转: 用C++进行设计模式解析与实现
设计模式主要分为3类.
1.创建型模式
前面讲过,社会化的分工越来越细,自然在软件设计方面也是如此,因此对象的创建和对象的使用分开也就成为了必然趋势。因为对象的创建会消耗掉系统的很多资源,所以单独对对象的创建进行研究,从而能够高效地创建对象就是创建型模式要探讨的问题。这里有6个具体的创建型模式可供研究,它们分别是:
简单工厂模式(Simple Factory);
工厂方法模式(Factory Method);
抽象工厂模式(Abstract Factory);
创建者模式(Builder);
原型模式(Prototype);
单例模式(Singleton)。
说明: 严格来说,简单工厂模式不是GoF总结出来的23种设计模式之一。
2.结构型模式
在解决了对象的创建问题之后,对象的组成以及对象之间的依赖关系就成了开发人员关注的焦点,因为如何设计对象的结构、继承和依赖关系会影响到后续程序的维护性、代码的健壮性、耦合性等。对象结构的设计很容易体现出设计人员水平的高低,这里有7个具体的结构型模式可供研究,它们分别是:
外观模式(Facade);
适配器模式(Adapter);
代理模式(Proxy);
装饰模式(Decorator);
桥模式(Bridge);
组合模式(Composite);
享元模式(Flyweight)。
3.行为型模式
在对象的结构和对象的创建问题都解决了之后,就剩下对象的行为问题了,如果对象的行为设计的好,那么对象的行为就会更清晰,它们之间的协作效率就会提高,这里有11个具体的行为型模式可供研究,它们分别是:
模板方法模式(Template Method);
观察者模式(Observer);
状态模式(State);
策略模式(Strategy);
职责链模式(Chain of Responsibility);
命令模式(Command);
访问者模式(Visitor);
调停者模式(Mediator);
备忘录模式(Memento);
迭代器模式(Iterator);
解释器模式(Interpreter)。
设计模式的解析和实现(C++)之一-Factory模式
在面向对象系统设计中经常可以遇到以下的两类问题:
1)为了提高内聚(Cohesion)和松耦合(Coupling),我们经常会抽象出一些类的公共接口以形成抽象基类或者接口。
这样我们可以通过声明一个指向基类的指针来指向实际的子类实现,达到了多态的目的。这里很容易出现的一个问题 n 多的子类继承自抽象基类,我们不得不在每次要用到子类的地方就编写诸如 new ×××;的代码。这里带来两个问题 1)客户程序员必须知道实际子类的名称(当系统复杂后,命名将是一个很不好处理的问题,为了处理可能的名字冲突,有的命名可能并不是具有很好的可读性和可记忆性,就姑且不论不同程序员千奇百怪的个人偏好了。,2)程序的扩展性和维护变得越来越困难。
2)还有一种情况就是在父类中并不知道具体要实例化哪一个具体的子类。这里的意思为:假设我们在类 A 中要使用到类 B,B 是一个抽象父类,在 A 中并不知道具体要实例化那一个 B 的子类,但是在类 A 的子类 D 中是可以知道的。在 A 中我们没有办法直接使用类似于 new ×××的语句,因为根本就不知道×××是什么。
以上两个问题也就引出了 Factory 模式的两个最重要的功能:
1)定义创建对象的接口,封装了对象的创建;
2)使得具体化类的工作延迟到了子类中。
模式选择:
我们通常使用 Factory 模式来解决上面给出的两个问题。在第一个问题中,我们经常就是声明一个创建对象的接口,并封装了对象的创建过程。Factory 这里类似于一个真正意义上的工厂(生产对象)。在第二个问题中,我们需要提供一个对象创建对象的接口,并在子类中提供其具体实现(因为只有在子类中可以决定到底实例化哪一个类)。
第一中情况的 Factory 的结构示意图为:
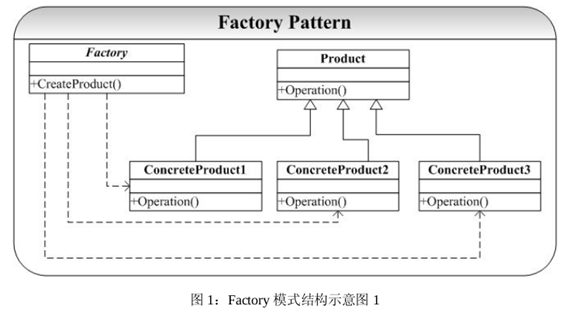
图 1 所以的 Factory 模式经常在系统开发中用到,但是这并不是 Factory 模式的最大威力所在(因为这可以通过其他方式解决这个问题)。Factory 模式不单是提供了创建对象的接口,其最重要的是延迟了子类的实例化(第二个问题),以下是这种情况的一个 Factory 的结构示意图:
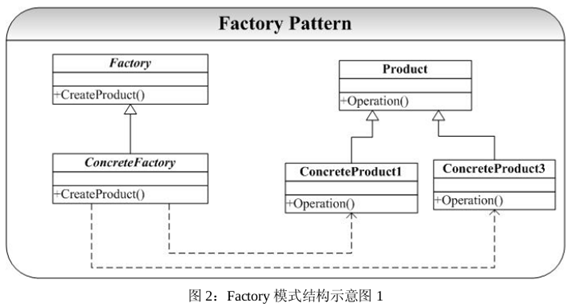
图 2 中关键中 Factory 模式的应用并不是只是为了封装对象的创建,而是要把对象的创建放到子类中实现:Factory 中只是提供了对象创建的接口,其实现将放在 Factory 的子类ConcreteFactory 中进行。这是图 2 和图 1 的区别所在。
实现代码如下:
 View Code
View Code 
#define _PRODUCT_H_
class Product{
public:
virtual ~Product();
virtual void Operation()=0;
protected:
Product();
};
class ConcreteProduct1:
public Product{
public:
ConcreteProduct1();
~ConcreteProduct1();
void Operation();
};
class ConcreteProduct0:
public Product{
public:
ConcreteProduct0();
~ConcreteProduct0();
void Operation();
};
#endif
View Code #define _FACTORY_H_
class Product;
class Factory{
public:
virtual ~Factory();
virtual Product* CreateProduct(int)=0;
protected:
Factory();
};
class ConcreteFactory:
public Factory{
public:
ConcreteFactory();
~ConcreteFactory();
Product* CreateProduct(int);
};
#endif
View Code #include "Factory.h"
#include "Product.h"
Factory::Factory(){
std::cout<<"constructor of Factory\n";
}
Factory::~Factory(){
std::cout<<"destructor of Factory\n";
}
ConcreteFactory::ConcreteFactory(){
std::cout<<"constructor of ConcreteFactory\n";
}
ConcreteFactory::~ConcreteFactory(){
std::cout<<"destructor of ConcreteFactory\n";
}
Product* ConcreteFactory::CreateProduct(int n){
Product* p=0;
switch(n){
case 0:
p=new ConcreteProduct0;
break;
case 1:
p=new ConcreteProduct1;
break;
}
return p;
}
View Code #include <iostream>
Product::Product(){
std::cout<<"constructor of Product\n";
}
Product::~Product(){
std::cout<<"destructor of Product\n";
}
ConcreteProduct1::ConcreteProduct1(){
std::cout<<"constructor of ConcreteProduct1\n";
}
ConcreteProduct1::~ConcreteProduct1(){
std::cout<<"destructor of ConcreteProduct1\n";
}
void ConcreteProduct1::Operation(){
std::cout<<"Operation of ConcreteProduct1\n";
}
ConcreteProduct0::ConcreteProduct0(){
std::cout<<"constructor of ConcreteProduct0\n";
}
ConcreteProduct0::~ConcreteProduct0(){
std::cout<<"destructor of ConcreteProduct0\n";
}
void ConcreteProduct0::Operation(){
std::cout<<"Operation of ConcreteProduct0\n";
}
View Code #include "Factory.h"
#include "Product.h"
#include <cstdlib>
using namespace std;
int main(){
Factory* f=new ConcreteFactory;
Product *p;
int n=10;
for(int i=0;i<n;i++){
int val=rand()%1000;
p=f->CreateProduct(val%2);
p->Operation();
delete p;
}
delete f;
return 0;
}
设计模式解析和实现之二-Abstract Factory模式
作用:
提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
UML结构图:
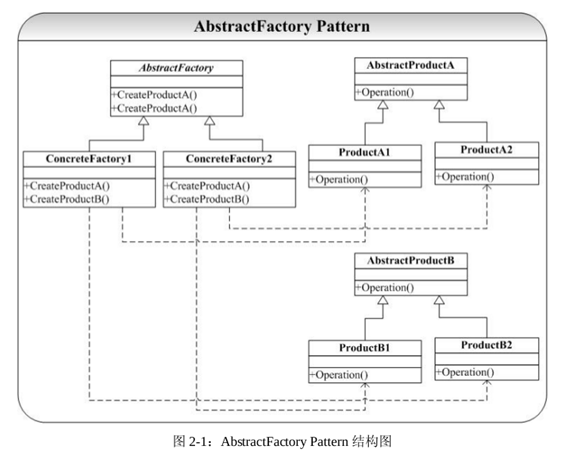
抽象基类:
1)ProductA,ProductB:分别代表不同类型的产品,而它们的派生类则是这种产品的一个实现。
2)AbstractFactory:生产这一系列产品的一个抽象工厂,它的派生类是不同的实现。
接口函数:
1)AbstractFactory::CreateProductA和AbstractFactory::CreateProductB:分别是生产不同产品的不同的实现,由各个派生出来的抽象工厂实现之。
解析:
Abstract Factory模式和Factory最大的差别就是抽象工厂创建的是一系列相关的对象,其中创建的实现其实采用的就是Factory模式的方法,对于某个实现的有一个派生出来的抽象工厂,另一个实现有另一个派生出来的工厂,等等。
可以举一个简单的例子来解释这个模式:比如,同样是鸡腿(ProductA)和汉堡(ProductB),它们都可以有商店出售 (AbstractFactory),但是有不同的实现,有肯德基(ConcreateFactory1)和麦当劳 (ConcreateFactory2)两家生产出来的不同风味的鸡腿和汉堡(也就是ProductA和ProductB的不同实现)。
而负责生产汉堡和鸡腿的就是之前提过的Factory模式了。
抽象工厂需要特别注意的地方就是区分不同类型的产品和这些产品的不同实现。显而易见的,如果有n种产品同时有m中不同的实现,那么根据乘法原理可知有n*m个Factory模式的使用。
讨论
AbstractFactory 模式和 Factory 模式的区别是初学(使用)设计模式时候的一个容易引起困惑的地方。实际上,AbstractFactory 模式是为创建一组(有多类)相关或依赖的对象提供创建接口,而 Factory 模式正如我在相应的文档中分析的是为一类对象提供创建接口或延迟对象的创建到子类中实现。并且可以看到,AbstractFactory 模式通常都是使用 Factory 模式实现(ConcreteFactory1)。
实现代码如下:
View Code #define _FACTORY_H_
class AbstractProductA;
class AbstractProductB;
class AbstractFactory{
public:
virtual ~AbstractFactory();
virtual AbstractProductA* CreateProductA(int)=0;
virtual AbstractProductB* CreateProductB(int)=0;
protected:
AbstractFactory();
};
class ConcreteFactory0:
public AbstractFactory{
public:
ConcreteFactory0();
~ConcreteFactory0();
AbstractProductA* CreateProductA(int);
AbstractProductB* CreateProductB(int);
};
class ConcreteFactory1:
public AbstractFactory{
public:
ConcreteFactory1();
~ConcreteFactory1();
AbstractProductA* CreateProductA(int);
AbstractProductB* CreateProductB(int);
};
#endif
View Code #define _PRODUCT_H_
class AbstractProductA{
public:
virtual ~AbstractProductA();
virtual void Operation()=0;
protected:
AbstractProductA();
};
class AbstractProductB{
public:
virtual ~AbstractProductB();
virtual void Operation()=0;
protected:
AbstractProductB();
};
class ProductA0:
public AbstractProductA{
public:
ProductA0();
~ProductA0();
void Operation();
};
class ProductA1:
public AbstractProductA{
public:
ProductA1();
~ProductA1();
void Operation();
};
class ProductB0:
public AbstractProductB{
public:
ProductB0();
~ProductB0();
void Operation();
};
class ProductB1:
public AbstractProductB{
public:
ProductB1();
~ProductB1();
void Operation();
};
#endif
View Code #include <iostream>
AbstractProductA::AbstractProductA(){
std::cout<<"constructor of AbstractProductA\n";
