
算法——查找
一、查找
查找:在一些数据元素中,通过一定的方法找出与给定关键字相同的数据元素的过程。
列表查找(线性表查找):从列表中查找指定元素。
- 输入:列表、待查找元素
- 输出:元素下标(未找到元素时一般返回None或-1)
python中内置列表查找函数:index()。
二、顺序查找(Linear Search)
顺序查找:也叫线性查找,从列表第一个元素开始,顺序进行搜索,直到找到元素或搜索到列表最后一个元素为止。
1、代码示例
def linear_search(li, val):
"""
顺序查找
:param li: 输入的列表
:param val: 输入的待查找的值
:return:
"""
for ind, v in enumerate(li): # index和值
if v == val:
return ind # 返回元素下标index
else:
# 循环完毕仍没找到
return None
2、时间复杂度分析
在这里n就是列表的长度,且并没有循环减半的过程,有一个与n相关的循环,因此时间复杂度是:O(n)。
三、二分查找(Binary Search)
二分查找:又叫做折半查找,从有序列表的初始候选区li[0:n]开始,通过对待查找的值与候选区中间值的比较,可以使候选区减少一半。
1、二分查找示例
(1)从列表中查找元素3:

(2)用left和right两个变量来维护候选区
初始的时候left=0,right=n-1
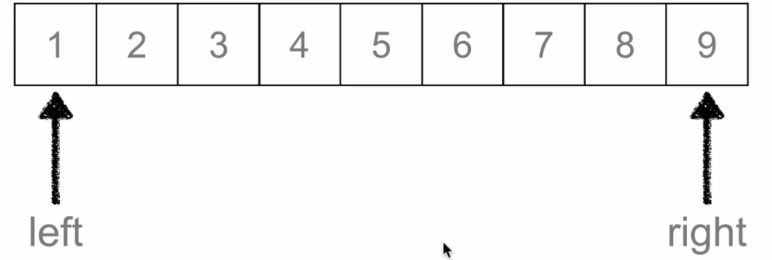
通过(left+right)/2求出中间元素5与3进行比较:
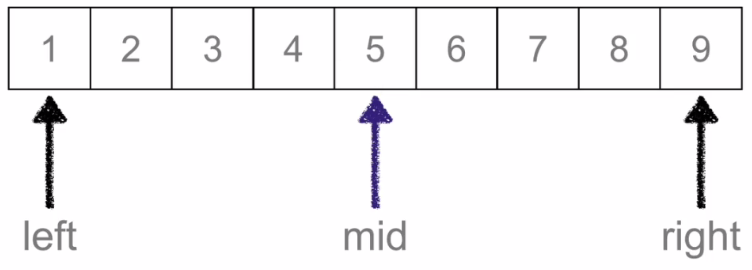
由于5比3大,候选区修改为mid的左边,right=mid-1,完成候选区修改:

计算出新的mid:(0+3)/2=1找到新的mid:

