关于“编码”的方方面面
背景:之前做 Scrapy 爬虫,遇到一些编码的问题,导致自己损耗了一些不必要的时间,还是基础知识不扎实呀,所以专门来整理整理,遂成此篇。
一、概念
这里先厘清一些概念,方便接下来的阐述。
字节 byte:是计算机存储数据的存储单元,是一个8位的二进制数,所以最多只能表示256个数字(0-255)
字符 character:是人们常用的一些记号,比如”1”, “汉”, “お”,”℃”等等
编码 Encoding:从字符到0、1二进制
解码 Decoding:从0、1二进制到字符
码的单位:
1 bit(b) 比特 = 1个二进制位(0 或 1)
1 byte(B) 字节 = 8 b
1 KB 千字节 = 1024 B
1 MB 兆字节 = 1024 KB
1 GB 吉字节 = 1024 MB
1 TB 太字节 = 1024 GB
编码后存储:
计算机存储数据肯定都是以二进制的方式来存储,但从方便人们阅读的角度上还是分为
-
文本文件- 如 .txt -
二进制文件- 如 .png
所以文本文件和二进制文件在存储上是没有区别的,都是二进制。
二、编码方式
编码方式涉及到两个概念:
-
字符集(Charset):字符的集合,不同字符集包含的字符数不同。 -
字符编码(Character Encoding):字符集中字符的实际编码方式。 -
一个字符集可能本身包含了字符编码,可能对应有多种字符编码。
如下面即将介绍的,ASCII,本身即是字符集又是字符编码;CB2312,只是字符集,仅有一种字符编码叫EUC-CN;而 Unicode 作为字符集,却对应了更多的字符编码方式,即 UTF-8、UTF-16、UTF-32。
1、ASCII
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是第一个 字符集/字符编码标准。
包括:可显示字符(英文大小写字符、阿拉伯数字和西文符号) + 控制字符(回车键、退格、换行键等)
举例:A = 0x41(一个字节)
2、Latin-1
Latin-1 是 ISO-8859-1 的别名。
上面介绍了美国的 ASCII,但是在欧洲,例如法语,字母上方有注音符号,它就无法用 ASCII 码表示,于是欧洲人在 ASCII 的基础上搞了 Latin-1。
相信 99% 的人第一次知道 Latin1 都是在使用 Mysq 数据库的时候接触到的。Latin1 是 Mysql 数据库表的默认编码方式,原因之一是 Mysql 最开始是某瑞典公司开发的。
3、GBxxxx
