
前言
笔者最近开始学习如何用DEAP落实进化算法,本文既是教程,也是学习笔记,希望在帮助自己记忆理解的同时对同样正在学习的同学能有所帮助。碍于笔者水平有限,又非运筹优化科班出身,错误难免,请方家多多指正。本文比较长,涉及内容有:
- DEAP简介
- 进化算法简介
- 进化算法中问题的定义、个体编码与初始族群创建
- 个体评价
- 选择操作
- 交叉操作
- 突变操作
关于DEAP
DEAP是一个进化计算框架,能够帮助我们快速实现和测试进化算法。由于它的灵活与强大,目前在Github上已经有2848个star。
DEAP的特性:
- 各类遗传算法
- 遗传规划
- 进化策略
- 多目标优化
- 多种群之间的协作与竞争
- 并行计算
- 计算过程中设定检查点
- 设置基准模块,检验算法能力
- 支持粒子群算法、差分进化算法等
可以简单的使用 pip install deap 来安装,本文基于当前的最新版(deap - 1.2.2)。
进化算法简介
什么是进化算法
进化算法(Evolutionary Algorithms)是一类元启发式算法的统称。这类算法借鉴大自然中生物的进化、选择与淘汰机制,通常先产生一个族群,然后不断进化与淘汰,最终产生能够在严酷的自然环境中生存的优异个体(也就是有较大适应度函数的可行解)。它具有自组织、自适应的特性,常被用来处理传统优化算法难以解决的问题。
进化算法的优缺点
优点:
- 泛用性强,对连续变量和离散变量都能适用;
- 不需要导数信息,因此不要求适应度函数的连续和可微性质(或者说不需要问题内在机理的相关信息);
- 可以在解空间内大范围并行搜索;
- 不容易陷入局部最优;
- 高度并行化,并且容易与其他优化方法整合。
缺点:
- 对于凸优化问题,相对基于梯度的优化方法(例如梯度下降法,牛顿/拟牛顿法)收敛速度更慢;
- 进化算法需要在搜索空间投放大量个体来搜索最优解。对于高维问题,由于搜索空间随维度指数级膨胀,需要投放的个体数也大幅增长,会导致收敛速度变慢;
- 设计编码方式、适应度函数以及变异规则需要大量经验。
进化算法的基本元素
宽泛来讲,大部分进化算法都具有以下元素:
- 个体编码(Individual representation): 将问题的解空间编码映射到搜索空间的过程。常用的编码方式有二值编码(Binary),格雷编码(Gray),浮点编码(Floating-point)等。
- 评价(Evaluation): 设定一定的准则评价族群内每个个体的优秀程度。这种优秀程度通常称为适应度(Fitness)。
- 配种选择(Mating selection): 建立准则从父代中选择个体参与育种。尽可能选择精英个体的同时也应当维护种群的多样性,避免算法过早陷入局部最优。
- 变异(Variation): 变异过程包括一系列受到生物启发的操作,例如重组(Recombination),突变(mutation)等。通过变异操作,父代的个体编码以一定方式继承和重新组合后,形成后代族群。
- 环境选择(Environmental selection): 将父代与子代重组成新的族群。这个过程中育种得到的后代被重新插入到父代种群中,替换父代种群的部分或全体,形成具有与前代相近规模的新族群。
- 停止准则(Stopping crieterion): 确定算法何时停止,通常有两种情况:算法已经找到最优解或者算法已经选入局部最优,不能继续在解空间内搜索。
利用这些元素,我们就可以依照流程图组成一个进化算法:

用文字表述实现一个简单进化算法的过程如下:
Generate the initial population P(0) at random, and set t to 0.
repeat
Evaluate the fitness of each individual in P(t).
Select parents from P(t) based on their fitness.
Obtain population P(t+1) by making variations to parents.
Set t = t + 1
until Stopping crieterion satisfied进化算法各元素的DEAP实现(一):问题定义、个体编码与创建初始族群
1.优化问题的定义
单目标优化:creator.create('FitnessMin', base.Fitness, weights=(-1.0, ))
在创建单目标优化问题时,weights用来指示最大化和最小化。此处-1.0即代表问题是一个最小化问题,对于最大化,应将weights改为正数,如1.0。
另外即使是单目标优化,weights也需要是一个tuple,以保证单目标和多目标优化时数据结构的统一。
对于单目标优化问题,weights 的绝对值没有意义,只要符号选择正确即可。
多目标优化:creator.create('FitnessMulti', base.Fitness, weights=(-1.0, 1.0))
对于多目标优化问题,weights用来指示多个优化目标之间的相对重要程度以及最大化最小化。如示例中给出的(-1.0, 1.0)代表对第一个目标函数取最小值,对第二个目标函数取最大值。
2.个体编码
实数编码(Value encoding):直接用实数对变量进行编码。优点是不用解码,基因表达非常简洁,而且能对应连续区间。但是实数编码后搜索区间连续,因此容易陷入局部最优。
实数编码DEAP实现:
from deap import base, creator, tools
import random
IND_SIZE = 5
creator.create('FitnessMin', base.Fitness, weights=(-1.0,)) #优化目标:单变量,求最小值
creator.create('Individual', list, fitness = creator.FitnessMin) #创建Individual类,继承list
toolbox = base.Toolbox()