}
AbstractProductA::~AbstractProductA(){
std::cout<<"destructor of AbstractProductA\n";
}
AbstractProductB::AbstractProductB(){
std::cout<<"constructor of AbstractProductB\n";
}
AbstractProductB::~AbstractProductB(){
std::cout<<"destructor of AbstractProductB\n";
}
ProductA0::ProductA0(){
std::cout<<"constructor of ProductA0\n";
}
ProductA0::~ProductA0(){
std::cout<<"destructor of ProductA0\n";
}
void ProductA0::Operation(){
std::cout<<"Operation of ConcreteProductA0\n";
}
ProductA1::ProductA1(){
std::cout<<"constructor of ProductA1\n";
}
ProductA1::~ProductA1(){
std::cout<<"destructor of ProductA1\n";
}
void ProductA1::Operation(){
std::cout<<"Operation of ConcreteProductA1\n";
}
ProductB0::ProductB0(){
std::cout<<"constructor of ProductB0\n";
}
ProductB0::~ProductB0(){
std::cout<<"destructor of ProductB0\n";
}
void ProductB0::Operation(){
std::cout<<"Operation of ConcreteProductB0\n";
}
ProductB1::ProductB1(){
std::cout<<"constructor of ProductB1\n";
}
ProductB1::~ProductB1(){
std::cout<<"destructor of ProductB1\n";
}
void ProductB1::Operation(){
std::cout<<"Operation of ConcreteProductB1\n";
}
View Code #include "Factory.h"
#include "Product.h"
AbstractFactory::AbstractFactory(){
std::cout<<"constructor of AbstractFactory\n";
}
AbstractFactory::~AbstractFactory(){
std::cout<<"destructor of AbstractFactory\n";
}
ConcreteFactory0::ConcreteFactory0(){
std::cout<<"constructor of ConcreteFactory0\n";
}
ConcreteFactory0::~ConcreteFactory0(){
std::cout<<"destructor of ConcreteFactory\n";
}
AbstractProductA* ConcreteFactory0::CreateProductA(int n){
AbstractProductA* p=0;
switch(n){
case 0:
p=new ProductA0;
break;
case 1:
p=new ProductA1;
break;
}
return p;
}
AbstractProductB* ConcreteFactory0::CreateProductB(int n){
AbstractProductB* p=0;
switch(n){
case 0:
p=new ProductB0;
break;
case 1:
p=new ProductB1;
break;
}
return p;
}
ConcreteFactory1::ConcreteFactory1(){
std::cout<<"constructor of ConcreteFactory1\n";
}
ConcreteFactory1::~ConcreteFactory1(){
std::cout<<"destructor of ConcreteFactory\n";
}
AbstractProductA* ConcreteFactory1::CreateProductA(int n){
AbstractProductA* p=0;
switch(n){
case 0:
p=new ProductA0;
break;
case 1:
p=new ProductA1;
break;
}
return p;
}
AbstractProductB* ConcreteFactory1::CreateProductB(int n){
AbstractProductB* p=0;
switch(n){
case 0:
p=new ProductB0;
break;
case 1:
p=new ProductB1;
break;
}
return p;
}
View Code #include "Factory.h"
#include "Product.h"
#include <cstdlib>
using namespace std;
int main(){
AbstractFactory* f=new ConcreteFactory1;
AbstractProductA* pA;
AbstractProductB* pB;
int n=10;
for(int i=0;i<n;i++){
int val=rand()%1000;
pA=f->CreateProductA(val%2);
pA->Operation();
val=rand()%1000;
pB=f->CreateProductB(val%2);
pB->Operation();
delete pA;
delete pB;
}
delete f;
return 0;
}
设计模式的解析和实现(C++)之三-Builder模式
作用:
将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
UML结构图:
适用于以下情况:
1)当创建复杂对象的算法应该独立于该对象的组成部分以及它们的装配方式时。
2)当构造过程必须允许被构造的对象有不同的表示时。
抽象基类:
1)Builder:这个基类是全部创建对象过程的抽象,提供构建不同组成部分的接口函数
接口:
1)Builder::BuildPartA,Builder::BuildPartB:是对一个对象不同部分的构建函数接口,Builder的派生类来具体实现。
另外还有一个需要注意的函数,就是Director::Construct函数,这个函数里面通过调用上面的两个接口函数完成对象的构建——也就是说各个 不同部分装配的过程都是一致的(同样的调用的Construct函数),但是不同的构建方式会有不同的表示(根据Builder的实际类型来决定如何构 建,也就是多态)
解析:
Builder模式是基于这样的一个情况:一个对象可能有不同的组成部分,这几个部分的不同的创建对象会有不同的表示,但是各个部分之间装配的方式是一致的。比方说一辆单车,都是由车轮车座等等的构成的(一个对象不同的组成部分),不同的品牌生产出来的也不一样(不同的构建方式)。虽然不同的品牌构建出来 的单车不同,但是构建的过程还是一样的(哦,你见过车轮长在车座上的么?)。
实现代码如下:
View Code #define _DIRECTOR_H_
class Builder;
class Director{
public:
Director(Builder*);
~Director();
void Construct();
private:
Builder* _bldr;
};
#endif
View Code #define _BUILDER_H_
class Builder{
public:
Builder();
virtual ~Builder();
virtual void BuildPartA()=0;
virtual void BuildPartB()=0;
virtual void BuildPartC()=0;
};
class ConcreteBuilder0:
public Builder{
public:
ConcreteBuilder0();
~ConcreteBuilder0();
void BuildPartA();
void BuildPartB();
void BuildPartC();
};
class ConcreteBuilder1:
public Builder{
public:
ConcreteBuilder1();
~ConcreteBuilder1();
void BuildPartA();
void BuildPartB();
void BuildPartC();
};
#endif
View Code #include "Director.h"
#include <iostream>
Director::Director(Builder* b){
std::cout<<"constructor of Director\n";
_bldr=b;
}
Director::~Director(){
std::cout<<"destructor of Director\n";
if(_bldr!=0){
delete _bldr;
_bldr=0;
}
}
void Director::Construct(){
_bldr->BuildPartA();
_bldr->BuildPartB();
_bldr->BuildPartC();
}
View Code #include "Builder.h"
Builder::Builder(){
std::cout<<"constructor of Builder\n";
}
Builder::~Builder(){
std::cout<<"destructor of Builder\n";
}
ConcreteBuilder0::ConcreteBuilder0(){
std::cout<<"constructor of ConcreteBuilder0\n";
}
ConcreteBuilder0::~ConcreteBuilder0(){
std::cout<<"destructor of ConcreteBuilder0\n";
}
void ConcreteBuilder0::BuildPartA(){
std::cout<<"Part A has been built\n";
}
void ConcreteBuilder0::BuildPartB(){
std::cout<<"Part B has been built\n";
}
void ConcreteBuilder0::BuildPartC(){
std::cout<<"Part C has been built\n";
}
ConcreteBuilder1::ConcreteBuilder1(){
std::cout<<"constructor of ConcreteBuilder1\n";
}
ConcreteBuilder1::~ConcreteBuilder1(){
std::cout<<"destructor of ConcreteBuilder1\n";
}
void ConcreteBuilder1::BuildPartA(){
std::cout<<"Part A has been built\n";
}
void ConcreteBuilder1::BuildPartB(){
std::cout<<"Part B has been built\n";
}
void ConcreteBuilder1::BuildPartC(){
std::cout<<"Part C has been built\n";
}
View Code #include "./Director.h"
#include <iostream>
#include <cstdlib>
using namespace std;
int main(){
Director *p=0;
int n=5;
for(int i=0;i<n;i++){
int val=rand()%100;
if(val%2)
p=new Director(new ConcreteBuilder1);
else
p=new Director(new ConcreteBuilder0);
p->Construct();
delete p;
}
}
设计模式的解析和实现(C++)之四-Prototype模式
作用:
用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
UML结构图:

抽象基类:
1)Prototype:虚拟基类,所有原型的基类,提供Clone接口函数
接口函数:
1)Prototype::Clone函数:纯虚函数,根据不同的派生类来实例化创建对象。
解析:
Prototype模式其实就是常说的"虚拟构造函数"一个实现,C++的 实现机制中并没有支持这个特性,但是通过不同派生类实现的Clone接口函数可以完成与"虚拟构造函数"同样的效果。举一个例子来解释这个模式的作用,假 设有一家店铺是配钥匙的,他对外提供配制钥匙的服务(提供Clone接口函数),你需要配什么钥匙它不知道只是提供这种服务,具体需要配什么钥匙只有到了 真正看到钥匙的原型才能配好。也就是说,需要一个提供这个服务的对象,同时还需要一个原型(Prototype),不然不知道该配什么样的钥匙。
实现代码如下:
View Code #define _PROTOTYPE_H_
class Prototype{
public:
Prototype();
virtual ~Prototype();
virtual Prototype* Clone()=0;
};
class ConcretePrototype0:
public Prototype{
public:
ConcretePrototype0();
~ConcretePrototype0();
ConcretePrototype0(const ConcretePrototype0&);
Prototype* Clone();
};
class ConcretePrototype1:
public Prototype{
public:
ConcretePrototype1();
~ConcretePrototype1();
ConcretePrototype1(const ConcretePrototype1&);
