

Schedulers On Driver
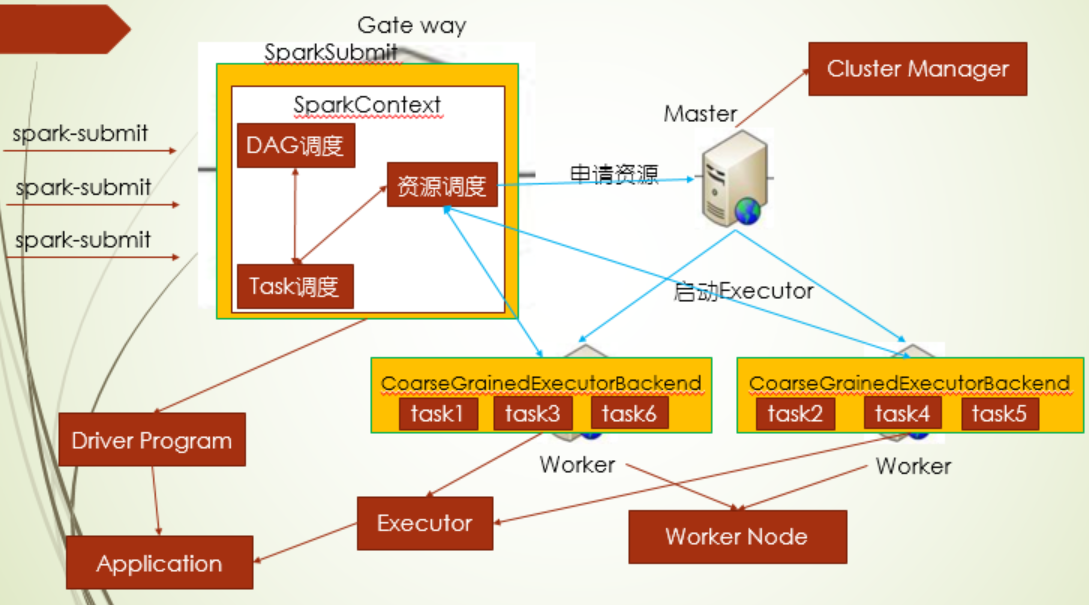
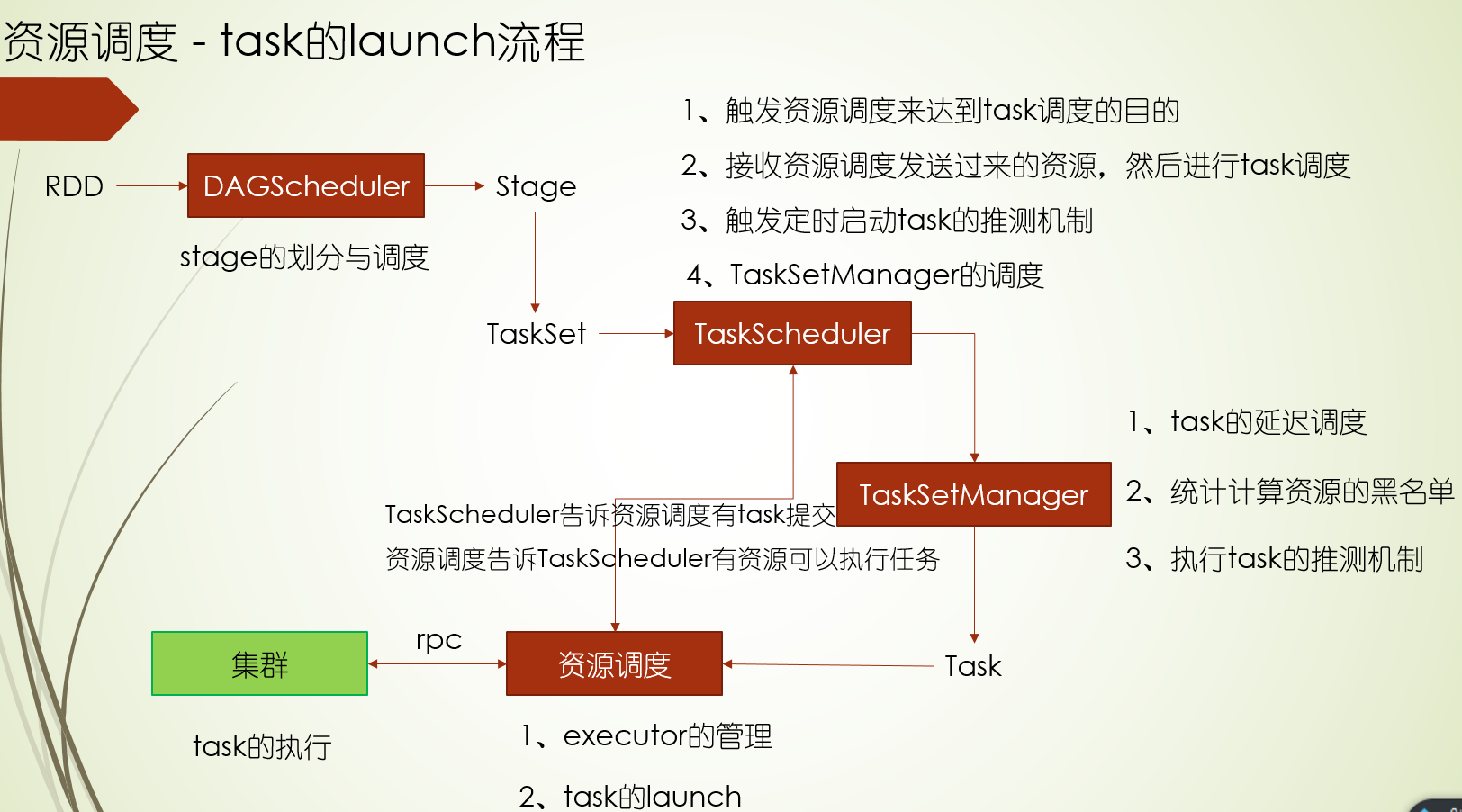
通过spark-submit提交 spark应用程序,会在driver端启动一个spark app,在实例的SparkContent中,会有三个调度器:DAG调度,Task调度,资源调度,本着移动计算少移动数据的原则,这三个调度器配合着完成高效调度的事
首先资源调度器会根据spark-submit提交命令时的资源配置向Master申请资源,Master启动Executor端,Executor启动完成后向资源调度反馈Executor资源 情况,资源调用器有资源了,就会向Task调度器发出通知:有资源了可以调用了启动task,然后task调度器经过一系列的机制,给出一个最优的task给到资源调度器启动,而DAG调度则是把RDD划分stage,
stage
***stage的划分
在DAG调度中,会根据父子RDD之间的关系划分stage,其中这种关系主要分:窄依赖,宽依赖,窄依赖就是父亲RDD的一个分区数据只能被子RDD的一个分区消费;宽依赖则是父亲RDD的一个分区的数据同时被子RDD多个分区消费,其中窄依赖常见操作,比如map,filter,flatMap(这些都是OneToOneDependency),union(RangeDependency),宽依赖常见操作有reduceByKey,groupByKey,coalesce,combineByKey(ShuffleDependency)
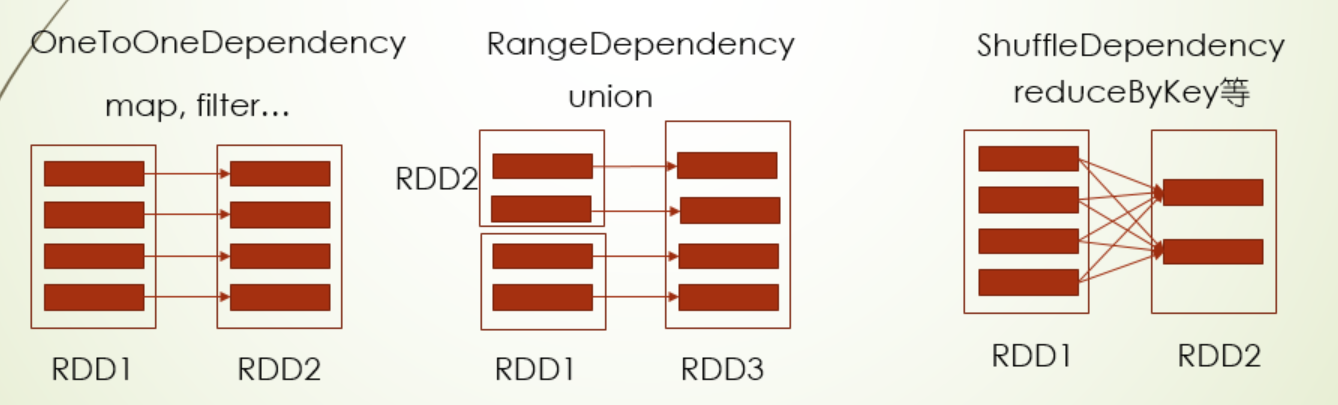
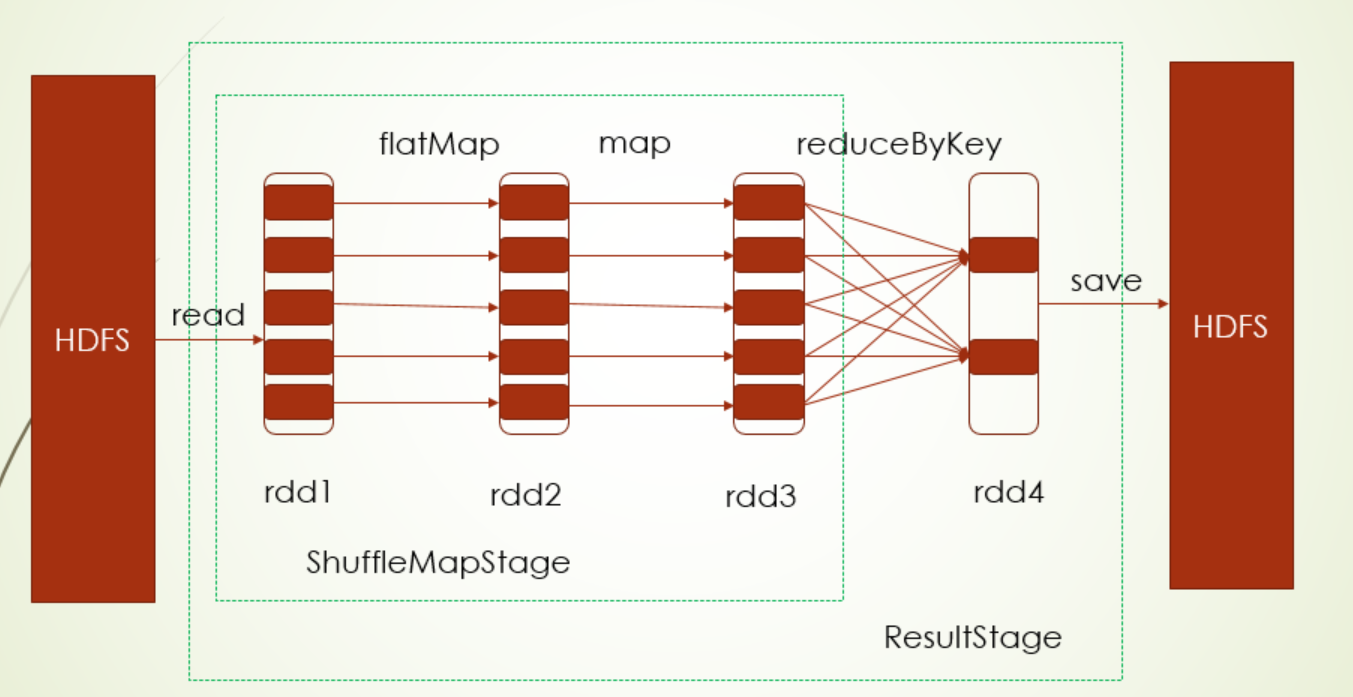
其中stage的划分原则就是遇到ShuffleDenpendency就进行stage划分,也就是Shuffle准备阶段(Shuffle之前的Map端)划分为一个stage,以及Shuffle汇总阶段(Shuffle之后的reduce端)划分为一个stage
ShuffleMapStage:为Shuffle提供数据的中间stage(Shuffle准备阶段的stage);ResultStage:为一个action操作计算结果的stage(Shuffle汇总阶段的stage)
为什么说Map端stage是在为Shuffle提供数据呢?因为在Shuffle过程之前,map端会把最后的计算结果按照分区器的规则分区好存储在磁盘上,reduce端则按照分区器的规则到对应map端存储位置上取数据
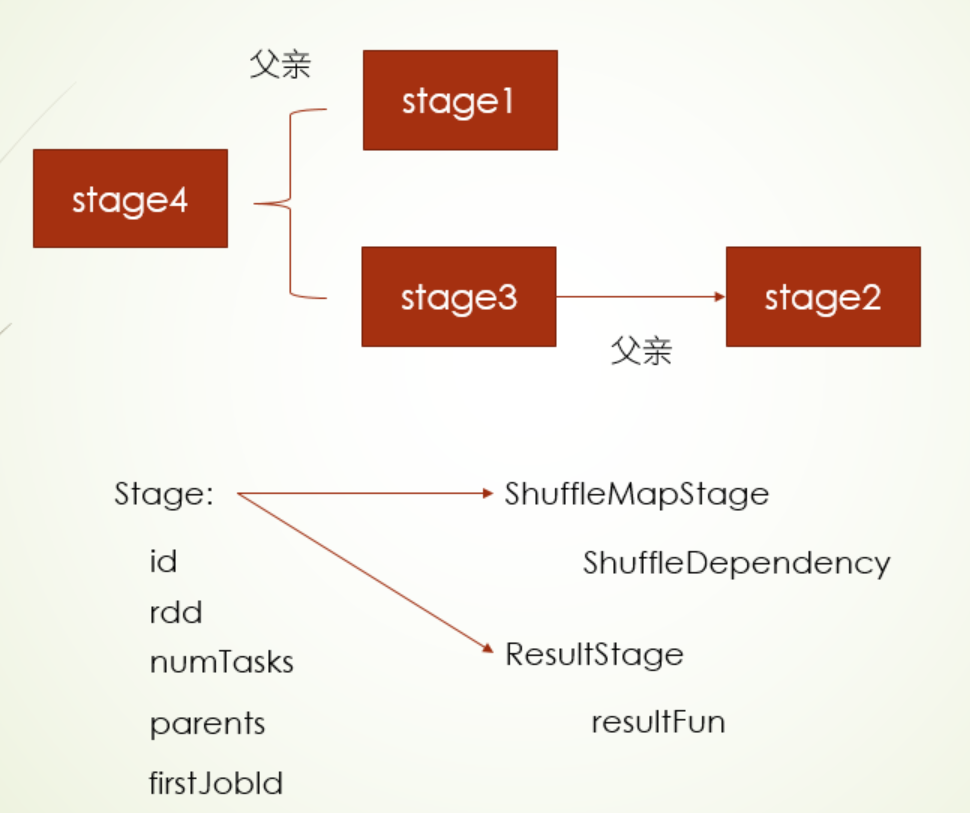
当然stage也有父子关系之说
***stage的调度
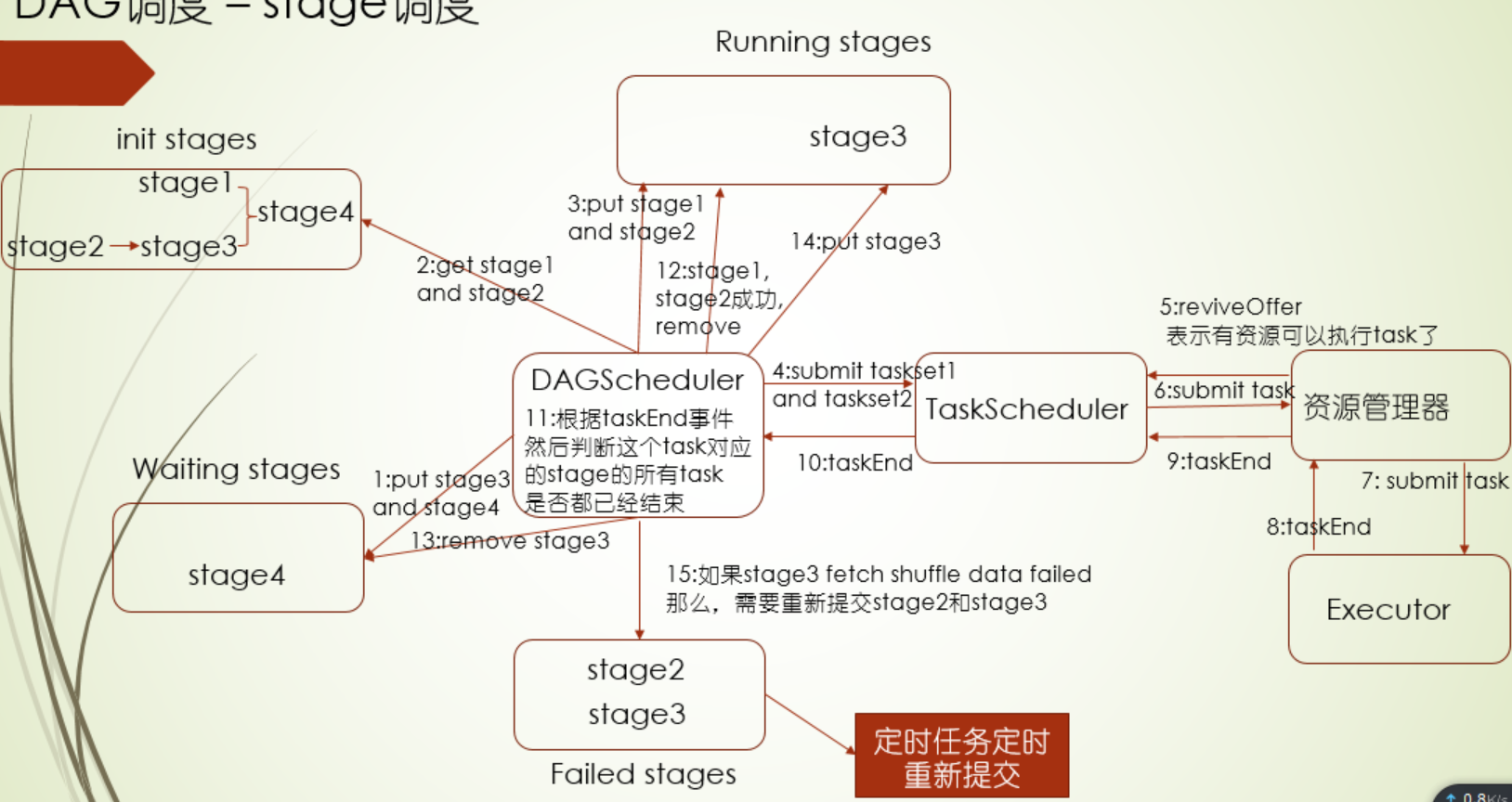
stage的调度是由DAGScheduler来实现的,假如现在就以上面有4个stage的图来说明DAG调度过程
- 首先,会按照上面图中的stage关系初始化四个stage放入init stages,其中DAG调度器会把有父stage的stage3和stage4会放入Waiting stages这么一个容器中
- 获取没有父stage的stage1和stage2
- 把stage1和stage2放入Running stages中
- DAG调度器把每个stage分解成一个taskset,stage1和stage2被分解成taskset1和taskset2,提交给TaskScheduler(Task调度器)
- 资源管理器表示有资源执行task,把这个信息反馈给task调度器
- task调度器收到资源管理器的有资源信息,按照自己的规则和机制给到一个最优的task
