


与非负矩阵分解(NMF)相关的数学公式及方法
本文主要是针对疾病基因预测方向,非负矩阵分解的应用
1. 目标函数:
1. 非负矩阵分解(NMF)
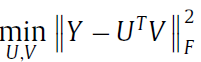
Y是miRNA与disease的关系, U代表了所有miRNA的特征, V代表了所有disease的特征, 将Y分解为U和V
最小化这个公式,将通过已知的Y得到两个非负矩阵U和V
2. 加Graph regularization的NMF(根据manifold learning 和 spectral grapg theories)(又叫manifold regularization, Laplacian regularization)
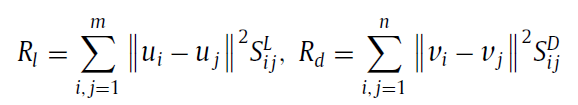
主要根据是:如果两个miRNA非常相似,也就是Sij很大, 那么他们在映射后的特征ui 和 uj 还是很相似。这部分主要是为了保证miRNA和disease的特征中相对位置没有改变,如固有的几何结构。
Rd = 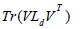 , Ld = Dd - Sd, Dd is the diagonal matrix whose entries are the row sums of of Sd.
, Ld = Dd - Sd, Dd is the diagonal matrix whose entries are the row sums of of Sd.
3. 确保特征矩阵U和V的平滑(Tikhonov ( L 2 ) regularization to ensure U and V smoothness)
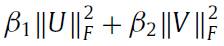
防止一行特征中只有少数几个值分散开这种情况,例如[0,0,1,0,0,0,0],我们要尽可能得到一个稀疏的每一维都有意义的特征
在非负矩阵分解的情况下,当特征值越分散的时候,二范数的值越小
最终的objective function 是:
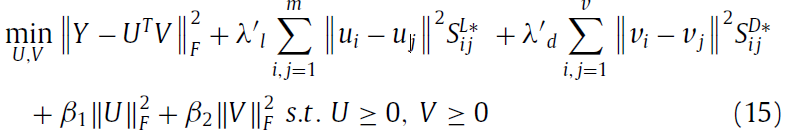
2. 解这个目标函数用到的相关数学知识:
矩阵迹 Tr(A) 的相关知识:
(1)设有N阶矩阵A,那么矩阵A的迹(用 Tr(A) 表示)就等于A的特征值的总和,也即矩阵A的主对角线元素的总和。
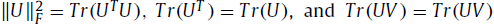
如果矩阵M是对称的,那么即使矩阵H不对称, H*M*HT 仍然是对称的。
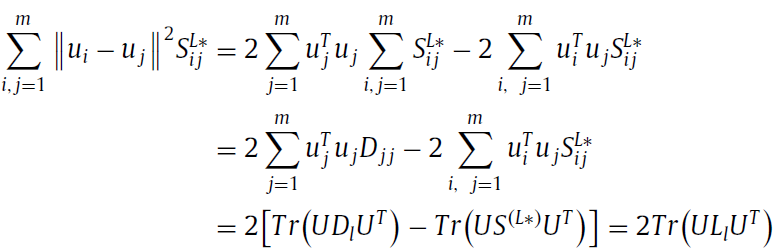
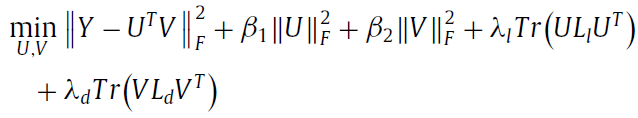
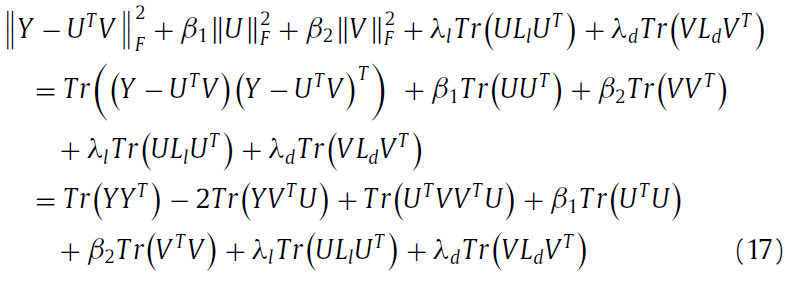
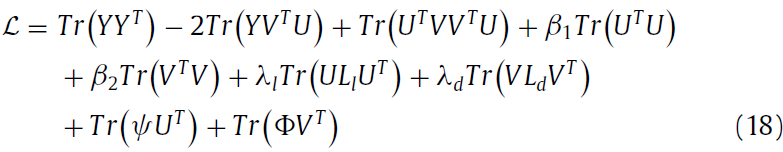
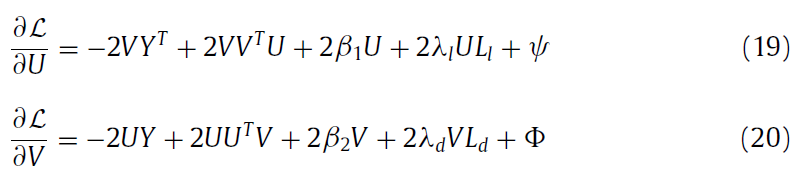
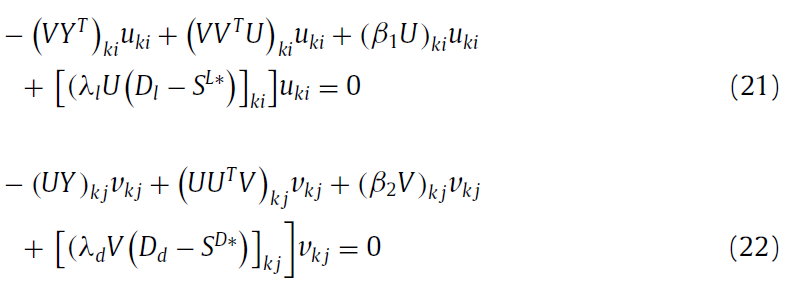
根据KTT condation, 得到下面更新公式:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号