深度学习在计算机视觉中的应用
Q1:卷积深经网络有什么特性?
- 平移不变性(translation invariant):卷积神经网络学习到的模式具有平移不变性,即卷积神经网络在图像中右下角学习到某个模式之后,它可以在任何地方识别这个模式,比如左上角。视觉空间从根本上也具有平移不变性。
- 卷积神经网络可以学习到模式的空间层次结构。如下图1所示:第一层学习到的是较小的局部模式(比如边缘),第二层学到的是由第一层特征组成较大的模式,越往上学习到的越复杂、越抽象的视觉概念
![]()
- 卷积层和密集连接层(比如之前学到的BP神经网络)不同的是:卷积层学习到的是局部的模式,学到的就是输入图像在特定尺寸的窗口中的模式;而密集连接层学习到的是全局的模式,全局模式是针对所有像素点的模式。

Q2:响应图(特征图)
 举个例子,这个单个过滤器可以是垂直边缘检测器或者水平边缘检测器,检测输入图像中的水平/垂直边缘。
举个例子,这个单个过滤器可以是垂直边缘检测器或者水平边缘检测器,检测输入图像中的水平/垂直边缘。
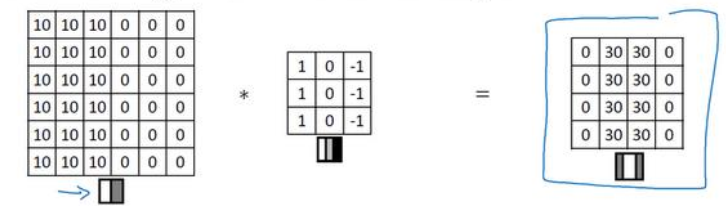 图3、垂直边缘检测,中间是垂直边缘检测滤波器
图3、垂直边缘检测,中间是垂直边缘检测滤波器
Q3、卷积的工作原理
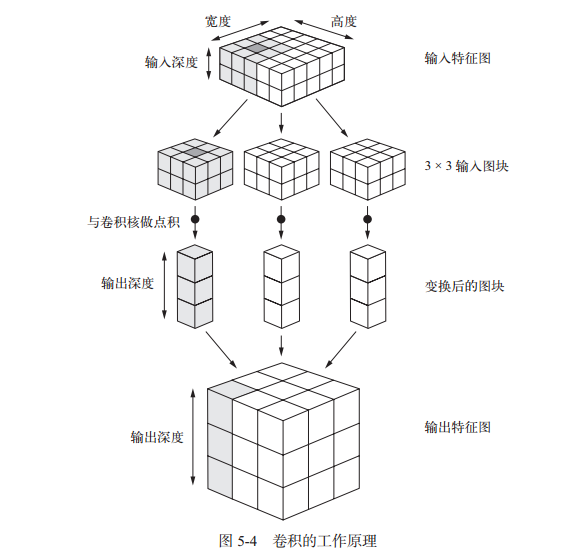
注:卷积滤波器的深度与输入特征图的深度相同;输出特征图的深度与卷积滤波器的数量相同。
Q4、填充(Padding)的作用?
填充是在输入特征图的每一边添加适当数目的行和列,使得每个输入方块都能作为卷积窗口的中心。
- 填充避免了每次执行卷积后,输出图像缩小。
- 避免了图像边缘的像素点只是用了一次,导致图像边缘的大部分信息丢失,如下图绿色阴影方块。
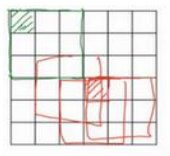
在大多数的深度学习框架中,可以通过设置padding参数来设置填充,这个参数有两个取值:“valid”表示不填充,只使用有效的窗口位置;“same”表示填充后输出特征图的宽度和高度与输入相同。padding参数默认为“valid”。
Q5、步幅stride
步幅stride可以影响输出特征图的尺寸,表示为两个连续窗口的中心方块间的距离。当步幅大于1时,称为步进卷积
Q6、最大池化运算(MaxPooling)
最大池化是从输入特征图中提取窗口,并输出每个通道的最大值。
最大池化常使用2×2的窗口和步幅2,结果输出特征图的尺寸减半,将特征图下采样2倍(特征图的宽度和高度都做了2倍下采样)
那为什么要引入MaxPooling?
①、如果不利用MaxPooling进行下采样,那么需要处理的特征图中的元素个数会很多。之后接上全连接层以后,训练的参数过多,会导致过拟合。
②、下采样之后,通过让连续卷积层的观察窗口越来越大(即窗口覆盖原始输入图像的比例越来越大)。
给出DEEPLIZARD上的解释:
①、减少计算负荷:最大池化降低了给定的卷积层输出的分辨率(输出的特征图的尺寸减少了),网络将一次看到更大的图像区域,从而减少了网络中的参数数量,从而减少了计算量。
②、减少过拟合:最大池化也可能有助于减少过拟合。对于一个特定的图像,我们的网络将寻找一些特定的特征。卷积层的输出可以看作是某些特征的集合,如边缘、曲线、圆圈等等。从卷积层的输出,我们可以认为是高值像素是最活跃的。
当我们从卷积输出中遍历每个区域时,我们能够选择最活跃的像素并保持这些高值,同时丢弃那些没有激活的低值像素。最大化运算的实际作用就是,如果存在某个特征,那么保留其最大值;如果没有提取到这个特征,即最大值也很小。
作者:Ryanjie
出处:http://www.cnblogs.com/ryanjan/
本文版权归作者和博客园所有,欢迎转载。转载请在留言板处留言给我,且在文章标明原文链接,谢谢!
如果您觉得本篇博文对您有所收获,觉得我还算用心,请点击右下角的 [推荐],谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号