【转载】NonEmpty和Non Empty的区别
转载来源:http://www.ssas-info.com/analysis-services-articles/50-mdx/2196-mdx-non-empty-vs-nonempty
One of my favourite questions in MDX is the difference between Non Empty and NonEmpty because even though many people use them daily to remove NULLS from their queries, very few understand the working behind it. Many times, I have even got answers like “there is a space between Non and Empty, that is the difference”. The objective of this post is to clearly differentiate between the two.
Let us say my initial query is
SELECT { [Measures].[Hits] ,[Measures].[Subscribers] ,[Measures].[Spam] } ON COLUMNS ,{ [Geography].[Country].Children } ON ROWS FROM [Blog Statistics];
This will give the following output

NON EMPTY
Non Empty is prefixed before the sets defining the axes and is used for removing NULLs. Let us see what happens when we add Non Empty on the Rows axis.
SELECT { [Measures].[Hits] ,[Measures].[Subscribers] ,[Measures].[Spam] } ON COLUMNS ,NON EMPTY { [Geography].[Country].Children } ON ROWS FROM [Blog Statistics];
The output is shown below
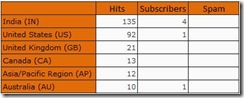
You will notice that Chile (CL) has been filtered out while rows like UK, Canada, etc are still there even if they have NULLs for some of the measures. In short, only the rows having NULL for all the members of the set defined in the column axis is filtered out. This is because the Non Empty operator works on the top level of the query. Internally, the sets defined for the axes are generated first and then the tuples having NULL values are removed. Now that we know how NON EMPTY works, it shouldn’t be hard for us to tell the output of the below query
SELECT NON EMPTY { [Measures].[Hits] ,[Measures].[Subscribers] ,[Measures].[Spam] } ON COLUMNS ,{ [Geography].[Country].Children } ON ROWS FROM [Blog Statistics];
The output is shown below
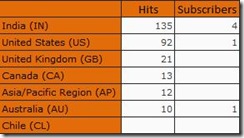
NONEMPTY()
The NonEmpty() returns the set of tuples that are not empty from a specified set, based on the cross product of the specified set with a second set. Suppose we want to see all the measures related to countries which have a non-null value for Subscribers
SELECT { [Measures].[Hits] ,[Measures].[Subscribers] ,[Measures].[Spam] } ON COLUMNS ,{ NonEmpty ( [Geography].[Country].Children ,[Measures].[Subscribers] ) } ON ROWS FROM [Blog Statistics];
This will give the following output
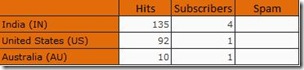
As you can see, the NonEmpty operator takes all the rows having a not NULL value for Subscribers in the rows and then displays all the measures defined in the column axis. Basically what happens internally is that NonEmpty is evaluated when the sets defining the axis are evaluated. So at this point of time, there is no context of the other axes. What I said now can be better understood from the following example
Now, we write the below query
SELECT {[Date].[Month].[March]} ON COLUMNS ,{ [Geography].[Country].Children } ON ROWS FROM [Blog Statistics] WHERE [Measures].[Hits];
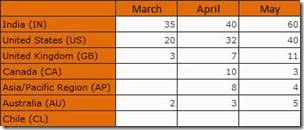
Output is given below
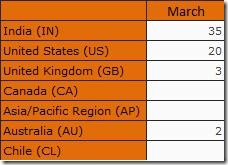
Think for a while and predict which all rows would be returned when the NonEmpty operator is applied on the rows
SELECT {[Date].[Month].[March]} ON COLUMNS ,{ NonEmpty([Geography].[Country].Children) } ON ROWS FROM [Blog Statistics] WHERE [Measures].[Hits];
If you guessed just IN, US, GB and AU, please go back and read once again. If you replied All rows except Chile, full marks to you, you have been an attentive reader. The reason is because NonEmpty is evaluated when the set defining the axis is evaluated (here, Country) and at that point of time, NonEmpty is evaluated for each member of the country against the default member of the Date dimension (which would be ALL generally). As you can see, we already have values for CA and AP for other months and hence they will not be filtered out.
Optimizing Non Empty by using NonEmpty
Ok, now you know how Non Empty and NonEmpty works internally and we can apply this knowledge to optimize our queries. Suppose there is a complex logic in our axes like finding all the countries that have 30 or more hits in any month. The query is given below
SELECT {[Measures].[Hits]} ON COLUMNS ,{ Filter ( [Geography].[Country].Children * [Date].[Month].Children , [Measures].[Hits] > 30 ) } ON ROWS FROM [Blog Statistics];
Now my time dimension will have 10 years of data, which means around 120 (10*12) members for the month attribute and my country attribute may have let’s say, 100 members. Now even though I just have 3 months of data for 10 countries for hits, the filter function will need to go through all the combinations of country and month (120*100 combinations). Instead of that, we can just use the NonEmpty operator and bring down the combinations to less than 30 (3 months*10 countries) by using the below query
SELECT {[Measures].[Hits]} ON COLUMNS ,{ Filter ( NonEmpty ( [Geography].[Country].Children * [Date].[Month].Children ,[Measures].[Hits] ) , [Measures].[Hits] > 30 ) } ON ROWS FROM [Blog Statistics];
作者:DataStrategy
出处:https://www.cnblogs.com/xiongnanbin/
联系:1183744742@qq.com;xiongnanbin@126.com
本文版权归作者和博客园共有(转载的归原作者所有),欢迎转载,但是请在文章页面明显位置给出原文连接。如有问题或建议,请多多留言、赐教,非常感谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号