正如欧洲人拓展了 ASCII 来适应欧洲各个国家的文字,中国也一样。
汉字数量庞大,多达10万左右。(日常所使用的汉字只有几千)
简体中文常见的编码方式是 GB2312(中国国家标准简体中文字符集),全称《信息交换用汉字编码字符集·基本集》,由中国国家标准总局发布,1981年5月1日实施。
提出了全角/半角符号的概念。
对于人名、古汉语等方面出现的罕用字,GB2312 不能处理,这导致了后来 GBK 及 GB18030 汉字字符集的出现:
GBK自身并非国家标准,只是曾由国家技术监督局标准化司、电子工业部科技与质量监督司公布为"技术规范指导性文件"。
加入对繁体字的支持。
GB18030,全称:国家标准 GB18030-2005《信息技术中文编码字符集》,是中华人民共和国现时最新的内码字集
支持中国少数民族的文字。甚至还包括中文、日文、朝鲜语。
下面是几种编码方式的关系(可以看出都是新出的兼容旧出的):
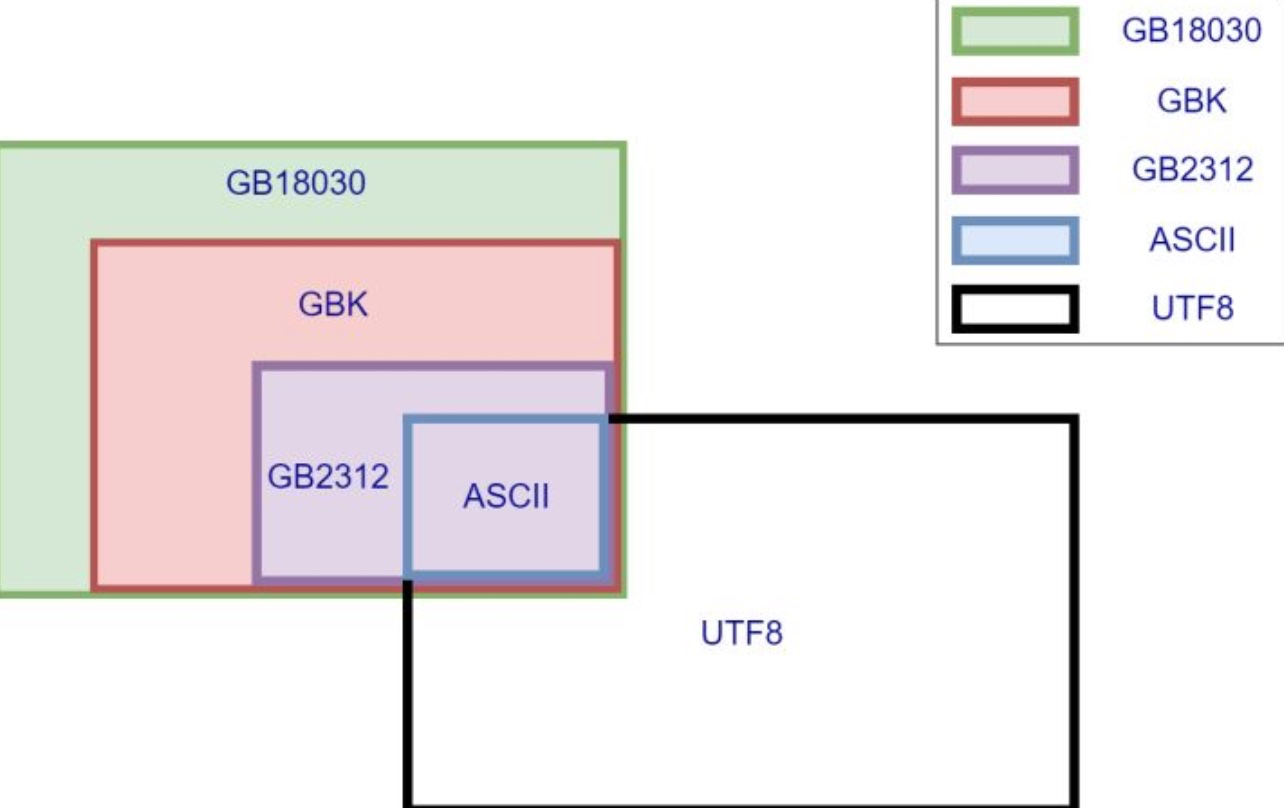
4、其他国家
Big5,又称为大五码或五大码,是使用繁体中文社区中最常用的电脑汉字字符集标准。Big5 虽普及于台湾、香港与澳门等繁体中文通行区,但长期以来并非当地的国家标准,而只是业界标准。
JIS,日本常用编码。
等等……
5、Unicode / UTF
Unicode(统一码、万国码、单一码、标准万国码),由非营利性的 Unicode 组织(The Unicode Consortium)所运作。
Unicode 包括 emoji。
Unicode 字符集,支持的字符编码有 UTF-8 (常用、推荐)、UTF-16、UTF-32。
UTF-8(8-bit Unicode Transformation Format)和 UTF-16 最大的特点,就是它们是一种变长的编码方式。UTF-8 可以使用1~5个字节表示一个符号,而 UTF-16 使用2个字节或4个字节表示;而 UTF-32 是 定长的编码方式,用4个字节表示。
UTF-8 的具体编码方式待写。
举例:UTF-8 下,英文字母只需要一个字节,汉字三个字节。
1、UTF-8 对更古怪更稀有的字符可以用四个甚至五个字节表示,但因使用频率低,所以空间浪费不大。
2、UTF-8 / UTF-16 这种变长的性质节省空间,很适合网络传输,所以在互联网流行的时候迅速风靡。
3、早期 UTF-16 是定长的2字节,但是后来吸收了更多字符放不下了,才改成了变长。但改变前,Windows NT 和 Java 为了国际化早已采用了 UTF-16。
