Debezium监控MySQL,PGsql,SQLServer
1. Debezium简介
Debezium 是一个分布式平台,它将现有的数据库转换为事件流,应用程序消费事件流,就可以知道数据库中的每一个行级更改,并立即做出响应。
Debezium 构建在 Apache Kafka 之上,并提供 Kafka 连接器来监视特定的数据库。在介绍 Debezium 之前,我们要先了解一下什么是 Kafka Connect。
2. Debezium架构
最常见的是,Debezium是通过Apache Kafka连接部署的。Kafka Connect是一个用于实现和操作的框架和运行时
源连接器,如Debezium,它将数据摄取到Kafka和接收连接器,它将数据从Kafka主题传播到其他系统。下图显示了一个基于Debezium的CDC管道的架构:
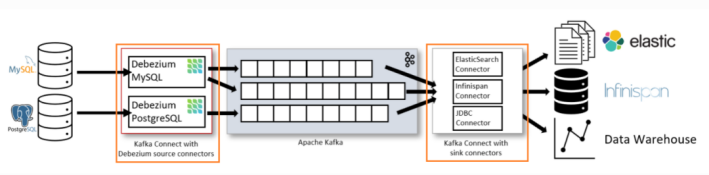
除了Kafka代理本身之外,Kafka Connect是作为一个单独的服务来操作的。部署了用于MySQL和Postgres的Debezium连接器来捕获这两个数据库的更改。为此,两个连接器使用客户端库建立到两个源数据库的连接,在使用MySQL时访问binlog,在使用Postgres时从逻辑复制流读取数据。
默认情况下,来自一个捕获表的更改被写入一个对应的Kafka主题。如果需要,可以在Debezium的主题路由SMT的帮助下调整主题名称,例如,使用与捕获的表名不同的主题名称,或者将多个表的更改转换为单个主题。
一旦更改事件位于Apache Kafka中,来自Kafka Connect生态系统的不同连接器就可以将更改流到其他系统和数据库,如Elasticsearch、数据仓库和分析系统或Infinispan等缓存。根据所选的接收连接器,可能需要应用Debezium的新记录状态提取SMT,它只会将“after”结构从Debezium的事件信封传播到接收连接器。
3. Debezium特性
Debezium是Apache Kafka Connect的一组源连接器,使用change data capture (CDC)从不同的数据库中获取更改。与其他方法如轮询或双写不同,基于日志的CDC由Debezium实现:
确保捕获所有数据更改以非常低的延迟(例如,MySQL或Postgres的ms范围)生成更改事件,同时避免增加频繁轮询的CPU使用量不需要更改数据模型(如“最后更新”列)可以捕获删除可以捕获旧记录状态和其他元数据,如事务id和引发查询(取决于数据库的功能和配置)要了解更多关于基于日志的CDC的优点,请参阅本文。
Debezium的实际变化数据捕获特性被修改了一系列相关的功能和选项:
快照:可选的,一个初始数据库的当前状态的快照可以采取如果连接器被启动并不是所有日志仍然存在(通常在数据库已经运行了一段时间和丢弃任何事务日志不再需要事务恢复或复制);快照有不同的模式,请参考特定连接器的文档以了解更多信息过滤器:可以通过白名单/黑名单过滤器配置捕获的模式、表和列集屏蔽:可以屏蔽特定列中的值,例如敏感数据监视:大多数连接器都可以使用JMX进行监视不同的即时消息转换:例如,用于消息路由、提取新记录状态(关系连接器、MongoDB)和从事务性发件箱表中路由事件有关所有受支持的数据库的列表,以及关于每个连接器的功能和配置选项的详细信息,请参阅连接器文档。
https://debezium.io/documentation/reference/1.5
4. Kafka Connect 简介
Kafka 相信大家都很熟悉,是一款分布式,高性能的消息队列框架。
一般情况下,读写 Kafka 数据,都是用 Consumer 和 Producer Api 来完成,但是自己实现这些需要去考虑很多额外的东西,比如管理 Schema,容错,并行化,数据延迟,监控等等问题。
而在 0.9.0.0 版本之后,官方推出了 Kafka Connect ,大大减少了程序员的工作量,它有下面的特性:
统一而通用的框架;
支持分布式模式和单机模式;
REST 接口,用来查看和管理Kafka connectors;
自动化的offset管理,开发人员不必担心错误处理的影响;
分布式、可扩展;
流/批处理集成。
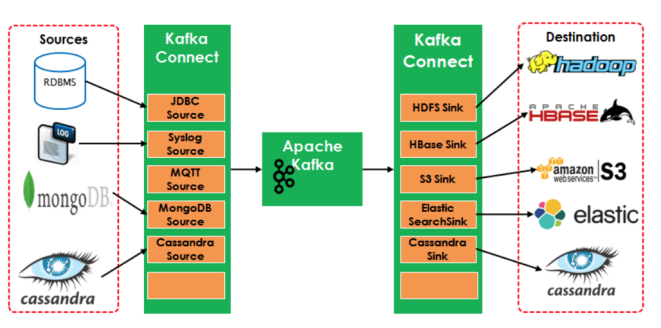
Kafka Connect 有两个核心的概念:Source 和 Sink,Source 负责导入数据到 Kafka,Sink 负责从 Kafka 导出数据,它们都被称为是 Connector。
如下图,左边的 Source 负责从源数据(RDBMS,File等)读数据到 Kafka,右边的 Sinks 负责从 Kafka 消费到其他系统。
5. Debezium的安装
因为Debezium依赖Kafka,Kafka依赖ZK,所以先把Kafka和ZK安装
5.1. ZK安装
5.1.1. 3.1 分布式安装部署
1)集群规划
在hadoop102、hadoop103和hadoop104三个节点上部署Zookeeper。
2)解压安装
(1)解压Zookeeper安装包到/opt/module/目录下
[atguigu@hadoop102 software]$ tar -zxvf zookeeper-3.5.7.tar.gz -C /opt/module/
(2)修改/opt/module/apache-zookeeper-3.5.7-bin名称为zookeeper-3.5.7
[atguigu@hadoop102 module]$ mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
(3)同步/opt/module/zookeeper-3.5.7目录内容到hadoop103、hadoop104
[atguigu@hadoop102 module]$ xsync zookeeper-3.5.7/
3)配置服务器编号
(1)在/opt/module/zookeeper-3.5.7/这个目录下创建zkData
[atguigu@hadoop102 zookeeper-3.5.7]$ mkdir zkData
(2)在/opt/module/zookeeper-3.5.7/zkData目录下创建一个myid的文件
[atguigu@hadoop102 zkData]$ vi myid
添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码
在文件中添加与server对应的编号:
2
(3)拷贝配置好的zookeeper到其他机器上
[atguigu@hadoop102 zkData]$ xsync myid