2比3小说明在mid的右边,需要移动left更新候选区,left=mid+1:
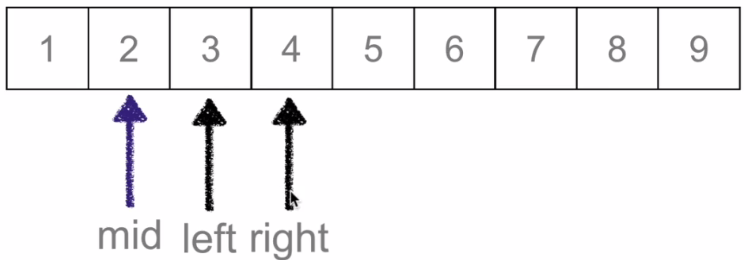
再次通过(2+3)/2=2找到mid的索引值:
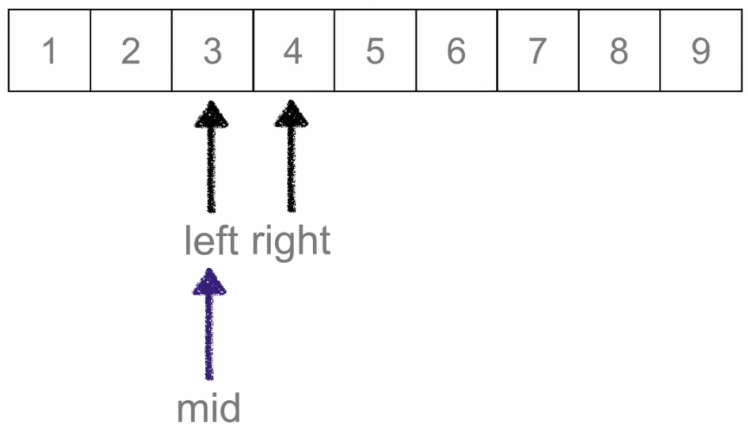
mid的值与要找的元素3一致,说明找到了,输出mid的下标。left如果大于right则候选区已经没有值了,说明找不到匹配的值。
2、二分查找代码
def binary_search(li, val):
"""
二分查找
:param li: 输入的列表
:param val: 输入的待查找的值
:return:
"""
left = 0
right = len(li) - 1
while left <= right: # 说明候选区有值
mid = (left + right) // 2 # 因为是下标, 因此要整除2
if li[mid] == val:
# 找到待查找的值返回index
return mid
elif li[mid] > val:
# 待查找的值在mid左侧
right = mid - 1 # 更新候选区
else: # li[mid] < val
# 待查找的值在mid右侧
left = mid + 1 # 更新候选区
else:
# 没有找到
return None
li = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(binary_search(li, 3)) # 输出:2(index值)
3、时间复杂度分析
由于二分查找是循环减半的,因此它的复杂度是:O(logn)。
可以得出:二分查找的效率比线性查找高。
测试验证:
cal_time.py:
import time
def cal_time(func):
def wrapper(*args, **kwargs):
t1 = time.time()
result = func(*args, **kwargs)
t2 = time.time()
print("%s running time: %s secs." % (func.__name__, t2 - t1))
return result
return wrapper
给二分查找和线性查找都对同一问题测试查看输出的值:
from cal_time import *
@cal_time
def linear_search(li, val):
"""
顺序查找
:param li: 输入的列表
:param val: 输入的待查找的值
:return:
"""
for ind, v in enumerate(li): # index和值
if v == val:
return ind # 返回元素下标index
else:
# 循环完毕仍没找到
return None
@cal_time
def binary_search(li, val):
"""
二分查找
:param li: 输入的列表
:param val: 输入的待查找的值
:return:
"""
left = 0
right = len(li) - 1
while left <= right: # 说明候选区有值
mid = (left + right) // 2 # 因为是下标, 因此要整除2
if li[mid] == val:
# 找到待查找的值返回index
return mid
elif li[mid] > val:
# 待查找的值在mid左侧
right = mid - 1 # 更新候选区
else: # li[mid] < val
# 待查找的值在mid右侧
left = mid + 1 # 更新候选区
else:
# 没有找到
return None
li = list(range(1000000))
# print(binary_search(li, 3)) # 输出:2(index值)
linear_search(li, 3800)
binary_search(li, 3800)
"""
linear_search running time: 0.0004601478576660156 secs.
binary_search running time: 2.193450927734375e-05 secs.
"""
由此可见二分查找的巨大优势。
四、总结
python中内置列表查找函数index()一定是顺序查找,因为二分查找要求列表必须是有序列表,但是Python的列表不一定是有序的,因此这个内置的查找函数一定是顺序查找。
因此在考虑选择顺序查找或者二分查找时,如果是有序的肯定是使用二分查找,如果是无序的则需要考虑是否要先进行排序。
排序的时间会非常长,如果查找就此一次那选用顺序查找,如果未来查找的次数会非常多,那可以先排序,未来再查找时速度就非常快了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号