4、UTF-8 更适合欧美人,更 UTF-16 适合中国人。因为对于欧美人来说,英文字符更常见,UTF-16 存每个英文字符需用2个字节,而UTF-8的只需要1个字节。但对于中国人来说,汉字更常见,UTF-16 存每个中文字符需用2个字节,而UTF-8的需要3个字节,多占50%。
5、UTF-32 对本来就可以1个字节就表示的英文字母,还要用4个字节,真的太浪费了空间了。所以很少用。
6、总结
单字节编码:一个字节就表示一个字符,比如 ASCII
双字节编码:需要用两个字节来表示一个字符的编码,比如 GB2312,GBK 编码
多字节编码:需要用多个字节来表示一个字符的编码,比如 Unicode/UTF-x 编码
注意:ASCII 编码几乎被世界上所有编码所兼容(UTF16和UTF32是个例外)
三、解码
解码会按照上面介绍的 字符编码 规则来解码,如果在 字符集 里找不到对应的字符,则会显示:
单字节会用 ?代替,多字节会用 � 代替。
“�” 本身是一个合法的 Unicode 字符,码点为U+FFFD,对应的UTF-8编码为 EF BF BD。
四、字节序 与 BOM
打开 Sublime Text ,在保存文件时,有以下几个编码选项:
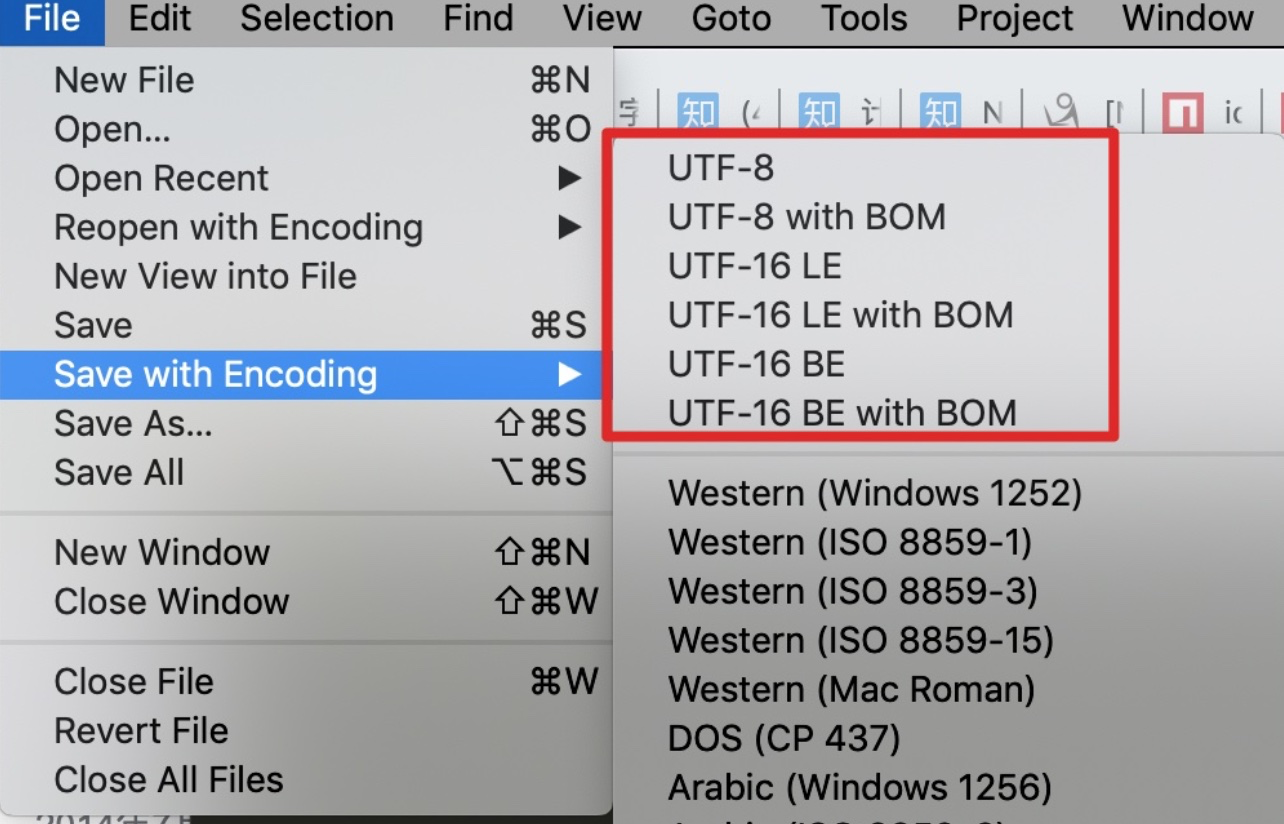
打开 VSCode,右下角也有以下几个编码选项:
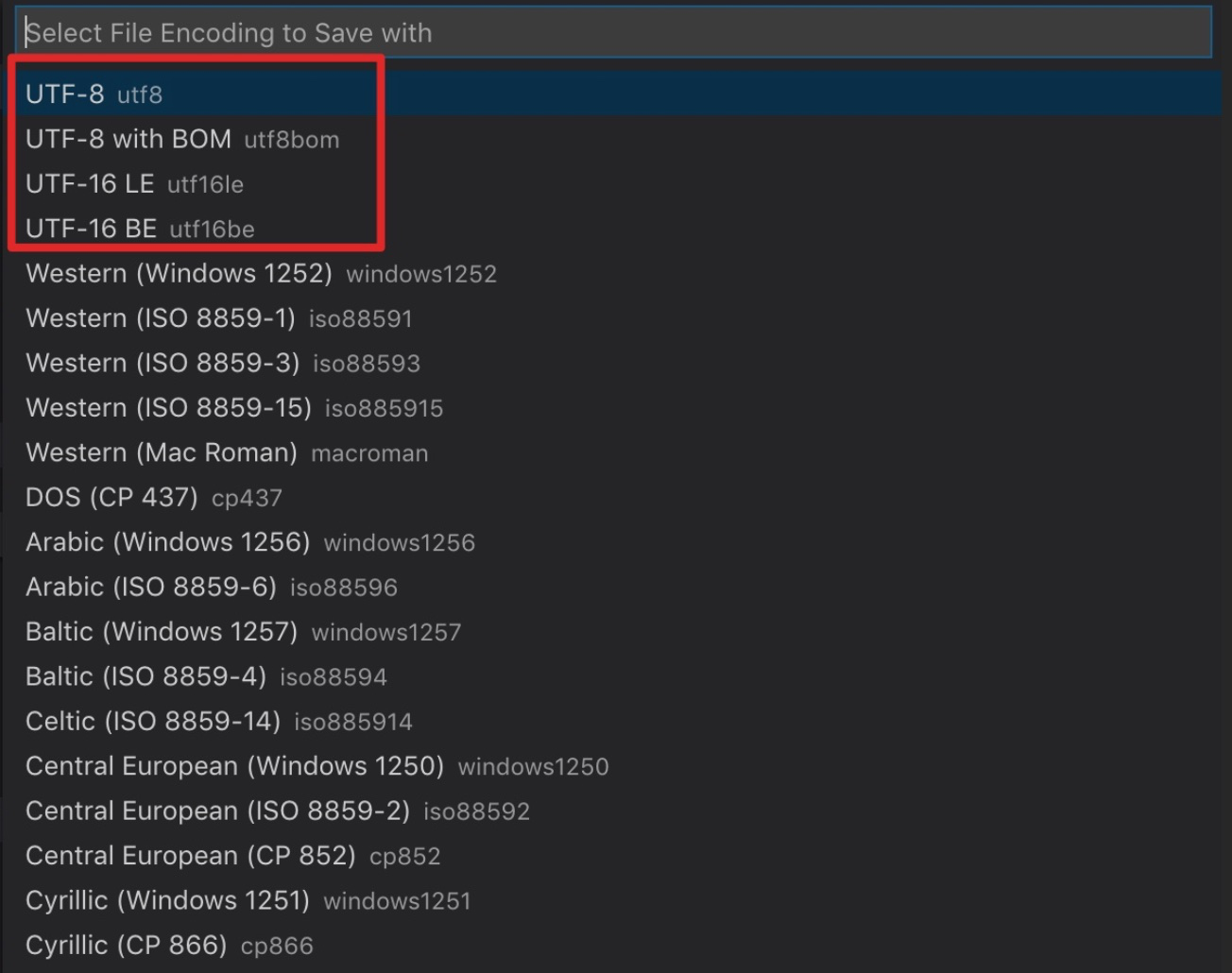
那什么是 LE、BE 和 BOM 呢?
1、字节序 与 大端、小端
字节序(byte order),也就是字节的顺序,指的是多字节的数据在内存中的存放顺序。
虽然有字节序的概念,但这仅仅是在处理多字节数据才会存在的问题,比如double、long这种一个字节无法存放的数据。
字节序分为两种:大端序 BE(Big Endian)与 小端序 LE(Little Endian)。
- 大端序是指低地址端存放高位字节。
- 小端序是指低地址端存放低位字节。
例如,一个“奎”的 Unicode 编码是 594E,“乙”的 Unicode 编码是 4E59。如果我们收到 UTF-16 字节流为 “594E”,那么这是“奎”还是“乙”呢?如果是大端序,那么就是594E——“奎”,如果是小端序,那么就是4E59——“乙”。
所以采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。
