
读书笔记之:C++ Primer (第4版)及习题(ch12-ch18) [++++]
第12章 类
1. 类的声明与定义:前向声明,不完全类型

2. 从const函数返回*this

3. 可变数据成员mutable

4. 用于const对象的构造函数:构造函数不能声明为const

5. 构造函数初始化式

构造函数的执行分为两个阶段:初始化阶段和普通的计算阶段
6. 构造函数初始化列表

7. 默认实参与构造函数

8. 类通常定义一个默认构造函数,不然的话使用起来会很麻烦。

9. 使用默认构造函数

10. 隐式类类型转换:使用explicit来杜绝隐式类类型的转换

11. 类成员的显式初始化,这种显式初始化的方式是从C继承来的

12. static类成员

13. static成员函数

14. static成员变量


第13章 复制控制
1.C++中的复制控制

2. 复制构造函数

3. 合成复制构造函数

4. 禁止复制

5. 智能指针,引用计数

智能指针的实现:
 View Code
View Code

#include <string>
#include <cstddef>
using namespace std;
class U_Ptr {
friend class HasPtr;
int *ip;
size_t use;
U_Ptr(int *p): ip(p), use(1) { }
~U_Ptr() { delete ip; }
};
class HasPtr {
public:
HasPtr(int *p, int i): ptr(new U_Ptr(p)), val(i) { }
HasPtr(const HasPtr &orig):
ptr(orig.ptr), val(orig.val) { ++ptr->use; }
HasPtr& operator=(const HasPtr&);
~HasPtr() { if (--ptr->use == 0) delete ptr; }
friend ostream& operator<<(ostream&, const HasPtr&);
int *get_ptr() const { return ptr->ip; }
int get_int() const { return val; }
void set_ptr(int *p) { ptr->ip = p; }
void set_int(int i) { val = i; }
int get_ptr_val() const { return *ptr->ip; }
void set_ptr_val(int i) { *ptr->ip = i; }
private:
U_Ptr *ptr;
int val;
};
HasPtr& HasPtr::operator=(const HasPtr &rhs)
{
++rhs.ptr->use;
if (--ptr->use == 0)
delete ptr;
ptr = rhs.ptr;
val = rhs.val;
return *this;
}
ostream& operator<<(ostream &os, const HasPtr &hp)
{
os << "*ptr: " << hp.get_ptr_val() << "\tval: " << hp.get_int() << endl;
return os;
}
int main()
{
int obj = 0;
HasPtr ptr1(&obj, 42);
HasPtr ptr2(ptr1);
cout << "(1) ptr1: " << ptr1 << endl << "ptr2: " << ptr2 << endl;
ptr1.set_ptr_val(42);
ptr2.get_ptr_val();
cout << "(2) ptr1: " << ptr1 << endl << "ptr2: " << ptr2 << endl;
ptr1.set_int(0);
ptr2.get_int();
ptr1.get_int();
cout << "(3) ptr1: " << ptr1 << endl << "ptr2: " << ptr2 << endl;
}
第14章 重载操作符与转换
1.可重载的操作符与不可重载的操作符

