
什么是归一化和标准化
归一化(Rescaling,max-min normalization,有的翻译为离差标准化)是指将数据缩放到[0,1]范围内,公式如下:
X' = [X - min(X)] / [max(X) - min(X)]
标准化(Standardization, Z-score normalization,后者翻译为标准分)是指在不改变数据分布情况下,将数据处理为均值为0,标准差为1的数据集合。公式如下:
X' = [X - mean(X)] / δ
标准化的公式很眼熟,则不就是正态分布N(μ,δ) ~ N(0, 1)的公式吗?
X' = (X - μ) / δ
注意标准化的公式并不局限于正态分布,任何分布都可以通过标准化将数据分布变为均值为0,方差为1的数据序列。
注:
1. 中心化,是部分标准化:X' = X - mean(X),比如PCA就需要对数据首先进行中心化处理之后,得到的数据才能比较好的描述主成分。
2. normalization被翻译为正规化。有的博客和文章写作正则化(regularization)笑笑就好了。
区别和用途
归一化和标准化虽然都是在保持数据分布不变的情况下(为什么能够保持数据的分布不变?因为两者本质上都只是对数据进行线性变化),对数据进行处理,但是从公式上面还是能够明显看出来,归一化的处理只是和最大值最小值相关,标准化却是和数据的分布相关(均值,方差),所以标准化的统计意义更强,是是对于数据缩放处理的首选。只是有些特殊场景下,比如需要数据缩放到[0,1]之间(标准化并不保证数据范围),以及在一些稀疏数据场景,想要保留0值,会采用到归一化,其他的大部分时候,标准化是首选。
为什么需要标准化?
让数据因为量纲不一致导致的数据差别较大情况有所收敛。为什么量纲不一致会导致问题?如果一个特征的A的值分布式在[0, 1],另外一个特征B的分布是在[100, 10000],那么在进行梯度下降调试参数的时候,明显对于B特征的参数的修改造成的改动要强于A特征,但是在显示意义可能并不是如此。
另外,在梯度下降的时候,对于数据进行求解梯度,如果数据是在同一个量纲之下,形成的将会是类似于规则的,等距的数据簇(比如低维空间圆形,球形等),这个时候,梯度下降是最快的(变化率最快的方向),因为梯度的方向不会有大的偏差;
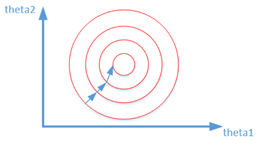
但是如果特征间的数据量级差别比较大,就会形成不成比例的数据簇(在低维空间里面类似于椭圆,橄榄球形状的数据分布),这样的数据分布的求梯度的过程,首先线条是曲折的,加长了从边缘到中心的距离,其次从边缘到中心的距离直线距离本身也是漫长的;按照统一步长的话(step)是相等的,后者是需要更多次的梯度迭代才能够实现(局部)最优化。
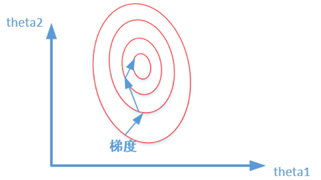
所以,数据标准化之后将会加快求解的过程。
可以看到在通过梯度下降的时候需要对数据进行标准化处理,但是并不是所有的处理都需要进行标准化,有些学习、优化过程是和距离无关的,比如决策树(随机森林)就不需要对数据进行标准化处理。
附录:
PCA需要进行中心化
1. 因为PCA在高维向低维映射的时候,会追求方差最大化;如果没有进行标准化,则会是的算法会倾向于追求大量纲的方差,而忽略小量纲的方差,但是这个在业务逻辑上未必合理;所以一般在进行PCA降维之前会进行标准化,去掉特征的量纲。
2. PCA计算过程也是会有梯度下降,通过标准化,可以缩小大量纲数据的量级,加速梯度下降的收敛。
3. 中心化之后,处理的主成分的方向将会是一个可以描述;如果没有进行中心化,则不一定。至于什么是可描述性,指的是经过了中心化之后,向量的方向就是原点到点坐标的方向。比如计算出来的主成分是[1, 2],那么如果是经过中心化的数据,我们可以说主成分的方向是[0, 0]到点[1, 2]。
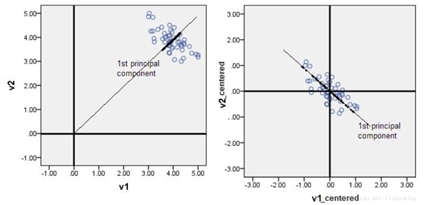
图片为什么要中心化?
减少计算量
经验风险,结构风险
经验风险,可以理解为损失函数的均值:
EXP_RISK = (1/n) * Σ( f(xi) - yi )²
所谓的"经验"就是指已经被标注的训练数据,风险就是指模型的预测值和真实值的差别,这里的经验风险就是模型的训练数据的预测值和真实值的差别的平方项的均值。我们机器学习调优目标就是经验风险最小。
期望风险,是指所有的样本(无论是已知的还是未知的)差别平方项的均值,毫无以为,这是不可能求出来的,因为你无法获得所有的样本。期望在统计学的意义不再是部分数据集,而是全部的样本集的数字特征。
因为模型是经过部分样本集训练出来的,所以调优追求经验风险最小化的结果就是大概率会有过拟合的情况,这个时候,就需要为风险结构引入正则项,使之成为结构风险,顾名思义风险是由多余一个部分组成,这里包括经验风险+正则化两部分;其中正则化部分也称之为“置信风险”,即我在多大程度上可以信赖模型的结果,是一个区间。
注意结构风险其实是经验风险和期望风险一个折中经验风险因为数据不充分,可能会导致过拟合其实是需要期望风险来减少过拟合,但是现实无法获取期望风险,于是通过结构风险来限制经验风险,使之能够接近经验风险。
参考:
https://blog.csdn.net/weixin_36604953/article/details/102652160
https://www.zhihu.com/question/20467170
https://www.cnblogs.com/wangqiang9/p/9285594.html
http://sofasofa.io/forum_main_post.php?postid=1000375 PCA为什么要标准化
PCA为什么要去均值
https://blog.csdn.net/fisherming/article/details/80236631
https://www.zhihu.com/question/37069477
https://blog.csdn.net/liyajuan521/article/details/44565269 经验风险,期望风险以及结构风险的介绍


 浙公网安备 33010602011771号
浙公网安备 33010602011771号