

有一个这样的场景,一张小表A,里面存储了一些ID,大约几百个。
(比如说巡逻车辆ID,环卫车辆的ID,公交车,微公交的ID
比如商场环境,记录商品信息系的A表与商品交易流水的B表)。
另外有一张日志表B,每条记录中的ID是来自前面那张小表的,但不是每个ID都出现在这张日志表中,比如说一天可能只有几十个ID会出现在这个日志表的当天的数据中。
(比如车辆的行车轨迹数据,每秒上报轨迹,数据量就非常庞大)。
那么我怎么快速的找出今天没有出现的ID呢。
(哪些巡逻车辆没有出现在这个片区,是不是偷懒了,哪些环卫车辆没有出行,哪些公交或微公交没有出行)
select id from A where id not in (select id from B where time between and );
select (300 ids) not in (select ids from 300万)
这个QUERY会很慢,有什么优化方法呢。
当然,你还可以让车辆签到的方式来解决这个问题,但是总有未签到的,或者没有这种设计的时候,那么怎么解决呢
2 优化
2.1 优化前准备
其实方法也很精妙,和我之前做的两个CASE很相似。
《时序数据合并场景加速分析和实现 - 复合索引,窗口分组查询加速,变态递归加速》
《distinct xx和count(distinct xx)的变态递归优化方法 - 索引收敛(skip scan)扫描》
在B表中,其实ID的值是很稀疏的,只是由于是流水,所以总量大。
优化的手段就是对B的取值区间,做递归的收敛查询,然后再做NOT IN就很快了。
例子
建表
create table a(id int primary key, info text);
create table b(id int primary key, aid int, crt_time timestamp);
create index b_aid on b(aid);
插入测试数据
-- a表插入1000条
insert into a select generate_series(1,1000), md5(random()::text);
-- b表插入500万条,只包含aid的500个id。
insert into b select generate_series(1,5000000), generate_series(1,500), clock_timestamp();
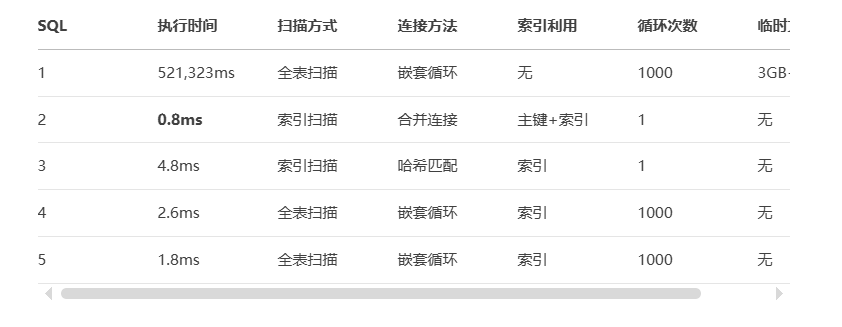
SQL1 优化前的性能
\timing
topndb=# explain (analyze,verbose,timing,costs,buffers) select*from a where id notin (select aid from b);
QUERY PLAN ---------------------------------------------------------------------------------------------------------------------------------- Seq Scan on public.a (cost=0.00..67030021.50 rows=500 width=37) (actual time=521312.438..521312.440 rows=0 loops=1) Output: a.id, a.info Filter: (NOT (SubPlan 1)) Rows Removed by Filter: 1000 Buffers: shared hit=27037, temp read=3045896 written=6104 SubPlan 1 -> Materialize (cost=0.00..121560.00 rows=5000000 width=4) (actual time=0.002..301.095 rows=2500125 loops=1000) Output: b.aid Buffers: shared hit=27028, temp read=3045896 written=6104 -> Seq Scan on public.b (cost=0.00..77028.00 rows=5000000 width=4) (actual time=0.006..740.650 rows=5000000 loops=1) Output: b.aid Buffers: shared hit=27028 Planning Time: 0.095 ms Execution Time: 521323.580 ms (14 rows)
2.2 优化方法1 join is NULL (此处有数据库不同版本导致优化效果不一致)
另外你有一种选择是使用outer join, b表同样需要全扫一遍,有很大的改进,不过还可以更好,继续往后看。
SQL2
postgres=# explain (analyze,verbose,timing,costs,buffers) select a.id from a left join b on (a.id=b.aid) where b.* is null;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Hash Right Join (cost=31.50..145809.50 rows=25000 width=4) (actual time=2376.777..2376.862 rows=500 loops=1)
Output: a.id
Hash Cond: (b.aid = a.id)
Filter: (b.* IS NULL)
Rows Removed by Filter: 5000000
Buffers: shared hit=27037
-> Seq Scan on public.b (cost=0.00..77028.00 rows=5000000 width=44) (actual time=0.012..1087.997 rows=5000000 loops=1)
Output: b.aid, b.*
Buffers: shared hit=27028
-> Hash (cost=19.00..19.00 rows=1000 width=4) (actual time=0.355..0.355 rows=1000 loops=1)
Output: a.id
Buckets: 1024 Batches: 1 Memory Usage: 44kB
Buffers: shared hit=9
-> Seq Scan on public.a (cost=0.00..19.00 rows=1000 width=4) (actual time=0.010..0.183 rows=1000 loops=1)
