

spark SQL前世今生





Spark SQL架构
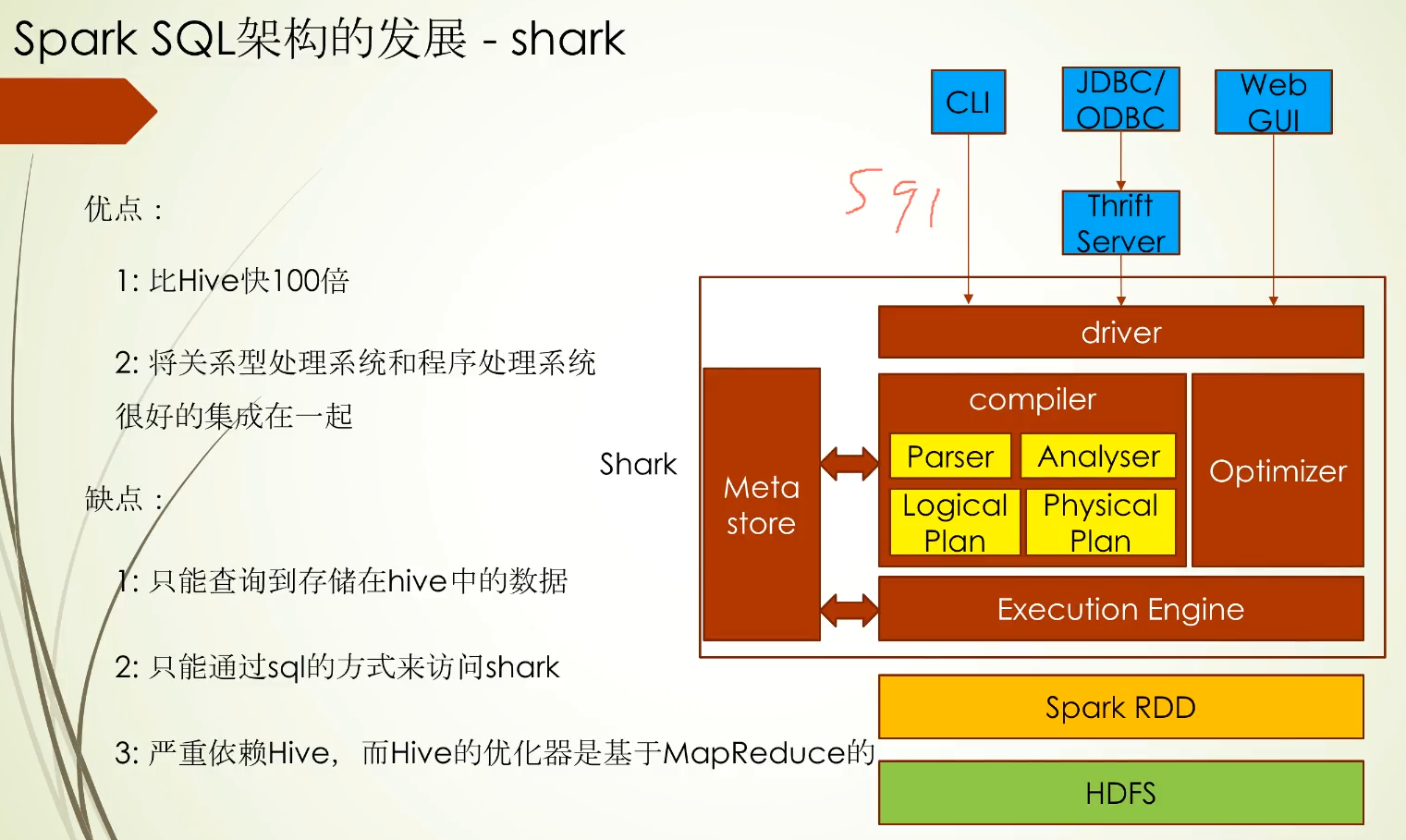
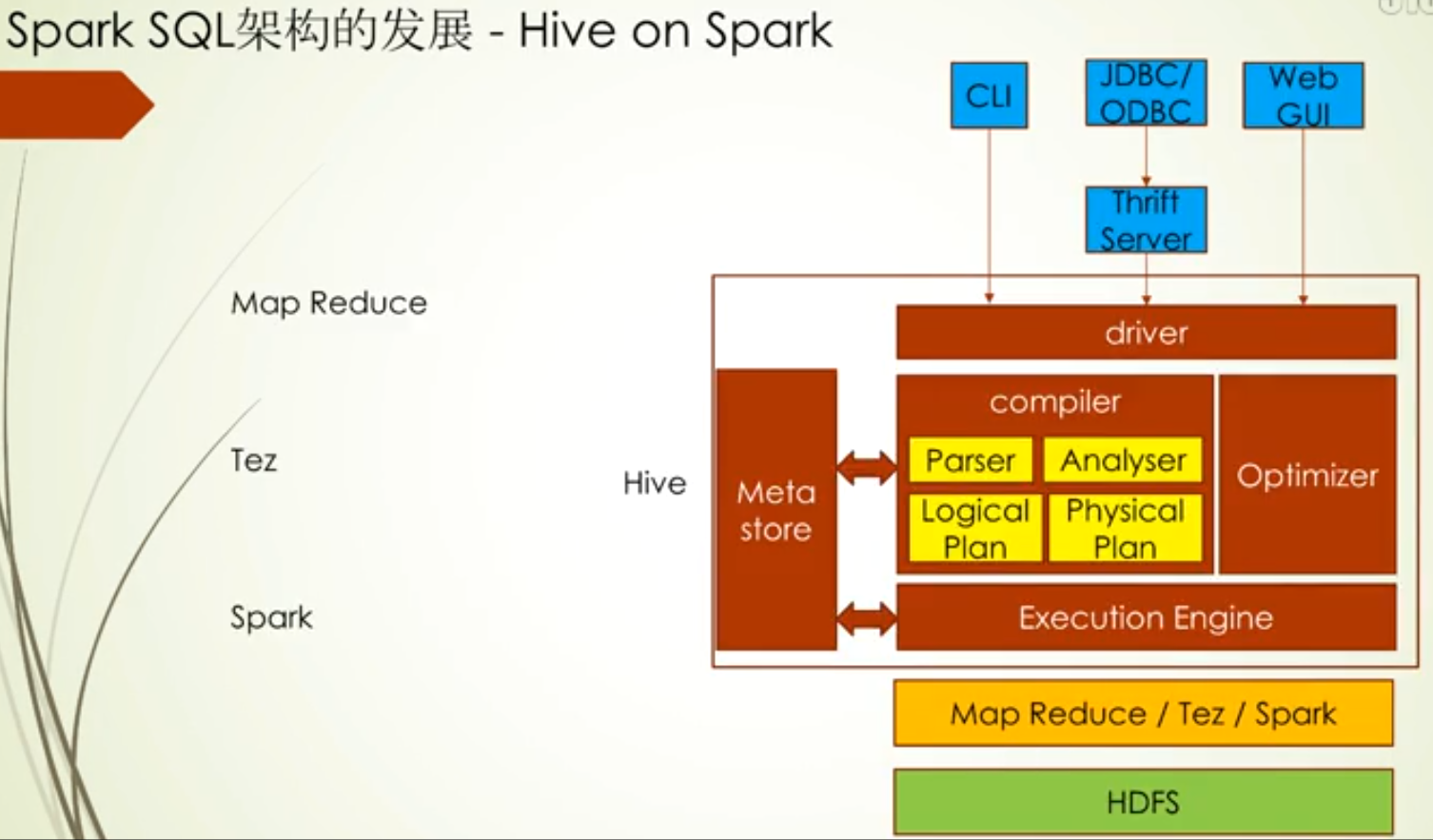
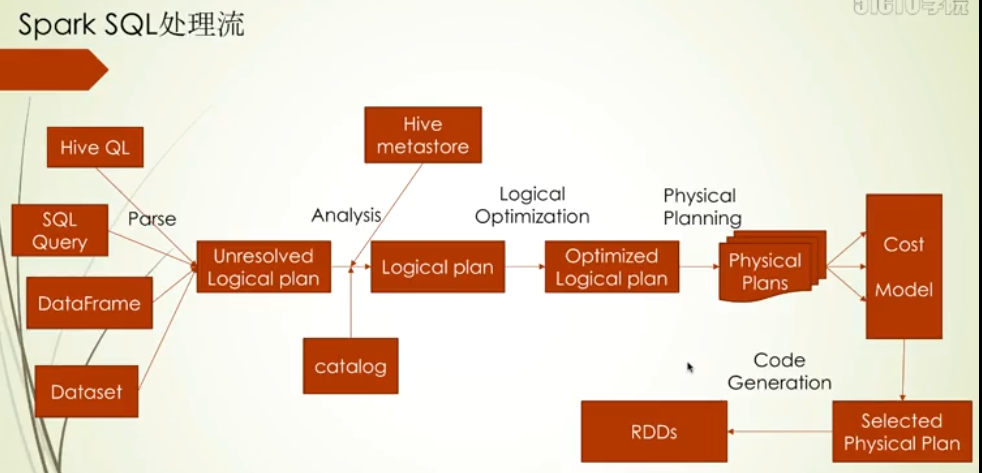
Spark SQL架构的出现主要是弥补shark的不足的,看到下面这张图
Spark sql core下的Catalog主要存储表的一些元数据信息,比如字段,字段类型
