python系统模块之re
正则模块re:
元字符:
| 字符 | 描述 |
| . | 除换行符外的任意字符 |
| \ | 转义字符 |
| [...] | 字符集合,匹配任务其中一个 |
| \d | 数字:[0-9] |
| \D | 非数字:[^\d] |
| \w | 单词字符[A-Za-z0-9] |
| \W | 非单词字符[^\w] |
| \s | 空白字符[\t\r\n\f 空格] |
| \S | 非空白字符[^\s] |
数量词:
| * | 匹配一个字符0次或多次 |
| + | 匹配一个字符1次或多次 |
| ? | 匹配一个字符0次或1次 |
| {m} | 匹配一个字符m次 |
| {m,n} | 匹配一个字符m次到n次 |
| ? | 非贪婪模式 |
边界:
| ^ | 匹配字符串开头和行首 |
| $ | 匹配字符串结尾和行尾 |
| \A | 匹配字符串开头 |
| \Z | 匹配字符串结尾 |
| \b | 匹配\w到\W之间 |
分组:
| | | 左右表达式任意匹配一个,先匹配左边,一般成功则跳过匹配右边, 如果没有|则匹配整个表达式 |
| (...) | 分组匹配,从左到右,没遇到一个编号就+1, 后面可以根据数量词提取内容 |
| (?P<name>...) | 除了分组序号外, 还可以执行一个name的别名 |
|
\<number> |
引用编号为<number>的分组匹配到的字符串 |
| (?P=name) | 引用别名为<name>的分组匹配到的串 |
常用函数:
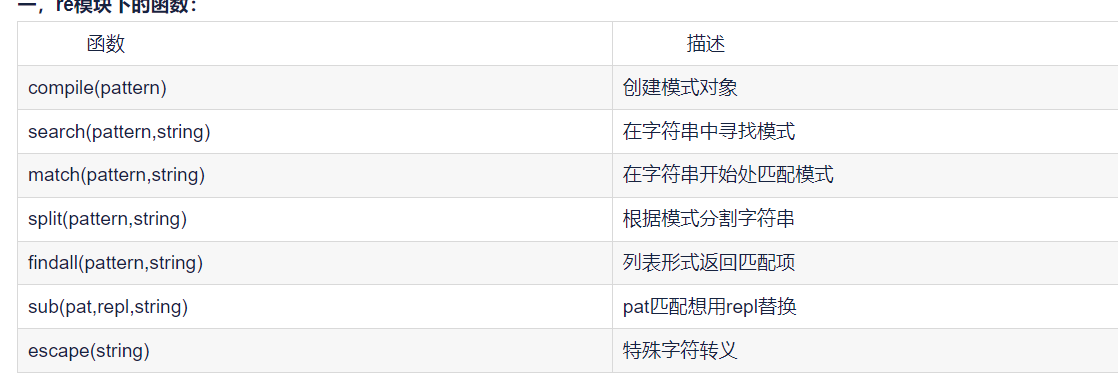
1) compile(pattern)
创建正则匹配规则对象
>>> import re >>> pat=re.compile('A') >>> m=pat.search('CBA') >>> print m <_sre.SRE_Match object at 0x9d690c8> #匹配到了,返回MatchObject(True) >>> m=pat.search('CBD') >>> print m None #没有匹配到,返回None(False) #上面的等价于 >>> re.search('A','CBA') <_sre.SRE_Match object at 0xb72cd170> #推荐都用第一种方法
2)findall(pattern, string)
在字符串中查询所有匹配项,并以列表的形式返回
>>> re.findall('a','ASDaDFGAa') ['a', 'a'] #列表形式返回匹配到的字符串 >>> pat = re.compile('a') >>> pat.findall('ASDaDFGAa') ['a', 'a'] #列表形式返回匹配到的字符串 >>> pat = re.compile('[A-Z]+') #正则匹配:'[A-Z]+' 后面有说明 >>> pat.findall('ASDcDFGAa') ['ASD', 'DFGA'] #找到匹配到的字符串 >>> pat = re.compile('[A-Z]') >>> pat.findall('ASDcDFGAa') #正则匹配:'[A-Z]+' 后面有说明 ['A', 'S', 'D', 'D', 'F', 'G', 'A'] #找到匹配到的字符串 >>> pat = re.compile('[A-Za-z]') #正则匹配:'[A-Za-z]+' 匹配所有单词,后面有说明 >>> pat.findall('ASDcDFGAa') ['A', 'S', 'D', 'c', 'D', 'F', 'G', 'A', 'a']
3)search(pattern,string)
在字符串中查询第一个匹配项,并以对象的形式返回
>>> m = re.search('asd','ASDasd') >>> print m <_sre.SRE_Match object at 0xb72cd6e8> #匹配到了,返回MatchObject(True) >>> m = re.search('asd','ASDASD') >>> print m None #没有匹配到,返回None(False)
4)match(pattern,string)
在字符串开始位置查询匹配项,并以对象的形式返回
