

FlinkSQL CDC 测试
原创文章,转载请标明出处:https://www.cnblogs.com/xibuhaohao/articles/15312233.html
零、FlinkSQL CDC 2.0简介
1、常见开源CDC方案比较

2、 flink cdc 2.0解决痛点

一、工具准备
1、ETL工具flink-1.13.2
1)flink:
flink-1.13.2
下载地址:
flink connector 都放到flink 的 lib 目录下
2)flinksql cdc 2:
flink-format-changelog-json-2.0.1.jar
flink-sql-connector-mysql-cdc-2.0.1.jar
flink-sql-connector-postgres-cdc-2.0.1.jar
FlinkSQL CDC 2.0下载地址:
Release Release 2.0.1 · ververica/flink-cdc-connectors · GitHub
3)flink jdbc :
flink-connector-jdbc_2.11-1.12.3.jar (版本符合1.12.3与测试的flink1.13.2版本不符合,使用报错)
flink-connector-jdbc_2.11-1.13.2.jar
Apache Flink 1.12 Documentation: JDBC SQL Connector
https://repo.maven.apache.org/maven2/org/apache/flink/flink-connector-jdbc_2.11
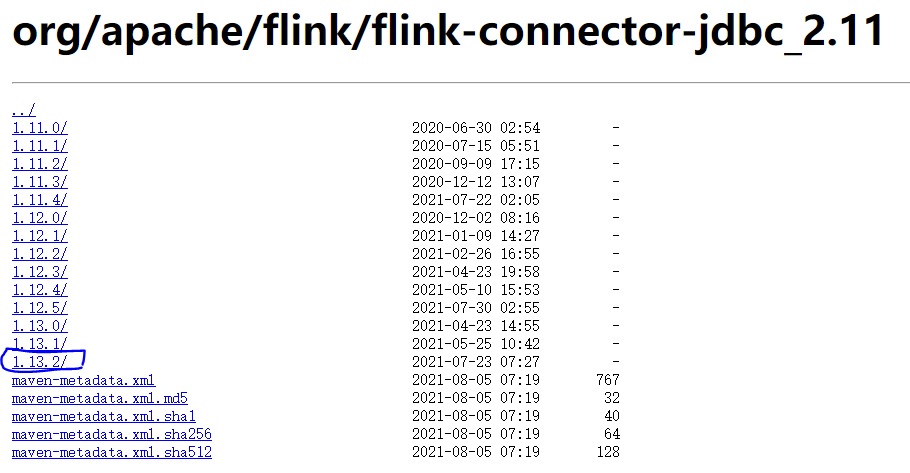
4)elasticsearch
flink-sql-connector-elasticsearch7_2.11-1.13.2.jar
https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-elasticsearch7_2.11

2、OLTP关系数据库
1)MySQL5.7.34 RPM安装
MySQL5.7.34下载地址:
https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.34-1.el7.x86_64.rpm-bundle.tar
注意:
在使用CDC之前务必要开启MySQl的binlog。下面以MySQL 5.7版本为例说明
log-bin=mysql-bin
server-id=1
binlog_format=ROW
expire_logs_days=302)PostgreSQL13.4
PostgreSQL13.4下载地址
RepoView: PostgreSQL PGDG 13 Updates RPMs
3、OLAP数据库
Clickhouse21.8.5.7
Release v21.8.5.7-lts · ClickHouse/ClickHouse · GitHub
4、NOSQL数据库
Elasticsearch:Version:7.14.1
Download Elasticsearch Free | Get Started Now | Elastic | Elastic
5、kafka分布式发布订阅消息系统
https://dlcdn.apache.org/kafka/2.8.0/kafka_2.12-2.8.0.tgz
flink-connector-kafka_2.12-1.13.2.jar
6、flink1.13.2 安装与配置开机自启动
注意:
在使用flink sql 前一定要开启 flink。
在flink未开启的情况下,可以用flink sql 操作建表等,比如:创建mysql-cdc的表,但是,无法查询表的数据,因为未开启flink。
自启动配置:
[root@flinkdb01 system]# cat flink.service
Description=flink.service
After=network.target
ConditionPathExists=/u01/soft/flink/flink-1.13.2/conf/flink-conf.yaml
[Service]
Type=forking
User=root
Group=root
ExecStart=/u01/soft/flink/flink-1.13.2/bin/start-cluster.sh
ExecStop=/u01/soft/flink/flink-1.13.2/bin/stop-cluster.sh
Restart=no
PrivateTmp=true
[Install]
WantedBy=default.target
设置开机自启
systemctl daemon-reload
systemctl enable flink.service
开启flink
systemctl start flink.service
systemctl status flink.service
7、flink1.13.2 web
开启web页面端口
vim flink-conf.yaml
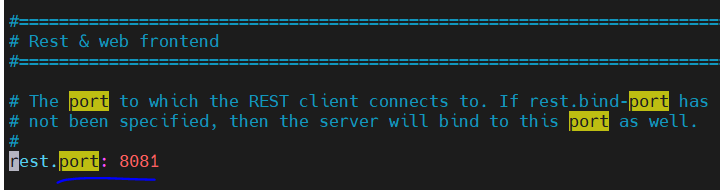
访问
二、flink sql cdc2 同步MySQL 写入MySQL案例
1、mysql建表语句(明细表、维度表)
新建数据库inventory
create database inventory;
新建表products,company作为cdc同步表
新建表result作为products,company join后结果存放的表
CREATE TABLE `products` (
`id` int NOT NULL,
`name` varchar(45) DEFAULT NULL,
`description` varchar(45) DEFAULT NULL,
`weight` decimal(10,3) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `company` (
`id` int NOT NULL,
`company` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `result` (
`id` int NOT NULL,
`name` varchar(45) DEFAULT NULL,
`description` varchar(45) DEFAULT NULL,
`weight` decimal(10,3) DEFAULT NULL,
`company` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
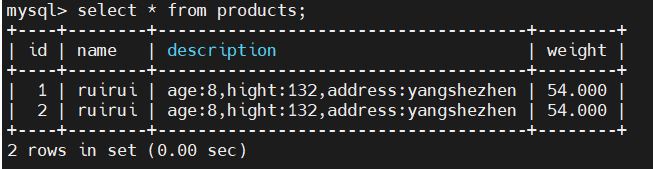
2、MySQL写入测试数据
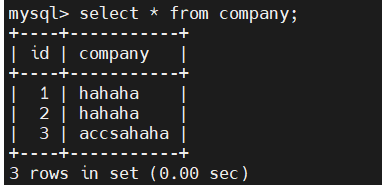
3、flinksql建表语句(同步MySQL维度表、明细表)
创建测试DB
create database inventory;
use inventory;
-- creates a mysql cdc table source
--同步products表
注意:建表的时候需要设置主键,可以MySQL结构设置,否则会报错,或者通过修改参数,可以不加主键
CREATE TABLE products (
id INT NOT NULL PRIMARY key ,
name STRING,
description STRING,
weight DECIMAL(10,3)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.2.100',
'port' = '3306',
'username' = 'root',
'password' = 'sg123456',
'database-name' = 'inventory',
'table-name' = 'products'
);
--同步company表
CREATE TABLE company(
id INT NOT NULL PRIMARY key ,
company STRING
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.2.100',
'port' = '3306',
'username' = 'root',
'password' = 'sg123456',
'database-name' = 'inventory',
'table-name' = 'company'
);
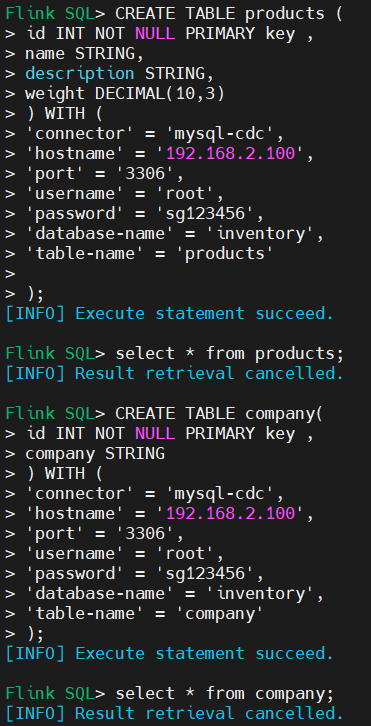
4、验证同步结果
Flink SQL> select * from products;