- 资源管理器把这个task提交到Executor端启动
- task执行完后,返回结束信息给资源管理器
- 资源管理器反馈任务结束信息给task调度器
- task调度器返回任务 结束信息给DAG调度器
- 在DAG调度器中,根据taskEnd事件,判断task对应的stage是否所有task都结束
- 如果stage的task都结束了,就把成功的stage1和stage2都从Running stages移除掉
- 然后从Waiting stages中把stage3移除掉,把stage3给到DAG调度器进行调度
- DAG调度器会stage3放入Running stages中,然后之后流程就按照stage2一样,提交给task调度器,资源管理器,Executor端执行
- 如果stage3 获取shuffle过程的数据失败,那就要重新提交stage2和stage3,这两个stage暂时会放在Failed stages中,由定时任务取重新提交
taskset
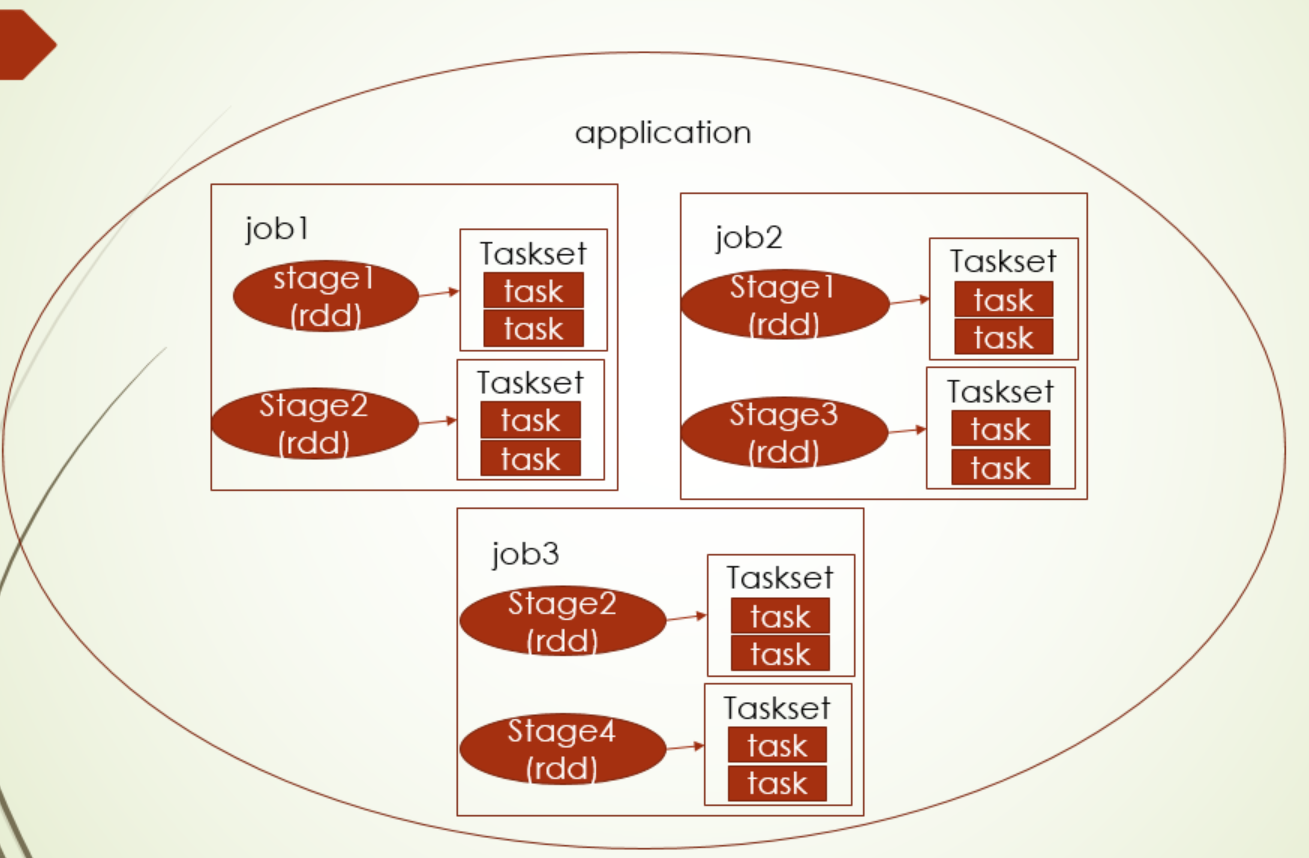
说task调度前,需要先明确下application、job、stage、taskSet、task的关系
application就spark app应用程序,它下面一般包括一个或者多个job,一般情况下触发一个action操作(试下collect这样的操作),就算一个job,当然更常见的还是保存到文件中,有几个保存动作就有几个job,每个job下就是对RDD的一系列操作,对RDD进行stage的划分,每个stage又都会划分成TaskSet,TaskSet就是task的集合,task的数量是由RDD的分区数决定的
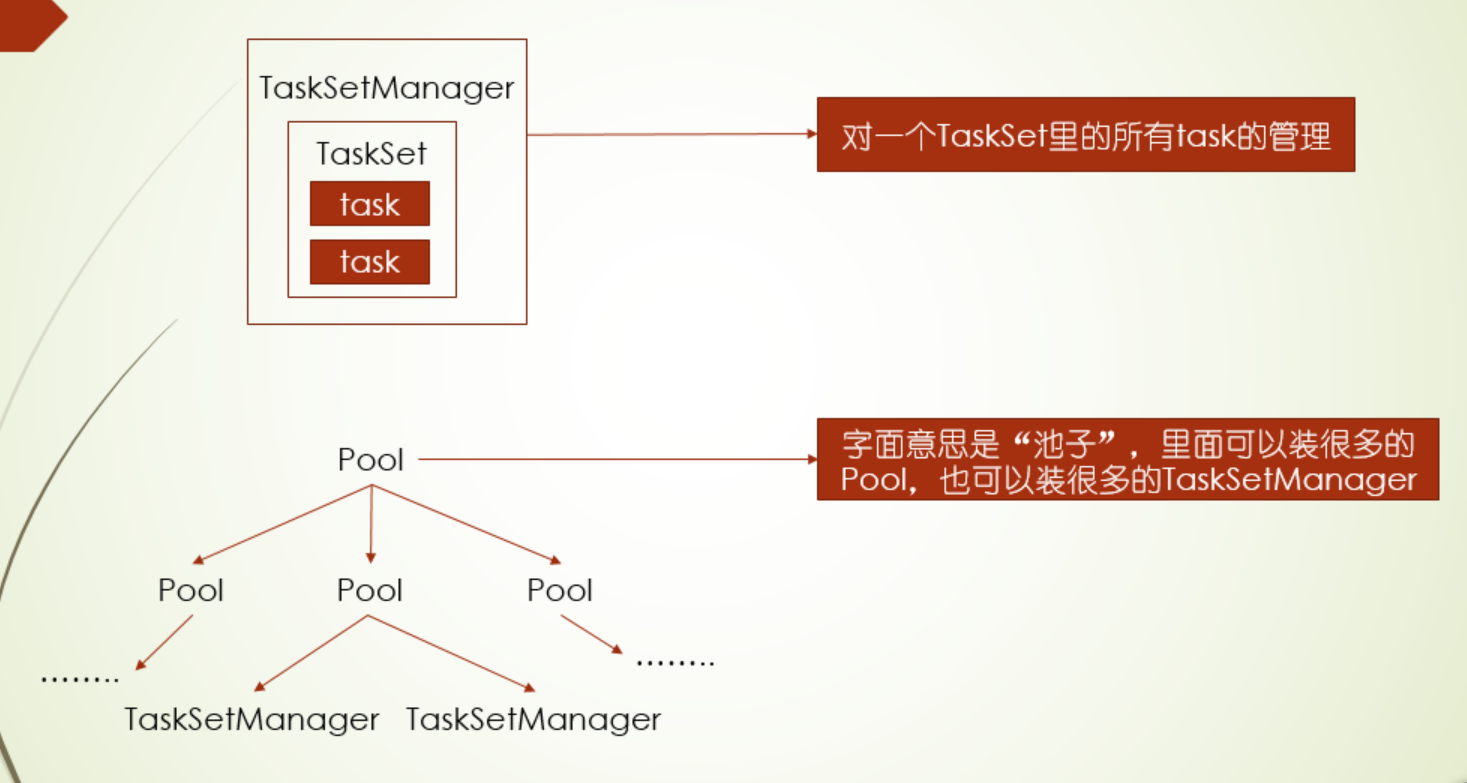
其中DAG调度器是对stage调度,Task调度器则是对TaskSet进行调度,而task则是由TaskSetManager调度
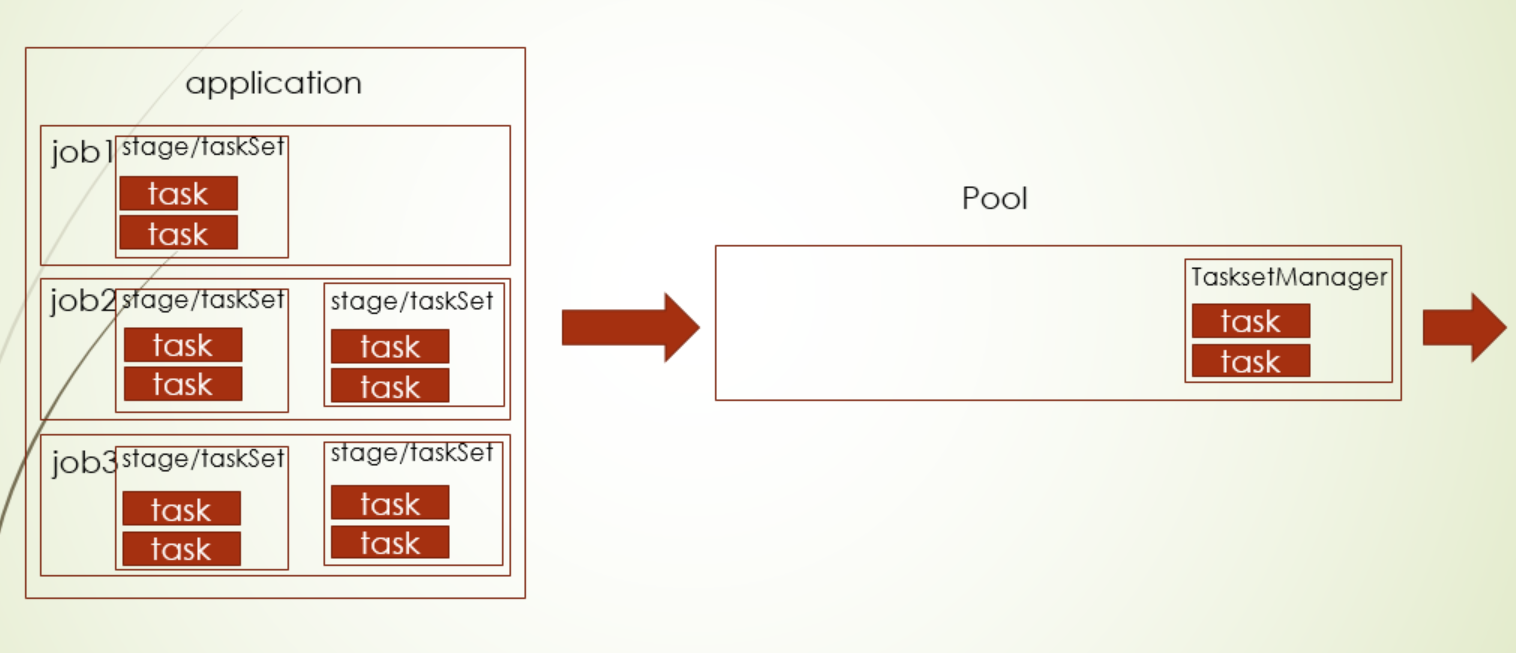
 其中两种调度模式FIFO和FAIR都对TaskSet级别调度,其中FIFO使用的默认的pool,没有上面这个树形pool(这个是在FAIR中使用),FIFO是默认支持的模式
其中两种调度模式FIFO和FAIR都对TaskSet级别调度,其中FIFO使用的默认的pool,没有上面这个树形pool(这个是在FAIR中使用),FIFO是默认支持的模式
***先进先出(FIFO)
***公平调度(FAIR)
公平调度就有pool树的概念,提交job的程序代码里可以指定给某个pool,没有指定(也就是填null的情况)就进入到defaultPool
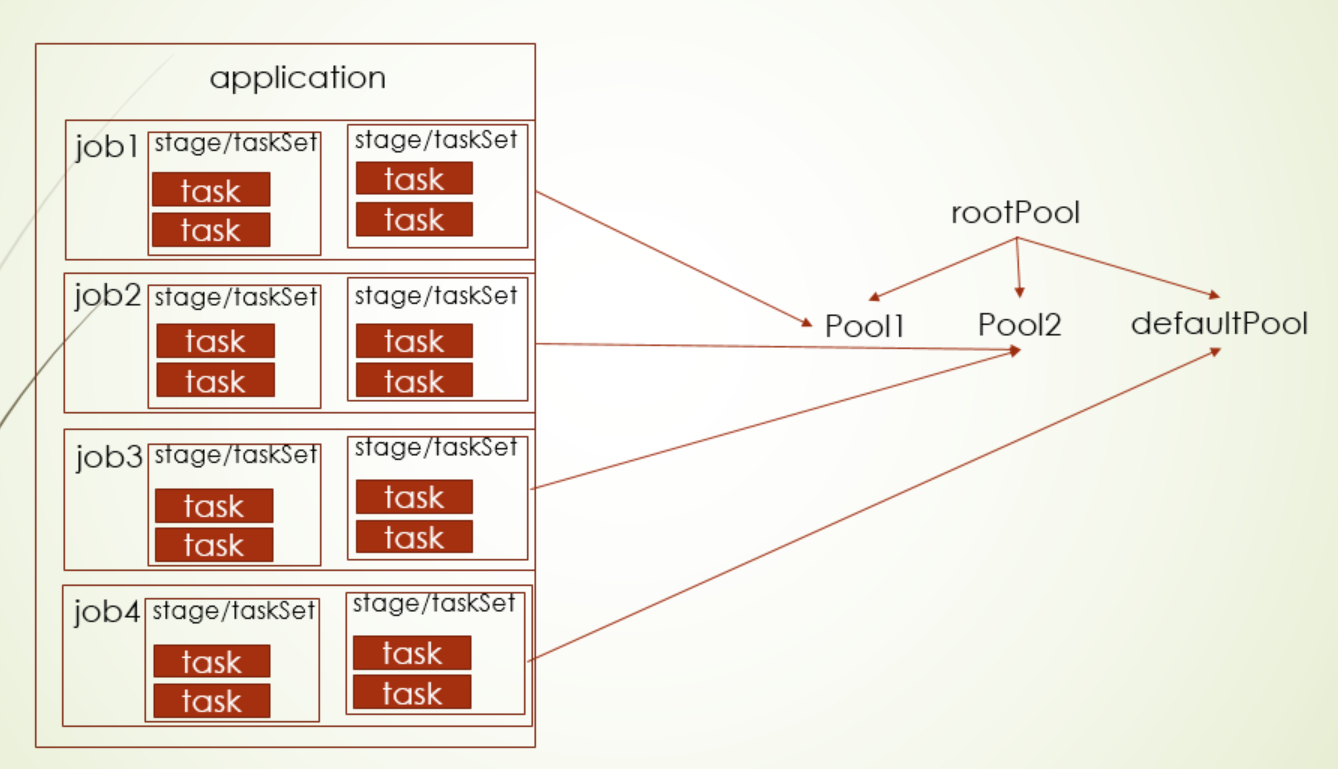
那么这个pool树是怎么构建的呢?另外Executor有资源了,会调哪个pool下TaskSet呢?
对于第一个问题,可以弄一个xml文件进行配置,配置的pool都挂在rootPool下,除了配置的pool,还会有个defaultPool,每个pool都有三个值minShare(最小task运行数量),weight(权重),scheduleMode(pool下TaskSet的调度模式)
一个spark app怎么设置taskset级别的公平调度呢?1.配置conf,spark.scheduler.mode设置为FAIR和spark.scheduler.allocation.file设置为配置文件路路径 2.运行job时,通过sc.setLocalProperty("spark.scheduler.pool", "Pool2")指定,其中这里需要注意的是:这个设置动作是threadLocal线程级别的

