SIMD指令学习笔记
SIMD发展
所谓的SIMD指令,指的是single instruction multiple data,即单指令多数据运算,其目的就在于帮助CPU实现数据并行,提高运算效率。
MMX
MMX是由57条指令组成的SIMD多媒体指令集,MMX将64位寄存当作2个32位或8个8位寄存器来用,只能处理整形计算,这样的64位寄存器有8组,分别命名为MM0~MM7.这些寄存器不是为MMX单独设置的,而是借用的FPU的寄存器,占用浮点寄存器进行运算(64位MMX寄存器实际上就是浮点数寄存器的别名),以至于MMX指令和浮点数操作不能同时工作。为了减少在MMX和浮点数模式切换之间所消耗的时间,程序员们尽可能减少模式切换的次数,也就是说,这两种操作在应用上是互斥的。
SSE
SSE全称是Streaming SIMD Extensions,是一种在MMX基础上发展出来的SIMD指令集,其不再占用浮点寄存器,而是使用单独的128位XMM寄存器。在此基础上又发展除了SSE2/SSE3/SSE4指令集。SSE2则进一步支持双精度浮点数,由于寄存器长度没有变长,所以只能支持2个双精度浮点计算或是4个单精度浮点计算,另外,它在这组寄存器上实现了整型计算,从而代替了MMX。SSE3支持一些更加复杂的算术计算。SSE4增加了更多指令,并且在数据搬移上下了一番工夫,支持不对齐的数据搬移,增加了super shuffle引擎等。
AVX
在SSE指令集的基础上将128位的XMM寄存器扩展为长度为256位的YMM寄存器,使其支持256位的矢量计算,并且AVX全面兼容SSE/SSE2/SSE3/SSE4,也就是YMM寄存器的低128位就是XMM寄存器。
3DNow!
3DNow!是对于Intel MMX寄存器的逻辑拓展,MMX仅提供了并行的整数操作,3DNow!实现了并行浮点操作。3DNow!在现有MMX指令集基础上拓展可以做到混合操作整数代码和浮点代码,同时不需要MMX必须的上下文转换。
SIMD指令支持
要使用SIMD指令集,需要同时获得处理器和编译器的支持,以我目前的电脑为例:
查看CPU支持的SIMD指令集
cat /proc/cpuinfo
可以看到编译器支持的SIMD指令集:
......
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d
......
查看GCC处理器支持的SIMD指令集
gcc -march=native -c -Q --help=target
可以看到支持和不支持的SIMD指令集:
The following options are target specific:
......
-mavx [enabled]
-mavx2 [enabled]
-mavx256-split-unaligned-load [disabled]
-mavx256-split-unaligned-store [disabled]
-mavx512bw [disabled]
-mavx512cd [disabled]
-mavx512dq [disabled]
-mavx512er [disabled]
-mavx512f [disabled]
-mavx512ifma [disabled]
-mavx512pf [disabled]
-mavx512vbmi [disabled]
-mavx512vl [disabled]
......
-mmmx [enabled]
......
-msse [enabled]
-msse2 [enabled]
-msse2avx [disabled]
-msse3 [enabled]
-msse4 [enabled]
-msse4.1 [enabled]
-msse4.2 [enabled]
-msse4a [disabled]
-msse5
-msseregparm [disabled]
-mssse3 [enabled]
......
