
TCP/IP知识总结
1. 网络协议
1.1 TCP
TCP报头:
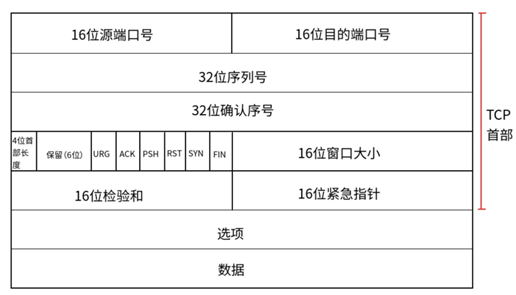
最小报头: 20Byte.
1.1.1 TCP三次握手
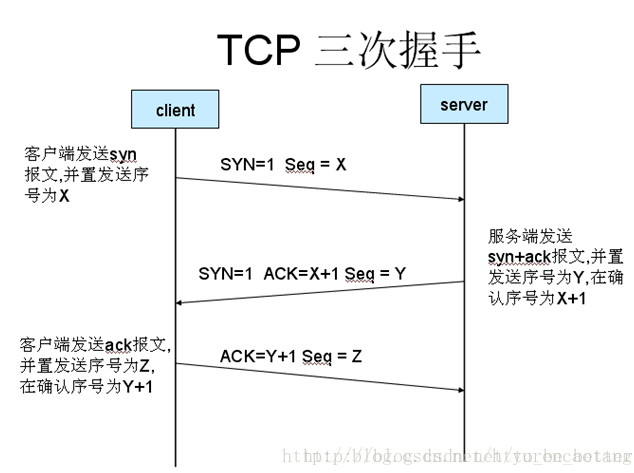
为什么需要三次握手?不是两次或者四次?
- 首先得说,TCP三次握手其实是可以理解成四次,之所以是三次是因为服务端发送的是
ACK+SYN包,即合并了两个包,导致握手比挥手少了一次。之所以能这样,是因为连接还未建立时,服务端是没有多余的数据需要发送给客户端的,大家可以想一下挥手时,服务端发送ACK和FIN包之间可能并不是连续进行的,中间的时间就是预留给服务端发送数据的,发送完后它才会在发出SYN包表示自己已准备断开连接。- 其次,如果握手是两次的话,也就是最后客户端不发送
ACK给服务端。当服务端发送完ACK包后,就认为连接已建立的话,如果这个包客户端没收到,那么客户端就会认为连接没建立,它就会重发SYN包,可能导致服务端重复建立连接,消耗系统资源,严重甚至可能导致系统崩溃。
1.1.2 TCP四次挥手
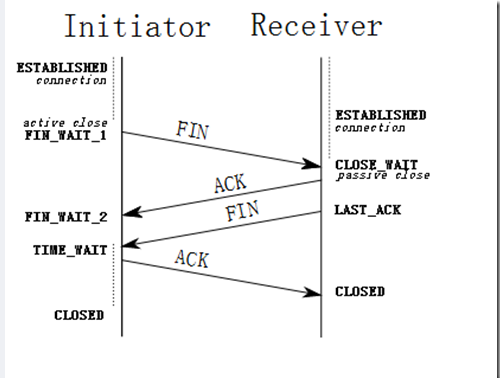
为什么需要四次挥手
和"为什么是三次握手"的问题相对应,服务端会发送两个包,这个在握手过程中是被合并成一个包。这个包之间,服务端要等待将其他没有发送完的数据发送完成。
为什么有TIME_WAIT状态
作用主要有两个:
- 可靠的关闭全双工TCP连接。假如没有这个状态,客户端最后发送完
ACK就自己关闭的话,这个ACK包有可能在网络中丢失,服务端没有接收到,根据TCP包重传的机制,服务端此时又会发送FIN包,而此时已经关闭的客户端接收到FIN包时,会响应一个RST包,这对服务端来说是个错误状态。- 让旧的数据包在网络中消逝。这也是为什么需要
2MSL时间(发送+应答)。假设连接断开又迅速建立新的连接,前一次连接的某些数据仍然留在网络中,这些延迟数据在若在建立了新连接之后才到达Server,由于新连接和老连接端口是一样的(IP五元组一致),那和就会新旧连接数据混淆。
TIME_WAIT状态危害
因为2MSL时间一般不短(缺省状态就能达到几百秒),而这期间,端口号以及对应的连接状态等资源是不会被释放的。因此当某些场景下会存在大量的TIME_WAIT状态,消耗资源不说,端口号占用也会导致一些想启动的服务无法启动。
如何避免TIME_WAIT危害
常用做法是开启端口复用:SO_REUSEADDR。
注:开启端口复用后,如果一台机器上存在多个服务监听在一个端口上,一般只有第一个绑定该端口的TCP/UDP连接能接收到数据;而如果想多个服务同时收到,可以考虑使用组播。
1.1.3 TCP粘包问题
何为粘包?
