MySQL
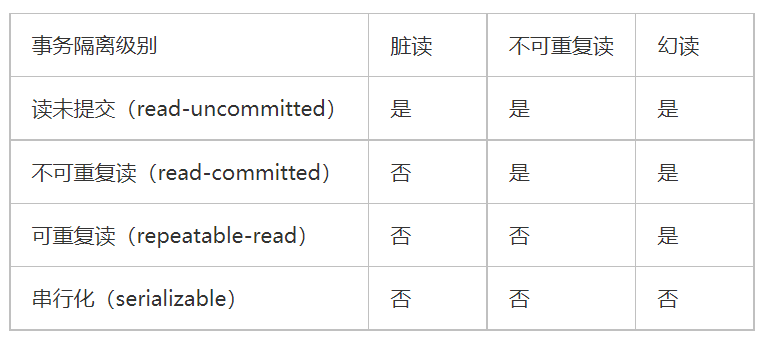
MySQL事务隔离级别
- Read-uncommitted(RU):
- Read-commited(RC):
- Repeatable-read(RR):InnoDB默认隔离级别,并用了Next-KeyLock锁算法,不会出现幻读 通过>select @@tx_isolation命令查看
- Serializable:InnoDB存储引擎在分布式事务时一般用的Serializable
MySQL的默认存储方式 P186
查看存储方式的命令为:>show engines
默认方式为InnoDB,是支持事务性的存储引擎
MyISAM和InnoDB区别 P187
MyISAM
1)5.5之前默认存储方式
2)不支持事务,效率极高,奔溃后将无法安全恢复
3)只支持表级锁
4)不支持外键
InnoDB
1)5.5之后包含存储方式,5.7后为默认存储方式
2)支持事务、回滚、奔溃修复能力的事务安全,效率慢
3)支持行级锁(默认)和表级锁
4)支持外键
5)支持MVCC(多版本并发):只有写写相互阻塞,读写|写读|读读可以并行,可以使用乐观锁和悲观锁来实现
为什么InnBD使用可重复的的隔离级别?
之前老版本主要解决MySQL主从复制问题
可以发现在RR级别下,binlog为任何格式均不会造成主从数据不一致的情况出现,但是当低版本MySQL使用RC+STATEMENT组合时(MySQL5.1.5前只有statement格式)将会导致主从数据不一致。当前这个历史遗漏问题以及解决,大家可以将其设置为RC+ROW组合的方式(例如ORACLE等数据库隔离级别就是RC),而不是必须使用RR(会带来更多的锁等待),具体可以视情况选择。
MySQL归档日志binlog、undolog、redolog
undolog:https://www.cnblogs.com/xin-xing/p/16615395.html
具体命令/讲解:https://baijiahao.baidu.com/s?id=1727529344670607619&wfr=spider&for=pc
1)Statement追加模式(Statement-Based Replication,SBR):每一条会修改数据的 SQL 都会记录在 binlog 中
- 优点:Statement 模式只记录执行的 SQL,不需要记录每一行数据的变化,因此极大的减少了 binlog 的日志量,避免了大量的 IO 操作,提升了系统的性能。
- 缺点:正是由于 Statement 模式只记录 SQL,而如果一些 SQL 中 包含了函数,那么可能会出现执行结果不一致的情况。比如说 uuid() 函数,每次执行的时候都会生成一个随机字符串,在 master 中记录了 uuid,当同步到 slave 之后,再次执行,就得到另外一个结果了。所以使用 Statement 格式会出现数据一致性问题。
2)Row快照模式(Row-Based Replication,RBR):不记录 SQL 语句上下文信息,仅保存哪条记录被修改。
- 优点:Row 格式的日志内容会非常清楚地记录下每一行数据修改的细节,这样就不会出现 Statement 中存在的那种数据无法被正常复制的情况。
- 缺点:Row 格式日志量太大了,特别是批量 update、整表 delete、alter 表等操作,由于要记录每一行数据的变化,此时会产生大量的日志,大量的日志也会带来 IO 性能问题。
3)Mixed(Mixed-Based Replication,MBR):Statement 和 Row 的混合体
MySQL的索引数据结构 P188
BTree索引:(MySQL中主要是B+Tree索引)
MyISAM:叶节点的data域存放的是数据记录的地址,在检索的时候,先搜索索引,如果key存在,就取出data域的值读取数据记录。
InnoDB:叶子节点保存了完整的数据记录。在根据主索引搜索时,直接找到key所在节点取出数据;在根据辅助索引检索时需要先取主索引的值,再走一遍主索引
哈希索引:当单条记录时查询更快,对于哈希索引来说底层就是哈希表
大表优化方案 P192
SQL查询规范:https://mp.weixin.qq.com/s__biz=Mzg2OTA0Njk0OA==&mid=2247485117&idx=1&sn=92361755b7c3de488b415ec4c5f46d73&chksm=cea24976f9d5c060babe50c3747616cce63df5d50947903a262704988143c2eeb4069ae45420&token=79317275&lang=zh_CN%23rd
