


openstack系列文章(一)
学习openstack的系列文章-虚拟化
- 虚拟化
- KVM CPU 虚拟化
- KVM 内存虚拟化
- 全虚拟化 I/O 设备
- 半虚拟化 I/O 设备
- I/O PCI PCIe 设备直接分配
- SR-IOV
在 kVM-QEMU 中,虚拟机使用的设备大致可以分为三类:
- 模拟设备:完全由 QEMU 纯软件模拟的设备;
- Virtio 设备:实现 VIRTIO API 的半虚拟化设备;
- PCI 设备直接分配 (PCI device assignment);
1. 虚拟化
虚拟化: 虚拟化是 openstack 的基础,通过虚拟化使得物理机(Host)上可以跑多台虚拟机(Guest),虚拟机共享物理机的CPU、内存、IO硬件资源,各虚拟机在逻辑上是相互隔离的。
那么 Host 是如何将资源分给 Guest 的呢?
主要是通过名为 Hypervisor 的程序来实现的。
根据 Hypervisor 所处的位置和实现方式可将虚拟化分为:1型虚拟化和2型虚拟化。
1型虚拟化即 Hypervisor 直接安装在物理机上,Hypervisor 的实现方式是一个特殊定制的 Liunx 系统。
2型虚拟化即物理机上首先安装常规的操作系统(Liunx、RedHat),Hypervisor 作为 OS 上的一个程序模块运行,从而实现虚拟机的管理。 KVM、VirtualBox 和 VMWare Workstation 都属于这个类型的 Hypervisor。
学习虚拟化操作系统是绕不过去的,操作系统是直接运行在硬件设备上的,它们完全占有计算机的硬件资源。
x86 架构提供四个级别给操作系统和应用程序来访问硬件,Ring 指 CPU 的运行级别,Ring0 最高,Ring1 较低,依次递减。
操作系统内核运行在 Ring0 这个级别,它可以使用特权指令直接访问硬件和内存。
应用程序的代码运行在最低级别 Ring3 上,如果代码要访问硬件,如进行读取磁盘中的文件操作,那么将执行系统调用,调用到对应的内核代码位置,从而通过内核完成磁盘设备的访问,CPU 的运行级别发生 Ring3 到 Ring0 级别的切换,完成操作之后再从 Ring0 切换到 Ring3。这个过程也称作用户态到内核态的切换。
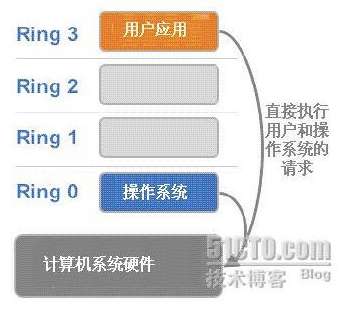
那么,Host OS 工作在 Ring0 上,Guest Os 不能工作 在 Ring0,而是工作在用户层,但是它并不知道自己工作在哪里,以前执行什么命令,现在还是执行什么命令,所以一旦它执行特权指令,Host OS 系统就会报错。这时候就需要虚拟机管理程序 VMM 来避免这种系统报错。虚拟机怎么通过 VMM 实现 Guest CPU 对硬件的访问,根据原理不同可分为三种实现技术:
- 全虚拟化
- 半虚拟化
- 硬件辅助的虚拟化
1.1 全虚拟化
客户操作系统运行在 Ring 1,它在执行特权指令时,会触发异常(CPU的机制,没权限的指令会触发异常),然后 VMM 捕获这个异常,在异常里面做翻译,模拟,最后返回到客户操作系统内,客户操作系统认为自己的特权指令工作正常,继续运行。但是这个性能损耗非常的大,简单的一条指令,执行完,了事,现在却要通过复杂的异常处理过程。
1.2 半虚拟化
半虚拟化即修改 Guest OS 内核,将含有敏感指令的操作替换为对 Hypervisor 的超级调用(hypercall),直接和底层的虚拟化层 Hypervisor 通讯,Hypervisor 同时也提供 hypercall 接口来满足其他关键内核操作,比如内存管理、中断和时间保持。
这种做法省去了全虚拟化中的捕获和模拟,大大提高了效率。但是它的缺点也是很明显的,即需要修改 Guest OS 内核。
1.3 硬件辅助的虚拟化
2005年,CPU厂商Intel 和 AMD 开始支持虚拟化。 Intel 引入了 Intel-VT (Virtualization Technology)技术。
该技术通过引入新的处理器运行模式和新的指令,使得 VMM 和 Guest OS 运行于不同的模式下,Guest OS 运行于受控模式,原来的一些敏感指令在受控模式下全部会陷入 VMM,这样就解决了部分非特权的敏感指令的陷入 — 模拟难题,而且模式切换时上下文的保存恢复由硬件来完成,这样就大大提高了陷入 — 模拟时上下文切换的效率
2. KVM CPU 虚拟化
KVM 是基于 CPU 辅助的全虚拟化,它需要 CPU 虚拟化技术的支持。
命令 egrep "(vmx|svm)" /proc/cpuinfo 可查看 Intel CPU 的 vmx 或者 AMD CPU 的 svm 扩展是否生效,如果生效即可支持虚拟化。
如上节硬件辅助的虚拟化所述,以 Intel VT 技术为例,它增加了两种运行模式:VMX root 模式和 VMX nonroot 模式。通常来讲,主机操作系统和 VMM 运行在 VMX root 模式中,客户机操作系统及其应用运行在 VMX nonroot 模式中。
两种模式都支持所有的 ring,因此,客户机可以运行在它所需要的 ring 中(OS 运行在 ring 0 中,应用运行在 ring 3 中),VMM 也运行在其需要的 ring 中 (对 KVM 来说,QEMU 运行在 ring 3,KVM 运行在 ring 0)。
CPU 在两种模式之间的切换称为 VMX 切换。从 root mode 进入 nonroot mode,称为 VM entry;从 nonroot mode 进入 root mode,称为 VM exit。可见,CPU 受控制地在两种模式之间切换,轮流执行 VMM 代码和 Guest OS 代码。