并分别在hadoop103、hadoop104上修改myid文件中内容为3、4
4)配置zoo.cfg文件
(1)重命名/opt/module/zookeeper-3.5.7/conf这个目录下的zoo_sample.cfg为zoo.cfg
[atguigu@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
(2)打开zoo.cfg文件
[atguigu@hadoop102 conf]$ vim zoo.cfg
修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.5.7/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
(3)同步zoo.cfg配置文件
[atguigu@hadoop102 conf]$ xsync zoo.cfg
(4)配置参数解读
server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B是这个服务器的地址;
C是这个服务器Follower与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
5)集群操作
(1)分别启动Zookeeper
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
[atguigu@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
[atguigu@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start
(2)查看状态
[atguigu@hadoop102 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: follower
[atguigu@hadoop103 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: leader
[atguigu@hadoop104 zookeeper-3.4.5]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: follower
5.1.2. 3.2 客户端命令行操作
|
命令基本语法 |
功能描述 |
|
help |
显示所有操作命令 |
|
ls path |
使用 ls 命令来查看当前znode的子节点 -w 监听子节点变化 -s 附加次级信息 |
|
create |
普通创建 -s 含有序列 -e 临时(重启或者超时消失) |
|
get path |
获得节点的值 -w 监听节点内容变化 -s 附加次级信息 |
|
set |
设置节点的具体值 |
|
stat |
查看节点状态 |
|
delete |
删除节点 |
|
deleteall |
递归删除节点 |
1)启动客户端
[atguigu@hadoop103 zookeeper-3.5.7]$ bin/zkCli.sh
5.2. Kafka安装
5.2.1. 集群规划
|
hadoop102 |
hadoop103 |
hadoop104 |
|
zk |
zk |
zk |
|
kafka |
kafka |
kafka |
5.2.2. jar包下载
http://kafka.apache.org/downloads
5.2.3. 集群部署
1)解压安装包
[atguigu@hadoop102 software]$ tar -zxvf kafka_2.11-2.4.1.tgz -C /opt/module/
2)修改解压后的文件名称
[atguigu@hadoop102 module]$ mv kafka_2.11-2.4.1/ kafka
3)在/opt/module/kafka目录下创建logs文件夹
[atguigu@hadoop102 kafka]$ mkdir logs
4)修改配置文件
[atguigu@hadoop102 kafka]$ cd config/
[atguigu@hadoop102 config]$ vi server.properties
修改或者增加以下内容:
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka/data
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
5)配置环境变量
[atguigu@hadoop102 module]$ sudo vi /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[atguigu@hadoop102 module]$ source /etc/profile.d/my_env.sh
6)分发安装包
[atguigu@hadoop102 module]$ xsync kafka/
注意:分发之后记得配置其他机器的环境变量
7)分别在hadoop103和hadoop104上修改配置文件/opt/module/kafka/config/server.properties中的broker.id=1、broker.id=2
注:broker.id不得重复
8)启动集群
依次在hadoop102、hadoop103、hadoop104节点上启动kafka
[atguigu@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
[atguigu@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
[atguigu@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
9)关闭集群
[atguigu@hadoop102 kafka]$ bin/kafka-server-stop.sh
[atguigu@hadoop103 kafka]$ bin/kafka-server-stop.sh
[atguigu@hadoop104 kafka]$ bin/kafka-server-stop.sh
10)kafka群起脚本
(1)在/home/atguigu/bin目录下创建脚本kf.sh
[atguigu@hadoop102 bin]$ vim kf.sh
在脚本中填写如下内容
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties "
