

spark系列-1、spark介绍 & wordcount
一、spark介绍
1.1、spark的特点
- 运行速度快:使用DAG(全称 Directed Acyclic Graph, 中文为:有向无环图)执行引擎以支持循环数据流与内存计算(当然也有部分计算基于磁盘,比如shuffle)
- 易用性好:支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程
- 通用性强:Spark提供了完整而强大的工具,包括SQL查询、流式计算、机器学习和图算法组件
- 随处运行:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源
1.2、对比hadoop
解决问题的出发点不一样
- Hadoop用普通硬件解决存储和计算问题
- Spark用于构建大型的、低延迟的数据处理及分析应用程序,不实现存储
- Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷
- Spark中间数据放到内存中,迭代运算效率高
- Spark引进了弹性分布式数据集的抽象,数据对象既可以放在内存,也可以放在磁盘,容错性高,可用自动重建。
- RDD计算时可以通过CheckPoint来实现容错
- Hadoop只提供了Map和Reduce操作,Spark更加通用,提供的数据集操作类型有很多种,主要分为: Transformations(返回下一个RDD)和Actions(返回unit、产生动作如下载 打印)两大类
1.3、spark vs mapreduce
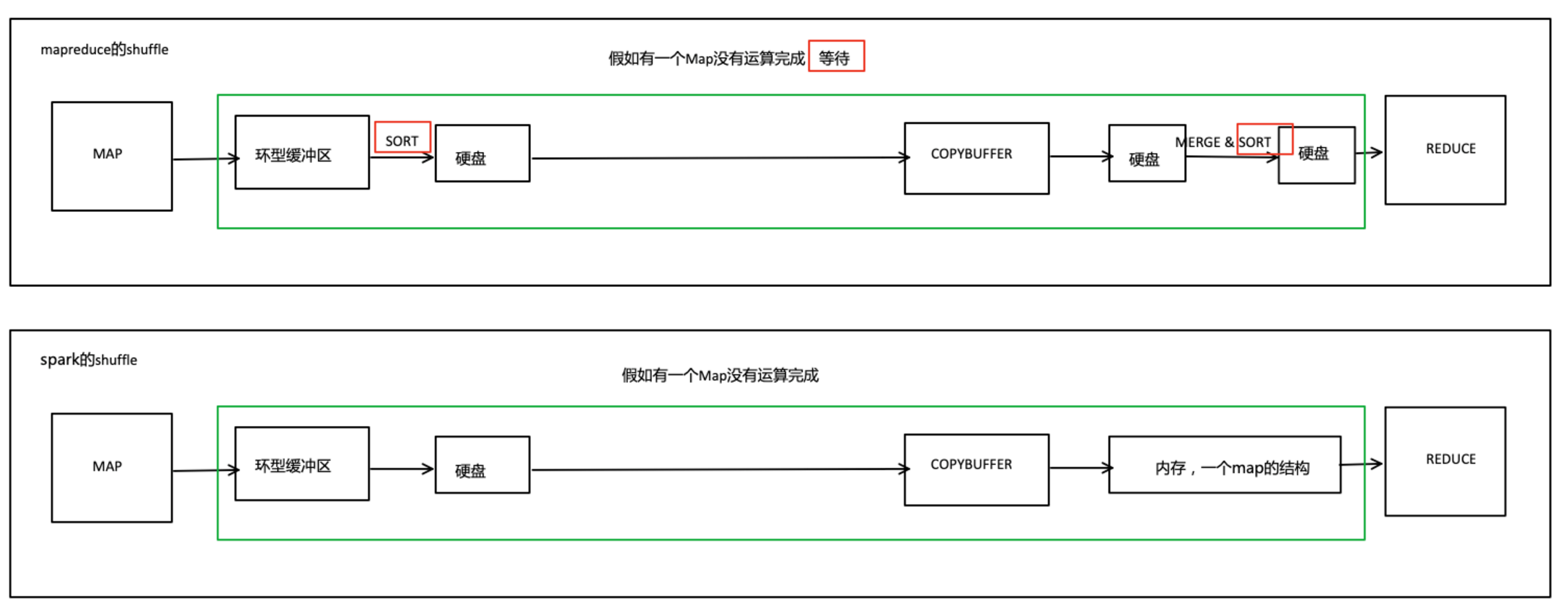
优点:
- shuffle对比,不用等,用的时候再排序
- MapReduce排序原因:硬盘按照顺序读取快,随机读取慢;
- MapReduce中reduce拉取数据的时间较长,拉取完才能进行reduce计算
- spark可以按照任务需求进行选择性排序(内存随机读无影响),也不需要等待数据拉取完(防止内存爆,来了就消化达到平衡状态)
![]()
- 会的招式多,各种算子方便你处理数据
- 可以把多次使用的数据放到内存中(MapReduce是放在磁盘中)
缺点:
-
过度依赖内存,内存不够用了就很难堪
二、Wordcount
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @author xiandongxie */ object WordCount { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf() conf.setMaster("local[*]") .setAppName("wordCount") val context: SparkContext = new SparkContext(conf) val sourceRDD: RDD[String] = context.parallelize( List( "a b c d e", "a b c d", "a b c", "a b", "a") ) val wordCountRDD: RDD[(String, Int)] = sourceRDD.flatMap(f => f.split(" ")) .map((_, 1)) .reduceByKey(_ + _) wordCountRDD.foreach(f => { println(f) }) } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号