大端、小端,这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头 (Big-endian) 敲开还是从小头 (Little-endian) 敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
2、字节序的存在
网络字节序:TCP/IP 各层协议将字节序定义为大端序。
主机字节序:不同的 CPU 有不同的字节序。
这就牵涉出两大 CPU 派系:
-
x86系列,VAX,PDP-11等处理器采用 小端序 方式存储数据。
-
Motorola 6800,PowerPC 970,SPARC(除V9外)等处理器采用 大端序 方式存储数据。
编程语言字节序:C/C++ 的字节序是依赖于编译平台所在的 CPU,Java 的字节序是大端序。
3、如何标识字节序 —— BOM
Unicode 的标准里,有对 BOM(byte order mark - 定义字节顺序)的定义:如果一个文本文件的头两个字节是FE FF,就表示该文件采用大端序;如果头两个字节是FF FE,就表示该文件采用小端序。
U+FEFF 这个字符的名字叫做"零宽度非换行空格"(zero width no-break space),是Unicode提出来的规范。
这个在源数据里标注的方法叫 ”magic number“,很多非文本文件也会用到,比如 bmp 文件通常会以 “42 4D” 两字节开头,又比如 Java 的 class 文件,则是以四字节的 “CA FE BA BE” 打头。
只不过非文本文件仅是用来标注文件类型(所以即使丢失了拓展名依然可以正确打开),而文本文件:
-
标识字节序(主要作用)
-
标注文件类型【例如标注采用哪种 unicode 编码方式】(附带作用)
下面是 unicode 编码里带 BOM 的文件开头的表示方法:
-
UTF-8: EF BB BF
-
UTF-16 little-endian: FF FE
-
UTF-16 big-endian: FE FF
-
UTF-32 little-endian: FF FE 00 00
-
UTF-32 big-endian: 00 00 FE FF
注意:UTF-8 编码不存在字节序大小端问题(因为字节序只影响同时处理多于两个字节的编码方式,比如 UTF-16/UTF-32,而UTF-8是按照单字节进行处理的),所以 UTF-8 的 BOM 仅起标注文件编码方式的作用,可加可不加。
可加可不家,这可真含糊,到底有没有标准说,要不要给 UTF-8 加 BOM 呢?