不要重载具有内置含义的操作符

定义为成员函数或非成员函数

2. 输出操作符重载

3. 函数对象的函数适配器:绑定器与求反器

4. 转换操作符重载

5. 习题

第15章 面向对象编程
1. 动态绑定virtual,从派生类到基类的转换

2. C++中的多态性

3. 虚函数与默认实参

4. 转换与继承

5. 派生类到基类的转换

5.1 引用转换不同于对象转换

5.2 派生类对象对基类对象的初始化或赋值:切割

6. 从基类到派生类的转换

7. 复制控制和继承



8. 虚析构函数

9. 构造函数和赋值操作符不是虚函数:构造函数不能定义为虚函数,而赋值操作符定义为虚函数的话会令人混淆。

10. 构造函数和析构函数中的虚函数

11. 名字查找与继承

12. 容器与继承
容器中如果定义保存基类,那么派生类对象会被切割,如果定义为保持派生类,那么会产生很大问题。

13. 句柄类与继承

指针型句柄
一个例子如下:
View Code
#include <iostream>
#include <string>
#include <set>
#include <map>
#include <utility>
#include <cstddef>
#include <stdexcept>
#include <algorithm>
using namespace std;
class Item_base {
friend std::istream& operator>>(std::istream&, Item_base&);
friend std::ostream& operator<<(std::ostream&, const Item_base&);
public:
virtual Item_base* clone() const { return new Item_base(*this); }
public:
Item_base(const std::string &book = "", double sales_price = 0.0):
isbn(book), price(sales_price) { }
std::string book() const { return isbn; }
virtual double net_price(std::size_t n) const { return n * price; }
virtual ~Item_base() { }
private:
std::string isbn;
protected:
double price;
};
class Bulk_item : public Item_base {
public:
std::pair<size_t, double> discount_policy() const
{ return std::make_pair(min_qty, discount); }
Bulk_item* clone() const
{ return new Bulk_item(*this); }
Bulk_item(): min_qty(0), discount(0.0) { }
Bulk_item(const std::string& book, double sales_price,
std::size_t qty = 0, double disc_rate = 0.0):
Item_base(book, sales_price),
min_qty(qty), discount(disc_rate) { }
double net_price(std::size_t cnt) const
{
if (cnt >= min_qty)
return cnt * (1 - discount) * price;
else
return cnt * price;
}
private:
std::size_t min_qty;
double discount;
};
class Lim_item : public Item_base {
public:
Lim_item(const std::string& book = "", double sales_price = 0.0,
std::size_t qty = 0, double disc_rate = 0.0):
Item_base(book, sales_price),
max_qty(qty), discount(disc_rate) { }
double net_price(std::size_t cnt) const
{
size_t discounted = min(cnt, max_qty);
size_t undiscounted = cnt - discounted;
return discounted * (1 - discount) * price
+ undiscounted * price;
}
private:
std::size_t max_qty;
double discount;
public:
Lim_item* clone() const { return new Lim_item(*this); }
std::pair<size_t, double> discount_policy() const
{ return std::make_pair(max_qty, discount); }
};
class Sales_item {
friend class Basket;
friend bool compare(const Sales_item& lhs,const Sales_item& rhs);
public:
Sales_item(): p(0), use(new std::size_t(1)) { }
Sales_item(const Item_base& item):p(item.clone()), use(new std::size_t(1)) { }
Sales_item(const Sales_item &i):
p(i.p), use(i.use) { ++*use; }
~Sales_item() { decr_use(); }
Sales_item& operator=(const Sales_item& rhs) {
++*rhs.use;
decr_use();
p = rhs.p;
use = rhs.use;
return *this;
}
const Item_base *operator->() const { if (p) return p;
else throw std::logic_error("unbound Sales_item"); }
const Item_base &operator*() const { if (p) return *p;
else throw std::logic_error("unbound Sales_item"); }
private:
Item_base *p;
std::size_t *use;
void decr_use()
{ if (--*use == 0) { delete p; delete use; } }
};
bool compare(const Sales_item& lhs,const Sales_item& rhs){
return lhs->book()<rhs->book();
}
class Basket {
typedef bool (*Comp)(const Sales_item&, const Sales_item&);
public:
typedef std::multiset<Sales_item, Comp> set_type;
typedef set_type::size_type size_type;
typedef set_type::const_iterator const_iter;
void display(std::ostream&) const;
Basket(): items(compare) { }
void add_item(const Sales_item &item)
{ items.insert(item); }
size_type size(const Sales_item &i) const
{ return items.count(i); }
double total() const;
private:
std::multiset<Sales_item, Comp> items;
};
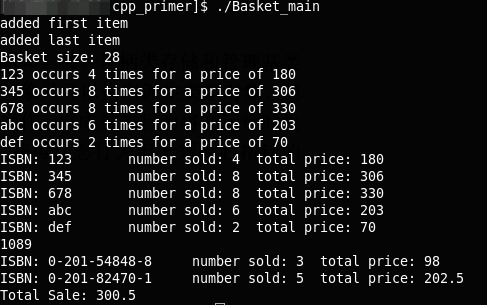
void Basket::display(ostream &os) const
{
os << "Basket size: " << items.size() << endl;
for (const_iter next_item = items.begin(); next_item != items.end();
next_item = items.upper_bound(*next_item)) {
os << (*next_item)->book() << " occurs "
<< items.count(*next_item) << " times"
<< " for a price of "
<< (*next_item)->net_price(items.count(*next_item))
<< endl;
}
}
void print_total(ostream &os, const Item_base &item, size_t n) {
os << "ISBN: " << item.book() // calls Item_base::book
<< "\tnumber sold: " << n << "\ttotal price: "
<< item.net_price(n) << endl;
}
double Basket::total() const
{
double sum = 0.0; // holds the running total
for (const_iter iter = items.begin(); iter != items.end();
iter = items.upper_bound(*iter)) {
print_total(cout, *(iter->p), items.count(*iter));
sum += (*iter)->net_price(items.count(*iter));
}
return sum;
}
int main()
{
Sales_item item1(Item_base("123", 45));
Sales_item item2(Bulk_item("345", 45, 3, .15));
Sales_item item3(Bulk_item("678", 55, 5, .25));
Sales_item item4(Lim_item("abc", 35, 2, .10));
Sales_item item5(Item_base("def", 35));
Basket sale;
sale.add_item(item1);
cout << "added first item" << endl;
sale.add_item(item1);
sale.add_item(item1);
sale.add_item(item1);
sale.add_item(item2);
sale.add_item(item2);
sale.add_item(item2);
sale.add_item(item2);
sale.add_item(item2);
sale.add_item(item2);
sale.add_item(item2);
sale.add_item(item2);
sale.add_item(item3);
sale.add_item(item3);
sale.add_item(item3);
sale.add_item(item3);
sale.add_item(item3);
sale.add_item(item3);
sale.add_item(item3);
sale.add_item(item3);
sale.add_item(item4);
sale.add_item(item4);
sale.add_item(item4);
sale.add_item(item4);
sale.add_item(item4);
sale.add_item(item4);
sale.add_item(item5);
sale.add_item(item5);
cout << "added last item" << endl;
sale.display(cout);
cout << sale.total() << endl;
{
// arguments are the isbn, price, minimum quantity, and discount
Bulk_item bulk("0-201-82470-1", 50, 5, .19);
Basket sale;
sale.add_item(Bulk_item("0-201-82470-1", 50, 5, .19));
sale.add_item(Bulk_item("0-201-82470-1", 50, 5, .19));
sale.add_item(Bulk_item("0-201-82470-1", 50, 5, .19));
sale.add_item(Bulk_item("0-201-82470-1", 50, 5, .19));
sale.add_item(Bulk_item("0-201-82470-1", 50, 5, .19));
sale.add_item(Lim_item("0-201-54848-8", 35, 2, .10));
sale.add_item(Lim_item("0-201-54848-8", 35, 2, .10));
sale.add_item(Lim_item("0-201-54848-8", 35, 2, .10));
double total = sale.total();
cout << "Total Sale: " << total << endl;
}
}
输出如下:
14. 文本查询
在原来的基础上添加了~,& 和| 来进行组合查询。
代码如下:
View Code
#include <set>
#include <map>
#include <vector>
#include <string>
#include <algorithm>
#include <fstream>
using namespace std;
class TextQuery
{
public:
typedef string::size_type str_size;
typedef vector<string>::size_type line_no;
void read_file(ifstream&is) {
store_file(is);
build_map();
}
set<line_no> run_query(const string&)const;
string text_line(line_no)const;
void display_map();
str_size size()const {
return lines_of_text.size();
}
private:
void store_file(ifstream&);
void build_map();
private:
vector<string> lines_of_text;
map<string,set<line_no> > word_map;
static string sep;
static string cleanup_str(const string&);
};
string TextQuery::sep(" \t\n\v\r\f,.`~!@#$%^&*-+=()[]{}<>;:\\/?\'\"|");
void TextQuery::store_file(ifstream& is)
{
string textline;
while(getline(is,textline))
lines_of_text.push_back(textline);
}
void TextQuery::build_map()
{
string line;
string word;
for(line_no num=0;num!=lines_of_text.size();++num)
{
line=lines_of_text[num];
string::size_type pos=0,pos2=0;
while((pos2=line.find_first_not_of(sep,pos))
!=string::npos){
pos=line.find_first_of(sep,pos2);
if(pos!=string::npos){
word=line.substr(pos2,pos-pos2);
}
else{
word=line.substr(pos2);
}
word_map[word].insert(num);
}
}
}
set<TextQuery::line_no>TextQuery::run_query(const string& query_word)const
{
map<string,set<line_no> >::const_iterator
loc=word_map.find(query_word);
if(loc==word_map.end())
return set<line_no>();
else
return loc->second;
}
string TextQuery::text_line(line_no line)const
{
if(line<lines_of_text.size())
return lines_of_text[line];
throw "line_number out of range";
}
void TextQuery::display_map()
{
map<string,set<line_no> >::iterator iter=word_map.begin(),
iter_end=word_map.end();
for(;iter!=iter_end;++iter)
{
cout<<"word: "<<iter->first<<" {";
const set<line_no>&text_locs=iter->second;
set<line_no>::const_iterator loc_iter=text_locs.begin(),
loc_iter_end=text_locs.end();
while(loc_iter!=loc_iter_end)
{
cout<<*loc_iter;
if(++loc_iter!=loc_iter_end)
cout<<", ";
}
cout<<"}\n";
}
cout<<endl;
}
string TextQuery::cleanup_str(const string &word)
{
string ret;
for(string::const_iterator it=word.begin();it!=word.end();++it)
{
if(!ispunct(*it))
ret+=tolower(*it);
}
return ret;
}
string make_plural(size_t ctr, const string &word,const string &ending)
{
return (ctr == 1) ? word : word + ending;
}
class Query_base {
friend class Query;
protected:
typedef TextQuery::line_no line_no;
virtual ~Query_base() { }
private:
virtual set<line_no> eval(const TextQuery&) const = 0;
virtual ostream& display(ostream& = cout) const = 0;
};
class Query {
friend Query operator~(const Query &);
friend Query operator|(const Query&, const Query&);
friend Query operator&(const Query&, const Query&);
public:
Query(const string&);
Query(const Query &c): q(c.q), use(c.use) { ++*use; }
~Query() { decr_use(); }
Query& operator=(const Query&rhs) {
++*rhs.use;
decr_use();
q = rhs.q;
use = rhs.use;
return *this;
}
set<TextQuery::line_no> eval(const TextQuery &t) const { return q->eval(t); }
ostream &display(ostream &os) const { return q->display(os); }
private:
Query(Query_base *query): q(query), use(new size_t(1)) { }
Query_base *q;
size_t *use;
void decr_use() { if (--*use == 0) { delete q; delete use; } }
};
ostream& operator<<(ostream &os, const Query &q) {
return q.display(os);
}
class WordQuery: public Query_base {
friend class Query;
WordQuery(const string &s): query_word(s) { }
set<line_no> eval(const TextQuery &t) const
{ return t.run_query(query_word); }
ostream& display (ostream &os) const
{ return os << query_word; }
string query_word;
};
inline Query::Query(const string &s): q(new WordQuery(s)), use(new size_t(1)) { }
class NotQuery: public Query_base {
friend Query operator~(const Query &);
NotQuery(Query q): query(q) { }
set<line_no> eval(const TextQuery&) const;
ostream& display(ostream &os) const
{ return os << "~(" << query << ")"; }
const Query query;
};
class BinaryQuery: public Query_base {
protected:
BinaryQuery(Query left, Query right, string op):
lhs(left), rhs(right), oper(op) { }
ostream& display(ostream &os) const
{ return os << "(" << lhs << " " << oper << " " << rhs << ")"; }
const Query lhs, rhs;
const string oper;
};
class AndQuery: public BinaryQuery {
friend Query operator&(const Query&, const Query&);
AndQuery(Query left, Query right):
BinaryQuery(left, right, "&") { }
set<line_no> eval(const TextQuery&) const;
};
class OrQuery: public BinaryQuery {
friend Query operator|(const Query&, const Query&);
OrQuery(Query left, Query right):
BinaryQuery(left, right, "|") { }
set<line_no> eval(const TextQuery&) const;
};
inline Query operator&(const Query &lhs, const Query &rhs)
{
return new AndQuery(lhs, rhs);
}
inline Query operator|(const Query &lhs, const Query &rhs)
{
return new OrQuery(lhs, rhs);
}
inline Query operator~(const Query &oper)
{
return new NotQuery(oper);
}
set<TextQuery::line_no>
NotQuery::eval(const TextQuery& file) const
{
set<TextQuery::line_no> has_val = query.eval(file);
set<line_no> ret_lines;
for (TextQuery::line_no n = 0; n != file.size(); ++n)
if (has_val.find(n) == has_val.end())
ret_lines.insert(n);
return ret_lines;
}
set<TextQuery::line_no>
AndQuery::eval(const TextQuery& file) const
{
set<line_no> left = lhs.eval(file),
right = rhs.eval(file);
set<line_no> ret_lines; // destination to hold results
set_intersection(left.begin(), left.end(),
right.begin(), right.end(),
inserter(ret_lines, ret_lines.begin()));
return ret_lines;
}
set<TextQuery::line_no>
OrQuery::eval(const TextQuery& file) const
{
set<line_no> right = rhs.eval(file),
ret_lines = lhs.eval(file); // destination to hold results
ret_lines.insert(right.begin(), right.end());
return ret_lines;
}
TextQuery build_textfile(const char* filename)
{
// get a file to read from which user will query words
ifstream infile;
infile.open(filename);
if (!infile) {
cerr << "No input file!" << endl;
return TextQuery();
}
TextQuery ret;
ret.read_file(infile); // builds query map
return ret; // builds query map
}
void print_results(const set<TextQuery::line_no>& locs, const TextQuery &file)
{
// report no matches
if (locs.empty()) {
cout << "\nSorry. There are no entries for your query."
<< "\nTry again." << endl;
return;
}
// if the word was found, then print count and all occurrences
set<TextQuery::line_no>::size_type size = locs.size();
cout << "match occurs "
<< size << (size == 1 ? " time:" : " times:") << endl;
// print each line in which the word appeared
set<TextQuery::line_no>::const_iterator it = locs.begin();
for ( ; it != locs.end(); ++it) {
cout << "\t(line "
// don't confound user with text lines starting at 0
<< (*it) + 1 << ") "
<< file.text_line(*it) << endl;
}
}
string& trim(string& s){
if(s.empty())
return s;
s.erase(0,s.find_first_not_of(' '));
s.erase(s.find_last_not_of(' ')+1);
return s;
}
int main(int argc,char**argv){
TextQuery file = build_textfile(argv[1]);
string sought;
while(true){
cout << "enter a word(s) to search for, or q to quit: ";
getline(cin,sought);
if(!cin||sought=="q")
break;
string::size_type pos;
if((pos=sought.find('~'))!=string::npos){
sought=sought.substr(pos+1);
trim(sought);
Query name(sought);
Query notq = ~name;
const set<TextQuery::line_no> locs = notq.eval(file);
cout << "\nExecuted Query for: " << notq << endl;
print_results(locs, file);
}
else if((pos=sought.find('&'))!=string::npos){
string sought1, sought2;
sought1=sought.substr(0,pos);
trim(sought1);
sought2=sought.substr(pos+1);
trim(sought2);
cout<<"sought1="<<sought1<<" sought2="<<sought2<<endl;
Query andq = Query(sought1) & Query(sought2);
set<TextQuery::line_no> locs = andq.eval(file);
cout << "\nExecuted query: " << andq << endl;
print_results(locs, file);
locs = Query(sought1).eval(file);
cout << "\nExecuted query: " << Query(sought1) << endl;
print_results(locs, file);
locs = Query(sought2).eval(file);
cout << "\nExecuted query: " << Query(sought2) << endl;
print_results(locs, file);
}
else if((pos=sought.find('|'))!=string::npos){
string sought1, sought2;
sought1=sought.substr(0,pos);
trim(sought1);
sought2=sought.substr(pos+1);
trim(sought2);
cout<<"sought1="<<sought1<<" sought2="<<sought2<<endl;
Query orq = Query(sought1) | Query(sought2);
cout << "\nExecuting Query for: " << orq << endl;
const set<TextQuery::line_no> locs = orq.eval(file);
print_results(locs, file);
}
else{
trim(sought);
Query name(sought);
const set<TextQuery::line_no> locs = name.eval(file);
cout << "\nExecuted Query for: " << name << endl;
print_results(locs, file);
}
}
return 0;
}
简单的运行结果如下:

第16章 模板与泛型编程
1. typename与class

只能使用typename来声明在类内部定义的类型成员。
2. 非类型模板参数
模板形参不一定都是类型。
void array_init(T (&parm)[N]){
for(size_t i=0;i!=N;++i)
parm[i]=0;
}
int main(){
int x[42];
double y[10];
array_init(x);
array_init(y);
}
可以使用非类型模板来确定数组的长度。
size_t size(T (&parm)[N]){
return N;
}
3. 模板实例化