粘包只是一个通俗的说法,还有半包也是类似的问题,指的是收到的数据包的数据可能并不是我们发送时预想的样子,比如可能包含上一个发送或者下一部个发送的部分等等情况,即不能按照发送时的设计来对应实际收到的数据包。比如发送端发送ABC和DEF两个包,但是实际收到的可能是ABCD+EF或者AD+C+DE+F等很多可能。
产生粘包的原因
应用A通过网络发送数据向应用B发送消息,大概会经过如下阶段:
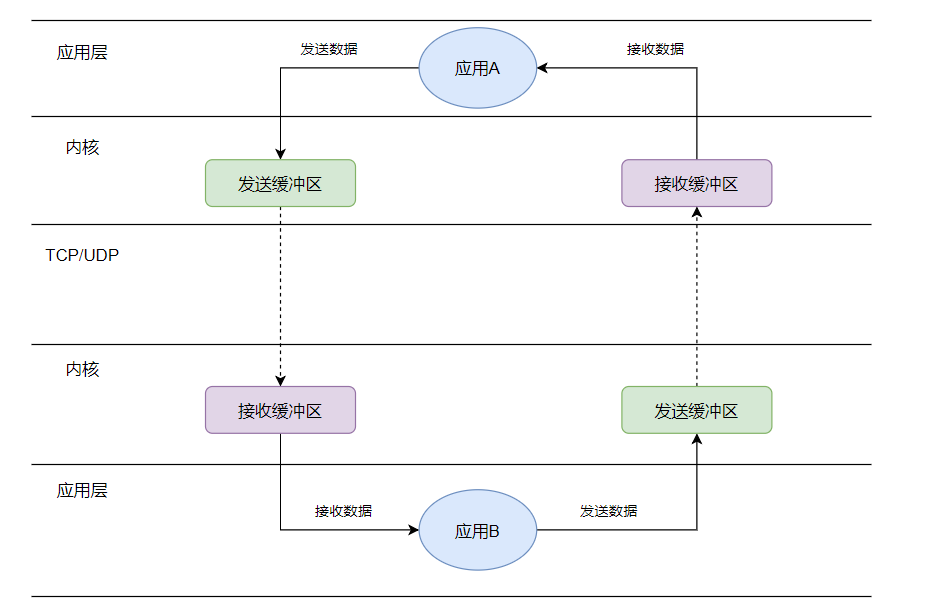
主要原因包括:
- 发送方的问题:TCP包本身可能会过大,需要对他进行拆包;
negal算法会对小包进行优化,先放入接收缓冲区中,组成大的数据包后再发送。 - 接收方的问题:接收方从接收缓冲区中读取数据时,优于TCP是基于字节流的协议,数据没有明确的边界,因此读取的时候是不会区分包的,而是尽量读取一部分数据。(这是和UDP最大的区别,UDP是有明确边界的,因此它不存在粘包半包等问题)。
TCP是基于字节流的协议,数据无边界;UDP是基于数据报的协议,有明确边界。这是TCP有粘包半包问题,而UDP没有的核心原因。
如何解决粘包问题?
解决问题当然是要从产生问题的原因着手,有的人可能会回答关闭negal算法等,那只是在发送端解决了一部分问题,并不能解决最后区分不了包的问题。可靠的做法还是从应用层去解决:自定义用户层传输协议,听起来高大上,其实通俗点就是用户在应用层自定义数据边界。
比如:
- 固定大小,即每次都传输固定长度大小的数据,但不够时填充默认数据。
- 封装成'帧',简单讲就是
HEAD+BODY的组合,头部设置固定长度字段,带上body长度,每次接收时先接收固定长度的head,根据head里面的body长度信息,去接收body。 - 字符边界,即采用很明确的分隔符,这个其实在很多协议设计里是用到的。
实际开发中,程序猿应该是更加常用封装的解决方法,比较灵活。
1.1.4 TCP流量控制
TCP中的流量控制主要是通过滑动窗口实现的。
首先,为什么需要流量控制?