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh stop"
done
};;
esac
(2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 kf.sh
(3)kf集群启动脚本
[atguigu@hadoop102 module]$ kf.sh start
(4)kf集群停止脚本
[atguigu@hadoop102 module]$ kf.sh stop
5.2.4. Kafka命令行操作
1)查看当前服务器中的所有topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --list
2)创建topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka \
--create --replication-factor 3 --partitions 1 --topic first
选项说明:
--topic 定义topic名
--replication-factor 定义副本数
--partitions 定义分区数
3)删除topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka \
--delete --topic first
需要server.properties中设置delete.topic.enable=true否则只是标记删除。
4)发送消息
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh \
--broker-list hadoop102:9092 --topic first
>hello world
>atguigu atguigu
5)消费消息
[atguigu@hadoop103 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic first
[atguigu@hadoop103 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic first
--from-beginning:会把主题中以往所有的数据都读取出来。
6)查看某个Topic的详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka \
--describe --topic first
7)修改分区数
[atguigu@hadoop102 kafka]$bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --alter --topic first --partitions 6
5.3. Debezium安装
5.3.1. 安装包下载
https://repo1.maven.org/maven2/io/debezium/
我这边选择的都是1.5版本
MySQL包下载地址
PGSql包下载地址
SqlServer下载地址
5.3.2. 部署安装
1) 上传解压安装包
上传压缩包到/opt/software目录下

解压压缩包到/opt/module/kafka/plugins目录下
新建文件夹plugins
mkdir -p /opt/module/kafka/plugins
解压文件(Oracle暂时还没有验证通过)
tar -zxvf debezium-connector-mysql-1.5.0.Final-plugin.tar.gz -C /opt/module/kafka/plugins
tar -zxvf debezium-connector-postgres-1.5.0.Final-plugin.tar.gz -C /opt/module/kafka/plugins
tar -zxvf debezium-connector-sqlserver-1.5.0.Final-plugin.tar.gz -C /opt/module/kafka/plugins
2) 修改配置文件
进入kafka配置文件
修改connect-distributed.properties文件
[atguigu@hadoop102 config]$ pwd
/opt/module/kafka/config
[atguigu@hadoop102 config]$ vim connect-distributed.properties
# 配置插件位置
plugin.path=/opt/module/kafka/plugins/
# 把key和value的schemas去掉,减少冗余存储
key.converter.schemas.enable=false
value.converter.schemas.enable=false
分发plugins文件和connect-distributed.properties到其它机器
3) 启动连接器
[atguigu@hadoop102 kafka]$ bin/connect-distributed.sh -daemon config/connect-distributed.properties
[atguigu@hadoop102 config]$ jps
41232 QuorumPeerMain
50594 ConnectDistributed
52212 Jps
41644 Kafka
4) 查看日志
[atguigu@hadoop102 kafka]$ tail -f logs/connectDistributed.out
5) 查看是否正常启动
[atguigu@hadoop102 kafka]$ curl -H "Accept:application/json" hadoop102:8083/connectors/
[]
# 返回空列表,表示正常启动
6. Debezium实操案例
参考官网:
https://debezium.io/documentation/reference/1.5/connectors/mysql.html
6.1. Debezium监控MySQL
1)准备MySQL
查看MySQL配置文件路径
[atguigu@hadoop102 etc]$ sudo find / -name my.cnf
/etc/my.cnf
#添加如下配置
log-bin=/var/lib/mysql/mysql-bin.log # 指定binlog日志存储位置
binlog_format=ROW # 这里一定是row格式