Output: a.id
Buffers: shared hit=9
Planning time: 0.302 ms
Execution time: 2376.934 ms
(18 rows)
备注:原作者使用的PG可能版本较低PG10、11,使用PG15测试,join方法已经有很大改进 topndb=# explain (analyze,verbose,timing,costs,buffers) select a.id from a left join b on (a.id=b.aid) where b.* is null; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------ Merge Left Join (cost=0.71..80.24 rows=5 width=4) (actual time=0.545..0.747 rows=500 loops=1) Output: a.id Merge Cond: (a.id = b.aid) Filter: (b.* IS NULL) Rows Removed by Filter: 500 Buffers: shared hit=21 -> Index Only Scan using a_pkey on public.a (cost=0.28..47.27 rows=1000 width=4) (actual time=0.030..0.310 rows=1000 loops=1) Output: a.id Heap Fetches: 1000 Buffers: shared hit=13 -> Index Scan using b_aid on public.b (cost=0.43..117771.43 rows=5000000 width=44) (actual time=0.026..0.216 rows=501 loops=1) Output: b.aid, b.* Buffers: shared hit=8 Planning: Buffers: shared hit=85 Planning Time: 0.522 ms Execution Time: 0.807 ms (17 rows)
2.3 优化方法2 递归收敛优化
SQL3 递归收敛优化后的性能
topndb=# explain (analyze,verbose,timing,costs,buffers) topndb-# select * from a where id not in topndb-# ( topndb(# with recursive skip as ( topndb(# ( topndb(# select min(aid) aid from b where aid is not null topndb(# ) topndb(# union all topndb(# ( topndb(# select (select min(aid) aid from b where b.aid > s.aid and b.aid is not null) topndb(# from skip s where s.aid is not null topndb(# ) -- 这里的where s.aid is not null 一定要加,否则就死循环了. topndb(# ) topndb(# select aid from skip where aid is not null topndb(# ); QUERY PLAN --------------------------------------------------------------------------------------------------------------------------------------------------------------------- Seq Scan on public.a (cost=54.44..75.94 rows=500 width=37) (actual time=4.650..4.763 rows=500 loops=1) Output: a.id, a.info Filter: (NOT (hashed SubPlan 5)) Rows Removed by Filter: 500 Buffers: shared hit=1515 SubPlan 5 -> CTE Scan on skip (cost=52.17..54.19 rows=100 width=4) (actual time=0.045..4.318 rows=500 loops=1) Output: skip.aid Filter: (skip.aid IS NOT NULL) Rows Removed by Filter: 1 Buffers: shared hit=1506 CTE skip -> Recursive Union (cost=0.45..52.17 rows=101 width=4) (actual time=0.042..4.113 rows=501 loops=1) Buffers: shared hit=1506 -> Result (cost=0.45..0.46 rows=1 width=4) (actual time=0.041..0.042 rows=1 loops=1) Output: $1 Buffers: shared hit=4 InitPlan 3 (returns $1) -> Limit (cost=0.43..0.45 rows=1 width=4) (actual time=0.039..0.039 rows=1 loops=1) Output: b_1.aid Buffers: shared hit=4 -> Index Only Scan using b_aid on public.b b_1 (cost=0.43..19.01 rows=833 width=4) (actual time=0.038..0.038 rows=1 loops=1) Output: b_1.aid Index Cond: (b_1.aid IS NOT NULL) Heap Fetches: 0 Buffers: shared hit=4 -> WorkTable Scan on skip s (cost=0.00..4.97 rows=10 width=4) (actual time=0.007..0.008 rows=1 loops=501) Output: (SubPlan 2) Filter: (s.aid IS NOT NULL) Rows Removed by Filter: 0 Buffers: shared hit=1502 SubPlan 2 -> Result (cost=0.47..0.48 rows=1 