在模板实参推断期间确定模板实参的类型和值。
4. 模板推断过程中涉及的函数实参允许的类型转换


5.应用于非模板形参的常规转换

6. 模板实参推断与函数指针
可以使用函数模板对函数指针进行初始化或赋值,这样做的时候,编译器使用指针的类型实例化具有适当模板实参的模板版本。
例如,假定有一个函数指针指向返回 int 值的函数,该函数接受两个形参,都是 const int 引用,可以用该指针指向 compare 的实例化
// pf1 points to the instantiation int compare (const int&, const int&)
int (*pf1) (const int&, const int&) = compare;
pf1 的类型是一个指针,指向"接受两个 const int& 类型形参并返回 int 值的函数",形参的类型决定了 T 的模板实参的类型,T 的模板实参为 int 型,指针 pf1 引用的是将 T 绑定到 int 的实例化。
获取函数模板实例化的地址的时候,上下文必须是这样的:它允许为每个模板形参确定唯一的类型或值。
如果不能从函数指针类型确定模板实参,就会出错。例如,假定有两个名为 func 的函数,每个函数接受一个指向函数实参的指针。func 的第一个版本接受有两个 const string 引用形参并返回 string 对象的函数的指针,func 的第二个版本接受带两个 const int 引用形参并返回 int 值的函数的指针,不能使用 compare 作为传给 func 的实参:
void func(int(*) (const string&, const string&));
void func(int(*) (const int&, const int&));
func(compare); // error: which instantiation of compare?
问题在于,通过查看 func 的形参类型不可能确定模板实参的唯一类型,对 func 的调用可以实例化下列函数中的任意一个:
compare(const int&, const int&)
因为不能为传给 func 的实参确定唯一的实例化,该调用会产生一个编译时(或链接时)错误。
7. 函数模板的显式实参
(1) 指定显式模板实参

(2)在返回类型中使用类型形参

(3)显式实参与函数模板的指针

8. 非类型形参的模板实参

9. 类模板中的友元声明
在类模板中可以出现三种友元声明,每一种都声明了与一个或多个实体友元关系:
(1) 普通非模板类或函数的友元声明,将友元关系授予明确指定的类或函数。

(2) 类模板或函数模板的友元声明,授予对友元所有实例的访问权。

(3) 类模板或函数模板的特定实例的访问权的友元声明。


10. 成员模板
任意类(模板或非模板)可以拥有本身为类模板或函数模板的成员,这种成员称为成员模板,成员模板不能为虚。


11. 类模板的static成员



12. 模板特化
函数模板特化



13. 类模板特化
类模板的部分特化
如果类模板有一个以上的模板形参,我们也许想要特化某些模板形参而非全部。使用类模板的部分特化可以做到这一点:
class some_template {
// ...
};
// partial specialization: fixes T2 as int and allows T1 to vary
template <class T1>
class some_template<T1, int> {
// ...
};
类模板的部分特化本身也是模板。部分特化的定义看来像模板定义,这种定义以关键字 template 开头,接着是由尖括号(<>)括住的模板形参表。部分特化的模板形参表是对应的类模板定义形参表的子集。some_template 的部分特化只有一个名为 T1 的模板类型形参,第二个模板形参 T2 的实参已知为 int。部分特化的模板形参表只列出未知模板实参的那些形参。
部分特化的定义与通用模板的定义完全不会冲突。部分特化可以具有与通用类模板完全不同的成员集合。类模板成员的通用定义永远不会用来实例化类模板部分特化的成员。
14. 重载与函数模板


确定重载函数模板的调用
可以在不同类型上调用这些函数:
compare(1, 0);
// calls compare(U, U, V), with U and V bound to vector<int>::iterator
vector<int> ivec1(10), ivec2(20);
compare(ivec1.begin(), ivec1.end(), ivec2.begin());
int ia1[] = {0,1,2,3,4,5,6,7,8,9};
// calls compare(U, U, V) with U bound to int*
// and V bound to vector<int>::iterator
compare(ia1, ia1 + 10, ivec1.begin());
// calls the ordinary function taking const char* parameters
const char const_arr1[] = "world", const_arr2[] = "hi";
compare(const_arr1, const_arr2);
// calls the ordinary function taking const char* parameters
char ch_arr1[] = "world", ch_arr2[] = "hi";
compare(ch_arr1, ch_arr2);
下面依次介绍每个调用。
compare(1, 0):两个形参都是 int 类型。候选函数是第一个模板将 T 绑定到 int 的实例化,以及名为 compare 的普通函数。但该普通函数不可行——不能将 int 对象传给期待 char* 对象的形参。用 int 实例化的函数与该调用完全匹配,所以选择它。
compare(ivec1.begin(), ivec1.end(), ivec2.begin())
compare(ia1, ia1 + 10, ivec1.begin()):
这两个调用中,唯一可行的函数是有三个形参的模板的实例化。带两个参数的模板和普通非模板函数都不能匹配这两个调用。
compare(const_arr1, const_arr2): 这个调用正如我们所期待的,调用普通函数。该函数和将 T 绑定到 const char* 的第一个模板都是可行的,也都完全匹配。根据规则 3b,会选择普通函数。从候选集合中去掉模板实例,只剩下普通函数可行。
compare(ch_arr1, ch_arr2):这个调用也绑定到普通函数。候选者是将 T 绑定到 char* 的函数模板的版本,以及接受 const char* 实参的普通函数,两个函数都需要稍加转换将数组 ch_arr1 和 ch_arr2 转换为指针。因为两个函数一样匹配,所以普通函数优先于模板版本。
第17章 用于大型程序的工具
1. 抛出类类型的异常
异常是通过抛出对象而引发的。该对象的类型决定应该激活哪个处理代码。被选中的处理代码是调用链中与该对象类型匹配且离抛出异常位置最近的那个。
异常以类似于将实参传递给函数的方式抛出和捕获。异常可以是可传给非引用形参的任意类型的对象,这意味着必须能够复制该类型的对象。
回忆一下,传递数组或函数类型实参的时候,该实参自动转换为一个指针。被抛出的对象将发生同样的自动转换,因此,不存在数组或函数类型的异常。相反。相反,如果抛出一个数组,被抛出的对象转换为指向数组首元素的指针,类似地,如果抛出一个函数,函数被转换为指向该函数的指针第 7.9 节。
执行 throw 的时候,不会执行跟在 throw 后面的语句,而是将控制从 throw 转移到匹配的 catch,该 catch 可以是同一函数中局部的 catch,也可以在直接或间接调用发生异常的函数的另一个函数中。控制从一个地方传到另一地方,这有两个重要含义:
1. 沿着调用链的函数提早退出。第 17.1.2 节将讨论函数因异常而退出时会发生什么。
2. 一般而言,在处理异常的时候,抛出异常的块中的局部存储不存在了。
因为在处理异常的时候会释放局部存储,所以被抛出的对象就不能再局部存储,而是用 throw 表达式初始化一个称为异常对象的特殊对象。异常对象由编译器管理,而且保证驻留在可能被激活的任意 catch 都可以访问的空间。这个对象由 throw 创建,并被初始化为被抛出的表达式的副本。异常对象将传给对应的 catch,并且在完全处理了异常之后撤销。
异常对象通过复制被抛出表达式的结果创建,该结果必须是可以复制的类型
2. 异常对象与继承
当抛出一个表达式的时候,被抛出对象的静态编译时类型将决定异常对象的类型。
通常,使用静态类型抛出对象不成问题。当抛出一个异常的时候,通常在抛出点构造将抛出的对象,该对象表示出了什么问题,所以我们知道确切的异常类型。
3. 异常与指针
用抛出表达式抛出静态类型时,比较麻烦的一种情况是,在抛出中对指针解引用。对指针解引用的结果是一个对象,其类型与指针的类型匹配。如果指针指向继承层次中的一种类型,指针所指对象的类型就有可能与指针的类型不同。无论对象的实际类型是什么,异常对象的类型都与指针的静态类型相匹配。如果该指针是一个指向派生类对象的基类类型指针,则那个对象将被分割,只抛出基类部分。
如果抛出指针本身,可能会引发比分割对象更严重的问题。具体而言,抛出指向局部对象的指针总是错误的,其理由与从函数返回指向局部对象的指针是错误的一样。抛出指针的时候,必须确定进入处理代码时指针所指向的对象存在。
如果抛出指向局部对象的指针,而且处理代码在另一函数中,则执行处理代码时指针所指向的对象将不再存在。即使处理代码在同一函数中,也必须确信指针所指向的对象在 catch 处存在。如果指针指向某个在 catch 之前退出的块中的对象,那么,将在 catch 之前撤销该局部对象。

