
中文文本 分类 text_cnn fasttext
一.fasttext
介绍:https://blog.csdn.net/feilong_csdn/article/details/88655927
官方文档:https://fasttext.cc/docs/en/support.html
例子:https://github.com/facebookresearch/fastText/blob/master/python/doc/examples
补充:
1.预处理
查看多少行数据
wc -l train_9.txt
分配训练数据和测试数据
head -n 9000 train_9.txt > 9.train
tail -n 447 train_9.txt > 9.valid
2.训练命令
./fasttext supervised -input cooking.train -output model_cooking -lr 1.0 -epoch 25 -wordNgrams 3 -loss one-vs-all
3.验证
./fasttext test model_cooking cooking.valid
4.自动微调超参数
./fasttext supervised -input cooking.train -output model_cooking -autotune-validation cooking.valid -autotune-duration 600
5.调整模型大小
-autotune-modelsize 2M
二.text_cnn
论文:
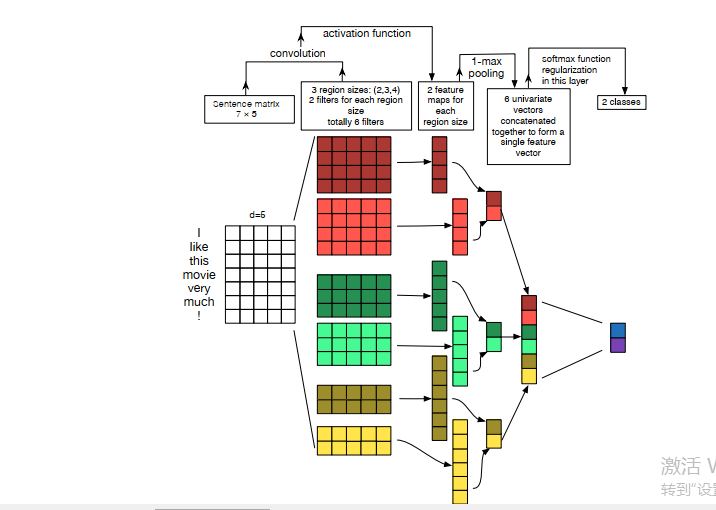
代码:
(1)tensorflow版本
def inference(self):
"""主计算图在这里
1.embedding-->
2.CONV-BN-RELU-MAX_POOLING-->
3.linear classifier"""
# 1.获取句子中出现的词 向量的集合 embedding 格式[None,sentence_length,embed_size]
self.embedded_words = tf.nn.embedding_lookup(self.Embedding, self.input_x)
# 扩大为[None,sentence_length,embed_size,1) 三维数组、满足2d-conv的要求
self.sentence_embeddings_expanded = tf.expand_dims(self.embedded_words, -1)
# 2.循环每个filter
# tf.nn.conv2d==>tf.nn.relu===>tf.nn.max_pool;
print("--------CNN is Training-----------")
pooled_outputs = []
for i, filter_size in enumerate(self.filter_sizes):
print('第%s次卷积,卷积核大小为%s' % (i + 1, filter_size))
with tf.variable_scope("convolution-pooling-%s" % filter_size):
# ====>a.创建 filter
filter = tf.get_variable("filter-%s" % filter_size, [filter_size, self.embed_size, 1, self.num_filters],
initializer=self.initializer)
# ====>b.卷积:
# conv2d===>计算2-D卷积 需要:4-D `input` 和 `filter`
# Conv.Input: input tensor `[batch, in_height, in_width, in_channels]`
# filter tensor `[filter_height, filter_width, in_channels, out_channels]`
# Conv.Returns: `Tensor`. 和 `input`一样. 4-D tensor.
# output shape:[batch_size,sequence_length - filter_size + 1,1,num_filters]
# 1)卷积核 conv2d 输出shape: [1,sequence_length-filter_size+1,1,1];
# 2)*num_filters--->[1,sequence_length-filter_size+1,1, num_filters];
# 3)*batch_size--->[batch_size,sequence_length-filter_size+1,1,num_filters]
# 输入数据格式:[batch, height, width, channels];
conv = tf.nn.conv2d(self.sentence_embeddings_expanded, filter, strides=[1, 1, 1, 1], padding="VALID",
name="conv")
conv = tf.contrib.layers.batch_norm(conv, is_training=self.is_training_flag, scope='cnn_bn_')
# ====>c. relu b == bias
b = tf.get_variable("b-%s" % filter_size, [self.num_filters])
h = tf.nn.relu(tf.nn.bias_add(conv, b), "relu")