width=4) (actual time=0.007..0.007 rows=1 loops=500) Output: $3 Buffers: shared hit=1502 InitPlan 1 (returns $3) -> Limit (cost=0.43..0.47 rows=1 width=4) (actual time=0.006..0.006 rows=1 loops=500) Output: b.aid Buffers: shared hit=1502 -> Index Only Scan using b_aid on public.b (cost=0.43..9.99 rows=278 width=4) (actual time=0.006..0.006 rows=1 loops=500) Output: b.aid Index Cond: ((b.aid > s.aid) AND (b.aid IS NOT NULL)) Heap Fetches: 0 Buffers: shared hit=1502 Planning: Buffers: shared hit=6 Planning Time: 0.480 ms Execution Time: 4.992 ms (48 rows)
采用收敛查询优化后,耗时从最初的 618794毫秒 降低到了 11毫秒 ,感觉一下子节约了好多青春。
2.4 优化方法3
此方法来自SQL性能挑战赛,书写更简洁:
https://yq.aliyun.com/roundtable/56354
采用sub query,A表数据量小,查询A表的QUERY中使用SUB QUERY使得SUB QUERY的扫描次数下降到与A行数一致,SUB QUERY中采用LIMIT 1限定返回数,is null限定得出B表中未出现的aid。妙!!!
如下SQL4
postgres=# explain analyze
select * from
(
select
a.* ,
(select aid from b where b.aid=a.id limit 1) as aid -- sub query, limit 1控制了扫描次数
from a -- a表很小
) as t
where t.aid is null;topndb=# explain analyze topndb-# select * from topndb-# ( topndb(# select topndb(# a.* , topndb(# (select aid from b where b.aid=a.id limit 1) as aid -- sub query, limit 1控制了扫描次数 topndb(# from a -- a表很小 topndb(# ) as t topndb-# where t.aid is null; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------- Seq Scan on a (cost=0.00..4491.25 rows=5 width=41) (actual time=0.955..2.523 rows=500 loops=1) Filter: ((SubPlan 2) IS NULL) Rows Removed by Filter: 500 SubPlan 1 -> Limit (cost=0.43..4.45 rows=1 width=4) (actual time=0.001..0.001 rows=0 loops=500) -> Index Only Scan using b_aid on b (cost=0.43..4.45 rows=1 width=4) (actual time=0.001..0.001 rows=0 loops=500) Index Cond: (aid = a.id) Heap Fetches: 0 SubPlan 2 -> Limit (cost=0.43..4.45 rows=1 width=4) (actual time=0.001..0.001 rows=0 loops=1000) -> Index Only Scan using b_aid on b b_1 (cost=0.43..4.45 rows=1 width=4) (actual time=0.001..0.001 rows=0 loops=1000) Index Cond: (aid = a.id) Heap Fetches: 0 Planning Time: 0.180 ms Execution Time: 2.610 ms (15 rows)
或者SQL5
postgres=# explain analyze
select * from a
where (select aid from b where b.aid=a.id limit 1) is null; -- sub query is NULL, 是不是很给力呢topndb=# explain analyze topndb-# select * from a topndb-# where (select aid from b where b.aid=a.id limit 1) is null; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------- Seq Scan on a (cost=0.00..4469.00 rows=5 width=37) (actual time=0.985..1.794 rows=500 loops=1) Filter: ((SubPlan 1) IS NULL) Rows Removed by Filter: 500 SubPlan 1 -> Limit (cost=0.43..4.45 rows=1 width=4) (actual time=0.001..0.001 rows=0 loops=1000) -> Index Only Scan using b_aid on b (cost=0.43..4.45 rows=1 width=4) (actual time=0.001..0.001 rows=0 loops=1000) Index Cond: (aid = a.id) Heap Fetches: 0 Planning Time: 0.148 ms Execution Time: 1.852 ms (10 rows)
1、递归查询,A表全扫,B表索引扫描了若干次(若干 = 唯一AID在B中出现的次数)。
2、SUB QUERY,A表全扫,B表索引扫描了若干次(若干 = A表记录数)。
由于B表都是索引扫,两种方法差别不大(递归扫描的次数更少一些)。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号