1 模型【数据集】
数据集
1、数据集简介
在顺练数据模型中,我们通常是通过对大量的数据去重,清洗和计算,从而训练出我们需要的数据模型
2、sklearn介绍
scikit-learn 是基于 Python 语言的机器学习工具
- 简单高效的数据挖掘和数据分析工具
- 可供大家在各种环境中重复使用
- 建立在 NumPy ,SciPy 和 matplotlib 上
- 开源,可商业使用 - BSD许可证
1、sklearn官方文档结构
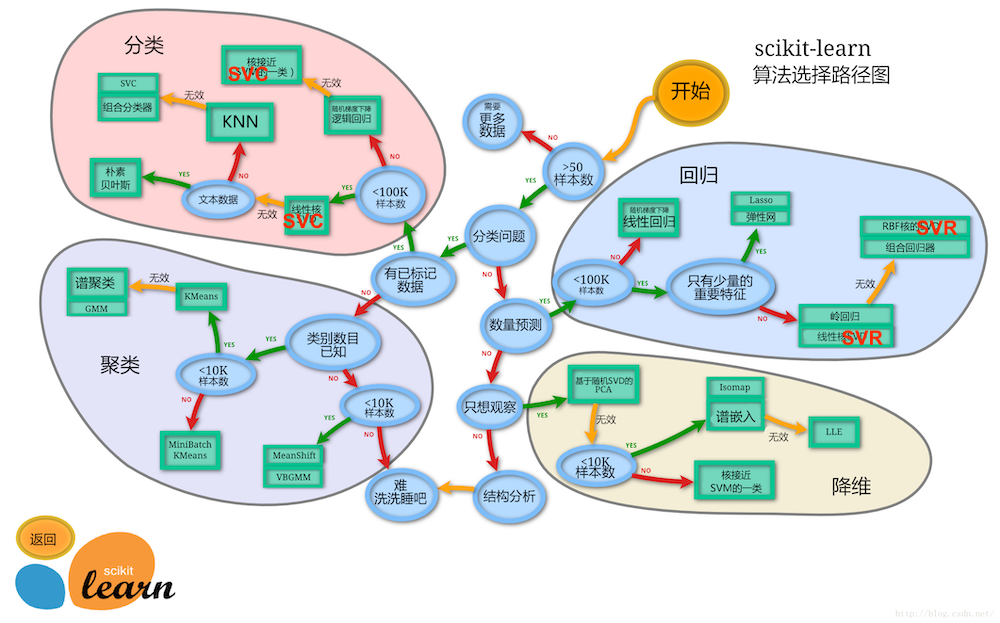
由图中,可以看到库的算法主要有四类:分类,回归,聚类,降维。其中:
- 常用的回归:线性、决策树、SVM、KNN ;集成回归:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
- 常用的分类:线性、决策树、SVM、KNN,朴素贝叶斯;集成分类:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
- 常用聚类:k均值(K-means)、层次聚类(Hierarchical clustering)、DBSCAN
- 常用降维:LinearDiscriminantAnalysis、PCA
这个流程图代表:蓝色圆圈是判断条件,绿色方框是可以选择的算法,我们可以根据自己的数据特征和任务目标去找一条自己的操作路线。
鸢尾花识别是一个经典的机器学习分类问题,它的数据样本中包括了4个特征变量,1个类别变量,样本总数为150。