SIMD指令
MMX指令
寄存器
MMX使用8个64位的通用寄存器MM0-MM7,这些寄存器中每个都可以作为一个64位,也可以作为2个32位,4个16位或者8个8位使用。
模式
由于MMX和FPU寄存器共享相同的空间,因此MMX代码和浮点代码就不能同时使用,所以也就有MMX模式和FPU模型。从FPU模式进入MMX模式比较简单,就是直接执行一个MMX指令即可。但是退出MMX模式进入FPU模式就不那么简单,这里要使用一个指令:
emms
该指令没有任何参数,可以在任何时候执行。使用该指令就可以恢复FPU从可以正常执行浮点指令。
指令与指令形式
MMX的指令除了几个特殊的,几乎都是以字母p开头的。
大多数指令结尾处标明的操作数的位数:
b:byte,字节,8位
w:word,双字节,字,16位
d:doubleword,双字,32位
q:quadwords,四字,64位
不以p开头的指令
从MMX模式进入FPU模式:
emm
32位数据移动,在内存和寄存器或者寄存器之间,移动之后,寄存器高32位会置为0:
movd
在寄存器之间或者内存和寄存器之间移动64位数据:
movq
以p开头的指令
p+功能+其他+位数
paddb ;无符号
paddsb ;有符号
paddusb ;无符号
paddw
paddsw
paddusw
paddd
SSE指令
寄存器
SSE指令有8个128位寄存器XMM0-XMM7,每个寄存器可以存放4个32位单精度浮点数,使用这些寄存器就可以完成SSE的浮点运算指令。此外,还有一个控制寄存器MXCSR。MXCSR寄存器是一个32位的关于SSE指令控制状态信息的一个32位寄存器。
模式
按照运算方式的不同将SSE指令分成Packed和Scalar两类:
Packed方式:这种方式的SSE指令,对于XMM寄存器中四个浮点数都对应进行计算
Scalar方式:这种方式的SSE指令,只对XMM寄存器最低的一个浮点数进行计算
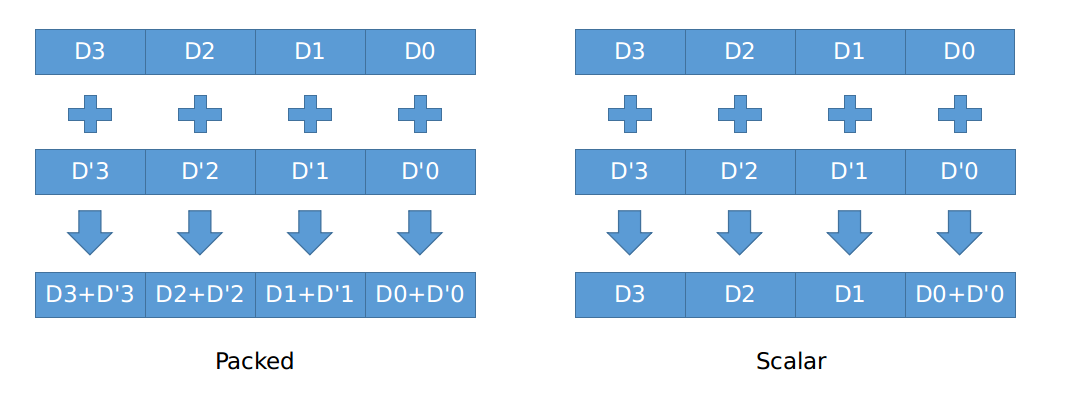
指令与指令形式
SSE指令的指令格式由三部分组成:指令+模式+s,比如addps,就代表xmm寄存器四个单精度浮点数都分别相加。
算数指令
addps ;加法,4个32位全加
addss ;加法,低32位加,其他不变
mulps ;乘法,
mulss ;乘法,
比较指令
cmpxxps ;比较4个单精度浮点数。
cmpxxss ;比较最低的两个单精度浮点数。
comiss ;比较最低的两个单精度浮点值,并且将结果存到EFLAGS。
ucomiss ;同上,不同指出是不会QNaNs抛出异常。
逻辑指令
andps ;逻辑与4个单精度浮点数与其他4个单精度浮点数。
转换指令
cvtpi2ps ;将2个32位整数转换为32位浮点数。
cvtps2pi ;与上条指令相反,
cvtsi2ss ;将一个32位整数转换为32位浮点数,前边的3个值保持不变。
cvtss2si ;与上条指令相反。
cvttps2pi ;使用截断,将2个32位浮点值转换为32位整数。
cvttss2si ;与上条指令相反。
Load/Store指令
movaps ;移动128位值。
movhlps ;移动高一半到低一半
movhps ;移动64位值到xmm寄存器的高一半。.