4. 栈展开Stack Unwinding
抛出异常的时候,将暂停当前函数的执行,开始查找匹配的 catch 子句。首先检查 throw 本身是否在 try 块内部,如果是,检查与该 catch 相关的 catch 子句,看是否其中之一与抛出对象相匹配。如果找到匹配的 catch,就处理异常;如果找不到,就退出当前函数(释放当前函数的内在并撤销局部对象),并且继续在调用函数中查找。
如果对抛出异常的函数的调用是在 try 块中,则检查与该 try 相关的 catch 子句。如果找到匹配的 catch,就处理异常;如果找不到匹配的 catch,调用函数也退出,并且继续在调用这个函数的函数中查找。
这个过程,称之为栈展开(stack unwinding),沿嵌套函数调用链继续向上,直到为异常找到一个 catch 子句。只要找到能够处理异常的 catch 子句,就进入该 catch 子句,并在该处理代码中继续执行。当 catch 结束的时候,在紧接在与该 try 块相关的最后一个 catch 子句之后的点继续执行。
(1)为局部对象调用析构函数
栈展开期间,提早退出包含 throw 的函数和调用链中可能的其他函数。一般而言,这些函数已经创建了可以在退出函数时撤销的局部对象。因异常而退出函数时,编译器保证适当地撤销局部对象。每个函数退出的时候,它的局部存储都被释放,在释放内存之前,撤销在异常发生之前创建的所有对象。如果局部对象是类类型的,就自动调用该对象的析构函数。通常,编译器不撤销内置类型的对象。
栈展开期间,释放局部对象所用的内存并运行类类型局部对象的析构函数。
如果一个块直接分配资源,而且在释放资源之前发生异常,在栈展开期间将不会释放该资源。例如,一个块可以通过调用 new 动态分配内存,如果该块因异常而退出,编译器不会删除该指针,已分配的内在将不会释放。
由类类型对象分配的资源一般会被适当地释放。运行局部对象的析构函数,由类类型对象分配的资源通常由它们的析构函数释放。第 17.1.8 节说明面对异常使用类管理资源分配的编程技术
(2)析构函数应该从不抛出异常
栈展开期间会经常执行析构函数。在执行析构函数的时候,已经引发了异常但还没有处理它。如果在这个过程中析构函数本身抛出新的异常,又会发生什么呢?新的异常应该取代仍未处理的早先的异常吗?应该忽略析构函数中的异常吗?
答案是:在为某个异常进行栈展开的时候,析构函数如果又抛出自己的未经处理的另一个异常,将会导致调用标准库 terminate 函数。一般而言,terminate 函数将调用 abort 函数,强制从整个程序非正常退出。
因为 terminate 函数结束程序,所以析构函数做任何可能导致异常的事情通常都是非常糟糕的主意。在实践中,因为析构函数释放资源,所以它不太可能抛出异常。标准库类型都保证它们的析构函数不会引发异常。
(3)异常与构造函数
与析构函数不同,构造函数内部所做的事情经常会抛出异常。如果在构造函数对象的时候发生异常,则该对象可能只是部分被构造,它的一些成员可能已经初始化,而另一些成员在异常发生之前还没有初始化。即使对象只是部分被构造了,也要保证将会适当地撤销已构造的成员。
类似地,在初始化数组或其他容器类型的元素的时候,也可能发生异常,同样,也要保证将会适当地撤销已构造的元素。
(4)未捕获的异常终止程序
不能不处理异常。异常是足够重要的、使程序不能继续正常执行的事件。如果找不到匹配的 catch,程序就调用库函数 terminate。
5. 捕获异常
catch 子句中的异常说明符看起来像只包含一个形参的形参表,异常说明符是在其后跟一个(可选)形参名的类型名。
说明符的类型决定了处理代码能够捕获的异常种类。类型必须是完全类型,即必须是内置类型或者是已经定义的程序员自定义类型。类型的前向声明不行。
当 catch 为了处理异常只需要了解异常的类型的时候,异常说明符可以省略形参名;如果处理代码需要已发生异常的类型之外的信息,则异常说明符就包含形参名,catch 使用这个名字访问异常对象。
(1)查找匹配的处理代码
在查找匹配的 catch 期间,找到的 catch 不必是与异常最匹配的那个 catch,相反,将选中第一个找到的可以处理该异常的 catch。因此,在 catch 子句列表中,最特殊的 catch 必须最先出现。
异常与 catch 异常说明符匹配的规则比匹配实参和形参类型的规则更严格,大多数转换都不允许——除下面几种可能的区别之外,异常的类型与 catch 说明符的类型必须完全匹配:
*允许从非 const 到 const 的转换。也就是说,非 const 对象的 throw 可以与指定接受 const 引用的 catch 匹配。
*允许从派生类型型到基类类型的转换。
*将数组转换为指向数组类型的指针,将函数转换为指向函数类型的适当指针。
在查找匹配 catch 的时候,不允许其他转换。具体而言,既不允许标准算术转换,也不允许为类类型定义的转换。
(2)异常说明符
进入 catch 的时候,用异常对象初始化 catch 的形参。像函数形参一样,异常说明符类型可以是引用。异常对象本身是被抛出对象的副本。是否再次将异常对象复制到 catch 位置取决于异常说明符类型。
如果说明符不是引用,就将异常对象复制到 catch 形参中,catch 操作异常对象的副本,对形参所做的任何改变都只作用于副本,不会作用于异常对象本身。如果说明符是引用,则像引用形参一样,不存在单独的 catch 对象,catch 形参只是异常对象的另一名字。对 catch 形参所做的改变作用于异常对象。
(3)异常说明符与继承
像形参声明一样,基类的异常说明符可以用于捕获派生类型的异常对象,而且,异常说明符的静态类型决定 catch 子句可以执行的动作。如果被抛出的异常对象是派生类类型的,但由接受基类类型的 catch 处理,那么,catch 不能使用派生类特有的任何成员。
通常,如果 catch 子句处理因继承而相关的类型的异常,它就应该将自己的形参定义为引用。
如果 catch 形参是引用类型,catch 对象就直接访问异常对象,catch 对象的静态类型可以与 catch 对象所引用的异常对象的动态类型不同。如果异常说明符不是引用,则 catch 对象是异常对象的副本,如果 catch 对象是基类类型对象而异常对象是派生类型的,就将异常对象分割(第 15.3.1 节)为它的基类子对象。
而且,正如第 15.2.4 节所介绍的,对象(相对于引用)不是多态的。当通过对象而不是引用使用虚函数的时候,对象的静态类型和动态类型相同,函数是虚函数也一样。只有通过引用或指针调用时才发生动态绑定,通过对象调用不进行动态绑定。
(4)catch子句的次序必须反映类型层次
将异常类型组织成类层次的时候,用户可以选择应用程序处理异常的粒度级别。例如,只希望清除并退出的应用程序可以定义一个 try 块,该 try 块包围 main 函数中带有如下 catch 代码:
// do cleanup
// print a message
cerr << "Exiting: " << e.what() << endl;
size_t status_indicator = 42; // set and return an
return(status_indicator); // error indicator
}
有更严格实时需求的程序可能需要更好的异常控制,这样的应用程序将清除导致异常的一切并继续执行。
因为 catch 子句按出现次序匹配,所以使用来自继承层次的异常的程序必须将它们的 catch 子句排序,以便派生类型的处理代码出现在其基类类型的 catch 之前。
6. 重新抛出
一般而言,catch 可以改变它的形参。在改变它的形参之后,如果 catch 重新抛出异常,那么,只有当异常说明符是引用的时候,才会传播那些改变。
eObj.status = severeErr; // modifies the exception object
throw; // the status member of the exception object is severeErr
} catch (other_error eObj) { // specifier is a nonreference type
eObj.status = badErr; // modifies local copy only
throw; // the status member of the exception rethrown is unchanged
}
7. 捕获所有异常的代码
即使函数不能处理被抛出的异常,它也可能想要在随抛出异常退出之前执行一些动作。除了为每个可能的异常提供特定 catch 子句之外,因为不可能知道可能被抛出的所有异常,所以可以使用捕获所有异常 catch 子句的。捕获所有异常的 catch 子句形式为 (...)。例如:
catch (...) {
// place our code here
}
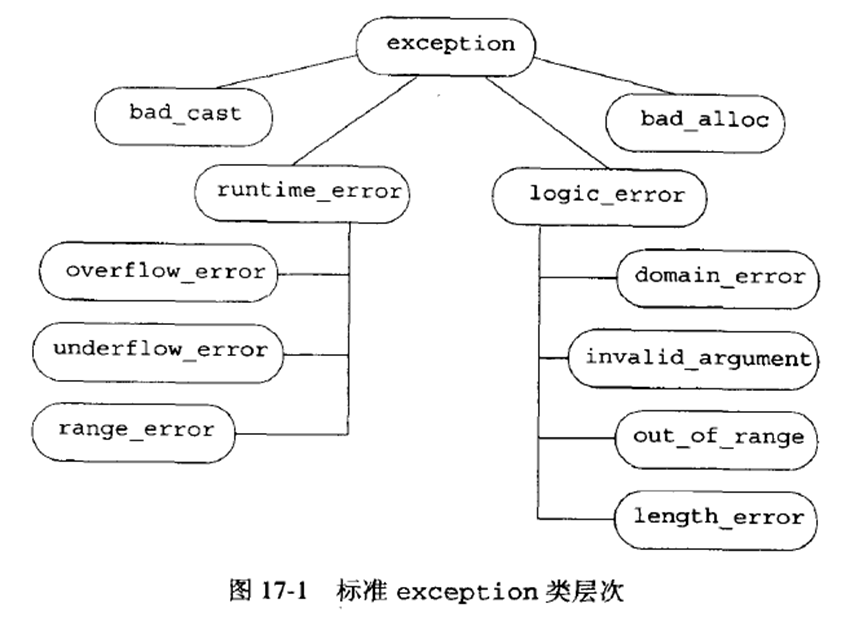
8. 标准异常类
9. 自动资源释放
用类管理资源分配。
对析构函数的运行导致一个重要的编程技术的出现,它使程序更为异常安全的。异常安全的意味着,即使发生异常,程序也能正确操作。在这种情况下,"安全"来自于保证"如果发生异常,被分配的任何资源都适当地释放"。
通过定义一个类来封闭资源的分配和释放,可以保证正确释放资源。这一技术常称为"资源分配即初始化",简称 RAII。
应该设计资源管理类,以便构造函数分配资源而析构函数释放资源。想要分配资源的时候,就定义该类类型的对象。如果不发生异常,就在获得资源的对象超出作用域的进修释放资源。更为重要的是,如果在创建了对象之后但在它超出作用域之前发生异常,那么,编译器保证撤销该对象,作为展开定义对象的作用域的一部分。
10. auto_ptr类
位于头文件memory中,智能指针

