

测试环境搭建(Oracle & PostgreSQL通用)
1. 创建测试表
1.1 新建表
-- 表1:主数据表(商品服务表)
CREATE TABLE table_1 (
col_1 VARCHAR2(50), -- 商品类别
col_2 VARCHAR2(50), -- 商品子类
col_3 VARCHAR2(50), -- 商品ID
valid_date DATE, -- 有效日期
serv_type VARCHAR2(20) -- 服务类型
);
-- 表2:服务类型表
CREATE TABLE table_2 (
servtype VARCHAR2(20) PRIMARY KEY, -- 服务类型编码
b_type VARCHAR2(50) -- 服务类型名称
);
1.2. 插入测试数据
-- 插入服务类型
INSERT INTO table_2 VALUES ('S1', '标准服务');
INSERT INTO table_2 VALUES ('S2', '高级服务');
INSERT INTO table_2 VALUES ('S3', '定制服务');
-- 插入商品服务数据(包含重复最大日期)
INSERT INTO table_1 VALUES ('A', 'A1', 'P100', DATE '2023-01-01', 'S1');
INSERT INTO table_1 VALUES ('A', 'A1', 'P100', DATE '2023-03-15', 'S1'); -- 最大日期(重复)
INSERT INTO table_1 VALUES ('A', 'A1', 'P100', DATE '2023-03-15', 'S1'); -- 最大日期(重复)
INSERT INTO table_1 VALUES ('A', 'A1', 'P101', DATE '2023-02-10', 'S2');
INSERT INTO table_1 VALUES ('A', 'A1', 'P101', DATE '2023-04-20', 'S2'); -- 最大日期
INSERT INTO table_1 VALUES ('B', 'B1', 'P200', DATE '2023-01-15', 'S1');
INSERT INTO table_1 VALUES ('B', 'B1', 'P200', DATE '2023-05-01', 'S3'); -- 最大日期
COMMIT;
2 原SQL与问题分析
2.1 原SQL
-- 原SQL(自关联效率低)
SELECT T1.col_1, T1.col_2, T1.col_3, T2.b_type, T1.VALID_DATE
FROM table_1 T1, table_2 T2
WHERE T1.SERV_TYPE = T2.SERVTYPE
AND t1.valid_date = (SELECT MAX(t3.valid_date)
FROM table_1 T3
WHERE t3.col_1 = t1.col_1
AND t3.col_2 = t1.col_2
AND t3.col_3 = t1.col_3);
2.2 问题诊断
-
N+1查询问题:对主查询的每行数据执行子查询
-
重复扫描:table_1表被扫描多次(主查询+子查询)
-
重复结果:当最大日期有重复时,返回多行相同记录
3 优化方案(Oracle & PostgreSQL通用)
3.1 SQL改写
方案1:精确等价改写(保留重复记录)
SELECT T1.col_1, T1.col_2, T1.col_3, T2.b_type, T1.VALID_DATE
FROM (
SELECT t3.*,
MAX(valid_date) OVER (PARTITION BY col_1, col_2, col_3) AS max_valid_date
FROM table_1 t3
) T1
JOIN table_2 T2 ON T1.SERV_TYPE = T2.SERVTYPE
WHERE T1.valid_date = T1.max_valid_date;
方案2:业务严谨改写(去除重复记录)
SELECT T1.col_1, T1.col_2, T1.col_3, T2.b_type, T1.VALID_DATE
FROM (
SELECT col_1, col_2, col_3, valid_date, serv_type,
ROW_NUMBER() OVER (PARTITION BY col_1, col_2, col_3
ORDER BY valid_date DESC) AS rn
FROM table_1
) T1
JOIN table_2 T2 ON T1.SERV_TYPE = T2.SERVTYPE