Flink SQL> select * from company;

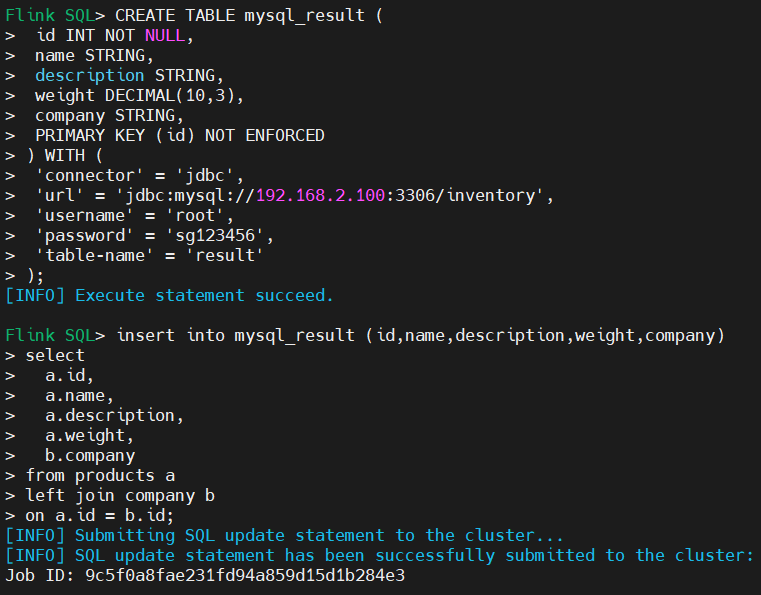
5、flink创建结果表同步到MySQL
--存放join之后结果的表,注意建表时必须指定主键,不然会报错
CREATE TABLE mysql_result (
id INT NOT NULL,
name STRING,
description STRING,
weight DECIMAL(10,3),
company STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.2.100:3306/inventory',
'username' = 'root',
'password' = 'sg123456',
'table-name' = 'result'
);
insert into mysql_result (id,name,description,weight,company)
select
a.id,
a.name,
a.description,
a.weight,
b.company
from products a
left join company b
on a.id = b.id;
1)版本不符合,建表成功,但是写入数据报错