下面过程是决定有Executor资源了会优先调度哪个pool下的TaskSet,其中值越小,就会优先调度,其中runningTasks指的是当pool所有运行的task,pool的公平调度机制可以在这个场景下使用:先提交一个不是很重要的大job,再提交一个很重要的小job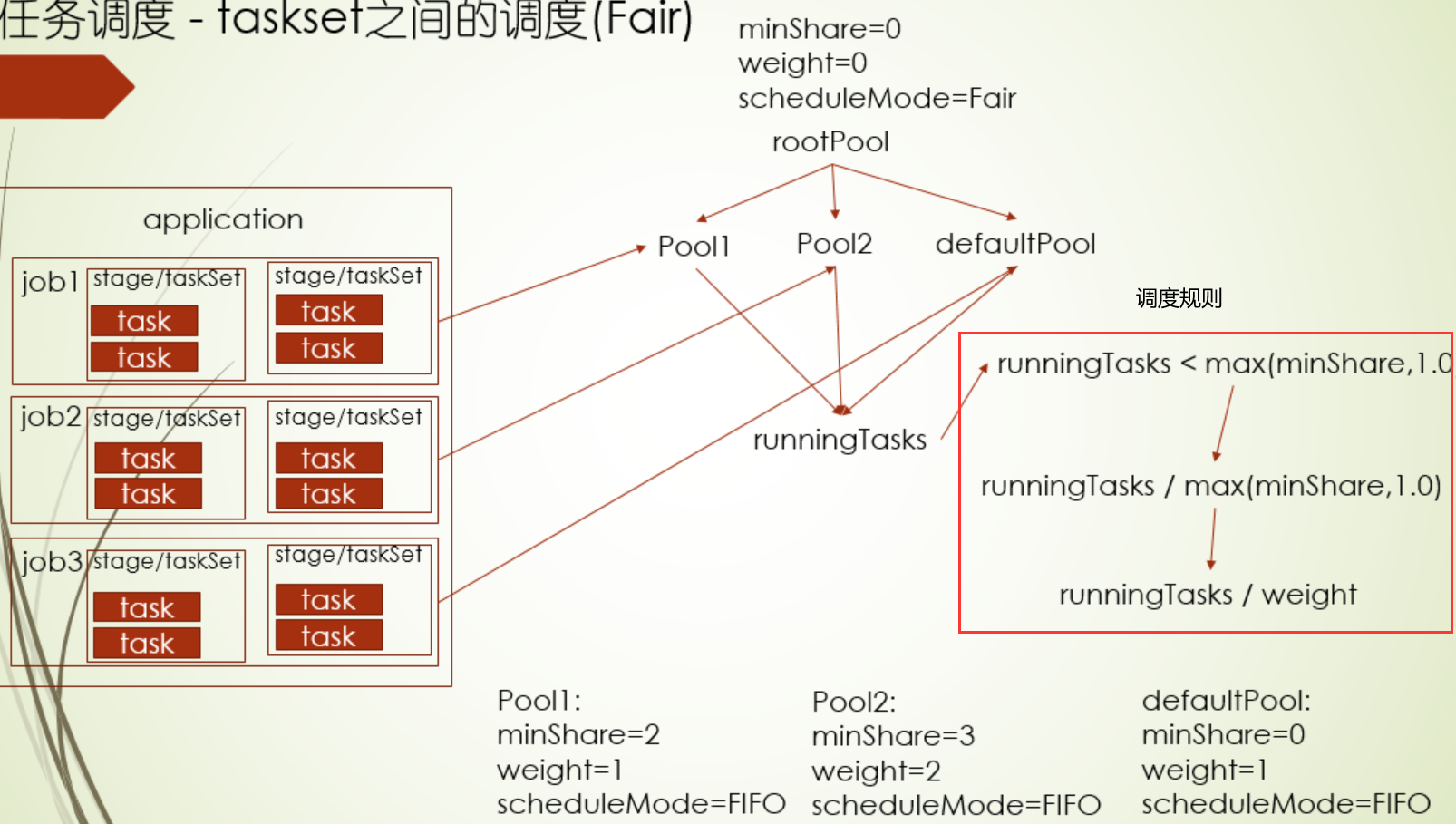
package com.twq.scheduler
import java.util.concurrent.CyclicBarrier
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by tangweiqun on 2017/9/24.
*/
object FairSchedulerApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("FairSchedulerApp")
//设置公平调度模式
conf.set("spark.scheduler.mode", "FAIR")
// 设置pool xml文件
conf.set("spark.scheduler.allocation.file",
"/Users/tangweiqun/spark/source/spark-course/spark-scheduler/src/main/resources/fairscheduler.xml")
val sc = new SparkContext(conf)
var friendCount = 0L
var orderCount = 0L
// CyclicBarrier 等待其他两个job执行完,再执行
val barrier = new CyclicBarrier(2, new Runnable {
override def run(): Unit = {
println("start save ======================")
//ThreadLocal级别
sc.setLocalProperty("spark.scheduler.pool", null) //指定提交到哪个pool,如果为null提交defaultPool
val total = friendCount + orderCount
val rdd = sc.parallelize(0 to total.toInt)
rdd.saveAsTextFile("file:///Users/tangweiqun/FairSchedulerApp")
}
})
new Thread(){
override def run(): Unit = {
println("count friend =====================")
//ThreadLocal级别
sc.setLocalProperty("spark.scheduler.pool", "Pool1")
friendCount = sc.textFile("file:///Users/tangweiqun/friend.txt").count()
barrier.await()
}
}.start()
new Thread(){
override def run(): Unit = {
println("count order ==========")
//ThreadLocal级别
sc.setLocalProperty("spark.scheduler.pool", "Pool2")