toolbox.register('Attr_float', random.random)
toolbox.register('Individual', tools.initRepeat, creator.Individual, toolbox.Attr_float, n=IND_SIZE)
ind1 = toolbox.Individual()
print(ind1)
# 结果:[0.8579615693371493, 0.05774821674048369, 0.8812411734389638, 0.5854279538236896, 0.12908399219828248]这段代码中用了random.random来产生随机数,如果喜欢numpy的,也可以用np.random.rand代替,DEAP的灵活性还是很强的。
二进制编码(Binary encoding):在二进制编码中,用01两种数字模拟人类染色体中的4中碱基,用一定长度的01字符串来描述变量。其优点在于种群多样性大,但是需要解码,而且不连续,容易产生Hamming cliff(例如0111=7, 1000=8,改动了全部的4位数字之后,实际值只变动了1),在接近局部最优位置时,染色体稍有变动,就会使变量产生很大偏移(格雷编码(Gray coding)能够克服汉明距离的问题,但是实际问题复杂度较大时,格雷编码很难精确描述问题)。
变量的二进制编码:
由于通常情况下,搜索空间都是实数空间,因此在编码时,需要建立实数空间到二进制编码空间的映射。使用二进制不能对实数空间进行连续编码,但是可以在给定精度下对连续空间进行离散化。
以例子来说明如何对变量进行二进制编码,假设需要对一个在区间[-2, 2]上的变量进行二进制编码:
选择编码长度:在需要6位精度的情况下,我们需要将该区间离散为 个数。由于
,我们至少需要22位二进制数字来满足我们的精度要求。
设置解码器:将二进制数字 转化为十进制
之后(在python中可以用
int('Binary number', 2)来实现),按照公式 解码,就可以得到一个在[-2,2]区间内的实数。
二进制编码DEAP实现:
以随机生成一个长度为10的二进制编码为例,本身DEAP库中没有内置的Binary encoding,我们可以借助Scipy模块中的伯努利分布来生成一个二进制序列。
from deap import base, creator, tools
from scipy.stats import bernoulli
creator.create('FitnessMin', base.Fitness, weights=(-1.0,)) #优化目标:单变量,求最小值
creator.create('Individual', list, fitness = creator.FitnessMin) #创建Individual类,继承list
GENE_LENGTH = 10
toolbox = base.Toolbox()
toolbox.register('Binary', bernoulli.rvs, 0.5) #注册一个Binary的alias,指向scipy.stats中的bernoulli.rvs,概率为0.5
toolbox.register('Individual', tools.initRepeat, creator.Individual, toolbox.Binary, n = GENE_LENGTH) #用tools.initRepeat生成长度为GENE_LENGTH的Individual
ind1 = toolbox.Individual()
print(ind1)
# 结果:[1, 0, 0, 0, 0, 1, 0, 1, 1, 0]当然,不使用伯努利分布,而是用toolbox.register('Binary', random.randint, 0, 1)也可以达到同样的效果。
序列编码(Permutation encoding):通常在求解顺序问题时用到,例如TSP问题。序列编码中的每个染色体都是一个序列。
序列编码的DEAP实现:
from deap import base, creator, tools
import random
creator.create("FitnessMin", base.Fitness, weights=(-1.0,))
creator.create("Individual", list, fitness=creator.FitnessMin)
IND_SIZE=10
toolbox = base.Toolbox()
toolbox.register("Indices", random.sample, range(IND_SIZE), IND_SIZE)
toolbox.register("Individual", tools.initIterate, creator.Individual,toolbox.Indices)
ind1 = toolbox.Individual()
print(ind1)
#结果:[0, 1, 5, 8, 2, 3, 6, 7, 9, 4]同样的,这里的random.sampole也可以用np.random.permutation代替。
粒子(Particles):粒子是一种特殊个体,主要用于粒子群算法。相比普通的个体,它额外具有速度、速度限制并且能记录最优位置。
粒子的DEAP实现:
import random
from deap import base, creator, tools
creator.create("FitnessMax", base.Fitness, weights=(1.0, 1.0))
creator.create("Particle", list, fitness=creator.FitnessMax, speed=None,
smin=None, smax=None, best=None)
# 自定义的粒子初始化函数
def initParticle(pcls, size, pmin, pmax, smin, smax):
