

一、了解字符编码的知识储备
1、计算机基础知识
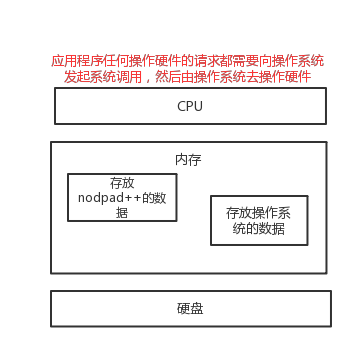
2、文本编辑器存取文件的原理(nodepad++,pycharm,word)
1)打开编辑器就打开了启动了一个进程,是在内存中的,所以,用编辑器编写的内容也都是存放在内存中的,断电后数据丢失
2)要想永久保存,需要点击保存按钮:编辑器把内存的数据刷到了硬盘上。
3)在我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
3、python解释器执行py文件的原理 ,例如python test.py
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中(小复习:pyhon的解释性,决定了解释器只关心文件内容,不关心文件后缀名)
第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码( ps:在该阶段,即真正执行代码时,才会识别python的语法,执行文件内代码,当执行到name="egon"时,会开辟内存空间存放字符串"egon")
4、总结python解释器与文件本编辑的异同
1)相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
2)不同点:文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不去理会python的语法,而python解释器将文件内容读入内存后,可不是为了给你瞅一眼python代码写的啥,而是为了执行python代码、会识别python语法。
二、字符编码
1、ASCII
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
2、Unicode
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:改版前由16位表示一个字符,改变后由32位表示一个字符,非常浪费资源。
3、UTF-8
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存。目前公认最好的编码方式就是UTF-8。
4、GBK
GBK是国标,只识别中文和英文,采用单双字节编码,英文使用单字节编码,完全兼容ASCII,中文部分采用双字节编码。
5、单位转化
8bit =1bytes
1024bytes=1kb
1024kb=1mb
1024mb=1GB
1024GB=1TB
三、Python3下的编码转化
python3环境下:
1、不同编码之间的二进制是不能互相识别的;
2、python3,str内部编码方式(内存)为unicode。
3、对于文件的存贮和传输不能用unicode,bytes类型内部编码方式,为非unicode
str与bytes的表现形式:
1 #str表现形式,内部编码方式:unicode 2 s1='hello'
3 #bytes表现形式,内部编码方式:非unicode(utf-8,gbk....) 4 s2=b'hello'
例:
1 #对于英文 2 s1='hello' 3 print(s1,type(s1))#>>>hello <class 'str'> 4 s2=b'hello' 5 print(s2,type(s2))#>>>b'hello' <class 'bytes'> 6 #对于中文 7 s='你好' 8 print(s,type(s))#>>>你好 <class 'str'> 9 print(s.encode('utf-8'))#>>>b'\xe4\xbd\xa0\xe5\xa5\xbd' 10 s1=b'\xe4\xbd\xa0\xe5\xa5\xbd' 11 print(s1,type(s1))#>>>b'\xe4\xbd\xa0\xe5\xa5\xbd' <class 'bytes'>
编码转化:str 转化成 bytes
1 # str(英文)转化 bytes 2 s='hello' 3 s2=s.encode('utf-8') 4 s3=s.encode('gbk') 5 print(s2,type(s2))#>>>b'hello' <class 'bytes'> 6 print(s3,type(s3))#>>>b'hello' <class 'bytes'> 7 #str(中文)转化 bytes 8 s='你好' 9 s2=s.encode('utf-8')#一个中文三个字节 10 s3=s.encode('gbk')#一个中文两个字节 11 print(s2,type(s2))#>>>b'\xe4\xbd\xa0\xe5\xa5\xbd' <class 'bytes'> 12 print(s3,type(s3))#>>>b'\xc4\xe3\xba\xc3' <class 'bytes'>
解码:bytes 转化成str
1 s='你好' 2 s1=s.encode('utf-8')#一个中文三个字节 3 s2=s.encode('gbk')#一个中文两个字节 4 s3=s1.decode('utf-8') 5 s4=s2.decode('gbk') 6 print(s3,type(s3))#>>>你好 <class 'str'> 7 print(s4,type(s4))#>>>你好 <class 'str'>
编码方式补充:
unicode - --> bytes encode()
bytes - --> unicode decode()
1 #将gbk的bytes类型转化为utf-8的bytes类型 2 s1=b'\xd6\xd0\xb9\xfa' 3 s2=s1.decode('gbk') 4 s3=s2.encode('utf-8') 5 print(s2)#>>>中国 6 print(s3)#>>>b'\xe4\xb8\xad\xe5\x9b\xbd' 7 #简化 8 s1=b'\xd6\xd0\xb9\xfa'.decode('gbk').encode('utf-8') 9 print(s1)#>>>b'\xe4\xb8\xad\xe5\x9b\xbd'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号