它的目标是为了根据花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)、花瓣宽度(petal width)这四个特征来识别出鸢尾花属于山鸢尾(iris-setosa)、变色鸢尾(iris-versicolor)和维吉尼亚鸢尾(iris-virginica)中的哪一种。
# 引入数据集,sklearn包含众多数据集
from sklearn import datasets
# 将数据分为测试集和训练集
from sklearn.model_selection import train_test_split
# 利用邻近点方式训练数据
from sklearn.neighbors import KNeighborsClassifier
# 引入数据,本次导入鸢尾花数据,iris数据包含4个特征变量
iris = datasets.load_iris()
# 特征变量
iris_X = iris.data
# print(iris_X)
print('特征变量的长度',len(iris_X))
# 目标值
iris_y = iris.target
print('鸢尾花的目标值',iris_y)
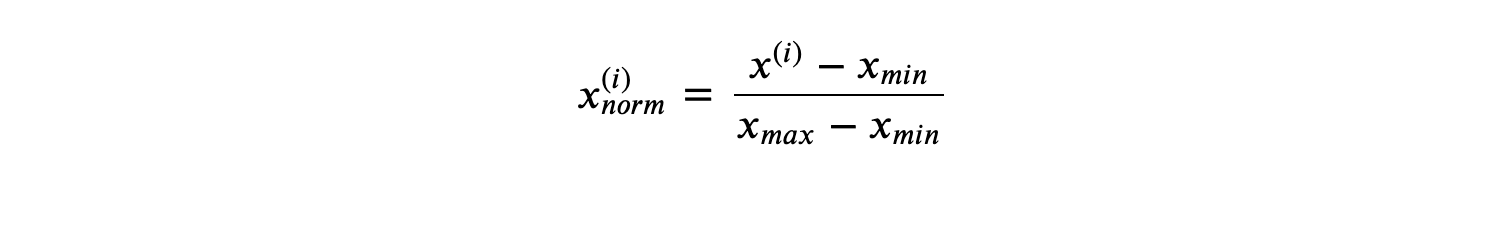
3、数据集预处理
在日常生活中,数据往往是残缺的或不全面的。很对样本都存在这数据丢失的问题,这样的话就会对我们训练的模型的准确度产生干扰。
3.1、缺省值处理
展示数据