Prototype* Clone();
};
#endif
View Code #include <iostream>
Prototype::Prototype(){
std::cout<<"constructor of Prototype\n";
}
Prototype::~Prototype(){
std::cout<<"destructor of Prototype\n";
}
ConcretePrototype0::ConcretePrototype0(){
std::cout<<"constructor of ConcretePrototype0\n";
}
ConcretePrototype0::~ConcretePrototype0(){
std::cout<<"destructor of ConcretePrototype0\n";
}
ConcretePrototype0::ConcretePrototype0(const ConcretePrototype0& rhs){
std::cout<<"Copy constructor of ConcretePrototype0\n";
}
Prototype* ConcretePrototype0::Clone(){
return new ConcretePrototype0(*this);
}
ConcretePrototype1::ConcretePrototype1(){
std::cout<<"constructor of ConcretePrototype1\n";
}
ConcretePrototype1::~ConcretePrototype1(){
std::cout<<"destructor of ConcretePrototype1\n";
}
ConcretePrototype1::ConcretePrototype1(const ConcretePrototype1& rhs){
std::cout<<"Copy constructor of ConcretePrototype1\n";
}
Prototype* ConcretePrototype1::Clone(){
return new ConcretePrototype1(*this);
}
View Code #include <cstdlib>
#include "./Prototype.h"
using namespace std;
int main(){
Prototype *p0=new ConcretePrototype0;
Prototype *p1=new ConcretePrototype1;
int n=5;
Prototype* pp;
for(int i=0;i<n;i++){
int val=rand()%1000;
if(val%2)
pp=p1->Clone();
else
pp=p0->Clone();
delete pp;
}
delete p0;
delete p1;
}
讨论
Prototype 模式通过复制原型(Prototype)而获得新对象创建的功能,这里 Prototype 本身就是"对象工厂"(因为能够生产对象),实际上 Prototype 模式和 Builder 模式、AbstractFactory 模式都是通过一个类(对象实例)来专门负责对象的创建工作(工厂对象),它们之间的区别是:Builder 模式重在复杂对象的一步步创建(并不直接返回对象),AbstractFactory 模式重在产生多个相互依赖类的对象,而 Prototype 模式重在从自身复制自己创建新类。
设计模式的解析和实现(C++)之五-Singleton模式
作用:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
UML结构图:

解析:
Singleton模式其实是对全局静态变量的一个取代策略,上面提到的Singleton模式的两个作用在C++中是通过如下的机制实现的:1)仅有一个实例,提供一个类的静态成员变量,大家知道类的静态成员变量对于一个类的所有对象而言是惟一的 2)提供一个访问它的全局访问点,也就是提供对应的访问这个静态成员变量的静态成员函数,对类的所有对象而言也是惟一的。在C++中,可以直接使用类域进行访问而不必初始化一个类的对象。
实现代码如下:
View Code #define _SINGLETON_H_
class Singleton{
public:
static Singleton* Instance();
private:
Singleton();
private:
static Singleton* _instance;
};
#endif
View Code #include <iostream>
Singleton* Singleton::_instance=0;
Singleton::Singleton(){
std::cout<<"constructor of Singleton\n";
}
Singleton* Singleton::Instance(){
if(_instance==0){
_instance=new Singleton;
}
return _instance;
}
View Code #include <iostream>
using namespace std;
int main(){
int n=5;
Singleton* p;
for(int i=0;i<n;i++){
p=Singleton::Instance();
cout<<(void*)p<<endl;
}
delete p;
}
设计模式的解析和实现(C++)之六-Adapt模式
作用:
将一个类的接口转换成客户希望的另外一个接口。Adapt 模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
UML示意图
1)采用继承原有接口类的方式
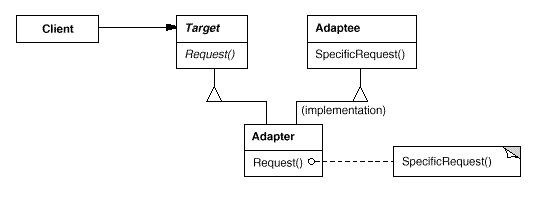
2)采用组合原有接口类的方式

解析:
Adapt模式其实就是把完成同样的一个功能但是接口不能兼容的类桥接在一起使之可以在一起工作,这个模式使得复用旧的接口成为可能。
实现代码如下:
Adapt模式有两种实现办法,一种是采用继承原有接口类的方法,一种是采用组合原有接口类的方法,这里采用的是第二种实现方法。
代码实现如下:
View Code #include <iostream>
Target::Target(){
std::cout<<"Target::Target()\n";
}
Target::~Target(){
std::cout<<"Target::~Target()\n";
}
void Target::Request(){
std::cout<<"Target::Request()\n";
}
Adaptee::Adaptee(){
std::cout<<"Adaptee::Adaptee()\n";
}
Adaptee::~Adaptee(){
std::cout<<"Adaptee::~Adaptee()\n";
}
void Adaptee::SpecificRequest(){
std::cout<<"Adaptee::SpecificRequest()\n";
}
Adapter::Adapter(Adaptee* adp){
std::cout<<"Adapter::Adapter(Adaptee*)\n";
this->_adp=adp;
}
Adapter::~Adapter(){
std::cout<<"Adapter::~Adapter() ";
if(_adp!=0){
delete _adp;
_adp=0;
}
}
void Adapter::Request(){
std::cout<<"Adapter::Request() ";
_adp->SpecificRequest();
}
View Code #include "./Adapter.h"
using namespace std;
int main(){
Adaptee *pad=new Adaptee;
Target *pt=new Adapter(pad);
pt->Request();
delete pt;
}
View Code #define _ADAPTER_H_
class Target{
public:
Target();
virtual ~Target();
virtual void Request();
};
class Adaptee{
public:
Adaptee();
~Adaptee();
void SpecificRequest();
};
class Adapter:public Target{
public:
Adapter(Adaptee* adp);
void Request();
~Adapter();
private:
Adaptee* _adp;
};
#endif
设计模式的解析和实现(C++)之七-Bridge模式
作用:
将抽象部分与它的实现部分分离,使它们都可以独立地变化。
UML结构图:
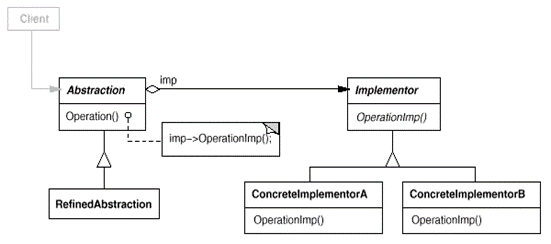
抽象基类:
1)Abstraction:某个抽象类,它的实现方式由Implementor完成。
2)Implementor:实现类的抽象基类,定义了实现Abastraction的基本操作,而它的派生类实现这些接口。
接口函数:
1)Implementor::OperationImpl:定义了为实现Abstraction需要的基本操作,由Implementor的派生类实现之,而在Abstraction::Operation函数中根据不同的指针多态调用这个函数。
解析:
Bridge用于将表示和实现解耦,两者可以独立的变化。在Abstraction类中维护一个Implementor类指针,需要采用不同的实现方式的时候只需要传入不同的Implementor派生类就可以了。
Bridge的实现方式其实和Builder十分的相近,可以这么说:本质上是一样的,只是封装的东西不一样罢了。两者的实现都有如下的共同点:抽象出来一个基类,这个基类里面定义了共有的一些行为,形成接口函数(对接口编程而不是对实现编程),这个接口函数在Buildier中是BuildePart函数, 在Bridge中是OperationImpl函数;其次,聚合一个基类的指针,如Builder模式中Director类聚合了一个Builder基类的指针,而Brige模式中Abstraction类聚合了一个Implementor基类的指针(优先采用聚合而不是继承);而在使用的时候,都把对这个类的使用封装在一个函数中,在Bridge中是封装在Director::Construct函数中,因为装配不同部分的过程是一致的,而在 Bridge模式中则是封装在Abstraction::Operation函数中,在这个函数中调用对应的 Implementor::OperationImpl函数。就两个模式而言,Builder封装了不同的生成组成部分的方式,而Bridge封装了不同 的实现方式。
因此,如果以一些最基本的面向对象的设计原则来分析这些模式的实现的话,还是可以看到很多共同的地方的。
实现代码如下:
View Code #define _ABSTRACTIONIMP_H_
#include <iostream>
class AbstractionImp{
public:
AbstractionImp(){}
virtual ~AbstractionImp(){}
virtual void Operation()=0;
};
class ConcreteAbstractionImp0:
public AbstractionImp{
public:
ConcreteAbstractionImp0(){}
~ConcreteAbstractionImp0(){}
void Operation(){
std::cout<<"ConcreteAbstractionImp0::Operation()\n";
}
};
class ConcreteAbstractionImp1:
public AbstractionImp{
public:
ConcreteAbstractionImp1(){}
~ConcreteAbstractionImp1(){}
void Operation(){
std::cout<<"ConcreteAbstractionImp1::Operation()\n";
}
};
#endif
View Code #define _ABSTRACTION_H_
#include "./AbstractionImp.h"
class Abstraction{
public:
Abstraction(AbstractionImp* imp):_abimp(imp){};
virtual ~Abstraction(){};
virtual void Operation()=0;
protected:
AbstractionImp* _abimp;
};
class RefinedAbstraction:
public Abstraction{
public:
RefinedAbstraction(AbstractionImp* imp):Abstraction(imp){}
~RefinedAbstraction(){
if(_abimp!=0){
delete _abimp;
_abimp=0;
}
}
void Operation(){
_abimp->Operation();
}
};
#endif
View Code #include <iostream>
#include <cstdlib>
using namespace std;
int main(){
Abstraction *pabs;
int n=5;
srand(time(0));
for(int i=0;i<n;i++){
int val=rand()%1000;
if(val%2)
pabs=new RefinedAbstraction(new ConcreteAbstractionImp1);
else
pabs=new RefinedAbstraction(new ConcreteAbstractionImp0);
pabs->Operation();
delete pabs;
}
}
设计模式解析和实现(C++)之八-Composite模式
作用:
将对象组合成树形结构以表示"部分-整体"的层次结构。Composite使得用户对单个对象和组合对象的使用具有一致性。
UML结构图:

抽象基类:
1)Component:为组合中的对象声明接口,声明了类共有接口的缺省行为(如这里的Add,Remove,GetChild函数),声明一个接口函数可以访问Component的子组件。
接口函数:
1)Component::Operatation:定义了各个组件共有的行为接口,由各个组件的具体实现。
2)Component::Add添加一个子组件
3)Component::Remove::删除一个子组件。