expire-logs-days = 14 # 日志保留时间
max-binlog-size = 500M # 日志滚动大小
server-id=1
重启数据库,然后查看日志是否开启
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.01 sec)
2)配置MySQL连接信息
[atguigu@hadoop102 config]$ curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" hadoop102:8083/connectors/ -d '{"name":"bd_test-mysql-connector","config":{"connector.class":"io.debezium.connector.mysql.MySqlConnector","tasks.max":"1","database.hostname":"localhost","database.port":"3306","database.user":"bd_test","database.password":"123456","database.server.id":"184054","database.server.name":"bd_test","database.include.list":"test_db","database.history.kafka.bootstrap.servers":"hadoop102:9092","database.history.kafka.topic":"dbhistory.test_db","decimal.handling.mode":"String","snapshot.mode":"schema_only","tombstones.on.delete":"false","table.include.list":"test_db.test0430,test_db.zd_business_type,test_db.zd_business_type_copy1,test_db.zd_business_type_copy2"}}'
3)格式化(方便查看)
{
"name":"bd_test-mysql-connector",
"config":{
"connector.class":"io.debezium.connector.mysql.MySqlConnector",
"tasks.max":"1",
"database.hostname":"localhost",
"database.port":"3306",
"database.user":"bd_test",
"database.password":"123456",
"database.server.id":"184054",
"database.server.name":"bd_test",
"database.include.list":"test_db",
"database.history.kafka.bootstrap.servers":"hadoop102:9092",
"database.history.kafka.topic":"dbhistory.test_db",
"decimal.handling.mode":"String",
"snapshot.mode":"schema_only",
"tombstones.on.delete":"false",
"table.include.list":"test_db.test0430,test_db.zd_business_type,test_db.zd_business_type_copy1,test_db.zd_business_type_copy2"
}
}
4)参数解析
name:标识连接器的名称
connector.class:对应数据库类
tasks.max:默认1
database.hostname:数据库ip
database.port:数据库端口
database.user:数据库登录名
database.password:数据库密码
database.server.id:数据库id,标识当前库,不重复就行
database.server.name:给数据库取别名
database.include.list:类似白名单,里面的库可以监控到,不在里面监控不到,多库逗号分隔,支持正则匹配
database.history.kafka.bootstrap.servers:表DDL相关信息知道kafka地址
database.history.kafka.topic:表DDL相关信息会保存在这个topic里面
decimal.handling.mode:当处理decimal和Int类型时,默认是二进制显示,我们改为字符串显示
snapshot.mode:快照模式,这个需要具体情况,具体分析,因为我只需要实时数据,不需要历史数据,所以设置为schema_only
tombstones.on.delete:默认是True,当我们删除记录的时候,会产生两天数据,第二条为NULL,但是我们不希望出现NULL,所以设置为False
table.include.list:类似白名单,里面的表可以监控到,不在里面监控不到,多表逗号分隔,支持正则匹配
5)查看是否新建成功
[atguigu@hadoop102 config]$ curl -H "Accept:application/json" hadoop102:8083/connectors/
["bd_test-mysql-connector"]
# 出现刚刚配置的名称说明成功新建
6)查看Kafka的Topic信息
[atguigu@hadoop103 bin]$ ./kafka-topics.sh --bootstrap-server hadoop102:9092 --list
7)可以往mysql插入数据,然后查看对应Topic的是否有数据,只要表数据进行更新,Topic会自动创建。
6.2. Debezium监控PGSql
1)准备PGSql
Ø 更改配置文件postgresql.conf
# 更改wal日志方式为logical
wal_level = logical # minimal, replica, or logical
# 中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认60s)
wal_sender_timeout = 180s # in milliseconds; 0 disable
Ø 重启pg服务生效,所以一般是在业务低峰期更改
Ø 新建用户并且给用户复制流权限