报错:
[ERROR] Could not execute SQL statement. Reason:
java.lang.NoSuchMethodError: org.apache.flink.table.factories.DynamicTableFactory$Context.getCatalogTable()Lorg/apache/flink/table/catalog/CatalogTable;
原因:
flink-connector-jdbc_2.11-1.12.3.jar版本与flink1.13 版本不一致
参考:(7条消息) 编写Flink入门代码报出java.lang.NoSuchMethodError,解决建议。_鹿儿跳阿跳阿跳的博客-CSDN博客
2)更换jdbc连接器后建表成功,写入数据成功,但是查询报错
原因:
查询表错误,应该查询MySQL中的表,而不是查询flink中的表
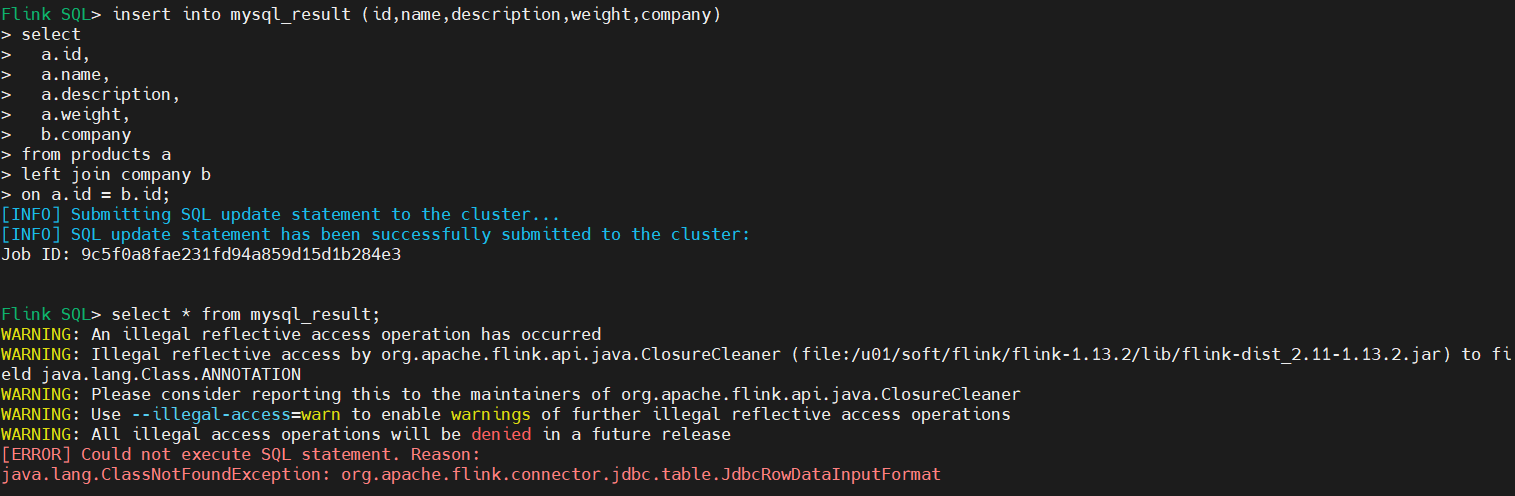
3)查询MySQL验证是否将flink数据同步到MySQL
可以看到数据已经同步:
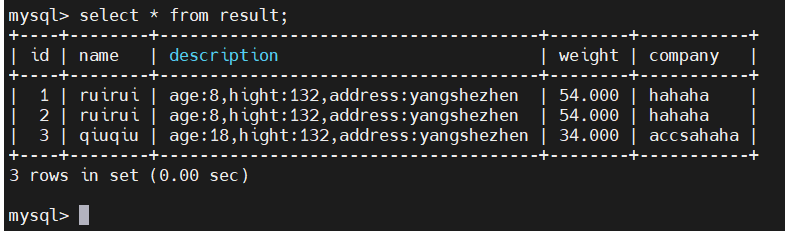
6、insert MySQL数据,看是否支持增量insert 同步

7、update MySQL数据,看是否支持增量update同步
通过测试:flink cdc 2.0 支持 update 操作
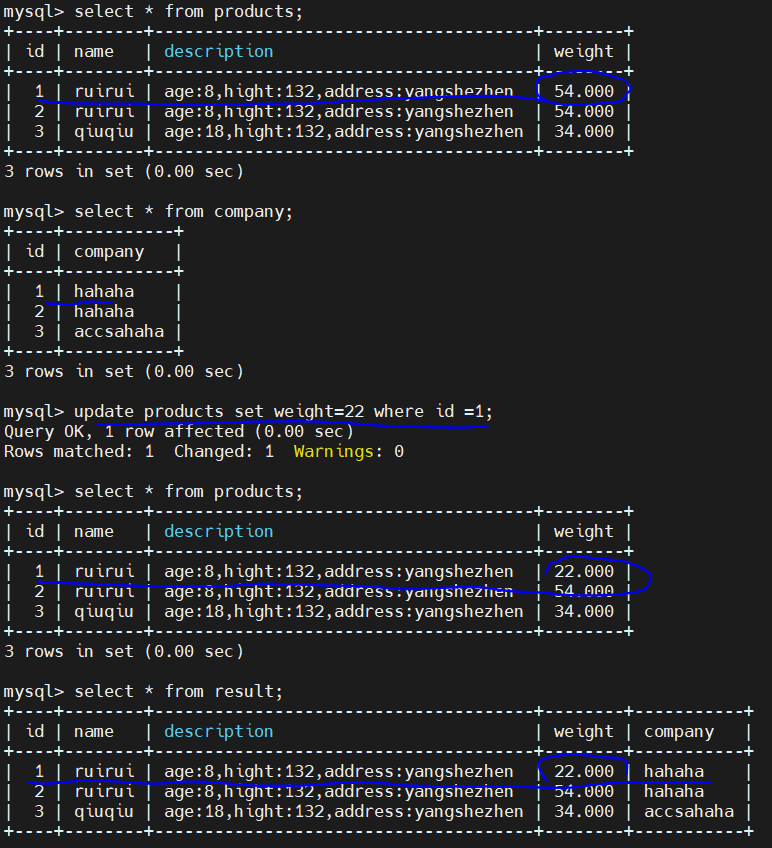
8、delete MySQL数据,看是否支持增量delete 同步