windows 的习惯:加 BOM
微软很早就加入了 unicode 组织对标准的制定,所以很早就实现了 BOM 这个option feature,而且也很好满足了自家操作系统对高兼容性的要求。
linux 的习惯:不加 BOM
BOM本身违反了一个UNIX设计的常见原则,就是文档中存在的数据必须可见。BOM 不能作为可见字符被文本编辑器编辑,就这一条很多UNIX开发者就不满意。所以 linux 现在不会加,以后也不会加。
我的建议:如果你是 windows 的普通用户,可以加 BOM(例如 windows 下的 notepad ++ 默认保存格式就是 UTF-8 BOM)。但如果你是开发者,还是别加 BOM,这样:
-
1、可以照顾各家操作系统,实现最大的兼容性
-
2、如果你是前端开发者,在网页文档里使用 BOM 是多此一举。要识别文本编码,HTML 有 charset 属性,XML 有 encoding 属性,没必要用 BOM 。
-
3、如果你是后端开发者,各种编程(脚本)语言对文本编码的识别都有自己的一套,Python 的 # -- coding: utf-8 --,Perl 的 use utf8,都比 BOM 简单而且可靠。
更多关于 BOM 的讨论,可看:
知乎:「带 BOM 的 UTF-8」和「无 BOM 的 UTF-8」有什么区别?网页代码一般使用哪个?
知乎:微软为什么用带 BOM 的 UTF-8,造成和多数系统的不兼容?
五、使用场景
1、操作系统
1、MacOS 中, locale 命令可以查看计算机用户所使用的语言,所在国家或者地区,以及当地的文化传统所定义的一个软件运行时的语言环境。
以我的 英文系统 和同事的 中文系统 这两台 macbook 分别运行 locale 命令,结果如下:
# 我的
LANG=
LC_COLLATE="C"
LC_CTYPE="UTF-8"
LC_MESSAGES="C"
LC_MONETARY="C"
LC_NUMERIC="C"
LC_TIME="C"
LC_ALL=
# 同事的
LANG="zh_CN.UTF-8"
LC_COLLATE="zh_CN.UTF-8"
LC_CTYPE="zh_CN.UTF-8"
LC_MESSAGES="zh_CN.UTF-8"
LC_MONETARY="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
LC_TIME="zh_CN.UTF-8"
LC_ALL=
上面的 C 是指POSIX语言环境,它又称C语言环境,反映了UNIX系统的历史行为。详情看:https://pubs.opengroup.org/onlinepubs/009695399/xrat/xbd_chap07.html
字段解释如下:
-
比较和排序习惯(LC_COLLATE)
-
语言符号及其分类(LC_CTYPE)
-
信息主要是提示信息,错误信息,状态信息,标题,标签,按钮和菜单等(LC_MESSAGES)
-
货币单位(LC_MONETARY)
-
数字(LC_NUMERIC)
-
时间显示格式(LC_TIME)
一般来说,这些字段要改,就改成统一的。你不可能 LC_COLLATE 是德国的,然后LC_MONETARY 是美国的,LC_TIME 又是中国的,那就乱套了。
字段的优先级:LC_ALL > LC_* >LANG
总结:可以看出 MacOS 默认的编码是UTF-8。
2、在 Windows 中,默认编码为 GBK,而 linux 为 UTF-8。
windows 里查看默认编码的方式是在 CMD 里输入
chcp命令,如果结果是 936 ,即为 GBK。
注意:例如 python 在用 open() 读取本地文件时,如果不指定 encoding 这个参数,缺省值就是本地默认编码,它指的就是当前操作系统的默认编码,如果在 windows 上,有必要的话记得指定,防止出错。
3、编程语言里也可以查看操作系统的编码,以 Python 为例:
import locale
print(locale.getdefaultlocale()) # ('en_US', 'UTF-8')
4、操作系统其实还存在 外码、内码 的概念,例如 windows 其实内码是 UTF-16,外码才是 GBK。但这里涉及更深的计算机字符与编码的知识,按下不表,以后待写。
2、编辑器
我常用的文本文件编辑工具:Sublime Text 和 VSCode 的默认编码也是 UTF-8。
多说一句,git 的默认编码方式也是 utf-8。 但你如果在windows 下遇到问题,可以参考这里的解决方案:http://howiefh.github.io/2014/10/11/git-encoding/
