多模态
1. CLIP模型
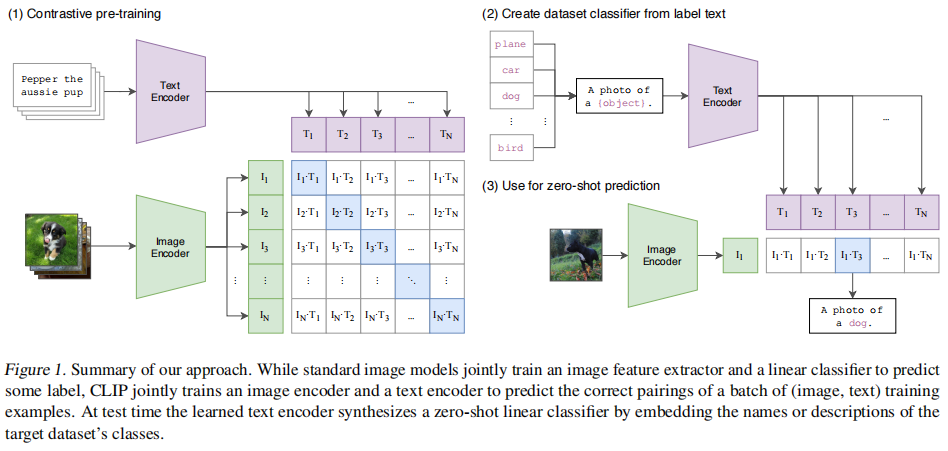
图1 CLIP Model
通过text encoder和text encode分别提取文字和图片的特征,然后通过向量的点乘得到相似度;仅仅通过点乘就可以实现,速度快,对于图文匹配效果好。对于别的任务(VQA、VR、VE)性能就不够好了,因为模态间光靠一个简单的点乘是不够的。
2. BLIP
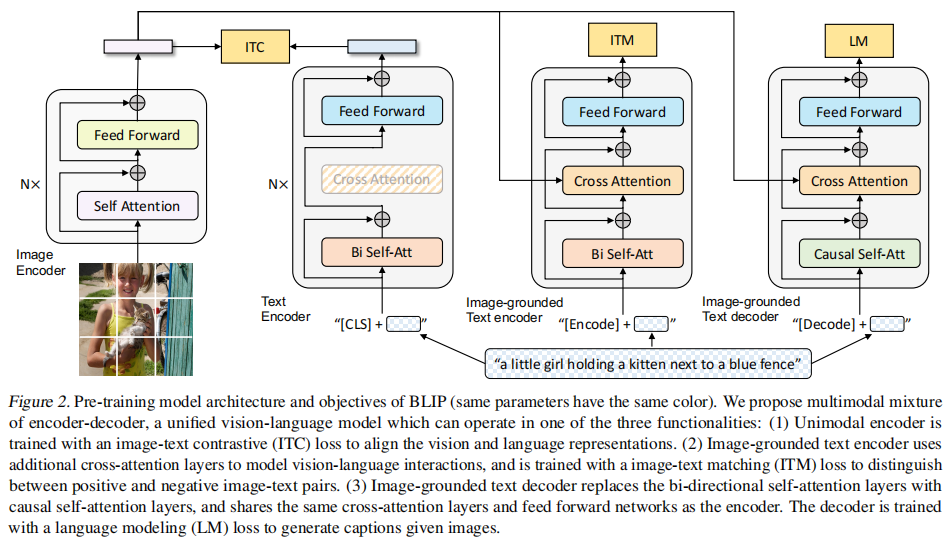
图2 BLIP Model
ITC loss & ITM loss
任务分工:
ITC:ITC是对比学习,通过最大化positive image-text pair,最小化negative image-text pair。计算图像和文本的全局特征相似度(通过[CLS]标记),快速筛选潜在匹配对。
ITM:ITM是二分类模型,加入一个linear layer,直接给image-text pair打分。通过交叉注意力分析局部对齐(如物体-单词关系),判断图文是否真正匹配,ITM可以纠正ITC可能误判的样本。
LM: 生成任务。
Q:有了ITC这个目标,加入ITM这个目标有什么好处?
由于训练ITC目标时,为了防止信息泄露,image和text不能attention彼此,捕捉到的image-text交互信息有限。训练ITM允许image和text互相attention,而且是双向的,来捕捉到更细粒度的image-text交互信息。
同时训练这两个目标,互补一下,以更好地进行image-text对齐。
下图是BLIP模型的Cap Filter,整体思路如下:
1. 使用网上抓取的数据和COCO干净数据集进行预训练BLIP模型;因为网上抓取的数据不干净,存在错误标注的数据。
2. 因此再使用干净的COCO数据集finetune训练上述预训练的BLIP模型。
3. 然后使用finetune的BLIP模型中的Image-grounded Text Encoder过滤掉网上抓取的数据集,得到比较干净的数据集;
4. 同时使用finetune的BLIP模型中的Image-grounded Text Decoder对网上抓取的图片数据重新标注文字;
5. 同时将COCO数据集和上述的两个重新生成的数据组合成一个大数据集,然后在训练BLIP模型;
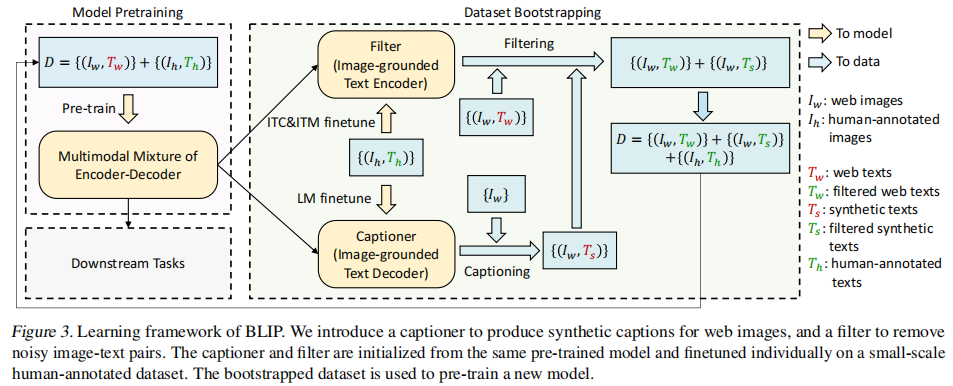
图3 Cap Filter Model

 浙公网安备 33010602011771号
浙公网安备 33010602011771号