢到我们的巻积网络当中最后再过两层全连接。那为了理解视频帧与帧之间的时序关系,自然会去考虑学习不同帧下的特征提取来帮助网络更好的完成任务
- Late Fusion则是从视频中随机的选两帧,通过两个巻积网络(权值共享的)后得到的特征再一起过最后的两层FC,其中late指的就是两帧的特征融合的地方比较晚
- Early Fusion则将特征融合提前到了巻积网络前。比如一帧图片原本是RGB三个通道,那么在这里要提取五帧图片,那么堆叠后得到的输入将会是3*5=15个通道的输入
- 介于Late和Early之间的就是Slow Fusion了,也很直观,就是在学习过程中逐渐合并特征
三种网络构造效果都不如传统手工特征, 于是作者提出了多分辨率架构multiresolution。下面的分支用来学习原分辨率的图像,上面分支用来学习原图中抠出来的中间的部分图像。上下分支的两套巻积网络同样是权值共享的。
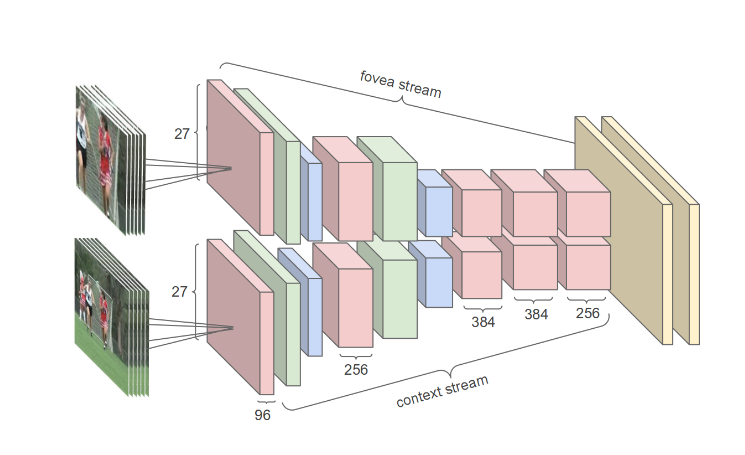
这篇工作的重点意义在于其作为最早在视频领域尝试巻积网络,并且在当时较大的数据集Sports-1M上进行了实验。这为后来的工作的铺垫意义是很大的。
Two-stream networks
Two-stream CNN
2014📕 Two-Stream Convolutional Networks for Action Recognition in Videos
网络
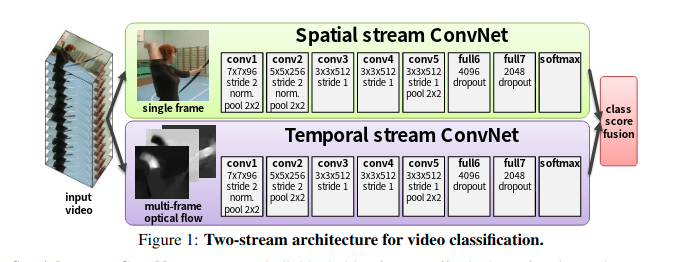
整CNN分为两个子网络:
Spatio Stream Convet:空间流卷积网络,输入是单个帧画面(静态图片),主要学习场景信息。因为是处理静态图片,所以可以使用预训练的模型来做,更容易优化。最后根据网络输出的特征得出一个logist(假设模型是在UCF-101数据集上做测试,数据集共101个类,logist是softmax之后的类别概率
temporal stream convet:时间流卷积网络(光流网络),输入是光流图像,通过多帧画面的光流位移来获取画面中物体的运动信息,最后也根据网络输出的特征得出一个logist
- 光流输入显式地描述了视频帧之间的运动,而不需要CNN网络去隐式地估计运动信息,所以使得识别更加容易。加入时间流卷积网络之后,模型精度大大提升
- 直接以光流做输入来预测动作,而不用CNN本身去学动作信息,大大简化了学习过程。
融合方式:
- ate fusion融合:两个logist加权平均得到最终分类结果(比如两个softmax向量取平均,再做一个argmax操作)
- 将softmax分数作为特征再训练一个SVM分类器
光流
optical flow简单说就是每个物体的运动轨迹,运动越明显的区域亮度越高。比如下图,背景不变,只有人的运动状态变了;右图背景运动状态不变,所以是白色的,只有图中的人处于运动中,是亮色的。通过提取光流,可以去掉背景噪声、人物穿着性别等和运动无关的特征都忽略掉,所以最后提取的特征能很好的描述运动信息,也变相的相当于视频里的时序信息的特征表示。

光流由一些位移矢量场(displacement vector fields)组成的,其中第t帧的位移矢量用dt表示,是通过第t和第t+1帧图像得到的。dt可以拆分成水平部分dtx和竖直部分dty。将dt、dtx、dty可视化后结果如下:

-
a、b:前后两帧图片,维度为240×320×3(UCF-101数据集视频帧的大小)
-
c:光流dt的可视化显示,射箭动作是超右上走的,维度是240×320×2。