-- pg新建用户
CREATE USER user WITH PASSWORD 'pwd';
-- 给用户复制流权限
ALTER ROLE user replication;
-- 给用户登录数据库权限
grant CONNECT ON DATABASE test to user;
-- 把当前库public下所有表查询权限赋给用户
GRANT SELECT ON ALL TABLES IN SCHEMA public TO user;
Ø 发布表
-- 更改复制标识包含更新和删除之前值
ALTER TABLE test0425 REPLICA IDENTITY FULL;
-- 查看复制标识(为f标识说明设置成功)
select relreplident from pg_class where relname='test0425';
Ø 更改表的复制标识包含更新和删除的值
-- 更改复制标识包含更新和删除之前值
ALTER TABLE test0425 REPLICA IDENTITY FULL;
-- 查看复制标识(为f标识说明设置成功)
select relreplident from pg_class where relname='test0425';
2)配置PGsql连接信息
[atguigu@hadoop102 config]$ curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" hadoop102:8083/connectors/ -d '{"name":"pgsql-connector","config":{"connector.class":"io.debezium.connector.postgresql.PostgresConnector","database.hostname":"localhost","database.port":"5432","database.user":"bd_test","database.password":"123456","database.dbname":"bd_test","database.server.name":"pgsql_cs","schema.include.list":"public","slot.name":"pgsql_cs_slot","snapshot.mode":"never","table.include.list":"public.test0425,public.test0425_copy1,public.zd_business_type_copy1","publication.autocreate.mode":"filtered","decimal.handling.mode":"String","heartbeat.interval.ms":"100","tombstones.on.delete":"false","plugin.name":"pgoutput"}}'
3)格式化(方便查看)
{
"name":"pgsql-connector",
"config":{
"connector.class":"io.debezium.connector.postgresql.PostgresConnector",
"database.hostname":"localhost",
"database.port":"5432",
"database.user":"bd_test",
"database.password":"123456",
"database.dbname":"bd_test",
"database.server.name":"pgsql_cs",
"schema.include.list":"public",
"slot.name":"pgsql_cs_slot",
"snapshot.mode":"never",
"table.include.list":"public.test0425,public.test0425_copy1",
"publication.autocreate.mode":"filtered",
"decimal.handling.mode":"String",
"heartbeat.interval.ms":"100",
"tombstones.on.delete":"false",
"plugin.name":"pgoutput"
}
}
4)参数解析
name:标识连接器的名称
connector.class:对应数据库类
database.hostname:数据库ip
database.port:数据库端口
database.user:数据库登录名
database.password:数据库密码
database.dbname:数据库名称
database.server.name:给数据库取别名
schema.include.list:类似白名单,里面的模式可以监控到,不在里面监控不到,多模式逗号分隔,支持正则匹配
slot.name:slot的名称
snapshot.mode:快照模式,这个需要具体情况,具体分析,因为我只需要实时数据,不需要历史数据,所以设置为never
table.include.list:类似白名单,里面的表可以监控到,不在里面监控不到,多表逗号分隔,支持正则匹配
publication.autocreate.mode:发布表处理策略,具体查看官网
decimal.handling.mode:当处理decimal和Int类型时,默认是二进制显示,我们改为字符串显示
heartbeat.interval.ms:控制连接器向 Kafka 主题发送心跳消息的频率。默认行为是连接器不发送心跳消息(毫秒)
tombstones.on.delete:默认是True,当我们删除记录的时候,会产生两天数据,第二条为NULL,但是我们不希望出现NULL,所以设置为False
plugin.name:使用pgoutput插件,是pgsql自带的,不需要安装
5)查看是否新建成功
[atguigu@hadoop102 config]$ curl -H "Accept:application/json" hadoop102:8083/connectors/
["bd_test-mysql-connector"]
# 出现刚刚配置的名称说明成功新建
6)查看Kafka的Topic信息
[atguigu@hadoop103 bin]$ ./kafka-topics.sh --bootstrap-server hadoop102:9092 --list
7)可以往PGSQL表插入数据,然后查看对应Topic的是否有数据,只要表数据进行更新,Topic会自动创建。
