
JM8.6中的关于写比特流的问题
JM8.6中的关于写比特流的问题

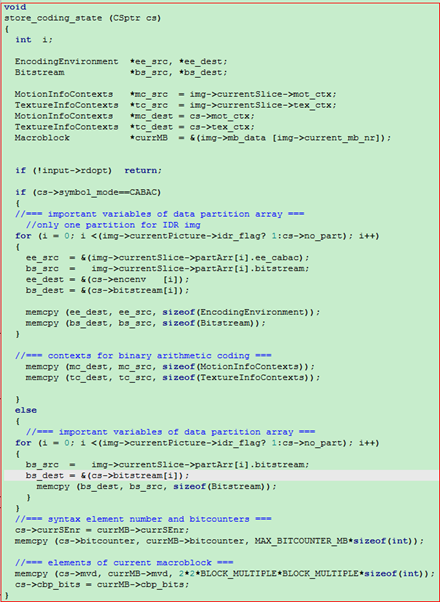

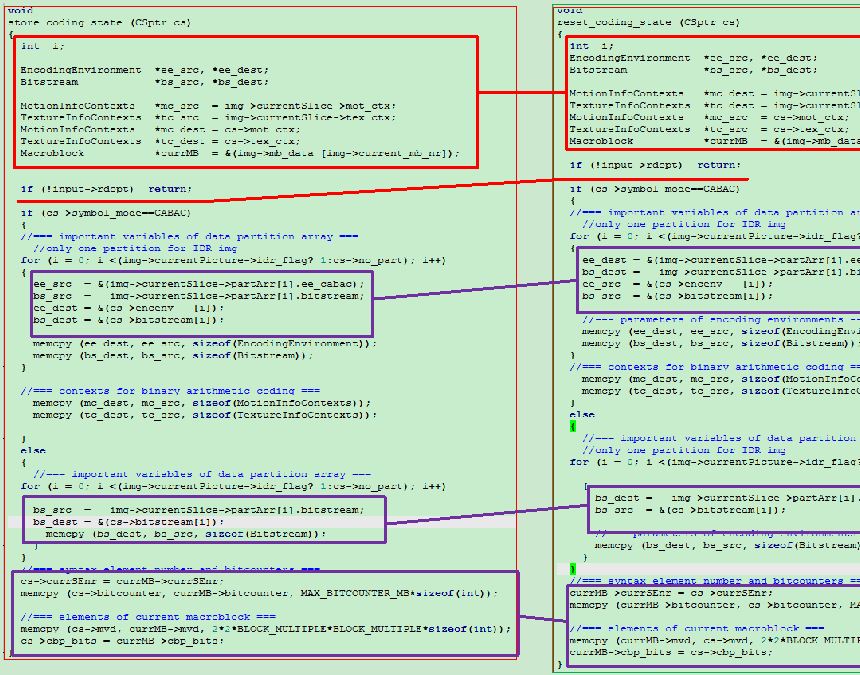
通过上面的对比, 我们可以发现store_coding_state函数和reset_coding_state函数基本上完全一致, 对于cs_mb, store_coding_state函数将img->currentslice变量中的一些需要保存的量存储在cs_mb中, 然后等到进行编码完成后, 要恢复现场, 利用reset_coding_state函数将cs_mb中保存的相关量恢复到变量img->currentslice中, 便于下面的利用.
从上面的截图我们也可以看出, 对于非CABAC编码的状况, 主要是保存的bitstream

