
limu|P23-27|LeNet, AlexNet, VGG, NiN, GoogLeNet
LeNet
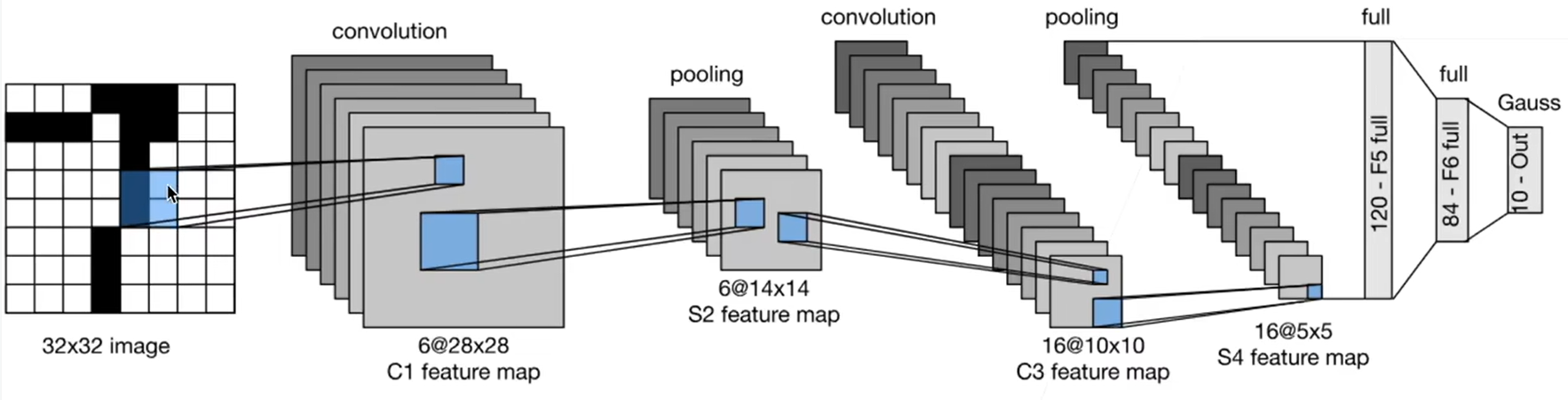
组成特点:2* (卷积+池化)+ 2 *全连接 + 输出
其中,卷积层压缩空间信息,提取图像特征(高宽减小,通道数增加),池化层降低空间敏感度&计算量(高宽减半,通道数不变),全连接层降维(理解为将卷积层提取的特征进行组合,帮助确定最终分类),最后输出数=类别数
AlexNet
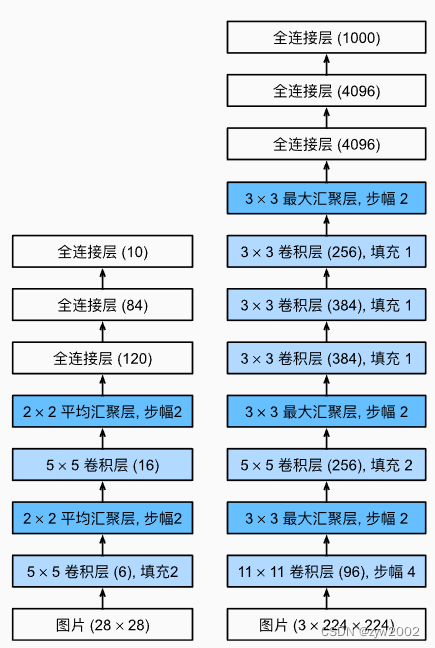
左:LeNet;右:AlexNet(5* 卷积层+2* 全连接隐藏层+1* 全连接输出层;用的ImageNet数据集)
AlexNet是更深更大的LeNet,主要改进:
1、激活函数由sigmoid变为ReLU(因为模型变深,sigmoid可导致梯度消失,ReLU求导更稳定)
2、Maxpooling
3、全连接隐藏层后加入dropout(因为模型变大——dim=4096,需要做一些正则去限制模型)
4、数据增强(相当于破坏次要特征,让模型关注主要特征;但是,数据增强后可能效果会变差,这是一个超参数)
• 全连接层:作为卷积神经网络的重要组成部分,主要用于将特征映射转化为分类所需的向量,实现端到端学习。它们通过组合特征帮助确定最终分类,但因计算量大,通常仅在卷积层后少量使用。全连接层的引入增加了模型的表达能力和鲁棒性,但也带来了更多的参数。在资源允许的情况下,全连接层可能会提升模型性能
