

go ants pool 协程池学习笔记
概述
使用 Go 开发并发程序很容易,一个 go 关键字就可以启动协程处理任务。Go 创建一个 goroutine 只需要 2K 内存空间,并且 go 协程上下文信息仅存储在两个寄存器中,对于 Go 运行时来说,切换上下文特别快。
不过凡事不加限制就会出问题,如果不加节制的滥用 goroutine 就可能导致内存泄露,增加 Go 运行时调度负担等。
下面看一段 Go http 标准库的代码:
func (s *Server) Serve(l net.Listener) error {
for {
...
c := s.newConn(rw)
go c.serve(connCtx)
}
}
当来一个 http 请求,http 会启动一个协程 Server.serve() 处理该请求。
这种方式对于请求的响应很快,但是如果有恶意大规模并发请求,就可能导致后端服务内存爆增,响应慢等问题。
测试千万并发的内存使用情况如下:
const n = 10000000
func demoFunc() {
time.Sleep(time.Duration(BenchParam) * time.Millisecond)
}
func TestNoPool(t *testing.T) {
var start, end runtime.MemStats
runtime.ReadMemStats(&start)
var wg sync.WaitGroup
for i := 0; i < n; i++ {
wg.Add(1)
go func() {
demoFunc()
wg.Done()
}()
}
wg.Wait()
runtime.ReadMemStats(&end)
usageMem := end.TotalAlloc/MiB - start.TotalAlloc/MiB
t.Logf("memory usage:%d MB", usageMem)
}
测试结果:
go test -v -bench=. -benchmem -run=TestNoPool
=== RUN TestNoPool
ants_test.go:41: memory usage:1304 M
--- PASS: TestNoPool (5.70s)
当并发量到千万时,内存使用率达到了 1 个多 G,看起来好像不多。不过可别忘了,这里处理的任务只是 time.Sleep,如果每个协程处理内存型或 IO 型任务,那该是多大内存或者 CPU 的消耗,并且调度如此多的协程也会让 Go 运行时(调度器,GC)的压力非常大。
因此,需要协程池来限制协程的使用,起到稳定内存使用率,减轻 Go 运行时负担的目的。
协程池
既然协程池的主要任务是限制协程的数量,那么作为池应该有几个需求是要实现的:
- 协程池生命周期管理,包括创建,释放等操作;
- 协程池的扩缩容,按需使用;
- 协程池中过期协程的清理;
ants 是一个满足上述需求的高性能协程池。本文重点学习 ants 的源码了解协程池。
ants 协程池
结构
首先看代码的层次结构,作为一个协程池库,ants 很扁平,只有一层:
tree
.
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── LICENSE
├── README.md
├── README_ZH.md
├── ants.go
├── ants_benchmark_test.go
├── ants_test.go
├── example_test.go
├── go.mod
├── go.sum
├── multipool.go
├── multipool_func.go
├── multipool_func_generic.go
├── options.go
├── pkg
│ └── sync
│ ├── spinlock.go
│ ├── spinlock_test.go
│ └── sync.go
├── pool.go
├── pool_func.go
├── pool_func_generic.go
├── worker.go
├── worker_func.go
├── worker_func_generic.go
├── worker_loop_queue.go
├── worker_loop_queue_test.go
├── worker_queue.go
├── worker_stack.go
└── worker_stack_test.go
从结构可以看出,主要分为三类:
- pool:实现了协程池,是暴露给用户调用的对象;
- workqueue:工作队列,负责装载工作协程,其接口实现是
worker_stack和worker_loop_queue对象; - worker:工作协程,是实际执行任务的协程;
这个结构还是很清晰的,就不画 UML 图表示了。
流程
设计
在看流程图之前,先自己想一下,如果让我设计协程池该如何做呢?