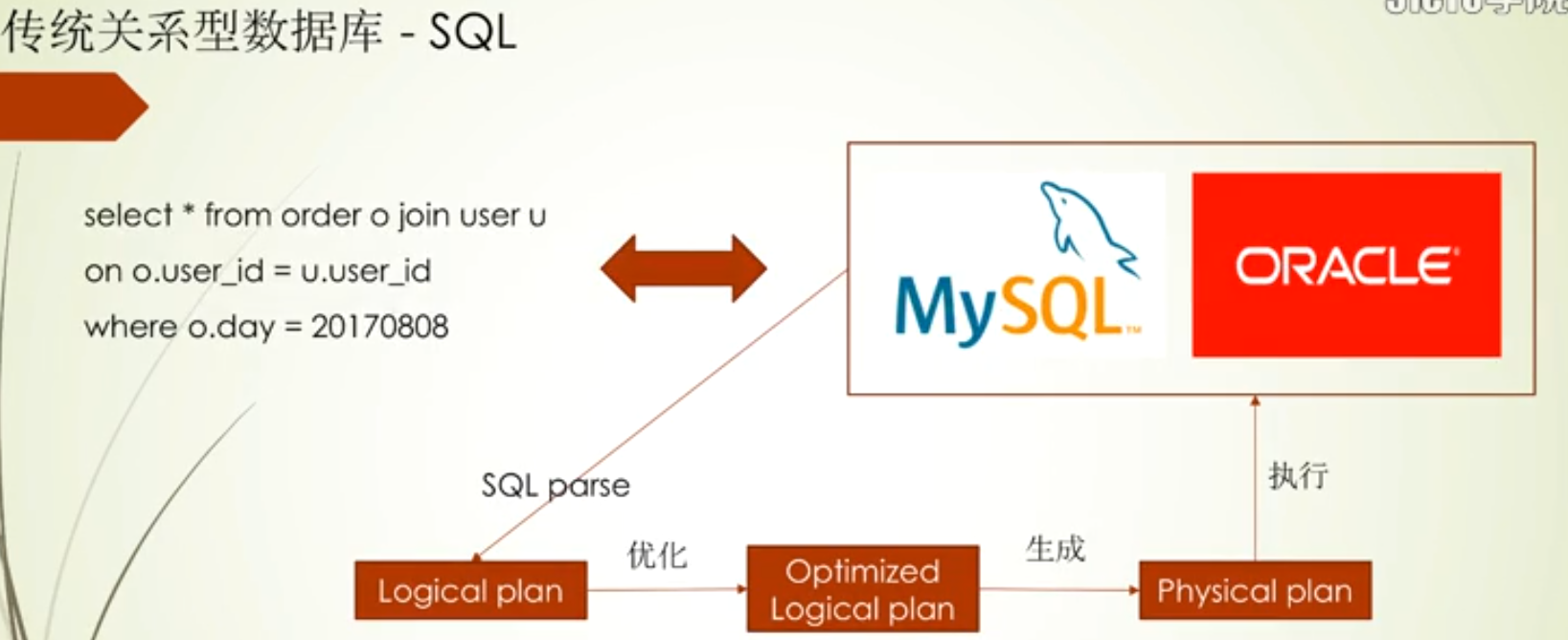
Spark sql core是基于Catalyst组件实现的,下面会有Parser,这个主要对字符串sql进行解析,解析完后交给Analyser进行分析,这个主要是判定查询的表对不对啊,有没有相关的字段啊,分析完成之后就会生成一个Logical Plan,逻辑执行计划在给到Optimizer进行优化,优化后生成一个Physical Plan,进而把物理执行计划转化Spark RDD,RDD来进行分布式计算