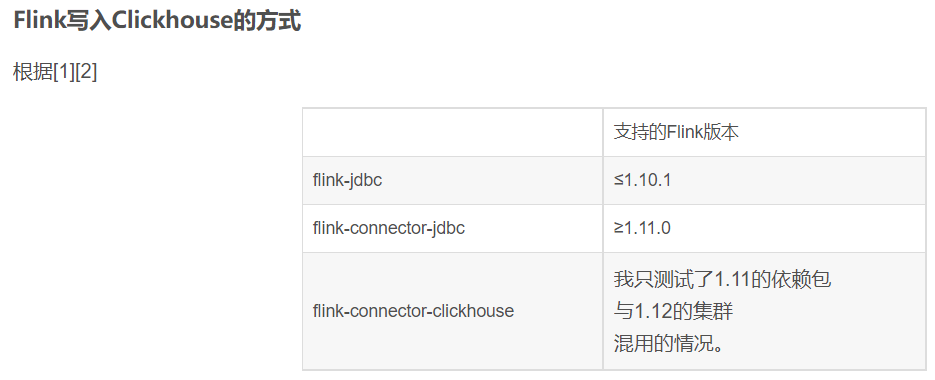
三、flink sql cdc2 同步MySQL 写入Clickhouse案例
四、flink sql cdc2 同步MySQL 写入ElasticSearch7案例
1、安装es
ERROR: [3] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
解决办法:
编辑 /etc/security/limits.conf,追加以下内容;
* soft nofile 65536
* hard nofile 65536
此文件修改后需要重新登录用户,才会生效
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:
编辑 /etc/sysctl.conf,追加以下内容:
vm.max_map_count=655360
保存后,执行:
sysctl -p
[3]: max number of threads [2048] for user [tongtech] is too low, increase to at least [4096]
错误原因:启动检查未通过
elasticsearch用户的最大线程数太低
解决办法:
vim /etc/security/limits.d/90-nproc.conf
将2048改为4096或更大
[4]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
解决办法:
修改
elasticsearch.yml
取消注释保留一个节点
cluster.initial_master_nodes: ["node-1"]
这个的话,这里的node-1是上面一个默认的记得打开就可以了
2、flink创建结果表
--elasticsearch
CREATE TABLE res_es1 (
id INT NOT NULL,
name STRING,
description STRING,
weight DECIMAL(10,3),
company STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://192.168.2.103:9200',
'index' = 'res_es1'
);
3、flink创建结果表同步到elasticsearch
insert into res_es1 (id,name,description,weight,company)
select
a.id,
a.name,
a.description,
a.weight,
b.company
from products a
left join company b
on a.id = b.id;
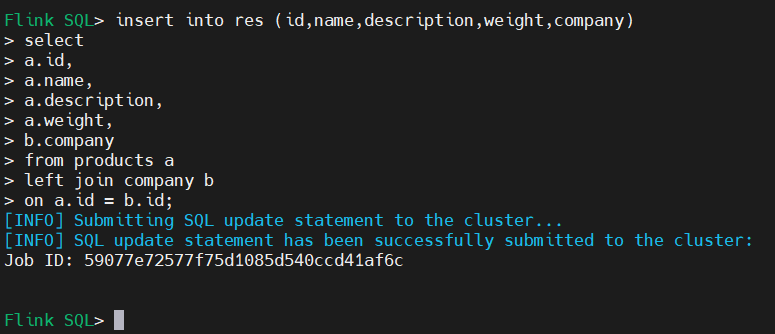
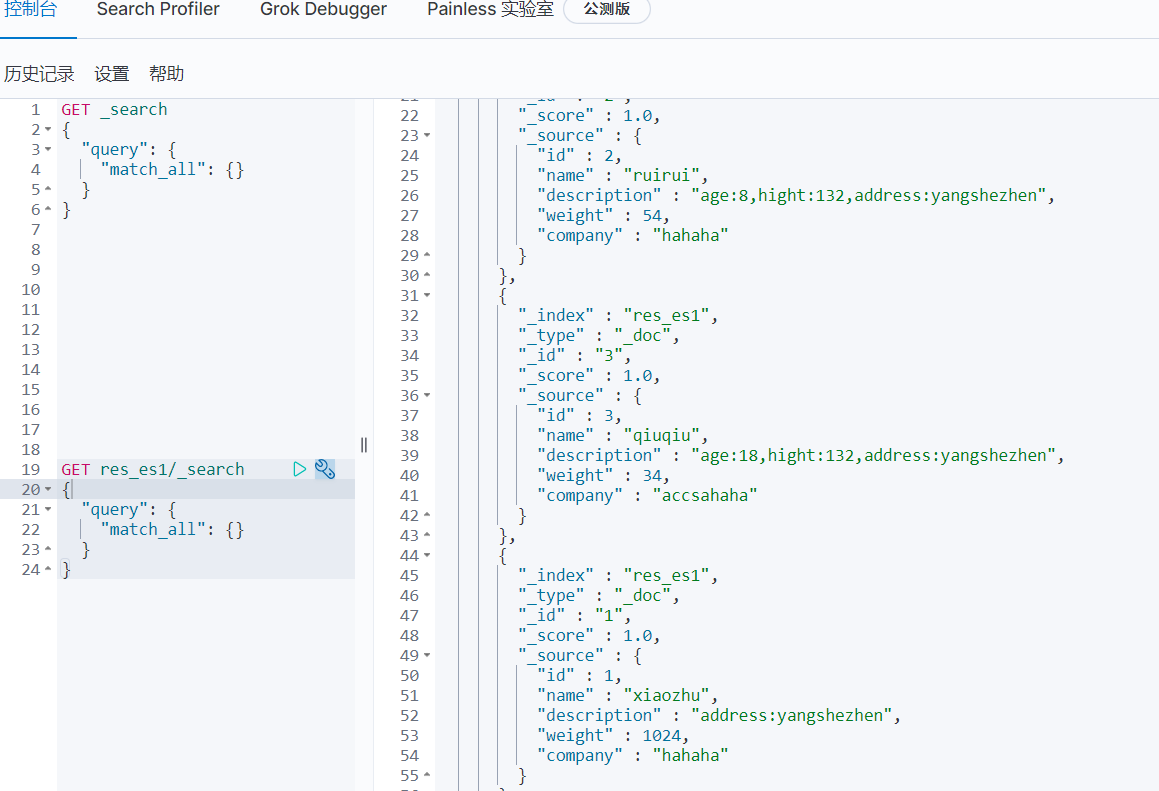
4、通过查询es验证
