
win11家庭版升级key
TPYNC-4J6KF-4B4GP-2HD89-7XMP6
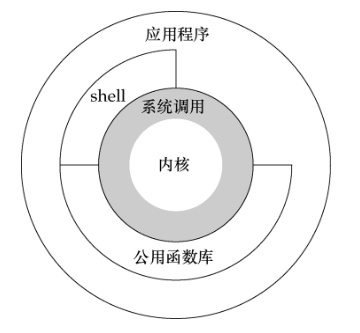
1. poweroff 2. init 0 3. shutdown -h now
1. reboot 2. init 6 3. shutdown -r now
init 3: 登录到纯字符界面 init 5: 登录到图形界面 (前提是安装了server with GUI) startx: 从字符界面退到图形界面(前提是安装了server with GUI )
-:也可以 -l(小写L),当前用户不仅切换为指定用户的身份,同时所用的工作环境也切换为此用户的环境(包括 PATH 变量、MAIL 变量等) 使用 - 选项可省略用户名,默认会切换为 root 用户。 注意,使用 su 命令时,有 - 和没有 - 是完全不同的,- 选项表示在切换用户身份的同时,连当前使用的环境变量也切换成指定用户的。 环境变量是用来定义操作系统环境的,因此如果系统环境没有随用户身份切换,很多命令无法正确执行。 举个例子 普通用户 lamp 通过 su 命令切换成 root 用户,但没有使用 - 选项, 这样情况下,虽然看似是 root 用户,但系统中的 $PATH 环境变量依然是 lamp 的(而不是 root 的), 因此当前工作环境中,并不包含 /sbin、/usr/sbin等超级用户命令的保存路径,这就导致很多管理员命令根本无法使用。 不仅如此,当 root 用户接受邮件时,会发现收到的是 lamp 用户的邮件,因为环境变量 $MAIL 也没有切换。
单字母/短格式 选项前一般都带有一个横线 -,例如-a,-b,c,多个短格式选项可以写在一起,如 -abc
全字/长格式 选项前通常带有两个横线 --,例如:--help,--version
command --help man command info command
#快捷键不区分大小写 Tab键:自动补齐 反斜杠“\”:强制换行 快捷键 Ctrl+U:清空至行首 快捷键 Ctrl+K:清空至行尾 快捷键 Ctrl+A:跳转至行首 快捷键 Ctrl+E:跳转至行尾 快捷键 Ctrl+L:清屏 快捷键 Ctrl+C:取消本次命令编辑
格式1:chmod [ugoa] [+-=] [rwx] 文件或目录... 格式2:chmod nnn 文件或目录(多个逗号分割),其中nnn为3位八进制数 常用命令选项 -R:递归修改指定目录下所有文件、子目录的权限
格式1:chown 拥有人 文件或目录 格式2:chown :拥有组 文件或目录 格式3:chown 拥有人:拥有组 常用命令选项 -R:递归修改指定目录下所有文件、子目录的归属
\ 反斜杠,去除特殊符号的意义、用在一行的末尾,那么他就是分行符
例如:需要输出 "echo you cost: $5.00"
echo you cost: \$5.00
"" 双引号,遇到任何特殊字符均转义,均当特殊字符来用,即双引号中特殊字符需要\转义
'' 单引号,遇到任何特殊符号均不转义,不当特殊字符来用,就是一个普通字符
$ ` \ ! * ?
#当前登录生效 ulimit -n 65536 #永久生效 /etc/security/limits.conf * - nproc 65535 * - nofile 65535 #合并脚本 echo -e 使字符串支持转义字符\n \t等 ulimit -n 65535 && echo -e "*\t-\tnproc\t65535\n*\t-\tnofile\t65535" >> /etc/security/limits.conf
linux 标准输入保存文件
1.覆盖文件
tee test.txt <<-EOF cat > test.txt <<-EOF tee > test.txt <<-EOF
echo -e "hello\nworld" > test.txt
2.追加文件
tee -a test.txt <<-EOF cat >> test.txt <<-EOF tee >> test.txt <<-EOF
echo -e "hello\nworld" >> test.txt
特别关注
- cat必须有重定向符号,否则要么报文件不存在,要么只是打印现有内容,无法保存输入内容
- tee语法:tee 选项 文件,其中选项常用 -a=追加,-i=忽略终端符号ctrl + c
- <<-EOF,表示输入结束符,可以是任何字符串,其中 - 符号表示,结束符前后可以有空白符,如空格或制表符,所以指定 <<EOF 时结束符必须是新行顶格写EOF,不能有空白符
- 如果不指定结束符,则默认为 ctrl + d
- echo指定 -e 支持转义字符,否则转义字符将直接输出
- nohup,非中断运行模式,可以免疫终端关闭(session关闭)或用户退出,但不免疫Ctrl C;
- &,后台运行模式,可以免疫Ctrl C,但无法免疫终端关闭或用户退出
- nohup command &,持续后台运行模式
shell脚本,定位到当前目录
ps -ef
[root@localhost ~]# ps -ef | head UID PID PPID C STIME TTY TIME CMD root 1 0 0 15:18 ? 00:00:01 /usr/lib/systemd/systemd --switched-root --system --deserialize 22 root 2 0 0 15:18 ? 00:00:00 [kthreadd] root 4 2 0 15:18 ? 00:00:00 [kworker/0:0H] root 6 2 0 15:18 ? 00:00:00 [ksoftirqd/0] root 7 2 0 15:18 ? 00:00:00 [migration/0] root 8 2 0 15:18 ? 00:00:00 [rcu_bh] root 9 2 0 15:18 ? 00:00:00 [rcu_sched] root 10 2 0 15:18 ? 00:00:00 [lru-add-drain] root 11 2 0 15:18 ? 00:00:00 [watchdog/0]