4)Component::GetChild:获得子组件的指针。
解析:
Component模式是为解决组件之间的递归组合提供了解决的办法,它主要分为两个派生类,其中的Leaf是叶子结点,也就是不含有子组件的结点,而 Composite是含有子组件的类。举一个例子来说明这个模式,在UI的设计中,最基本的控件是诸如Button,Edit这样的控件,相当于是这里的 Leaf组件,而比较复杂的控件比如List则可也看做是由这些基本的组件组合起来的控件,相当于这里的Composite,它们之间有一些行为含义是相 同的,比如在控件上作一个点击,移动操作等等的,这些都可以定义为抽象基类中的接口虚函数,由各个派生类去实现之,这些都会有的行为就是这里的 Operation函数,而添加,删除等进行组件组合的操作只有非叶子结点才可能有,所以虚拟基类中只是提供接口而且默认的实现是什么都不做。
实现代码如下:
View Code #define _COMPONENT_H_
#include <vector>
#include <iostream>
class Componnet{
public:
Componnet(){
std::cout<<"Componnet::Componnet()\n";
}
virtual ~Componnet(){
std::cout<<"Componnet::~Componnet\n";
}
virtual void Operation()=0;
virtual void Add(Componnet* pChild){}
virtual void Remove(Componnet* pChild){}
virtual Componnet* GetChild(int){return 0;}
};
class Leaf:public Componnet{
public:
Leaf(){}
~Leaf(){}
void Operation(){
std::cout<<"Leaf::Operation()\n";
}
};
class Composite{
public:
Composite(){
std::cout<<"Composite::Composite()\n";
}
~Composite();
void Operation();
void Add(Componnet* pChild);
void Remove(Componnet* pChild);
Componnet* GetChild(int index);
private:
std::vector<Componnet*> vec;
};
Composite::~Composite(){
std::vector<Componnet*>::iterator it;
for(it=vec.begin();it!=vec.end();++it){
delete *it;
}
}
void Composite::Operation(){
std::vector<Componnet*>::iterator it;
for(it=vec.begin();it!=vec.end();++it){
(*it)->Operation();
}
}
void Composite::Add(Componnet* pChild){
vec.push_back(pChild);
}
void Composite::Remove(Componnet* pChild){
std::vector<Componnet*>::iterator it;
for(it=vec.begin();it!=vec.end()&&*it!=pChild;++it);
if(it!=vec.end()){
delete pChild;
vec.erase(it);
}
}
Componnet* Composite::GetChild(int index){
int len=vec.size();
if(index>=len||index<0)
return NULL;
return vec[index];
}
#endif
View Code #include <iostream>
using namespace std;
int main(){
Leaf* p1=new Leaf;
Leaf* p2=new Leaf;
Composite* p=new Composite;
p->Add(p1);
p->Add(p2);
p->Operation();
p->GetChild(0)->Operation();
delete p;
return 0;
}
设计模式的解析和实现(C++)之九-Decorator模式
作用:
动态地给一个对象添加一些额外的职责。就增加功能来说,Decorator 模式相比生成子类更为灵活。
UML结构图:
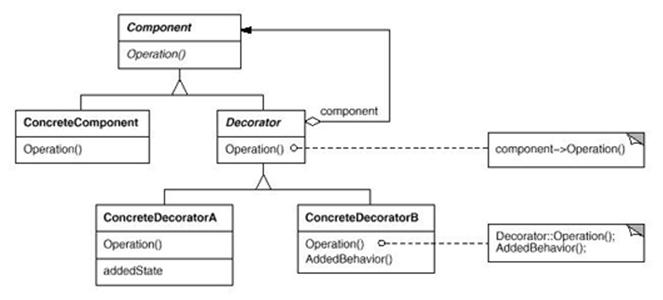
抽象基类:
1)Component:定义一个对象接口,可以为这个接口动态的添加职责。
2)Decorator:维持一个指向Component的指针,并且有一个和Component一致的接口函数。
接口函数:
1)Component::Operation:这个接口函数由Component声明,因此Component的派生类都需要实现,可以在这个接口函数的基础上给它动态添加职责。
解析:
Decorator的派生类可以为ConcreateComponent类的对象动态的添加职责,或者可以这么说:Decorator的派生类装饰 ConcreateComponent类的对象。具体是这么实现的,首先初始化一个ConcreateComponent类的对象(被装饰者),采用这个 对象去生成一个Decorator对象(装饰者),之后对Operation函数的调用则是对这个Decorator对象成员函数的多态调用。这里的实现 要点是Decorator类和ConcreateComponent类都继承自Component,从而两者的接口函数是一致的;其 次,Decorator维护了一个指向Component的指针,从而可以实现对Component::Operation函数的动态调用。
实现代码如下:
View Code #define _DECORATOR_H_
#include <iostream>
class Component{
public:
Component(){}
virtual ~Component(){}
virtual void Operation()=0;
};
class ConcreteComponent: public Component{
public:
ConcreteComponent(){}
~ConcreteComponent(){}
void Operation(){
std::cout<<"ConcreteComponent::Operation()\n";
}
};
class Decorator: public Component{
public:
Decorator(Component* comp):_comp(comp){}
virtual ~Decorator(){
if(_comp!=0) {
delete _comp;
_comp=0;
}
}
protected:
Component* _comp;
};
class ConcreteDecoratorA: public Decorator{
public:
ConcreteDecoratorA(Component*p):Decorator(p){}
~ConcreteDecoratorA(){}
virtual void Operation(){
_comp->Operation();
AddedBehavior();
}
void AddedBehavior(){
std::cout<<"ConcreteDecoratorA::AddedBehavior()\n";
}
};
class ConcreteDecoratorB: public Decorator{
public:
ConcreteDecoratorB(Component*p):Decorator(p){}
~ConcreteDecoratorB(){}
virtual void Operation(){
_comp->Operation();
AddedBehavior();
}
void AddedBehavior(){
std::cout<<"ConcreteDecoratorB::AddedBehavior()\n";
}
};
#endif
View Code #include <iostream>
#include <cstdlib>
using namespace std;
int main(){
Component* p;
Decorator* pd;
int n=5;
for(int i=0;i<n;i++){
int val=rand()%1000;
p=new ConcreteComponent;
if(val%2)
pd=new ConcreteDecoratorB(p);
else
pd=new ConcreteDecoratorA(p);
pd->Operation();
delete pd;
}
}
设计模式的解析和实现(C++)之十-Proxy模式
作用:
为其他对象提供一种代理以控制对这个对象的访问。
UML结构图:

抽象基类:
1)Subject:定义了Proxy和RealSubject的公有接口,这样就可以在任何需要使用到RealSubject的地方都使用Proxy.
解析:
Proxy其实是基于这样一种时常使用到的技术-某个对象直到它真正被使用到的时候才被初始化,在没有使用到的时候就暂时用Proxy作一个占位符。这个 模式实现的要点就是Proxy和RealSubject都继承自Subject,这样保证了两个的接口都是一致的。
实现代码如下:
View Code #define _PROXY_H_
#include <iostream>
class Subject{
public:
Subject(){}
virtual ~Subject(){}
virtual void Request()=0;
};
class RealSubject:public Subject{
public:
RealSubject(){}
~RealSubject(){}
void Request(){
std::cout<<"RealSubject::Request()\n";
}
};
class Proxy:public Subject{
public:
Proxy(Subject*s):_sub(s){}
~Proxy(){
if(_sub!=0) {
delete _sub;
_sub=0;
}
}
void Request(){
std::cout<<"Proxy::Request -> ";
_sub->Request();
}
private:
Subject* _sub;
};
#endif
View Code #include <iostream>
#include <cstdlib>
using namespace std;
int main(){
Subject* sub;
Proxy* p;
for(int i=0;i<5;i++){
sub=new RealSubject;
p=new Proxy(sub);
p->Request();
delete p;
}
}
设计模式的解析和实现(C++)之十三-FlyWeight模式
作用:
运用共享技术有效地支持大量细粒度的对象。
UML结构图:
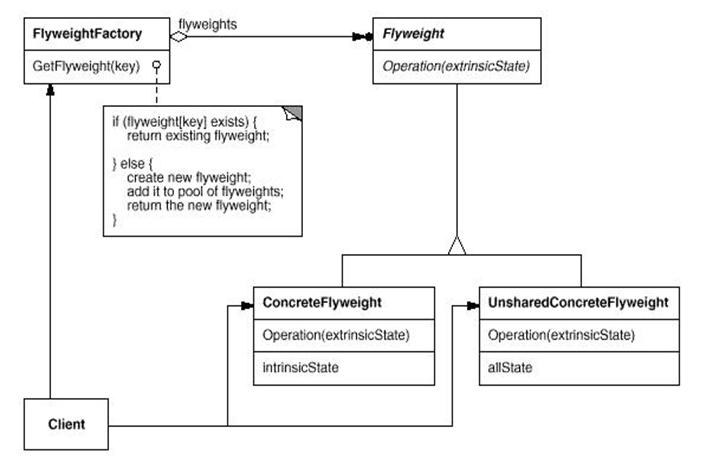
解析:
Flyweight模式在大量使用一些可以被共享的对象的时候经常使用。比如,在QQ聊天的时候很多时候你懒得回复又不得不回复的时候,一般会用一些客套 的话语敷衍别人,如"呵呵","好的"等等之类的,这些简单的答复其实每个人都是提前定义好的,在使用的时候才调用出来。Flyweight就是基于解决 这种问题的思路而产生的,当需要一个可以在其它地方共享使用的对象的时候,先去查询是否已经存在了同样的对象,如果没有就生成之有的话就直接使用。因 此,Flyweight模式和Factory模式也经常混用。
实现:
需要说明的是下面的实现仅仅实现了对可共享对象的使用,非可共享对象的使用没有列出,因为这个不是Flyweight模式的重点。这里的实现要点是采用一 个list链表来保存这些可以被共享的对象,需要使用的时候就到链表中查询是不是已经存在了,如果不存在就初始化一个,然后返回这个对象的指针。
实现代码如下:
View Code #define _FLYWEIGHT_H_
#include <list>
#include <string>
#include <iostream>
template <class STATE>
class Flyweight{
public:
Flyweight(const STATE& st):_state(st){}
virtual ~Flyweight(){}
virtual void Operation(STATE& extrinsicSate){}
STATE GetIntrinsicState(){
return _state;
}
private:
STATE _state;
};
template <class STATE>
class ConcreteFlyweight: public Flyweight<STATE>{
public:
ConcreteFlyweight(const STATE& st):Flyweight<STATE>(st){}
~ConcreteFlyweight(){}
void Operation(STATE& extrinsicSate){}
};
template <class STATE>
class FlyweightFactory{
public:
FlyweightFactory(){}
~FlyweightFactory();
Flyweight<STATE>* GetFlyweight(const STATE& key);
private:
std::list<Flyweight<STATE>*> _lst;
};
template <class STATE>
FlyweightFactory<STATE>::~FlyweightFactory(){
typename std::list<Flyweight<STATE>*>::iterator it;
for(it=_lst.begin();it!=_lst.end();++it) {
delete (*it);
}
}
template <class STATE>
Flyweight<STATE>* FlyweightFactory<STATE>::GetFlyweight(const STATE& key){
typename std::list<Flyweight<STATE>*>::iterator it;
for(it=_lst.begin();it!=_lst.end();++it) {
if((*it)->GetIntrinsicState()==key){
