

transformer中带掩码的多头注意力理解
解码器在做多头注意力的掩码时候, 得到的相似度矩阵
相似度矩阵A
A = Q@KT : [batch_size,n_head,seq_len,seq_len]
第一个为Q的seq_len,第二个为K的seq_len
对A做因果掩码
生成下三角掩码矩阵:
M: [seq_len,seq_len]
将该掩码矩阵与句子本身的掩码进行合并
由于掩码矩阵与句子本身的掩码形状不合,需要处理
对掩码矩阵做扩充 unsqueeze
M:[1,seq_len,seq_len]
将target_mask进行扩充
target_mask: [batch_size,1,seq_len]
将target_mask 与 M 逐乘得到最终掩码
M=target_mask * M
M: [batch_size,seq_len,seq_len]
由于此时掩码矩阵中还没有包含多头信息,所以,形状与相似度矩阵的形状不合,需要处理
扩充M
M: [batch_size,1,seq_len,seq_len]
进行掩码
对相似度矩阵A做掩码
A:[batch_size,n_head,seq_len,seq_len]
此时, A 中被掩码的部分, 既包含了下三角掩码矩阵的掩码 ,也包含了句子本身的掩码, 其内容大概会像:
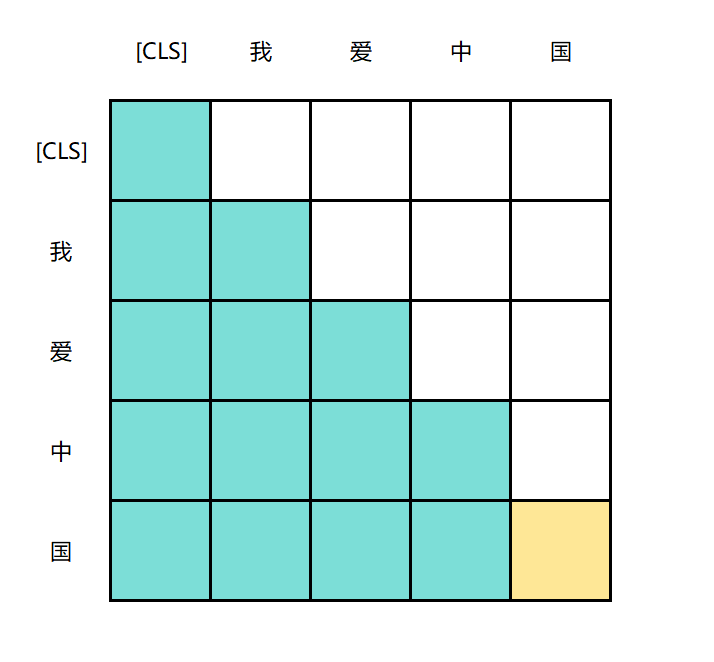
可以看到, 沿着竖的方向,只能看到自己位置与之前token的相似度。黄色的位置被句子自身的掩码所遮掩,其被遮掩的地方会填充成 -float(inf)
本质上来说,注意力计算分为两步:
- 相似度计算,A = Q@KT, 得到每个token之间的相似度方阵。此时方阵中token的排列从左上角依次从上到下,从左到右。 第一行则表示 token1 与token1,token2,token3... 之间的相似度
- 注意力计算, A@V,得到没个token在模型维度上的注意力值, 此时,从矩阵的左上上角开始,从上到下,分别为 token1,token2,token3... 从做到右分别是模型维度d1,d2,d3... ,第一行则表示token1在模型维度 d1,d2,d3...上的注意力值
所以注意力计算公式计算之后的最终结果: 列维度是模型维度。行维度是token列表维度, 即Q的维度, 且从上到下一次表示句子的token1, token2,token3 ....
即使是多次注意力计算, Q的维度依然不会变更。
所以,在进行交叉注意力计算之后, 列维度依然表示token维度,也就是目标句子的token维度。
由于对目标句子做了掩码, 所以,第一行则表示token1 与原句子之间的token列表的注意力。其维度大小为模型维度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号