- 因为图片上每个点都可能运动,所以每个像素点都有对应的光流值,所以论文中一直称之为密集光流(dense optical flow)。最终光流图和原图大小一致。
- 2表示水平和垂直两个方向(维度)
- 每两张图得到一个光流,如果视频一共抽取L帧,那么光流就是L-1帧。这些光流一起输入光流网络
-
d、e分别是水平位移dtx和垂直位移dty
利用光流:
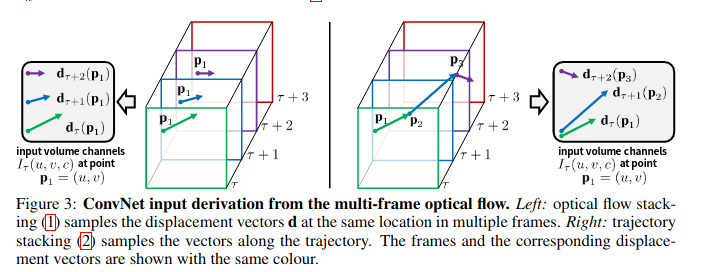
- 简单叠加:网络输入是图中每个点多次光流的叠加,比如网络每次都取P1处的光流。这种方式简单直接,但是应该没有充分利用光流信息。
- 按轨迹叠加:每一帧都根据光流轨迹,更新光流点的位置,比如网络按照P1、P2、P3…这些位置依次提取光流。这种方式听起来合理很多,充分利用了光流信息。
- 每次叠加都是先叠加水平位移,再叠加垂直位移,所以是 [x1,x2,...xL,y1,y2,...yL],即光流网络输入维度224×224×2L(resize到224)
光流局限性及应对方式
- 光流抽取非常耗时(单张0.06秒)
- 光流的密集表示导致其存储困难,无法训练。对于13,320(UCF-101)大小的数据集存下所有光流需要1.5T
- 光流预处理为JPEG图, 将光流值rescale到[0, 255], 1.5T --> 27GB
TSN
2016📕 Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
🔥 code
首先第一步:将长视频均匀分成K个段(K-segment),从K的片段里头提取K个片(snipnet)这种方法相当于全局性的稀疏抽帧。像下图中,假设一个包含踢足球的动作视频共30frame,那么就把这个视频分为三段,每段就是10frame,在这10frame中也就是每个Segment里面只取1frame,这样原本有30frame的视频数据,我们现在只需要取其中的3帧进行处理就好了,这样的好处在于(1)取得数据少,计算成本低(2)取得帧在整个视频片段里分布均匀,前中后程都有估计到:所以long-range。
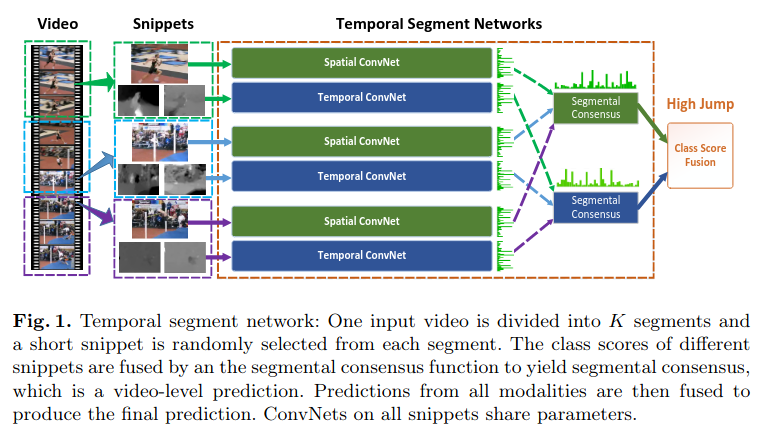
如上图所示:一个输入视频被分为K段(segment),一个片段(snippet)从它对应的段中随机采样得到。不同片段的类别得分采用段共识函数(The segmental consensus function)进行融合来产生段共识(segmental consensus),这是一个视频级的预测。然后对所有模式的预测融合产生最终的预测结果
3D CNN
I3D
2017📕 Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
🔥 code
主要贡献
- 作者提出了一个新的大型视频行为识别数据集 Kinetics
- Two-Stream Inflated 3D ConvNets (I3D) 网络结构, 使用INceptionv1作为backbone
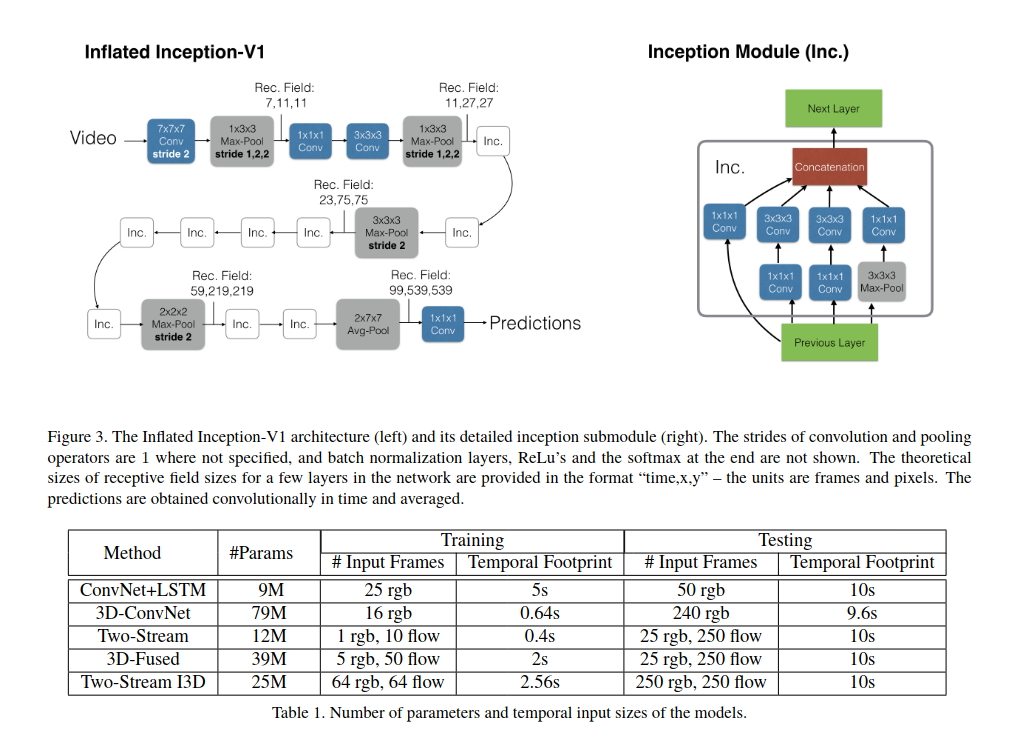
2D to 3D
对于分类任务, 很容易做到迁移学习, 作者这里对于迁移学习的解决方案是, 直接把2D卷积或2D池化的 \(N*N\)的kernel变成\(N*N*N\) 的kernel。对于预训练权重,首先把2D卷积核在时间维度上复制N份,然后除以时间维度的维度N,这样做是为了扩展到3D卷积之后,每一层都仍然获取到类似大小的输出相应。如果不除以N,就会出现输出相应会增大N倍,改变了预训练时网络所学习到的数据分布。
WHY?