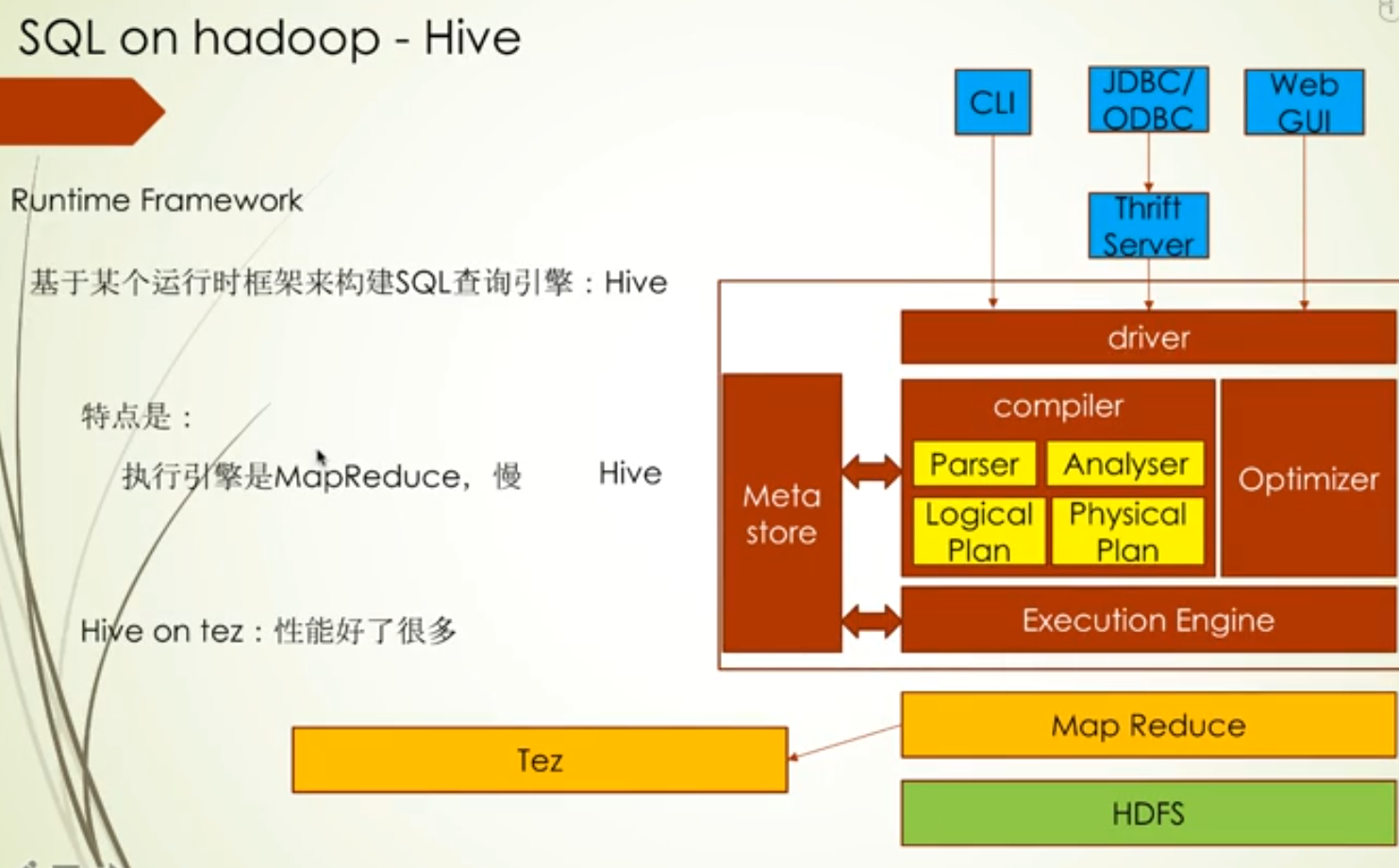
当然Spark SQL里还支持Hive Sql,Hive发展了这么久,在语法上还是很丰富的,Hive元数据存储的地方是Hive Metadata,Hive Sql会访问这个地方而Hive Sql最终利用spark sql core的接口来实现调用 spark RDD
Hive-thriftserver对外提供的服务的,允许jdbc的方式访问Spark SQL