而对于CABAC编码的状况, 还需要保存一些相关的上下文信息.
所以, 我们需要看看bitstream结构中所包含的一些量

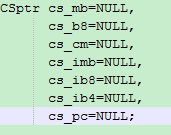



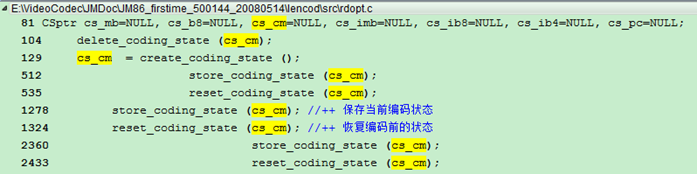




从上面的截图, 我们可以看到cs_mb和cs_b8应该分别是一个宏块和一个8x8块对应的一些bitstream信息, cs_cm更像一个中间量, 其他的量都没有使用过. 一般cs_cm和cs_mb和cs_b8这些存储当前编码状态的变量, 使用的主要原因就是在RDO方式下需要真正的进行一遍编码, 所以需要保存一下当前状态, 等代价计算完毕后,需要恢复现场, 再计算其他模式的代价.
If (valid[P8x8])
{
Cost8x8 = 0;
//===== store coding state of macroblock =====
Store_coding_state (cs_mb); //第一次出现
Store_coding_state
假设现在是第二帧, 现在用来存储比特流的结构体里数据情况如下
Img->currentslice->partarr[0].bitstream->byte_pos 0x00000003
Img->currentslice->partarr[0].bitstream->bits_to_go 0x00000007
在这时候执行store_coding_state (cs_mb),把
Img->currentslice->partarr[0].bitstream的内容赋给了cs_mb->bitstream[0]
接着进入for (cbp8x8=cbp_blk8x8=cnt_nonz_8x8=0, block=0; block<4; block++)循环 1
进入for (min_cost8x8=(1<<20), min_rdcost=1e30, index=(bframe?0:1); index<5; index++)循环 2
在循环2里
执行函数rdcost_for_8x8blocks之前,
执行store_coding_state (cs_cm) 把img->currentslice->partarr[0].bitstream的内容赋给了cs_cm->bitstream[0]
执行rdcost_for_8x8blocks函数之后 //这个函数包含了编码与写比特到img->currentslice->partarr[0].bitstream中
Img->currentslice->partarr[0].bitstream->byte_pos 0x000000012
Img->currentslice->partarr[0].bitstream->bits_to_go 0x00000008

若本模式的率失真更小, 则store_coding_state (cs_b8), 把img->currentslice->partarr[0].bitstream的内容赋给了cs_b8->bitstream[0]
然后reset_coding_state (cs_cm); 把cs_cm->bitstream[0]内容赋给img->currentslice->partarr[0].bitstream 即保证每次比较8*8块的率失真时,将比特流情况设置成
Img->currentslice->partarr[0].bitstream->byte_pos 0x00000003
Img->currentslice->partarr[0].bitstream->bits_to_go 0x00000007
(可以这样看, 在进行rdcost_for_8x8blocks之前, 要保存一下当前的img->currentslice->partarr[0].bitstream到cs_cm中去, 因为在这个函数中有对img->currentslice->partarr[0].bitstream的修改, 所以从rdcost_for_8x8blocks函数返回后, 由于需要计算下一个P8x8模式的rdcost, 所以要恢复成之前的状态, 这样保证了对每种P8x8模式进行计算rdcost之前的img->currentslice->partarr[0].bitstream状态是一样的. 同时, 如果发现当前模式的rdcost比较小, 则需要保存一下bitstream, 保存在了cs_b8中)
由此可见循环2完成后, 本8*8块的最佳比特流将存在cs_b8->bitstream[0]中(其实还包括slice头部比特流和其他的前面的最佳8*8块比特流)
循环2完成后,执行reset_coding_state (cs_b8);