对于一个短视频抽取16帧(8n),基本每帧变化不大, 对于一个3D卷积核, 可以表示为\(H*W*t\), 这里t为16, 可以将一帧图片复制16份, 相应地, 在ImageNet上预训练的2D卷积复制16份, 这里比较好理解, 但是这里为什么还要除以N呢?假设一个2D卷积为
提取特征图上的一块 \(3*3\)区域的像素
输出为\(Y_{out}= 0.1x_1+0.2x_2+0.3x_3+...+0.9x_9\)
如果使用3D卷积的话, 对应的输出为\(\hat{Y_{out}}= t Y_{out}\)
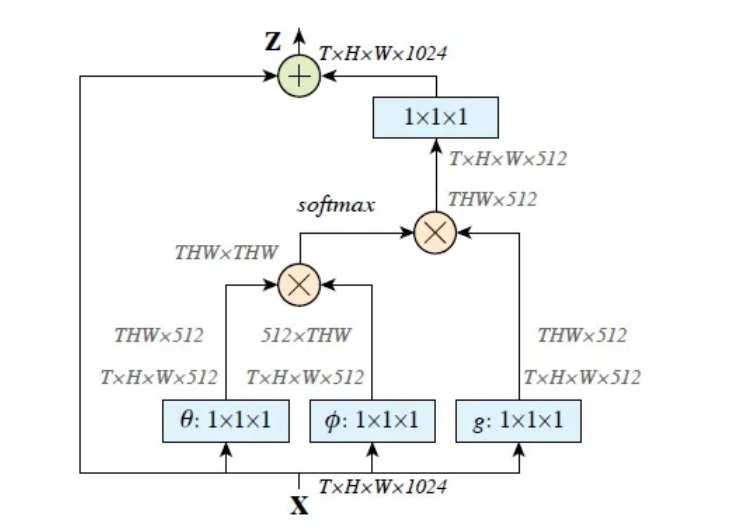
Non-local
2018
动机:卷积运算和递归操作都在空间或时间上处理一个local邻域;只有在重复应用这些运算、通过数据逐步传播信号时,才能捕获long-range相关性。换句话说,在卷积网络中,想要增加视野域,就要不断的增加卷积层数量和池化层数量,换句话说,增加视野域就是增加网络的深度。这样必然会增加计算的成本,参数的数量,还需要考虑梯度消失问题。
code实现
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation):
super(Self_Attn,self).__init__()
self.chanel_in = in_dim
self.activation = activation
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # transpose check
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x
return out,attention
ECO
2018📕 ECO_Efficient Convolutional Network for Online Video Understanding
🔥 code
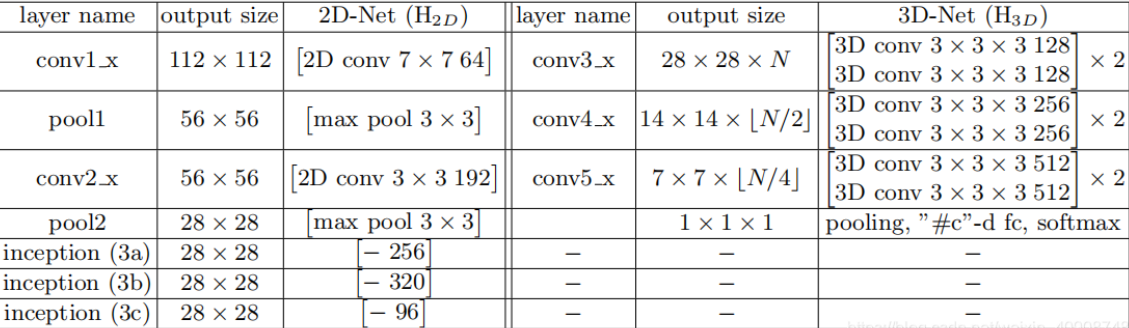
作者提出了一种新的视频分类模型ECO,创新在于将 2D卷积(提取图像特征)和3D卷积(提取时间上的特征)相结合。
具体的网络结构:作者提出了两种模型ECO Lite和ECO Full。ECO Lite是结构上较为简单的一种模型,它比ECO Full少了一个2D的卷积处理。二者的区别是:ECO Lite运行速度快,精确度较低;ECO Full运行速度较慢,但是精确度较高(因为它设计的2DNets能更好地得到图片特征,同时又可以和时序特征相融合得到最终的判断结果)

-
首先是数据处理。将一个视频分成N段,从每段中随机地取一帧图片,这样一个video对应N帧图片,将其作为输入放入2D卷积层中。
-
2DNet结构。使用了BN-Inception结构中前面的一部分(inception-3a, inception-3b, inception-3c)
-
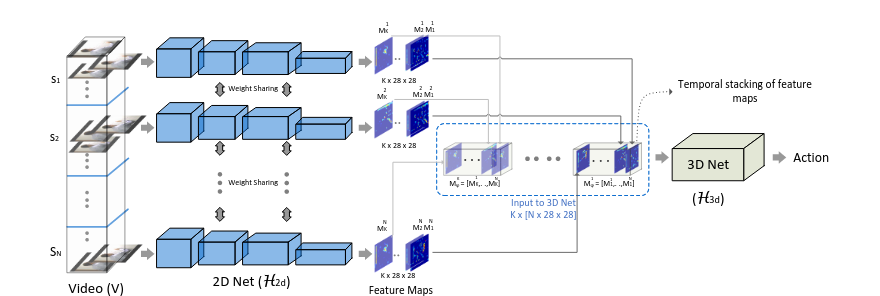
3DNet结构。在将2DNet输出作为3DNet的输入前,要对2DNet的输出做处理。具体处理见下图。左边的S1, S2, ..., SN指的是将一个video划分成N段,每段随机地取一帧图像送入2DNet中(weight shared指的是共用一个2DNet网络)。从2DNet得到的输出是每一帧都对应K个通道、size=28*28的特征图。在这里重组这些特征图,将对应通道的图片放在一组中。比如我将每帧第一个通道的图片放在一组,将每帧第二个通道的图片放在第二组,依此类推,每一组中有N张28*28大小的图片。这样我们得到的数据shape就变成了[K, N, 28, 28](如上图中的蓝色小字所示),这里对应代码的处理就是transpose将维度变换一下即可。我们这样处理主要是为了通过3DNet得到时序关系(因为是由同一个通道不同时间帧组成的)。接下来只要处理成3DNet模型可以接受的输入shape即可