orderCount = sc.textFile("file:///Users/tangweiqun/order.txt").count()
barrier.await()
}
}.start()
}
}
当如果pool配置FAIR模式,是对这个pool所有TaskManager采用公平调度机制,TaskManager也会有那三个属性,公平调度时的规则和pool调度是一样的(下面是pool的配置,目前版本对TaskManager的公平调度机制是无效的)
<?xml version="1.0"?>
<allocations>
<pool name="Pool1">
<minShare>2</minShare>
<weight>1</weight>
<schedulingMode>FIFO</schedulingMode>
</pool>
<pool name="Pool2">
<minShare>3</minShare>
<weight>1</weight>
<schedulingMode>FAIR</schedulingMode>
</pool>
</allocations>
总结:
- spark app的组成关系:一个app包含多个job,一个job多个stage(job和stage是多对多的关系,也就是同一stage,其背后的RDD,也会用在多个job上),stage会划分成一个TaskSet,TaskSet对应多个task
- Spark app在提交的时候,是按照job级别(下有多个stage和taskset)提交到队列里,只不过对于FIFO和FAIR两种模式下,调度的TaskSet的规则不一样,也就是说当Executor端有资源可以运行告知Task调度器,应该调度哪个pool下的哪个TaskSet?首先是FIFO模式,你可以理解为它就一个队列,所有的job都提交在这里队列里,谁先提交,谁就先调度, 其次就是FAIR模式,这种模式其实有两个层级的调度,第一个调度确定哪个pool,第二个调度确定的pool下的哪个TaskSet,这两个按照配置文件的配置值以及规则来确定优先调度哪个
task
上面主要讲了job提交到pool,pool的调度模式,那么TaskSet里的task是怎么进行调度的呢?
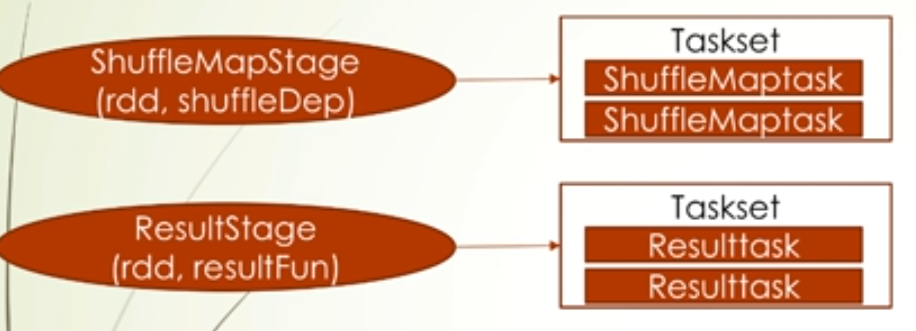
上面也提到,stage主要分为两类:ShuffleMapStage和ResultStage,其中ShuffleMapStage会记住最后RDD的信息和shuffleDep信息,而ResultStage则会记住萃取函数的信息,ShuffleMapStage划分的TaskSet,下面的task称为ShuffleMaptask,ResultStage划分的TaskSet下的task称为Resulttask,一般task数量是由RDD的分区数决定的
task信息:stageId,stageAttemptId(task重试id),partitionId,locations(需要分发到哪些机器上进行计算)
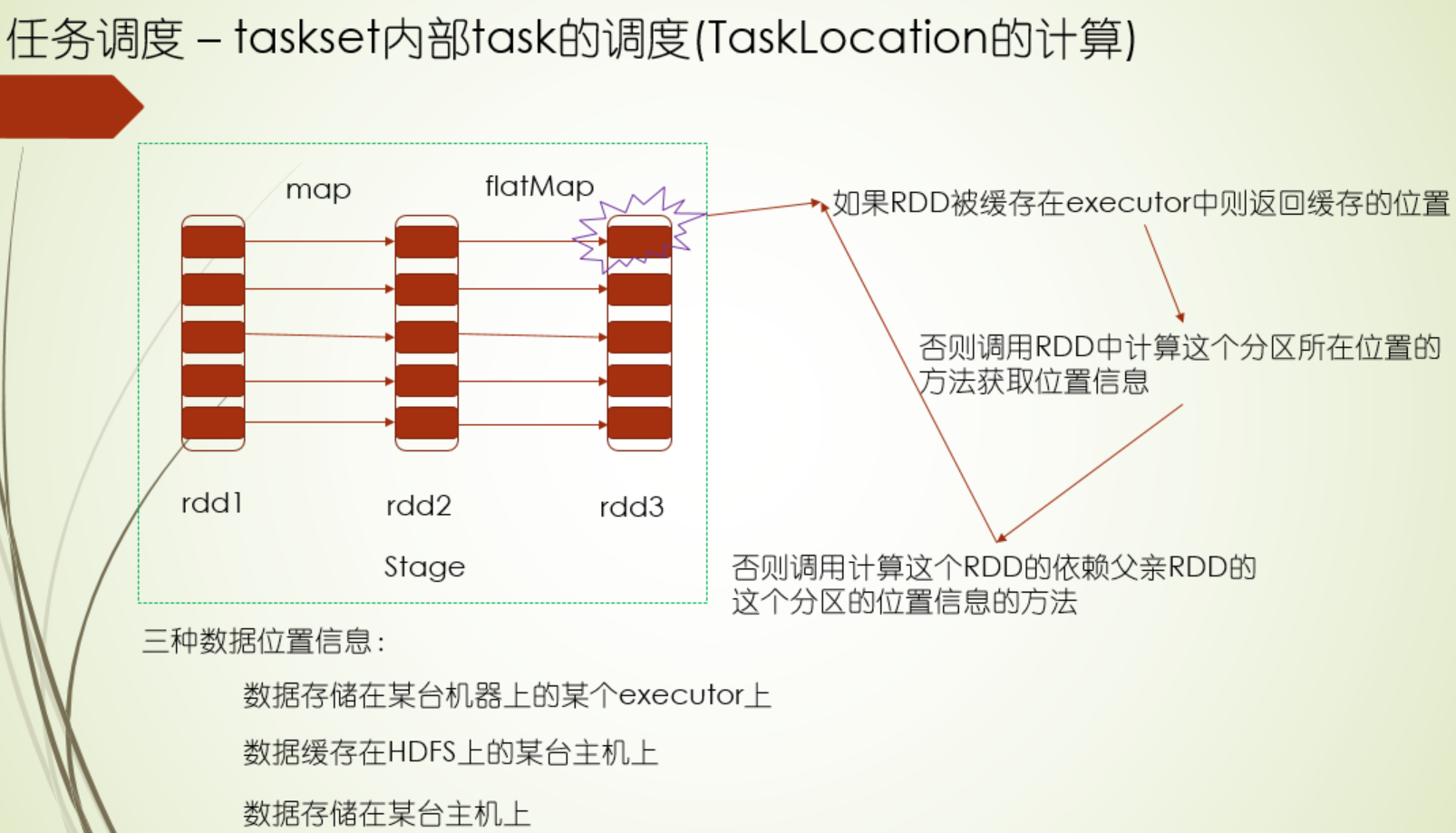
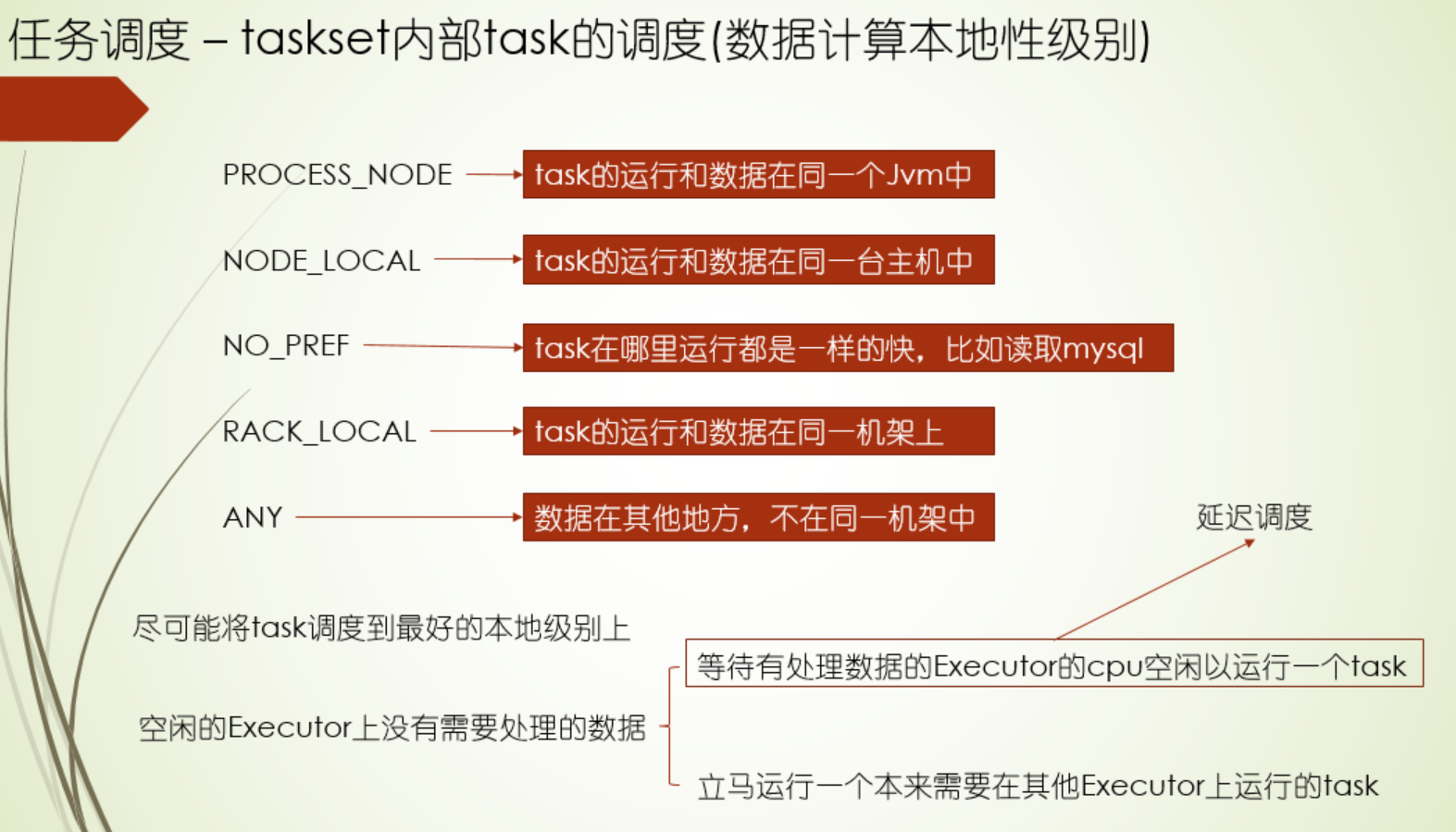
本地性级别定义
延迟调度
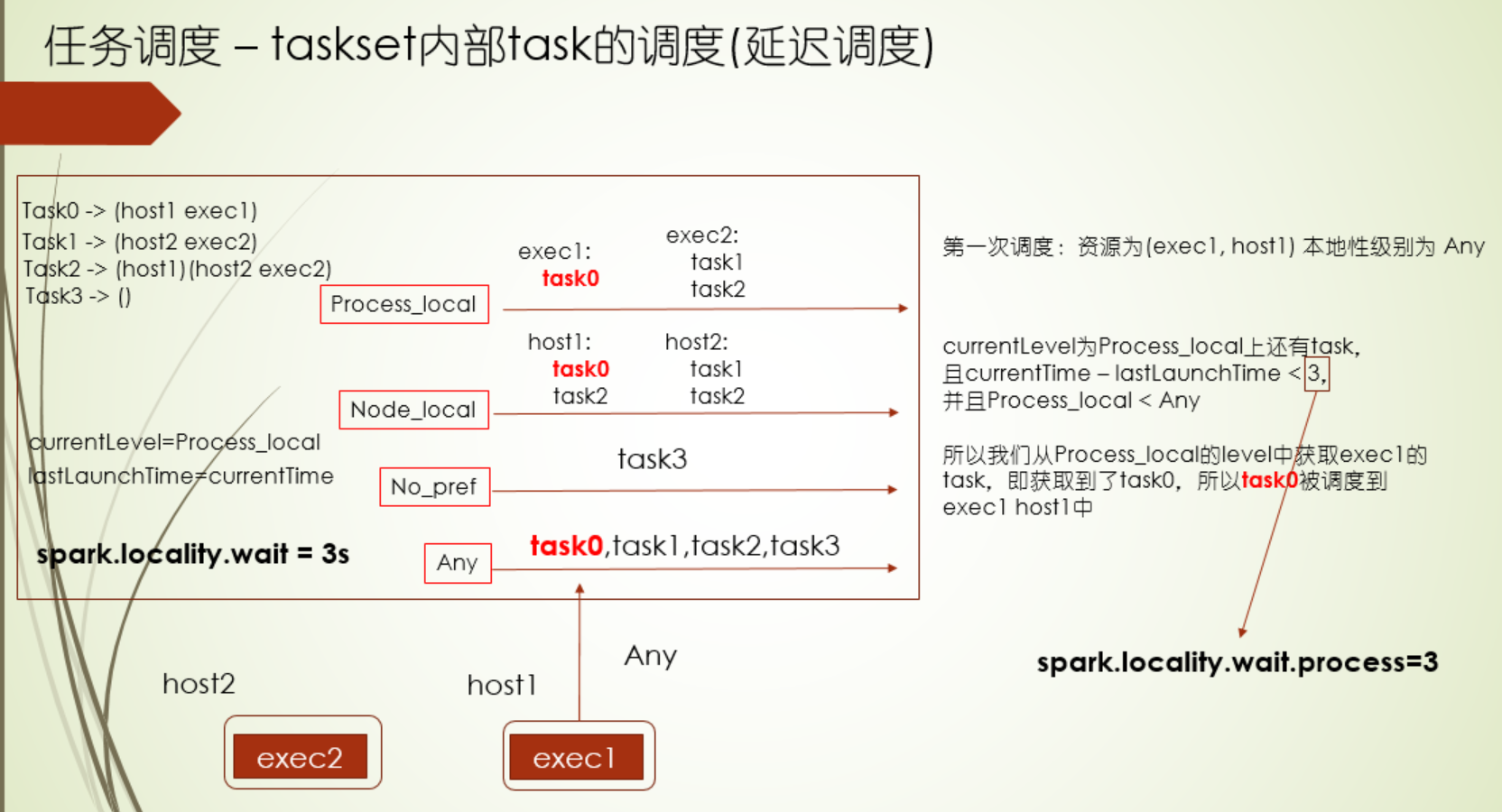
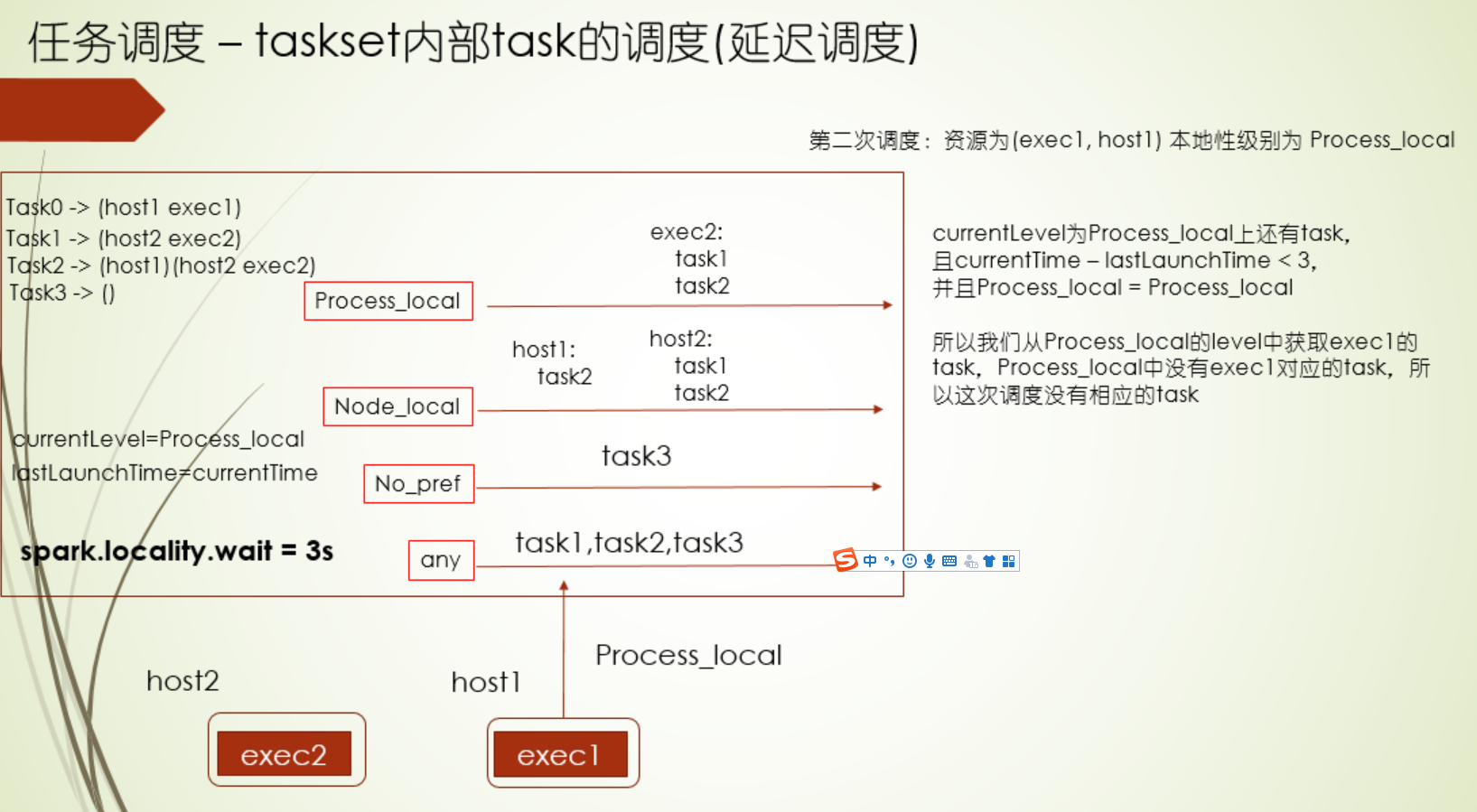
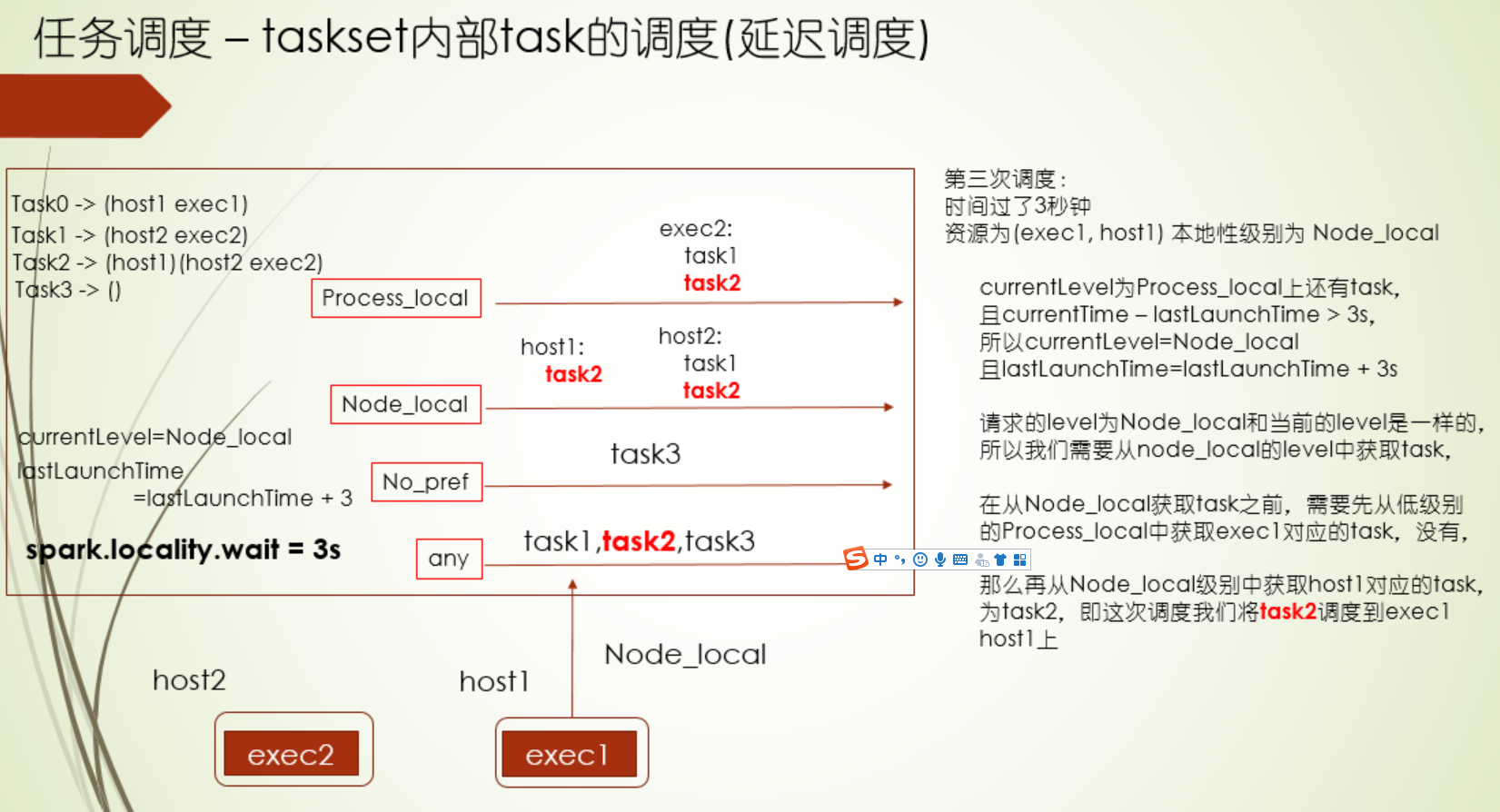
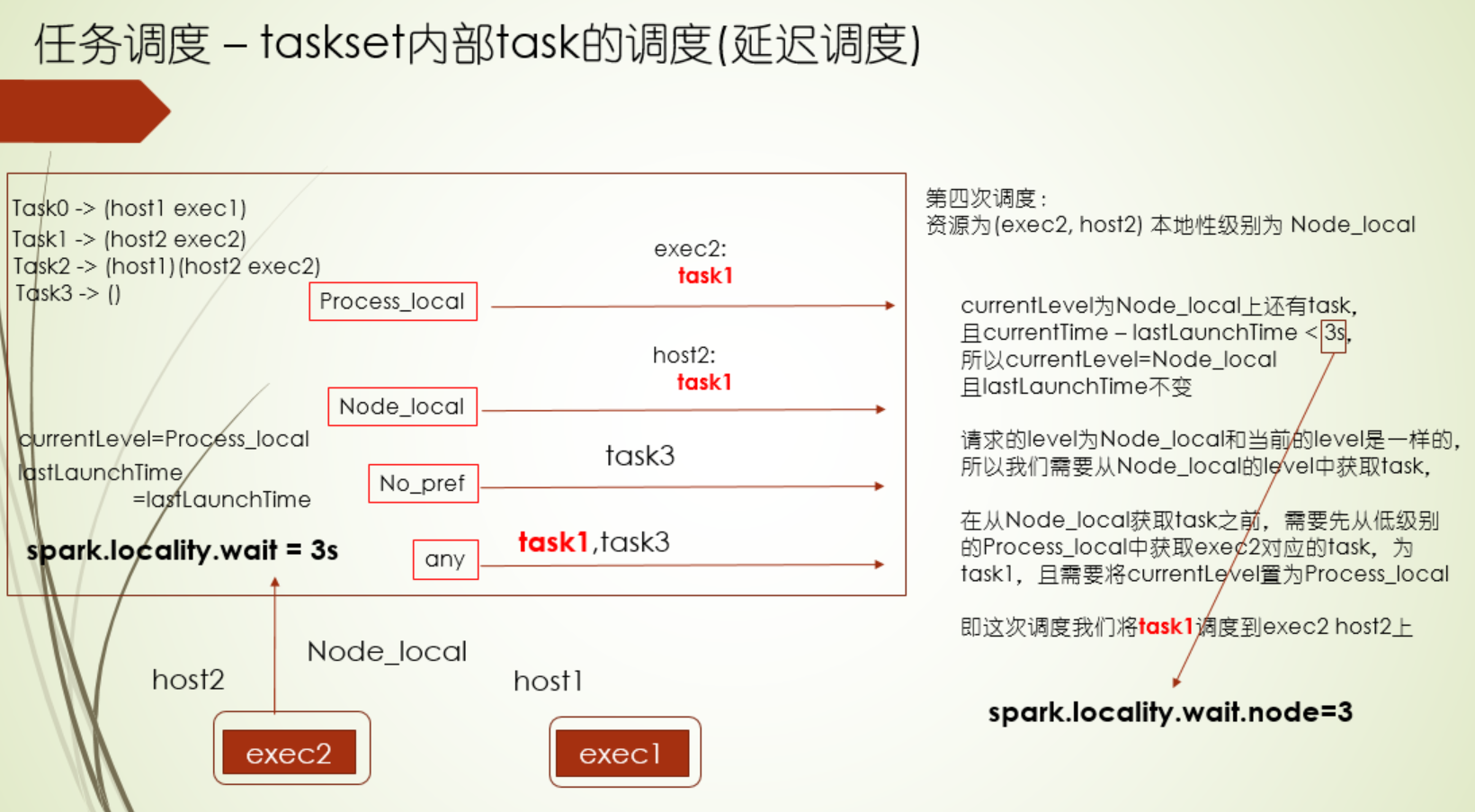