如果发送端的发送速度远大于接收端的接收速度,不做控制的话,接收端无法接收,会导致网络大量丢包,也浪费网络资源。
因此,流量控制即指对发送端的发送速率的控制。
滑动窗口的工作原理?
我们都知道TCP发送包是需要收到ACK确认的。那么在发送数据时,发送端存在一个发送窗口,接收端存在一个接收窗口。
对于发送端来说,滑动窗口如下图所示:

只有落在滑动窗口内的包才会发送;只有按顺序接收到ACK后才会将滑动窗口向后移动。
接收窗口可能的示意图:
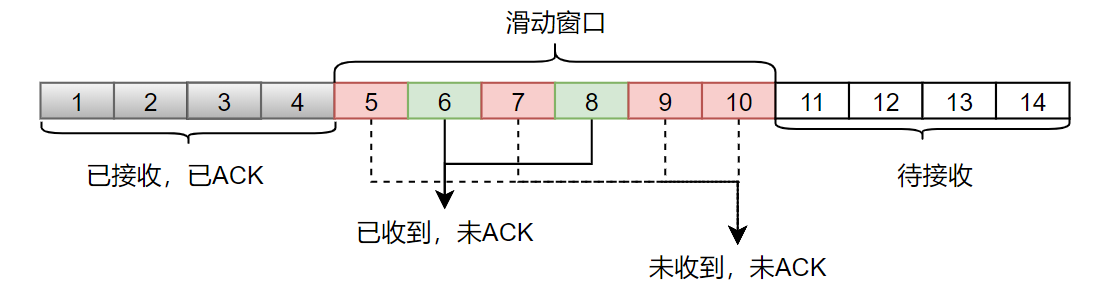
接收端发送的ACK是按顺序发送的,即它必须等到收到包5,发送包5的ack之后才会发送包6的ack,才能移动窗口。回复一个ack,就表示之前的所有包都已收到。
如此操作,就能限制发送方发送数据包的速率。
第一次的发送窗口大小是根据链路状态,即拥塞窗口大小决定的;后面发送窗口大小是接收端接收窗口大小和拥塞窗口大小共同决定。当然接收窗口大小可能会动态改变。TCP协议中有个字段可以带上窗口大小信息。
1.1.5 TCP拥塞控制
滑动窗口是对发送接收双方的流量控制,流量控制并不能完全避免拥塞,TCP还利用拥塞窗口实现拥塞控制。
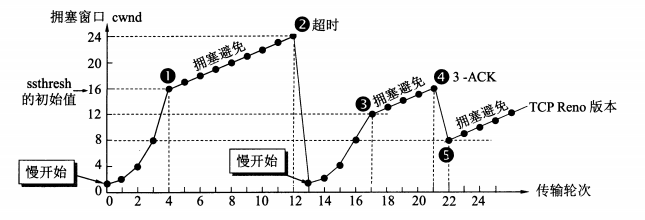
拥塞控制分为四个阶段,每个阶段的处理策略都不同,大概就是先猛增,然后小心增长预防拥塞,还有就是已经发生拥塞了的措施和快速恢复。
-
慢启动
慢启动并不代表拥塞窗口大小增长的慢,只是初始值比较小。 -
拥塞避免
拥塞避免并不能完全避免拥塞,只是说拥塞窗口线性增长,使网络不容易出现拥塞。 -
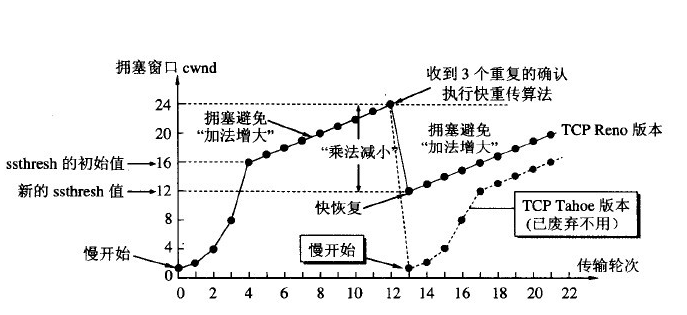
快重传
快重传要求接收方在收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方)而不要等到自己发送数据时捎带确认。快重传算法规定,发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器时间到期。
![image]()
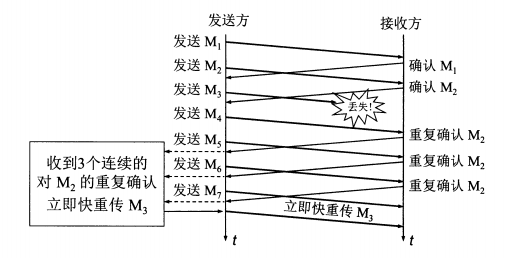
由于不需要等待设置的重传计时器到期,能尽早重传未被确认的报文段,能提高整个网络的吞吐量。
- 快恢复