对 KVM 虚机来说,运行在 VMX Root Mode 下的 VMM 在需要执行 Guest OS 指令时执行 VMLAUNCH 指令将 CPU 转换到 VMX non-root mode,开始执行客户机代码,即 VM entry 过程;在 Guest OS 需要退出该 mode 时,CPU 自动切换到 VMX Root mode,即 VM exit 过程。可见,KVM 客户机代码是受 VMM 控制直接运行在物理 CPU 上的。QEMU 只是通过 KVM 控制虚机的代码被 CPU 执行,但是它们本身并不执行其代码。也就是说,CPU 并没有真正的被虚级化成虚拟的 CPU 给客户机使用。
vCPU、QEMU 进程、LInux 进程调度和物理 CPU 之间的逻辑关系如下图所示:
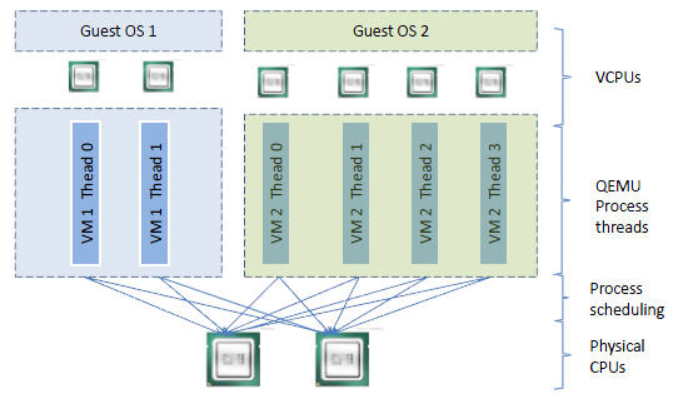
- qemu-kvm 通过对 /dev/kvm 的 一系列 ICOTL 命令控制虚机,比如 :
open("/dev/kvm", O_RDWR|O_LARGEFILE) = 3 ioctl(3, KVM_GET_API_VERSION, 0) = 12 ioctl(3, KVM_CHECK_EXTENSION, 0x19) = 0 ioctl(3, KVM_CREATE_VM, 0) = 4 ioctl(3, KVM_CHECK_EXTENSION, 0x4) = 1 ioctl(3, KVM_CHECK_EXTENSION, 0x4) = 1 ioctl(4, KVM_SET_TSS_ADDR, 0xfffbd000) = 0 ioctl(3, KVM_CHECK_EXTENSION, 0x25) = 0 ioctl(3, KVM_CHECK_EXTENSION, 0xb) = 1 ioctl(4, KVM_CREATE_PIT, 0xb) = 0 ioctl(3, KVM_CHECK_EXTENSION, 0xf) = 2 ioctl(3, KVM_CHECK_EXTENSION, 0x3) = 1 ioctl(3, KVM_CHECK_EXTENSION, 0) = 1 ioctl(4, KVM_CREATE_IRQCHIP, 0) = 0 ioctl(3, KVM_CHECK_EXTENSION, 0x1a) = 0
- 一个 KVM 虚拟机即一个 Linux qemu-kvm 进程,与其他 Linux 进程一样被 Linux 进程调度器调度;
可通过 ps -elf | grep kvm1 命令查看该进程:

- KVM 虚拟机包括虚拟内存、虚拟 CPU 和虚机 I/O 设备。其中,内存和 CPU 的虚拟化由 KVM 内核模块 kvm.ko 负责实现,I/O 设备的虚拟化由 QEMU 和 Liunx内核负责实现;
- KVM Guest OS 的内存是 qumu-kvm 进程的地址空间的一部分;
- KVM 虚拟机的 vCPU 作为 线程运行在 qemu-kvm 进程的上下文中;
3. KVM 内存虚拟化
KVM 通过内存虚拟化共享物理系统内存,动态分配给虚拟机,看下图 :
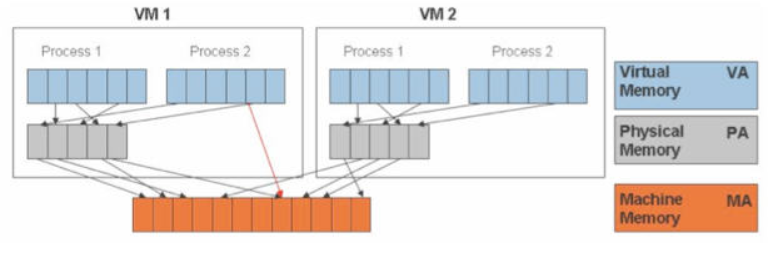
为了在一台机器上运行多个虚拟机,KVM 需要实现 VA(虚拟内存) -> PA(物理内存) -> MA(机器内存)直接的地址转换。虚机 OS 控制虚拟地址到客户内存物理地址的映射 (VA -> PA),但是虚机 OS 不能直接访问实际机器内存,因此 KVM 需要负责映射客户物理内存到实际机器内存 (PA -> MA)。
4. 全虚拟化 I/O 设备
KVM 在 I/O 虚拟化方面,传统或者默认的方式是使用 QEMU 纯软件的方式来模拟 I/O 设备,包括键盘、鼠标、显示器,硬盘和网卡 等。

I/O 全虚拟化过程:
- 客户机的设备驱动程序发起 I/O 请求;
- KVM 模块中的 I/O 操作捕获代码拦截这次 I/O 请求;
- KVM 经过处理后将本次 I/O 请求的信息放到 I/O 共享页 (sharing page),并通知用户空间的 QEMU 程序;
- QEMU 程序获得 I/O 操作的具体信息之后,交由硬件模拟代码来模拟出本次 I/O 操作;
- 完成之后,QEMU 将结果放回 I/O 共享页,并通知 KVM 模块中的 I/O 操作捕获代码;
- KVM 模块的捕获代码读取 I/O 共享页中的操作结果,并把结果放回客户机;
这种方式的优点是可以模拟出各种各样的硬件设备,缺点是每次 I/O 操作的路径比较长,需要多次上下文切换,也需要多次数据复制,所以性能较差。
4.1 QEMU 模拟网卡的实现
Guest 的网络功能是有限的,全虚拟化情况下,KVM 虚拟机可以选择的网络模式有默认用户模式、网桥模式和 NAT 模式。
网桥模式下的 VM 的收发包流程如下图所示:
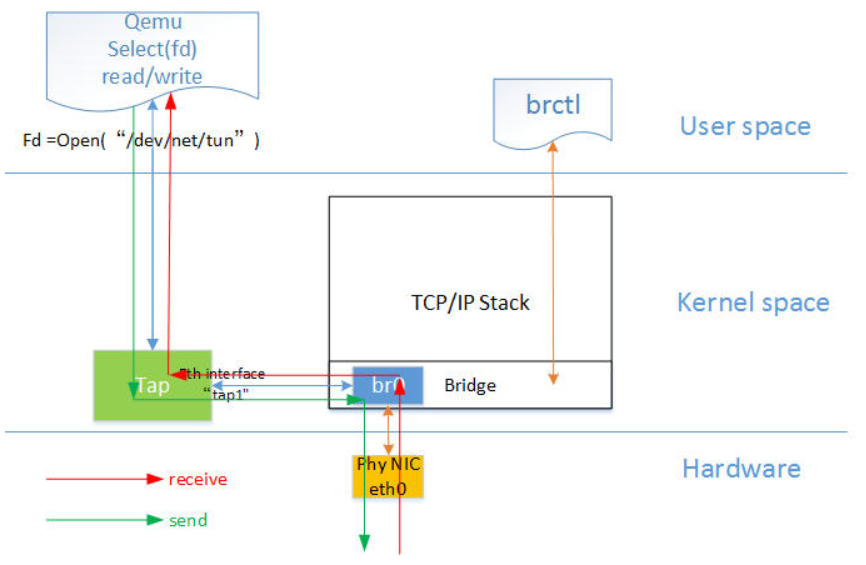
图中红色箭头表示数据报文的入方向,步骤:
- 网络数据从 Host 上的物理网卡接收,到达网桥;
- 由于 eth0 与 tap1 均加入网桥中,根据二层转发原则,br0 将数据从 tap1 口转发出去,即数据由 Tap 设备接收;
- Tap 设备通知对应的 fd 数据可读;
- fd 的读动作通过 tap 设备的字符设备驱动将数据拷贝到用户空间,完成数据报文的前端接收。
图中的 brctl 是用来管理以太网桥,在内核中建立、维护、检查网桥配置的工具。