auto_ptr 只能用于管理从 new 返回的一个对象,它不能管理动态分配的数组。
正如我们所见,当 auto_ptr 被复制或赋值的时候,有不寻常的行为,因此,不能将 auto_ptrs 存储在标准库容器类型中。
auto_ptr 对象只能保存一个指向对象的指针,并且不能用于指向动态分配的数组,使用 auto_ptr 对象指向动态分配的数组会导致未定义的运行时行为。
每个 auto_ptr 对象绑定到一个对象或者指向一个对象。当 auto_ptr 对象指向一个对象的时候,可以说它"拥有"该对象。当 auto_ptr 对象超出作用域或者另外撤销的时候,就自动回收 auto_ptr 所指向的动态分配对象。
(1)为异常安全的内存分配使用 auto_ptr
如果通过常规指针分配内在,而且在执行 delete 之前发生异常,就不会自动释放该内存:
{
int *ip = new int(42); // dynamically allocate a new object
// code that throws an exception that is not caught inside f
delete ip; // return the memory before exiting
}
如果在 new 和 delete 之间发生异常,并且该异常不被局部捕获,就不会执行 delete,则永不回收该内存。
如果使用一个 auto_ptr 对象来代替,将会自动释放内存,即使提早退出这个块也是这样:
{
auto_ptr<int> ap(new int(42)); // allocate a new object
// code that throws an exception that is not caught inside f
} // auto_ptr freed automatically when function ends
在这个例子中,编译器保证在展开栈越过 f 之前运行 ap 的析构函数。
(2)auto_ptr 是可以保存任何类型指针的模板
auto_ptr 类是接受单个类型形参的模板,该类型指定 auto_ptr 可以绑定的对象的类型,因此,可以创建任何类型的 auto_ptrs:
(3)将 auto_ptr 绑定到指针
在最常见的情况下,将 auto_ptr 对象初始化为由 new 表达式返回的对象的地址:
这个语句将 pi 初始化为由 new 表达式创建的对象的地址,这个 new 表达式将对象初始化为 1024。
接受指针的构造函数为 explicit(第 12.4.4 节)构造函数,所以必须使用初始化的直接形式来创建 auto_ptr 对象:
auto_ptr<int> pi = new int(1024);
auto_ptr<int> pi(new int(1024)); // ok: uses direct initialization
pi 所指的由 new 表达式创建的对象在超出作用域时自动删除。如果 pi 是局部对象,pi 所指对象在定义 pi 的块的末尾删除;如果发生异常,则 pi 也超出作用域,析构函数将自动运行 pi 的析构函数作为异常处理的一部分;如果 pi 是全局对象,就在程序末尾删除 pi 引用的对象。
(4)使用 auto_ptr 对象
auto_ptr 类定义了解引用操作符(*)和箭头操作符(->)的重载版本(第 14.6 节),因为 auto_ptr 定义了这些操作符,所以可以用类似于使用内置指针的方式使用 auto_ptr 对象:
*ap1 = "TRex"; // assigns a new value to the object to which ap1 points
string s = *ap1; // initializes s as a copy of the object to which ap1 points
if (ap1->empty()) // runs empty on the string to which ap1 points
auto_ptr 的主要目的,在保证自动删除 auto_ptr 对象引用的对象的同时,支持普通指针式行为。正如我们所见,自动删除该对象这一事实导致在怎样复制和访问它们的地址值方面,auto_ptrs 与普通指针明显不同。
(5)auto_ptr 对象的复制和赋值是破坏性操作
auto_ptr 和内置指针对待复制和赋值有非常关键的重要区别。当复制 auto_ptr 对象或者将它的值赋给其他 auto_ptr 对象的时候,将基础对象的所有权从原来的 auto_ptr 对象转给副本,原来的 auto_ptr 对象重置为未绑定状态。
(6)赋值删除左操作数指向的对象
除了将所有权从右操作数转给左操作数之外,赋值还删除左操作数原来指向的对象——假如两个对象不同。通常自身赋值没有效果。
// object pointed to by ap3 is deleted and ownership transferred from ap2 to ap3;
ap3 = ap2; // after the assignment, ap2 is unbound
因为复制和赋值是破坏性操作,所以auto_ptrs不能将 auto_ptr 对象存储在标准容器中。标准库的容器类要求在复制或赋值之后两个对象相等,auto_ptr 不满足这一要求,如果将 ap2 赋给 ap1,则在赋值之后 ap1 != ap2,复制也类似。
(7)auto_ptr 的默认构造函数
如果不给定初始式,auto_ptr 对象是未绑定的,它不指向对象:
默认情况下,auto_ptr 的内部指针值置为 0。对未绑定的 auto_ptr 对象解引用,其效果与对未绑定的指针解引用相同——程序出错并且没有定义会发生什么:
(8)测试 auto_ptr 对象
auto_ptr 类型没有定义到可用作条件的类型的转换,相反,要测试 auto_ptr 对象,必须使用它的 get 成员,该成员返回包含在 auto_ptr 对象中的基础指针:
if (p_auto.get())
*p_auto = 1024;
使用 get 成员初始化其他 auto_ptr 对象违反 auto_ptr 类设计原则:在任意时刻只有一个 auto_ptrs 对象保存给定指针,如果两个 auto_ptrs 对象保存相同的指针,该指针就会被 delete 两次。
(9)reset 操作
auto_ptr 对象与内置指针的另一个区别是,不能直接将一个地址(或者其他指针)赋给 auto_ptr 对象:
相反,必须调用 reset 函数来改变指针:
if (p_auto.get())
*p_auto = 1024;
else
// reset p_auto to a new object
p_auto.reset(new int(1024));
要复位 auto_ptr 对象,可以将 0 传给 reset 函数。
11. auto_ptr的缺陷
auto_ptr 类模板为处理动态分配的内存提供了安全性和便利性的尺度。要正确地使用 auto_ptr 类,必须坚持该类强加的下列限制:
1.不要使用 auto_ptr 对象保存指向静态分配对象的指针,否则,当 auto_ptr 对象本身被撤销的时候,它将试图删除指向非动态分配对象的指针,导致未定义的行为。
2.永远不要使用两个 auto_ptr 对象指向同一对象,导致这个错误的一种明显方式是,使用同一指针来初始化或者 reset 两个不同的 auto_ptr 对象。另一种导致这个错误的微妙方式可能是,使用一个 auto_ptr 对象的 get 函数的结果来初始化或者 reset 另一个 auto_ptr 对象。
3.不要使用 auto_ptr 对象保存指向动态分配数组的指针。当 auto_ptr 对象被删除的时候,它只释放一个对象——它使用普通 delete 操作符,而不用数组的 delete [] 操作符。
4.不要将 auto_ptr 对象存储在容器中。容器要求所保存的类型定义复制和赋值操作符,使它们表现得类似于内置类型的操作符:在复制(或者赋值)之后,两个对象必须具有相同值,auto_ptr 类不满足这个要求。
12. 异常说明
异常说明跟在函数形参表之后。一个异常说明在关键字 throw 之后跟着一个(可能为空的)由圆括号括住的异常类型列表。
空说明列表指出函数不抛出任何异常:
void no_problem() throw();
异常说明是函数接口的一部分,函数定义以及该函数的任意声明必须具有相同的异常说明。
如果一个函数声明没有指定异常说明,则该函数可以抛出任意类型的异常。
(1)违反异常说明
如果函数抛出了没有在其异常说明中列出的异常,就调用标准库函数 unexpected。默认情况下,unexpected 函数调用 terminate 函数,terminate 函数一般会终止程序。
(2)确定函数不抛出异常
异常说服有用的一种重要情况是,如果函数可以保证不会抛出任何异常。
确定函数将不抛出任何异常,对函数的用户和编译器都有所帮助:知道函数不抛出异常会简化编写调用该函数的异常安全的代码的工作,我们可以知道在调用函数时不必担心异常,而且,如果编译器知道不会抛出异常,它就可以执行被可能抛出异常的代码所抑制的优化。
(3)异常说明与成员函数
像非成员函数一样,成员函数声明的异常说明跟在函数形参表之后。例如,C++ 标准库中的 bad_alloc 类定义为所有成员都有空异常说明,这些成员承诺不抛出异常:
class bad_alloc : public exception {
public:
bad_alloc() throw();
bad_alloc(const bad_alloc &) throw();
bad_alloc & operator=(const
bad_alloc &) throw();
virtual ~bad_alloc() throw();
virtual const char* what() const throw();
};
注意,在 const 成员函数声明中,异常说明跟在 const 限定符之后。
(4)异常说明与虚函数
基类中虚函数的异常说明,可以与派生类中对应虚函数的异常说明不同。但是,派生类虚函数的异常说明必须与对应基类虚函数的异常说明同样严格,或者比后者更受限。
这个限制保证,当使用指向基类类型的指针调用派生类虚函数的时候,派生类的异常说明不会增加新的可抛出异常。例如:
public:
virtual double f1(double) throw ();
virtual int f2(int) throw (std::logic_error);
virtual std::string f3() throw
(std::logic_error, std::runtime_error);
};
class Derived : public Base {
public:
// error: exception specification is less restrictive than Base::f1's
double f1(double) throw (std::underflow_error);
// ok: same exception specification as Base::f2
int f2(int) throw (std::logic_error);
// ok: Derived f3 is more restrictive
std::string f3() throw ();
};
派生类中 f1 的声明是错误的,因为它的异常说明在基类 f1 版本列出的异常中增加了一个异常。派生类不能在异常说明列表中增加异常,原因在于,继承层次的用户应该能够编写依赖于该说明列表的代码。如果通过基类指针或引用进行函数调用,那么,这些类的用户所涉及的应该只是在基类中指定的异常。
通过派生类抛出的异常限制为由基类所列出的那些,在编写代码时就可以知道必须处理哪些异常。代码可以依赖于这样一个事实:基类中的异常列表是虚函数的派生类版本可以抛出的异常列表的超集。例如,当调用 f3 的时候,我们知道只需要处理 logic_error 或 runtime_error:
void compute(Base *pb) throw()
{
try {
// may throw exception of type std::logic_error
// or std::runtime_error
pb->f3();
} catch (const logic_error &le) { /* ... */ }
catch (const runtime_error &re) { /* ... */ }
}
(5)函数指针异常说明
异常说明是函数类型的一部分。这样,也可以在函数指针的定义中提供异常说明:
void (*pf)(int) throw(runtime_error);
这个声明是说,pf 指向接受 int 值的函数,该函数返回 void 对象,该函数只能抛出 runtime_error 类型的异常。如果不提供异常说明,该指针就可以指向能够抛出任意类型异常的具有匹配类型的函数。
在用另一指针初始化带异常说明的函数的指针,或者将后者赋值给函数地址的时候,两个指针的异常说明不必相同,但是,源指针的异常说明必须至少与目标指针的一样严格。
// ok: recoup is as restrictive as pf1
void (*pf1)(int) throw(runtime_error) = recoup;
// ok: recoup is more restrictive than pf2
void (*pf2)(int) throw(runtime_error, logic_error) = recoup;
// error: recoup is less restrictive than pf3
void (*pf3)(int) throw() = recoup;
// ok: recoup is more restrictive than pf4
void (*pf4)(int) = recoup;
第三个初始化是错误的。指针声明指出,pf3 指向不抛出任何异常的函数,但是,recoup 函数指出它能抛出 runtime_error 类型的异常,recoup 函数抛出的异常类型超出了 pf3 所指定的,对 pf3 而言,recoup 函数不是有效的初始化式,并且会引发一个编译时错误。
13. 命名空间/名字空间
命名空间可以是不连续的。与其他作用域不同,命名空间可以在几个部分中定义。命名空间由它的分离定义部分的总和构成,命名空间是累积的。一个命名空间的分离部分可以分散在多个文件中,在不同文本文件中的命名空间定义也是累积的。当然,名字只在声明名字的文件中可见,这一常规限制继续应用,所以,如果命名空间的一个部分需要定义在另一文件中的名字,仍然必须声明该名字。
定义多个不相关类型的命名空间应该使用分离的文件,表示该命名空间定义的每个类型。
(1)未命名的名字空间
未命名的命名空间与其他命名空间不同,未命名的命名空间的定义局部于特定文件,从不跨越多个文本文件。
未命名的命名空间可以在给定文件中不连续,但不能跨越文件,每个文件有自己的未命名的命名空间。
未命名的命名空间中定义的名字可直接使用,毕竟,没有命名空间名字来限定它们。不能使用作用域操作符来引用未命名的命名空间的成员。
未命名的命名空间中定义的名字只在包含该命名空间的文件中可见。如果另一文件包含一个未命名的命名空间,两个命名空间不相关。两个命名空间可以定义相同的名字,而这些定义将引用不同的实体。
未命名空间中定义的名字可以在定义该命名空间所在的作用域中找到。如果在文件的最外层作用域中定义未命名的命名空间,那么,未命名的空间中的名字必须与全局作用域中定义的名字不同:
namespace {
int i;
}
// error: ambiguous defined globally and in an unnested, unnamed namespace
i = 10;
像任意其他命名空间一样,未命名的命名空间也可以嵌套在另一命名空间内部。如果未命名的命名空间是嵌套的,其中的名字按常规方法使用外围命名空间名字访问:
namespace {
int i;
}
}
// ok: i defined in a nested unnamed namespace is distinct from global i
local::i = 42;
在标准 C++ 中引入命名空间之前,程序必须将名字声明为 static,使它们局部于一个文件。文件中静态声明的使用从 C 语言继承而来,在 C 语言中,声明为 static 的局部实体在声明它的文件之外不可见。
C++ 不赞成文件静态声明。不造成的特征是在未来版本中可能不支持的特征。应该避免文件静态而使用未命名空间代替。
14. 多重继承与虚继承
在多重继承下,派生类的对象包含每个基类的基类子对象。
虚继承来解决菱形继承中的多个基类子对象的问题。
在 C++ 中,通过使用虚继承解决这类问题。虚继承是一种机制,类通过虚继承指出它希望共享其虚基类的状态。在虚继承下,对给定虚基类,无论该类在派生层次中作为虚基类出现多少次,只继承一个共享的基类子对象。共享的基类子对象称为虚基类。
虚继承带来了初始化顺序的问题。
通常,每个类只初始化自己的直接基类。在应用于虚基类的进修,这个初始化策略会失败。如果使用常规规则,就可能会多次初始化虚基类。类将沿着包含该虚基类的每个继承路径初始化。
为了解决这个重复初始化问题,从具有虚基类的类继承的类对初始化进行特殊处理。在虚派生中,由最低层派生类的构造函数初始化虚基类。
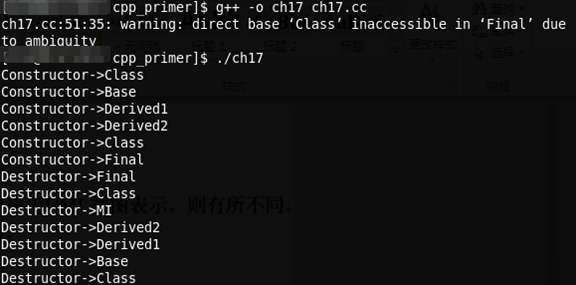
构造函数与析构函数次序:无论虚基类出现在继承层次中任何地方,总是在构造非虚基类之前构造虚基类。




