
游戏编程模式--字节码
写在前面
”通过将行为编码成虚拟机指令,而使其具备数据的灵活性。”
动机
制作游戏很有趣,但制作游戏却不易,特别是现在的游戏。现代游戏随着硬件技术的发展,游戏内容和玩法变得越来越丰富多样,在以前可能代码就几千行,但现代游戏的代码往往能达到几十万甚至几百万行。这么大的代码量,如果我们选择了c++这样的重量级语言(对于性能的追求,往往会让我们选择c或c++),编译的时间就不得不考虑了。游戏一个独有的苛刻的要求:有趣。玩家需要既新奇又具有平衡性的体验。这就需要持续迭代,但假如我们每一次修改都要工程师改底层的代码,然后等待漫长的重新编译,那么整个游戏的创作流程就被毁了。比如我们当前流行的moba类游戏,对于每个英雄的技能效果,设计都需要反复的修改才能在整体上达到一个平衡,如果不能提供一种修改后快速反馈结果的方式,相信没有那个设计师能坚持下去。
很明显,我们的编程语言不适合解决这个问题,我们需要另一种方式把这些经常需要修改的部分转移到安全沙箱中,同时让它们易于加载且在物理上于游戏的可执行文件分离。其实这些特性就优点像“数据”了,我们在运行的时候把它加载到内存中,然后按某种方式执行。也就是说我们使用“数据”来定义行为,然后执行这些数据。那有什么方法能让我们实现这种功能呢?其中一个是解释器模式,一个就是我们本节要讲的字节码模式。
首先我们简单来了解一下解释器模式,这能对我们接下来要将的字节码模式有个更好的理解。
解释器模式
解释器模式Gof早已著作成书,在这里,我们只做简单的了解。首先我们使用解释器来实现一个数学计算器,面对表达式:
(1+2)*(3-4)
我们首先对它进行一个语法分析,构建一个语法树(当然怎么构建语法树与解释器模式无关),然后执行它。
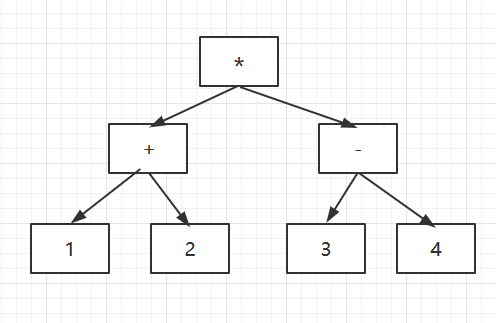
在这里如何执行了?我们把每个对象都看成一个表达式或子表达式,表达式定义如下:
class Expression { public: virtual ~Expression(){} virtual double evaluate() = 0; };
然后每个语法定义类都实现这个接口。比如数字和加法:
class NumberExpression:public Expression { public: NumberExpression(double value):value_(value) {} virtual double evaluate(){return value_;} private: double value_; }; class AdditionExpression:public Expression { public: AdditionExpression(Expression* left,Expression* right):left_(left),right_(right) {} virtual double evaluate() { //Evaluate the operands. double left = left_->evaluate(); double right = right_->evaluate(); //add them. return left+right; } private: Expression* left_; Expression* right_; };
只需要简单的几个类,就能够表达任何复杂的算术表达式了。我们要做的只是创建几个对象,然后把它们关联起来。
解释器模式虽然很简单,很漂亮,但是也是有些问题:
- 从磁盘加载它需要进行实例化并串联成堆的小对象;
- 这些对象和它们之间的指针占用了大量内存;
- 从每个指针遍历子表达式都会消耗大量的数据缓存,而虚函数调用也会对指令缓存造成很大的压力。
简单来说,就是:慢。大部分广泛使用的编程语言没有基于解释器模式也正因于此。它太慢了,且占用了大量的内存。
虚拟机器码
对比一下计算机的机器码,它不会生产小的对象,也不会有各种对象间的关联,它的特点是:
- 高密度。它是坚实连续的二进制数据块。不会再内存中跳跃访问;
- 线性。指令被打包在一起顺序执行,不会再内存中跳跃访问(当然,除非你确实写了控制流);
- 底层。每个单独的指令仅仅完成一个小动作,各种有趣的行为都是这些小动作的组合;
- 迅速。以上几点让机器码疾行如风。