3、编程语言
在用编辑器编辑好源代码后,执行它,就会涉及到编程语言对应的编译器编码。
(1)python
python2 的编译器,默认编码是 ASCII,所以若是执行下面这段代码,会报错:
s = "你好,世界"
print s
解决办法就是在源代码文件的开头指定编码:
# coding=utf-8
或者
# -*- coding: utf-8 -*-
这种在源代码里添加额外信息来标注用了什么编码的方法,跟上面提到的 BOM 的方法是一样的。
但不同的是,因为不是二进制信息去标识的,而是用字符形式,所以浏览器通常会先猜测编码来解析,等到发现了 charset设置 再更换编码来读取。
而 python3 则修改了默认编码为 UTF-8,所以不再需要上面的声明。
但我遇到一种情况需要强制指定
# -*- coding: utf-8 -*-,原因未知,发了帖子咨询网友也没解决:Python 一个关于字符编码的诡异问题(Non-UTF-8 code starting with '\xe5') 【待写】
在 Python3 中, str 为字符串类型,bytes 为二进制类型。
如何查看 Python 编译器默认编码呢?
import sys
print(sys.getdefaultencoding()) # utf-8
题外话:
很多设计比较早的编程语言,字符串类型其实根本就不是真的字符串,而是一串二进制数据,他的编码跟源代码文件的编码保持一致,比如 C,C++,PHP,Python2。
但之后设计的编程语言就明确区分了字符串和二进制(数组)这两种数据类型。前者跟源代码文件的编码保持一致,后者却不一定。可能源代码文件的编码是 utf-8,即字符串也是这个编码,但是二进制数组里存的是以 GBK 方式编码的数据。所以还诞生了明确标注编码类型的二进制数组的数据类型,如 Java 使用的 UTF32 和 Go 使用的 UTF8。
(2)Node.js
Node.js 的默认编码是 UTF-8。
Node.js 有两个库可以实现编码类型转换:lconv 和 Iconv-lite 。
Iconv-lite 采用纯 Javascripts 实现,Iconv 则通过 C++ 调用 libiconv 库完成。前者比后者更轻量,无须编译和处理环境依赖直接使用。在性能方面,由于转码都是耗用 CPU,在 V8 的高性能下,少了 C++ 到 javascript 的层次转换,纯 Javascript 的性能比 C++ 实现得更好。
即,Iconv-lite 性能更好,推荐使用。
Iconv-lite 示例:
var iconv = require('iconv-lite');
// Convert from an encoded buffer to js string.
let str = iconv.decode(Buffer.from([0x68, 0x65, 0x6c, 0x6c, 0x6f]), 'win1251');
// Convert from js string to an encoded buffer.
let buf = iconv.encode("Sample input string", 'win1251');
// Check if encoding is supported
iconv.encodingExists("us-ascii")
// supported:
// All node.js native encodings: utf8, ucs2 / utf16-le, ascii, binary, base64, hex.
// Additional unicode encodings: utf16, utf16-be, utf-7, utf-7-imap, utf32, utf32-le, and utf32-be.
// All widespread singlebyte encodings: Windows 125x family, ISO-8859 family, IBM/DOS codepages, Macintosh family, KOI8 family, all others supported by iconv library. Aliases like 'latin1', 'us-ascii' also supported.
// All widespread multibyte encodings: CP932, CP936, CP949, CP950, GB2312, GBK, GB18030, Big5, Shift_JIS, EUC-JP.