一个网桥一般用来连接多个不同的网络,这样这些不同的网络就可以像一个网络那样进行通讯。
登录虚机,通过 lspci 命令查看 pci 设备,可以看到模拟设备:
通过 lspci | grep Eth 可以查看网卡信息:

从图中可以看到一块网卡对应两个网口。
5. 半虚拟化 I/O 设备
在 KVM 中可以使用半虚拟化驱动来提供客户机的 I/O 性能。目前 KVM 采用的是 virtio 这个 Linux 上的设备驱动标准框架,它提供了一种 Host 与 Guest 交互的 IO 框架。
KVM-QEMU 的 vitio 实现采用在 Guest OS 内核中安装前端驱动 (Front-end driver)和在 QEMU 中实现后端驱动(Back-end)的方式。前后端驱动通过 vring 直接通信,这就绕过了经过 KVM 内核模块的过程,达到提高 I/O 性能的目的。

纯软件模拟的设备和 Virtio 设备的区别:virtio 省去了纯模拟模式下的异常捕获环节,Guest OS 可以和 QEMU 的 I/O 模块直接通信。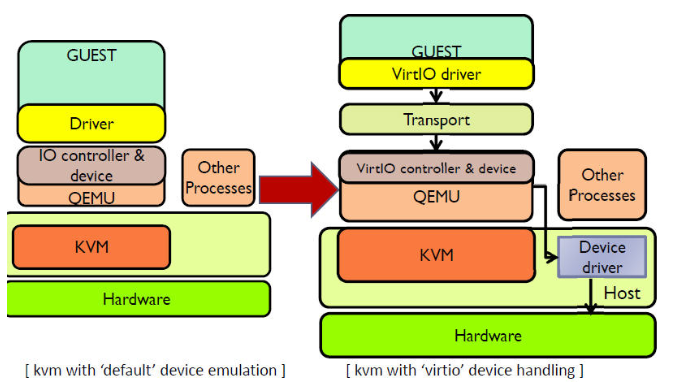
使用 Virtio 的完整虚机 I/O流程:

Host 数据发到 Guest:
- KVM 通过中断的方式通知 QEMU 去获取数据,放到 virtio queue 中;
- KVM 再通知 Guest 去 virtio queue 中取数据;
6. I/O PCI PCIe 设备直接分配
这种方式允许将 Host 中的物理 PCI 设备直接分配给客户机使用。
较新的x86平台已经支持这种类型,Intel 定义的 I/O 虚拟化技术成为 VT-d,AMD 的称为 AMD-V。
KVM 支持客户机以独占方式访问这个宿主机的 PCI/PCI-E 设备。通过硬件支持的 VT-d 技术将设备分给客户机后,在客户机看来,设备是物理上连接在 PCI 或者 PCI-E 总线上的,客户机对该设备的 I/O 交互操作和实际的物理设备操作完全一样,不需要或者很少需要 KVM 的参与。运行在 VT-d 平台上的 KVM-QEMU,可以分配网卡、磁盘控制器、USB 控制器、VGA 显卡等设备供客户机直接使用。
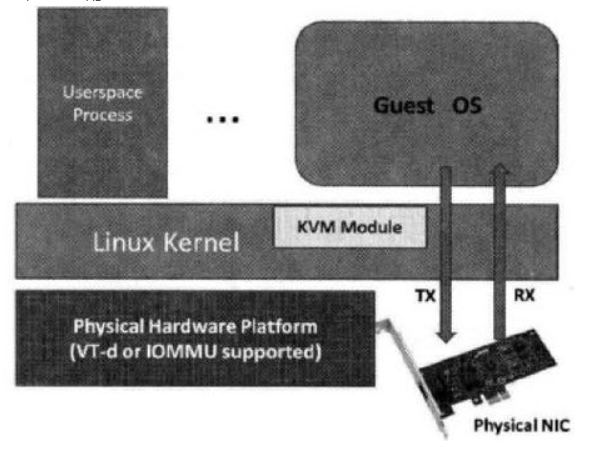
TX: Transmit,传送数据,上行流量;
RX: Receive, 接收数据,下行流量;
7. SR-IOV
VT-d 的性能非常好,但是它的物理设备只能分配给一个客户机使用。为了实现多个虚机共享一个物理设备,并且达到直接分配的目的,PCI-SIG 组织发布了 SR-IOV (Single Root I/O Virtualization and sharing) 规范,它定义了一个标准化的机制用以原生地支持实现多个客户机共享一个设备。不过,目前 SR-IOV (单根 I/O 虚拟化)最广泛地应用还是网卡上。