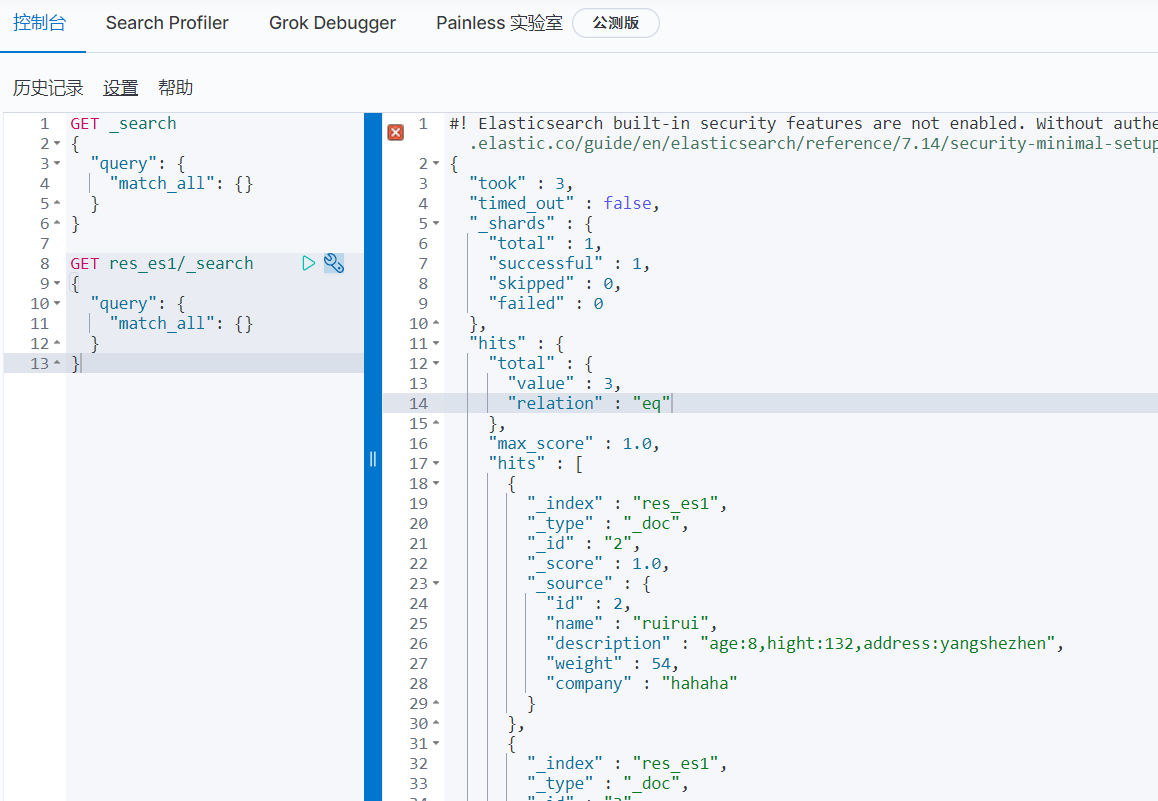
5、insert MySQL数据,看是否支持增量insert 同步
1)MySQL插入新数据id=10
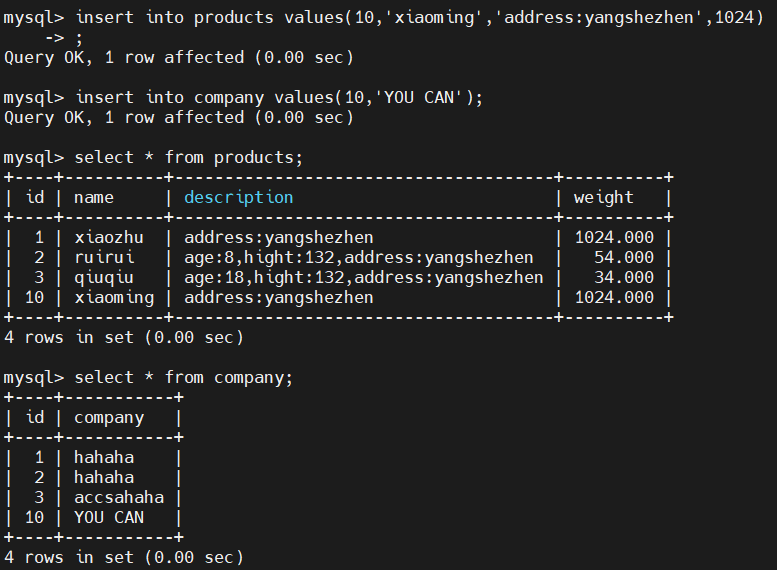
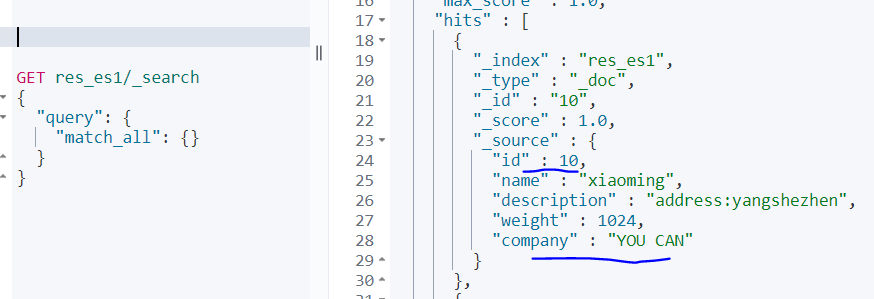
2)查看es
可以看到支持insert 新增
6、update MySQL数据,看是否支持增量update同步
1)MySQL更新id=10的数据
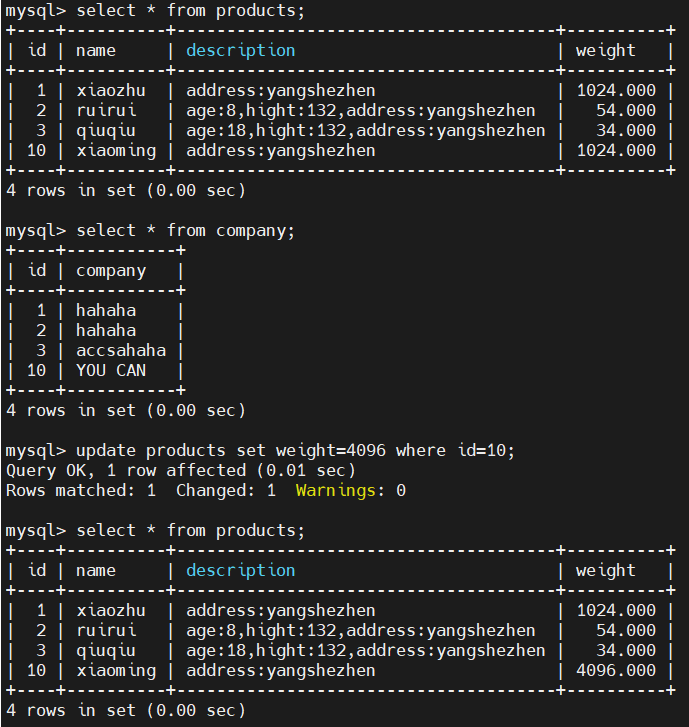
2)查看es
可以看到支持update新增
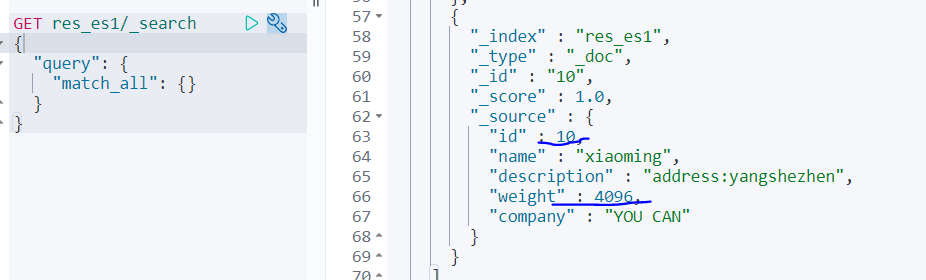
7、delete MySQL数据,看是否支持增量delete同步
1)MySQL删除id=10的数据
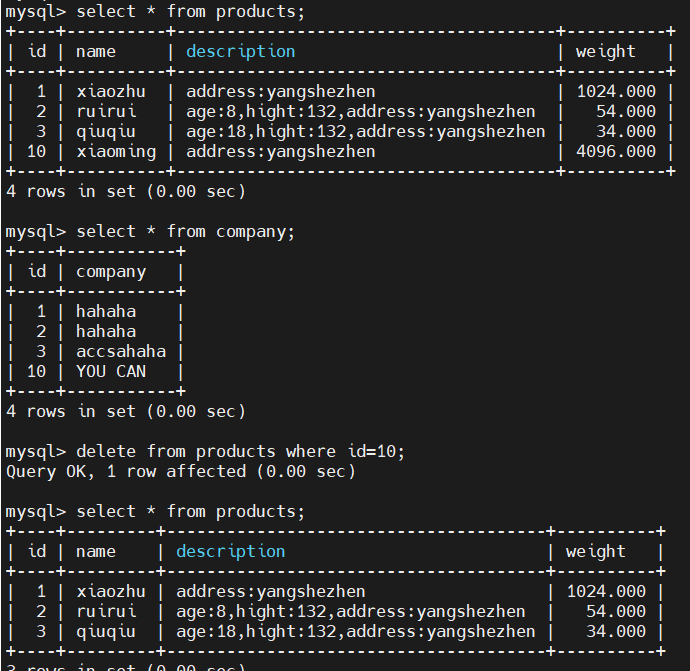
2)查看es
可以看到支持delete删除操作
五、flink sql cdc2 同步MySQL 写入Kafka案例
1、kafka 安装
Kafka集群安装需要依赖zookeeper
0)安装角色划分
zookeeper:2181
Kafka01:9091
Kafka02:9092
Kafka03:9093
kafka图形化工具:kafka tool
1)安装zookeeper
配置自启动
[root@flinkdb02 system]# cat /etc/systemd/system/zookeeper.service
Description=zookeeper.service
After=network.target
ConditionPathExists=/u01/soft/zookeeper/apache-zookeeper-3.7.0-bin/conf/zoo.cfg
[Service]
Type=forking
User=root
Group=root
ExecStart=/u01/soft/zookeeper/apache-zookeeper-3.7.0-bin/bin/zkServer.sh start
ExecStop=/u01/soft/zookeeper/apache-zookeeper-3.7.0-bin/bin/zkServer.sh stop
ExecReload=/u01/soft/zookeeper/apache-zookeeper-3.7.0-bin/bin/zkServer.sh restart
Restart=no
PrivateTmp=true
[Install]
WantedBy=default.target
2)安装Kafka
解压后,将kafka解压文件复制两份,并把这三份文件命名为:
/u01/soft/kafka/kafka01
/u01/soft/kafka/kafka02
/u01/soft/kafka/kafka03
服务器重启后,kafka三个节点启动报错:

解决方法一:
关闭kafka集群所有节点,把logs_dir内容清空后,在把集群启动,则不会报错。但是每次服务器重启后,还是会报出相同错误。
解决方法二:

zookeeper默认dataDir目录由默认的/tmp目录,修改为固定目录,变更后,服务器重启则不再报错(/tmp目录每次重启后,目录中的数据都会被重置)。
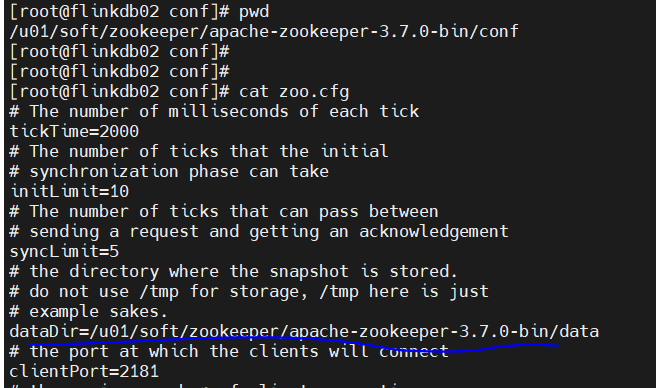
自启动配置
[root@flinkdb02 system]# cat /etc/systemd/system/kafka01.service
[Unit]
Description=Apache kafka service
After=network.target
After=kafka.service
[Service]
Type=forking
User=root
Group=root
ExecStart=/u01/soft/kafka/kafka01/bin/kafka-server-start.sh -daemon /u01/soft/kafka/kafka01/config/server.properties
Restart=no
PrivateTmp=true
[Install]
WantedBy=default.target
3)关键配置如下
| name | 含义 | 举例 |
|---|---|---|
| broker.id | 一个Kafka节点就是一个Broker.id,要保证唯一性 | broker.id=0 |
| listeners | kafka只面向内网时用到listeners,内外网需要作区分时才需要用到advertised.listeners | listeners=PLAINTEXT://192.168.2.103:9091 |
| zookeeper.connect | 配置zk集群信息 | zookeeper.connect=192.168.2.103:2181 |
kafka01-03 配置文件:
/u01/soft/kafka/kafka01/config/server01.properties
/u01/soft/kafka/kafka02/config/server01.properties
/u01/soft/kafka/kafka03/config/server01.properties
4)测试Kafka
生产topic数据:
kafka-console-producer.sh --topic quickstart-events --bootstrap-server 192.168.2.103:9091,192.168.2.103:9092,192.168.2.103:9093