part = pcls(random.uniform(pmin, pmax) for _ in range(size))
part.speed = [random.uniform(smin, smax) for _ in range(size)]
part.smin = smin
part.smax = smax
return part
toolbox = base.Toolbox()
toolbox.register("Particle", initParticle, creator.Particle, size=2, pmin=-6, pmax=6, smin=-3, smax=3) #为自己编写的initParticle函数注册一个alias "Particle",调用时生成一个2维粒子,放在容器creator.Particle中,粒子的位置落在(-6,6)中,速度限制为(-3,3)
ind1 = toolbox.Particle()
print(ind1)
print(ind1.speed)
print(ind1.smin, ind1.smax)
# 结果:[-2.176528549934324, -3.0796558214905]
#[-2.9943676285620104, -0.3222138308543414]
#-3 3
print(ind1.fitness.valid)
# 结果:False
# 因为当前还没有计算适应度函数,所以粒子的最优适应度值还是invalid
DEAP中的个体生成函数
- initRepeat:
deap.tools.initRepeat(container, func, n)
输入:
container - 数据容器
func - 调用n次,用以产生数据填充数据容器的函数;其返回值可以是列表或者是单个值
n - 重复func的次数
代码示例:
# initRepeat中的函数可以返回单个值
def myFun():
return random.randint(0,1)
tools.initRepeat(list, myFun, 10)
# 结果:
# [1, 1, 0, 1, 0, 1, 1, 1, 1, 1]
# initRepeat中的函数也可以返回列表
def myFun():
return [random.randint(0,1) for _ in range(3)]
tools.initRepeat(list, myFun, 10)
# 结果:
# [[1, 0, 1],
# [0, 1, 1],
# [1, 0, 1],
# [0, 1, 1],
# [0, 1, 0],
# [0, 1, 0],
# [1, 0, 0],
# [1, 1, 0],
# [0, 1, 1],
# [0, 1, 0]]
- initIterate
deap.tools.initIterate(container, generator)
输入:
container - 数据容器
generator - 返回一个可迭代对象(list, tuple),返回的可迭代对象会用来填充数据容器
代码示例:
# initIterate
def myFun():
return [random.randint(0,1) for _ in range(3)]
tools.initIterate(list, myFun)
# 结果:
# [1, 0, 0]
- initCycle
deap.tools.initCycle(container, seq_func, n=1)
输入:
container - 数据容器
seq_func - 一个函数列表,被循环调用来填充数据容器
n - 循环生成的次数
代码示例:
# initCycle
def fun1():
return random.random()
def fun2():
return random.randint(0,1)
funList = [fun1, fun2]
tools.initCycle(list, funList, 3)
# 结果:
# [0.5517038947997075, 1, 0.7458837793951623, 0, 0.9399259038570086, 0]3.初始族群的创建:
一般族群:这是最常用的族群类型,族群中没有特别的顺序或者子族群。
一般族群的DEAP实现:toolbox.register('population', tools.initRepeat, list, toolbox.individual)
以二进制编码为例,以下代码可以生成由10个长度为5的随机二进制编码个体组成的一般族群:
from deap import base, creator, tools
from scipy.stats import bernoulli
# 定义问题
creator.create('FitnessMin', base.Fitness, weights=(-1.0,)) # 单目标,最小化
creator.create('Individual', list, fitness = creator.FitnessMin)
# 生成个体
GENE_LENGTH = 5
toolbox = base.Toolbox() #实例化一个Toolbox
toolbox.register('Binary', bernoulli.rvs, 0.5)
toolbox.register('Individual', tools.initRepeat, creator.Individual, toolbox.Binary, n=GENE_LENGTH)
# 生成初始族群
N_POP = 10
toolbox.register('Population', tools.initRepeat, list, toolbox.Individual)
toolbox.Population(n = N_POP)