-
如果是ECO Lite的话,接下来对3DNet的输出做一个Pool3D+reshape就可以得到一维的张量,输入fc层,得到的fc结果做一个softmax就可以得到视频分类了。如果是ECO Full的话,需要将之前2DNet没做的BN-Inception余下部分接着做完,最后也像上面提到的transpose改变维度的顺序,做Pool3D+reshape后得到一个一维的输出。将2DNets的输出和3DNet的输出结合(Concatenate),作为一个整体输入fc,再做sofmax进行分类
Efficient computational networks
视频分类目前主要难点:
- 视频流的大量增长导致了对视频理解达到高准确率以及高性能变得十分具有挑战性
- 传统的2D卷积虽然计算量小,但是却不能很好的利用时序上的连续信息
- 3D卷积虽然效果很好,但是计算量比较大, 使得实际应用变得困难
- 双流网络需要预先计算光流并将其存储在本地磁盘上, 这对于大数据集而言往往需要数TB空间,庞大的IO将成为训练最大瓶颈。
随着数据集规模的扩大和部署需求的增加,效率成为一个重要问题。
SlowFast
2019📕 SlowFast Networks for Video Recognition
🔥 code
Slow pathway 慢通道
模型结构上面的分支Slow Pathway, 输入是低帧率的采样,捕获稀疏帧图像。Low frame rate意味着这个“慢通道”使用了一个较大的时序跨度,实验里设置为每秒跳过了16帧(a large temporal stride \(\tau\)=16 ),如果按30fps算,即每秒只采样2帧。若慢通道的采样数为T,则原视频的长度即为\(T*\tau\)帧。“慢通道”用于提取空间语义信息。
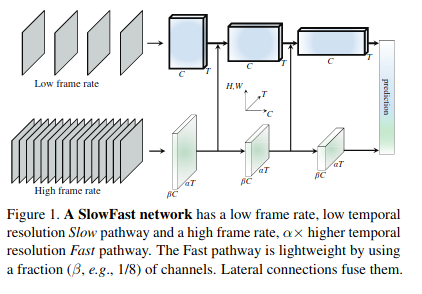
Fast pathway 快通道
下面的分支Fast Pathway, 输入是高帧率的采样(为慢通道的 \(\alpha\)倍, 通常设为8,即输入的采样数为$ \alphaT\(),则每秒跳过的帧数为\) T/\alpha$ (a small temporal stride, $ T/\alpha$ = 2) 。 在使用更高的时序分辨率作为输入时,也保持了同样的高时序分辨率作为输出,没用采用时序下采样,输出仍然是$ \alphaT$。
CSN
2019📕 Video Classification with Channel-Separated Convolutional Networks
- 分解3D卷积通过分开通道间相互作用和时空域信息的交互将对于提高准确率和节省计算量有很好的帮助。
- 将3D卷积进行通道分离这种方法从某种程度上说可以等效成一种正则化,虽然在训练集上的准确率不高,但在测试集上表现出跟高的准确率。
Channel-Separated Bottleneck Block
提出两个结构,即下图b、c,分别称为interaction-preserved channel-separated network (ip-CSN) 、interaction-reduced channel-separated network (ir-CSN) 。