VGG
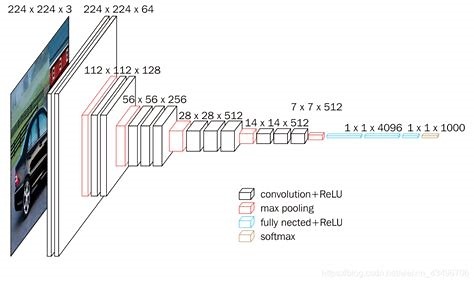
VGG把AlexNet的卷积层部分替换为数个VGG块,然后继续接3个dense layer,得到VGG16,VGG19等(数字包含卷积层数+全连接层数)。VGG很占内存
NiN
思路
全连接层的参数量=权重矩阵的size=\(H_{in}*W_{in}*C_{in}*C_{out}\)
卷积层的参数量=4维卷积核的size=\(H_{kernal}*W_{kernal}*C_{in}*C_{out}\)
显然,全连接层的参数量太大了(参数量大的弊端:1-占内存;2-用较多的计算带宽;3-很容易过拟合,需要加正则化去抑制)!卷积层的参数量相对较少
实现
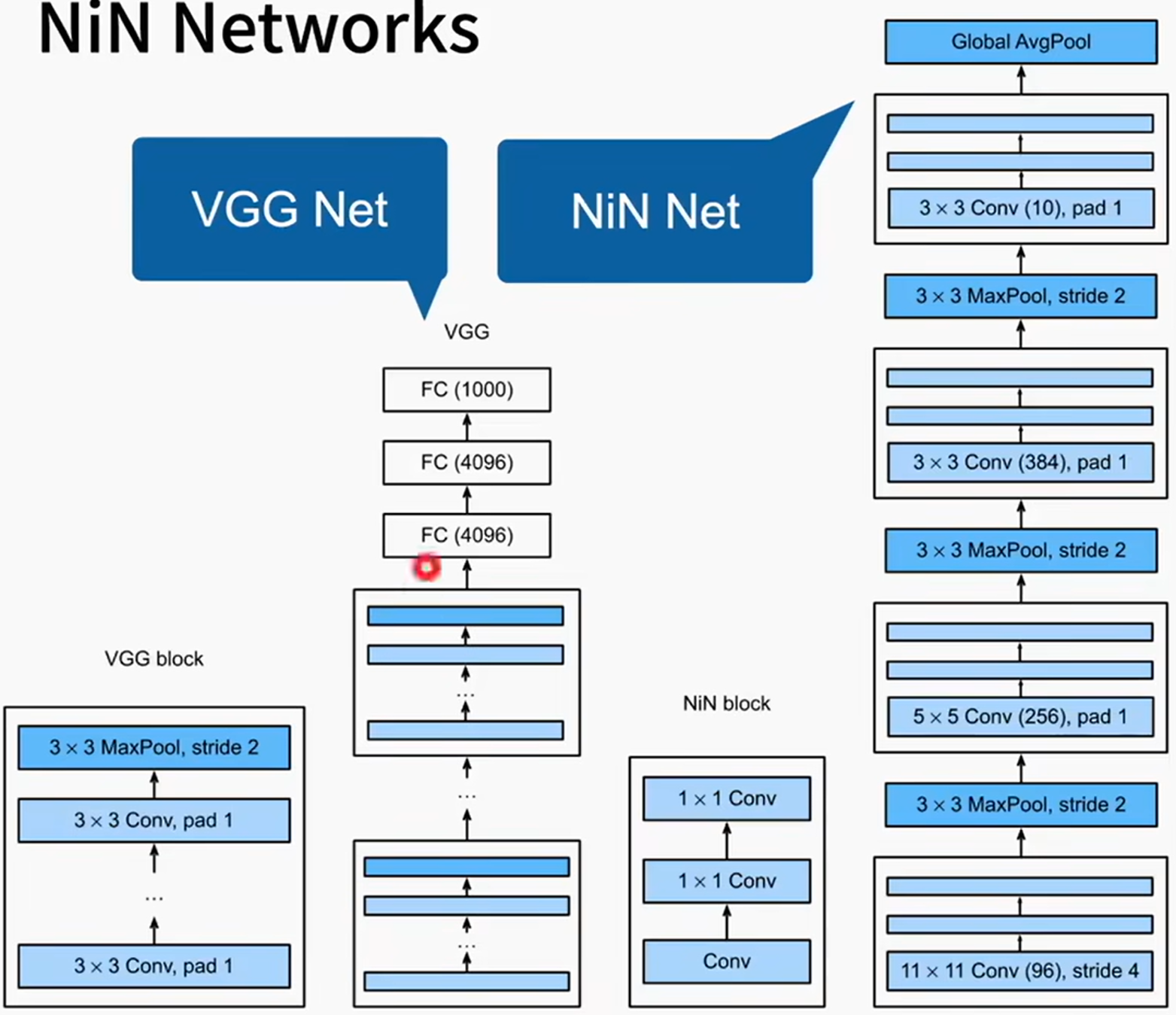
NiN不使用任何全连接层:
1、用卷积层替代全连接层:1* 1卷积层可充当逐像素全连接层(NiN块:1* 卷积层+2* kernal_size=1的卷积层)
为什么1* 1卷积层等价于逐像素全连接层?见我另一篇笔记
2、最后用全局平均池化层得到输出:其输入通道数=类别数,在每个输入通道上取max从而得到此通道的输出,作为此类别的输出(最后再softmax,在Pytorch中与cross_entropy集成在一起,因此架构图里可以不画)
全局平均池化层降低模型复杂度,但可能导致收敛慢
GoogLeNet
思路
我全都要!
实现
