补交作业
python基础
# -*- coding:utf-8 -*-
from turtle import *
def mygoto(x,y):
up()
goto(x,y)
down()
def drawStar(r):
begin_fill()
for i in range(5):
forward(r)
right(144)
end_fill()
setup(800,500)
bgcolor('red')
color('yellow')
fillcolor('yellow')
mygoto(-335,125)
drawStar(100)
mygoto(-240,200)
drawStar(50)
mygoto(-180,140)
drawStar(50)
mygoto(-180,75)
drawStar(50)
mygoto(-240,30)
drawStar(50)
done()
综合练习:英文词频统计
- 词频统计预处理
- 下载一首英文的歌词或文章
- 将所有,.?!’:等分隔符全部替换为空格
- 将所有大写转换为小写
- 生成单词列表
- 生成词频统计
- 排序
- 排除语法型词汇,代词、冠词、连词
- 输出词频最大TOP10
截图:


中文词频统计
下载一长篇中文文章。
从文件读取待分析文本。
news = open('gzccnews.txt','r',encoding = 'utf-8')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
输出词频最大TOP20
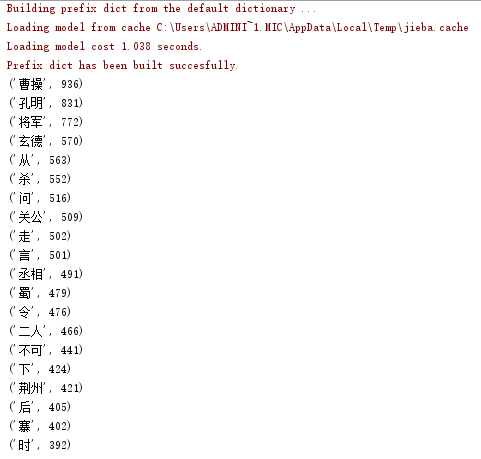
网络爬虫基础练习
0.可以新建一个用于练习的html文件,在浏览器中打开。
1.利用requests.get(url)获取网页页面的html文件
import requests
newsurl='http://news.gzcc.cn/html/xiaoyuanxinwen/'
res = requests.get(newsurl) #返回response对象
res.encoding='utf-8'
2.利用BeautifulSoup的HTML解析器,生成结构树
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text,'html.parser')
3.找出特定标签的html元素
soup.p #标签名,返回第一个
soup.head
soup.p.name #字符串
soup.p. attrs #字典,标签的所有属性
soup.p. contents # 列表,所有子标签
soup.p.text #字符串
soup.p.string
soup.select(‘li')
4.取得含有特定CSS属性的元素
soup.select('#p1Node')
soup.select('.news-list-title')
5.练习:
取出h1标签的文本
取出a标签的链接
取出所有li标签的所有内容
取出第2个li标签的a标签的第3个div标签的属性
取出一条新闻的标题、链接、发布时间、来源
# -*- coding : UTF-8 -*-
# -*- author : onexiaofeng -*-
import requests
url='http://localhost:63342/hello/venv/lz.html?_ijt=l26l1kkfr4kkmba1tsi16auibm'
res=requests.get(url)
res.encoding='utf-8'
res.text
from bs4 import BeautifulSoup
soup=BeautifulSoup(res.text,'html.parser')
soup
print(soup.h1.text)
print(soup.a['href'])
for i in soup.select('li'):
print(i)
print(soup.select('li')[1].a.select('div')[2].attrs)
print('标题:'+soup.select('.news-list-title')[0].text)
print('链接:'+soup.select('a')[2]['href'])
print('发布时间:'+soup.select('.news-list-info')[0].span.text)
print('来源:'+soup.select('.news-list-info')[0].select('span')[1].text)
截图:
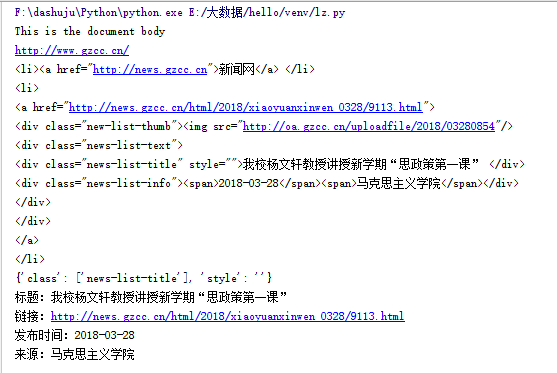
获取全部校园新闻
1.取出一个新闻列表页的全部新闻 包装成函数。
2.获取总的新闻篇数,算出新闻总页数。
3.获取全部新闻列表页的全部新闻详情。
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import re
#获得新闻点击次数
def getclick(link):
newId = re.search('\_(.*).html', link).group(1).split('/')[1]
click = requests.get('http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(newId))
return click.text.split('.html')[-1].lstrip("('").rstrip("');")
def getnewsdetail(link):
resd = requests.get(link)
resd.encoding = 'utf-8'
soupd = BeautifulSoup(resd.text, 'html.parser')
content=soupd.select('.show-content')[0].text
info=soupd.select('.show-info')[0].text
clickcount = getclick(link)
time=re.search('(\d{4}.\d{2}.\d{2}\s\d{2}.\d{2}.\d{2})',info).group(1)
if (info.find('作者') > 0):
author = re.search('作者:((.{2,4}\s|.{2,4}、|.{2,4},|\w*\s){1,5})', info).group(1)
else:
author = 'none'
if (info.find('审核') > 0):
auditing = re.search('审核:((.{2,4}\s|.{2,4}、|.{2,4},|\w*\s){1,5})', info).group(1)
