

一、现象
1、数据库配置
云数据库8核32G,存储300G
2、问题时间
2024-10-11号到2024-10-12号早上9:00至9:10,会出现数据库卡顿现象,且业务端报错。
且11-12号有促销活动。
3、问题现象
1)CPU跑满

2)MEM稍有增加
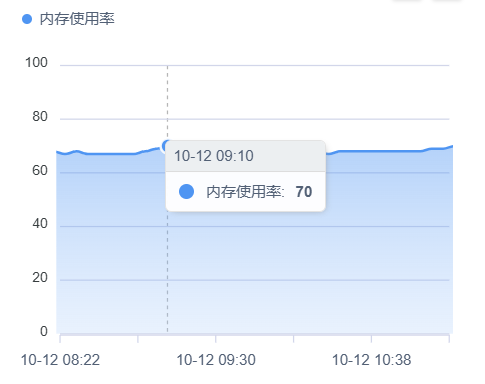
3)IO使用率降低

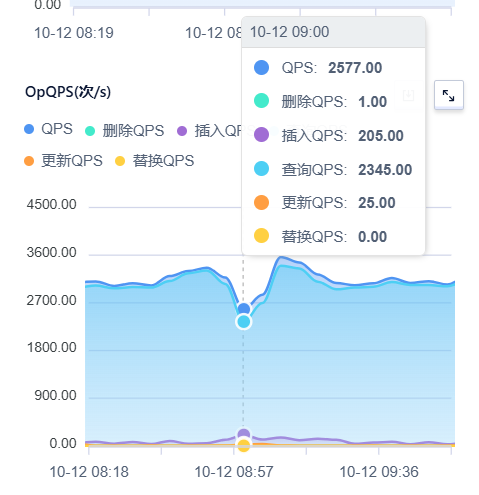
4)QPS insert、update增加较多
5)globalLock(个) 读lock超过128个

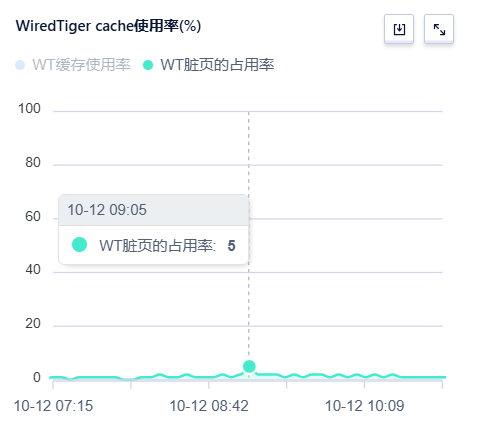
6)刷脏 脏页占比达到5%
4、业务报错
二、问题分析
1、通过慢日志与错误日志分析
CPU跑满时间点,部分SQL执行时长超过1s,平时小于500ms
错误日志中有大量没有运行成功的SQL
2、通过监控分析
1)CPU跑满,一般并发过高,业务过大,超过CPU承受度
2)QPS中,insert、update、delete都增加了,但是查询却降低了
促销活动带来的业务流量突增,导致系统资源吃紧。数据库实例刷脏过程中,读请求延时等待
3)globalLock :当前都队列过高
3、globalLock说明
serverStatus.globalLock 或者 mongostat (qr|qw ar|aw指标)能查看mongod globalLock的各个指标情况。
- Wiredtiger限制传递到引擎层面的最大读写并发数均为128(合理的经验值,通常无需调整),如果超过这个阈值,排队的请求就会体现在globalLock.currentQueue.readers/writers里。
- 如果globalLock.currentQueue.readers/writers个值长时间都不为0(此时globalLock.activeClients.readers/writers肯定是持续接近或等于128的),说明你的系统并发太高(或者有长时间占用互斥锁的请求比如前台建索引),可以通过优化单个请求的处理时间(比如建索引来减少COLLSCAN或SORT),或升级后端资源(内存、磁盘IO能力、CPU)来优化。
- globalLock.activeClients.readers/writers 持续不为0(但没达到128,此时currentQueue为空),并且你觉得请求处理已经很慢了,这时也可以考虑2中提到的优化方法。
三、总结
本次由于促销,问题时间范围业务量变大,导致脏数据变多,在刷脏过程中导出查询卡顿且并发降低
部分整理自:
https://www.jianshu.com/p/c72b2110c79d
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号