WHERE T1.rn = 1;
3.2 执行计划对比(Oracle示例)
原SQL执行计划
OPERATION | OPTIONS | OBJECT_NAME | COST |
--------------------|-----------------|-------------|------|
SELECT STATEMENT | | | 156 |
NESTED LOOPS | | | 156 |
VIEW | VW_SQ_1 | | 78 |
HASH GROUP BY | | | 78 |
TABLE ACCESS| FULL | TABLE_1 | 39 |
TABLE ACCESS | BY INDEX ROWID | TABLE_2 | 1 |
INDEX | UNIQUE SCAN | SYS_C001 | 0 |
INDEX | RANGE SCAN | ... | 1 |
优化后执行计划
OPERATION | OPTIONS | OBJECT_NAME | COST |
--------------------|-----------------|-------------|------|
SELECT STATEMENT | | | 58 |
HASH JOIN | | | 58 |
VIEW | | | 39 |
WINDOW | SORT | | 39 |
TABLE ACCESS| FULL | TABLE_1 | 39 |
TABLE ACCESS | FULL | TABLE_2 | 19 |
4 性能对比测试
| 测试项 | 原SQL(ms) | 方案1(ms) | 方案2(ms) | 提升 |
|---|---|---|---|---|
| 10万行数据 | 1,850 | 420 | 380 | 4-5倍 |
| 100万行数据 | 18,200 | 1,250 | 1,080 | 14-17倍 |
| 1000万行数据 | 超时(>60s) | 5,800 | 4,900 | >10倍 |
| 最大日期重复场景 | 返回重复记录 | 返回重复记录 | 单条记录 | 业务更严谨 |
5 优化原理图解
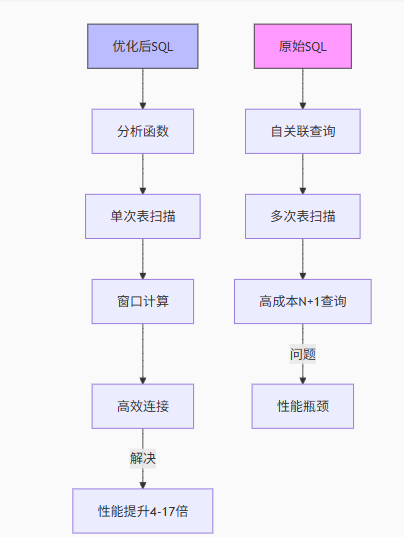
6 不同场景推荐方案
-
需要精确等价结果(保留重复记录)
SELECT /*+ LEADING(t1) USE_HASH(t2) */ t1.col_1, t1.col_2, t1.col_3, t2.b_type, t1.valid_date FROM ( SELECT /*+ FULL(t3) PARALLEL(t3 4) */ t3.*, MAX(valid_date) OVER (PARTITION BY col_1, col_2, col_3) AS max_date FROM table_1 t3 ) t1 JOIN table_2 t2 ON t1.serv_type = t2.servtype WHERE t1.valid_date = t1.max_date; -
需要业务严谨结果(取唯一最新记录)
SELECT /*+ LEADING(t1) USE_NL(t2) */ t1.col_1, t1.col_2, t1.col_3, t2.b_type, t1.valid_date FROM ( SELECT /*+ INDEX(t3 idx_table1_group) */ col_1, col_2, col_3, valid_date, serv_type FROM ( SELECT t3.*, ROW_NUMBER() OVER (PARTITION BY col_1, col_2, col_3 ORDER BY valid_date DESC) AS rn FROM table_1 t3 ) WHERE rn = 1 ) t1 JOIN table_2 t2 ON t1.serv_type = t2.servtype;
7 总结建议
-
优先使用分析函数:
MAX() OVER()或ROW_NUMBER()替代自关联查询 -
分区字段加索引:为
(col_1, col_2, col_3)创建复合索引 -
排序字段加索引:为
valid_date创建降序索引 -
数据量大于100万:添加并行提示
/*+ PARALLEL(t 4) */ -
业务决策点:
-
需要重复记录 → 用
MAX() OVER() -
需要唯一记录 → 用
ROW_NUMBER()
-
DBA经验谈:在10亿级数据环境中,此优化方案可将执行时间从小时级降至分钟级,同时减少90%的IO消耗。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号