movss ;移动低位的单精度浮点数,如果目的地址是另外的Xmm寄存器,高位3个浮点数保持不变,否则置为0。
shuffle指令
shufps ;打乱4个单精度浮点数
SSE2
SSE2是SSE指令的升级版,寄存器与指令格式都和SSE一致,不同之处在于其能够处理双精度浮点数等更多数据类型。
addpd ;2个64位双精度浮点数分别相加
addsd ;只加低64位双精度浮点数
mulpd
mulsd
paddq ;2个64位整数相加
cmppd ;比较2对64位double
cmpsd ;比较处于低64位的double
movq ;移动一个64位的值,清空XMM寄存器的高64位
movsd ;移动一个64位的double,如果在两个XMM寄存器之间移动那么就保持高64位不变
movapd ;移动两个对其的64位double
movupd ;移动两个不对其的64位double
movhpd ;移动到XMM寄存器或者从XMM寄存器移出高64位值
movlpd ;移动到XMM寄存器或者从XMM寄存器移出低64位值
movdq2q ;Moves bottom 64bit value into an MMX register.
movq2dq ;Moves an MMX register value to the bottom of an XMM register. Top is cleared to zero.
movntpd ;Moves a 128bit value to memory without using the cache. NT is "Non Temporal."
movntdq ;Moves a 128bit value to memory without using the cache.
movnti ;Moves a 32bit value without using the cache.
clflush ;从所有级别的cache刷新cache line
SSE3
SSE3增加了13条新的指令。
addsubpd ;高位的两个double相加,低位的两个double相减
addsubps ;对于打包单精度浮点数,对第2个和第4个32位执行加法,第1和第3个32位执行减法
haddpd ;结果高位的double是第一个操作数的高位和低位的和,低位的double是第二个操作数的高位和低位和
haddps ;两个操作数四个单精度浮点数分别相加
lddqu ;加载一个不对其的128位值
movddup ;将64位值同时加载进128位寄存器的高位和低位
movshdup ;Duplicates the high singles into high and low singles.
movsldup ;Duplicates the low singles into high and low singles.
fisttp ;用截断的方式转换一个浮点值到一个整数
3DNow!指令
寄存器
3DNow!指令的寄存器和MMX一样,都是和FPU寄存器共享空间的8个64位寄存器,在3DNow中,如果当做浮点单元使用,每一个寄存器都存储两个32位的浮点值,如果当做整数单元使用,同MMX。
模式
3DNow和MMX使用相同的空间,因此同样可以使用:
emms
指令进行清除,该指令用在从MMX/3DNow转换到一般浮点寄存器模式。
除了以上这个指令,3DNow增加了一个比emms更快的指令:
femms
作用相同,速度更快。
指令与指令形式
大多数指令都是以p开头的。
浮点指令
pfmax ;获取两个浮点数中大者,第一个参数是寄存器,第二个参数是内存或者寄存器,最终结果存储在第一个寄存器中。
pfcmpeq ;比较两个32位浮点数是否相等。参数,运算结果情况同上。
pfadd ;加法指令,参数,运算结果情况同上。
pfmul ;同上。
转换指令
3DNow提供了在整数和浮点数类型之间的转换指令。
pi2fd ;第一个参数是浮点数值,第二个参数是MMX寄存器或者一个内存位置,该指令将整数转换为浮点数。
pf2id ;将浮点数转换为整数
整数指令
虽然3DNow!主要是针对浮点运算的,但是3DNow还是在MMX基础上增加了整数指令:
pavgusb
pmulhrw
其他指令
3DNow!增加了两个缓存管理的指令,这两个指令的作用是相同的,都是将数据加载进缓存,不同的是后者同时准备将数据写回。参数都是一个,即加载数据的地址。一个完全的cache line被加载,都至少是32位。
prefetch
prefetchw
AVX
寄存器
YMM0-YMM15一共16个256位寄存器,XMM寄存器被映射到YMM寄存器的高一半的位置。
指令与指令形式
AVX重现了许多SSE指令,但是也增加了一些新的指令:
VBROADCAST[S|D|F128] ;赋值一个32到128位操作数到一个寄存器的所有域