std::cout<<"exists\n";
return *it;
}
}
Flyweight<STATE>* pf=new ConcreteFlyweight<STATE>(key);
_lst.push_back(pf);
std::cout<<"created\n";
return pf;
}
#endif
View Code #include <string>
#include <iostream>
#include <cstdlib>
using namespace std;
int main(){
FlyweightFactory<string> ff;
ff.GetFlyweight("hello");
ff.GetFlyweight("world");
ff.GetFlyweight("hello");
FlyweightFactory<int> fi;
srand(time(0));
for(int i=0;i<10;i++){
int val=rand()%20;
fi.GetFlyweight(val);
}
}
Facade 模式
Facade(外观)模式为子系统中的各类(或结构与方法)提供一个简明一致的界面,隐藏子系统的复杂性,使子系统更加容易使用。他是为子系统中的一组接口所提供的一个一致的界面。
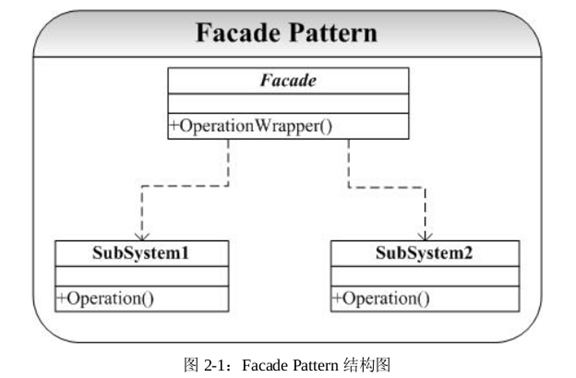
老旧的code(尤其是将C的代码转成C++代码)或者即便不是老旧code,但涉及多个子系统时,除了重写全部代码(对于老旧code而言),我们还可能采用这样一种策略:
重新进行类的设计,将原来分散在源码中的类/结构及方法重新组合,形成新的、统一的接口,供上层应用使用。
这在某种意义上与Adapter及Proxy有类似之处,但是,Proxy(代理)注重在为Client-Subject提供一个访问的中间层,如CORBA可为应用程序提供透明访问支持,使应用程序无需去考虑平台及网络造成的差异及其它诸多技术细节;Adapter(适配器)注重对接口的转换与调整;而Facade所面对的往往是多个类或其它程序单元,通过重新组合各类及程序单元,对外提供统一的接口/界面。
实现代码如下:
View Code #define _FACADE_H_
#include <iostream>
class SubSystem1{
public:
SubSystem1(){}
~SubSystem1(){}
void Operation(){
std::cout<<"SubSystem1::Operation()\n";
}
};
class SubSystem2{
public:
SubSystem2(){}
~SubSystem2(){}
void Operation(){
std::cout<<"SubSystem2::Operation()\n";
}
};
class Facade{
public:
Facade():sb1(new SubSystem1),sb2(new SubSystem2){}
~Facade(){
delete sb1;
delete sb2;
}
void OperationWrapper(){
std::cout<<"Facade::Operation() ->\n ";
sb1->Operation();
std::cout<<" ";
sb2->Operation();
}
private:
SubSystem1* sb1;
SubSystem2* sb2;
};
#endif
View Code #include <iostream>
using namespace std;
int main(){
Facade f;
f.OperationWrapper();
}
设计模式解析和实现之十一-TemplateMethod模式
作用:
定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。TemplateMethod 使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
UML结构图:

抽象基类:
1)AbstractClass:抽象基类,定义算法的轮廓
解析:
TemplateMethod 的关键在于在基类中定义了一个算法的轮廓,但是算法每一步具体的实现留给了派生类。但是这样也会造成设计的灵活性不高的缺点,因为轮廓已经定下来了要想改变就比较难了,这也是为什么优先采用聚合而不是继承的原因。
实现代码如下:
设计模式解析和实现之十二-ChainOfResponsibility模式
作用:
使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
UML结构图:
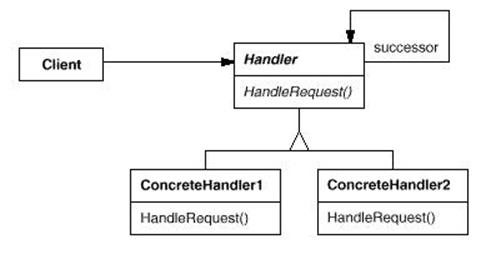
抽象基类:
1)Handler:定义一个处理请求的接口,在图中这个接口就是HandleRequset函数,这个类同时有一个指向Handler对象的指针,指向后续的处理请求的对象(如果有的话)。
解析:
这个模式把可以处理一个请求的对象以链的形式连在了一起,让这些对象都有处理请求的机会。好比原来看古装电视中经常看到皇宫中召见某人的时候,太监们(可 以处理一个请求的对象)就会依次的喊:传XX……这样一直下去直到找到这个人为止。ChainOfResponsibility模式也是这样的处理请求 的,如果有后续的对象可以处理,那么传给后续的对象处理,否则就自己处理请求。这样的设计把请求的发送者和请求这种的处理者解耦了,好比发号的皇帝不知道 到底是哪个太监最后会找到他要找到的人一般,只管发出命令就OK了。
实现代码如下:
View Code int main(){
Handler* pch1=new ConcreteHandle1();
Handler* pch2=new ConcreteHandle2(pch1);
pch2->HandleRequest();
delete pch2;
}
View Code #define _HANDLER_H_
#include <iostream>
class Handler{
public:
Handler():_successor(0){}
Handler(Handler* su):_successor(su){}
virtual ~Handler(){
delete _successor;
_successor=0;
}
virtual void HandleRequest()=0;
protected:
Handler* _successor;
};
class ConcreteHandle1:public Handler{
public:
ConcreteHandle1(){}
ConcreteHandle1(Handler* su):Handler(su){}
~ConcreteHandle1(){}
void HandleRequest(){
if(_successor!=0){
_successor->HandleRequest();
}
else {
std::cout<<"ConcreteHandle1 handle the Request\n";
}
}
};
class ConcreteHandle2:public Handler{
public:
ConcreteHandle2(){}
ConcreteHandle2(Handler* su):Handler(su){}
~ConcreteHandle2(){}
void HandleRequest(){
if(_successor!=0){
std::cout<<"deliver\n ";
_successor->HandleRequest();
}
else {
std::cout<<"ConcreteHandle2 handle the Request\n";
}
}
};
#endif
设计模式解析和实现之十四-Command模式
作用:
将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可撤消的操作。
UML结构图:

解析:
Comnand模式的思想是把命令封装在一个类中,就是这里的Command基类,同时把接收对象也封装在一个类中就是这里的Receiver类中,由调 用这个命令的类也就是这里的Invoker类来调用。其实,如果弄清楚了Command模式的原理,就会发现其实它和注册回调函数的原理是很相似的,而在 面向过程的设计中的回调函数其实和这里的Command类的作用是一致的。采用Command模式解耦了命令的发出者和命令的执行者。
实现代码如下:
View Code #define _COMMAND_H_
#include <iostream>
class Command{
public:
Command(){}
virtual ~Command(){}
virtual void Execute()=0;
};
class Invoker{
public:
Invoker(Command*cmd):_cmd(cmd){}
~Invoker(){ }
void Invoke(){
if(_cmd!=0)
_cmd->Execute();
}
private:
Command* _cmd;
};
class Receiver{
public:
void Action(){
std::cout<<"Receiver::Action()\n";
}
};
class ConcreteCommand:public Command{
public:
ConcreteCommand(Receiver* rec):_rec(rec){}
~ConcreteCommand(){
}
void Execute(){
if(_rec!=0)
_rec->Action();
}
private:
Receiver* _rec;
};
#endif
View Code int main(){
Receiver rec;
Command *cmd=new ConcreteCommand(&rec);
Invoker inv(cmd);
inv.Invoke();
delete cmd;
}
设计模式解析和实现(C++)之十五-Observer模式
作用:
定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
UML结构图:

解析:
Observer模式定义的是一种一对多的关系,这里的一就是图中的Subject类,而多则是Obesrver类,当Subject类的状态发生变化的 时候通知与之对应的Obesrver类们也去相应的更新状态,同时支持动态的添加和删除Observer对象的功能。Obesrver模式的实现要点是, 第一一般subject类都是采用链表等容器来存放Observer对象,第二抽取出Observer对象的一些公共的属性形成Observer基类,而 Subject中保存的则是Observer类对象的指针,这样就使Subject和具体的Observer实现了解耦,也就是Subject不需要去关 心到底是哪个Observer对放进了自己的容器中。生活中有很多例子可以看做是Observer模式的运用,比方说,一个班有一个班主任 (Subject),他管理手下的一帮学生(Observer),当班里有一些事情发生需要通知学生的时候,班主任要做的不是逐个学生挨个的通知而是把学 生召集起来一起通知,实现了班主任和具体学生的关系解耦。
实现代码如下:
View Code #include <cstdlib>
using namespace std;
int main(){
Observer* o1=new ConcreteObserver1(1);
Observer* o2=new ConcreteObserver2(1);
Subject *sub=new ConcreteSubject;
sub->Attach(o1);
sub->Attach(o2);
sub->SetState(7);
sub->Notify();
for(int i=0;i<5;i++) {
int val=rand()%100;
if(val%2)
sub->Attach(new ConcreteObserver1);
else
sub->Attach(new ConcreteObserver2);
}
sub->SetState(44);
sub->Notify();
delete sub;
}
View Code #define _SUBJECT_H_
#include <list>
#include <iostream>
typedef int STATE;
class Subject;
class Observer{
public:
Observer():_stat(-1){}
Observer(const STATE& st):_stat(st){}
virtual ~Observer(){}
virtual void Update(Subject*)=0;
protected:
STATE _stat;
};
class Subject{
public:
virtual ~Subject();
void Attach(Observer* ob);
void Detach(Observer* ob);
void Notify();
virtual STATE GetState()=0;
virtual void SetState(const STATE&)=0;
protected:
std::list<Observer*> _lst;
};
Subject::~Subject(){
std::list<Observer*>::iterator it;
for(it=_lst.begin();it!=_lst.end();++it)
delete *it;
}
void Subject::Attach(Observer*ob){
_lst.push_back(ob);
std::cout<<(void*)ob<<" Attached\n";
}
void Subject::Detach(Observer*ob){
_lst.remove(ob);
std::cout<<(void*)ob<<" Detached\n";
}
void Subject::Notify(){
std::cout<<"Subject::Notify \n";
std::list<Observer*>::iterator it;
for(it=_lst.begin();it!=_lst.end();++it) {
std::cout<<" ";
(*it)->Update(this);
}
}
class ConcreteSubject:public Subject{
public:
ConcreteSubject():_stat(-1){}
STATE GetState(){
return _stat;
}
void SetState(const STATE& st){
_stat=st;
}
private:
STATE _stat;