代码如下:
View Code
#include <iostream>
class Class{
public:
Class(){
std::cout<<"Constructor->Class"<<std::endl;
}
~Class(){
std::cout<<"Destructor->Class"<<std::endl;
}
};
class Base: public Class{
public:
Base():name("Base"){std::cout<<"Constructor->Base"<<std::endl;}
Base(std::string s):name(s){std::cout<<"Constructor->Base"<<std::endl;}
Base(const Base& b):name(b.name){std::cout<<"Constructor->Base"<<std::endl;}
~Base(){
std::cout<<"Destructor->Base"<<std::endl;
}
protected:
std::string name;
};
class Derived1:virtual public Base{
public:
Derived1():Base("Derived1"){std::cout<<"Constructor->Derived1"<<std::endl;}
Derived1(std::string s):Base(s){std::cout<<"Constructor->Derived1"<<std::endl;}
Derived1(const Derived1& d):Base(d){std::cout<<"Constructor->Derived1"<<std::endl;}
~Derived1(){
std::cout<<"Destructor->Derived1"<<std::endl;
}
};
class Derived2:virtual public Base{
public:
Derived2():Base("Derived2"){std::cout<<"Constructor->Derived2"<<std::endl;}
Derived2(std::string s):Base(s){std::cout<<"Constructor->Derived2"<<std::endl;}
Derived2(const Derived2& d):Base(d){std::cout<<"Constructor->Derived2"<<std::endl;}
~Derived2(){
std::cout<<"Destructor->Derived2"<<std::endl;
}
};
class MI:public Derived1,public Derived2{
public:
MI():Base("MI"){}
MI(std::string s):Base(s),Derived1(s),Derived2(s){std::cout<<"Constructor->MI"<<std::endl;}
MI(const MI& m):Base(m),Derived1(m),Derived2(m){std::cout<<"Constructor->MI"<<std::endl;}
~MI(){
std::cout<<"Destructor->MI"<<std::endl;
}
};
class Final:public MI,public Class{
public:
Final():Base("Final"){std::cout<<"Constructor->Final"<<std::endl;}
Final(std::string s):Base(s),MI(s){std::cout<<"Constructor->Final"<<std::endl;}
Final(const Final& f):Base(f),MI(f){std::cout<<"Constructor->Final"<<std::endl;}
~Final(){
std::cout<<"Destructor->Final"<<std::endl;
}
};
int main(){
Final f;
}
#endif
运行结果:
第18章 特殊工具和技术
1. 优化内存分配
C++ 的内存分配是一种类型化操作:new为特定类型分配内存,并在新分配的内存中构造该类型的一个对象。new 表达式自动运行合适的构造函数来初始化每个动态分配的类类型对象。
new 基于每个对象分配内存的事实可能会对某些类强加不可接受的运行时开销,这样的类可能需要使用用户级的类类型对象分配能够更快一些。这样的类使用的通用策略是,预先分配用于创建新对象的内存,需要时在预先分配的内存中构造每个新对象。
另外一些类希望按最小尺寸为自己的数据成员分配需要的内存。例如,标准库中的 vector 类预先分配额外内存以保存加入的附加元素,将新元素加入到这个保留容量中。将元素保持在连续内存中的时候,预先分配的元素使 vector 能够高效地加入元素。
在每种情况下(预先分配内存以保存用户级对象或者保存类的内部数据)都需要将内存分配与对象构造分离开。将内存分配与对象构造分离开的明显的理由是,在预先分配的内存中构造对象很浪费,可能会创建从不使用的对象。当实际使用预先分配的对象的时候,被使用的对象必须重新赋以新值。更微妙的是,如果预先分配的内存必须被构造,某些类就不能使用它。例如,考虑 vector,它使用了预先分配策略。如果必须构造预先分配的内存中的对象,就不能有基类型为没有默认构造函数的 vector——vector 没有办法知道怎样构造这些对象。
2. C++中的内存分配
C++ 中,内存分配和对象构造紧密纠缠,就像对象和内存回收一样。使用 new 表达式的时候,分配内存,并在该内存中构造一个对象;使用 delete 表达式的时候,调用析构函数撤销对象,并将对象所用内存返还给系统。
接管内存分配时,必须处理这两个任务。分配原始内存时,必须在该内存中构造对象;在释放该内存之前,必须保证适当地撤销这些对象。
C++ 提供下面两种方法分配和释放未构造的原始内存。
(1).allocator 类,它提供可感知类型的内存分配。这个类支持一个抽象接口,以分配内存并随后使用该内存保存对象。
(2).标准库中的 operator new 和 operator delete,它们分配和释放需要大小的原始的、未类型化的内存。
C++ 还提供不同的方法在原始内存中构造和撤销对象。
(1).allocator 类定义了名为 construct 和 destroy 的成员,其操作正如它们的名字所指出的那样:construct 成员在未构造内存中初始化对象,destroy 成员在对象上运行适当的析构函数。
(2).定位 new 表达式(placement new expression)接受指向未构造内存的指针,并在该空间中初始化一个对象或一个数组。
(3).可以直接调用对象的析构函数来撤销对象。运行析构函数并不释放对象所在的内存。
(4).算法 uninitialized_fill 和 uninitialized_copy 像 fill 和 copy 算法一样执行,除了它们的目的地构造对象而不是给对象赋值之外。
3. allocator类
allocator 类将内存分配和对象构造分开。当 allocator 对象分配内存的时候,它分配适当大小并排列成保存给定类型对象的空间。但是,它分配的内存是未构造的,allocator 的用户必须分别 construct 和 destroy 放置在该内存中的对象。
回忆一下,vector 类将元素保存在连续的存储中。为了获得可接受的性能,vector 预先分配比所需元素更多的元素。每个将元素加到容器中的 vector 成员检查是否有可用空间以容纳另一元素。如果有,该成员在预分配内存中下一可用位置初始化一个对象;如果没有自由元素,就重新分配 vector:vector 获取新的空间,将现在元素复制到空间,增加新元素,并释放旧空间。
vector 所用存储开始是未构造内存,它还没有保存任何对象。将元素复制或增加到这个预分配空间的时候,必须使用 allocator 类的 construct 成员构造元素。
为了说明这些概念,我们将实现 vector 的一小部分。将我们的类命名为 Vector,以区别于标准类 vector:
template <class T> class Vector {
public:
Vector(): elements(0), first_free(0), end(0) { }
void push_back(const T&);
// ...
private:
static std::allocator<T> alloc; // object to get raw memory
void reallocate(); // get more space and copy existing elements
T* elements; // pointer to first element in the array
T* first_free; // pointer to first free element in the array
T* end; // pointer to one past the end of the array
// ...
};
每个 Vector<T> 类型定义一个 allocator<T> 类型的 static 数据成员,以便在给定类型的 Vector 中分配和构造元素。每个 Vector 对象在指定类型的内置数组中保存其元素,并维持该数组的下列三个指针:
-
elements,指向数组的第一个元素。
-
first_free,指向最后一个实际元素之后的那个元素。
-
end,指向数组本身之后的那个元素。