VINSERTF128 ;替代一个YMM寄存器的高一半或者低一半
VEXTRACT128 ;赋值一个YMM寄存器的高或者低一半
VMASKMOVP[S|D] ;条件移动
SIMD指令的使用
对于SIMD指令集的使用,有如下三种方式:
编译器优化
即使用C/C++编写程序之后,带有SIMD优化选项编译,在CPU支持的情况下,编译器按照自己的规则去优化。
使用intrinsic指令
参考Intel手册,针对SIMD指令,可以在编程时直接使用其内置的某些库函数,编译的时候在cpu和编译器的支持下会生成对应的SIMD指令。
比如:
double _mm_cvtsd_f64 (__m128d a)
该函数编译时就会翻译成指令:
movsd
嵌入式汇编
内联汇编直接在程序中嵌入对应的SIMD指令。
SIMD指令使用举例
简单浮点数矩阵乘法(编译器优化)
float_matrix_mutiply.c:
#include <stdio.h>
#include <stdio.h>
void printf_matrix(int x,int y,double a[x][y])
{
for(int i=0;i<x;i++){
for(int j=0;j<y;j++){
printf("%lf ",a[i][j]);
}
printf("\n");
}
}
int main()
{
int M=2,N=3,P=4;
double matrix1[M][N];
double matrix2[N][P];
FILE *fp1,*fp2;
fp1 = fopen("./matrix1","r");
fp2 = fopen("./matrix2","r");
int i = 0;
while(!feof(fp1)){
fscanf(fp1,"%lf %lf %lf",&matrix1[i][0],&matrix1[i][1],&matrix1[i][2]);
i++;
}
printf("The first matrix is:\n");
printf_matrix(M,N,matrix1);
int j = 0;
while(!feof(fp2)){
fscanf(fp2,"%lf %lf %lf %lf",&matrix2[j][0],&matrix2[j][1],&matrix2[j][2],&matrix2[j][3]);
j++;
}
printf("The second matrix is:\n");
printf_matrix(N,P,matrix2);
double result[M][P];
for(int i=0;i<M;i++){
for(int k=0;k<P;k++){
for(int j=0;j<N;j++){
result[i][k] += matrix1[i][j]*matrix2[j][k];
}
}
}
printf("The matrix mutilpy result is:\n");
printf_matrix(M,P,result);
}
编译:
gcc float_matrix_mutiply.c -o float_matrix_mutiply -msse -mfpmath=sse -march=native
反编译可以看到使用了xmm寄存器以及movsd这样的SIMD指令:
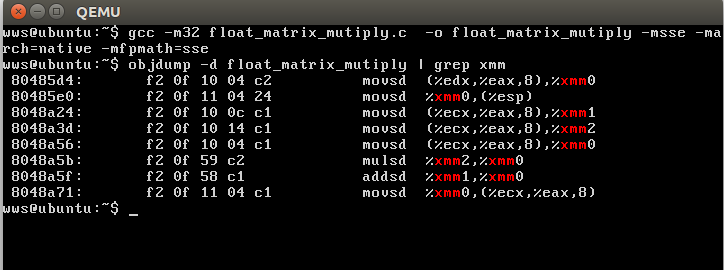
数组对应位置求和(intrinsic指令)
程序:
#include <stdio.h>
#include <x86intrin.h>
int main()
{
float __attribute__((aligned(16))) a[4]={1.0,2.0,3.0,4.0};
float __attribute__((aligned(16))) b[4]={4.0,3.0,2.0,1.0};
__m128 A=_mm_load_ps(a);
__m128 B=_mm_load_ps(b);
__m128 C=_mm_add_ps(A,B);
for(int i=0;i<4;i++)
printf("%f ",C[i]);
printf("\n");
return 0;
}
编译:
gcc time.c -o time -msse -m32
反汇编:

参考
difference between MMX and XMM register?
Streaming SIMD Extensions (SSE)
Streaming SIMD Extensions 2 (SSE2)
Streaming SIMD Extensions 3 (SSE3)
[使用Intel SSE/AVX指令集(SIMD)加速向量内积计算](

 浙公网安备 33010602011771号
浙公网安备 33010602011771号