当然,我们不会直接使用机器码来构建游戏。但我们确实希望能获得机器码的效率,这个时候我们就想到了搞一个折中的方案——虚拟字节码。即我们自己定义机器码,然后实现一个执行这些机器码的模拟器。机器码和模拟器完全受游戏本身的安全管理,这样就达到了灵活由高效的目标。我们把这个小型的模拟器称为虚拟机(VM),自定义的机器码称为字节码。看着挺吓人的,但如果你的功能清单不是太复杂的话,这个方案将非常可行。
字节码模式
指令集定义了一套可以执行的底层操作。一戏列的指令被编码称为字节序列。虚拟机逐条执行指令栈上这些指令。通过组合指令,即可完成很多高级的行为。
使用情境
字节码模式是最复杂的一个模式,它不是简单能放进你的游戏里的,当你的游戏中需要定义大量的行为,而且实现游戏的语言出现下列情况时才应该使用。
- 编程语言太底层了,编写起来繁琐易错;
- 因编译是按太长或工具问题,导致迭代慢;
- 它的安全性太依赖编码者。你想确保定义的行为不会让程序崩溃,就得把它们从代码库转移到安全沙箱中。
当然,这个列表符合大多数游戏的情况,谁不想提高迭代速度?谁不想让程序更安全?但那是有代价的,字节码比本地码要慢,所以它不适合对性能有极高要求的核心部分。
使用须知
建立一个自己的语言是一件非常有吸引力的事,但再游戏中我们需要克制,除非你确实想做个成熟的语言。否则,就需要对你的字节码所能表达的事情范围做一个限制,不能无限扩张。当你使用字节码的时候,你需要注意:
1)你需要一个界面
字节码性能很高,但你没法让用户直接编写二进制码。我们将行为从代码中移出来,就是想再更高级的层面上表述它。所以你需要为用户提供一个界面,让用户在更高的层次上编辑,然后使用一个工具自动生成字节码,这个工具我们称之为编译器。所以,如果你没有足够的资源实现一个编译器,那么字节码不适合你。
2)你会想念调试器的
成熟的编程语言,都会有一条完整的工具链,比如:调试器、静态分析器、反编译工具等。这些工具能极大的提高我们编程的效率,但当你使用自己的字节码时,这些工具就没有了(或者你也可以同时把它们都做了),那这个时候,如果程序出现bug,那你就只能慢慢猜是那个环节出错了,或者单步进入虚拟机的代码调试,这是非常低效的。
示例
现在我们已经对字节码有一个大概的了解了,现在我们来做一个简单的示例。
假设我们的游戏中有各种法术,大部分的法术都会改变角色身上的某个状态,比如生命值,我们就从定义这些行为的API开始:
void setHealth(int wizard,int amount); void setWisdom(int wizard,int amount); void setAgility(int wizard, int amount);
当然,为了游戏的有趣性,我们还会假如一些其它的特效和音效,
void playSound(int soundId); void spawnParticles(int particleType);
现在我们已经有了这些API了,现在让我们把它们编程一系列的指令并加入到我们的指令集中,一个指令对应一个枚举(因为我们的指令不多,枚举值长度取一个字节足矣,这就是所谓的字节码):
enum Instruction { INST_SET_HEALTH =0X00, INST_SET_WISDOM =0X01, INST_SET_AGILITY =0X02, INST_PLAY_SOUND =0X03, INST_SPAWN_PARTICLES =0X04 };
现在我们已经有了指令了,但还不够,我们还需要引入指令操作的参数,这里我们使用一个堆栈来存储所需的参数,堆栈也是实现表达式求值的通用做法。我们把栈放在虚拟机中,同时实现入栈,出栈的操作(假设数值只有整形):
class VM { public: VM():stackSize_(0){} void interpret(char bytecode[],int size) { for(int i=0;i<size;++i) { char instruction = bytecode[i]; switch(instruction) { //handle instruction... case INST_SET_HEALTH: int amount = pop(); int wizard = pop(); setHealth(wizard,amount); break; ...... default: break; } } } private: static const int MAX_STACK=128; int stackSize_; int stack_[MAX_STACK]; void push(int value) { //check assert(stackSize_<MAX_STACK); stack_[stackSize_++] = value; } int pop() { //check assert(stackSize_ > 0); return stack_[--stackSize_]; } };