6.3. Debezium监控SQLServer
1)准备SqlServer
启用表cdc
USE TestDB
GO
EXEC sys.sp_cdc_enable_db
GO
启用表cdc
USE TestDB
GO
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'tableName',
@role_name = NULL,
@supports_net_changes = 1
GO
查询是否启用
-- 库是否启用cdc
SELECT name,is_cdc_enabled
FROM sys.databases;
-- 表是否启用cdc
SELECT name,is_tracked_by_cdc
FROM sys.tables;
2)配置SQLServer连接信息
[atguigu@hadoop102 config]$ curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" hadoop102:8083/connectors/ -d '{"name":"SqlServer-connector","config":{"connector.class":"io.debezium.connector.sqlserver.SqlServerConnector","database.hostname":"localhost","database.port":"1433","database.user":"bd_test","database.password":"123456","database.dbname":"TestDB","database.server.name":"sql_server_test","snapshot.mode":"schema_only","table.include.list":"dbo.test0601,dbo.test0531","decimal.handling.mode":"String","heartbeat.interval.ms":"100","database.history.kafka.bootstrap.servers":"hadoop102:9092","database.history.kafka.topic":"sql_server_test.dbhistory","tombstones.on.delete":"false"}}'
3)格式化(可读性强)
{
"name":"SqlServer-connector",
"config":{
"connector.class":"io.debezium.connector.sqlserver.SqlServerConnector",
"database.hostname":"localhost",
"database.port":"1433",
"database.user":"bd_test",
"database.password":"123456",
"database.dbname":"TestDB",
"database.server.name":"sql_server_test",
"snapshot.mode":"schema_only",
"table.include.list":"dbo.test0601,dbo.test0531",
"decimal.handling.mode":"String",
"heartbeat.interval.ms":"100",
"database.history.kafka.bootstrap.servers":"hadoop102:9092",
"database.history.kafka.topic":"sql_server_test.dbhistory",
"tombstones.on.delete":"false"
}
}
4)参数解析
name:标识连接器的名称
connector.class:对应数据库类
database.hostname:数据库ip
database.port:数据库端口
database.user:数据库登录名
database.password:数据库密码
database.server.name:给数据库取别名
snapshot.mode:快照模式,这个需要具体情况,具体分析,因为我只需要实时数据,不需要历史数据,所以设置为schema_only
database.include.list:类似白名单,里面的库可以监控到,不在里面监控不到,多库逗号分隔,支持正则匹配
decimal.handling.mode:当处理decimal和Int类型时,默认是二进制显示,我们改为字符串显示
heartbeat.interval.ms:控制连接器向 Kafka 主题发送心跳消息的频率。默认行为是连接器不发送心跳消息(毫秒)
database.history.kafka.bootstrap.servers:表DDL相关信息知道kafka地址
database.history.kafka.topic:表DDL相关信息会保存在这个topic里面
tombstones.on.delete:默认是True,当我们删除记录的时候,会产生两天数据,第二条为NULL,但是我们不希望出现NULL,所以设置为False
5)查看是否新建成功
[atguigu@hadoop102 config]$ curl -H "Accept:application/json" hadoop102:8083/connectors/
["SqlServer-connector"]
# 出现刚刚配置的名称说明成功新建
6)查看Kafka的Topic信息
[atguigu@hadoop103 bin]$ ./kafka-topics.sh --bootstrap-server hadoop102:9092 --list
7)可以往SQLServer插入数据,然后查看对应Topic的是否有数据,只要表数据进行更新,Topic会自动创建。
6.4. Debezium监控Oracle(不推荐用)
Debezium使用本机LogMiner数据库包或XStream API从Oracle接收变更事件。虽然连接器可以与各种Oracle版本和版本配合使用,但只有Oracle EE 12和19经过测试。
1)准备Oracle
新建用户
create user userName identified by '123456';
给用户赋权限
UGRANT CREATE SESSION TO userName ;
GRANT SET CONTAINER TO userName ;