平时开发用的比较多的是类似这样的写法:
for i := 0; i < workerNumber; i++ {
go worker()
}
func worker() {
for task := range taskC {
doTask()
}
}
程序运行时启动 workerNumber 个协程监听同一个通道 taskC,如果 taskC 有 task,多个协程 worker 会抢 task 并调用 doTask() 处理任务。
这种写法的好处在于简单,缺点在于协程数固定,不能按需灵活使用,而且在程序启动时,workerNumber 个协程就开始运行,如果没有 task 会造成资源浪费。
这种写法对于数量少的协程还行,如果并发过大则需要上协程池了。
使用协程池,还是让 worker 去监听 taskC,不同的是每个 worker 都有自己的 taskC,这样设计的好处是协程 worker 不会打架。
让每个 worker 监听自己的通道,那谁来管理这些 worker 呢?我们可以将这些 worker 存入容器(堆或栈)中。让容器对象来管理 worker,包括插入 worker 到容器,弹出 worker 出容器等。
现在 worker 在容器中了,那什么时候该插入 worker 到容器,什么时候该弹出 worker 呢?
我们想每个 worker 都监听自己的通道,如果 worker 执行完任务就可以插入 worker 到容器,插入 worker 到容器的意思是,该 worker 可用,可以被拿出来执行任务。
这是插入逻辑,对于弹出,如果生产者需要往 worker 的通道中写任务,发现容器中有一个 worker 可用,就可以从容器中弹出 worker 给生产者使用。弹出的意思是,该 worker 我用了,别人不能在用了。
那么,谁是生产者呢?
生产者是客户端调用 pool 方法将任务写入 pool 对象,pool 对象从容器中获取可用的 worker,并往该 worker 的通道写入任务。
至此,主要的逻辑都走通了。
还有一点是容器该用栈还是用队列呢?
worker 写入容器后,如果长时间不用的话需要清理,清理需要按照时间排序。队列是符合这种需求的数据结构(按时间顺序,先进先出)。
流程图
ants 的流程图如下:
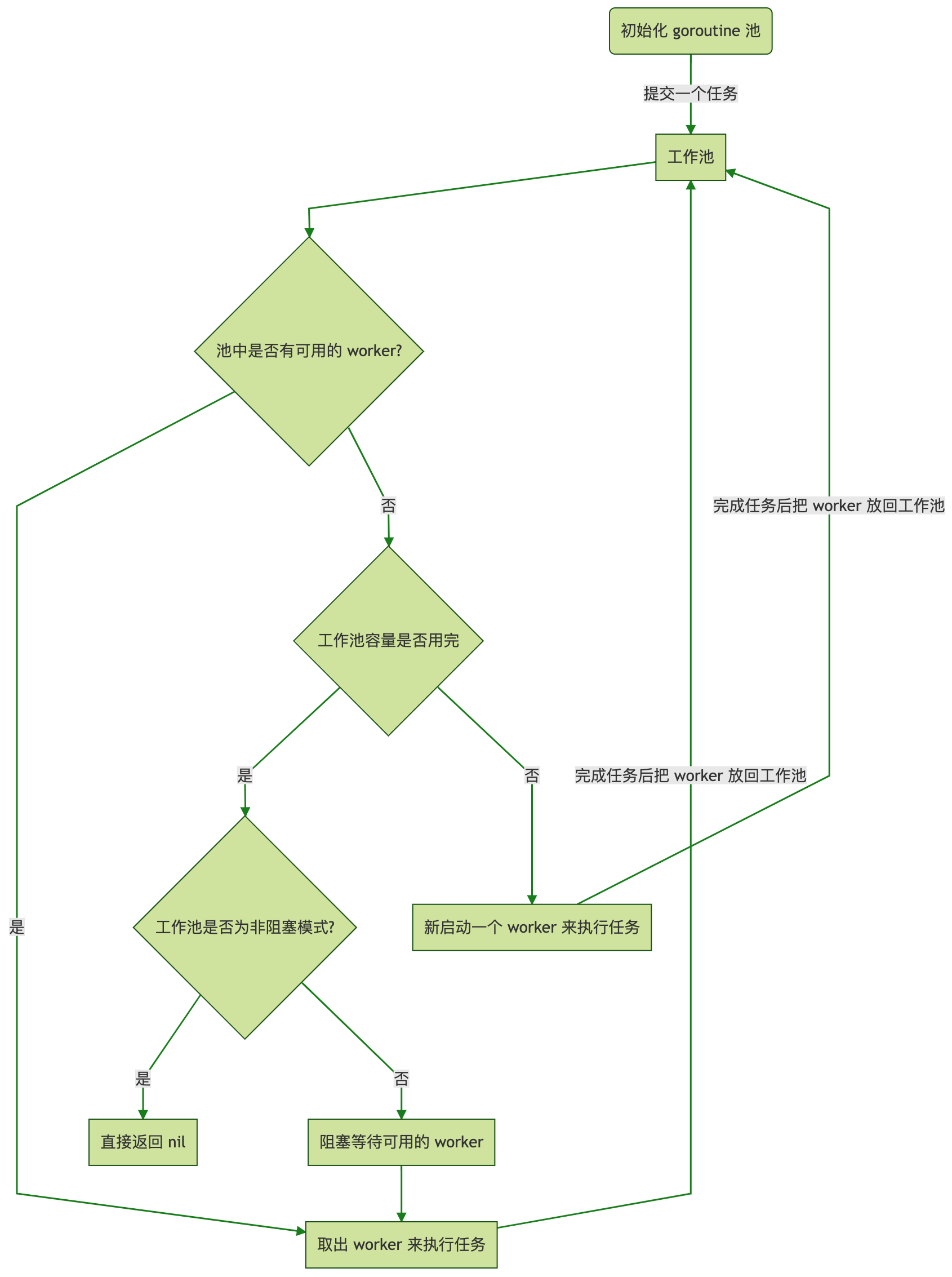
图片来源于 Github ants
结合图片看源码应该会很清晰,这里不在赘述了。
ants 源码实现
光了解流程还不够,ants 能在众多协程池中脱颖而出,肯定有它的过人之处。下面从细节出发看源码中有哪些过人之处,毕竟细节是魔鬼。
sync.Pool 对象复用
作为协程池,需要频繁创建 worker 对象。ants 使用 sync.Pool 作为对象缓存,复用 worker 对象,降低频繁创建销毁对象导致的内存开销。
type poolCommon struct {
workerCache sync.Pool
}
func NewPool(size int, options ...Option) (*Pool, error) {
...
// sync.Pool 创建对象
pool.workerCache.New = func() any {
return &goWorker{
pool: pool,
task: make(chan func(), workerChanCap),
}
}
return pool, nil
}
func (p *poolCommon) retrieveWorker() (w worker, err error) {
...
if capacity := p.Cap(); capacity == -1 || capacity > p.Running() {
p.lock.Unlock()
// 从 sync.Pool 中取 worker 对象
w = p.workerCache.Get().(worker)
w.run()
return
}
sync.spinLock
ants 实现了指数退避锁,如下:
type spinLock uint32
const maxBackoff = 16
func (sl *spinLock) Lock() {
backoff := 1
for !atomic.CompareAndSwapUint32((*uint32)(sl), 0, 1) {
// Leverage the exponential backoff algorithm, see https://en.wikipedia.org/wiki/Exponential_backoff.