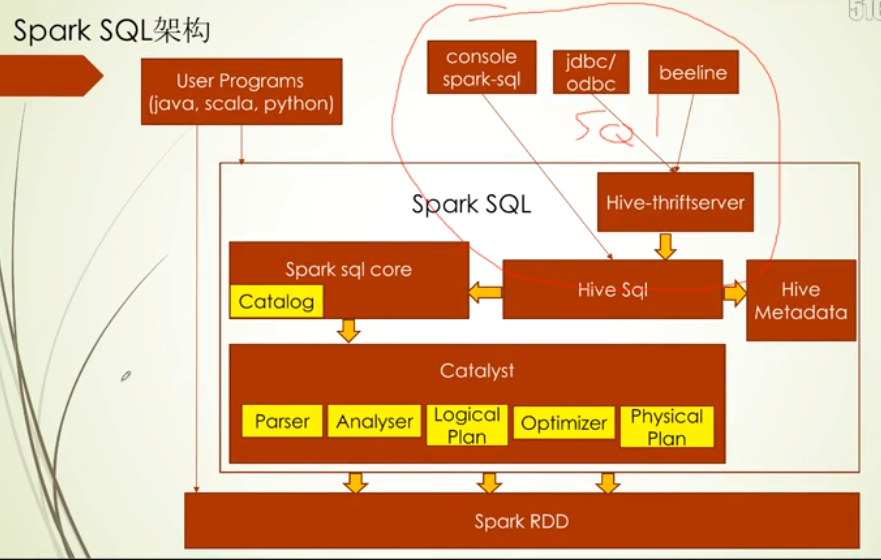
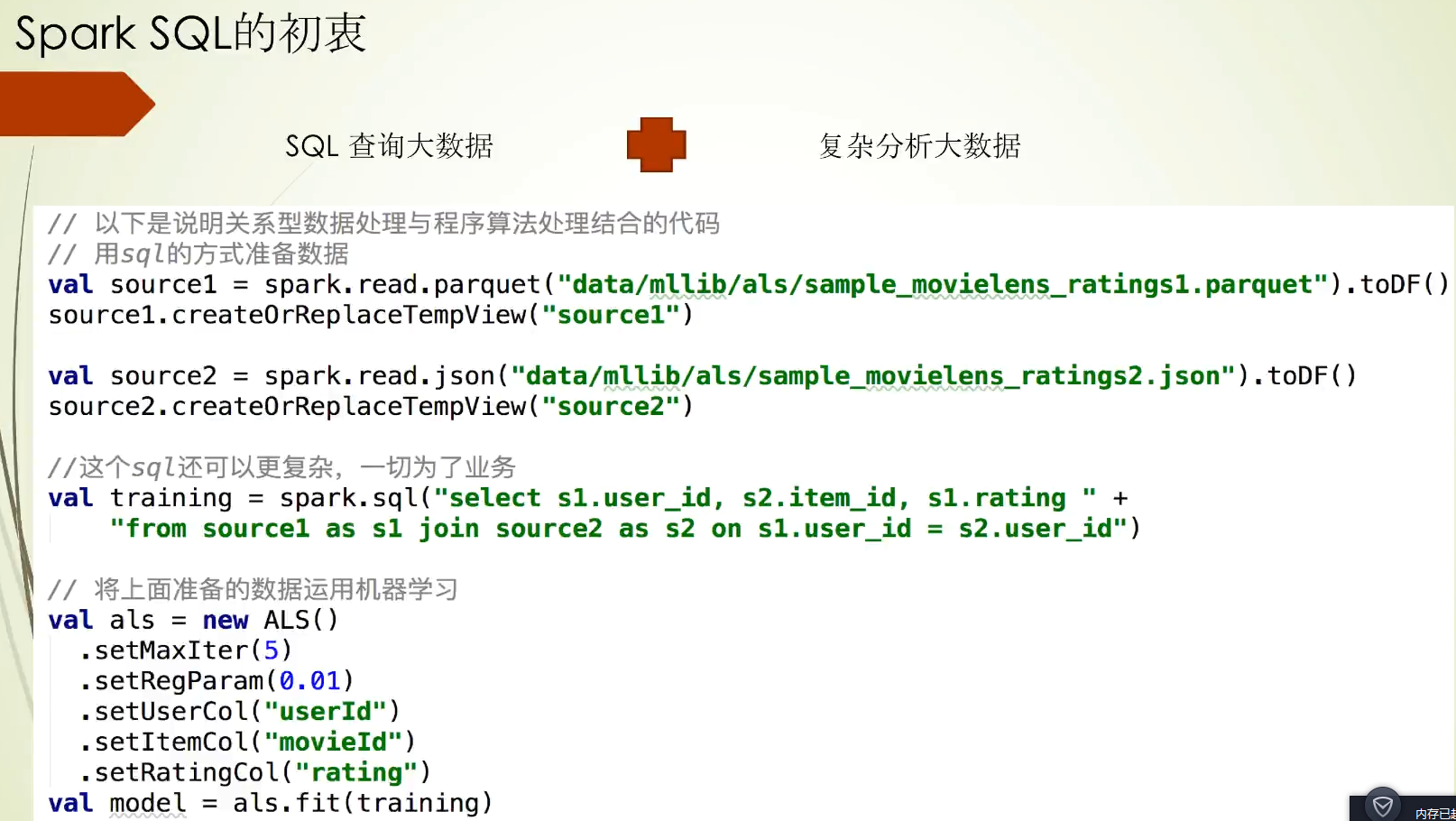
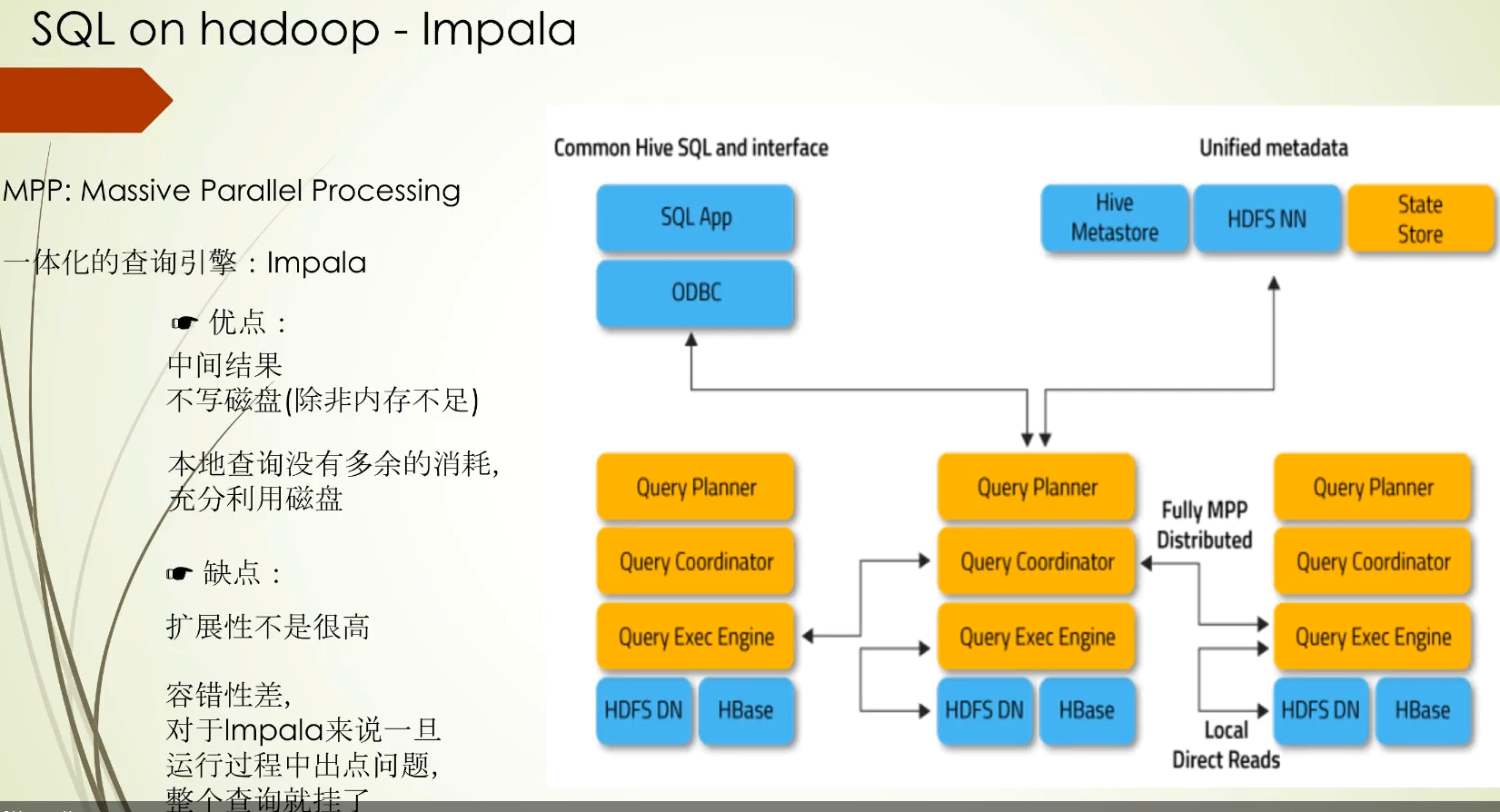
当然sql查询支持Hive QL和SQL,其中在验证表的元数据信息时访问的组件不一样,其他的流程上是一致的,另外还支持API形式:DataFrame和Dataset
