Attention研究
一、背景介绍
正好在工作中需要用到 Attention 来提升模型的去噪效果,因此进行了一些研究。整理了一下自己的理解过程。
CNN有归纳偏置(inductive bias),即:Locality(局部相关性)和Spatial Invariance(空间不变性),而Self-Attention 没有这些归纳偏置,所以训练Attention 需要更多的数据。
计算全局Attention的一个问题是随着序列的增加,计算量呈现二次方增长。因此在视觉领域,如果输入图片很大,那么使用Attention就不可行了,会导致大的计算量和大的内存消耗。
为了克服这个问题,提出了一些限制全局感受野到更小区域的的方法。例如:PVT和DAT,提出了稀疏全局注意力,从特征图中选择稀疏的键值位置,并在所有查询中共享它们。
另外的一些研究是swin Transformer和CSwin Transformer,这些方法遵循了窗口注意力范式。但是window attention可能缺少跨window的交互,需要额外的设计,如window shift。
相比之下,Local Attention具有卷积的一样的归纳偏置优点,同时也可以具有Self-Attention的灵活性和数据依赖性。但是这个方法要么使用低效的im2col方法,导致增加了推理时间;
要么依赖精心编写的CUDA内核,限制了应用。
其中,CV领域的Attention可以有如下分类:
表1 CV领域的Attention分类

二、Global Self-Attention
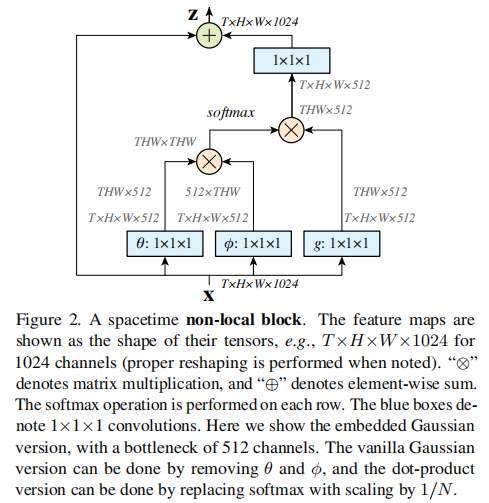
图1 Non-local block
三、Local Self-Attention
因为pixel level的attention计算量大,所以实际的工程项目中不实用,因此需要一些解决方法。后续提出了很多local attention的方法,下面对其介绍。
3.1 Vision Transformer
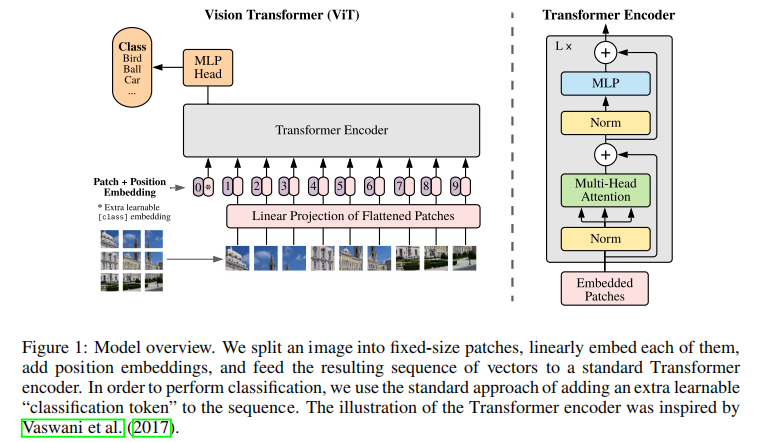
图2 VIT
如图2所示,VIT是将图像切成patch,每个patch作为一个token,在patch之间进行attention计算。可以设置每个patch的大小,增大patch大小,可以减少attention的计算量。
但是该attention操作缺乏了patch中间的attention操作,而且对于lowlevel的一些任务(比如去噪、图像恢复等任务),因为是切patch实现的attention,模型输出的图像存在块状网格。