# 结果:
# [[1, 0, 1, 1, 0],
# [0, 1, 1, 0, 0],
# [0, 1, 0, 0, 0],
# [1, 1, 0, 1, 0],
# [0, 1, 1, 1, 1],
# [0, 1, 1, 1, 1],
# [1, 0, 0, 0, 1],
# [1, 1, 0, 1, 0],
# [0, 1, 1, 0, 1],
# [1, 0, 0, 0, 0]]
同类群(Demes):同类群即一个族群中包含几个子族群。在有些算法中,会使用本地选择(Local selection)挑选育种个体,这种情况下个体仅与同一邻域的个体相互作用。
同类群的DEAP实现:
toolbox.register("deme", tools.initRepeat, list, toolbox.individual)
DEME_SIZES = 10, 50, 100
population = [toolbox.deme(n=i) for i in DEME_SIZES]
粒子群:粒子群中的所有粒子共享全局最优。在实现时需要额外传入全局最优位置与全局最优适应度给族群。
粒子群的DEAP实现:
creator.create("Swarm", list, gbest=None, gbestfit=creator.FitnessMax)
toolbox.register("swarm", tools.initRepeat, creator.Swarm, toolbox.particle)在算法迭代时,需要更新该轮迭代中最优的位置和最优适应度。
进化算法各元素的DEAP实现(二):评价
评价部分是根据任务的特性高度定制的,DEAP库中并没有预置的评价函数模版。
在使用DEAP时,需要注意的是,无论是单目标还是多目标优化,评价函数的返回值必须是一个tuple类型。
来做一个简单的例子:
from deap import base, creator, tools
import numpy as np
# 定义问题
creator.create('FitnessMin', base.Fitness, weights=(-1.0,)) #优化目标:单变量,求最小值
creator.create('Individual', list, fitness = creator.FitnessMin) #创建Individual类,继承list
# 生成个体
IND_SIZE = 5
toolbox = base.Toolbox()
toolbox.register('Attr_float', np.random.rand)
toolbox.register('Individual', tools.initRepeat, creator.Individual, toolbox.Attr_float, n=IND_SIZE)
# 生成初始族群
N_POP = 10
toolbox.register('Population', tools.initRepeat, list, toolbox.Individual)
pop = toolbox.Population(n = N_POP)
# 定义评价函数
def evaluate(individual):
return sum(individual), #注意这个逗号,即使是单变量优化问题,也需要返回tuple
# 评价初始族群
toolbox.register('Evaluate', evaluate)
fitnesses = map(toolbox.Evaluate, pop)
for ind, fit in zip(pop, fitnesses):
ind.fitness.values = fit
print(ind.fitness.values)
# 结果:
# (2.593989197511478,)
# (1.1287944225903104,)
# (2.6030877077096717,)
# (3.304964061515382,)
# (2.534627558467466,)
# (2.4697149450205536,)
# (2.344837782191844,)
# (1.8959030773060852,)
# (2.5192475334239,)
# (3.5069764929866585,)进化算法各元素的DEAP实现(三):配种选择
1.DEAP内置的选择操作
DEAP的tools模块中内置了13种选择操作,对全部选择算子的描述可以参考官方文档。
函数简介
2.常用选择操作介绍
下面简单介绍一些常用的配种选择操作:
锦标赛选择:deap.tools.selTournament(individuals, k, tournsize, fit_attr = 'fitness')
锦标赛选择顾名思义,就是模拟锦标赛的方式,首先在族群中随机抽取tournsize个个体,然后从中选取具有最佳适应度的个体,将此过程重复k次,获得育种族群。tournsize越大,选择强度(selection intensity)越高,在选择之后留下的育种族群的平均适应度也就越高。比较常用的tournsize是2。
下图给出了由5个个体构成的族群中进行一次tournsize为3的锦标赛选择的过程。
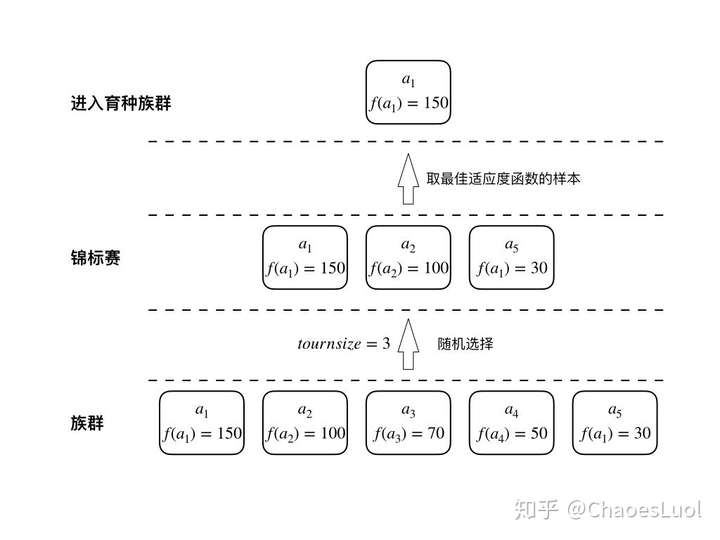
锦标赛选择相比于轮盘赌选择,通常能够有更快的收敛速度,在实际场景中应用较多。
轮盘赌选择:deap.tools.selRoulette(individuals, k, fit_attr = 'fitness')
轮盘赌选择是最常见的选择策略,它可以看作是有放回的随机抽样。
在轮盘赌选择中,每个个体 被选中的概率
与其适应度函数
成正比:
下图给出了与前文同样例子的轮盘赌选择:
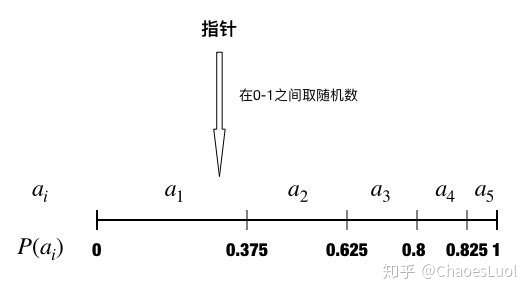
注意在适应度可能为负数时,不适合用轮盘赌选择。
在实际应用中,很多文章都指出轮盘赌选择的性能较差,在通常情况下都不如随机抽样选择和锦标赛选择。
随机普遍抽样选择:deap.tools.selStochasticUniversalSampling(individuals, k, fit_attr = 'fitness')