Spark Sql中有两种优化模式:规则优化模式(比如:优化逻辑执行计划),成本优化模式(比如根据成本分析模式选择最优的物理执行计划)
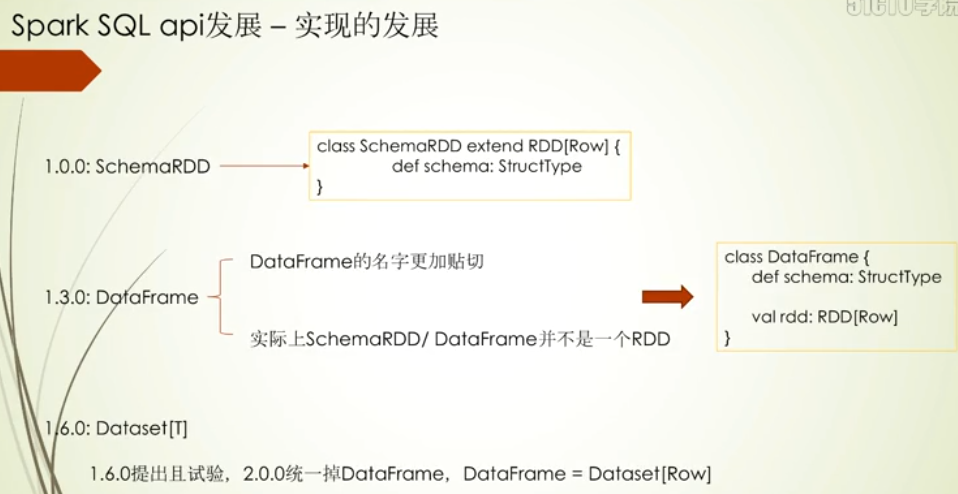
Spark SQL api发展
发展主线

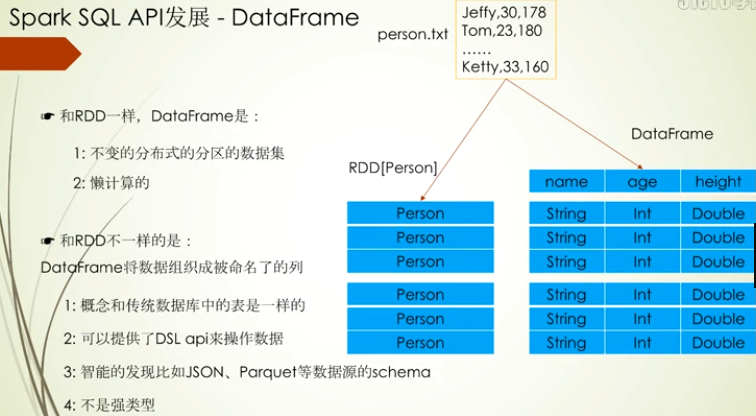
RDD特点

这里重点讲下SchemaRDD演变为DataFrame的过程,一个是考虑命名,DataFrame更贴合其他语言,之前SchemaRDD从定义上看SchemaRDD是一个RDD,虽然他们操作API名称一致,但是SchemaRDD的操作都带有Schema,为了代码上扩展和优化,DataFrame采用组合的方式加入Schema和RDD
其中下面第一点:主要优化在列式存储下,数据值类型相同,在压缩和解压缩,以及过滤时会更快
而最后一点:不仅优化了SQL性能,而且还让客户使用起来更方便(客户自己不用太关注SQL优化)
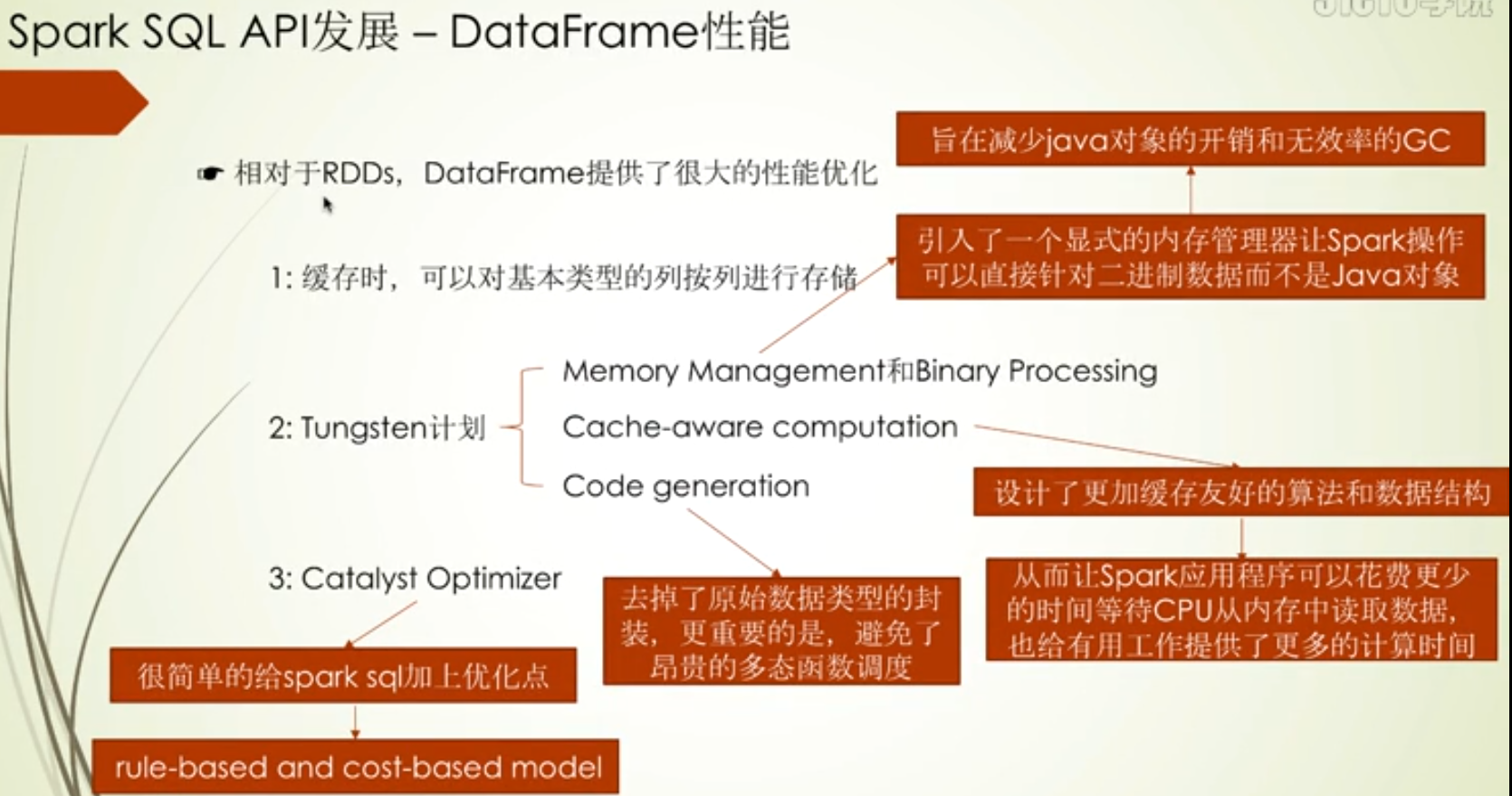
DataFrame的存储如下缺点,而这两个缺点也正是RDD的优点