GRANT SELECT ON V_$DATABASE to userName ;
GRANT FLASHBACK ANY TABLE TO userName ;
GRANT SELECT ANY TABLE TO userName ;
GRANT SELECT_CATALOG_ROLE TO userName ;
GRANT EXECUTE_CATALOG_ROLE TO userName ;
GRANT SELECT ANY TRANSACTION TO userName ;
GRANT LOGMINING TO userName ;
GRANT CREATE TABLE TO userName ;
GRANT LOCK ANY TABLE TO userName ;
GRANT ALTER ANY TABLE TO userName ;
GRANT CREATE SEQUENCE TO userName ;
GRANT EXECUTE ON DBMS_LOGMNR TO userName ;
GRANT EXECUTE ON DBMS_LOGMNR_D TO userName ;
GRANT SELECT ON V_$LOG TO userName ;
GRANT SELECT ON V_$LOG_HISTORY TO userName ;
GRANT SELECT ON V_$LOGMNR_LOGS TO userName ;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO userName ;
GRANT SELECT ON V_$LOGMNR_PARAMETERS TO userName ;
GRANT SELECT ON V_$LOGFILE TO userName ;
GRANT SELECT ON V_$ARCHIVED_LOG TO userName ;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO userName ;
grant connect to userName;
开启表补充日志,开启LOG_MODE模式为ARCHIVELOG
--给库表开启补充日志,所有表都要执行
SQL> ALTER DATABASE add SUPPLEMENTAL LOG DATA ;
SQL> ALTER TABLE inventory.test ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
--登录Oracle
[root@hadoop102 bin]$ su - oracle
[oracle@hadoop102 bin]$ sqlplus /nolog
SQL> conn /as sysdba
-- 开启ARCHIVELOG
关闭数据库
SQL> shutdown immediate;
启动数据库到mount状态
SQL> startup mount;
启动归档模式
SQL> alter database archivelog;
启动数据库
SQL> alter database open;
查看是否开启
SQL> archive log list
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 114
Next log sequence to archive 114
Current log sequence 117
2)配置Oracle连接信息
[atguigu@hadoop102 config]$ curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" hadoop102:8083/connectors/ -d '{"name":"SqlServer-connector","config":{"connector.class":"io.debezium.connector.sqlserver.SqlServerConnector","database.hostname":"localhost","database.port":"1433","database.user":"bd_test","database.password":"123456","database.dbname":"TestDB","database.server.name":"sql_server_test","snapshot.mode":"schema_only","table.include.list":"dbo.test0601,dbo.test0531","decimal.handling.mode":"String","heartbeat.interval.ms":"100","database.history.kafka.bootstrap.servers":"hadoop102:9092","database.history.kafka.topic":"sql_server_test.dbhistory","tombstones.on.delete":"false"}}'
3)格式化(可读性强)
{
"name":"SqlServer-connector",
"config":{
"connector.class":"io.debezium.connector.sqlserver.SqlServerConnector",
"database.hostname":"localhost",
"database.port":"1433",
"database.user":"bd_test",
"database.password":"123456",
"database.dbname":"TestDB",
"database.server.name":"sql_server_test",
"snapshot.mode":"schema_only",
"table.include.list":"dbo.test0601,dbo.test0531",
"decimal.handling.mode":"String",
"heartbeat.interval.ms":"100",
"database.history.kafka.bootstrap.servers":"hadoop102:9092",
"database.history.kafka.topic":"sql_server_test.dbhistory",
"tombstones.on.delete":"false"
}
}
4)参数解析
name:标识连接器的名称
connector.class:对应数据库类