# 缺省值处理
from io import StringIO
iris_data = '''
4.9,, 1.4, 0.2
4.7, 3.2, 1.3, 0.2
4.6, 3.1, 1.5, 0.2
5. , 3.6, 1.4,
5.4, 3.9, 1.7, 0.4
4.6, 3.4, 1.4, 0.3
5. ,, 1.5, 0.2
4.4, 2.9, 1.4, 0.2
4.9, 3.1, 1.5, 0.1
5.4, 3.7, 1.5, 0.2
4.8, 3.4, 1.6, 0.2
4.8,, 1.4, 0.1
'''
df = pd.read_csv(StringIO(iris_data), header=None)
df.columns = iris.feature_names
df = df.iloc[:, :4]
df
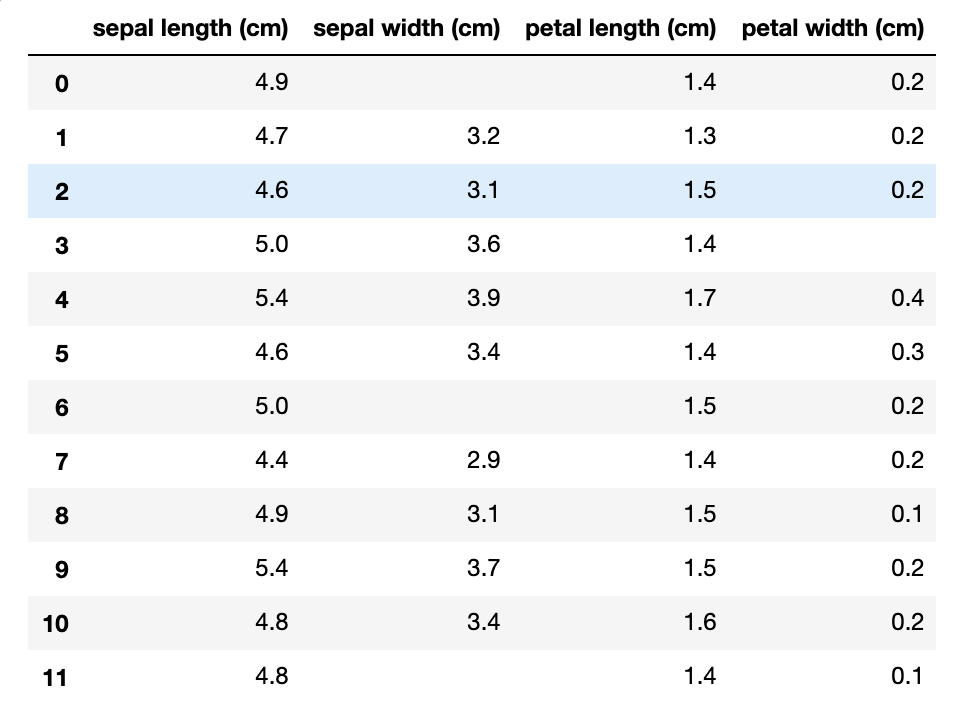
我们可以看出,以上的数据是有缺失的。这个缺失的数据极易影响我们训练的模型的结果,所以我们要想办法除掉或修复我们的数据集
3.1.1、删除缺省值
# 删除全为空白值的行或列
df.dropna(how='all')

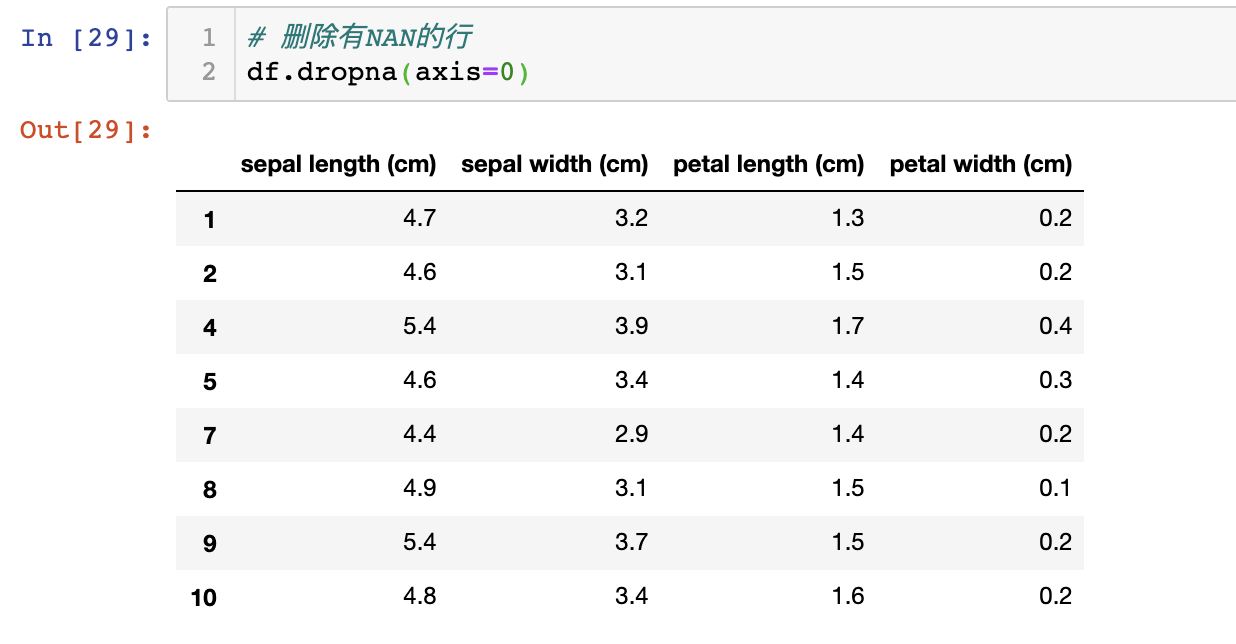
# 删除有NAN的行
df.dropna(axis=0)
# 删除有NAN的列
df.dropna(axis=1)
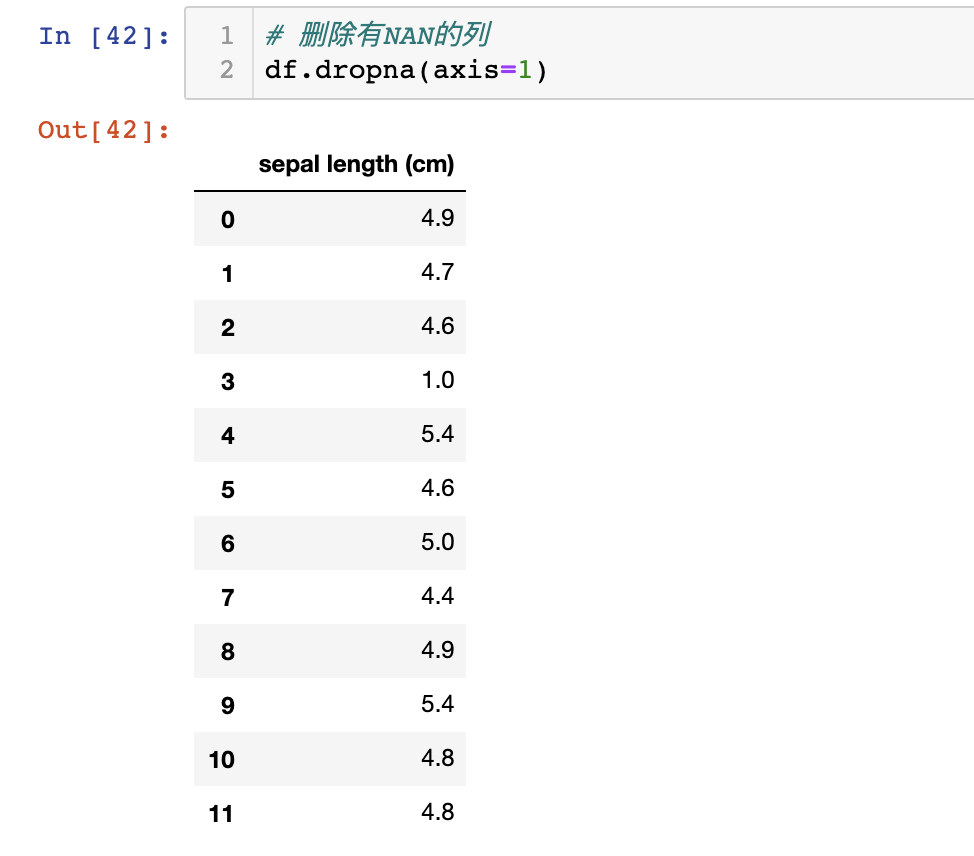