};
class ConcreteObserver1:public Observer{
public:
ConcreteObserver1():Observer(){}
ConcreteObserver1(const STATE& st):Observer(st){}
void Update(Subject*sub){
std::cout<<"state:"<<_stat<<" -> ";
_stat=sub->GetState();
std::cout<<_stat<<'\n';
}
};
class ConcreteObserver2:public Observer{
public:
ConcreteObserver2():Observer(){}
ConcreteObserver2(const STATE& st):Observer(st){}
void Update(Subject*sub){
std::cout<<"state:"<<_stat<<" -> ";
_stat=sub->GetState();
std::cout<<_stat<<'\n';
}
};
#endif
设计模式的解析和实现(C++)之十六-Strategy模式
作用:
定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换。本模式使得算法可独立于使用它的客户而变化。

解析:
简而言之一句话,Strategy模式是对算法的封装。处理一个问题的时候可能有多种算法,这些算法的接口(输入参数,输出参数等)都是一致的,那么可以考虑采用Strategy模式对这些算法进行封装,在基类中定义一个函数接口就可以了。
实现代码如下:
View Code #define _STRATEGY_H_
#include <iostream>
class Strategy{
public:
virtual ~Strategy(){}
virtual void AlgrithmInterface()=0;
};
class ConcreteStrategy1:
public Strategy{
public:
~ConcreteStrategy1(){}
void AlgrithmInterface(){
std::cout<<"ConcreteStrategy1::AlgrithmInterface()\n";
}
};
class ConcreteStrategy2:
public Strategy{
public:
~ConcreteStrategy2(){}
void AlgrithmInterface(){
std::cout<<"ConcreteStrategy2::AlgrithmInterface()\n";
}
};
class Context{
public:
Context(Strategy* st):_strgy(st){}
~Context(){
delete _strgy;
_strgy=0;
}
void DoAction(){
_strgy->AlgrithmInterface();
}
private:
Strategy* _strgy;
};
#endif
View Code #include <cstdlib>
using namespace std;
int main(){
Context *p;
srand(time(0));
for(int i=0;i<10;i++){
int val=rand()%100;
if(val%2)
p=new Context(new ConcreteStrategy1);
else
p=new Context(new ConcreteStrategy2);
p->DoAction();
delete p;
}
}
设计模式的解析和实现(C++)之十七-State模式
作用:
允许一个对象在其内部状态改变时改变它的行为。
UML结构图:
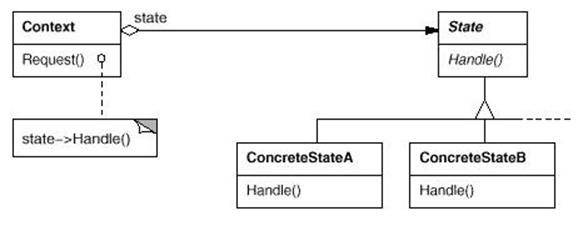
解析:
State模式主要解决的是在开发中时常遇到的根据不同的状态需要进行不同的处理操作的问题,而这样的问题,大部分人是采用switch-case语句进 行处理的,这样会造成一个问题:分支过多,而且如果加入一个新的状态就需要对原来的代码进行编译。State模式采用了对这些不同的状态进行封装的方式处 理这类问题,当状态改变的时候进行处理然后再切换到另一种状态,也就是说把状态的切换责任交给了具体的状态类去负责。同时,State模式和 Strategy模式在图示上有很多相似的地方,需要说明的是两者的思想都是一致的,只不过封装的东西不同:State模式封装的是不同的状态,而 Stategy模式封装的是不同的算法。
实现代码如下:
View Code #define _STATE_H_
#include <iostream>
class Context;
class State{
public:
virtual ~State(){}
virtual void Handle(Context*)=0;
};
class Context{
public:
Context(State* st):_state(st){}
void Request(){
if(_state!=0)
_state->Handle(this);
}
~Context(){
delete _state;
}
void ChangeState(State* st){
if(_state!=0){
delete _state;
}
_state=st;
}
private:
State* _state;
};
class ConcreteState1:public State{
public:
void Handle(Context* pC);
};
class ConcreteState2:public State{
public:
void Handle(Context* pC);
};
void ConcreteState1::Handle(Context* pC){
std::cout<<"ConcreteState1::Handle\n";
pC->ChangeState(new ConcreteState2);
}
void ConcreteState2::Handle(Context* pC){
std::cout<<"ConcreteState2::Handle\n";
pC->ChangeState(new ConcreteState1);
}
#endif
View Code int main(){
State *p1=new ConcreteState1;
Context *pc=new Context(p1);
pc->Request();
pc->Request();
pc->Request();
pc->Request();
pc->Request();
pc->Request();
delete pc;
}
设计模式的解析和实现(C++)之十八-Iterator模式
用:
提供一种方法顺序访问一个聚合对象中各个元素,而又不需暴露该对象的内部表示。
UML结构图:
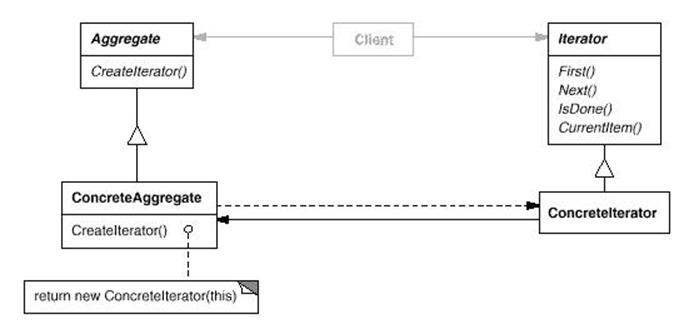
解析:
Iterator几乎是大部分人在初学C++的 时候就无意之中接触到的第一种设计模式,因为在STL之中,所有的容器类都有与之相关的迭代器。以前初学STL的时候,时常在看到讲述迭代器作用的时候是 这么说的:提供一种方式,使得算法和容器可以独立的变化,而且在访问容器对象的时候不必暴露容器的内部细节,具体是怎么做到这一点的呢?在STL的实现 中,所有的迭代器(Iterator)都必须遵照一套规范,这套规范里面定义了几种类型的名称,比如对象的名称,指向对象的指针的名称,指向对象的引用的 名称……等等,当新生成一个容器的时候与之对应的Iterator都要遵守这个规范里面所定义的名称,这样在外部看来虽然里面的实现细节不一样,但是作用 (也就是对外的表象)都是一样的,通过某个名称可以得到容器包含的对象,通过某个名称可以得到容器包含的对象的指针等等的。而且,采用这个模式把访问容器 的重任都交给了具体的iterator类中。于是,在使用Iterator来访问容器对象的算法不需要知道需要处理的是什么容器,只需要遵守事先约定好的 Iterator的规范就可以了;而对于各个容器类而言,不管内部的事先如何,是树还是链表还是数组,只需要对外的接口也遵守Iterator的标准,这 样算法(Iterator的使用者)和容器(IteIterator的提供者)就能很好的进行合作,而且不必关心对方是如何事先的,简而言 之,Iterator就是算法和容器之间的一座桥梁.
实现代码如下:
View Code #define _ITERATOR_H_
template <class T>
class Aggregate;
template <class T>
class Iterator{
public:
Iterator(Aggregate<T>*agg):_agg(agg),_indx(-1){}
virtual ~Iterator(){}
virtual void First()=0;
virtual void Next()=0;
virtual bool IsDone()=0;
virtual T& CurrentItem()=0;
protected:
Aggregate<T>* _agg;
int _indx;
};
template <class T>
class Aggregate{
public:
virtual ~Aggregate(){}
virtual Iterator<T>* CreateItertor(Aggregate<T>*)=0;
virtual int GetSize()=0;
virtual T& GetItem(int i)=0;
};
template <class T>
class ConcreteIterator:public Iterator<T>{
public:
ConcreteIterator(Aggregate<T>*agg):Iterator<T>(agg){}
void First(){ this->_indx=0; }
void Next(){this->_indx++;}
bool IsDone(){
return this->_indx==this->_agg->GetSize();
}
T& CurrentItem(){
return this->_agg->GetItem(this->_indx);
}
};
template <class T>
class ConcreteAggregate:public Aggregate<T>{
public:
ConcreteAggregate(int sz):_arr(new T[sz]()),_sz(sz){}
~ConcreteAggregate(){ delete[] _arr; }
Iterator<T>* CreateItertor(Aggregate<T>* agg){
return new ConcreteIterator<T>(this);
}
int GetSize(){
return _sz;
}
T& GetItem(int i){
return _arr[i];
}
private:
T *_arr;
int _sz;
};
#endif
View Code #include <iostream>
#include <cstdlib>
using namespace std;
int main(){
int n=10;
ConcreteAggregate<int> ca(n);
Iterator<int>* it=ca.CreateItertor(&ca);
it->First();
for(int i=0;i<n;i++){
int val=rand()%100;
std::cout<<val<<' ';
it->CurrentItem()=val;
it->Next();
}
std::cout<<endl;
it->First();
while(!it->IsDone()){
cout<<it->CurrentItem()<<' ';
it->Next();
}
cout<<endl;
}
设计模式解析和实现(C++)之十九-Memento模式
作用:
在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可将该对象恢复到原先保存的状态。
UML结构图:

解析:
Memento模式中封装的是需要保存的状态,当需要恢复的时候才取出来进行恢复。原理很简单,实现的时候需要注意一个地方:窄接口和宽接口。所谓的宽接 口就是一般意义上的接口,把对外的接口作为public成员;而窄接口反之,把接口作为private成员,而把需要访问这些接口函数的类作为这个类的友 元类,也就是说接口只暴露给了对这些接口感兴趣的类,而不是暴露在外部。下面的实现就是窄实现的方法来实现的。
实现代码如下:
View Code #define _MEMENTO_H_
#include <iostream>
typedef int STATE;
class Originator;
class Memento{
private:
friend class Originator;
Memento(const STATE& st):_state(st){}
~Memento(){}
STATE GetState(){
return _state;
}
void SetState(const STATE& st){
_state=st;
}
STATE _state;
};
class Originator{
public:
Originator(const STATE& st):_state(st){}
~Originator(){}
void SetMemento(Memento* m){
m->SetState(_state);
}
Memento* CreateMemento(){
return new Memento(_state);
}
STATE GetState(){
return _state;
}
void SetState(const STATE& st){
_state=st;
}
void RestoreState(Memento* pmem){
_state=pmem->GetState();
}
void PrintState(){
std::cout<<"Originator::_state="<<_state<<'\n';
}
private:
STATE _state;
};
#endif
View Code #include <iostream>
using namespace std;
int main(){
Originator *org=new Originator(1);
org->PrintState();
Memento* p=org->CreateMemento();
org->SetState(2);
org->PrintState();
org->RestoreState(p);