# shape:[batch_size,sequence_length - filter_size + 1,1,num_filters].
# tf.nn.bias_add:adds `bias` to `value` ====>.max-pooling .value:
# A 4-D `Tensor` with shape `[batch, height, width, channels]
# ksize: A list of ints that has length >= 4.
# The size of the window for each dimension of the input tensor.
# strides: A list of ints that has length >= 4.
# The stride of the sliding window for each dimension of the input tensor.
# shape:[batch_size, 1, 1, num_filters]
# .max_pool:performs the max pooling on the input.
pooled = tf.nn.max_pool(h, ksize=[1, self.sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1], padding='VALID',
name="pool")
pooled_outputs.append(pooled)
# 3.=====>合并所有pooled features, and flatten the feature.output' shape is a [1,None]
# e.g. >>> x1=tf.ones([3,3]);x2=tf.ones([3,3]);x=[x1,x2] x12_0=tf.concat(x,0)---->x12_0'
# shape:[6,3] x12_1=tf.concat(x,1)---->x12_1' shape;[3,6]
# shape:[batch_size, 1, 1, num_filters_total].
# tf.concat=>沿着一个维度对几个pooled进行连接.
# where num_filters_total=num_filters_1+num_filters_2+num_filters_3
self.h_pool = tf.concat(pooled_outputs, 3)
# shape should be:[None,num_filters_total].
# e.g. x's shape:[3,3];tf.reshape(-1,x) & (3, 3)---->(1,9)
self.h_pool_flat = tf.reshape(self.h_pool, [-1, self.num_filters_total])
# 4.=====>添加 dropout: use tf.nn.dropout
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, keep_prob=self.dropout_keep_prob) # [None,num_filters_total]
h = tf.layers.dense(self.h_drop, self.num_filters_total, activation=tf.nn.tanh, use_bias=True)
# 5. logits(use linear layer) and predictions(argmax)
# shape:[None, self.num_classes]==tf.matmul([None,self.embed_size],[self.embed_size,self.num_classes])
with tf.name_scope("output"):
logits = tf.matmul(h, self.W_projection) + self.b_projection
return logits
(2) keras
def get_model():
inp = Input(shape=(maxlen, ))
x = Embedding(max_features, embed_size, weights=[embedding_matrix])(inp)
x = SpatialDropout1D(0.4)(x)
x = Reshape((maxlen, embed_size, 1))(x)
conv_0 = Conv2D(num_filters, kernel_size=(filter_sizes[0], embed_size), kernel_initializer='normal',
activation='elu')(x)
conv_1 = Conv2D(num_filters, kernel_size=(filter_sizes[1], embed_size), kernel_initializer='normal',
activation='elu')(x)
conv_2 = Conv2D(num_filters, kernel_size=(filter_sizes[2], embed_size), kernel_initializer='normal',
activation='elu')(x)
conv_3 = Conv2D(num_filters, kernel_size=(filter_sizes[3], embed_size), kernel_initializer='normal',
activation='elu')(x)
maxpool_0 = MaxPool2D(pool_size=(maxlen - filter_sizes[0] + 1, 1))(conv_0)
maxpool_1 = MaxPool2D(pool_size=(maxlen - filter_sizes[1] + 1, 1))(conv_1)
maxpool_2 = MaxPool2D(pool_size=(maxlen - filter_sizes[2] + 1, 1))(conv_2)
maxpool_3 = MaxPool2D(pool_size=(maxlen - filter_sizes[3] + 1, 1))(conv_3)
z = Concatenate(axis=1)([maxpool_0, maxpool_1, maxpool_2, maxpool_3])
z = Flatten()(z)
z = Dropout(0.1)(z)
outp = Dense(6, activation="sigmoid")(z)
model = Model(inputs=inp, outputs=outp)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
posted on 2020-04-08 14:01 nnnnnnnnnnnnnnnn 阅读(764) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号