
从0开始的机器学习——knn算法篇(6)
网格搜索
首先设置搜索的参数:这是一个数组,每一个参数相应是一个字典,每个字典对应的是一族网格搜索,每一族网格搜索列出来相应的取值范围。
param_research = [
{
'weights':['uniform'],
'n_neighbors' : [i for i in range(1,11)]
},
{
'weights':['distance'],
'n_neighbors':[i for i in range(1,11)],
'p':[i for i in range(1,6)]
}
]
接下来是knn算法:
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(knn_clf,param_research)
这个CV意思是“交叉验证”,这种方法比train_test_split更加准确。
grid_search.fit(X_train,y_train)
输出结果:


这个方法可以获得最佳参数值,比如本例最佳p值是3.
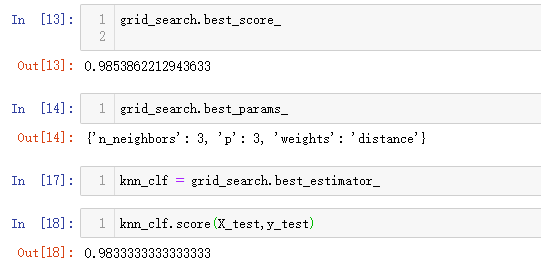
发现这次的准确度比上一节的低了。这是因为关于机器学习算法的评价标准改变了。关于评价标准,后续介绍。
GridSearchCV其实就是根据自己创建的参数数组来创建很多个分类器,然后比较这些分类器哪个更好。这些分类器是可以并行处理的。
grid_search = GridSearchCV(knn_clf,param_research,verbose=2) 这个方法里面是有几个参数可以优化的。有个参数n_jobs,这个用来判断运行时有几个核进行工作,如果n_jobs=-1即默认电脑所有的核都进行工作;verbose值是程序运行时进行细节显示。
除了闵可夫斯基距离以外,还有以下几种计算距离的方法:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号