随机普遍抽样选择是一种有多个指针的轮盘赌选择,其优点是能够保存族群多样性,而不会像轮盘赌一样,有较大几率对重复选择最优个体。
在与前文相同的例子中使用随机普遍抽样选择,设定指针数k为3,那么指针间距即为 ,如下图所示:
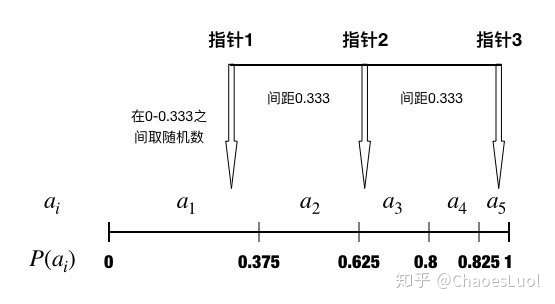
NSGA-II 选择:deap.tools.selNSGA2(individuals, k, nd = 'standard')
NSGA-II全称为 Nondominated sorting genetic algorithm II,是Kalyanmoy Deb于2002年提出的。该方法解决了前代NSGA的三个痛点:计算复杂度高;缺少精英选择;需要给定额外参数值。
在使用该函数时,需要注意族群中个体数量必须要比k值大,因为在该算法中,每个个体在返回的选择列表中至多出现一次。
由于本文意在工程应用,解释复杂的算法非我本意,需要详细了解该算法的同学可以参见这里,Deb教授在实验室网站上也给出了算法的C语言实现。
此外,一些基于排序的选择算法,如Linear ranking selection, Exponential ranking selection等,在DEAP中都没有给出直接的函数,需要自己实现。
3.选择操作代码示例
这里我们接着评价那一节使用的代码,加上常见的选择操作:
from deap import base, creator, tools
import numpy as np
# 定义问题
creator.create('FitnessMin', base.Fitness, weights=(-1.0,)) #优化目标:单变量,求最小值
creator.create('Individual', list, fitness = creator.FitnessMin) #创建Individual类,继承list
# 生成个体
IND_SIZE = 5
toolbox = base.Toolbox()
toolbox.register('Attr_float', np.random.rand)
toolbox.register('Individual', tools.initRepeat, creator.Individual, toolbox.Attr_float, n=IND_SIZE)
# 生成初始族群
N_POP = 10
toolbox.register('Population', tools.initRepeat, list, toolbox.Individual)
pop = toolbox.Population(n = N_POP)
# 定义评价函数
def evaluate(individual):
return sum(individual), #注意这个逗号,即使是单变量优化问题,也需要返回tuple
# 评价初始族群
toolbox.register('Evaluate', evaluate)
fitnesses = map(toolbox.Evaluate, pop)
for ind, fit in zip(pop, fitnesses):
ind.fitness.values = fit
# 选择方式1:锦标赛选择
toolbox.register('TourSel', tools.selTournament, tournsize = 2) # 注册Tournsize为2的锦标赛选择
selectedTour = toolbox.TourSel(pop, 5) # 选择5个个体
print('锦标赛选择结果:')
for ind in selectedTour:
print(ind)
print(ind.fitness.values)
# 选择方式2: 轮盘赌选择
toolbox.register('RoulSel', tools.selRoulette)
selectedRoul = toolbox.RoulSel(pop, 5)
print('轮盘赌选择结果:')
for ind in selectedRoul:
print(ind)
print(ind.fitness.values)
# 选择方式3: 随机普遍抽样选择
toolbox.register('StoSel', tools.selStochasticUniversalSampling)
selectedSto = toolbox.StoSel(pop, 5)
print('随机普遍抽样选择结果:')
for ind in selectedSto:
print(ind)
print(ind.fitness.values)
#结果:
#锦标赛选择结果:
#[0.2673058115582905, 0.8131397980144155, 0.13627430737326807, 0.10792026110464248, 0.4166962522797264]
#(1.741336430330343,)
#[0.5448284697291571, 0.9702727117158071, 0.03349947770537576, 0.7018813286570782, 0.3244029157717422]
#(2.5748849035791603,)
#[0.8525836387058023, 0.28064482205939634, 0.9235436615033125, 0.6429467684175085, 0.5965523553349544]
#(3.296271246020974,)
#[0.5243293164960845, 0.37883291328325286, 0.28423194217619596, 0.5005947374376103, 0.3017896612109636]
#(1.9897785706041071,)
#[0.4038211036464676, 0.841374996509095, 0.3555644512425019, 0.5849111474726337, 0.058759891556433574]