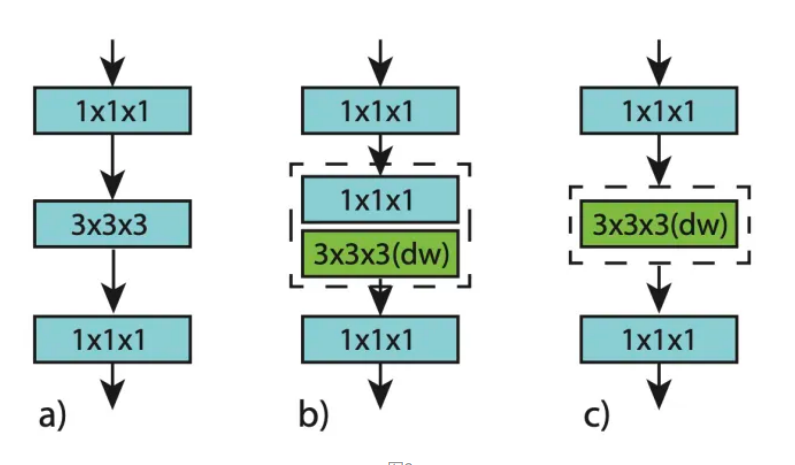
主要将原来的ResNet3D(图a)里bottleneck在中间的333卷积中该用depthwise。ip-CSN可以通过第二层的111卷积保留一定的通道之间的交互。ir-CSN则可以大大降低结构块中的计算量。
Channel Interactions in Convolutional Blocks
即将ResNet3D的Block块分别改为groupwise和depthwise,如下图b、c,主要是用来做后面的对比实验。
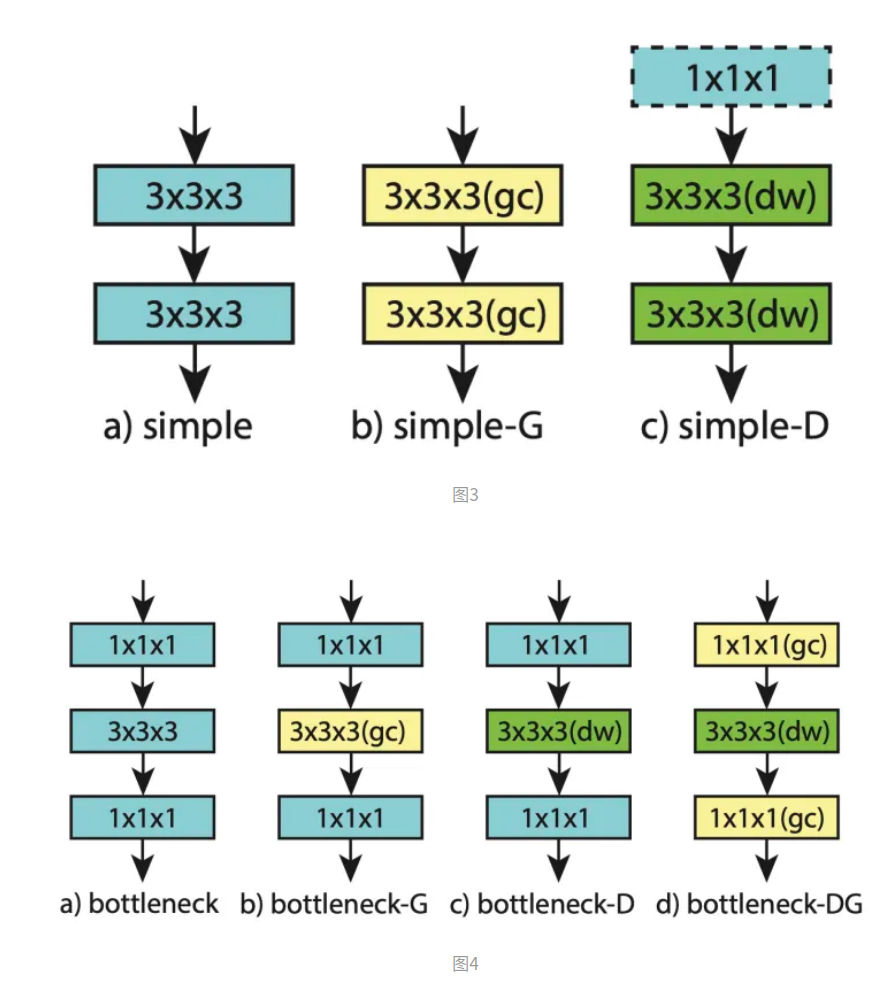
上图b、c、d分别为将bottleneck块内部改为groupwise(gc)、depthwise(dw)和gc+dw结构。
TSM
2019📕 Temporal Shift Module for Efficient Video Understanding
🔥 code
时序建模:最直接的方式就是3D卷积,也有一些其它方案,例如:2D卷积+最后在时间维度融合,2D卷积+LSTM,Attention等。这篇论文指在高效计算的基础上提高时序信息建模的能力,也属于折中方案。
TSM module: 分为两种模式, offline和online, 如下图所示, 对于离线视频shift是双向的, 在第一个channel向下移动一位, 在第二个channel上向上移动一位,这样不同帧之间就有信息交互
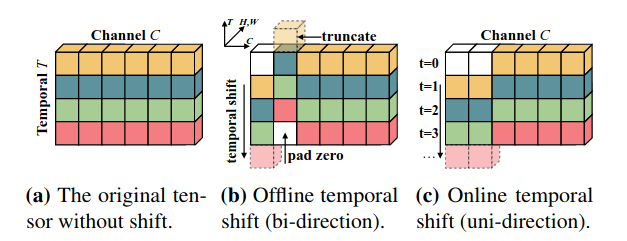
下面图a是直接在任意的卷积块中直接插入shift操作,但是通过实验发现这种结构并不好,因为shift破坏了原始的空间信息。右图b是将shift操作引入残差块中,残差连接保留了X原有的空间信息,效果比较好。而且,Residual TSM的通用性很强,可以移植到任意的ResNet-X中。
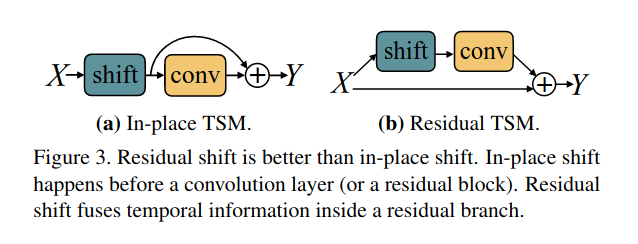
离线模式就是shift操作是双向的,然后移植到ResNet参差块中的第一部分即可。在线的视频由于得到不到未来的帧的通道信息,故而在线TSM模型shift操作只能是单向的。而且为了加速前向推理过程shift操作由cache-replace来代替,即将上一时刻1/8的通道信息缓存,然后在当前时刻替换掉,如下图所示
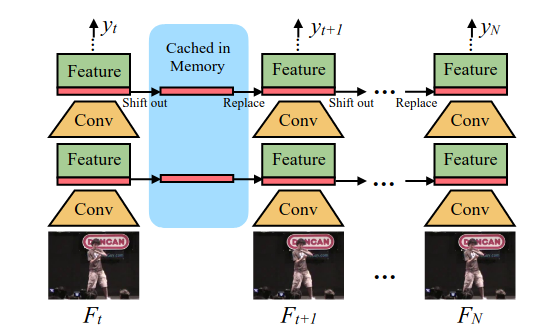
class TemporalShift(nn.Module):
"""Temporal shift module.
This module is proposed in
`TSM: Temporal Shift Module for Efficient Video Understanding
<https://arxiv.org/abs/1811.08383>`_
Args:
net (nn.module): Module to make temporal shift.
num_segments (int): Number of frame segments. Default: 3.
shift_div (int): Number of divisions for shift. Default: 8.
"""
def __init__(self, net, num_segments=3, shift_div=8):