4、web 前端之 HTTP 请求
因为 http 的数据传输也是二进制流,所以肯定会涉及编解码的过程。对编码的要求,都写在客户端与服务器来往的 Headers 中。
Request Headers:
-
Accept-Charset:浏览器申明自己想要接收的字符编码方式,例如:utf-8,gb2312;q=0.7,*;q=0.3
-
Accept-Encoding:浏览器申明自己想要接收的编码方法,通常指的是压缩方法。例如:gzip, deflate, br
-
Accept-Language:浏览器申明自己想要接收的语言。例如:zh-CN,zh;q=0.9,en;q=0.8
上面的值都按期望的优先级排列。
Response Headers:
-
Content-Type:WEB 服务器表明自己响应了什么数据类型和字符编码。例如:text/html; charset=utf-8
-
Content-Encoding:WEB 服务器表明自己使用了什么压缩方法。例如:gzip
-
Content-Language:WEB 服务器表明自己响应了什么语言的数据。例如:zh-CN
Content-Type 是通过 Nginx 的
charset utf-8;来配置的。
可以看出,浏览器发起一个请求时所携带的 headers 信息只是对服务器返回资源的一种 “期望”,资源本身的类型还得用服务器应答时携带的 headers 信息进行表示。如果两者不一致,浏览器会去做一些转码工作。
5、web 前端之 HTML 文档
HTML4 的声明编码方式:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
HTML5 的声明编码方式:
默认字符集就是 UTF-8。
<meta charset="UTF-8">
这种在源代码(html 文件)里通过添加标识数据来表明编码类型的方式,跟上面介绍的 BOM 类似。
6、web 前端之 浏览器编码设置
我记得之前的浏览器在页面右键是可以修改编码方式的,但现在的 chrome 我没有找到。可以安装这个拓展查看/修改当前页面编码:https://chrome.google.com/webstore/detail/charset/oenllhgkiiljibhfagbfogdbchhdchml
7、数据库
MySQL 默认编码为 latin1
PostgreSQL 默认编码为 UTF-8
MongoDB 默认编码为 UTF-8
六、编码检测
检测一个文件采用了什么编码,是一个很复杂的事。好在有一些工具可以帮我们。
1、linux
用 file 命令:
> file icon.js
icon.js: UTF-8 Unicode text
2、编辑器
直接把文件拖到编辑器(Sublime 或 VSCode )里打开,都支持自动识别编码。
3、编程语言
Python 里可用 chardet 库。
Node.js 里可用 jschardet 库:
var jschardet = require("jschardet")
//detect 接受 Buffer 类型
// "àíàçã" in UTF-8
jschardet.detect("\xc3\xa0\xc3\xad\xc3\xa0\xc3\xa7\xc3\xa3")
// { encoding: "UTF-8", confidence: 0.9690625 }
var fs = require("fs")
var content = fs.readFileSync("test.csv");
console.log(jschardet.detect(content))
// { encoding: 'UTF-8', confidence: 0.99 }
七、其他编码方式
1、URLEncode
(1)URL 编码
根据 2005 年发布的 RFC3986( Uniform Resource Identifier (URI): Generic Syntax ) 关于 “百分号编码”规范:对 URL 中属于 ASCII 字符集的非保留字不做编码;对 URL 中的保留字(如参数分隔符“&”)需要取其 ASCII 内码,然后加上“%”前缀将该字符进行替换(编码);对于 URL 中的非 ASCII 字符(如汉字)需要取其 Unicode 内码,然后加上“%”前缀将该字符进行替换(编码)。
所以,URL 转义是为了符合规范并保证可以被正确无误的传输。
(2)怎么编码
JS 里有专门负责 URL 编码的函数:encodeURI() 和 encodeURIComponent()。
encodeURI('https://www.baidu.com/s?wd=你好')
// "https://www.baidu.com/s?wd=%E4%BD%A0%E5%A5%BD"
encodeURIComponent('https://www.baidu.com/s?wd=你好')
// "https%3A%2F%2Fwww.baidu.com%2Fs%3Fwd%3D%E4%BD%A0%E5%A5%BD"
顾名思义,encodeURI 是用来编码整个 URI 的。
而 encodeURIComponent 是用来编码你准备用作 query 一部分的字符串的,例如:
-
手工拼URL的时候,对每对KV用 encodeURIComponent
-
参数传一个回调地址时,这个 url 需要用 encodeURIComponent
(3)为什么我的 chrome 地址栏可以输入中文?