查看topic数据信息:
kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server 192.168.2.103:9091,192.168.2.19092,192.168.2.103:9093

查看数据存储路径
2、flink同步kafka数据或将数据写入kafka说明
1 )前言(消息更新模式)
阅读之前可以先了解一下,动态table转换成data stream的3种模式,这个在动态Table转换成DataStream或者写入外部系统的时候是有严格的约束的。
Append Mode
一个只有Insert操作的动态表,才能转换成Append-only stream(或写入到支持AppendMode的外部系统如:文件、Kafka、Hive等)
Retract Mode
这种模式有2种类型的消息:add 和 retract
通常 insert操作被视为add消息
delete操作被视为 retract消息
update操作被视为先retract后add的消息
Upsert Mode
这种模式也将消息分成2类:upsert 和 delete
通常Insert和update的操作被堪称Upsert消息
Delete操作被看成Delete消息
通常能转换成Append DataStream的 Table都适用于其它2种更新模式
2) kafka连接器分类
Flink支持对kafka的Source 和 Sink,Flink1.12版本的Flink SQL支持2种kafka连接器。
(regular) Kafka
append only的连接器
这种连接器支持 unbounded source scan & streaming sink 【append】
Upsert Kafka
upsert-的连接器(upsert代表insert/update)
upsert-kafka connector提供了changelog stream
每条record代表一个update或delete的Event
必须指定一个primary key
#1、upsert-kafka作为Source的时候
Flink连接产生的stream是一个 chenge log stream,每来一条record消息,如果消息的key已经存在过,那么就update进行覆盖,如果不存在过那么就是insert,如果消息的value为空,且之前key已经存在,那么就是delete删除。
#2、upsert-kafka作为Sink的时候
upsert-kafka能消费Flink中的一个 chenge log stream
insert/update_after的消息作为普通的kafka message写入到kafka,delete操作的消息将会以value为null的形式写入到kafka,Flink将通过对primary key列的值进行分区,来保证消息在primary key上的排序,所以update/delete拥有相同key的message会被分配到相同的partition
作为Sink的时候,必须在DDL上指定primary key
3、读取MySQL数据同步至kafka并将计算(关联)结果写入MySQL
1)创建flink同步MySQL表
create database inventory;
use inventory;
--同步products 表
CREATE TABLE products (
id INT NOT NULL PRIMARY key ,
name STRING,
description STRING,
weight DECIMAL(10,3)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.2.100',
'port' = '3306',
'username' = 'root',
'password' = 'sg123456',
'database-name' = 'inventory',
'table-name' = 'products'
);
--同步company表
CREATE TABLE company (
id INT NOT NULL PRIMARY key ,
company STRING
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.2.100',
'port' = '3306',
'username' = 'root',
'password' = 'sg123456',
'database-name' = 'inventory',
'table-name' = 'company'
);
select * from products ;
select * from company ;
2)创建flink kafka表,用于接收同步数据
CREATE TABLE pageviews_per_region (
id INT NOT NULL,
name STRING,
description STRING,
weight DECIMAL(10,3),
company STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'pageviews_per_region',
'properties.bootstrap.servers' = 'flinkdb02:9091,flinkdb02:9092,flinkdb02:9093',
'key.format' = 'json',
'value.format' = 'json',
'value.json.fail-on-missing-field' = 'false'
);
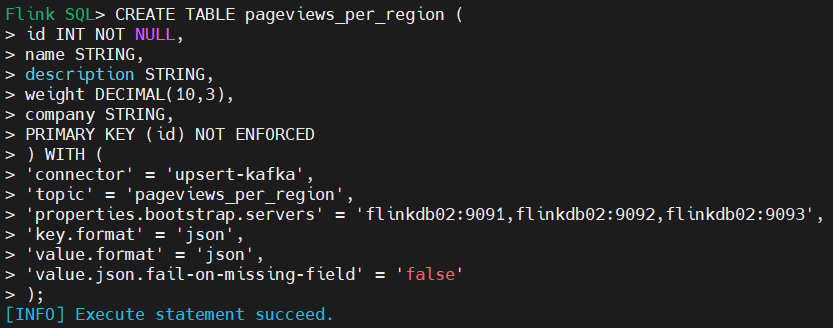
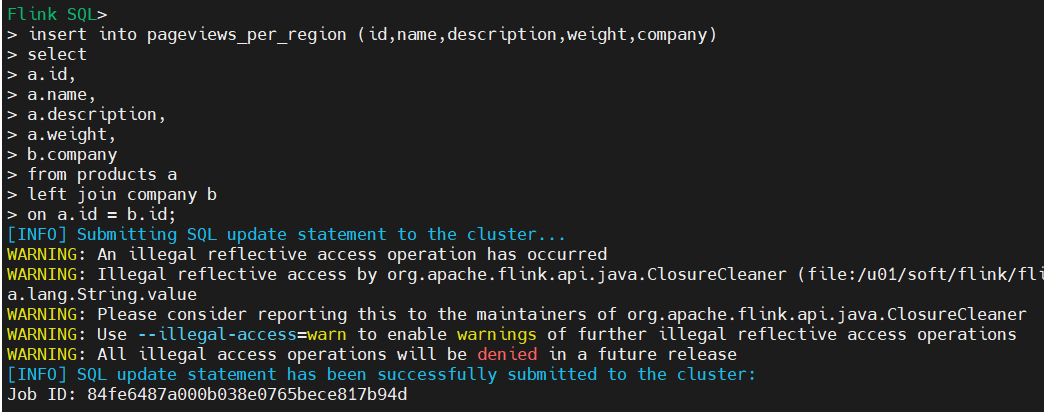
3)将数据同步至pageviews_per_region
insert into pageviews_per_region (id,name,description,weight,company)
select
a.id,
a.name,
a.description,
a.weight,
b.company
from products a
left join company b
on a.id = b.id;
4)查看kafka topic
[root@flinkdb02 system]# kafka-topics.sh --list --zookeeper 192.168.2.103:2181
pageviews_per_region
[root@flinkdb02 system]# kafka-topics.sh --describe --zookeeper 192.168.2.103:2181 --topic pageviews_per_region
Topic: pageviews_per_region TopicId: 0hvV87UYTNKUYJzURkLz9Q PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: pageviews_per_region Partition: 0 Leader: 0 Replicas: 0 Isr: 0
[root@flinkdb02 system]#
5)查看kafka topic数据
查看kafka中的topic:
kafka-topics.sh --list --zookeeper 192.168.2.103:2181