这样,通过栈我们就能组合指令完成各种各样的行为。但观察可以发现,这里的参数都是一些常量,但很多的时候我们想造成一个相对量的变化,而不是绝对的量,比如把敌人当前的生命值扣除一半。也就是我们需要考虑状态当前的值,所以我们还得加上一个读取它们状态值的指令。
case INST_GET_HEALTH: { int wizard = pop(); push(getHealth(wizard); break; }
在这里,指令对栈做了双向的操作。它首先出栈一个参数,来确定获取那个目标的生命值,然后再把获取的生命值入栈。当然,现在的指令还是太简单了,能做的事有限,我们可以再往里加其它的基本指令,比如加减乘除的算术运算,调用过程等,不断的完善我们的字节码。
不过,我们可以停一下了,除非你真的打算使用它。我们看看现在的“字节码”和“虚拟机”,我们发现它就是一个堆栈、一个循环或是switch语句。我们可以通过控制堆栈的尺寸来限制它的可用内存,也可以限制它的运行时间(在指令循环中记录它的运行时间,当超出某个阈值的时候取消其执行)。我们已经完成了一个最简单的字节码和虚拟机,但还有一项工作没做,就是语法转换工具。
语法转换工具
我们最初的一个目标是在较高的层次上编写行为,,但是我们已经做了些比c++还底层的东西。它能兼顾我们需要的运行时性能和安全性,但是彻底缺乏对设计师友好的可用性。为了填补这缺陷,需要制作一些工具。我们需要一个程序,让用户在高层次上定义对象行为,并能生成对应的低层次栈机字节码。
这里有两个方法:
- 做一个能编译一个基本文本语言的编译器,然后使用自定义的高级语言来编写对象的行为,这个通常是程序员非常喜欢的;
- 带图形界面的编辑工具,比如在这个工具中用户只需要拖动一个小方块,点选菜单或其它的一些简单操作。这样做的好处就是你的UI让用户几乎难以创建“非法的”程序,你可以前瞻性的禁用按钮或者提供默认值来保证他们创建的东西在任何时候都是合法程序。
两种方式各有千秋,但毫无疑问,这是影响字节码模式是否能真正使用的关键因素。如果你能接受这个挑战,字节码模式将会让你的游戏性能来到一个新的高度。
设计决策
指令如何访问堆栈
字节码虚拟机有两大风格:基于栈和基于寄存器。在基于栈的虚拟机中,指令总是操作栈顶。基于寄存器的虚拟机也有一个堆栈,唯一的区别就是指令可以从栈的更深层次中读取输入,它在字节码中存储两个索引来表示应该从堆栈的那个位置读取操作数。
基于栈的虚拟机
- 指令很小。因为每个指令都隐式的从栈顶找它的参数,你无需对任何数据做编码。
- 代码生成更简单。因为每个指令隐式操作栈顶,你需要以正确的顺序输出指令,就能实现参数的传递。
- 指令数更多,还是因为只能操作栈顶,指令简单,所以复杂的行为就需要更多的指令来组合。
基于寄存器的虚拟机
- 指令更大。因为它需要记录参数在栈中的偏移量,单个指令需要更多的位数。
- 指令更少。因为每个指令能做更多的事。
那这里我们如何选了?我的建议是实现基于栈的虚拟机。因为它们更容易实现,生成代码也更简单。
应该有那些指令
你的指令集划定了字节码表达能力的界限,它对虚拟机的性能也有影响。以下详细列出了几种你可能需要的指令类型:
- 外部基本操作。它们是位于虚拟机之外,引擎内部的,它们决定字节码能够表达的真正行为。没有它们,你的虚拟机除了在烧cpu之外,没有任何用处。
- 内部基本操作:它们操作虚拟机内部的值——例如字面值,算术运算符、比较运算符和操作栈的指令。
- 控制流:如果你想要让指令有选择的执行或是循环重复执行,那你就需要控制流。在字节码的底层语言部分中,它们极其简单——跳转。在我们的指令循环中,我们有一个索引指向字节码堆栈的当前位置。每条跳转指令所做的就是改变改索引的值从而改变当前的额执行位置。换句话说,它就是一个goto语句。