延迟调度配置

如果task执行的时间太长,或者本地性级别太差,那可以尝试调试下延迟调度
推测机制

使用 场景:Spark streaming解决单个task执行时间过长的问题
黑名单机制
打开黑名单机制的两种 方式

黑名单也分三种级别:task,stage,application,并且黑名单的失败次数是可以配置的
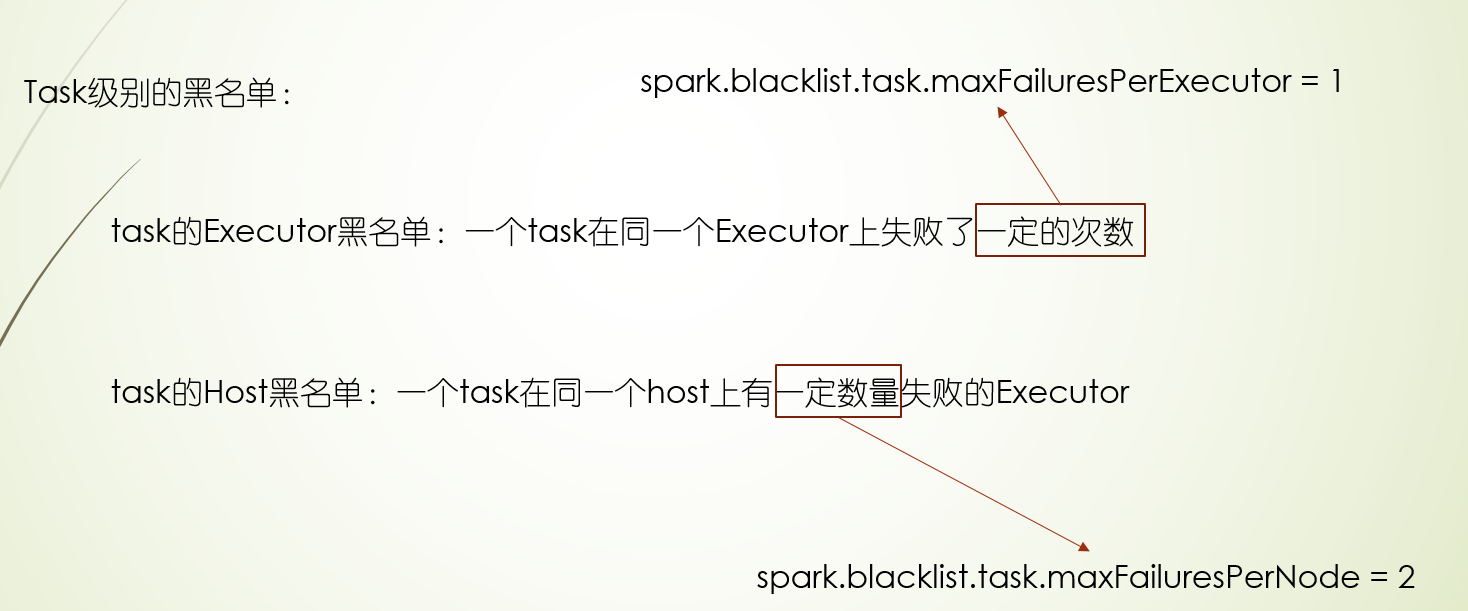
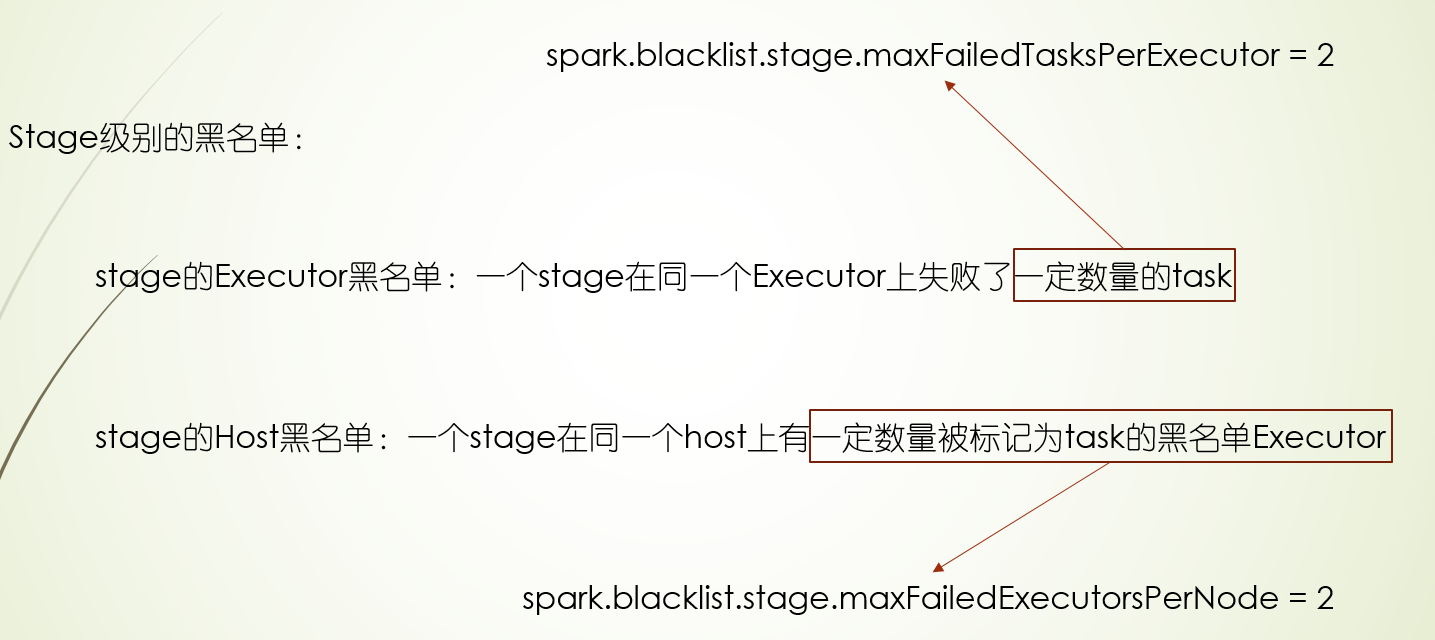
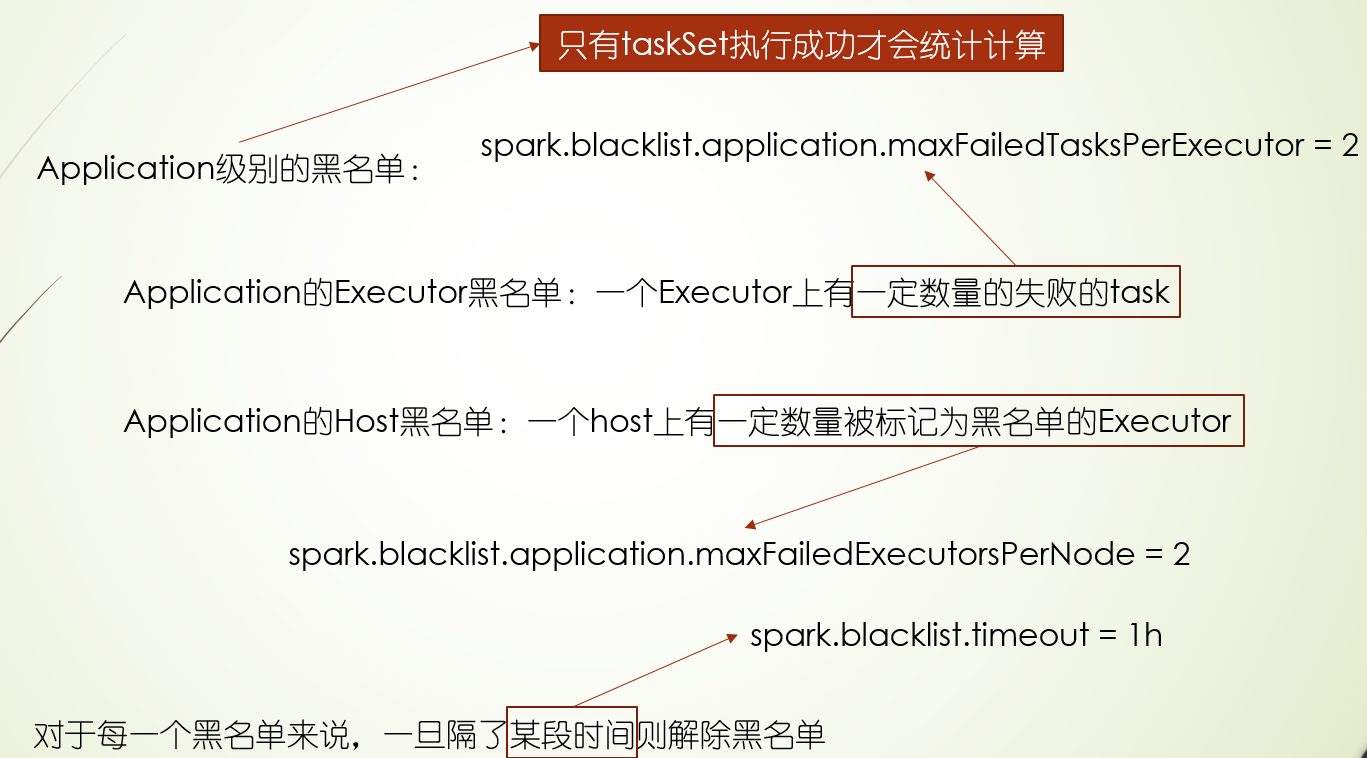
黑名单机制的应用场景:主要某块硬盘或者某个节点坏了,避免应用都跑到坏的节点而导致失败,或者在调试过程中,减少重试次数,让其尽快失败