else:
auditingr = 'none'
if (info.find('来源:') > 0):
source = re.search('来源:(.*)\s*摄|点', info).group(1)
else:
source = 'none'
dateTime=datetime.strptime(time,'%Y-%m-%d %H:%M:%S')
print('发布时间:{0}\n作者:{1}\n审核:{2}\n来源:{3}\n点击次数:{4}'.format(dateTime,author,auditing,source,clickcount))
print(content)
def getlistpage(listlink):
res=requests.get(listlink)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
for news in soup.select('li'):
if (len(news.select('.news-list-title')) > 0):
title = news.select('.news-list-title')[0].text
description = news.select('.news-list-description')[0].text
link = news.a.attrs['href']
print('新闻标题:{0}\n新闻描述:{1}\n新闻链接:{2}'.format(title,description,link))
getnewsdetail(link)
break
listlink='http://news.gzcc.cn/html/xiaoyuanxinwen/'
from datetime import datetime
getlistpage(listlink)
res=requests.get(listlink)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
listCount = int(soup.select('.a1')[0].text.rstrip('条'))//10+1
for i in range(2,listCount):
listlink='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
getlistpage(listlink)
4.找一个自己感兴趣的主题,进行数据爬取,并进行分词分析。不能与其它同学雷同。
# -*- coding: UTF-8 -*-
# -*- author: yjw -*-
import requests
import re
import jieba
from bs4 import BeautifulSoup
from datetime import datetime
def getnewdetail(link):
res=requests.get(link)
res.encoding='gb2312'
soup=BeautifulSoup(res.text,'html.parser')
Alltext=len(soup.select(".text"))
content=''
for p in range(0,Alltext):
content+=soup.select('.text')[p].text+'\n'
if(Alltext>0):
print(content+"\n词频统计:")
delword={['我', '他', '你', '了', '那', '又', '-', '的', '我们', '是', '但', '中', '这', '在', '也', '都', '而','你',' ','我','我们', '他', '他们', '我的', '他的', '你的', '呀', '和', '是',',','。',':','“','”','的','啊','?','在','了',\
'说','去','与','不','是','、','也','又','!','着','儿','这','到','就', '\n','(',')','那','有','上','便','和','只','要','小','罢','那里',\
'…','一个','?','人','把','被','她','都','道','好','还','’','‘','呢','来','得','你们','才','们'
'\n', ',', '。', '?', '!', '“', '”', ':', ';', '、', '.', '‘', '’', '(', ')', ' ', '【', '】', '…']
}
word={}
newscontent=list(jieba.cut(content))
wordfit=set(newscontent)-set(delword)
for i in wordfit:
word[i]=newscontent.count(i)
text = sorted(text3.items(), key=lambda x: x[1], reverse=True)
for i in range(20):
print(text[i])
else:
print('picture')
def getnewlist(link):
res=requests.get(link)
res.encoding='gb2312'
soup=BeautifulSoup(res.text,'html.parser')
for newlist in soup.select('.listInfo')[0].select('li'):
title = newsList.select('a')[0].text
time = newsList.select('.info')[0].select('p')
link = newsList.select('a')[0]['href']
print('\n新闻标题:{0}\n发表时间:{1}\n新闻链接:{2}\n'.format(title, time, link))
getnewdetail(link)
link='http://sports.qq.com/a/20180411/020544.htm'
getnewlist(link)
for i in range(1,20):
if(i==1):
getnewlist(link)
else:
link="http://sports.qq.com/a/20180411/020544_{}.htm".format(i)
getnewslist(link)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号