#(2.2444315904271317,)
#轮盘赌选择结果:
#[0.42469039733882064, 0.8411201950346711, 0.6322812691061555, 0.7566549973076343, 0.9352307652371067]
#(3.5899776240243884,)
#[0.42469039733882064, 0.8411201950346711, 0.6322812691061555, 0.7566549973076343, 0.9352307652371067]
#(3.5899776240243884,)
#[0.5448284697291571, 0.9702727117158071, 0.03349947770537576, 0.7018813286570782, 0.3244029157717422]
#(2.5748849035791603,)
#[0.630305953330188, 0.09565983206218687, 0.890691659939096, 0.8706091807317707, 0.19708949882847437]
#(2.684356124891716,)
#[0.5961060867498598, 0.4300051776616509, 0.4512760237511251, 0.047731561819711055, 0.009892120639829804]
#(1.5350109706221766,)
#随机普遍抽样选择结果:
#[0.2673058115582905, 0.8131397980144155, 0.13627430737326807, 0.10792026110464248, 0.4166962522797264]
#(1.741336430330343,)
#[0.4038211036464676, 0.841374996509095, 0.3555644512425019, 0.5849111474726337, 0.058759891556433574]
#(2.2444315904271317,)
#[0.630305953330188, 0.09565983206218687, 0.890691659939096, 0.8706091807317707, 0.19708949882847437]
#(2.684356124891716,)
#[0.40659881466060876, 0.8387139101647804, 0.28504735705240236, 0.46171554118627334, 0.7843353275244066]
#(2.7764109505884718,)
#[0.42469039733882064, 0.8411201950346711, 0.6322812691061555, 0.7566549973076343, 0.9352307652371067]
#(3.5899776240243884,)进化算法各元素的DEAP实现(四):变异
变异过程就是从父代的基因出发,进行操作,最终得到子代基因的过程。通常包括交叉(Crossover)和突变(Mutation)两种操作。
1.DEAP内置的交叉(Crossover)操作
函数简介适用编码方式
2.常用交叉操作介绍
单点交叉:deap.tools.cxOnePoint(ind1, ind2)
最简单的交叉方式,选择一个切口,将两条基因切开之后,交换尾部基因段。尽管该方法非常简单,但是多篇文章指出,该算法在各种实验中性能都被其他交叉算法吊打,因此算是一种不建议使用的loser algorithm,参考这里。
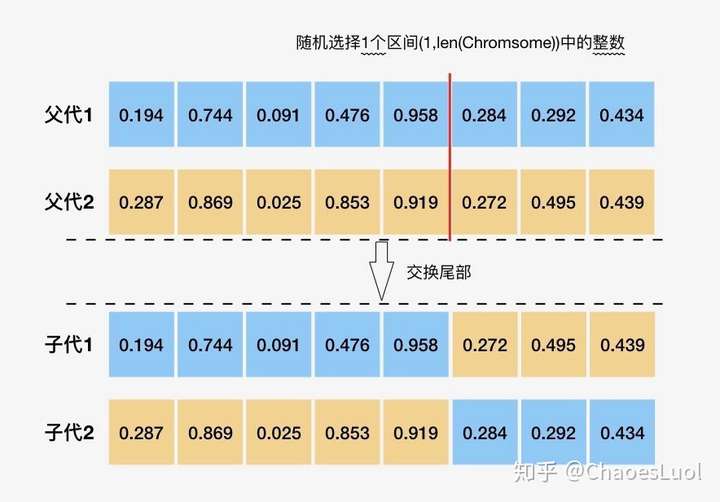
两点交叉:deap.tools.cxTwoPoint(ind1, ind2)
用两个点切开基因之后,交换切出来的基因段。
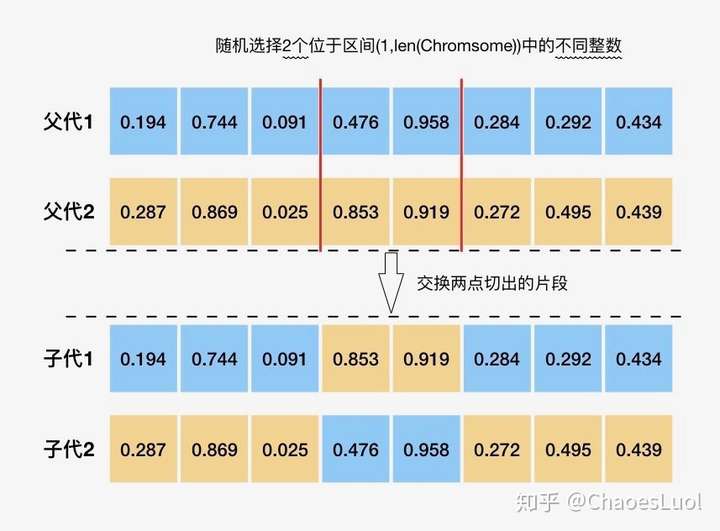
均匀交叉:deap.tools.cxUniform(ind1, ind2, indpb)
指定一个变异几率,两父代中的每个基因都以该几率交叉。
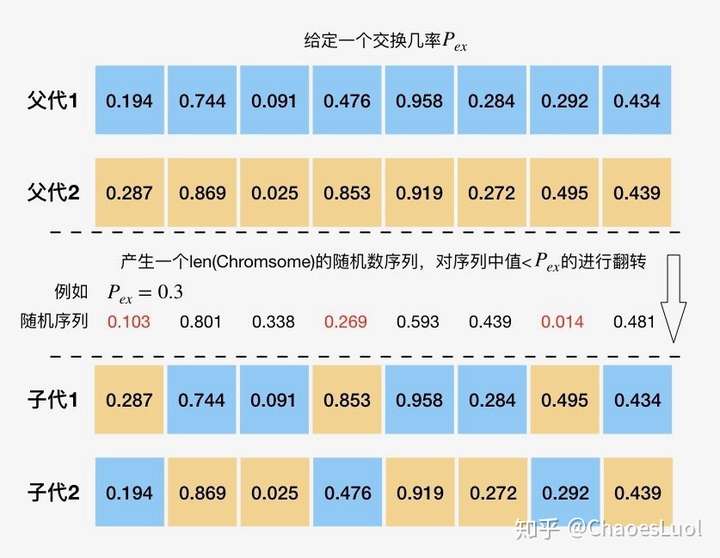
部分匹配交叉:deap.tools.cxPartialyMatched(ind1, ind2)
部分匹配交叉主要用于序列编码的个体,进行部分匹配交叉包括3个步骤:首先,选择父辈1的一段基因,复制到子代中;其次,查找父辈2中同位置的基因段,选择没有被复制的基因,建立一个映射关系;最后,进行冲突检查,如果基因有冲突,则通过建立的映射变换为无冲突的基因,保证形成的一对子代基因无冲突。我尽力用语言描述了一个例子:
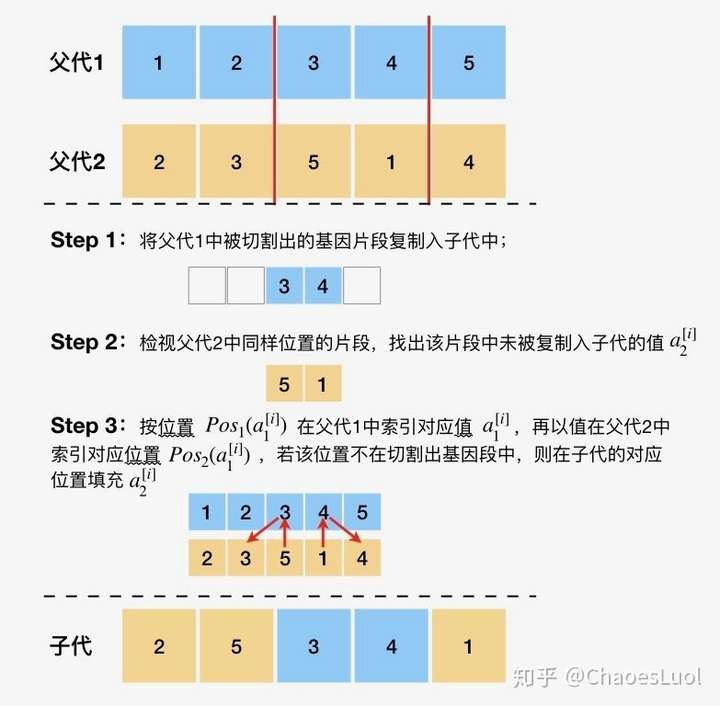
PMX用语言形容起来比较困难,更具体的阐述可以参考这里。
当解决路径规划问题时,如果最优sub-subrouine越长,PMX交叉后就越难在子代中保留。
需要注意的是DEAP中的cxPartialyMatched默认需要序列编码在range(0,len(sequence))之中,所以如果是从1开始编码的话,需要在交叉前后进行手动转换。
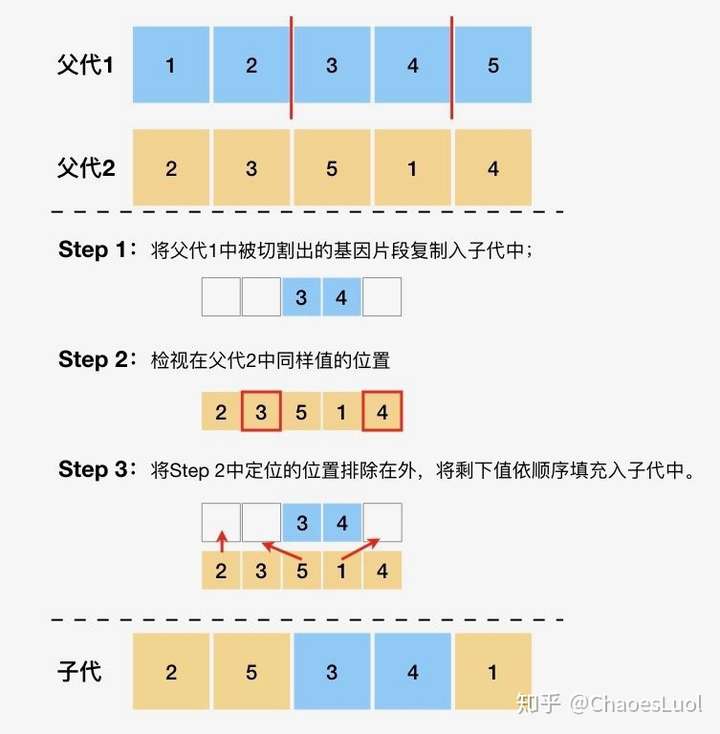
有序交叉:deap.tools.cxOrdered(ind1, ind2)
混合交叉:deap.tools.cxBlend(ind1, ind2, alpha)
混合交叉由Eshelman和Schaffer在1993年提出,常见的混合交叉算子有 与
两种,DEAP中内置的是前者。其具体算法如下:
- 选择两个父代
和
- 对基因
,计算
- 在区间
之间取随机数
- 将该随机数作为子代的片段,即
对于任意 ,混合交叉会扩张搜索空间,因此应用于受到约束的变量时需要注意。有些研究认为
时,搜索效果优于其他值。
模拟二值交叉:deap.tools.cxSimulatedBinary(ind1, ind2, eta)