super().__init__()
self.net = net
self.num_segments = num_segments
self.shift_div = shift_div
def forward(self, x):
"""Defines the computation performed at every call.
Args:
x (torch.Tensor): The input data.
Returns:
torch.Tensor: The output of the module.
"""
x = self.shift(x, self.num_segments, shift_div=self.shift_div)
return self.net(x)
@staticmethod
def shift(x, num_segments, shift_div=3):
"""Perform temporal shift operation on the feature.
Args:
x (torch.Tensor): The input feature to be shifted.
num_segments (int): Number of frame segments.
shift_div (int): Number of divisions for shift. Default: 3.
Returns:
torch.Tensor: The shifted feature.
"""
# [N, C, H, W]
n, c, h, w = x.size()
# [N // num_segments, num_segments, C, H*W]
# can't use 5 dimensional array on PPL2D backend for caffe
x = x.view(-1, num_segments, c, h * w)
# get shift fold
fold = c // shift_div
# split c channel into three parts:
# left_split, mid_split, right_split
left_split = x[:, :, :fold, :]
mid_split = x[:, :, fold:2 * fold, :]
right_split = x[:, :, 2 * fold:, :]
# can't use torch.zeros(*A.shape) or torch.zeros_like(A)
# because array on caffe inference must be got by computing
# shift left on num_segments channel in `left_split`
zeros = left_split - left_split
blank = zeros[:, :1, :, :]
left_split = left_split[:, 1:, :, :]
left_split = torch.cat((left_split, blank), 1)
# shift right on num_segments channel in `mid_split`
zeros = mid_split - mid_split
blank = zeros[:, :1, :, :]
mid_split = mid_split[:, :-1, :, :]
mid_split = torch.cat((blank, mid_split), 1)
