
pycaret之训练模型(创建模型、比较模型、微调模型)
1、比较模型
这是我们建议在任何受监管实验的工作流程中的第一步。此功能使用默认的超参数训练模型库中的所有模型,并使用交叉验证评估性能指标。它返回经过训练的模型对象。使用的评估指标是:
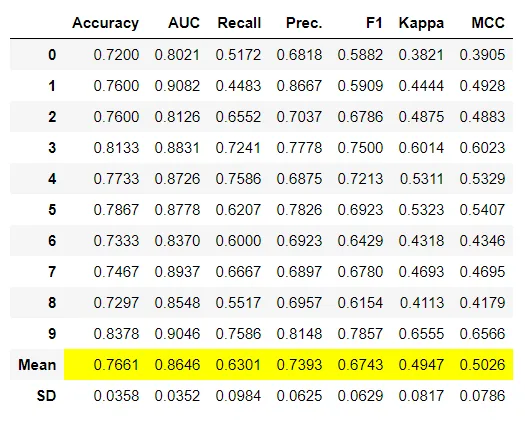
分类:准确性,AUC,召回率,精度,F1,Kappa,MCC
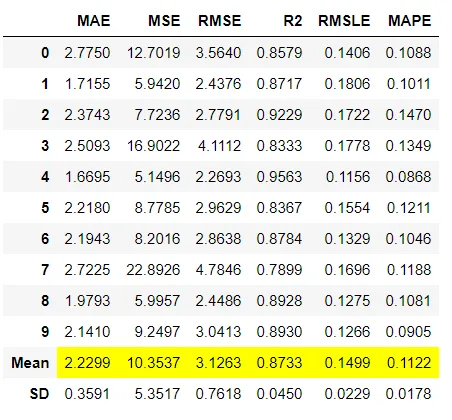
回归:MAE,MSE,RMSE,R2,RMSLE,MAPE
该函数的输出是一个表格,显示了所有模型在折痕处的平均得分。可以使用compare_models函数中的fold参数定义折叠次数。默认情况下,折页设置为10。表按选择的度量标准排序(从高到低),可以使用sort参数定义。默认情况下,对于分类实验,表按Accuracy排序;对于回归实验,按R2排序。由于某些模型的运行时间较长,因此无法进行比较。为了绕过此预防措施,可以将turbo参数设置为False。
该函数仅在pycaret.classification和pycaret.regression模块中可用。
(1)分类案例:
from pycaret.datasets import get_data diabetes = get_data('diabetes') # Importing module and initializing setup from pycaret.classification import * clf1 = setup(data = diabetes, target = 'Class variable') # return best model best = compare_models() # return top 3 models based on 'Accuracy' top3 = compare_models(n_select = 3) # return best model based on AUC best = compare_models(sort = 'AUC') #default is 'Accuracy' # compare specific models best_specific = compare_models(whitelist = ['dt','rf','xgboost']) # blacklist certain models best_specific = compare_models(blacklist = ['catboost', 'svm'])
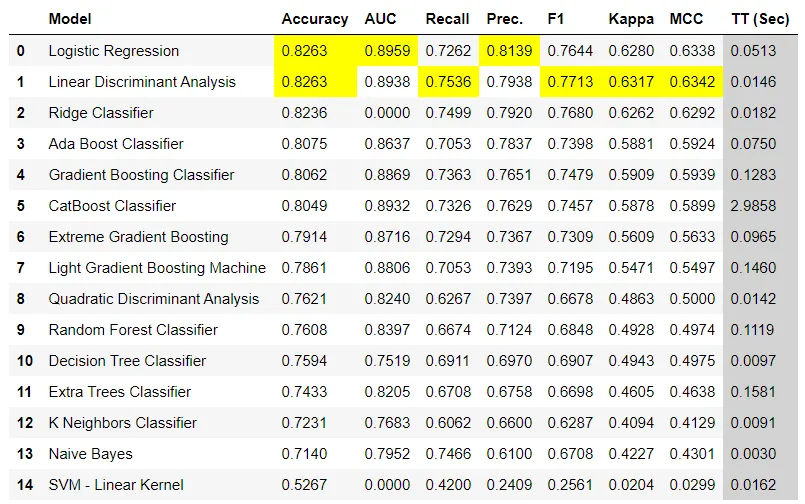
(2)回归案例:
from pycaret.datasets import get_data boston = get_data('boston') # Importing module and initializing setup from pycaret.regression import * reg1 = setup(data = boston, target = 'medv') # return best model best = compare_models() # return top 3 models based on 'R2' top3 = compare_models(n_select = 3) # return best model based on MAPE best = compare_models(sort = 'MAPE') #default is 'R2' # compare specific models best_specific = compare_models(whitelist = ['dt','rf','xgboost']) # blacklist certain models best_specific = compare_models(blacklist = ['catboost', 'svm'])
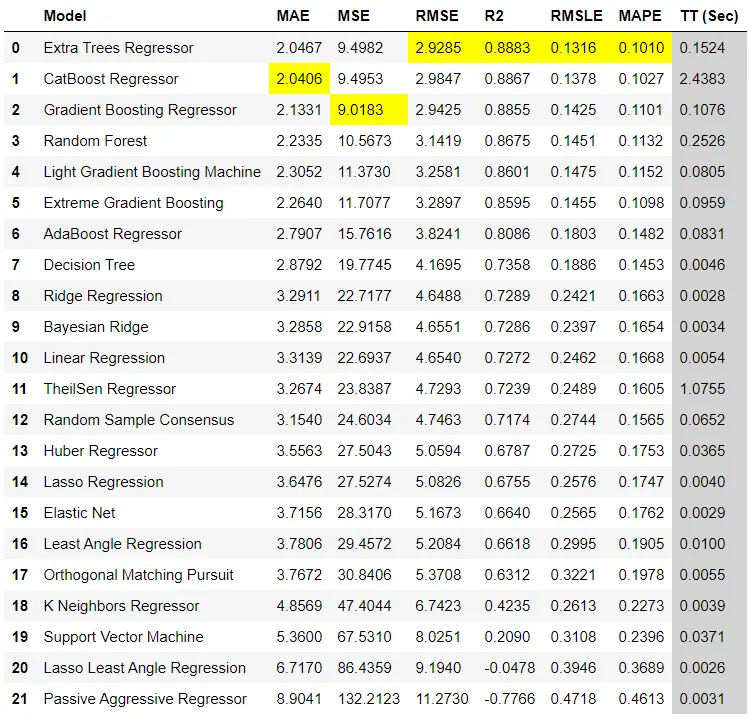
2、创建模型
在任何模块中创建模型就像编写create_model一样简单。它仅采用一个参数,即型号ID作为字符串。对于受监督的模块(分类和回归),此函数将返回一个表,该表具有k倍交叉验证的性能指标以及训练有素的模型对象。对于无监督的模块对于无监督的模块集群,它会返回性能指标以及经过训练的模型对象,而对于其余的无监督的模块异常检测,自然语言处理和关联规则挖掘,则仅返回经过训练的模型对象。使用的评估指标是:
分类:准确性,AUC,召回率,精度,F1,Kappa,MCC
回归:MAE,MSE,RMSE,R2,RMSLE,MAPE
可以使用create_model函数中的fold参数定义折叠次数。默认情况下,折痕设置为10。默认情况下,所有指标均四舍五入为4位小数,可以使用create_model中的round参数进行更改。尽管有一个单独的函数可以对训练后的模型进行集成,但是在通过create_model函数中的ensemble参数和方法参数创建时,有一种快速的方法可以对模型进行集成。
分类模型:
| ID | Name |
| ‘lr’ | Logistic Regression |
| ‘knn’ | K Nearest Neighbour |
| ‘nb’ | Naives Bayes |
| ‘dt’ | Decision Tree Classifier |
| ‘svm’ | SVM – Linear Kernel |
| ‘rbfsvm’ | SVM – Radial Kernel |
| ‘gpc’ | Gaussian Process Classifier |
| ‘mlp’ | Multi Level Perceptron |
| ‘ridge’ | Ridge Classifier |
| ‘rf’ | Random Forest Classifier |
| ‘qda’ | Quadratic Discriminant Analysis |
| ‘ada’ | Ada Boost Classifier |
| ‘gbc’ | Gradient Boosting Classifier |
| ‘lda’ | Linear Discriminant Analysis |
| ‘et’ | Extra Trees Classifier |
| ‘xgboost’ | Extreme Gradient Boosting |
| ‘lightgbm’ | Light Gradient Boosting |
| ‘catboost’ | CatBoost Classifier |
回归模型:
| ID | Name |
| ‘lr’ | Linear Regression |
| ‘lasso’ | Lasso Regression |
| ‘ridge’ | Ridge Regression |
| ‘en’ | Elastic Net |
| ‘lar’ | Least Angle Regression |
| ‘llar’ | Lasso Least Angle Regression |
| ‘omp’ | Orthogonal Matching Pursuit |
| ‘br’ | Bayesian Ridge |
| ‘ard’ | Automatic Relevance Determination |
| ‘par’ | Passive Aggressive Regressor |
| ‘ransac’ | Random Sample Consensus |
| ‘tr’ | TheilSen Regressor |
| ‘huber’ | Huber Regressor |
| ‘kr’ | Kernel Ridge |
| ‘svm’ | Support Vector Machine |
| ‘knn’ | K Neighbors Regressor |
| ‘dt’ | Decision Tree |
| ‘rf’ | Random Forest |
| ‘et’ | Extra Trees Regressor |
| ‘ada’ | AdaBoost Regressor |
| ‘gbr’ | Gradient Boosting Regressor |
| ‘mlp’ | Multi Level Perceptron |
| ‘xgboost’ | Extreme Gradient Boosting |
| ‘lightgbm’ | Light Gradient Boosting |
| ‘catboost’ | CatBoost Regressor |
聚类模型:
| ID | Name |
| ‘kmeans’ | K-Means Clustering |
| ‘ap’ | Affinity Propagation |
| ‘meanshift’ | Mean shift Clustering |
| ‘sc’ | Spectral Clustering |
| ‘hclust’ | Agglomerative Clustering |