分表(垂直分区):是将一张大表分成多个小表,垂直切分,查询时需要连表查询
表分区(水平分区):是列不变,将表中数据分到多个同样的表,查询时用union all合并查询结果
读写分离:主库负责写,从库负责读限定查询范围:分页查询
MySQL表分区方式
Range分区:基于一个给定的连续区间的列值。例如:范围分区(0,100],(100,200];时间分区(2022-01-01 00:00:00,2022-01-01 23:59:59]
List分区:类似range,区别是list分区是基于一个离散值集合,对某个值进行分区。例如()
Hash分区:基于用户定义的表达式进行分区
Key分区:
创建分区的两种方式
- 新表创建分区
REATE TABLE `fs_punch_in_log` ( `id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键自增' , `user_id` varchar(50) NULL DEFAULT NULL COMMENT '签到的用户id' , `punch_in_time` int(10) NULL DEFAULT NULL COMMENT '打卡签到时间戳' , PRIMARY KEY (`id`) ) partition BY RANGE (id) (
PARTITION p1 VALUES LESS THAN (40000000), PARTITION p2 VALUES LESS THAN (80000000), PARTITION p3 VALUES LESS THAN (120000000), PARTITION p4 VALUES LESS THAN MAXVALUE
);
- 已有表且有数据时创建分区
#order为表名,order_date为列名 alter table order partition by range(order_date)( partition p1 values less than (UNIX_TIMESTAMP('2020-01-01')), partition p2 values less than (UNIX_TIMESTAMP('2021-01-01')), partition pmax values less than (maxvalue) );
批量导数优化方案
1)复杂逻辑,数据仓库(hawq)加工,将结果直接存本地数据库(MySQL);
2)对于重复数据较多的,减少记录条数,合并不同列数据用“,”分割;
如:用户名 -1-> 证件号 -1-> 客户号 -n-> 卡号(卡号1,卡号2,卡号3...)本来一个卡号一行,现多个卡号一行,减少插入行数提高效率。
3)创建temp表,将结果数据导入后,修改表名,直接替换业务表;
如:业务表tab1,接口会一直对tab1进行操作,跑批则可以建立临时表tab1_temp,处理昨日的批量数据,处理好后将增量的tab1中的数据进行插入生成最终tab1_temp表,最后改tab1_temp表名为tab1替换原tab1表。
4)对于批量操作数据量不大的,对比差异,只更新差异数据;
接口慢SQL排查及优化方案
排查:1)同一时间段是否有批量操作;2)explain看SQL是否走索引;
优化:1)优化SQL语句;2)表分区;3)数据库读写分离;4)异步处理;
一点小知识
数据库的一些命令
是否走索引查询 >explain select * from ...
查询log是否开启 >show global variables like 'log'
查询数据库的隔离级别 >select @@tx_isolation
Mysql查看日志
1)查看日志是否开启>show variables like 'log_bin'
2)如果是开启,则在日志文件就在mysql的安装目录的data目录下
delete from 表名和truncate table 表名
1)delete相当于一条一条删除,自增id会继续增加
2)truncate相当于重建表,自增id从1开始
3)truncate比delete要快,但不记录日志不可恢复数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号