org->PrintState();
}
设计模式的解析和实现(C++)之二十-Visitor模式
作用:
表示一个作用于某对象结构中的各元素的操作。它使你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
UML结构图:

解析:
Visitor模式把对结点的访问封装成一个抽象基类,通过派生出不同的类生成新的访问方式。在实现的时候,在visitor抽象基类中声明了对所有不同 结点进行访问的接口函数,如图中的VisitConcreateElementA函数等,这样也造成了Visitor模式的一个缺陷——新加入一个结点的 时候都要添加Visitor中的对其进行访问接口函数,这样使得所有的Visitor及其派生类都要重新编译了,也就是说Visitor模式一个缺点就是 添加新的结点十分困难。另外,还需要指出的是Visitor模式采用了所谓的"双重分派"的技术,拿上图来作为例子,要对某一个结点进行访问,首先需要产 生一个Element的派生类对象,其次要传入一个Visitor类派生类对象来调用对应的Accept函数,也就是说,到底对哪种Element采用哪 种Visitor访问,需要两次动态绑定才可以确定下来,具体的实现可以参考下面实现代码中的Main.cpp部分是如何调用这些类的。
实现代码如下:
View Code #define _VISITOR_H_
#include <iostream>
class Visitor;
class Element{
public:
virtual ~Element(){}
virtual void Accept(Visitor*)=0;
};
class ConcreteElement1:public Element{
public:
~ConcreteElement1(){}
void Accept(Visitor*vt);
};
class ConcreteElement2:public Element{
public:
~ConcreteElement2(){}
void Accept(Visitor*vt);
};
class Visitor{
public:
virtual ~Visitor(){}
virtual void VisitConcreteElement1(ConcreteElement1*)=0;
virtual void VisitConcreteElement2(ConcreteElement2*)=0;
};
class ConcreteVisitor1:public Visitor{
public:
~ConcreteVisitor1(){}
void VisitConcreteElement1(ConcreteElement1*);
void VisitConcreteElement2(ConcreteElement2*);
};
class ConcreteVisitor2:public Visitor{
public:
~ConcreteVisitor2(){}
void VisitConcreteElement1(ConcreteElement1*);
void VisitConcreteElement2(ConcreteElement2*);
};
void ConcreteElement1::Accept(Visitor*vt){
vt->VisitConcreteElement1(this);
}
void ConcreteElement2::Accept(Visitor*vt){
vt->VisitConcreteElement2(this);
}
void ConcreteVisitor1::VisitConcreteElement1(ConcreteElement1*p1){
std::cout<<"ConcreteVisitor1::VisitConcreteElement1:"<<(void*)p1<<'\n';
}
void ConcreteVisitor1::VisitConcreteElement2(ConcreteElement2*p2){
std::cout<<"ConcreteVisitor1::VisitConcreteElement2:"<<(void*)p2<<'\n';
}
void ConcreteVisitor2::VisitConcreteElement1(ConcreteElement1*p1){
std::cout<<"ConcreteVisitor2::VisitConcreteElement1:"<<(void*)p1<<'\n';
}
void ConcreteVisitor2::VisitConcreteElement2(ConcreteElement2*p2){
std::cout<<"ConcreteVisitor2::VisitConcreteElement2:"<<(void*)p2<<'\n';
}
#endif
View Code int main(){
Visitor* vt1=new ConcreteVisitor1,
*vt2=new ConcreteVisitor2;
Element *el1=new ConcreteElement1,
*el2=new ConcreteElement2;
el1->Accept(vt1);
el1->Accept(vt2);
el2->Accept(vt1);
el2->Accept(vt2);
}
设计模式的解析和实现(C++)之二十一-完结篇
一个月下来,把常见的20个设计模式好好复习并且逐个用C++实现了一遍,收获还是很大的,很多东西看上去明白了但是真正动手去做的时候发现其实还是不明白——我深知这个道理,于是不敢怠慢,不敢写什么所谓的解释原理的伪代码,不敢说所谓的"知道原理就可以了"……因为我知道,我还还没有资格说这个话,至少对于设计模式而言我还是一个初学者,唯有踏实和实干才能慢慢的掌握到知识。
在我学习设计模式的过程中,觉得造成理解困难的主要是以下几点,谈一下自己的体会,希望对他人有帮助,不要走上我的老路上,毕竟我花了N长的时间才敢号称自己入门了~~!!-_-:
1)Gof并不适合于初学者。初学设计模式的一般都是从Gof入门开始学习的,不幸的是,这不是一本好的教科书,而把这本书称为一本奠定了设计模式理论基础的开山之作也许好一些,它把这些散落在各个设计中的常见模式收集起来,从此开始有了一个名词叫做"Design Pattern".说这本书不是一本好的教科书主要是以下的几个原因:a)对设计模式或者说面向对象里面的一些原则性的东西解释的不够多不够彻底,比如"面向接口编程而不是对实现编程","优先采用组合而不是继承"等等,以至于后面看到各个模式的实现的时候很多模式看起来很相似却找不到区别和共性的地方。 b)对各个模式的解释或者举出来的例子不是特别的好,大部分都是为了讲解模式而讲解,没有加入前面提到过的一些基本原则的考量在里面,也就是说:原理性的东西和实现(各个设计模式)脱节。
2)初学者对语言或者说一些概念理解的不好。拿C++来说,为了做到面向对象需要提供的语言上的支持有继承,多态,封装,虚函数,抽象等等,我以前初学C++的时候,只为了学这些概念而去学习,不知道为什么要提供这些特性,这也是造成我走弯路的重要原因之一。当然,指望一个初学者在初学语言的时候就知道why是一件很困难的事情,也许结合着对设计模式的理解可以帮助你消化这些概念(我就是这样的)。
3)看不懂UML结构图和时序图,UML图解释的类与类之间的关系,时序图解释的是各个对象的实现方式,两者结合在一起看才能加深对设计模式的理解,事实上,我现在已经可以做到仅仅看这两个图示就掌握一个模式的原理和实现了。
4)写的代码和参与过的项目不够多。设计模式和很多东西的产生过程都是一样的,首先人们遇到了问题,然后很多人解决了这个问题,于是渐渐的有人出来总结出解决这些问题所要遵守的一些原理和常用方法(我们称之为"模式"),久而久之就形成了一个理论或者说一个学科。而后人在讲述这些理论的时候大都是照本宣科,这对于计算机这样一个强调实践的学科或者说对于设计模式这样一个理论而言要理解起来是很困难的。前人在提出这些理论的时候一些考量,权衡等等只有在你自己遇到了这些问题的时候才能慢慢的体会。有一种说法是,没有写上10W行代码不要空谈什么设计模式大概就是这个意思吧。
综上所述,造成初学者学习设计模式困难的原因,一个是对基本的原则理解的不够透彻,一个的选的入门教材不合理,还有一个就是对各个模式的表述不明白,再次是实践不够多。
有几本书籍,我看过,我想可以谈谈我的看法。
第一本,<<敏捷软件开发:原则,模式与实践>>,这本书对于设计模式最大的贡献在于专门有几个章节讲述了面向对象的几个原则,比如Likov原则,开放封闭原则等等的,这几个章节在我学习设计模式的过程中起了关键的作用,因为当我理解了这些原则之后开始慢慢明白为什么要有纯虚函数提供接口,为什么要有抽象基类,为什么要封装……我开始用这些原则去理解各个设计模式,开始慢慢体会各个模式的区别和共性。
另外看过的两本书,我觉得性质都一样,如果你缺钱,任选其一吧。第一本是<<设计模式精解>>,第二本是<<深入浅出设计模式>>,都是我花上几个晚上就可以看完的书。这两本的立足点都是以生动的例子结合面向对象的基本原理来讲解模式,我更喜欢前者一些(后者太贵,要不是打5折我才不买呐:)
关于设计模式的一个疑问:非面向对象语言中有没有所谓的"设计模式"?设计模式最初的定义是解决一些问题的惯用方法(大意如此),并没有明确的说必 须要支持某种特性的语言。我用纯C开发的项目实在是有限,平时也只是自己作一些小东西玩玩,没有做过任何一个上万行的纯C开发的项目,所以一直对这个问题 抱有疑问~~anyway,有问题是好事,说明我在思考~~把这个问题放在这里,以后慢慢实践之琢磨之~~
博君一笑。
关于设计模式,还有一篇有意思的文章——<<追MM与设计模式>>,这篇文章可谓是"寓教于乐"的典范,讲述了23个模式在日常 生活中的原型,虽然没有具体讲述如何实现,但是对于理解各个设计模式的运用场合还是很有帮助的。相信对设计模式已经有了一定了解的人看了这篇文章都会会心 一笑:),作者和出处已经不详了。
追MM与设计模式
在CSDN看见了这篇文章,作者以轻松的语言比喻了java的32种模式,有很好的启发作用,但可惜没有给出具体的意思,我就在后边加上了:)这些都是最简单的介绍,要学习的话建议你看一下《java与模式》这本书。
创建型模式
1 、FACTORY—追MM少不了请吃饭了,麦当劳的鸡翅和肯德基的鸡翅都是MM爱吃的东西,虽然口味有所不同,但不管你带MM去麦当劳或肯德基,只管向服务员说"来四个鸡翅"就行了。麦当劳和肯德基就是生产鸡翅的Factory
工厂模式:客户类和工厂类分开。消费者任何时候需要某种产品,只需向工厂请求即可。消费者无须修改就可以接纳新产品。缺点是当产品修改时,工厂类也要做相应的修改。如:如何创建及如何向客户端提供。
2 、BUILDER—MM最爱听的就是"我爱你"这句话了,见到不同地方的MM,要能够用她们的方言跟她说这句话哦,我有一个多种语言翻译机,上面每种语言 都有一个按键,见到MM我只要按对应的键,它就能够用相应的语言说出"我爱你"这句话了,国外的MM也可以轻松搞掂,这就是我的"我爱 你"builder.(这一定比美军在伊拉克用的翻译机好卖)
建造模式:将产品的内部表象和产品的生成过程分割开来,从而使一个建造过程生成具有不同的内部表象的产品对象。建造模式使得产品内部表象可以独立的变化,客户不必知道产品内部组成的细节。建造模式可以强制实行一种分步骤进行的建造过程。
3 、FACTORY METHOD—请MM去麦当劳吃汉堡,不同的MM有不同的口味,要每个都记住是一件烦人的事情,我一般采用Factory Method模式,带着MM到服务员那儿,说"要一个汉堡",具体要什么样的汉堡呢,让MM直接跟服务员说就行了。
工厂方法模式:核心工厂类不再负责所有产品的创建,而是将具体创建的工作交给子类去做,成为一个抽象工厂角色,仅负责给出具体工厂类必须实现的接口,而不接触哪一个产品类应当被实例化这种细节。
4 、PROTOTYPE—跟MM用QQ聊天,一定要说些深情的话语了,我搜集了好多肉麻的情话,需要时只要copy出来放到QQ里面就行了,这就是我的情话prototype了。(100块钱一份,你要不要)
原始模型模式:通过给出一个原型对象来指明所要创建的对象的类型,然后用复制这个原型对象的方法创建出更多同类型的对象。原始模型模式允许动态的增加或减 少产品类,产品类不需要非得有任何事先确定的等级结构,原始模型模式适用于任何的等级结构。缺点是每一个类都必须配备一个克隆方法。
5 、SINGLETON—俺有6个漂亮的老婆,她们的老公都是我,我就是我们家里的老公Sigleton,她们只要说道"老公",都是指的同一个人,那就是我(刚才做了个梦啦,哪有这么好的事)
单例模式:单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例单例模式。单例模式只应在有真正的"单一实例"的需求时才可使用。
结构型模式
6 、ADAPTER—在朋友聚会上碰到了一个美女Sarah,从香港来的,可我不会说粤语,她不会说普通话,只好求助于我的朋友kent了,他作为我和Sarah之间的Adapter,让我和Sarah可以相互交谈了(也不知道他会不会耍我)
适配器(变压器)模式:把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口原因不匹配而无法一起工作的两个类能够一起工作。适配类可以根据参数返还一个合适的实例给客户端。
7 、BRIDGE—早上碰到MM,要说早上好,晚上碰到MM,要说晚上好;碰到MM穿了件新衣服,要说你的衣服好漂亮哦,碰到MM新做的发型,要说你的头发好漂亮哦。不要问我"早上碰到MM新做了个发型怎么说"这种问题,自己用BRIDGE组合一下不就行了
桥梁模式:将抽象化与实现化脱耦,使得二者可以独立的变化,也就是说将他们之间的强关联变成弱关联,也就是指在一个软件系统的抽象化和实现化之间使用组合 / 聚合关系而不是继承关系,从而使两者可以独立的变化。
8 、COMPOSITE—Mary今天过生日。"我过生日,你要送我一件礼物。""嗯,好吧,去商店,你自己挑。""这件T恤挺漂亮,买,这条裙子好看, 买,这个包也不错,买。""喂,买了三件了呀,我只答应送一件礼物的哦。""什么呀,T恤加裙子加包包,正好配成一套呀,小姐,麻烦你包起 来。""……",MM都会用Composite模式了,你会了没有?
合成模式:合成模式将对象组织到树结构中,可以用来描述整体与部分的关系。合成模式就是一个处理对象的树结构的模式。合成模式把部分与整体的关系用树结构表示出来。合成模式使得客户端把一个个单独的成分对象和由他们复合而成的合成对象同等看待。
9 、DECORATOR—Mary过完轮到Sarly过生日,还是不要叫她自己挑了,不然这个月伙食费肯定玩完,拿出我去年在华山顶上照的照片,在背面写上 "最好的的礼物,就是爱你的Fita",再到街上礼品店买了个像框(卖礼品的MM也很漂亮哦),再找隔壁搞美术设计的Mike设计了一个漂亮的盒子装起 来……,我们都是Decorator,最终都在修饰我这个人呀,怎么样,看懂了吗?