# right_split: no shift
# concatenate
out = torch.cat((left_split, mid_split, right_split), 2)
# [N, C, H, W]
# restore the original dimension
return out.view(n, c, h, w)
X3D
2020📕 X3D: Expanding Architectures for Efficient Video Recognition
主要思路:
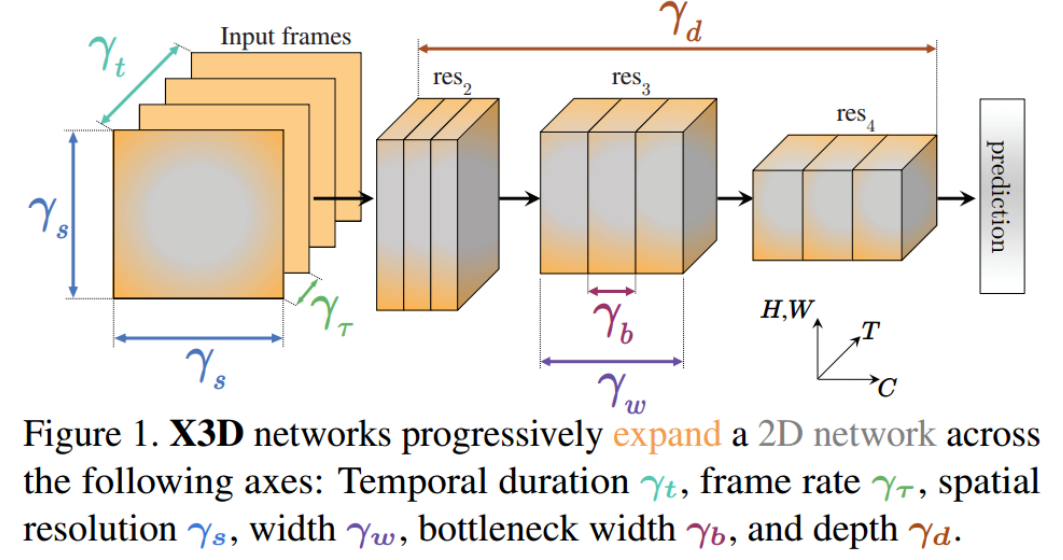
- 之前的网络主要是在时间维度上扩展2D卷积神经网络。
- 但时间尺度上扩展不一定是最佳选择,还可以在别的尺度上扩展。
- 这种设计的灵感主要来源于之前设计卷积网络都是在depth/resolution/width上进行扩展,另外还借鉴了机器学习中特征选择的方法。
需要扩展的axis(这几个axis可以理解为网络的几个基本参数)
- 输入数据的总帧长度。
- 输入数据的帧率。
- 输入帧的尺寸。
- 网络宽度(其实就是每个conv的的通道数量)
- bottlenet层宽度(即bottlenet中前两个conv的通道数量)
- 网络深度(其实就是bottlenet的数量)
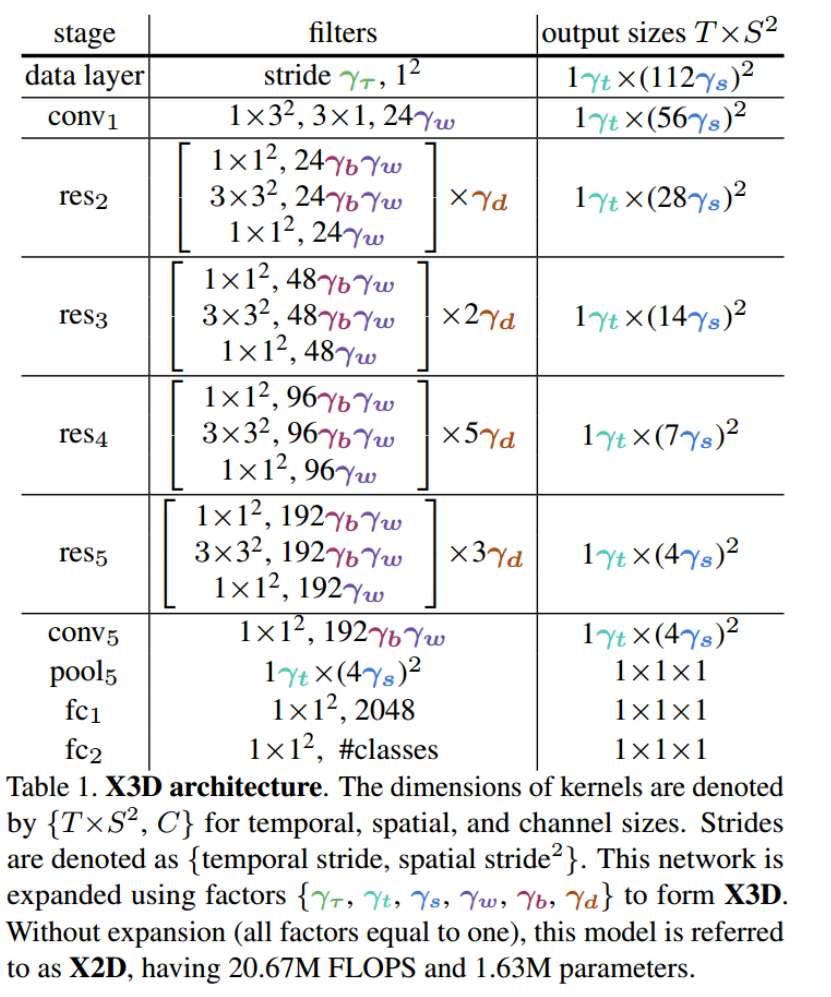
模型训练过程:
- 首先,给定一个初始状态,如下表所示,认为所有参数取值为1。
- 然后,每次改变一个参数,控制参数量与算力、训练模型,选择性能最后的模型作为下一步的输入。
- 以此类推,直到达到所需要的算力为止。
一次模型训练的实例
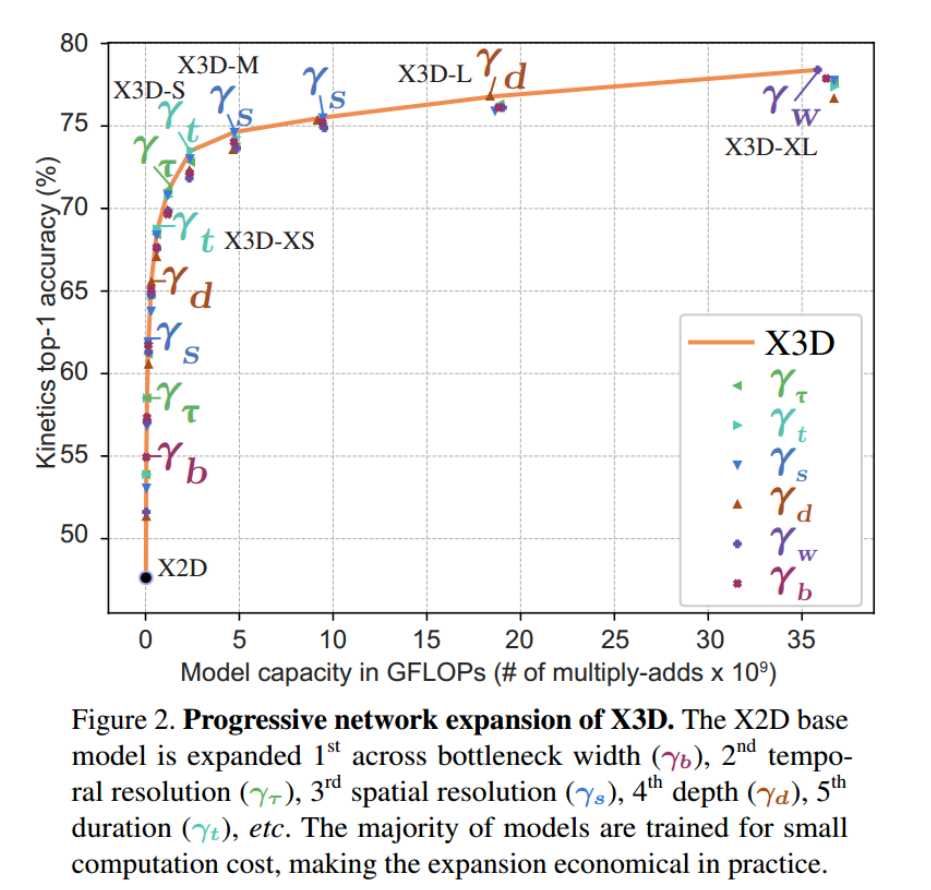
改变参数

不同尺寸的X3D模型
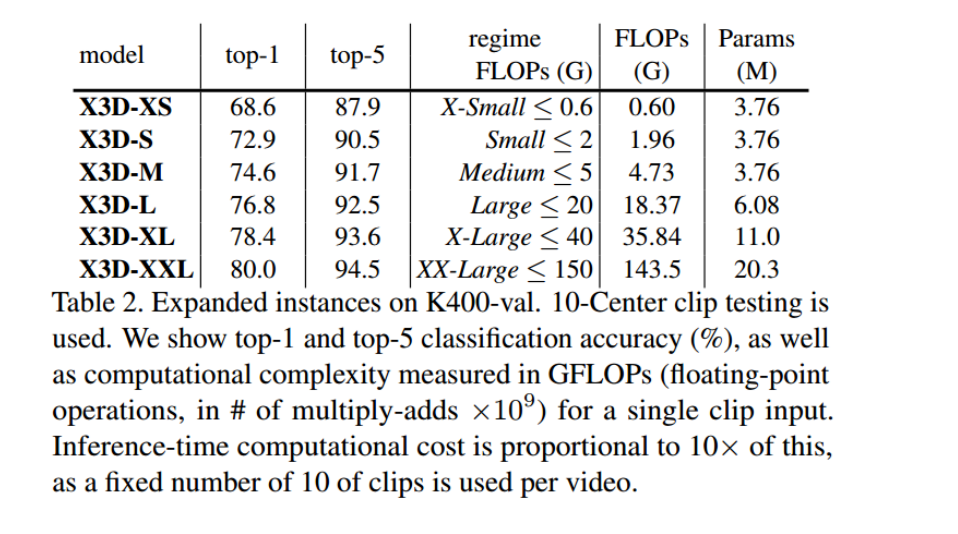
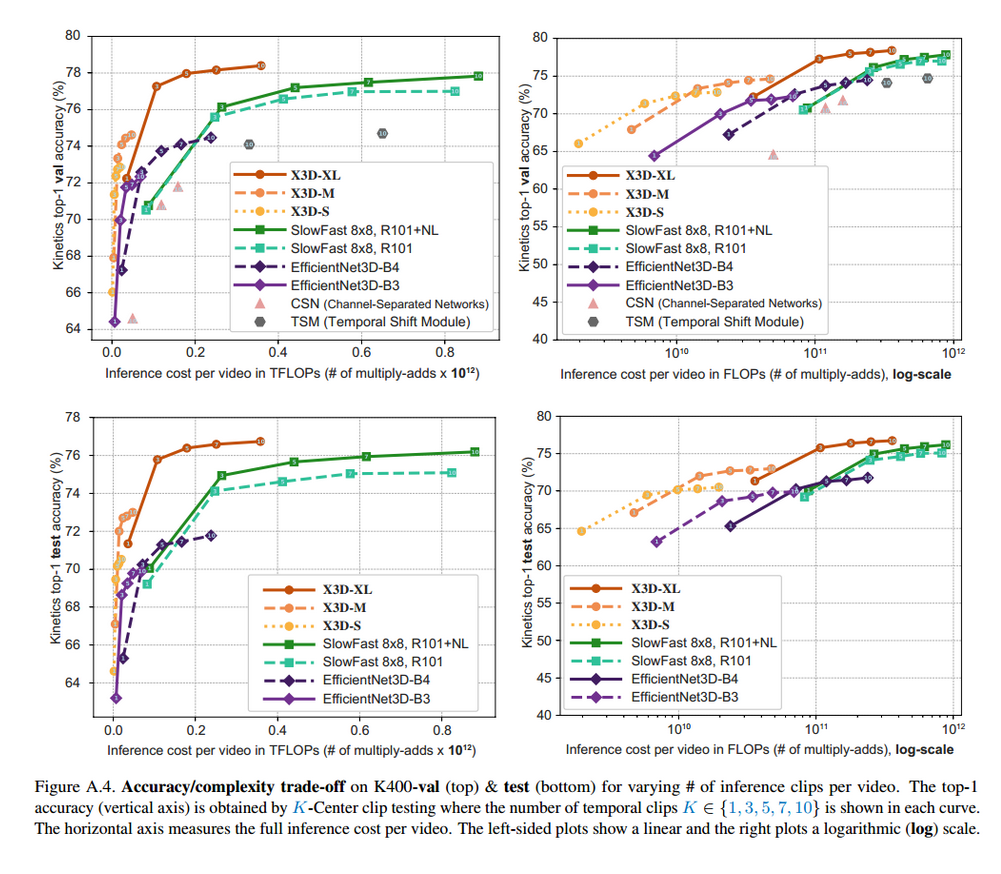
性能
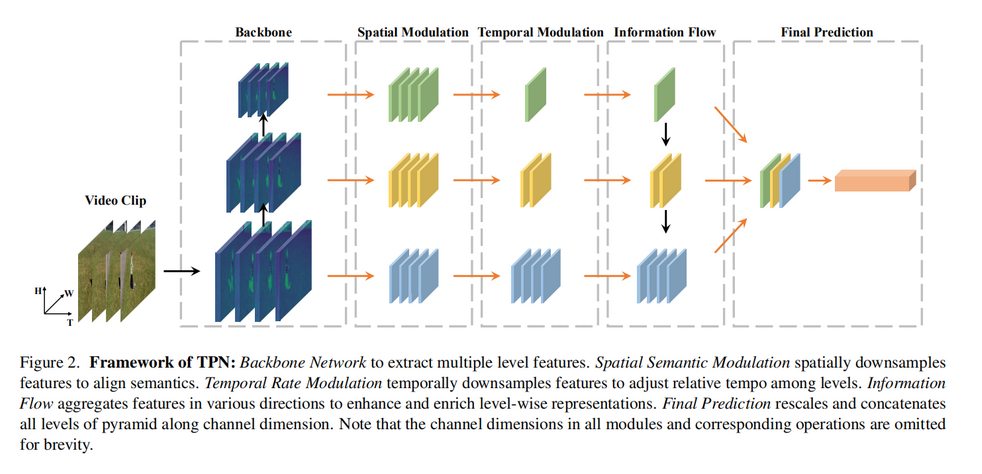
TPN
2020📕 Temporal Pyramid Network for Action Recognition
🔥 code
-
提出了一个即插即用的模块 Temporal Pyramid Network 。灵感来源:同一模型不同深度的网络都已经提取了不同tempo的特征。由于视频数据的特征图一般尺寸为
BATCH_SIZE, T, C, H, W,那么不同的T就代表了不同的帧率。 -
下图中的各个模块简单介绍
- Collection of Hierarchical Features
方法一:没有FPN,获取一个特征图,以特征图中的T通道作为基础,按照不同“帧率”选择BATCH_SIZE, C, H, W特征图。与下图展示不同。
方法二:有FPN,根据不同层特征图拥有不同的通道T,作为不同帧率作为后续输入。 - Spatial Semantic Modulation:大概意思是,从backbone获取的不同深度的空间语义特征不一致,通过卷积操作设置为相同尺寸。如下图中,这一层的结果的尺寸完全相同。
- Temporal Rate Modulation:就是获取不同帧率的特征图。这一步应该就是所谓的。
- Information Flow:特征融合
- Collection of Hierarchical Features
Transformer Based
