
随机森林
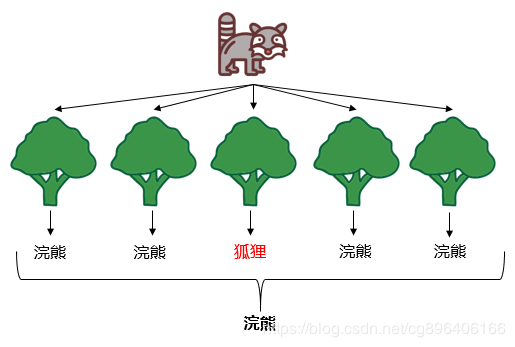
随机:一个是随机选取样本,一个是随机选取特征。 n 条数据 ,m个特征 随机2/3
袋外误差:袋外样本做测试集造成的误差称为袋外误差 1/3
随机森林的思想:构建出优秀的树,优秀的树需要优秀的特征。那我们需要知道各个特征的重要程度。
1.每个特征在多棵数中出现,取这个特征值在多棵树中的重要程度的均值即为该特征在森林中的重要程度。
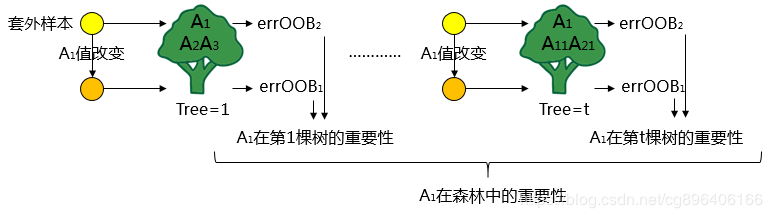
这样就得到了所有特征在森林中的重要程度。将所有的特征按照重要程度排序,去除森林中重要程度低的部分特征,得到新的特征集。这时相当于我们回到了原点,这算是真正意义上完成了一次迭代。
2.按照上面的步骤迭代多次,逐步去除相对较差的特征,每次都会生成新的森林,直到剩余的特征数为为止。最后再从所有迭代的森林中选出最好的森林。迭代的过程如下图所示:

2. demo 个人认为 最重要的两个值 深度 叶子结点 当然重中之重是特征的选择
RandomForestClassifier
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
"""
一个训练随机森林的脚本
# n_estimators:子树数量
# min_samples_leaf:最小样本叶片大小 如果样本量不大,不需要管这个值。
# max_features:随机森林允许单个决策树使用特征的最大数量 50维度默认None
# max_depth: 常用的可以取值10-100之间
# min_samples_split: 内部节点再划分所需最小样本数
# min_weight_fraction_leaf:叶子节点最小的样本权重和。有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重
# print("最终结果", sorted(results, key=lambda x: x[2], reverse=True))
# print(print(max(results, key=lambda x: x[2])))
results.append((leaf_size, n_estimators_size, (groud_truth == predict).mean()))
"""
import multiprocessing
import numpy as np
import pandas as pd
from joblib import Parallel, delayed
from keras import metrics
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score, GridSearchCV
from wssc.app.config import DIM_DICT, DATASET
import matplotlib.pylab as plt
# %matplotlib inline
def create_bag_of_centroids(wordlist, dim_dict=DIM_DICT, num_centroids=len(DIM_DICT)):
"""
向量袋
:param wordlist:
:param dim_dict:
:param num_centroids:
:return:
"""
bag_of_centroids = np.zeros(num_centroids, dtype="float32")
for word in wordlist:
if dim_dict.__contains__(word):
index = dim_dict.__getitem__(word)
bag_of_centroids[index] += 1
return bag_of_centroids
def main():
NUM_CORES = multiprocessing.cpu_count()
raw_data = pd.read_csv(DATASET % "result_1")
raw_data["DIM"] = Parallel(n_jobs=NUM_CORES, verbose=10)(
delayed(create_bag_of_centroids)(raw_data.iloc[index]["DIM"].split(";")) for index in range(len(raw_data)))
x_train = np.array(raw_data["DIM"].values.tolist())
print("训练集:", x_train.shape)
y_train = np.array(raw_data["C_ID"])
print("标签:", y_train.shape)
results = []
forest = RandomForestClassifier(n_estimators=60, min_samples_leaf=40,
min_samples_split=120, max_depth=9,
max_features='sqrt', random_state=10)
clf = forest.fit(x_train, y_train)
x_test = np.array(raw_data["DIM"].values.tolist()[:500])
y_test = np.array(raw_data["C_ID"][:500])
y_predprob = clf.predict_proba(x_test)[:, 1]
scores = cross_val_score(clf, x_test, y_test, cv=5)
results.append((scores.mean()))
print(results)
# joblib.dump(forest, MODEL % "lihun1.3", compress=3)
if __name__ == '__main__':
main()
posted on 2020-01-06 10:50 nnnnnnnnnnnnnnnn 阅读(473) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号