装饰模式:装饰模式以对客户端透明的方式扩展对象的功能,是继承关系的一个替代方案,提供比继承更多的灵活性。动态给一个对象增加功能,这些功能可以再动态的撤消。增加由一些基本功能的排列组合而产生的非常大量的功能。
10 、FACADE—我有一个专业的Nikon相机,我就喜欢自己手动调光圈、快门,这样照出来的照片才专业,但MM可不懂这些,教了半天也不会。幸好相机有 Facade设计模式,把相机调整到自动档,只要对准目标按快门就行了,一切由相机自动调整,这样MM也可以用这个相机给我拍张照片了。
门面模式:外部与一个子系统的通信必须通过一个统一的门面对象进行。门面模式提供一个高层次的接口,使得子系统更易于使用。每一个子系统只有一个门面类,而且此门面类只有一个实例,也就是说它是一个单例模式。但整个系统可以有多个门面类。
11 、FLYWEIGHT—每天跟MM发短信,手指都累死了,最近买了个新手机,可以把一些常用的句子存在手机里,要用的时候,直接拿出来,在前面加上MM的 名字就可以发送了,再不用一个字一个字敲了。共享的句子就是Flyweight,MM的名字就是提取出来的外部特征,根据上下文情况使用。
享元模式:FLYWEIGHT在拳击比赛中指最轻量级。享元模式以共享的方式高效的支持大量的细粒度对象。享元模式能做到共享的关键是区分内蕴状态和外蕴状态。内蕴状态存储在 享元内部,不会随环境的改变而有所不同。外蕴状态是随环境的改变而改变的。外蕴状态不能影响内蕴状态,它们是相互独立的。将可以共享的状态和不可以共享的 状态从常规类中区分开来,将不可以共享的状态从类里剔除出去。客户端不可以直接创建被共享的对象,而应当使用一个工厂对象负责创建被共享的对象。享元模式 大幅度的降低内存中对象的数量。
12 、PROXY—跟MM在网上聊天,一开头总是"hi,你好","你从哪儿来呀?""你多大了?""身高多少呀?"这些话,真烦人,写个程序做为我的Proxy吧,凡是接收到这些话都设置好了自动的回答,接收到其他的话时再通知我回答,怎么样,酷吧。
代理模式:代理模式给某一个对象提供一个代理对象,并由代理对象控制对源对象的引用。代理就是一个人或一个机构代表另一个人或者一个机构采取行动。某些情 况下,客户不想或者不能够直接引用一个对象,代理对象可以在客户和目标对象直接起到中介的作用。客户端分辨不出代理主题对象与真实主题对象。代理模式可以 并不知道真正的被代理对象,而仅仅持有一个被代理对象的接口,这时候代理对象不能够创建被代理对象,被代理对象必须有系统的其他角色代为创建并传入。
行为模式
13 、CHAIN OF RESPONSIBLEITY—晚上去上英语课,为了好开溜坐到了最后一排,哇,前面坐了好几个漂亮的MM哎,找张纸条,写上 "Hi,可以做我的女朋友吗?如果不愿意请向前传",纸条就一个接一个的传上去了,糟糕,传到第一排的MM把纸条传给老师了,听说是个老处女呀,快跑 !
责任链模式:在责任链模式中,很多对象由每一个对象对其下家的引用而接 起来形成一条链。请求在这个链上传递,直到链上的某一个对象决定处理此请求。客户 并不知道链上的哪一个对象最终处理这个请求,系统可以在不影响客户端的情况下动态的重新组织链和分配责任。处理者有两个选择:承担责任或者把责任推给下 家。一个请求可以最终不被任何接收端对象所接受。
14 、COMMAND—俺有一个MM家里管得特别严,没法见面,只好借助于她弟弟在我们俩之间传送信息,她对我有什么指示,就写一张纸条让她弟弟带给我。这 不,她弟弟又传送过来一个COMMAND,为了感谢他,我请他吃了碗杂酱面,哪知道他说:"我同时给我姐姐三个男朋友送COMMAND,就数你最小气,才 请我吃面。",: - (
命令模式:命令模式把一个请求或者操作封装到一个对象中。命令模式把发出命令的责任和执行命令的责任分割开,委派给不同的对象。命令模式允许请求的一方和 发送的一方独立开来,使得请求的一方不必知道接收请求的一方的接口,更不必知道请求是怎么被接收,以及操作是否执行,何时被执行以及是怎么被执行的。系统 支持命令的撤消。
15 、INTERPRETER—俺有一个《泡MM真经》,上面有各种泡MM的攻略,比如说去吃西餐的步骤、去看电影的方法等等,跟MM约会时,只要做一个Interpreter,照着上面的脚本执行就可以了。
解释器模式:给定一个语言后,解释器模式可以定义出其文法的一种表示,并同时提供一个解释器。客户端可以使用这个解释器来解释这个语言中的句子。解释器模 式将描述怎样在有了一个简单的文法后,使用模式设计解释这些语句。在解释器模式里面提到的语言是指任何解释器对象能够解释的任何组合。在解释器模式中需要 定义一个代表文法的命令类的等级结构,也就是一系列的组合规则。每一个命令对象都有一个解释方法,代表对命令对象的解释。命令对象的等级结构中的对象的任 何排列组合都是一个语言。
16 、ITERATOR—我爱上了Mary,不顾一切的向她求婚。
Mary:"想要我跟你结婚,得答应我的条件"
我:"什么条件我都答应,你说吧"
Mary:"我看上了那个一克拉的钻石"
我:"我买,我买,还有吗?"
Mary:"我看上了湖边的那栋别墅"
我:"我买,我买,还有吗?"
Mary:"你的小弟弟必须要有50cm长"
我脑袋嗡的一声,坐在椅子上,一咬牙:"我剪,我剪,还有吗?"
……
迭代子模式:迭代子模式可以顺序访问一个聚集中的元素而不必暴露聚集的内部表象。多个对象聚在一起形成的总体称之为聚集,聚集对象是能够包容一组对象的容 器对象。迭代子模式将迭代逻辑封装到一个独立的子对象中,从而与聚集本身隔开。迭代子模式简化了聚集的界面。每一个聚集对象都可以有一个或一个以上的迭代 子对象,每一个迭代子的迭代状态可以是彼此独立的。迭代算法可以独立于聚集角色变化。
17 、MEDIATOR—四个MM打麻将,相互之间谁应该给谁多少钱算不清楚了,幸亏当时我在旁边,按照各自的筹码数算钱,赚了钱的从我这里拿,赔了钱的也付给我,一切就OK啦,俺得到了四个MM的电话。
调停者模式:调停者模式包装了一系列对象相互作用的方式,使得这些对象不必相互明显作用。从而使他们可以松散偶合。当某些对象之间的作用发生改变 时,不会立即影响其他的一些对象之间的作用。保证这些作用可以彼此独立的变化。调停者模式将多对多的相互作用转化为一对多的相互作用。调停者模式将对象的 行为和协作抽象化,把对象在小尺度的行为上与其他对象的相互作用分开处理。
18 、MEMENTO—同时跟几个MM聊天时,一定要记清楚刚才跟MM说了些什么话,不然MM发现了会不高兴的哦,幸亏我有个备忘录,刚才与哪个MM说了什么话我都拷贝一份放到备忘录里面保存,这样可以随时察看以前的记录啦。
备忘录模式:备忘录对象是一个用来存储另外一个对象内部状态的快照的对象。备忘录模式的用意是在不破坏封装的条件下,将一个对象的状态捉住,并外部化,存储起来,从而可以在将来合适的时候把这个对象还原到存储起来的状态。
19 、OBSERVER—想知道咱们公司最新MM情报吗?加入公司的MM情报邮件组就行了,tom负责搜集情报,他发现的新情报不用一个一个通知我们,直接发布给邮件组,我们作为订阅者(观察者)就可以及时收到情报啦
观察者模式:观察者模式定义了一种一队多的依赖关系,让多个观察者对象同时监听某一个主题对象。这个主题对象在状态上发生变化时,会通知所有观察者对象,使他们能够自动更新自己。
20 、STATE—跟MM交往时,一定要注意她的状态哦,在不同的状态时她的行为会有不同,比如你约她今天晚上去看电影,对你没兴趣的MM就会说"有事情 啦",对你不讨厌但还没喜欢上的MM就会说"好啊,不过可以带上我同事么?",已经喜欢上你的MM就会说"几点钟?看完电影再去泡吧怎么样?",当然你看 电影过程中表现良好的话,也可以把MM的状态从不讨厌不喜欢变成喜欢哦。
状态模式:状态模式允许一个对象在其内部状态改变的时候改变行为。这个对象看上去象是改变了它的类一样。状态模式把所研究的对象的行为包装在不同的状态对 象里,每一个状态对象都属于一个抽象状态类的一个子类。状态模式的意图是让一个对象在其内部状态改变的时候,其行为也随之改变。状态模式需要对每一个系统 可能取得的状态创立一个状态类的子类。当系统的状态变化时,系统便改变所选的子类。
21 、STRATEGY—跟不同类型的MM约会,要用不同的策略,有的请电影比较好,有的则去吃小吃效果不错,有的去海边浪漫最合适,单目的都是为了得到MM的芳心,我的追MM锦囊中有好多Strategy哦。
策略模式:策略模式针对一组算法,将每一个算法封装到具有共同接口的独立的类中,从而使得它们可以相互替换。策略模式使得算法可以在不影响到客户端的情况 下发生变化。策略模式把行为和环境分开。环境类负责维持和查询行为类,各种算法在具体的策略类中提供。由于算法和环境独立开来,算法的增减,修改都不会影 响到环境和客户端。
22 、TEMPLATE METHOD——看过《如何说服女生上床》这部经典文章吗?女生从认识到上床的不变的步骤分为巧遇、打破僵局、展开追求、接吻、前 戏、动手、爱抚、进去八大步骤(Template method),但每个步骤针对不同的情况,都有不一样的做法,这就要看你随机应变啦(具体实现);
模板方法模式:模板方法模式准备一个抽象类,将部分逻辑以具体方法以及具体构造子的形式实现,然后声明一些抽象方法来迫使子类实现剩余的逻辑。不同的子类 可以以不同的方式实现这些抽象方法,从而对剩余的逻辑有不同的实现。先制定一个顶级逻辑框架,而将逻辑的细节留给具体的子类去实现。
23 、VISITOR—情人节到了,要给每个MM送一束鲜花和一张卡片,可是每个MM送的花都要针对她个人的特点,每张卡片也要根据个人的特点来挑,我一个人 哪搞得清楚,还是找花店老板和礼品店老板做一下Visitor,让花店老板根据MM的特点选一束花,让礼品店老板也根据每个人特点选一张卡,这样就轻松多 了;
访问者模式:访问者模式的目的是封装一些施加于某种数据结构元素之上的操作。一旦这些操作需要修改的话,接受这个操作的数据结构可以保持不变。访问者模式 适用于数据结构相对未定的系统,它把数据结构和作用于结构上的操作之间的耦合解脱开,使得操作集合可以相对自由的演化。访问者模式使得增加新的操作变的很 容易,就是增加一个新的访问者类。访问者模式将有关的行为集中到一个访问者对象中,而不是分散到一个个的节点类中。当使用访问者模式时,要将尽可能多的对 象浏览逻辑放在访问者类中,而不是放到它的子类中。访问者模式可以跨过几个类的等级结构访问属于不同的等级结构的成员类。
参考: http://c.chinaitlab.com/special/sjms/Index.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号