可以使用这些指针来确定 Vector 的大小和容量:
-
Vector 的 size(实际使用的元素的数目)等于 first_free-elements。
-
Vector 的 capacity(在必须重新分配 Vector 之前,可以定义的元素的总数)等于end-elements。
-
自由空间(在需要重新分配之前,可以增加的元素的数目)是 end-first_free。
push_back 成员使用这些指针将新元素加到 Vector 末尾:
void Vector<T>::push_back(const T& t)
{
// are we out of space?
if (first_free == end)
reallocate(); // gets more space and copies existing elements to it
alloc.construct(first_free, t);
++first_free;
}
push_back 函数首先确定是否有可用空间,如果没有,就调用 reallocate 函数,reallocate 分配新空间并复制现存元素,将指针重置为指向新分配的空间。
一旦 push_back 函数知道还有空间容纳新元素,它就请求 allocator 对象构造一个新的最后元素。construct 函数使用类型 T 的复制构造函数将 t 值复制到由 first_free 指出的元素,然后,将 first_free 加 1 以指出又有一个元素在用。
reallocate 函数所做的工作最多:
{
// compute size of current array and allocate space for twice as many elements
std::ptrdiff_t size = first_free - elements;
std::ptrdiff_t newcapacity = 2 * max(size, 1);
// allocate space to hold newcapacity number of elements of type T
T* newelements = alloc.allocate(newcapacity);
// construct copies of the existing elements in the new space
uninitialized_copy(elements, first_free, newelements);
// destroy the old elements in reverse order
for (T *p = first_free; p != elements; /* empty */ )
alloc.destroy(--p);
// deallocate cannot be called on a 0 pointer
if (elements)
// return the memory that held the elements
alloc.deallocate(elements, end - elements);
// make our data structure point to the new elements
elements = newelements;
first_free = elements + size;
end = elements + newcapacity;
}
我们使用一个简单但效果惊人的策略:每次重新分配时分配两倍内存。函数首先计算当前在用的元素数目,将该数目翻倍,并请求 allocator 对象来获得所需数量的空间。如果 Vector 为空,就分配两个元素。
如果 Vector 保存 int 值,allocate 函数调用为 newcapacity 数目的 int 值分配空间;如果 Vector 保存 string 对象,它就为给定数目的 string 对象分配空间。
uninitialized_copy 调用使用标准 copy 算法的特殊版本。这个版本希望目的地是原始的未构造内存,它在目的地复制构造每个元素,而不是将输入范围的元素赋值给目的地,使用 T 的复制构造函数从输入范围将每个元素复制到目的地。
for 循环对旧数组中每个对象调用 allocator 的 destroy 成员它按逆序撤销元素,从数组中最后一个元素开始,以第一个元素结束。destroy 函数运行 T 类型的析构函数来释放旧元素所用的任何资源。
一旦复制和撤销了元素,就释放原来数组所用的空间。在调用 deallocate 之前,必须检查 elements 是否实际指向一个数组。
最后,必须重置指针以指向新分配并初始化的数组。将 first_free 和 end 指针分别置为指向最后构造的元素之后的单元以及所分配空间末尾的下一单元。
完整的Vector的代码如下:
View Code
#include <memory>
using std::cout; using std::endl;
template <class T> class Vector {
public:
Vector(): elements(0), first_free(0), end(0) { }
void push_back(const T&);
size_t size() const { return first_free - elements; }
size_t capacity() const { return end - elements; }
// . . .
T& operator[](size_t n) { return elements[n]; }
const T& operator[](size_t n) const { return elements[n]; }
private:
static std::allocator<T> alloc; // member to handle allocation
void reallocate(); // get more space and copy existing elements
T* elements; // pointer to first element in the array
T* first_free; // pointer to first free element in the array
T* end; // pointer to one past the end of the array
// . . .
};
#include <algorithm>
using std::allocator;
template <class T> allocator<T> Vector<T>::alloc;
using std::max;
using std::uninitialized_copy;
template <class T> void Vector<T>::reallocate()
{
std::ptrdiff_t size = first_free - elements;
std::ptrdiff_t newcapacity = 2 * max(size, 1);
T* newelements = alloc.allocate(newcapacity);
uninitialized_copy(elements, first_free, newelements);
for (T *p = first_free; p != elements; /*empty*/ )
alloc.destroy(--p);
if (elements)
alloc.deallocate(elements, end - elements);
elements = newelements;
first_free = elements + size;
end = elements + newcapacity;
}
template <class T> void Vector<T>::push_back(const T& t)
{
if (first_free == end)
reallocate(); // gets more space and copies existing elements to it
alloc.construct(first_free, t);
++first_free;
}
int main()
{
Vector<int> vi;
for (int i = 0; i != 10; ++i) {
vi.push_back(i);
cout << vi[i] << endl;
}
for (int i = 0; i != 10; ++i)
cout << vi[i] << endl;
return 0;
}
4. new和delete表达式的工作原理:
当使用 new 表达式
string * sp = new string("initialized");
的时候,实际上发生三个步骤。首先,该表达式调用名为 operator new 的标准库函数,分配足够大的原始的未类型化的内存,以保存指定类型的一个对象;接下来,运行该类型的一个构造函数,用指定初始化式构造对象;最后,返回指向新分配并构造的对象的指针。
当使用 delete 表达式
删除动态分配对象的时候,发生两个步骤。首先,对 sp 指向的对象运行适当的析构函数;然后,通过调用名为 operator delete 的标准库函数释放该对象所用内存。
5. new表达式与operator new函数
标准库函数 operator new 和 operator delete 的命名容易让人误解。与其他 operator 函数(如 operator=)不同,这些函数没有重载 new 或 delete 表达式,实际上,我们不能重定义 new 和 delete 表达式的行为。
通过调用 operator new 函数执行 new 表达式获得内存,并接着在该内存中构造一个对象,通过撤销一个对象执行 delete 表达式,并接着调用 operator delete 函数,以释放该对象使用的内存。
6. operator new 函数和 operator delete 函数
(1) operator new 和 operator delete 接口如下:
operator new 和 operator delete 函数有两个重载版本,每个版本支持相关的 new 表达式和 delete 表达式:
void *operator new[](size_t); // allocate an array
void *operator delete(void*); // free an object
void *operator delete[](void*); // free an array
(2)使用分配操作符函数
虽然 operator new 和 operator delete 函数的设计意图是供 new 表达式使用,但它们通常是标准库中的可用函数。可以使用它们获得未构造内存,它们有点类似 allocate 类的 allocator 和 deallocate 成员。例如,代替使用 allocator 对象,可以在 Vector 类中使用 operator new 和 operator delete 函数。在分配新空间时我们曾编写
T* newelements = alloc.allocate(newcapacity);
这可以重新编写为
T* newelements = static_cast<T*>(operator new[](newcapacity * sizeof(T)));
类似地,在重新分配由 Vector 成员 elements 指向的旧空间的时候,我们曾经编写
alloc.deallocate(elements, end - elements);
这可以重新编写为
operator delete[](elements);
这些函数的表现与 allocate 类的 allocator 和 deallocate 成员类似。但是,它们在一个重要方面有不同:它们在 void* 指针而不是类型化的指针上进行操作。
一般而言,使用 allocator 比直接使用 operator new 和 operator delete 函数更为类型安全。
allocate 成员分配类型化的内存,所以使用它的程序可以不必计算以字节为单位的所需内存量,它们也可以避免对 operator new 的返回值进行强制类型转换。类似地,deallocate 释放特定类型的内存,也不必转换为 void*。
7. 定位new表达式
标准库函数 operator new 和 operator delete 是 allocator 的 allocate 和 deallocate 成员的低级版本,它们都分配但不初始化内存。
allocator 的成员 construct 和 destroy 也有两个低级选择,这些成员在由 allocator 对象分配的空间中初始化和撤销对象。
类似于 construct 成员,有第三种 new 表达式,称为定位 new。定位 new 表达式在已分配的原始内存中初始化一个对象,它与 new 的其他版本的不同之处在于,它不分配内存。相反,它接受指向已分配但未构造内存的指针,并在该内存中初始化一个对象。实际上,定位 new 表达式使我们能够在特定的、预分配的内存地址构造一个对象。
定位 new 表达式的形式是:
new (place_address) type
new (place_address) type (initializer-list)
其中 place_address 必须是一个指针,而 initializer-list 提供了(可能为空的)初始化列表,以便在构造新分配的对象时使用。
可以使用定位 new 表达式代替 Vector 实现中的 construct 调用。原来的代码
alloc.construct (first_free, t);
可以用等价的定位 new 表达式代替
new (first_free) T(t);
定位 new 表达式比 allocator 类的 construct 成员更灵活。定位 new 表达式初始化一个对象的时候,它可以使用任何构造函数,并直接建立对象。construct 函数总是使用复制构造函数。
例如,可以用下面两种方式之一,从一对迭代器初始化一个已分配但未构造的 string 对象:
string *sp = alloc.allocate(2); // allocate space to hold 2 strings
// two ways to construct a string from a pair of iterators
new (sp) string(b, e); // construct directly in place
alloc.construct(sp + 1, string(b, e)); // build and copy a temporary
定位 new 表达式使用了接受一对迭代器的 string 构造函数,在 sp 指向的空间直接构造 string 对象。当调用 construct 函数的时候,必须首先从迭代器构造一个 string 对象,以获得传递给 construct 的 string 对象,然后,该函数使用 string 的复制构造函数,将那个未命名的临时 string 对象复制到 sp 指向的对象中。
通常,这些区别是不相干的:对值型类而言,在适当的位置直接构造对象与构造临时对象并进行复制之间没有可观察到的区别,而且性能差别基本没有意义。但对某些类而言,使用复制构造函数是不可能的(因为复制构造函数是私有的),或者是应该避免的,在这种情况下,也许有必要使用定位 new 表达式。

8. 显示析构函数的调用
正如定位 new 表达式是使用 allocate 类的 construct 成员的低级选择,我们可以使用析构函数的显式调用作为调用 destroy 函数的低级选择。
在使用 allocator 对象的 Vector 版本中,通过调用 destroy 函数清除每个元素:
for (T *p = first_free; p != elements; /* empty */ )
alloc.destroy(--p);
对于使用定位 new 表达式构造对象的程序,显式调用析构函数:
p->~T(); // call the destructor
在这里直接调用析构函数。箭头操作符对迭代器 p 解引用以获得 p 所指的对象,然后,调用析构函数,析构函数以类名前加 ~ 来命名。
显式调用析构函数的效果是适当地清除对象本身。但是,并没有释放对象所占的内存,如果需要,可以重用该内存空间。
9. 运行时类型识别
通过运行时类型识别(RTTI),程序能够使用基类的指针或引用来检索这些指针或引用所指对象的实际派生类型。
通过下面两个操作符提供 RTTI:
(1) typeid 操作符,返回指针或引用所指对象的实际类型。
(2) dynamic_cast 操作符,将基类类型的指针或引用安全地转换为派生类型的指针或引用。
这些操作符只为带有一个或多个虚函数的类返回动态类型信息,对于其他类型,返回静态(即编译时)类型的信息。
对于带虚函数的类,在运行时执行 RTTI 操作符,但对于其他类型,在编译时计算 RTTI 操作符。
当具有基类的引用或指针,但需要执行不是基类组成部分的派生类操作的时候,需要动态的强制类型转换。通常,从基类指针获得派生类行为最好的方法是通过虚函数。当使用虚函数的时候,编译器自动根据对象的实际类型选择正确的函数。
但是,在某些情况下,不可能使用虚函数。在这些情况下,RTTI 提供了可选的机制。然而,这种机制比使用虚函数更容易出错:程序员必须知道应该将对象强制转换为哪种类型,并且必须检查转换是否成功执行了。
使用动态强制类型转换要小心。只要有可能,定义和使用虚函数比直接接管类型管理好得多。
10. dynamic_cast操作符
可以使用 dynamic_cast 操作符将基类类型对象的引用或指针转换为同一继承层次中其他类型的引用或指针。与 dynamic_cast 一起使用的指针必须是有效的——它必须为 0 或者指向一个对象。
与其他强制类型转换不同,dynamic_cast 涉及运行时类型检查。如果绑定到引用或指针的对象不是目标类型的对象,则 dynamic_cast 失败。如果转换到指针类型的 dynamic_cast 失败,则 dynamic_cast 的结果是 0 值;如果转换到引用类型的 dynamic_cast 失败,则抛出一个 bad_cast 类型的异常。
因此,dynamic_cast 操作符一次执行两个操作。它首先验证被请求的转换是否有效,只有转换有效,操作符才实际进行转换。一般而言,引用或指针所绑定的对象的类型在编译时是未知的,基类的指针可以赋值为指向派生类对象,同样,基类的引用也可以用派生类对象初始化,因此,dynamic_cast 操作符执行的验证必须在运行时进行。
作为例子,假定 Base 是至少带一个虚函数的类,并且 Derived 类派生于 Base 类。如果有一个名为 basePtr 的指向 Base 的指针,就可以像这样在运行时将它强制转换为指向 Derived 的指针:
{
// use the Derived object to which derivedPtr points
} else { // BasePtr points at a Base object
// use the Base object to which basePtr points
}
在前面例子中,使用了 dynamic_cast 将基类指针转换为派生类指针,也可以使用 dynamic_cast 将基类引用转换为派生类引用,这种 dynamic_cast 操作的形式如下:
dynamic_cast< Type& >(val)
这里,Type 是转换的目标类型,而 val 是基类类型的对象。
只有当 val 实际引用一个 Type 类型对象,或者 val 是一个 Type 派生类型的对象的时候,dynamic_cast 操作才将操作数 val 转换为想要的 Type& 类型。
因为不存在空引用,所以不可能对引用使用用于指针强制类型转换的检查策略,相反,当转换失败的时候,它抛出一个 std::bad_cast 异常,该异常在库头文件 typeinfo 中定义。
可以重写前面的例子如下,以便使用引用:
{
try {
const Derived &d = dynamic_cast<const Derived&>(b);
// use the Derived object to which b referred
} catch (bad_cast) {
// handle the fact that the cast failed
}
}
11. 使用dynamic_cast代替虚函数