将cs_b8->bitstream[0]内容赋给img->currentslice->partarr[0].bitstream, 保证在把第下个8*8 的最佳比特流放在前一个8*8的最佳比特流之后
如此下来,1和2都循环完之后,一个宏块的最佳编码比特流就存到了img->currentslice->partarr[0].bitstream中
接下来在for (ctr16x16=0, index=0; index<7; index++)循环中
在这个循环之前,执行reset_coding_state (cs_mb); 把cs_mb->bitstream[0]的内容
赋给了img->currentslice->partarr[0].bitstream
此时
Img->currentslice->partarr[0].bitstream->byte_pos 0x00000003
Img->currentslice->partarr[0].bitstream->bits_to_go 0x00000007
即回到未写宏块比特流之前
(for (ctr16x16=0, index=0; index<7; index++)的循环里比较的是0, 1, 2, 3, P8x8, I16MB, I4MB这几种模式
而P8*8的最佳rdcost在for (min_cost8x8=(1<<20), min_rdcost=1e30, index=(bframe?0:1); index<5; index++)里已经比较得到 所以for (ctr16x16=0, index=0; index<7; index++)它实际上是比较Skip,16*16,16*8,8*16,8*8,8*4,4*8,4*4,I4MB,I16MB这些模式的rdcost从而选择出有最小rdcost的模式)
执行if (rdcost_for_macroblocks (lambda_mode, mode, &min_rdcost))
在rdcost_for_macroblocks (lambda_mode, mode, &min_rdcost)里对Skip,16*16,16*8,8*16模式编码(每次循环对不同的模式编码)
编码完成之后, 写比特流之前store_coding_state (cs_cm); 把
Img->currentslice->partarr[0].bitstream的内容赋给了cs_cm->bitstream[0] (a)
之后writembheader (1); writemotioninfo2nal ();writecbpandlumacoeff ();writechromacoeff ();此时
Img->currentslice->partarr[0].bitstream->byte_pos 0x000000037
Img->currentslice->partarr[0].bitstream->bits_to_go 0x00000003
即编完一个宏块模式后的比特流情况
然后reset_coding_state (cs_cm);
把cs_cm->bitstream[0]内容赋给img->currentslice->partarr[0].bitstream (b)
由上可看出,实际上(a)和(b)操作时相反的,最后img->currentslice->partarr[0].bitstream里面实际上只存有slice头部信息
所有store_coding_state和reset_coding_state操作都是为比较率失真而设置的,
在encode_one_macroblock 结束后,img->currentslice->partarr[0].bitstream里实际上只有slice头部信息,但在这个函数里得到了最佳的宏块编码模式,
将宏块编码信息写入img->currentslice->partarr[0].bitstream的是在write_one_macroblock函数
里
Writembheader (0);
// Do nothing more if copy and inter mode
If ((IS_INTERMV (currmb) || IS_INTRA (currmb) ) ||
((img->type==B_SLICE) && currmb->cbp != 0) )
{
Writemotioninfo2nal ();
Writecbpandlumacoeff ();
Writechromacoeff ();
}
实际上是用到的img-> mv[block_x][block_y][list_idx][refindex][mv_mode][X/Y]
在求每种分割模式的最佳运动矢量时,将他们保存到了best8x8fwref[mode][k]中,k=0~3 即best8x8fwref[mode][k]保存了每种模式的最佳参考帧
在对各种模式进行比较时
For (ctr16x16=0, index=0; index<7; index++)
If (valid[mode])
{
Setmodesandrefframeforblocks (mode);
Setmodesandrefframeforblocks中
Enc_picture->ref_idx[LIST_0][img->block_x+i][img->block_y+j] = (IS_FW ? Best8x8fwref[mode][k] : -1);
将本模式的最佳参考帧赋值给enc_picture->ref_idx
在rdcost_for_macroblocks的lumaresidualcoding ()中,将会用到enc_picture->ref_idx求出预测值 [具体来说是利用enc_picture->ref_idx给出的参考帧,可以得到预测值]
在store_macroblock_parameters (mode);中将率失真小的那个模式的最佳参考帧存到frefframe[j][i]中
而后有一个函数set_stored_macroblock_parameters ()
有enc_picture->ref_idx[LIST_0][img->block_x+i][img->block_y+j] = frefframe[j][i];
也就是说最终的最佳模式的最佳参考帧就存到了enc_picture->ref_idx中
Enc_picture->mv[LIST_0][img->block_x+i][img->block_y+j][0] =
Img->all_mv[i][j][LIST_0][frefframe[j][i]][currmb->b8mode[i/2+(j/2)*2]][0]; enc_picture->mv[LIST_0][img->block_x+i][img->block_y+j][1] =
Img->all_mv[i][j][LIST_0][frefframe[j][i]][currmb->b8mode[i/2+(j/2)*2]][1];
最佳的运动矢量也存到了enc_picture->mv中
在write_one_macroblock()中每8x8块的最佳模式是由currmb->b8mode[i]参数来传递的[具体说是函数writemotioninfo2nal()中调用的writereferenceframe的参数],这个参数的值是在void encode_one_macroblock ()中的 set_stored_macroblock_parameters函数中的
For (i=0; i<4; i++)
{
Currmb->b8mode[i] = b8mode[i];求得的,
而b8mode[i]是在
If (rdcost_for_macroblocks (lambda_mode, mode, &min_rdcost))
{
Store_macroblock_parameters (mode);
中记录的那个具有最小的率失真的模式
Distortion的计算是综合了色度和亮度的distortion, 色度部分的计算也是在rdcost_for_macroblocks函数和rdcost_for_8x8blocks函数中的,
但JM8.5中得到色度分量的分像素运动矢量时好像有点问题,在 onecomponentchromaprediction4x4函数中!!
色度分量的运动矢量不需要搜索判决, 是根据亮度分量的运动矢量乘以2得到的(JM85中好像没乘2?)
色度分量的最佳模式是对应亮度分量的最佳模式除以2。 如亮度最佳模式是8*16,则色度最佳模式是4*8。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号