for i := 0; i < backoff; i++ {
runtime.Gosched()
}
if backoff < maxBackoff {
backoff <<= 1
}
}
}
作为高并发协程池,多个协程抢锁是常态。如果协程长期占有锁,其它协程一直在抢锁会造成资源浪费。ants 使用指数退避算法抢锁减少长时间占有锁的资源抢占。
并且,当抢不到锁时 ants 使用 runtime.Gosched 出让 CPU,而不是空转等待锁(空转协程会一直占用 CPU)。主动出让,而不是被动等待运行时请出 CPU 更加合理且快速,也让其它协程更快的执行抢占逻辑,雨露均沾。
执行基准测试看几种类型锁的执行性能:
func BenchmarkMutex(b *testing.B) {
m := sync.Mutex{}
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
m.Lock()
//nolint:staticcheck
m.Unlock()
}
})
}
type spinLock uint32
func (s *spinLock) Lock() {
for !atomic.CompareAndSwapUint32((*uint32)(s), 0, 1) {
}
}
func (s *spinLock) Unlock() {
atomic.StoreUint32((*uint32)(s), 0)
}
func newSpinLock() *spinLock {
return (*spinLock)(new(uint32))
}
func BenchmarkSpinLock(b *testing.B) {
m := newSpinLock()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
m.Lock()
//nolint:staticcheck
m.Unlock()
}
})
}
type backoffSpinLock uint32
var backoff = 16
func (s *backoffSpinLock) Lock() {
i := 1
for !atomic.CompareAndSwapUint32((*uint32)(s), 0, 1) {
if i == backoff {
continue
}
i <<= 1
}
}
func (s *backoffSpinLock) Unlock() {
atomic.StoreUint32((*uint32)(s), 0)
}
func newBackoffSpinLock() *backoffSpinLock {
return (*backoffSpinLock)(new(uint32))
}
func BenchmarkBackoffSpinLock(b *testing.B) {
m := newBackoffSpinLock()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
m.Lock()
//nolint:staticcheck
m.Unlock()
}
})
}
type spinSchedLock uint32
func (s *spinSchedLock) Lock() {
for !atomic.CompareAndSwapUint32((*uint32)(s), 0, 1) {
runtime.Gosched()
}
}
func (s *spinSchedLock) Unlock() {
atomic.StoreUint32((*uint32)(s), 0)
}
func newSpinSchedLock() *spinSchedLock {
return (*spinSchedLock)(new(uint32))
}
func BenchmarkSpinSchedLock(b *testing.B) {
m := newSpinSchedLock()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
m.Lock()
//nolint:staticcheck
m.Unlock()
}
})
}
type backoffSpinSchedLock uint32
var maxBackoff = 16
func (s *backoffSpinSchedLock) Lock() {