总结:TaskSet里的Task调度,有一系列的机制来保证高效执行
1.首先是延迟调度机制,它遵循的就是分布式计算里的尽可能少移动数据的原则,根据Executor端程序的位置和数据存储的位置划分了5个计算本地性级别,分别为PROCESS_NODE、NODE_LOCAL、NO_PREF、RACK_LOCAL、ANY,越靠前的,本地性越好,有时候突然释放了Executor资源,但是它和要马上计算的数据的本地性不好,如果直接运行在这个Executor上,性能不好,运行时间反而可能会加长,这种情况,我们不急着让计算这个数据,而是等会儿,如果还是没有合适的Executor,那么再运行在这个Executor上 ,这个就是延迟调度的通俗说法,这个等待时间是可以配置的,并且各个本地性级别等待时间都可以配置,当task执行时间太长时,或者本地性级别太差,那尝试配置这个时间
2.其次是推测机制,这个机制主要判断正在运行的task是否运行太长,然后决定是否重新调度,判断的前提是要有一定数量的task运行成功,主要用在单个task运行时间过长的场景
3.最后黑名单机制,黑名单机制从运行位置分,分为Executor级别和Host级别,从程序级别分,分为task,stage,application三个级别,当程序某个级别在某个Executor或Host上失败的task满足一定条件后,就把会这个程序级别的在这个Executor上或者Host拉入黑名单,后面task不会调度这个Executor上或Host上,黑名单机制常用在调试过程尽快失败,以及集群出现坏盘时,不让task跑在有问题的机器上
task数量和分区调整
1.默认情况下,conf.setMaster("local")本地模式是一个core,所以每个RDD分区数是一个,所以task也是一个,因为在textFile读取文件的时候,默认会 取core的数量和2的最小值,所以 这种情况下task数就一个,包括group操作,join操作,可以看看源码最终都会得到1
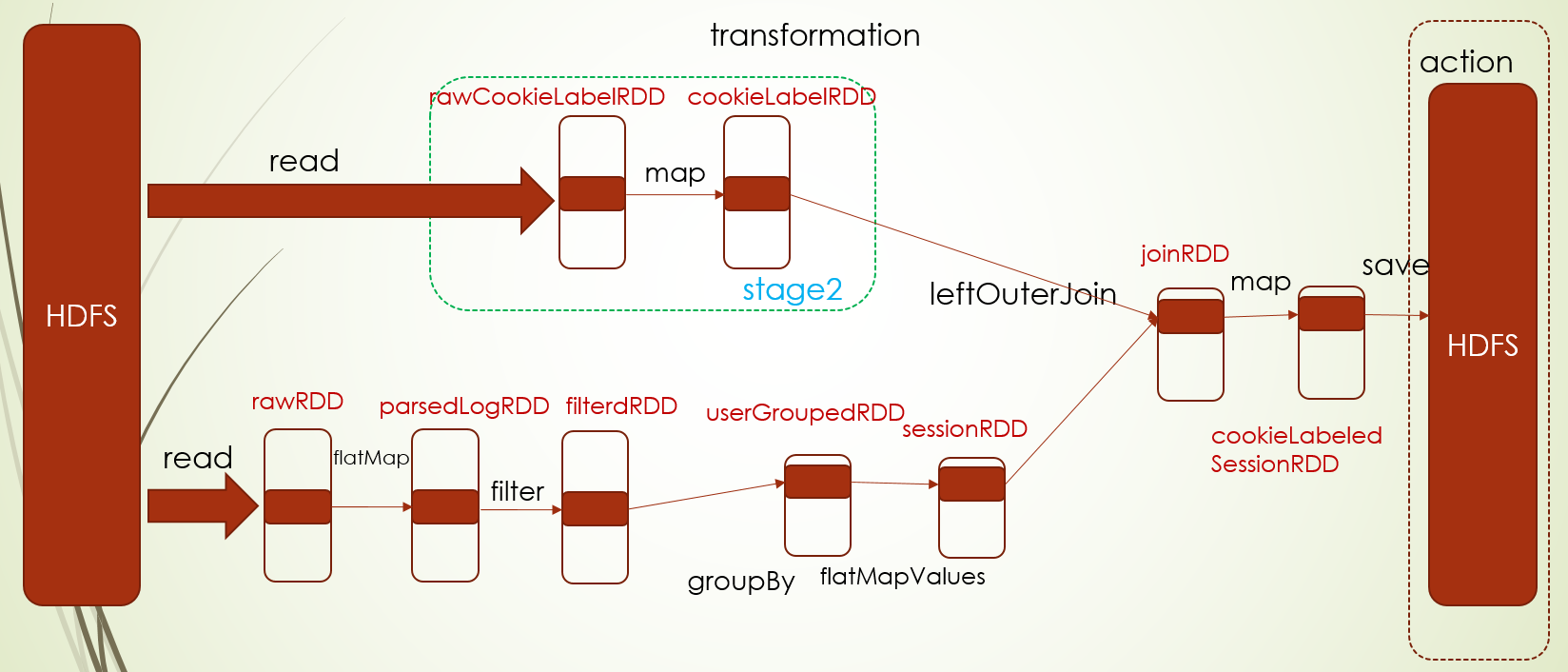
当然也有例外的情况,就是源文件是多个文件,这种 情况就有多个task,比如这里就两个文件

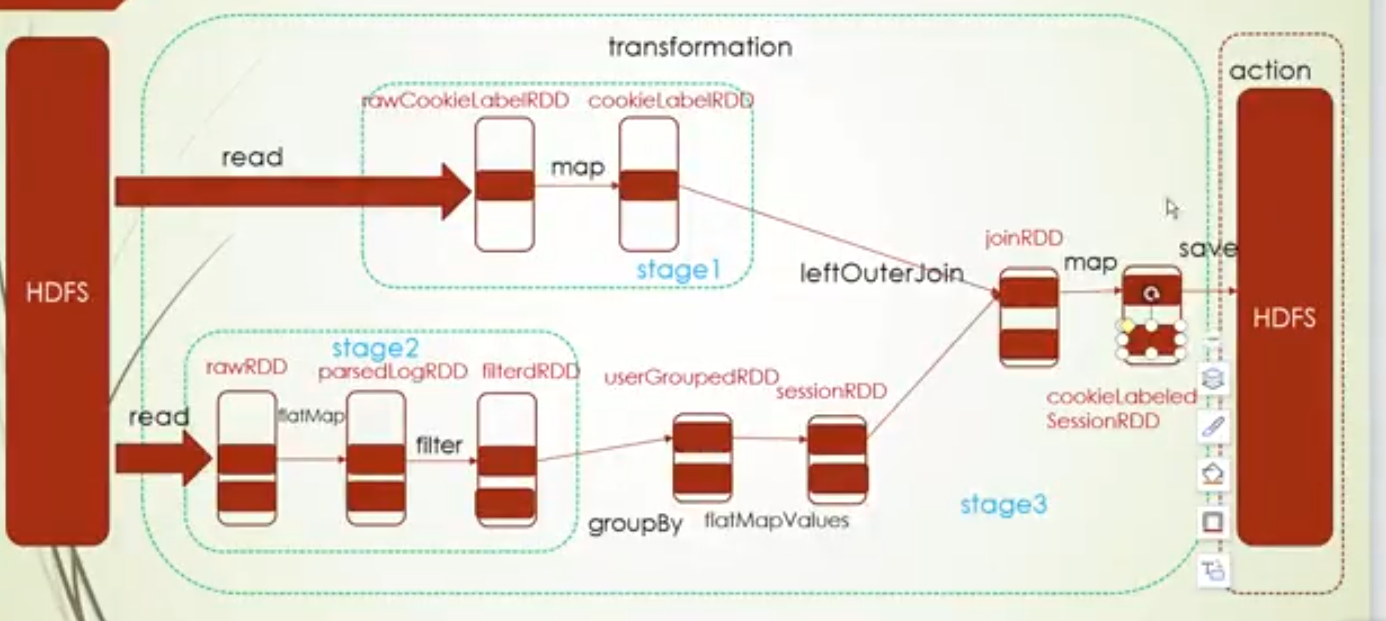
2.更改默认core, conf.setMaster("local[2]"),此时RDD的分区数都为2,所以task的数量为2
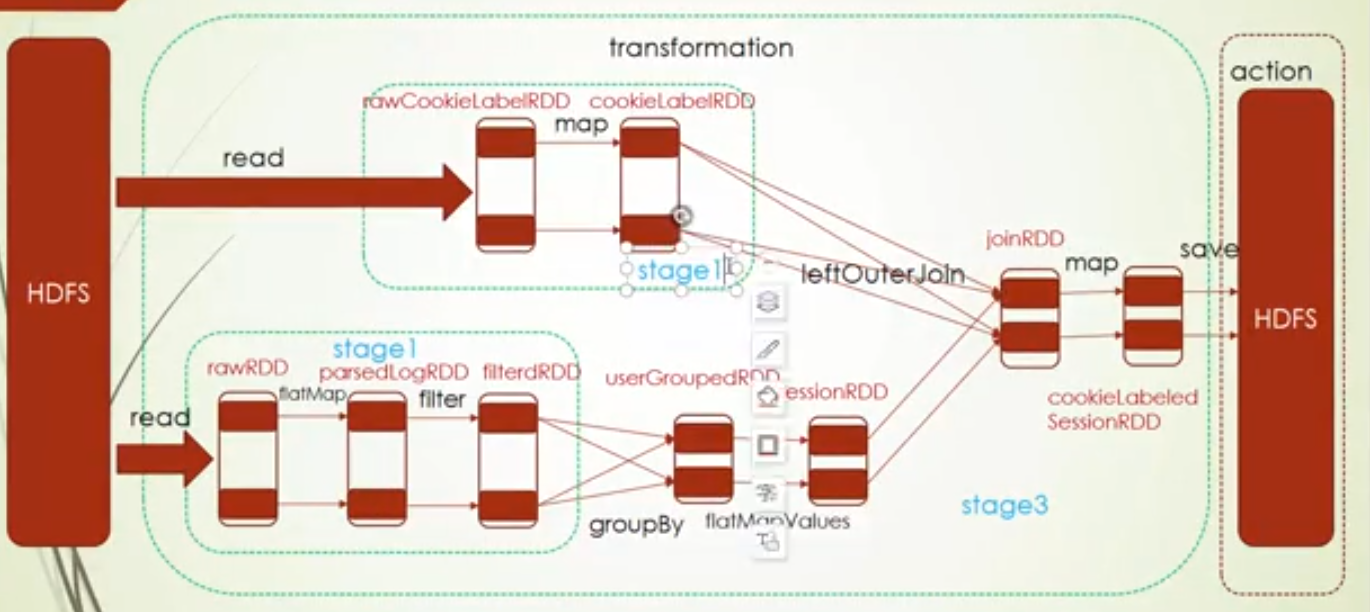
3.设置读取源文件分区数,设置的这个RDD有三个分区,就有3个task,对其他的读取文件的RDD没有这个参数,就会按照core的情况来决定,所以它取上次设置core的数量2和2的最小值,也就是2,所以其他的RDD的task数量为2

