
各种Attention机制
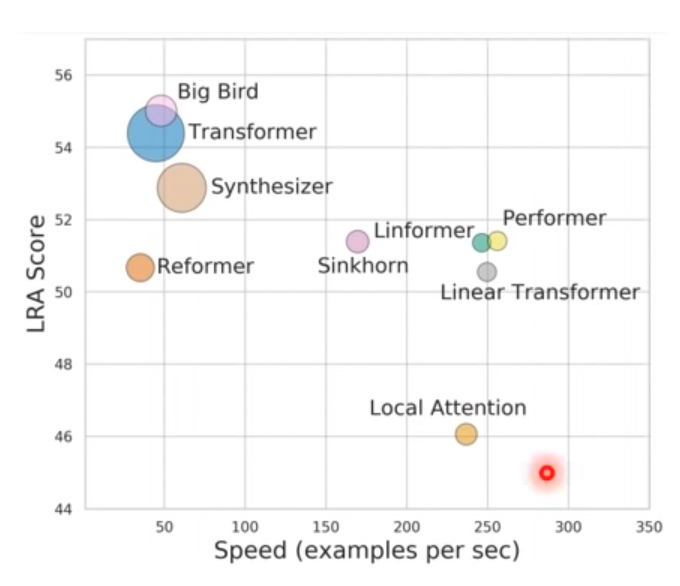
下面是9种Attention机制,右边LRA表示性能,下面坐标表示速度。
Big Bird 是指小孩子才做选择的一种Attention机制,里面包含了local,global,随机多种attention机制。
Transformer是最原始的self-Attention,速度比较慢,但性能比较好。
Synthesizer 是全新的想法, attention matrix不需要用q,a产生,直接当network的参数。性能掉了一点,速度快了一点
Reformer 做clustering选择重要区域做attention
Local attention 就是速度很快,performance有点惨的方法
Sinkhore 直接用网络决定哪些地方要上attention哪些位置不需要attention
Linformer,performer,linear transformer三种是速度比较快的,性能掉了一些的attention机制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号