SR-IOV 使得一个单一的功能单元(比如,一个以太网端口)能看起来像多个独立的物理设备。一个带有 SR-IOV 功能的物理设备能被配置为多个功能单元。SR-IOV 使用两种功能(function):
物理功能(Physical Functions,PF):这是完整的带有 SR-IOV 能力的 PCIe 设备。PF 能像普通 PCI 设备那样被发现、管理和配置。
虚拟功能(Virtual Functions,VF):简单的 PCIe 功能,它只能处理 I/O 。每个 VF 都是从 PF 中分离出来的。每个物理硬件都有一个 VF 数目的限制。一个 PF,能被虚拟成多个 VF 用于分配给多个虚拟机。
Hypervisor 能将一个或者多个 VF 分配给一个虚机。在某一时刻,一个 VF 只能被分配给一个虚机。一个虚机可以拥有多个 VF。在虚机的操作系统看来,一个 VF 网卡看起来和一个普通网卡没有区别。SR-IOV 驱动是在内核中实现的。

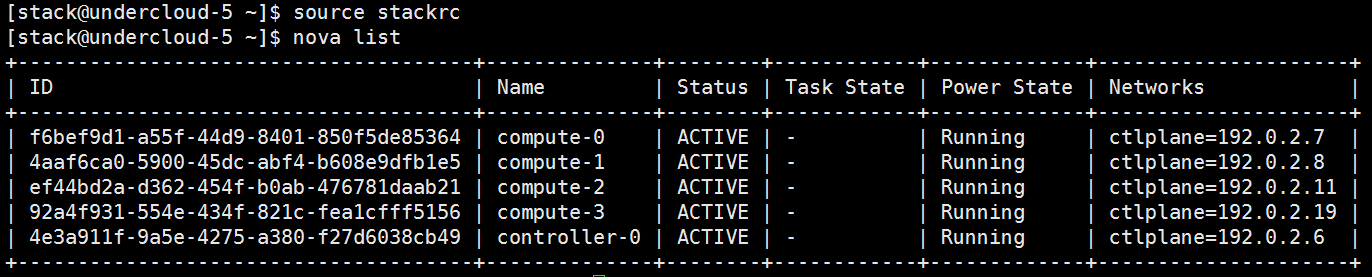
以一个instance为例,查看该 instance 是否有配置 SR-IOV:
- undercloud 下 source overcloudrc;
- $ nova list
- $ nova show [instance name] -> 查看该 instance 所在的计算节点和 Libvirt 管理的虚拟机名称;
- undercloud 下 source stackrc -> nova list -> ssh heat-admin@<instance computer node ip>
- virsh list -> 查找该虚拟机名称
- virsh dumpxml <instance name>
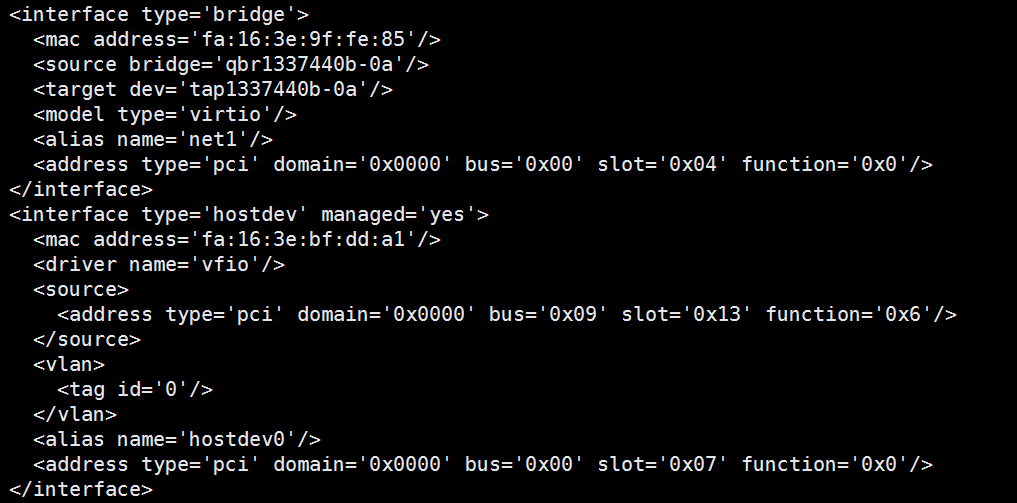
第一个 interface 是 virtio 模式, 第二个 interface 是 SR-IOV,对应的 VF 为 9136。
- lspci | grep Eth

查看 09:13.6 即为 网卡虚拟出的 VF,该 VF 与 前面的 instance 相连,进行通信。
7.1 几种架构比较

参考文章:
http://www.cnblogs.com/sammyliu/p/4548194.html
https://www.cnblogs.com/CloudMan6/p/5880394.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号