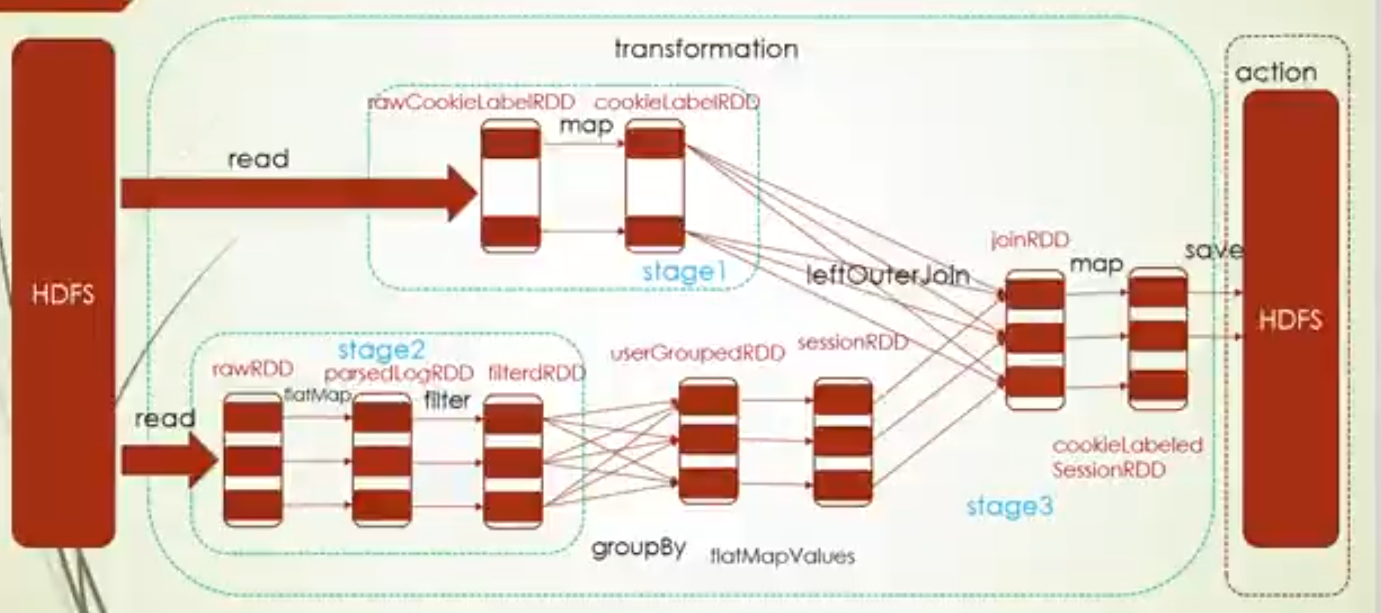
4.group操作设置分区数,下面group操作后RDD分区数就变成2了,也就是两个task

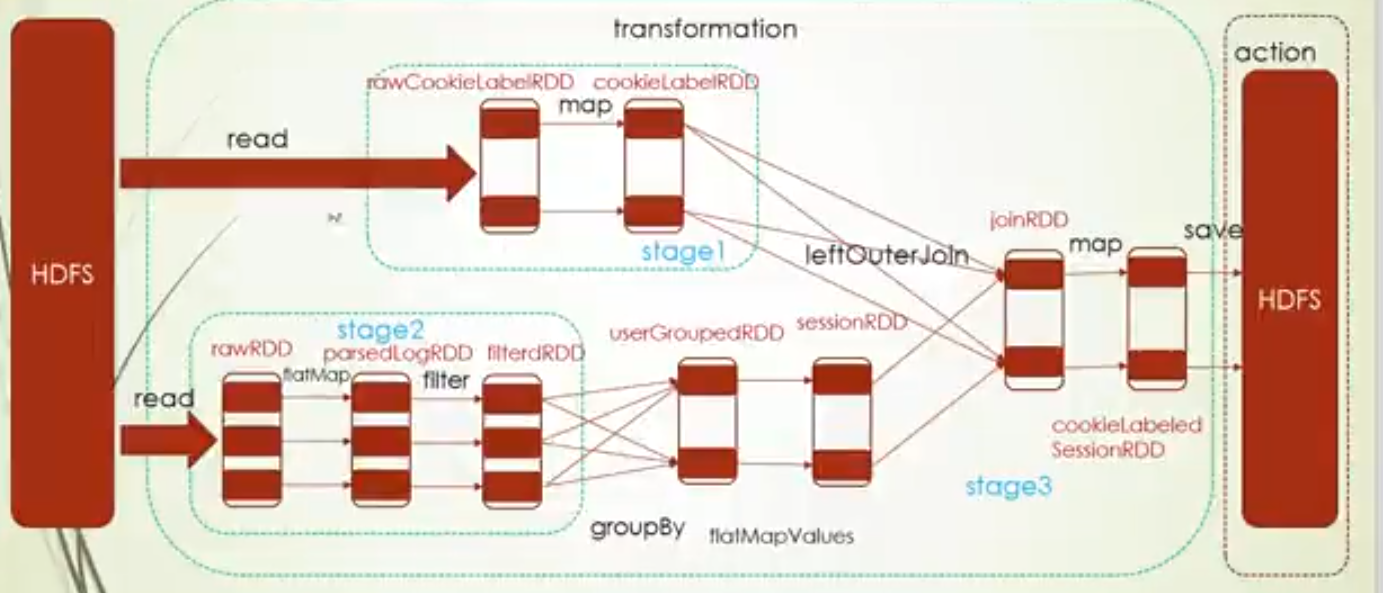
5.join操作设置分区数

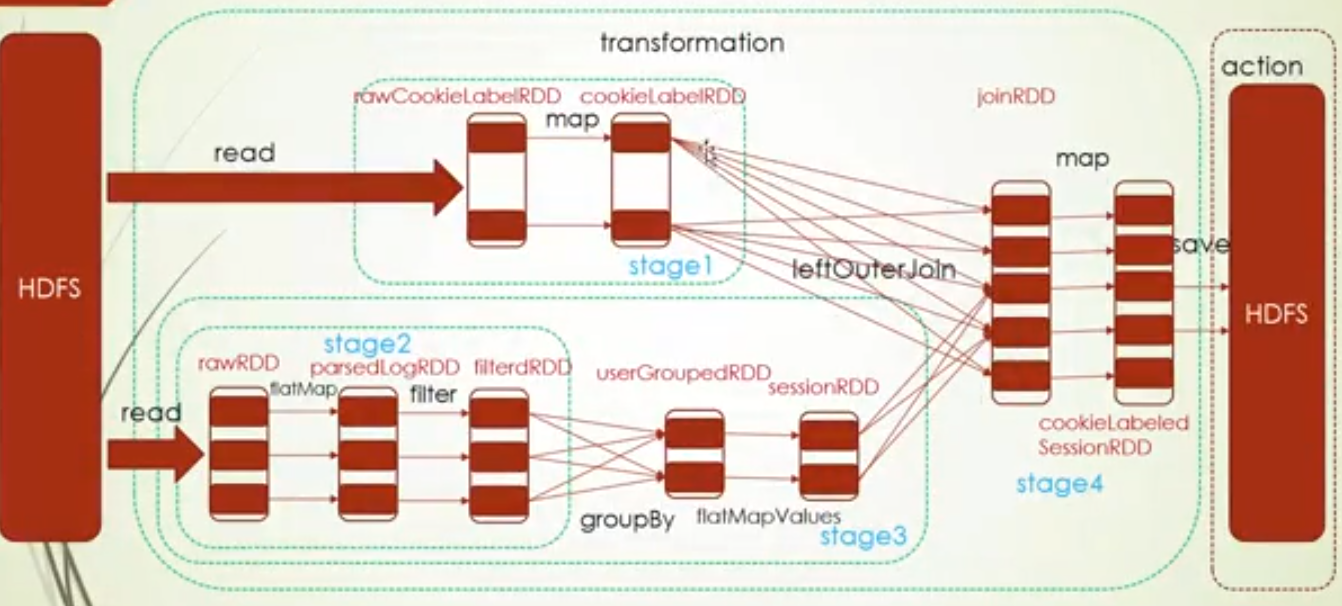
资源调度
在启动完Executor后,Executor会上报自己的信息给资源调度,资源调度会维护一个executorMap的记录Executor上报的信息(execId,info),并把有资源的信息告知给task调度,task调度计算一个最优的task,让资源调度到对应的Executor上启动
Executor上报的信息如下,其中RPC用于资源调度器和Executor进行通信,而第二个信息->网络地址可以用于Spark UI进行访问Executor端的信息

所以资源调度器主要的三大功能
- 资源管理
- 启动task(launch)
- task的状态更新通知(statusUpdate)
task launch

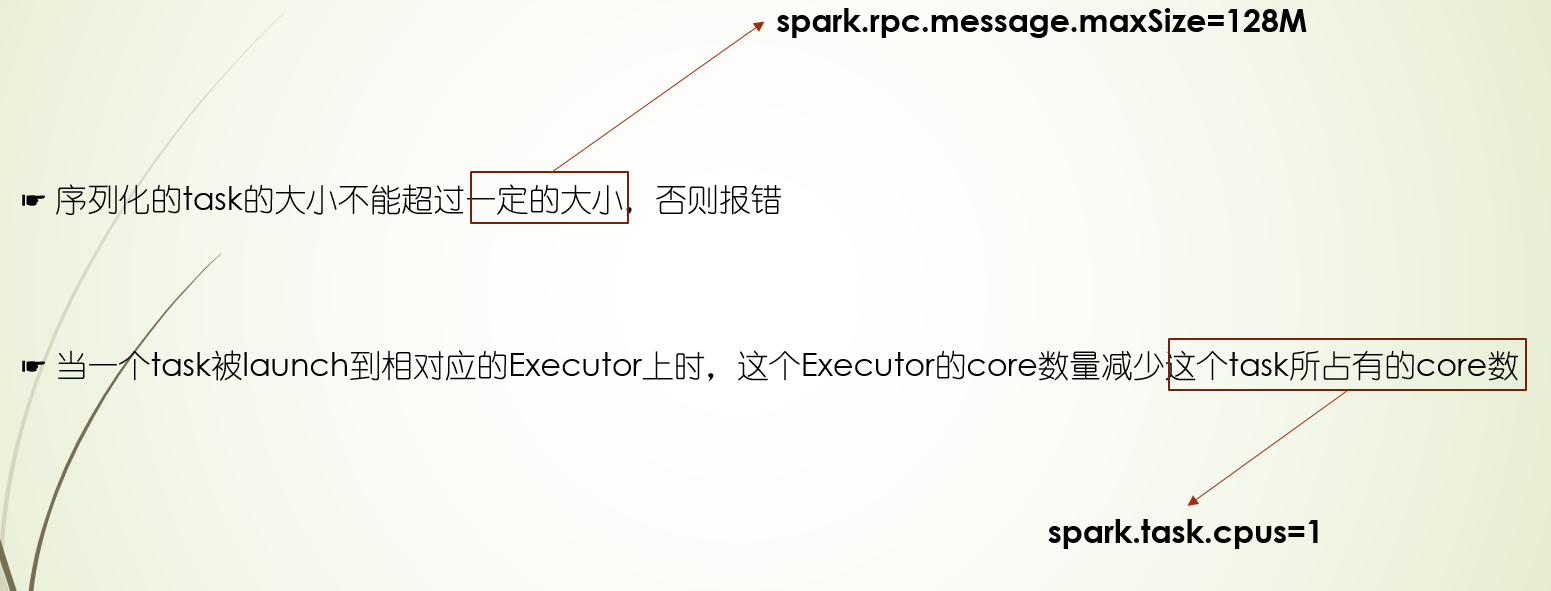
task statusUpdate
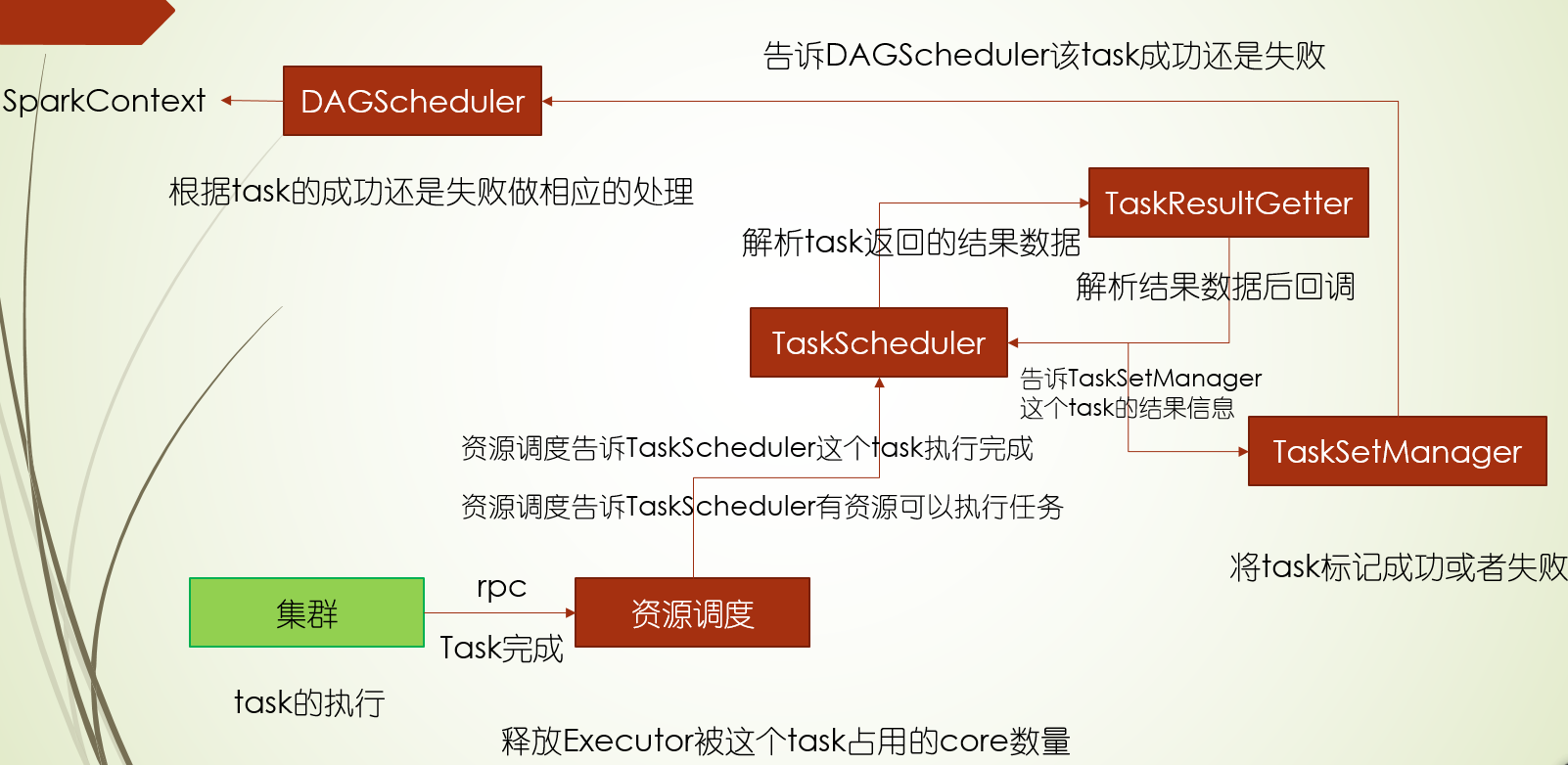
TaskSetManager成功:
DAGScheduler成功:

TaskSetManager失败

DAGScheduler失败

***调度流程图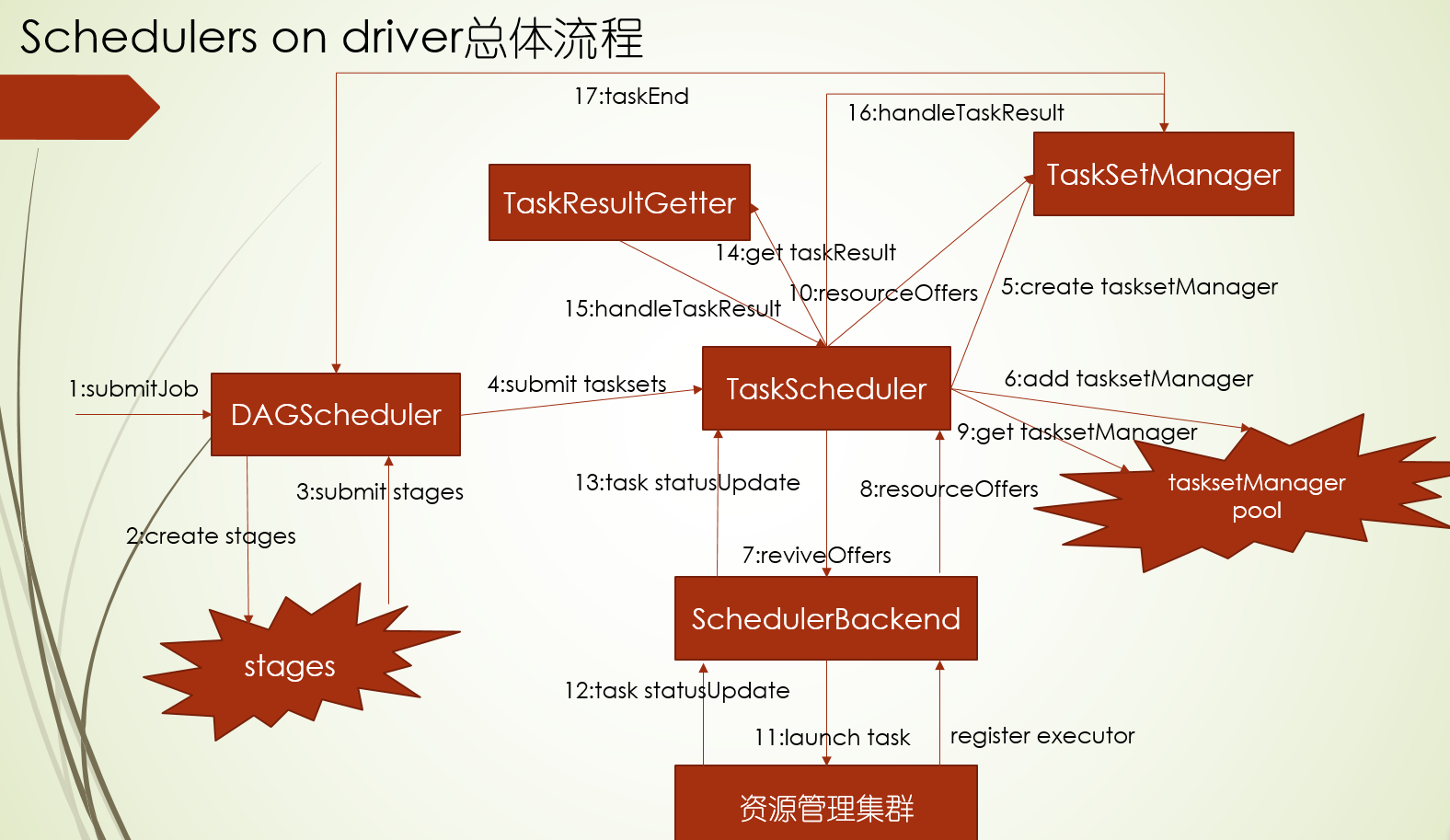
流程源码
待更新。。。。。
多个spark应用调度
***资源分配模式
如果多个spark应用往一个集群上提交,他们之间是怎么调度的呢?
假如现在只有一个spark app提交过程,它按照上面的过程申请资源启动Executor,并调度task,比如这个spark应用提交时指定要两个Executor,有假设每个Executor都分配了3个task执行,运行时Executor1所有的task都运行完了,Executor2还有两个task,这种情况下,Executor1空闲,但是并不会释放,等到Executor2都执行完了,才会把两个Executor释放,这种资源分配方式叫做静态资源分配
如果Executor1不等Executor2执行完,先销毁,留出资源给其他spark应用用,并且在后续过程中,task增多,一个Executor干不过来的,又启动一个Executor来运行task,那么这个过程中资源是在变化的,这种资源分配方式叫做动态资源分配,这种方式下,挂着的task少时,Executor也少,task多时,Executor也多
删除Executor的规则:有缓存数据的情况,配置配Max_value,表示不删除
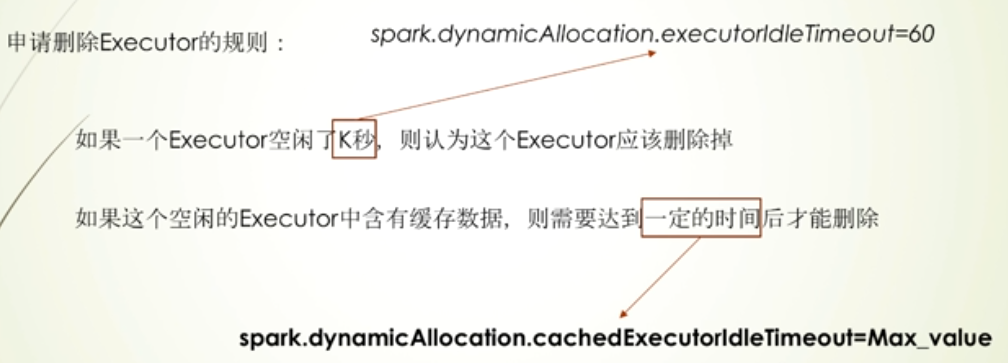
增加Executor的规则:第一种增长情况是慢慢增长,一开始增多了,删除Executor以及启动Executor都是很费时的,第二种增长情况则是task增长过快的情况,因为在M秒后启动过Executor,再等N秒,还task等待,说明task很多,所以这种情况下Executor指数增长(防止task多,Executor少,执行耗时长)

下面的开关是通过--conf进行设置,第一个开关是application级别,第二个开关则是application和集群级别
动态资源分配主要的场景:提交了很多不是很忙的spark应用
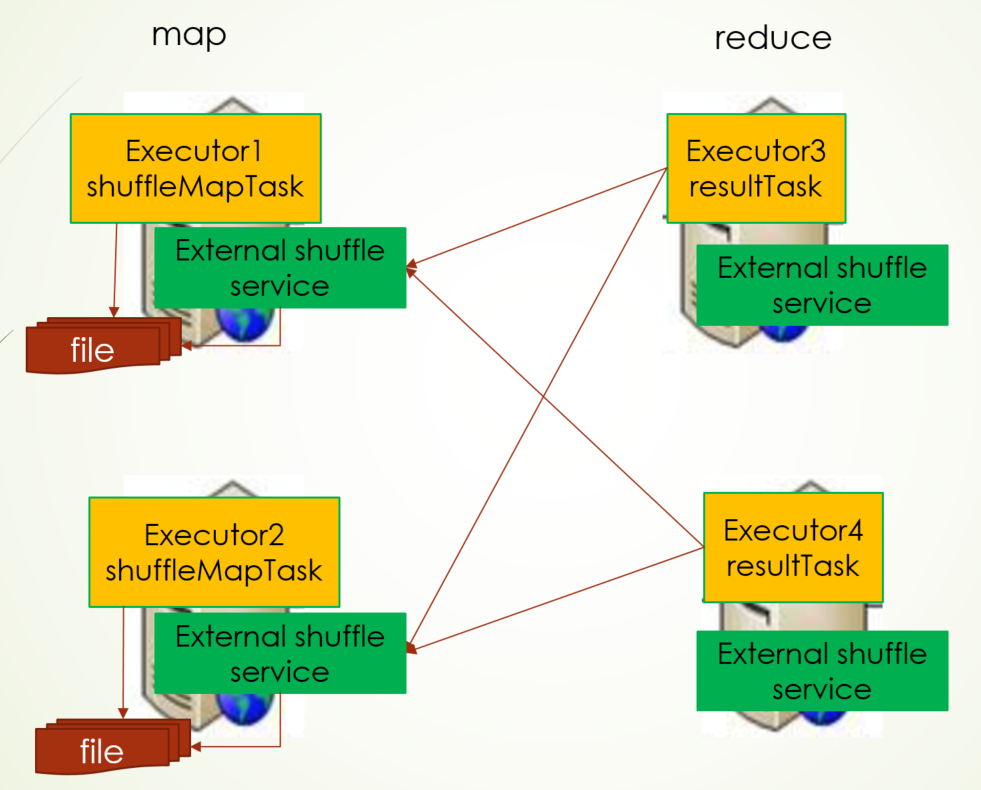
***External shuffle service
在shuffle过程中,Map端shuffleMapTask会把计算结果写入到本地磁盘中,reduce端ResultTask则会去map端读取shuffleMapTask写入磁盘文件的数据,假如现在有一台map端的Executor挂掉了(因为动态资源分配会释放Executor),而此时reduce去map端拉数据肯定是获取不到的,为此,它的解决方案是在每个节点上都会启动External shuffle service,它就是服务shuffle过程拉数据,Executor会在shuffle service上注册,并把计算结果存储地址告诉shuffle service,而reduce端拉取数据会从shuffle service上去拿,并且这么做还提高了Executor端性能,shuffle过程拉取数据都由shuffle service来做
启动External Shuffle Service
spark:

yarn:

yarn classpath路径如下,并且配置在每个NodeManager都要配置,启动日志中可以相关服务的字眼
package com.twq.scheduler
import java.util.concurrent.TimeUnit
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapred.TextInputFormat
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
import org.slf4j.LoggerFactory
/**
* Created by tangweiqun on 2017/8/13.
## --master=spark standalone
## --deploy-mode=client
spark-submit --class com.twq.scheduler.TestExternalShuffleService \
--name "TestExternalShuffleService" \
--master spark://master:7077 \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--total-executor-cores 2 \
--executor-cores 1 \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.shuffle.service.enabled=true \
/home/hadoop-twq/spark-course/spark-scheduler-1.0-SNAPSHOT.jar \
2
2、--master参数
## --master=yarn
## --deploy-mode=client
export HADOOP_CONF_DIR=/home/hadoop-twq/hadoop-2.6.5/etc/hadoop
spark-submit --class com.twq.scheduler.TestExternalShuffleService \
--name "yarn-TestExternalShuffleService" \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 2 \
--executor-cores 1 \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.shuffle.service.enabled=true \
/home/hadoop-twq/spark-course/spark-scheduler-1.0-SNAPSHOT.jar \
2
*/
object TestExternalShuffleService {
private val logger = LoggerFactory.getLogger("WordCount")
def main(args: Array[String]): Unit = {
if (args.size != 1) {
logger.error("arg for partition number is empty")
System.exit(-1)
}
val numPartitions = args(0).toInt
logger.info(s"numPartitions ========= ${numPartitions}")
val conf = new SparkConf()
//conf.setAppName("word count")
val sc = new SparkContext(conf)
val inputRdd: RDD[(LongWritable, Text)] = sc.hadoopFile("hdfs://master:9999/users/hadoop-twq/submitapp/word.txt",
classOf[TextInputFormat], classOf[LongWritable], classOf[Text])
val words: RDD[String] = inputRdd.flatMap(_._2.toString.split(" "))
val wordCount: RDD[(String, Int)] = words.map(word => (word, 1))
val counts: RDD[(String, Int)] = wordCount.reduceByKey(new HashPartitioner(numPartitions), (x, y) => x + y)
val path = new Path("hdfs://master:9999/users/hadoop-twq/submitapp/wordcount")
val configuration = new Configuration()
configuration.set("fs.defaultFS", "hdfs://master:9999")
val fs = path.getFileSystem(configuration)
if (fs.exists(path)) {
fs.delete(path, true)
}
counts.saveAsTextFile(path.toString)
//睡20秒,为了我们查看进程
TimeUnit.SECONDS.sleep(20)
sc.stop()
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号