>>> m = re.match('a','Aasd') >>> print m None #没有匹配到,返回None(False >>> m = re.match('a','aASD') >>> print m <_sre.SRE_Match object at 0xb72cd6e8> #匹配到了,返回MatchObject(True) 可以用第一个方法:compile >>> pat=re.compile('a') >>> printpat.match('Aasd') None >>> printpat.match('aASD') <_sre.SRE_Match object at 0xb72cd6e8>
5)split(pattern,string)
在字符串中根据模式分隔字符串
>>> re.split(',','a,s,d,asd') ['a', 's', 'd', 'asd'] #返回列表 >>> pat = re.compile(',') >>> pat.split('a,s,d,asd') ['a', 's', 'd', 'asd'] #返回列表 >>> re.split('[, ]+','a , s ,d ,,,,,asd') #正则匹配:[, ]+,后面说明 ['a', 's', 'd', 'asd'] >>> re.split('[, ]+','a , s ,d ,,,,,asd',maxsplit=2) # maxsplit 最多分割次数 ['a', 's', 'd ,,,,,asd'] >>> pat = re.compile('[, ]+') #正则匹配:[, ]+,后面说明 >>> pat.split('a , s ,d ,,,,,asd',maxsplit=2) # maxsplit 最多分割次数 ['a', 's', 'd ,,,,,asd']
6)sub(pattern,repl,string)
在字符串中将匹配项替换成目标,返回字符串
>>> re.sub('a','A','abcasd') #找到a用A替换,后面见和group的配合使用 'AbcAsd' >>> pat = re.compile('a') >>> pat.sub('A','abcasd') 'AbcAsd' #通过组进行更新替换: >>> pat=re.compile(r'www\.(.*)\..{3}') #正则表达式 >>> pat.match('www.dxy.com').group(1) 'dxy' >>> pat.sub(r'\1','hello,www.dxy.com') #通过正则匹配找到符合规则的”www.dxy.com“ ,取得组1字符串 去替换 整个匹配得到字符串。dxy -> www.dxy.com 'hello,dxy' >>> pat=re.compile(r'(\w+) (\w+)') #正则表达式 >>> s='hello world ! hello hz !' >>> pat.findall('hello world ! hello hz !') [('hello', 'world'), ('hello', 'hz')] >>> pat.sub(r'\2 \1',s) #通过正则得到组1(hello),组2(world),再通过sub去替换。即组1替换组2,组2替换组1,调换位置。 'world hello!hz hello!'
7)escape(string)
特殊字符转移
>>> re.escape('www.dxy.cn') 'www\\.dxy\\.cn' #转义
注意:
a) 以上函数中只有match,search返回的是一个对象, 可以使用span,group方法

>>> pat = re.compile(r'www\.(.*)\.(.*)') #用()表示一个组,2个组 >>> m = pat.match('www.dxy.com') >>> m.group() #默认为0,表示匹配整个字符串 'www.dxy.com' >>> m.group(1) #返回给定组1匹配的子字符串 'dxy' >>> m.group(2) 'com' >>> m.start(2) #组2开始的索引 8 >>> m.end(2) #组2结束的索引 11 >>> m.span(2) #组2开始、结束的索引 (8, 11) >>> m1 = pat.search('www.dxy.com') >>> m1.group() 'www.dxy.com' >>> m1.group(1) 'dxy' >>> m1.group(2) 'com' >>> m1.start(2) 8
b)正则表达式内容的时候, 尽量前面添加r'表达式', 可以保证内容中的正则不会被python进行转移处理, 保持原始字符给到re引擎
使用示例:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号