- 抽象化:如果你的用户开始往数据中定义很多内容,那最终他们会希望能重用字节码而不是复制粘贴。你也许会用到可调用过程。最简单的情况下,调用过程并不比跳转复杂。唯一不同的是虚拟机要维护另一个“返回”堆栈。当它执行到一个“call”指令时,它将当前指令压入返回栈中然后调准到被调用的字节码。当它遇到一个“return”时,虚拟机从返回栈中弹出索引并跳转回索引所指位置。
值应当如何表示
一个功能完善的虚拟机应当支持不同的数据类型:字符串、对象、列表等。你必须决定如何在内部存储它们。
单一数据类型
简单。但你无法使用不同的数据类型,这个缺陷太明显了。将不同的类型填入到单一的呈现方式中——例如将数字存储成字符串——就是在自找麻烦。
标签的一个变体
这个动态类型语言通用的形式。每个值由两部分组成,第一部分是个标签——一个用来标志所存储数据类型的枚举值。
enum ValueType { TYPE_INT, TYPE_DOUBLE, TYPE_STRING }; struct Value { ValueType type; union { int intValue; double doubleValue; char* stringValue; }; };
值存储类自身的类型信息,好处就是能够在运行时对值的类型做检查。这对动态调用很重要并能够保证你不会把操作执行到不支持它们的类型上,带来的缺点就是占用更多的内存。
不带标签的联合体。
这个是针对前一种方法中内存占用大的问题的一个解决方案。不为值携带类型标签。所以你需要自行确保值能得到正确的解析,你不要在运行时检查类型。这就是静态类型语言在内存中表达事物的方式。它带给我们的好处就是紧凑、快速,但随之而来的就是不安全。
一个接口
确定值类型的一种面向对象的解决方案是多态。比如接口可以提供各种类型测试和转换的虚方法。像下面这样:
class Value { public: virtual ~Value(){} virtual ValueType type() = 0; virtual int asInt() { //can only call this on ints. assert(false); return 0; } //other conversion methods... };
你可能像下面这样定义数据的具体类:
class IntValue:public Value { public: IntValue(int value):value_(value){} virtual ValueType Type(){return TYPE_INT;} virutal int asInt() { return value_;} private: int value_; };
使用接口的特点是:
- 开放式。你可以定义任何实现基础接口的数据类型;
- 面向对象;对类型可以采取多态性调度,而不用像上述例子种对类型标签进行switch。
- 累赘。每一个数据类型都要定义一个类,并在里面填写一些重复而又固定的内容。
- 低效。为了实现多态,你得借助指针。这意味着布尔和数字这种微小的值也要被封装到对象中,并在堆上分配。每次访问一个值,你都是在做虚函数调用。
- 在虚拟机核心中,这样影响效率的点会不断增加,也是因为这个问题,我们尽力避免使用解释器模式。所以对于值,如果单一数据类型就够用,那么用单一数据类型,否则使用带标签的联合体。这几乎是所有编程语言的解析方式。
如何生成字节码
也就是之前字节码转换工具一节所说,我们是定义一个基于文本的语言,还是设计一个图形化的编辑工具。
定义一个基于文本的语言
- 首先你要定义一个语法。定义一个对分析器友好的语法容易,但是定义一种对用户友好的语法就难了。
- 你要实现一个分析器。
- 你必须处理语法错误。这是整个过程种最难的部分,因为你只知道错误发生在一个点上,如何把这个错误有效的反馈并不是一件轻松的事。
- 对于非技术人员没有亲和力。程序员喜欢文本文件,配合强大的命令行工具。但非程序员却不这么看待。
设计一个图形化编辑工具
- 你需要实现一个用户界面。用户界面通常都会很繁琐,因为需要考虑不同用户的可能的操作。
- 不同意出错。因为能可以提前做一些工作来防止非法程序的出现。
- 可移植性差。因为UI框架通常都是依赖操作系统的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号