DataSet

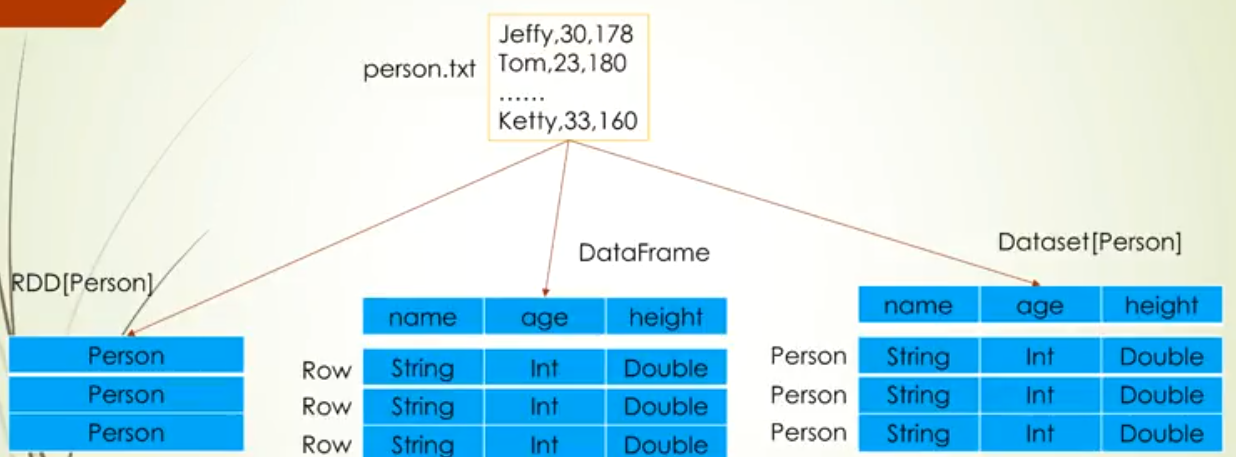
API演化的合理性
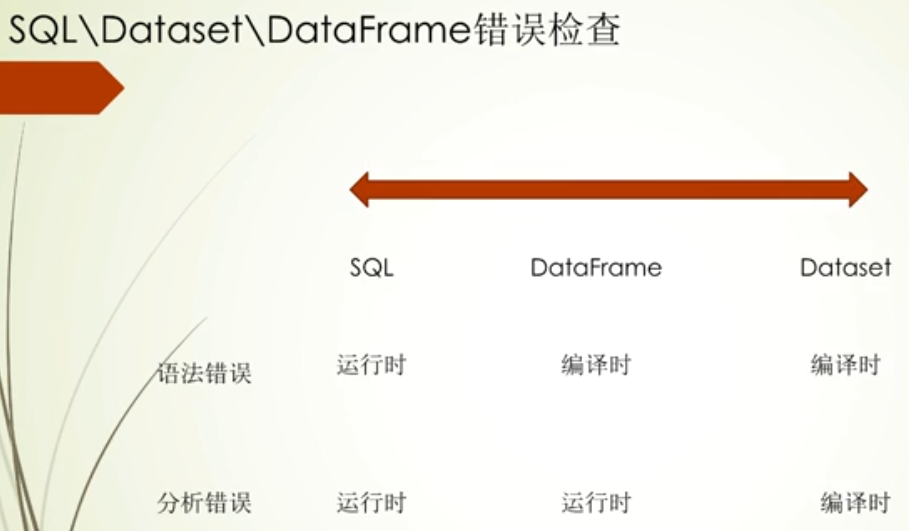
三种访问方式合理性对比:主要是从错误检查角度,如果程序能在编译时就发现程序错误,那无疑能提高开发效率
其中语法错误,这里说的sql的语法,比如select等关键词是否编写错误, 而分析错误,举例如查询字段是否存储