3.2 Swin Transformer
Swin-Transformer同样是将图像切成patch,但是在patch中间进行attention计算,同时为了建立patch之间的关系,使用shift-window计算patch之间的attention,如图3所示。同时,
通过下采样方式的patch merge,通过合并相邻patch降低空间分辨率,扩大感受野(相当于在不同感受野进行attention计算),如图4所示。
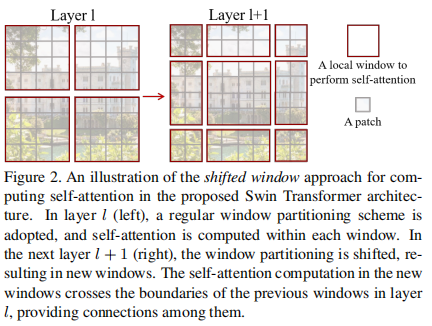
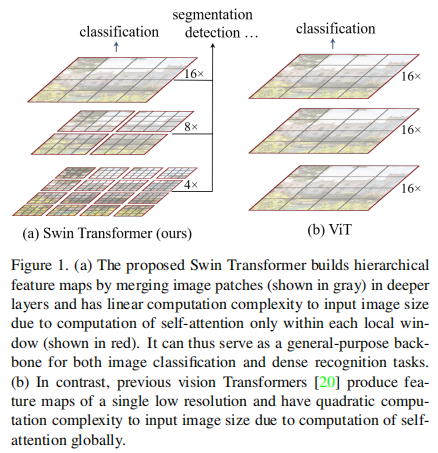
图3 shift-window attention 图4 Swin-transformer的层次化结构
3.3 Unfold实现local attention
unfold操作如图5所示。该操作提取特征和卷积类似。
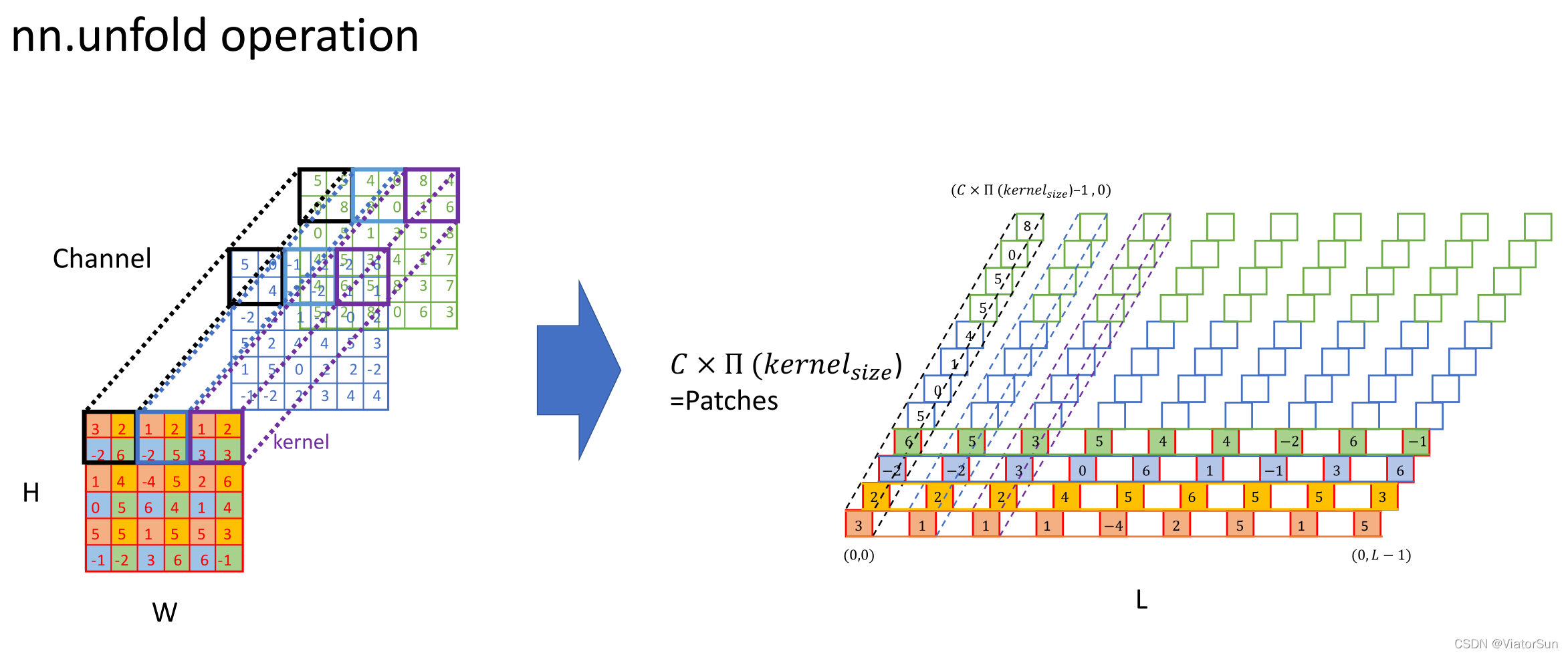
图5 unfold操作
使用unfold提取特征之后,可以在每个特征之间进行attention计算。
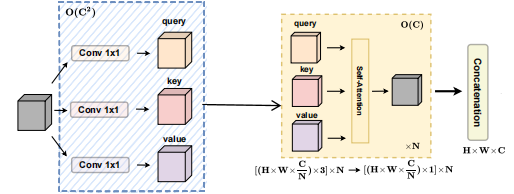
图6 local attention
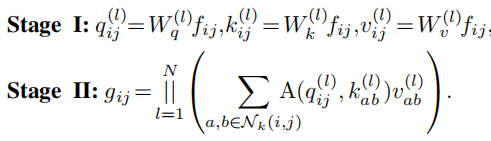
其中,$||$是N个注意力头输出的concat操作,$W_{q}^{(l)}$、$W_{k}^{(l)}$、$W_{v}^{(l)}$分别是q、k、v的映射矩阵。
$\mathcal{N}_{k}(i,j)$表示空间范围k以(i,j)为中心的像素局部区域。$A$表示attention中的除以$\sqrt{d}$,然后计算softmax。
3.4 Neighborhood Attention
上述使用unfold进行attention比较慢,这里直接使用c++和cuda kernel,实现了python包,实现原理类似于unfold,但是对local attention进行了加速。
四、其它Attention
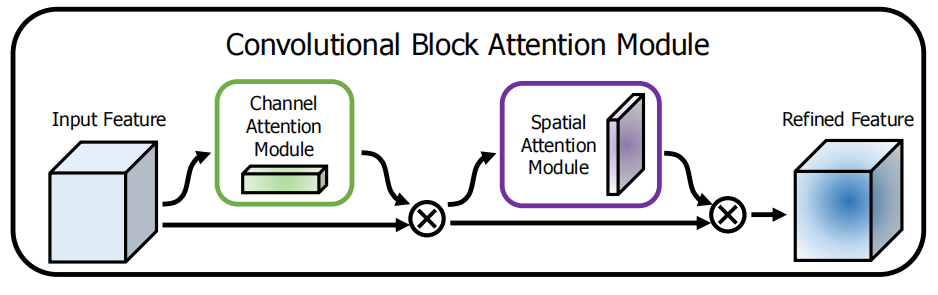
图7 CBAM
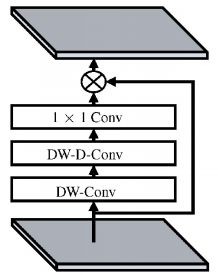
图8 LKA
五、其它
可以通过DyT技术,将transformer中的LN去掉,减少计算时间。在Low-Level领域的去噪等任务,在模型较小的情况下,DyT训练的模型去噪效果会稍差于LN训练的模型。
ref:
[1] Wang X, Girshick R, Gupta A, et al. Non-local neural networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7794-7803.
[2] https://blog.csdn.net/ViatorSun/article/details/119940759
[3] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[4] Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 10012-10022.
[5] Pan X, Ge C, Lu R, et al. On the integration of self-attention and convolution[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 815-825.
[6] Hassani A, Walton S, Li J, et al. Neighborhood attention transformer[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023: 6185-6194.
[7] Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 3-19.
[8] Guo M H, Lu C Z, Liu Z N, et al. Visual attention network[J]. Computational visual media, 2023, 9(4): 733-752.
[9] Wang Y, Li Y, Wang G, et al. Multi-scale attention network for single image super-resolution[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 5950-5960.
[10] Zhu J, Chen X, He K, et al. Transformers without normalization[J]. arXiv preprint arXiv:2503.10622, 2025.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号