| ‘dbscan’ | Density-Based Spatial Clustering |
| ‘optics’ | OPTICS Clustering |
| ‘birch’ | Birch Clustering |
| ‘kmodes’ | K-Modes Clustering |
异常检测模型:
| ID | Name |
| ‘abod’ | Angle-base Outlier Detection |
| ‘iforest’ | Isolation Forest |
| ‘cluster’ | Clustering-Based Local Outlier |
| ‘cof’ | Connectivity-Based Outlier Factor |
| ‘histogram’ | Histogram-based Outlier Detection |
| ‘knn’ | k-Nearest Neighbors Detector |
| ‘lof’ | Local Outlier Factor |
| ‘svm’ | One-class SVM detector |
| ‘pca’ | Principal Component Analysis |
| ‘mcd’ | Minimum Covariance Determinant |
| ‘sod’ | Subspace Outlier Detection |
| ‘sos | Stochastic Outlier Selection |
自然语言处理模型:
| ID | Model |
| ‘lda’ | Latent Dirichlet Allocation |
| ‘lsi’ | Latent Semantic Indexing |
| ‘hdp’ | Hierarchical Dirichlet Process |
| ‘rp’ | Random Projections |
| ‘nmf’ | Non-Negative Matrix Factorization |
分类例子:
# Importing dataset from pycaret.datasets import get_data diabetes = get_data('diabetes') # Importing module and initializing setup from pycaret.classification import * clf1 = setup(data = diabetes, target = 'Class variable') # train logistic regression model lr = create_model('lr') #lr is the id of the model # check the model library to see all models models() # train rf model using 5 fold CV rf = create_model('rf', fold = 5) # train svm model without CV svm = create_model('svm', cross_validation = False) # train xgboost model with max_depth = 10 xgboost = create_model('xgboost', max_depth = 10) # train xgboost model on gpu xgboost_gpu = create_model('xgboost', tree_method = 'gpu_hist', gpu_id = 0) #0 is gpu-id # train multiple lightgbm models with n learning_rate<br>import numpy as np lgbms = [create_model('lightgbm', learning_rate = i) for i in np.arange(0.1,1,0.1)] # train custom model from gplearn.genetic import SymbolicClassifier symclf = SymbolicClassifier(generation = 50) sc = create_model(symclf)

回归例子:
# Importing dataset from pycaret.datasets import get_data boston = get_data('boston') # Importing module and initializing setup from pycaret.regression import * reg1 = setup(data = boston, target = 'medv') # train linear regression model lr = create_model('lr') #lr is the id of the model # check the model library to see all models models() # train rf model using 5 fold CV rf = create_model('rf', fold = 5) # train svm model without CV svm = create_model('svm', cross_validation = False) # train xgboost model with max_depth = 10 xgboost = create_model('xgboost', max_depth = 10) # train xgboost model on gpu xgboost_gpu = create_model('xgboost', tree_method = 'gpu_hist', gpu_id = 0) #0 is gpu-id # train multiple lightgbm models with n learning_rate import numpy as np lgbms = [create_model('lightgbm', learning_rate = i) for i in np.arange(0.1,1,0.1)] # train custom model from gplearn.genetic import SymbolicRegressor symreg = SymbolicRegressor(generation = 50) sc = create_model(symreg)

聚类例子:
# Importing dataset from pycaret.datasets import get_data jewellery = get_data('jewellery') # Importing module and initializing setup from pycaret.clustering import * clu1 = setup(data = jewellery) # check the model library to see all models models() # training kmeans model kmeans = create_model('kmeans') # training kmodes model kmodes = create_model('kmodes')
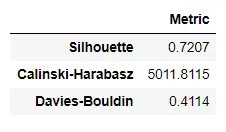
异常检测例子:
# Importing dataset from pycaret.datasets import get_data anomalies = get_data('anomalies') # Importing module and initializing setup from pycaret.anomaly import * ano1 = setup(data = anomalies) # check the model library to see all models models() # training Isolation Forest iforest = create_model('iforest') # training KNN model knn = create_model('knn')
自然语言处理例子:
# Importing dataset from pycaret.datasets import get_data kiva = get_data('kiva') # Importing module and initializing setup from pycaret.nlp import * nlp1 = setup(data = kiva, target = 'en') # check the model library to see all models models() # training LDA model lda = create_model('lda') # training NNMF model nmf = create_model('nmf')
关联规则例子:
# Importing dataset from pycaret.datasets import get_data france = get_data('france') # Importing module and initializing setup from pycaret.arules import * arule1 = setup(data = france, transaction_id = 'InvoiceNo', item_id = 'Description') # creating Association Rule model mod1 = create_model(metric = 'confidence')
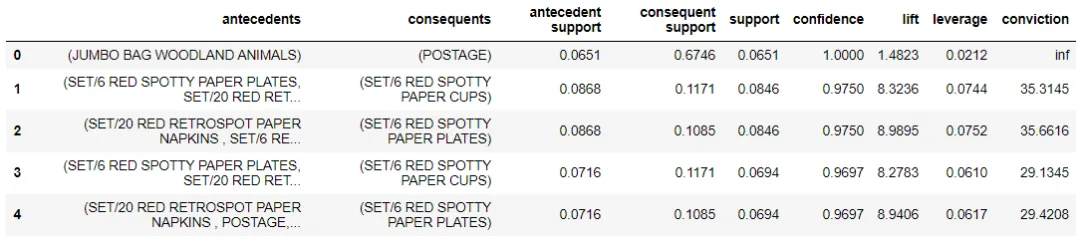
3、微调模型
在任何模块中调整机器学习模型的超参数就像编写tune_model一样简单。它使用带有完全可定制的预定义网格的随机网格搜索来调整作为估计量传递的模型的超参数。优化模型的超参数需要一个目标函数,该目标函数会在有监督的实验(例如分类或回归)中自动链接到目标变量。但是,对于诸如聚类,异常检测和自然语言处理之类的无监督实验,PyCaret允许您通过使用tune_model中的supervised_target参数指定受监督目标变量来定义自定义目标函数(请参见以下示例)。对于有监督的学习,此函数将返回一个表,该表包含k倍的通用评估指标的交叉验证分数以及训练有素的模型对象。对于无监督学习,此函数仅返回经过训练的模型对象。用于监督学习的评估指标是:
分类:准确性,AUC,召回率,精度,F1,Kappa,MCC
回归:MAE,MSE,RMSE,R2,RMSLE,MAPE
可以使用tune_model函数中的fold参数定义折叠次数。默认情况下,折叠倍数设置为10。默认情况下,所有指标均四舍五入到4位小数,可以使用round参数进行更改。 PyCaret中的音调模型功能是对预定义搜索空间进行的随机网格搜索,因此它依赖于搜索空间的迭代次数。默认情况下,此函数在搜索空间上执行10次随机迭代,可以使用tune_model中的n_iter参数进行更改。增加n_iter参数可能会增加训练时间,但通常会导致高度优化的模型。可以使用优化参数定义要优化的指标。默认情况下,回归任务将优化R2,而分类任务将优化Accuracy。
分类例子:
# Importing dataset from pycaret.datasets import get_data diabetes = get_data('diabetes') # Importing module and initializing setup from pycaret.classification import * clf1 = setup(data = diabetes, target = 'Class variable') # train a decision tree model dt = create_model('dt') # tune hyperparameters of decision tree tuned_dt = tune_model(dt) # tune hyperparameters with increased n_iter tuned_dt = tune_model(dt, n_iter = 50) # tune hyperparameters to optimize AUC tuned_dt = tune_model(dt, optimize = 'AUC') #default is 'Accuracy' # tune hyperparameters with custom_grid params = {"max_depth": np.random.randint(1, (len(data.columns)*.85),20), "max_features": np.random.randint(1, len(data.columns),20), "min_samples_leaf": [2,3,4,5,6], "criterion": ["gini", "entropy"] } tuned_dt_custom = tune_model(dt, custom_grid = params) # tune multiple models dynamically top3 = compare_models(n_select = 3) tuned_top3 = [tune_model(i) for i in top3]
回归例子:
from pycaret.datasets import get_data boston = get_data('boston') # Importing module and initializing setup from pycaret.regression import * reg1 = setup(data = boston, target = 'medv') # train a decision tree model dt = create_model('dt') # tune hyperparameters of decision tree tuned_dt = tune_model(dt) # tune hyperparameters with increased n_iter tuned_dt = tune_model(dt, n_iter = 50) # tune hyperparameters to optimize MAE tuned_dt = tune_model(dt, optimize = 'MAE') #default is 'R2' # tune hyperparameters with custom_grid params = {"max_depth": np.random.randint(1, (len(data.columns)*.85),20), "max_features": np.random.randint(1, len(data.columns),20), "min_samples_leaf": [2,3,4,5,6], "criterion": ["gini", "entropy"] } tuned_dt_custom = tune_model(dt, custom_grid = params) # tune multiple models dynamically top3 = compare_models(n_select = 3) tuned_top3 = [tune_model(i) for i in top3]
聚类例子:
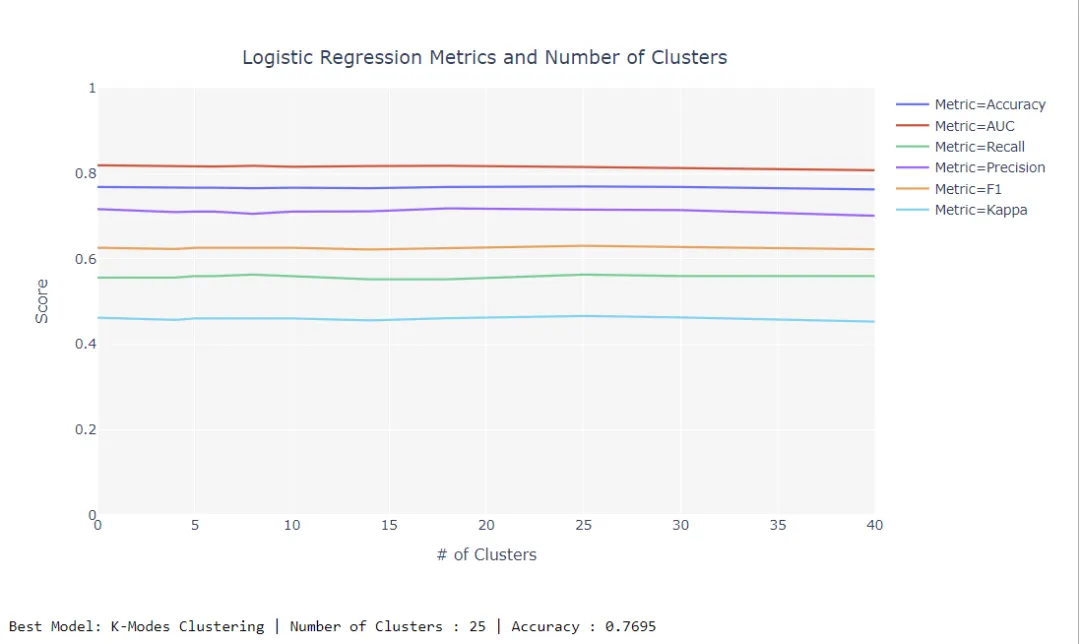
# Importing dataset from pycaret.datasets import get_data diabetes = get_data('diabetes') # Importing module and initializing setup from pycaret.clustering import * clu1 = setup(data = diabetes) # Tuning K-Modes Model tuned_kmodes = tune_model('kmodes', supervised_target = 'Class variable')
异常检测例子:
# Importing dataset from pycaret.datasets import get_data boston = get_data('boston') # Importing module and initializing setup from pycaret.anomaly import * ano1 = setup(data = boston) # Tuning Isolation Forest Model tuned_iforest = tune_model('iforest', supervised_target = 'medv')

自然语言例子:
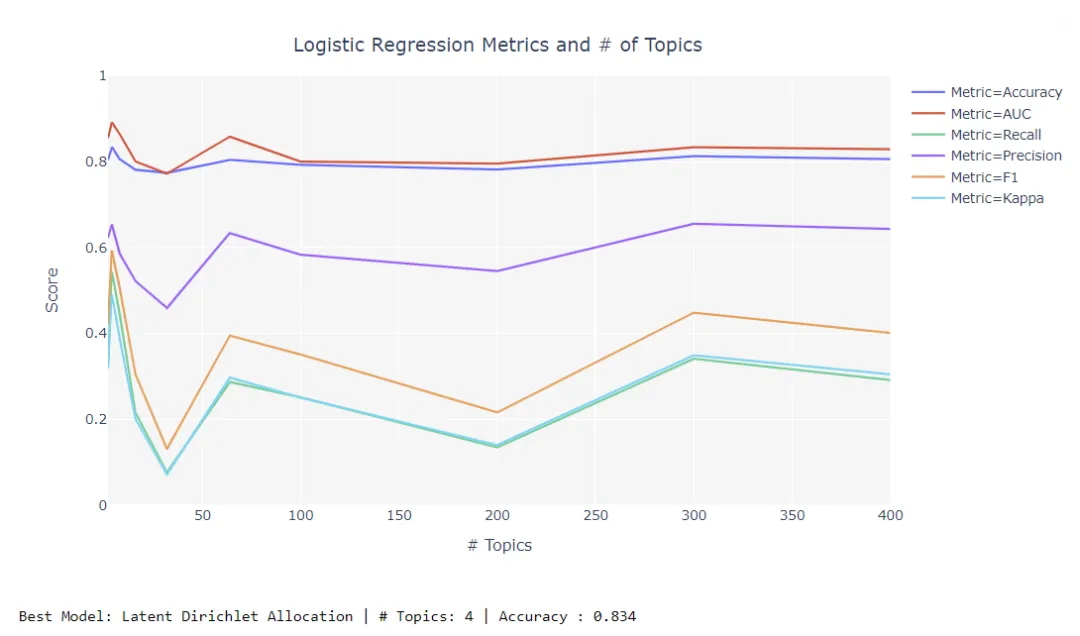
# Importing dataset from pycaret.datasets import get_data kiva = get_data('kiva') # Importing module and initializing setup from pycaret.nlp import * nlp1 = setup(data = kiva, target = 'en') # Tuning LDA Model tuned_lda = tune_model('lda', supervised_target = 'status')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号