12. typeid操作符
如果表达式的类型是类类型且该类包含一个或多个虚函数,则表达式的动态类型可能不同于它的静态编译时类型。例如,如果表达式对基类指针解引用,则该表达式的静态编译时类型是基类类型;但是,如果指针实际指向派生类对象,则 typeid 操作符将说表达式的类型是派生类型。
typeid 操作符可以与任何类型的表达式一起使用。内置类型的表达式以及常量都可以用作 typeid 操作符的操作数。如果操作数不是类类型或者是没有虚函数的类,则 typeid 操作符指出操作数的静态类型;如果操作数是定义了至少一个虚函数的类类型,则在运行时计算类型。
typeid 操作符的结果是名为 type_info 的标准库类型的对象引用,第 18.2.4 节将更详细地讨论这个类型。要使用 type_info 类,必须包含库头文件 typeinfo。
typeid 最常见的用途是比较两个表达式的类型,或者将表达式的类型与特定类型相比较:
Derived *dp;
// compare type at run time of two objects
if (typeid(*bp) == typeid(*dp)) {
// bp and dp point to objects of the same type
}
// test whether run time type is a specific type
if (typeid(*bp) == typeid(Derived)) {
// bp actually points to a Derived
}
13. type_info类

type_info 类随编译器而变。一些编译器提供附加的成员函数,那些函数提供关于程序中所用类型的附加信息。你应该查阅编译器的参考手册来理解所提供的确切的 type_info 支持。
#include <typeinfo>
#include <string>
using std::string;
using std::cout; using std::endl;
struct Base {
virtual ~Base() { }
};
struct Derived : Base { };
int main()
{
int iobj;
cout << typeid(iobj).name() << endl
<< typeid(8.16).name() << endl
<< typeid(std::string).name() << endl
<< typeid(Base).name() << endl
<< typeid(Derived).name() << endl;
return 0;
}

14. 类成员指针
可以通过使用称为成员指针的特殊各类的指针做到这一点。成员指针包含类的类型以及成员的类型。这一事实影响着怎样定义成员指针,怎样将成员指针绑定到函数或数据成员,以及怎样使用它们。
成员指针只应用于类的非 static 成员。static 类成员不是任何对象的组成部分,所以不需要特殊语法来指向 static 成员,static 成员指针是普通指针。
成员函数的指针必须在三个方面与它所指函数的类型相匹配:
(1)函数形参的类型和数目,包括成员是否为 const。
(2)返回类型。
(3)所属类的类型。
通过指定函数返回类型、形参表和类来定义成员函数的指针。
普通指针与成员指针

15. 类成员指针的使用
类似于成员访问操作符 . 和 ->,.* 和 -> 是两个新的操作符,它们使我们能够将成员指针绑定到实际对象。这两个操作符的左操作数必须是类类型的对象或类类型的指针,右操作数是该类型的成员指针。
(1) 成员指针解引用操作符(.*)从对象或引用获取成员。
(2) 成员指针箭头操作符(->*)通过对象的指针获取成员。



16. 联合Union
联合是一种特殊的类。一个 union 对象可以有多个数据成员,但在任何时刻,只有一个成员可以有值。当将一个值赋给 union 对象的一个成员的时候,其他所有都变为未定义的。
(1)没有静态数据成员、引用成员或类数据成员
某些(但不是全部)类特征同样适用于 union。例如,像任何类一样,union 可以指定保护标记使成员成为公用的、私有的或受保护的。默认情况下,union 表现得像 struct:除非另外指定,否则 union 的成员都为 public 成员。
union 也可以定义成员函数,包括构造函数和析构函数。但是,union 不能作为基类使用,所以成员函数不能为虚数。
union 不能具有静态数据成员或引用成员,而且,union 不能具有定义了构造函数、析构函数或赋值操作符的类类型的成员:
Screen s; // error: has constructor
static int is; // error: static member
int &rfi; // error: reference member
Screen *ps; // ok: ordinary built-in pointer type
};
这个限制包括了具有带构造函数、析构函数或赋值操作符的成员的类。
(2)嵌套联合,匿名联合
union 最经常用作嵌套类型,其中判别式是外围类的一个成员:
public:
// indicates which kind of value is in val
enum TokenKind {INT, CHAR, DBL};
TokenKind tok;
union { // unnamed union
char cval;
int ival;
double dval;
} val; // member val is a union of the 3 listed types
};
这个类中,用枚举对象 tok 指出 val 成员中存储了哪种值,val 成员是一个(未命名的)union,它保存 char、int 或 double 值。
经常使用 switch 语句(第 6.6 节)测试判别式,然后根据 union 中当前存储的值进行处理:
switch (token.tok) {
case Token::INT:
token.val.ival = 42; break;
case Token::CHAR:
token.val.cval = 'a'; break;
case Token::DBL:
token.val.dval = 3.14; break;
}
不用于定义对象的未命名 union 称为匿名联合。匿名 union 的成员的名字出现在外围作用域中。例如,使用匿名 union 重写的 Token 类如下:
public:
// indicates which kind of token value is in val
enum TokenKind {INT, CHAR, DBL};
TokenKind tok;
union { // anonymous union
char cval;
int ival;
double dval;
};
};
因为匿名 union 不提供访问其成员的途径,所以将成员作为定义匿名 union 的作用域的一部分直接访问。重写前面的 switch 以便使用类的匿名 union 版本,如下:
switch (token.tok) {
case Token::INT:
token.ival = 42; break;
case Token::CHAR:
token.cval = 'a'; break;
case Token::DBL:
token.dval = 3.14; break;
}
17. 固有的不可移植的特征
(1)位域
可以声明一种特殊的类数据成员,称为位域,来保存特定的位数。当程序需要将二进制数据传递给另一程序或硬件设备的时候,通常使用位域。
位域必须是整型数据类型,可以是 signed 或 unsigned。通过在成员名后面接一个冒号以及指定位数的常量表达式,指出成员是一个位域:
class File {
Bit mode: 2;
Bit modified: 1;
Bit prot_owner: 3;
Bit prot_group: 3;
Bit prot_world: 3;
// ...
};
(2)volatile限定符
直接处理硬件的程序常具有这样的数据成员,它们的值由程序本身直接控制之外的过程所控制。例如,程序可以包含由系统时钟更新的变量。当可以用编译器的控制或检测之外的方式改变对象值的时候,应该将对象声明为 volatile。关键字 volatile 是给编译器的指示,指出对这样的对象不应该执行优化。
用与 const 限定符相同的方式使用 volatile 限定符。volatile 限定符是一个对类型的附加修饰符:
volatile Task *curr_task;
volatile int ixa[max_size];
volatile Screen bitmap_buf;
第 4.2.5 节介绍了 const 限定符与指针的相互作用,volatile 限定符与指针之间也存在同样的相互作用。可以声明 volatile 指针、指向 volatile 对象的指针,以及指向 volatile 对象的 volatile 指针:
int *volatile vip; // vip is a volatile pointer to int
volatile int *ivp; // ivp is a pointer to volatile int
// vivp is a volatile pointer to volatile int
volatile int *volatile vivp;
int *ip = &v; // error: must use pointer to volatile
*ivp = &v; // ok: ivp is pointer to volatile
vivp = &v; // ok: vivp is volatile pointer to volatile
像用 const 一样,只能将 volatile 对象的地址赋给指向 volatile 的指针,或者将指向 volatile 类型的指针复制给指向 volatile 的指针。只有当引用为 volatile 时,我们才可以使用 volatile 对象对引用进行初始化。
对待 const 和 volatile 的一个重要区别是,不能使用合成的复制和赋值操作符从 volatile 对象进行初始化或赋值。合成的复制控制成员接受 const 形参,这些形参是对类类型的 const 引用,但是,不能将 volatile 对象传递给普通引用或 const 引用。
如果类希望允许复制 volatile 对象,或者,类希望允许从 volatile 操作数或对 volatile 操作数进行赋值,它必须定义自己的复制构造函数和/或赋值操作符版本:
public:
Foo(const volatile Foo&); // copy from a volatile object
// assign from a volatile object to a non volatile objet
Foo& operator=(volatile const Foo&);
// assign from a volatile object to a volatile object
Foo& operator=(volatile const Foo&) volatile;
// remainder of class Foo
};
通过将复制控制成员的形参定义为 const volatile 引用,我们可以从任何各类的 Foo 对象进行复制或赋值:普通 Foo 对象、const Foo 对象、volatile Foo 对象或 const volatile Foo 对象。
虽然可以定义复制控制成员来处理 volatile 对象,但更深入的问题是复制 volatile 对象是否有意义,对该问题的回答与任意特定程序中使用 volatile 的原因密切相关。
(3) 链接指示:extern "c"
链接指示与函数重载之间的相互作用依赖于目标语言。如果语言支持重载函数,则为该语言实现链接指示的编译器很可能也支持 C++ 的这些函数的重载。
C++ 保证支持的唯一语言是 C。C 语言不支持函数重载,所以,不应该对下面的情况感到惊讶:在一组重载函数中只能为一个 C 函数指定链接指示。用带给定名字的 C 链接声明多于一个函数是错误的:
extern "C" void print(const char*);
extern "C" void print(int);
在 C++ 程序中,重载 C 函数很常见,但是,重载集合中的其他函数必须都是 C++ 函数:
class BigNum { /* ... */ };
// the C function can be called from C and C++ programs
// the C++ functions overload that function and are callable from C++
extern "C" double calc(double);
extern SmallInt calc(const SmallInt&);
extern BigNum calc(const BigNum&);
可以从 C 程序和 C++ 程序调用 calc 的 C 版本。其余函数是带类型形参的 C++ 函数,只能从 C++ 程序调用。声明的次序不重要。
编写函数所用的语言是函数类型的一部分。为了声明用其他程序设计语言编写的函数的指针,必须使用链接指示:
extern "C" void (*pf)(int);
使用 pf 调用函数的时候,假定该调用是一个 C 函数调用而编译该函数。
C 函数的指针与 C++ 函数的指针具有不同的类型,不能将 C 函数的指针初始化或赋值为 C++ 函数的指针(反之亦然)。
存在这种不匹配的时候,会给出编译时错误:
extern "C" void (*pf2)(int); // points to a C function
pf1 = pf2; // error: pf1 and pf2 have different types
一些 C++ 编译器可以接受前面的赋值作为语言扩展,尽管严格说来它是非法的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号