database.hostname:数据库ip
database.port:数据库端口
database.user:数据库登录名
database.password:数据库密码
database.server.name:给数据库取别名
snapshot.mode:快照模式,这个需要具体情况,具体分析,因为我只需要实时数据,不需要历史数据,所以设置为schema_only
database.include.list:类似白名单,里面的库可以监控到,不在里面监控不到,多库逗号分隔,支持正则匹配
decimal.handling.mode:当处理decimal和Int类型时,默认是二进制显示,我们改为字符串显示
heartbeat.interval.ms:控制连接器向 Kafka 主题发送心跳消息的频率。默认行为是连接器不发送心跳消息(毫秒)
database.history.kafka.bootstrap.servers:表DDL相关信息知道kafka地址
database.history.kafka.topic:表DDL相关信息会保存在这个topic里面
tombstones.on.delete:默认是True,当我们删除记录的时候,会产生两天数据,第二条为NULL,但是我们不希望出现NULL,所以设置为False
5)查看是否新建成功
[atguigu@hadoop102 config]$ curl -H "Accept:application/json" hadoop102:8083/connectors/
["SqlServer-connector"]
# 出现刚刚配置的名称说明成功新建
6)查看Kafka的Topic信息
[atguigu@hadoop103 bin]$ ./kafka-topics.sh --bootstrap-server hadoop102:9092 --list
7)可以往Oracle插入数据,然后查看对应Topic的是否有数据,只要表数据进行更新,Topic会自动创建。
7. Flink消费Kafka数据
7.1. 大致配置信息
消费的时候指定为'value.format' = 'debezium-json'

这样就能消费到数据,使用cdc的方式进行消费,也可以获取一些其它的值,比如时间戳,表名称,库名称等等字段信息,增删改变化目标表会同步相应操作。
具体看Flink官方文档
https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/connectors/table/formats/debezium/
7.2. 案例:把kafka数据写入到mysql中采用debezium-json的方式进行format
7.2.1. 新建MySql输出表
create table `test02` (
`name` varchar(100) not null primary key,
`amount` double
);
7.2.2. 代码示例如下
package flinkTest.connect;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class kafkaTomysql {
public static void main(String[] args) {
//设置flink表环境变量
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
//获取flink流环境变量
StreamExecutionEnvironment exeEnv = StreamExecutionEnvironment.getExecutionEnvironment();
exeEnv.setParallelism(1);
//表执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(exeEnv, fsSettings);
String sourceDDL =
"CREATE TABLE kafka_source (\n" +
" id int,\n" +
" name STRING,\n" +
" age int,\n" +
" addr STRING,\n" +
" sku_id int,\n" +
" sku_name STRING,\n" +
" amount double,\n" +
" create_time timestamp,\n" +
" PRIMARY KEY (id) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'flink_test',\n" +
" 'properties.bootstrap.servers' = 'hadoop102:9092',\n" +
" 'value.format' = 'debezium-json'\n" +
")";
//拼接sinkDLL
String sinkDDL =
"CREATE TABLE mysql_sink (\n" +
" name STRING,\n" +
" amount double,\n" +
" PRIMARY KEY (name) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
// " 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'url' = 'jdbc:mysql://123.57.104.176:3306/flink_cs?useUnicode=true&characterEncoding=UTF-8',\n" +
" 'username' = 'root',\n" +
" 'password' = '000000',\n" +
" 'table-name' = 'test02'\n" +
")";
String transformSQL =
"INSERT INTO mysql_sink " +
"SELECT name,sum(amount) " +
"FROM kafka_source group by name";
//执行source表ddl
tableEnv.executeSql(sourceDDL);
//执行sink表ddl
tableEnv.executeSql(sinkDDL);
//执行逻辑sql语句
TableResult tableResult = tableEnv.executeSql(transformSQL);
}
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号