查看topic信息:
kafka-topics.sh --describe --zookeeper 192.168.2.103:2181 --topic pageviews_per_region

创建topic数据:
flink已经创建 pageviews_per_region
kafka-topics.sh --create --topic pageviews_per_region --bootstrap-server 192.168.2.103:9091,192.168.2.103:9092,192.168.2.103:9093
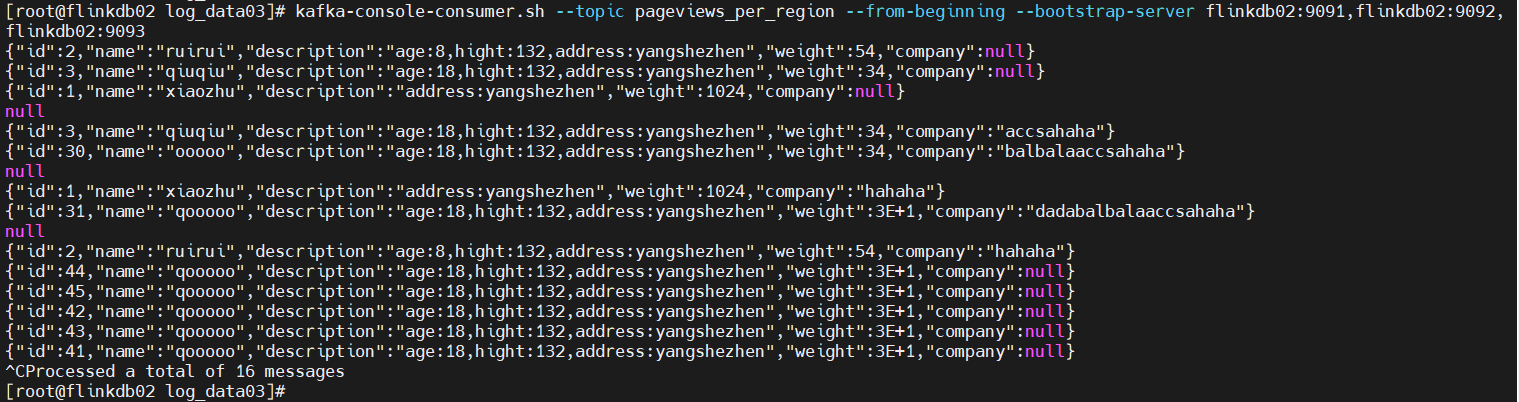
查看topic数据:
kafka-console-consumer.sh --topic pageviews_per_region --from-beginning --bootstrap-server 192.168.2.103:9091,192.168.2.103:9092,192.168.2.103:9093
或着
kafka-console-consumer.sh --topic pageviews_per_region --from-beginning --bootstrap-server flinkdb02:9091,flinkdb02:9092,flinkdb02:9093
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号