基本的卷积块为Inception块:输入被copy成4份,并行做不同的处理——取不同层面的信息,然后在输出时,在通道维度上合并,so size是不变的,只有通道数改变
不仅增加设计多样性,而且降低参数个数和计算复杂度——先使用1* 1卷积降低通道数然后再正式卷积,可降低计算量
不同Inception块设计不同,自己查查架构图。而且Inception后续还有各种变种:
• Inception-BN(v2):使用 batch normalization
• Inception-V3:修改了Inception块,替换5x5为多个3x3卷积层,替换5x5为1x7和7x1卷积层,替换 3x3为1x3和3x1(计算量会降1/3)卷积层,更深
• Inception-V4:使用残差连接
GoogLeNet是第一个达到上百层的网络,虽然精度提高一点点,但是由于速度不快、占内存、设计复杂,大家好像不太喜欢用
Q&A
• 用自己的数据跑时,最好不要动经典的模型网络的架构(除非比如通道数都除以2降计算复杂度这种)
• ResNest(李沐团队自己的工作)在迁移学习效果好
• 调参,可以在数据的子集调or把图片调小一点,这样计算量减少
• InceptionV3用了soft label,对效果有作用
• 用好trick可以把精度大幅提升
本文来自博客园,作者:xjl-ultrasound,转载请注明原文链接:https://www.cnblogs.com/xjl-ultrasound/p/18367987

 浙公网安备 33010602011771号
浙公网安备 33010602011771号