SBX是在1995年由Deb和Agrawal提出来的。二进制编码有只能进行离散搜索,Hamming cliff等问题,而实数编码尽管能在连续域上操作,但是搜索能力较弱(此处搜索能力定义为给定一对父辈,产生任意子代的几率,可以用扩散系数表征)。模拟二值交叉试图综合二者的优势,在实数编码上模拟二进制编码的搜索特点。
参数 越大,产生的子代与父代越接近;该参数越小,产生的子代越可能与父代差距较大。
作者认为SBX在较难的测试中,表现比BLX-0.5要更优,尤其在多局部最优问题中表现出色。更具体的测试可以参见原文。
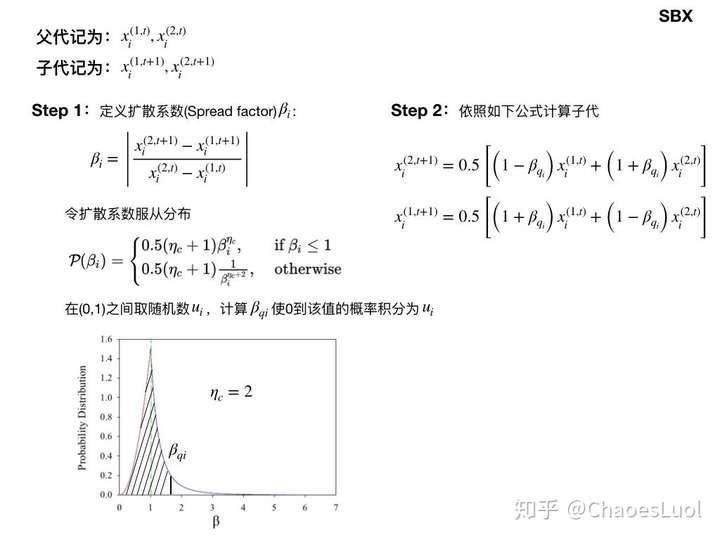
Deb教授在2007年又提出了改进型:Self-adaptive SBX,对学术部分感兴趣的可以参见这篇文章。
混乱单点交叉:deap.tools.cxMessyOnePoint(ind1, ind2)
混乱单点交叉源自一篇挺有意思的文章(本人猜测,未得到开发人员证实)。作者质疑为何遗传算法中的基因都是如此有序:长短一致,编码方式整整齐齐,反而在自然界中这样的规律并不多见。因而作者提出了Messy GA,在这篇文章中,他将交叉操作拆分为cut与splice。Messy Crossover与一般的单点交叉最大的不同在于序列长度不会保持,如下图所示:
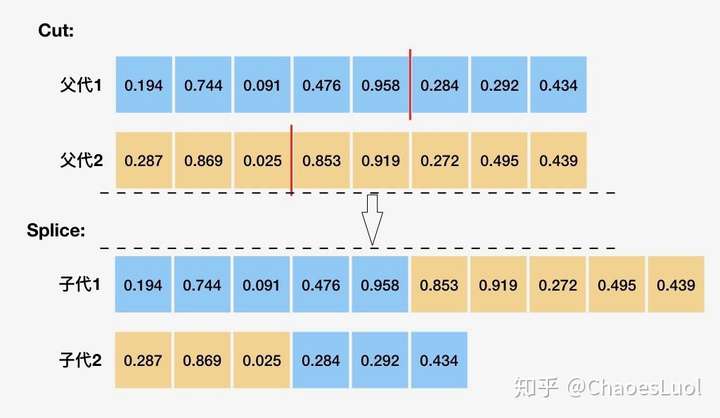
3.交叉操作代码示例
Talk is cheap,还是代码走起。官方提示最好不要直接用父代进行交叉,因为有些交叉算法是in-place运算的,因此最好先复制,再进行交叉。具体见代码:
from deap import base, creator, tools
import random
# 创建两个序列编码个体
random.seed(42) # 保证结果可复现
IND_SIZE = 8
creator.create('FitnessMin', base.Fitness, weights=(-1.0, ))
creator.create('Individual', list, fitness = creator.FitnessMin)
toolbox = base.Toolbox()
toolbox.register('Indices', random.sample, range(IND_SIZE), IND_SIZE)
toolbox.register('Individual', tools.initIterate, creator.Individual, toolbox.Indices)
ind1, ind2 = [toolbox.Individual() for _ in range(2)]
print(ind1, '\n', ind2)
# 结果:[1, 0, 5, 2, 7, 6, 4, 3]
# [1, 4, 3, 0, 6, 5, 2, 7]
# 单点交叉
child1, child2 = [toolbox.clone(ind) for ind in (ind1, ind2)]
tools.cxOnePoint(child1, child2)
print(child1, '\n', child2)
#结果:[1, 4, 3, 0, 6, 5, 2, 7]
# [1, 0, 5, 2, 7, 6, 4, 3]
# 可以看到从第四位开始被切开并交换了
# 两点交叉
child1, child2 = [toolbox.clone(ind) for ind in (ind1, ind2)]
tools.cxTwoPoint(child1, child2)
print(child1, '\n', child2)
# 结果:[1, 0, 5, 2, 6, 5, 2, 3]
# [1, 4, 3, 0, 7, 6, 4, 7]
# 基因段[6, 5, 2]与[7, 6, 4]互换了
# 均匀交叉
child1, child2 = [toolbox.clone(ind) for ind in (ind1, ind2)]
tools.cxUniform(child1, child2, 0.5)
print(child1, '\n', child2)
# 结果:[1, 0, 3, 2, 7, 5, 4, 3]
# [1, 4, 5, 0, 6, 6, 2, 7]
# 部分匹配交叉
child1, child2 = [toolbox.clone(ind) for ind in (ind1, ind2)]
tools.cxPartialyMatched(child1, child2)
print(child1, '\n', child2)
# 结果:[1, 0, 5, 2, 6, 7, 4, 3]
# [1, 4, 3, 0, 7, 5, 2, 6]
# 可以看到与之前交叉算子的明显不同,这里的每个序列都没有冲突
# 有序交叉
child1, child2 = [toolbox.clone(ind) for ind in (ind1, ind2)]
tools.cxOrdered(child1, child2)
print(child1, '\n', child2)
# 结果:[5, 4, 3, 2, 7, 6, 1, 0]
# [3, 0, 5, 6, 2, 7, 1, 4]
# 混乱单点交叉
child1, child2 = [toolbox.clone(ind) for ind in (ind1, ind2)]
tools.cxMessyOnePoint(child1, child2)
print(child1, '\n', child2)
# 结果:[1, 0, 5, 2, 7, 4, 3, 0, 6, 5, 2, 7]
# [1, 6, 4, 3]
# 注意个体序列长度的改变4.DEAP内置的突变(Mutation)操作
函数简介适用编码方式
5.常用突变操作介绍
高斯突变:tools.mutGaussian(individual, mu, sigma, indpb)
对个体序列中的每一个基因按概率变异,变异后的值为按均值为 ,方差为
