从0开始的机器学习——多项式与逻辑回归(1)
如果一组数据的分布不是近似线性的,应该如何去拟合?
可以添加特征。
如图,引入相应的库,函数y不是一次方程,得到如图所示的数据分布:

如果用一次函数来模拟,得到以下结果:
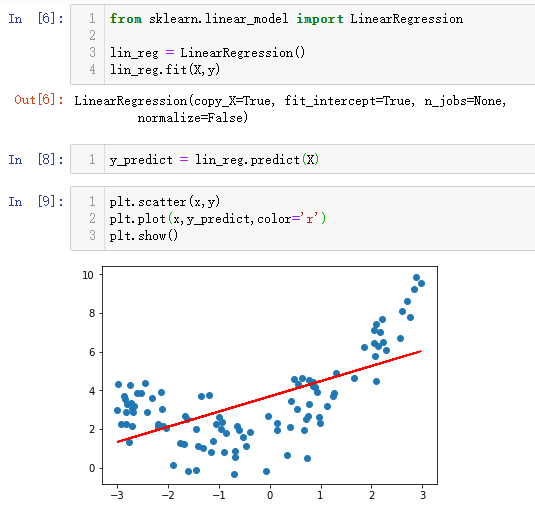
很显然不合适,丢失了很多数据。
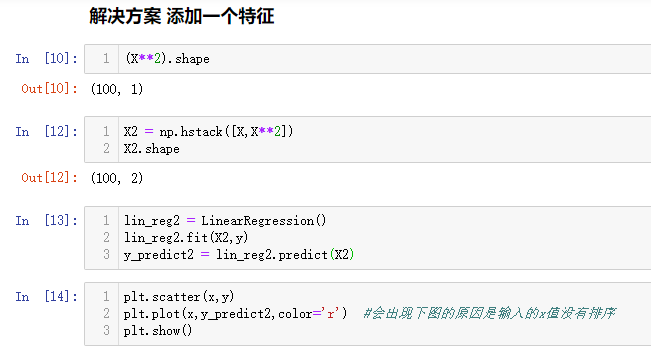
如果直接带入x和预测的y值作为参数,会出现以下的结果:
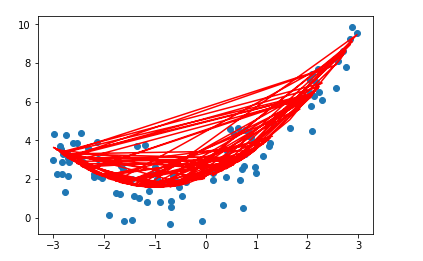
这是因为x值没有排序,输入排序后的x值后:
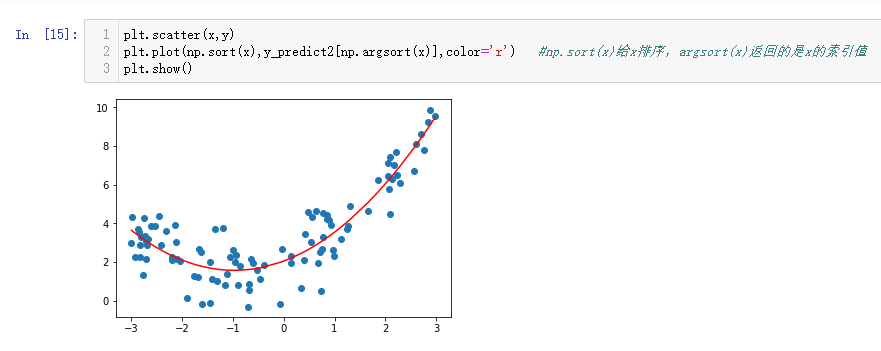
可以获得符合要求的回归曲线。
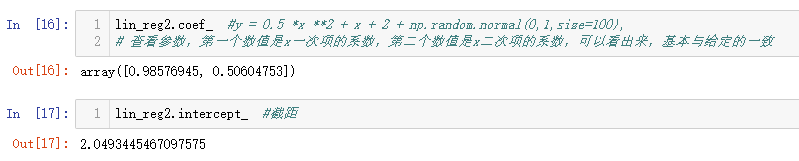
查看参数,也基本符合自己创建的函数y值。

如果一组数据的分布不是近似线性的,应该如何去拟合?
可以添加特征。
如图,引入相应的库,函数y不是一次方程,得到如图所示的数据分布:
如果用一次函数来模拟,得到以下结果:
很显然不合适,丢失了很多数据。
如果直接带入x和预测的y值作为参数,会出现以下的结果:
这是因为x值没有排序,输入排序后的x值后:
可以获得符合要求的回归曲线。
查看参数,也基本符合自己创建的函数y值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号