和快重传搭配使用。当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把ssthresh门限减半。但是接下去并不执行慢开始算法。
发送方窗口的上限值=Min(接受窗口rwnd,拥塞窗口cwnd)
网络拥塞的标志:
1.重传计时器超时,进入慢启动;
2.接收到三个重复确认,进入快重传和快恢复。
1.2 UDP
UDP报头:
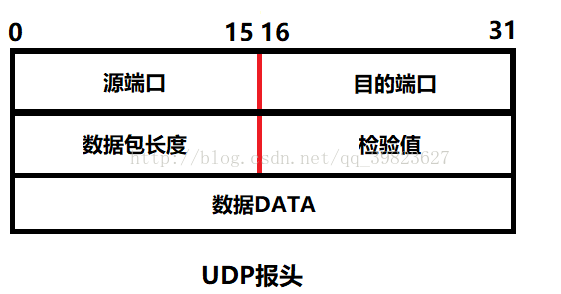
最短报头: 8Byte.
1.2.1 如何使UDP可靠?
首先得明确TCP可靠的机制包括哪些:
- 超时重传;
- 确认和应答;
- 数据校验;
- 流量控制;
- 拥塞控制;
- ......
对于UDP,需要在应用层加入可靠性设计,比如加入确认机制、数据校验、超时重传等等。
已有类似的协议,比如UDT、QUIC等。
1.2.2 广播
广播使用广播地址255.255.255.255,将消息发送到在同一广播网络上的每个主机。值得强调的是:本地广播信息是不会被路由器转发。
广播也是要指明接收者的端口号的。
1.2.3 组播
组播也叫多播,将网络中同一业务类型主机进行了逻辑上的分组,进行数据收发的时候其数据仅仅在同一分组中进行,其他的主机没有加入此分组不能收发对应的数据。
可以一次将数据发送到多个主机,又能保证不影响其他不需要(未加入组)的主机的其他通 信。
组播可以跨网段,可以在广域网上传播。
组播地址是特定的,D类地址用于多播。D类IP地址就是多播IP地址,即224.0.0.0至239.255.255.255之间的IP地址。
2. IO模型
首先,我们需要了解的是IO主要包括两个过程:
- 读存储设备的数据到内核缓存;
- 从内核缓存读取数据到用户空.
其中1操作比2操作慢很多,毕操作2还都是内存操作.
2.1 同步/异步
平时说的同步IO/异步IO是指操作2是否会阻塞.
同步IO就是说发出一个请求后,你需要自己去处理数据,也就是说最终你还是做了处理;(信号驱动IO只是说当有数据时会返回一个回调标识).
异步IO就是说你发出一个请求后,啥都不用管了,它会自动完成.linux下可以使用libaio实现.
我们说的IO复用,都是同步IO.意思只是说是一个或一组线程处理多个请求,毕竟最后处理数据的任务你还是要去管.
2.2 阻塞/非阻塞
平时说的阻塞IO/非阻塞IO指的是操作1是否会阻塞.
阻塞时就是一直等待调用返回;非阻塞时就是隔一段时间轮询查看是否完成,不用一直等在那.