# 删除不为5的值
df.dropna(thresh=4)

3.2、缺省值修复
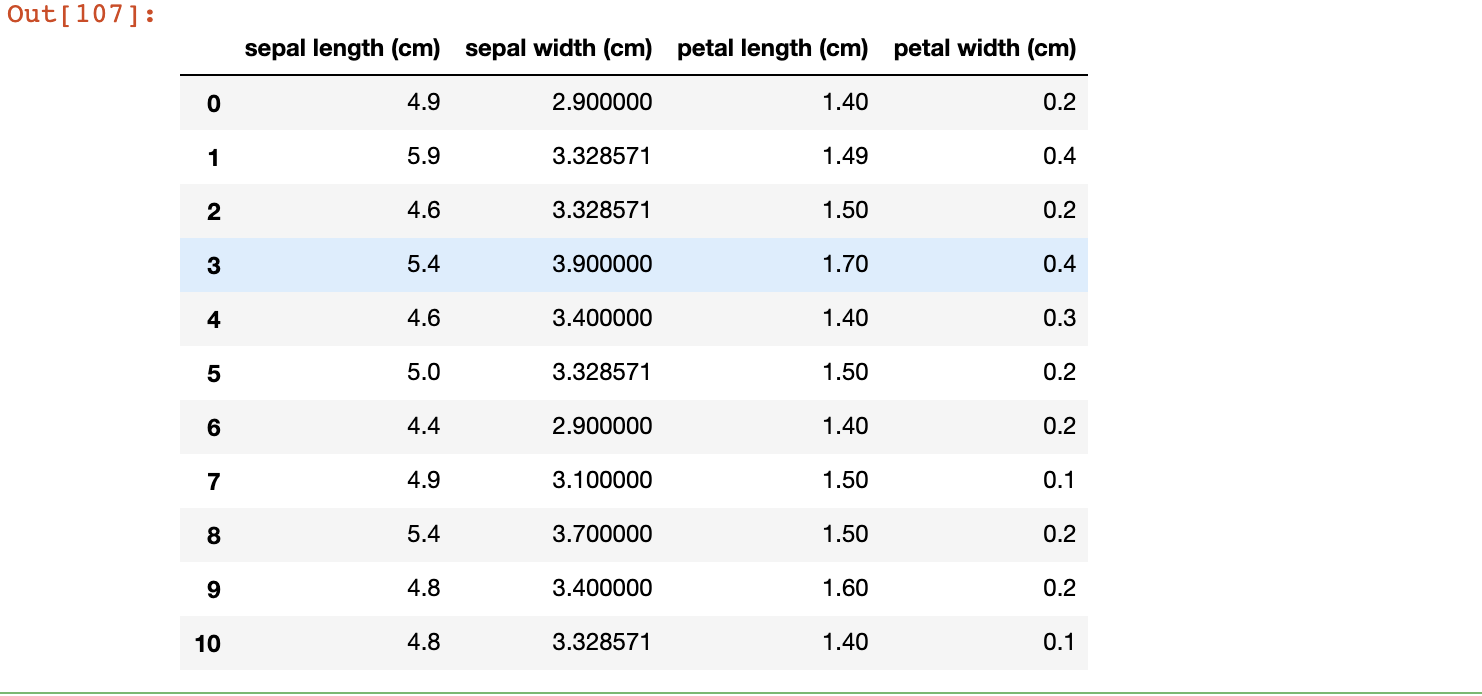
SimpleImputer类提供了输入缺失值的基本策略。缺失值可以用常量值或使用缺失值所在列的统计信息(平均值、中位数或最频繁)进行填充。以下代码演示如何使用包含缺少值的列(轴0)的平均值替换缺少值。
from sklearn.impute import SimpleImputer
import numpy as np
# 对所有的缺省值都固定为0
# impute = SimpleImputer(missing_values=np.nan, strategy='constant', fill_value=0)
# 对所有的缺省值都固定为中位数
impute = SimpleImputer(missing_values=np.nan, strategy='mean')
# 对所有的缺省值都固定为众数
# impute = SimpleImputer(missing_values=np.nan, strategy='most_frequent')
# 参数转换
impute = impute.fit_transform(df.values)
df = pd.DataFrame(impute, columns=iris.feature_names)
df

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}