通过图中对比发现,DataSet是强制类型的,此时的好处也就来了,它能在编译时检测语法错误和分析错误
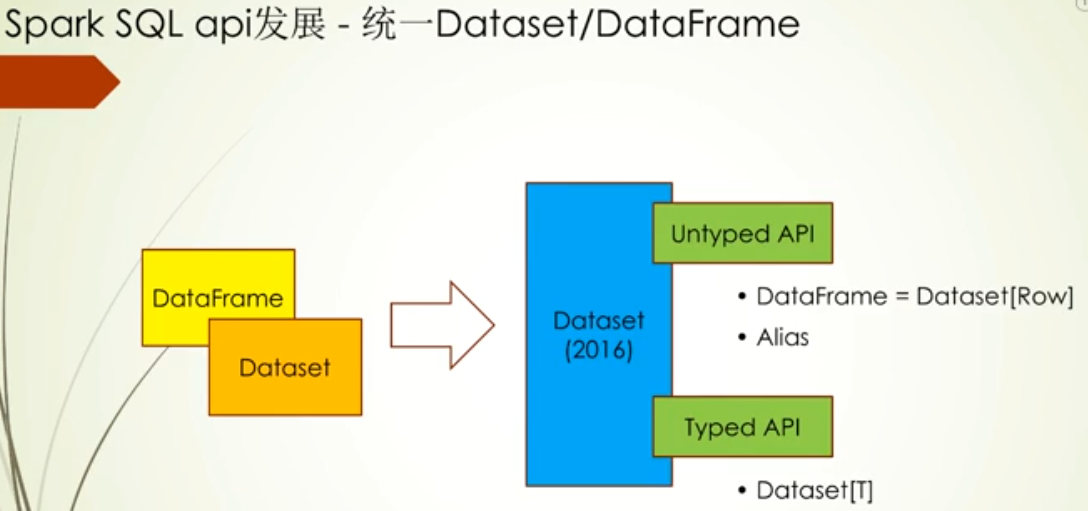
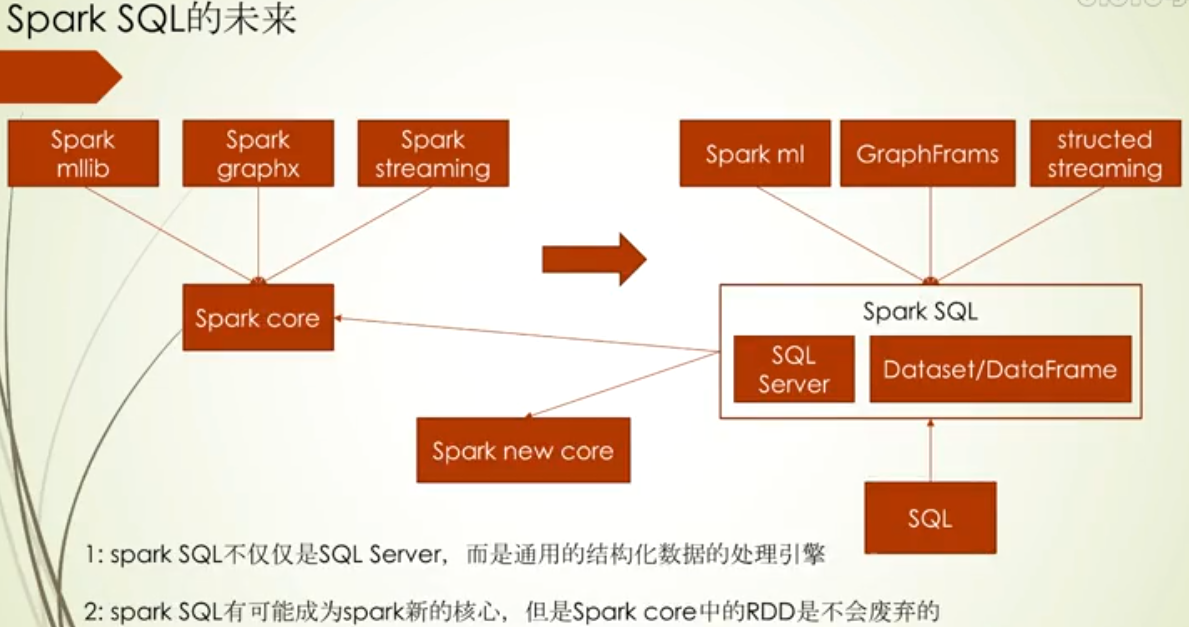
为什么说Spark core暂时不会废弃了,因为Spark SQL主要是处理结构化数据,在一些非结构化数据处理场景下,还是要用到Spark core

 浙公网安备 33010602011771号
浙公网安备 33010602011771号