早期的浏览器其实是不支持的,只是现在 chrome 做了更人性化的工作。
例如,虽然你访问了 https://www.baidu.com/s?wd=你好 ,但浏览器帮你偷偷做了转义(https://www.baidu.com/s?wd=%E4%BD%A0%E5%A5%BD)才发送了请求,虽然你看到地址栏上还是中文。
(4)除了地址栏, 还有其他部分的 URL
-
form 表单的 GET/POST 的 url
-
ajax 的 GET/POST 的 url
这些也需要做 UrlEncode,不过浏览器都会帮我们去做。
早期的 IE 等一些老的浏览器,存在很多不做 UrlEncode,或者实现了 UrlEncode 但标准不一的情况,好在现在开发者都无需操心了。
且现在的服务器端也基本都会帮你去自动的做 UrlDecode ,所以开发者也无需操心。
(5)在线编解码工具
https://tool.chinaz.com/tools/urlencode.aspx
2、Base64
(1)二进制协议 & 文本协议
首先我们先了解下协议的两种方式:
-
二进制协议binary protocol - 如 TCP/IP、HTTP2 -
文本协议Text-based protocol - 如 SMTP、HTTP 0.9、1.0、1.1
注意,他们的区别不在于,进行网络传输时,是二进制还是文本文件(因为传输一定是二进制)。而在于是否是人类可读的。
这点很像上面说到的 二进制文件 和 文本文件 的区别。本质上都是二进制文件,只是文本文件是人类可读的。
二进制协议优点:
-
数据紧凑,空间占用小,可高效传输
-
解析简单,性能高
-
方便加密
文本协议优点:
-
可读性高,也便于调试
-
拓展性好(而二进制协议是已经确定的数据解析顺序,不好轻易改变)
-
可跨处理器(据说是由于严格的内存到对象的转换。比如,不同处理器架构存在数据存储的大端小端问题)
(2)为什么出现 Base64
原理:
Base64 编码,是从二进制值到64个可打印字符的编码。
这 64 个字符都在 ASCII 码表里能找到(所以也可把 Base64 称为二进制值转 ASCII )。 而 ASCII 码太通用了,所以 Base64 的跨平台性兼容性很强,甚至比二进制还强。
起源:
Base64 最早是用在 SMTP 协议(一种邮件传输协议),它是文本协议,且只支持 ASCII 字符传递,所以SMTP 如果要传输图片、视频这类二进制文件,用 Base64 编码就可以传输了。
早期的 HTTP 协议,也是文本协议,尤其是 HTTP 0.9,只支持 HTML 这一种文档。所以根本无法传输图片。所以也只能用 base64 编码传输。
应用:
电子邮件的附件一般也作Base64编码的。
在前端开发中,如果网页有太多的图片(尤其是很多小图片、小 icon 之类的),则会多次请求服务器,影响加载速度,这时可以给 img 标签提供用 base64 编码后的图片:<img src="data:image/png;base64,iVBORw0……"/>
对证书来说,特别是根证书,一般都是Base64编码的。
从这里可以看出,Base64 虽然诞生是为了解决特定问题,但是后来的应用却并不局限一隅。
(3)Base64 在线转换工具
https://tool.oschina.net/encrypt?type=3
八、拓展知识
1、换行符
(1)含义
在一个文本文件里,需要给每一行结束并换行定义一个标志符(称为换行符 line break 或行结束符 end-of-line (EOL) )。但因为历史原因,有几种表示方法:
-
CR: 是 carriage return 的缩写。中文意思是回车。\r0x0D -
LF: 是 line feed 的缩写,中文意思是换行。\n0x0A -
CRLF: 是carriage return line feed的缩写。中文意思是回车换行。\r\n0x0D0x0A
在 Sublime Text 和 VScode 里,都有对 CR / LF 的设置。
历史:“回车” 和 “换行” 这两个词都是借鉴早期打字机的概念。
-
“回车”:告诉打字机把打印头定位在左边界
-
“换行”:告诉打字机把纸向下移一行
(2)现状
- Unix (Linux) 使用 LF
- 早期的 Mac 系统使用 CR,现在成了 LF
- Windows 使用 CRLF
其实,CRLF 才是正统,很多较早的协议,包括 RFC 0821 (SMTP)、RFC 1939 (POP)、RFC 2060 (IMAP)、RFC 2616 (HTTP) 都采用了 CRLF。
不同操作系统不一样的后果是:Unix/Mac 下的文件在 Windows 里打开的话,所有文字会变成一行;而 Windows 里的文件在 Unix/Mac 下打开的话,每行的结尾会多出一个^M符号。
所以,如何解决这个兼容性问题呢?
1、很多文本/代码编辑器带有换行符转换功能。
2、在不同操作系统平台间使用 FTP 软件传送文件时,在 ASCII 文本模式传输模式下, 一些 FTP 客户端程序会自动对换行符进行转换。
3、Git 提交的时候, 为了防止在提交记录里面会出现整个文件都被更改的局面,扰乱跨平台合作开发。可使用如下命令:
git config --global core.autocrlf true
【 Windows 下为默认】在 push 时自动地把 CRLF 转换成 LF,而在 pull 时把 LF 转换成 CRLF。
git config --global core.autocrlf input
【 Linux/Mac 下为默认】在 push 时自动地把 CRLF 转换成 LF,pull 时不转换。
git config --global core.autocrlf false
【 不推荐 】不自动转换。
可以看出 Git 还是以 Unix (Linux) 的 LF 换行符为标准。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号