的高斯分布选取的一个随机数。如果不希望均值发生变化,则应该将
设为0。
乱序突变:tools.mutShuffleIndexes(individual, indpb)
将个体序列打乱顺序,每个基因位置变动的几率由indpb给出。
位翻转突变:tools.mutFlipBit(individual, indpb)
对个体中的每一个基因按给定对变异概率取非。
有界多项式突变:tools.mutPolynomialBounded(individual, eta, low, up, indpb)
多项式突变一般配合cxSimulatedBinaryBounded()使用。其具体算法如下:
若 ,突变后的个体
由下式计算可得:
其中参数 服从多项式分布:
在具体计算时,首先在 中以均匀分布取一个随机数
再按下式计算
:
Deb教授建议的参数 取
之间的数字,当参数取的越小,那么突变后的结果离突变前越近,影响大约为
级。
均匀整数突变:tools.mutUniformInt(individual, low, up, indpb)
对序列中的每一位按概率变异,变异后的值为 中按均匀分布随机选取的一个整数。
6.突变操作代码示例
上代码,和交叉选择相同,如果想要保留父代作为参照,那么最好先复制,然后再进行变异:
from deap import base, creator, tools
import random
# 创建一个实数编码个体
random.seed(42) # 保证结果可复现
IND_SIZE = 5
creator.create('FitnessMin', base.Fitness, weights=(-1.0, ))
creator.create('Individual', list, fitness = creator.FitnessMin)
toolbox = base.Toolbox()
toolbox.register('Attr_float', random.random)
toolbox.register('Individual', tools.initRepeat, creator.Individual, toolbox.Attr_float, IND_SIZE)
ind1 = toolbox.Individual()
print(ind1)
# 结果:[0.6394267984578837, 0.025010755222666936, 0.27502931836911926, 0.22321073814882275, 0.7364712141640124]
# 高斯突变
mutant = toolbox.clone(ind1)
tools.mutGaussian(mutant, 3, 0.1, 1)
print(mutant)
# 结果:[3.672658632864655, 2.99827700737295, 3.2982590920597916, 3.339566606808737, 3.6626390539295306]
# 可以看到当均值给到3之后,变异形成的个体均值从0.5也增大到了3附近
# 乱序突变
mutant = toolbox.clone(ind1)
tools.mutShuffleIndexes(mutant, 0.5)
print(mutant)
# 结果:[0.22321073814882275, 0.7364712141640124, 0.025010755222666936, 0.6394267984578837, 0.27502931836911926]
# 有界多项式突变
mutant = toolbox.clone(ind1)
tools.mutPolynomialBounded(mutant, 20, 0, 1, 0.5)
print(mutant)
# 结果:[0.674443861742489, 0.020055418656044655, 0.2573977358171454, 0.11555018832942898, 0.6725269223692601]
# 均匀整数突变
mutant = toolbox.clone(ind1)
tools.mutUniformInt(mutant, 1, 5, 0.5)
print(mutant)
# 结果:[0.6394267984578837, 3, 0.27502931836911926, 0.22321073814882275, 0.7364712141640124]
# 可以看到在第二个位置生成了整数3进化算法各元素的DEAP实现(五):环境选择
环境选择也就是重插入(Reinsertion),在选择、交叉和突变之后,得到的育种后代族群规模与父代相比可能增加或减少。为保持族群规模,需要将育种后代插入到父代中,替换父代种群的一部分个体,或者丢弃一部分育种个体。
重插入分为全局重插入(Global reinsertion)和本地重插入(Local reinsertion)两种,后者只有在使用含有本地邻域的算法时使用。常见的全局重插入操作有以下四种:
- 完全重插入(Pure reinsertion):产生与父代个体数量相当的配种个体,直接用配种个体生成新一代族群。
- 均匀重插入(Uniform reinsertion):产生比父代个体少的配种个体,用配种个体随机均匀地替换父代个体。
- 精英重插入(Elitist reinsertion):产生比父代个体少的配种个体,选取配种后代中适应度最好的一些个体,插入父代中,取代适应度较低的父代个体。
- 精英保留重插入(Fitness-based reinsertion):产生比父代个体多的配种个体,选取其中适应度最大的配种个体形成新一代族群。
通常来说后两种方式由于精英保留的缘故,收敛速度较快,因此比较推荐。
DEAP中没有设定专门的reinsertion操作,可以用选择操作选择中的selBest, selWorst,selRandom来对育种族群和父代族群进行操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号