SWIN
2021🔥 code
Video Swin Transformer,严格遵循原始Swin Transformer的层次结构,但将局部注意力计算的范围从仅空间域扩展到了时空域。由于局部注意力是在非重叠窗口上计算的,所以原始的Swin Transformer移位窗口机制也被重新表述为处理时空输入。
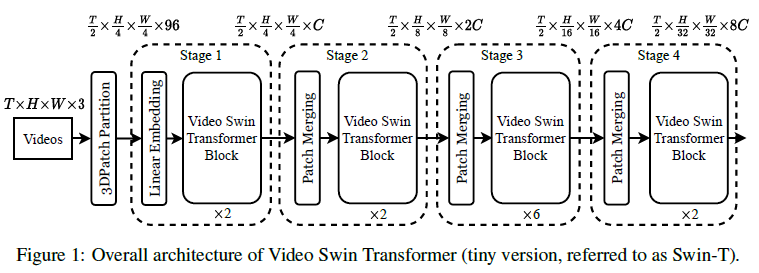
3D Patch Partition:将大小为2443的每个3D小块视为一个标记token。3D Patch Partition layer获得$ T / 2 ∗ H / 4 ∗ W / 4 T/2 * H/4 * W/4 T/2∗H/4∗W/4$个3维tokens,每个patch/token由96维特征组成
Linear Embedding:将每个token的特征投影到C维。
Patch Merging Layer:连接每组22个空间相邻的patch的特征,并应用线性层将连接的特征投影到其尺寸的一半
Video Swin Transformer block:它是通过将标准transformer中的多头自关注(MSA)模块替换为基于3D移动窗口的多头自关注模块并保持其他组件不变。
image–>video的改变
(1)原始的image recognition中的Swing Transformer中的embedding layer的size是video中的一半(时间纬度为2),因此作者直接将其复制两次,然后乘以0.5以保证均值和方差。
(2)对于relative position bias,原始的是(2M-1,2M-1),而video中是(2P-1,2M-1,2M-1),也是直接复制2P-1次以保证每一帧中的相对位置偏差一致
MViT V2
2022📕 MViTv2: Improved Multiscale Vision Transformers for Classification and Detection
🔥 code
在本文中,作者开发了两个简单的技术改进,以进一步提高其性能,并研究MViT作为一个单一模型家族的视觉识别横跨3个任务:图像分类、目标检测和视频分类,以了解它是否可以作为空间和时空识别任务的一般视觉主干。本文的实验研究产生了一个改进的架构(MViTv2),包括以下内容:
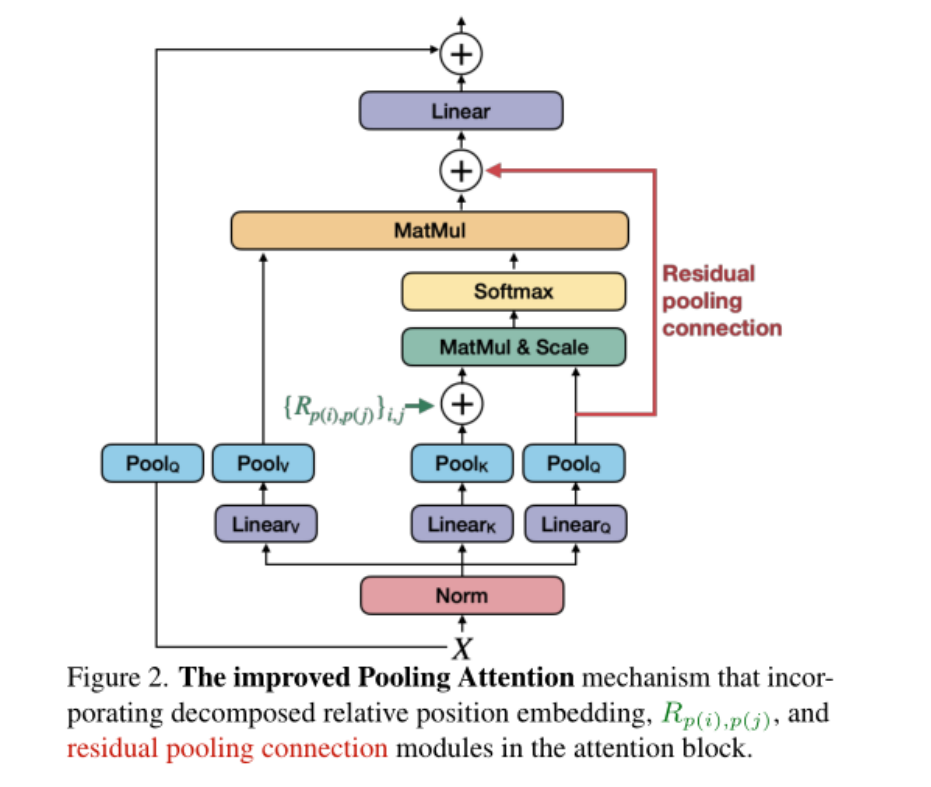
(1) 作者创建了强baseline,以改善沿两个轴的注意力:(a)使用分解的位置距离进行平移不变的位置嵌入,以在Transformer块中注入位置信息;(b) 一种残差池化连接,用于补偿在注意力计算中池化的影响。本文简单而有效的升级带来了显著更好的结果。
(2)利用改进的MViT结构,作者采用了一个标准的密集预测框架:带特征金字塔网络(FPN)的Mask R-CNN,并将其应用于目标检测和实例分割。作者研究了MViT是否可以通过池化注意力来处理高分辨率的视觉输入,以克服所涉及的计算和内存开销。实验表明,池化注意力比局部窗口注意机制(如Swin)更有效。作者进一步开发了一种简单而有效的混合窗口注意方案,该方案可以补充池化注意,以实现更好的准确性/计算权衡。
(3)作者以五种复杂的尺寸(宽度、深度、分辨率)实例化了本文的结构,并报告了大型多尺度Transformer的实用训练方法。MViT变体应用于图像分类、目标检测和视频分类,只需稍加修改,即可研究其作为通用视觉结构的目的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号