

1. 机器学习-特征工程
1. 为什么常常需要对数值型数据的特征做归一化?
为了消除数据特征之间的量纲影响,使不同指标之间具有可比性。数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
归一化的方法主要有:(1)线性函数归一化;
(2)零均值归一化(标准化)。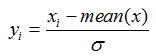
如果对输出结果范围有要求,或者数据较为稳定,不存在极端的取值的清况下,可以使用线性归一化;如果数据存在较多异常或噪声时,可以使用标准化.
通过梯度下降法求解的模型通常是需要归一化的,包括线性回归/逻辑回归/支持向量机/神经网络模型等,但是对于决策树模型则并不适用。
2. 怎样处理类别型特征?
类别型特征主要是指只在有限项内取值的特征。
常见的转换有以下三种:
(1)序号编码;用于处理类别间具有大小关系的数据
(2)独热码;用于处理类别间不具有大小关系的特征,在独热编码下,特征向量只有某一维取1,其他位置均取0.
(3)二进制编码;先用序号编码给每一个类别赋予一个类别ID,再用该类别ID的二进制编码作为结果。相比独热码,它的维数一般较少,节省了存储空间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号