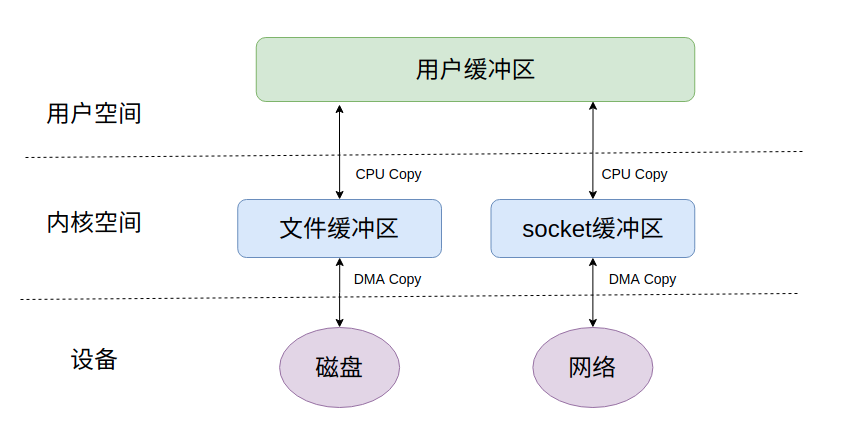
如何理解Linux的零拷贝技术?
回到刚刚的IO模型图,我们的数据拷贝总是要经过内核缓冲区进行缓冲的,好处是可以减少磁盘IO操作;坏处就是用户态和内核态需要频繁切换,会消耗大量的CPU资源,影响性能.
零拷贝就是针对这样的技术,尽量拷贝.
按正常的IO模型, 我们从文件中读取数据,然后再通过socket发送出去,是要经过4步拷贝:
- read将数据从磁盘文件通过DMA等方式拷贝到内缓冲区;
- 数据从内核缓冲区拷贝到用户缓冲;
- write将数据从用户缓冲区拷贝到内核缓冲区;
- 数据从socket内核缓冲通过DMA拷贝到网卡发送出去.
其中两次是DMA直接和硬件通讯完成,CPU不参与.
用户态直接IO:用户态的函数能直接访问硬件设备,跨过内核进行传输.
这种方法其实有问题:直接操作磁盘,会因为CPU和磁盘之间存在执行事件差距,会可能更浪费资源.
mmap:使用mmap可以减少一次IO拷贝,也即内核缓冲区通过mmap和用户缓冲区共享,减少从内核拷到用户缓冲区的过程,发送也可以直接从内核态发往设备.
这个方法使用比较普遍,不过需要注意目标文件不要被另一个进程截获导致异常,可以通过加锁解决.
sendfile: 和mmap一样,数据不用从用户态拷贝到内核态.
还用DMA辅助sendfile减少最后一次拷贝\splic等方法.
2.3 select/poll/epoll区别
select
优点:
- 能同时监听多个描述符,一旦每个描述符就绪,就能够通知应用程序进行响应的读写操作。
缺点:
- 每次调用都需要将fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大;
- 每次调用select都需要轮询遍历所有fd,当fd集合很大时开销很大;
- select支持的文件描述符数量太小,默认是1024(或2048),可通过修改FD_SETSIZE值来更改.
poll
poll和select实现上差不多,只是描述fd集合的方式不同。poll使用pollfd结构而不是select的fd_set结构;基于链表,没有最大文件连接数的限制.
epoll
epoll就是对select和poll的改进。
- 针对select的第一个缺点,epoll是在epoll_ctl函数中,每次注册新的事件到epoll句柄(指定EPOLL_CTL_ADD)时,会把所有的fd拷贝进内核,而不是在epoll_wait时重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
- 针对select的第二个缺点,epoll是在epoll_ctl时为每个fd指定一个回调函数,当设备就绪、唤醒等待队列上的等待者时,就会回调这个回调函数,而这个回调函数就会把就绪的fd加入到一个就绪的链表中。epoll_wait的工作实际上就是在这个链表中查看有没有就绪的fd。
- 针对select的第三个缺点,epoll所支持的fd上限是最大解打开文件的数目,这个数字一般远远大于2048,。具体数目可以查看/proc/sys/fs/file-max查看,一般来说这个数目和系统内存关系很大。
3. 网络模型
分两种: Reactor模型和Proactor模型.