backoff := 1
for !atomic.CompareAndSwapUint32((*uint32)(s), 0, 1) {
for i := 0; i < backoff; i++ {
runtime.Gosched()
}
if backoff < maxBackoff {
backoff <<= 1
}
}
}
func (s *backoffSpinSchedLock) Unlock() {
atomic.StoreUint32((*uint32)(s), 0)
}
func newBackoffSpinSchedLock() *backoffSpinSchedLock {
return (*backoffSpinSchedLock)(new(uint32))
}
func BenchmarkBackoffSpinSchedLock(b *testing.B) {
m := newBackoffSpinSchedLock()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
m.Lock()
//nolint:staticcheck
m.Unlock()
}
})
}
测试结果:
go test -v -bench=. -benchmem -run=^$
goos: darwin
goarch: arm64
pkg: github.com/xiahuyun/go-library/ants
cpu: Apple M3
BenchmarkMutex
BenchmarkMutex-8 17903019 69.40 ns/op 0 B/op 0 allocs/op
BenchmarkSpinLock
BenchmarkSpinLock-8 15894223 130.3 ns/op 0 B/op 0 allocs/op
BenchmarkBackoffSpinLock
BenchmarkBackoffSpinLock-8 10448190 124.0 ns/op 0 B/op 0 allocs/op
BenchmarkSpinSchedLock
BenchmarkSpinSchedLock-8 339347601 3.026 ns/op 0 B/op 0 allocs/op
BenchmarkBackoffSpinSchedLock
BenchmarkBackoffSpinSchedLock-8 400970906 2.641 ns/op 0 B/op 0 allocs/op
可以看到在众多锁中 ants 的指数退避锁表现最好。
purge worker
ants 使用一个清理协程定时清理 workerQueue 中的协程(ants 通过二分查找确定哪些协程是过期需要清理的,非常高效):
ticktock
ants 中 worker 在放入队列时需要记录自己放入队列的时间,purgeWorker 会根据该时间确定哪些 worker 需要清理。
如果每个 worker 调用 time.Now() 记录时间,会造成系统资源浪费,time.Now 会执行系统调用,涉及内核态/用户态的切换。
ants 使用 ticktock 协程周期性的调用 time.Now 生成时间戳并存到 pool 对象池中。worker 在记录时间放入队列时,只需要从对象池拿时间戳就行,显著避免系统资源消耗:
func (p *poolCommon) ticktock() {
ticker := time.NewTicker(nowTimeUpdateInterval)
defer func() {
ticker.Stop()
atomic.StoreInt32(&p.ticktockDone, 1)
}()
ticktockCtx := p.ticktockCtx // copy to the local variable to avoid race from Reboot()
for {
select {
case <-ticktockCtx.Done():
return
case <-ticker.C:
}
if p.IsClosed() {
break
}
// 记录当前时间到 pool 对象池
p.now.Store(time.Now())
}
}
总结
ants 是一个被广泛使用的高性能协程池,特别适合学习,了解协程池的实现。本文从整体到细节介绍 ants 的实现,希望对大家有所帮助,感谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号