3.1 proactor
典型如asio/iocp,异步非阻塞模型.
3.2 reactor
典型如libevent,同步阻塞模型.我们平常使用的select/poll/epoll也属于reactor模型.
3.3 proactor与reactor的比较
简单理解,reactor模型就是当IO读写事件事件触发时,通知我们自己去主动读写,也就是我们自己需要将内核缓冲区的数据读到用户空间中;
proactor模型就是我们指定一个用户缓冲区地址,交给系统,当有数据到达时,系统会帮我们填充用户缓冲区,只需告诉我们读写了多少字节.
可以想一下,使用asio编程时,我们是无需在回调函数中调用read/write等操作的,因为这些步骤系统都已经帮我们完成了,我们只需知道读写多少字节就行;使用libevent/epoll等,当回调事件触发时,我们还是需要手动调用read/write去读写数据的,这也就是异步/同步的区别所在了.
reactor: 来了事件我通知你,你来处理;
proactor: 来了事件我来处理,处理完了我通知你。
理论上:Proactor比Reactor效率要高一些。
注:其实asio也支持proactor模式
想要使用reactor模式,只需要调用下面两个函数:
socket::async_wait(tcp::socket::wait_read, handler)
socket::async_wait(tcp::socket::wait_write, handler)
在回调中自己调用read/write读写数据.
4. socket编程
4.1 socket通信过程
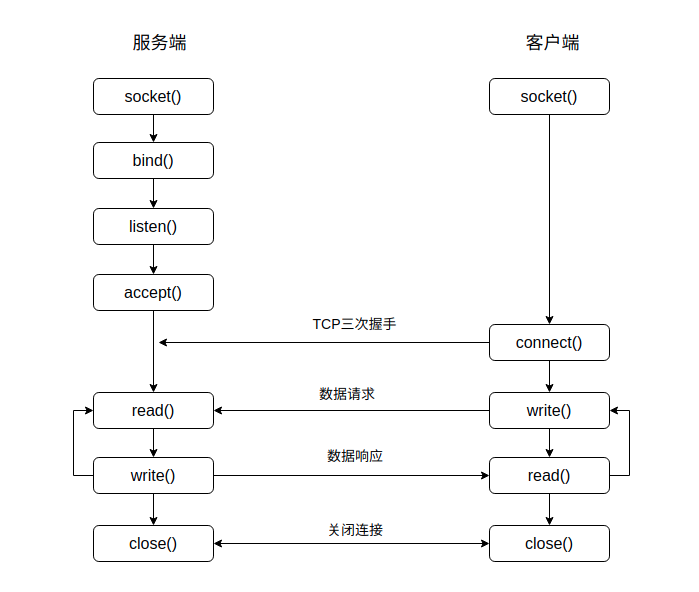
4.2 常用设置
4.2.1 设置端口复用
int opt = 1;
// sockfd为需要端口复用的套接字
setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, (const void *)&opt, sizeof(opt));
注意: 设置端口复用要bind之前.
4.2.2 设置socket非阻塞
有三种方法:
(1) 创建socket的时候,指定socket是异步的,在type的参数中设置SOCK_NONBLOCK标志即可:
int socket(int domain, int type, int protocol);
int s = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, IPPROTO_TCP);
(2) 使用fcntl函数:
fcntl(sockfd, F_SETFL, fcntl(sockfd, F_GETFL, 0) | O_NONBLOCK);
(3) 用ioctl函数:
ioctl(sockfd, FIONBIO, 1); //1:非阻塞 0:阻塞
4.2.3 设置读写超时
读超时:
sockfd = socket(/*...*/);
// 设置超时时间为 5 秒
struct timeval tv;
tv.tv_sec = 5;
tv.tv_usec = 0;
setsockopt(sockfd, SOL_SOCKET, SO_RCVTIMEO, &tv, sizeof(tv));
写超时:
sockfd = socket(/*...*/);
// 设置超时时间为 5 秒
struct timeval tv;
tv.tv_sec = 5;
tv.tv_usec = 0;
setsockopt(sockfd, SOL_SOCKET, SO_SNDTIMEO, &tv, sizeof(tv));

 浙公网安备 33010602011771号
浙公网安备 33010602011771号