[root@localhost ~]# ps -aux | head USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.3 128304 6880 ? Ss 15:18 0:01 /usr/lib/systemd/systemd --switched-root --system --deserialize 22 root 2 0.0 0.0 0 0 ? S 15:18 0:00 [kthreadd] root 4 0.0 0.0 0 0 ? S< 15:18 0:00 [kworker/0:0H] root 6 0.0 0.0 0 0 ? S 15:18 0:00 [ksoftirqd/0] root 7 0.0 0.0 0 0 ? S 15:18 0:00 [migration/0] root 8 0.0 0.0 0 0 ? S 15:18 0:00 [rcu_bh] root 9 0.0 0.0 0 0 ? S 15:18 0:00 [rcu_sched] root 10 0.0 0.0 0 0 ? S< 15:18 0:00 [lru-add-drain] root 11 0.0 0.0 0 0 ? S 15:18 0:00 [watchdog/0]
telnet
安装:yum install -y telnet 使用:telnet ip port 其中,退出方式为 ctrl + ],进入命令模式,然后输入quit。 进入命令模式的方式可以通过参数指定,telnet ip port -e char,指定单个字符,如telnet ip port -e c,则输入c即可进入命令模式
cur 或者 wget
tcp:
curl -v telnet://ip:port
http:
curl -v http://ip:port
nc 即 netcat
nc -zv <IP地址> <端口号> -z:只扫描,不发送数据 -v:显示详细信 -u: 测试udp
输出
succeeded!→ 端口开放refused→ 端口关闭- 超时 → 防火墙拦截或主机离线
nmap 端口扫描工具
nmap [选项] <目标>
常用:nmap -p <端口号> <IP地址>
输出
open:端口开放
closed:端口关闭
filtered:被防火墙过滤(无法确定)
------
目标,支持网段模式(即子网掩码模式 ip/mask)、范围模式(1-100)、离散ip模式(ip1 空格 ip2)、离散网段模式(网段1 空格 网段2)、文件模式(-iL targets.txt)
# 扫描整个 C 类网段(256 个 IP)
nmap 192.168.1.0/24
# 扫描指定范围
nmap 192.168.1.10-20
# 多个 IP
nmap 192.168.1.10 192.168.1.20 10.0.0.5
# 多个网段
nmap 192.168.1.0/24 10.0.0.0/24
# 扫描整个网段,但排除网关和服务器
nmap 192.168.1.0/24 --exclude 192.168.1.1,192.168.1.100 (区别于目标,排除使用逗号,或文件模式 --excludefile targets.txt)
# 从文件读取目标列表
nmap -iL targets.txt
# 从文件排除
nmap 192.168.1.0/24 --excludefile targets.txt
其中,txt文件格式
192.168.1.10
192.168.1.20
www.example.com
10.0.0.0/24
------
选项
-sS TCP SYN 扫描(默认,快速且隐蔽)
-p 22,80,443 只扫描指定端口
-p- 扫描全部 65535 个端口
-F 快速扫描(只扫前 100 个常用端口)
--open 只输出端口状态为 "open" 的结果
-oN result.txt 输出普通文本结果到文件
-oX result.xml 输出 XML 格式(便于程序解析)
-T4 加快扫描速度(-T0 到 -T5,数字越大越快,类似多线程)
-O 尝试识别操作系统
------
输出
Nmap scan report for 192.168.1.10
Host is up (0.002s latency).
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
其中,state
open:端口开放
closed:端口关闭(主机可达)
filtered:被防火墙过滤(无法确定是否开放)
:set nu
:set nonu
查找时使用\c参数 进入底行模式,输入命令“/string\c ” 或 “/\cstring”,将会忽略大小写查找string字符串。 注意:\c与字符串之间不要有空格,因为该空格也会被认为是查询的字符串
通过设置vim配置来忽略大小写查找。
:set ignorecase 或 set ic 忽略大小写查找
:set noignorecase 或set noic 严格大小写查找
临时的话,在底行模式,输入命令 set ignorecase 或 set ic,在没关闭该文件前提下,字符串的查找都将不区分大小写
[^\x00-\xff]
vim替换 - s命令
:[range]s/from/to/[flags] range:搜索范围,如果没有指定范围,则作用于当前行。 :1,10s/from/to/ 表示在第1到第10行(包含第1,第10行)之间搜索替换; :10s/from/to/ 表示只在第10行搜索替换; :%s/from/to/ 表示在所有行中搜索替换; :1,$s/from/to/ 同上。 flags 有如下四个选项: c confirm,每次替换前询问; e error, 不显示错误; g globle,不询问,整行替换。如果不加g选项,则只替换每行的第一个匹配到的字符串; i ignore,忽略大小写。
vim替换 - g命令,global
:[range]g/{pattern}/[command]
g!及其同义词:v,则可以针对所有不匹配模式的行执行操作
command常用如下
1.替换
:g/microsoft antitrust/s/judgment/ripoff/
2.删除
:g/pattern/d
3.查找
:g/pattern
:g/pattern/p
1.使用vi/vim命令打开文件后,输入"%d"清空,后保存即可。但当文件内容较大时,处理较慢,命令如下:vim filename:%d:wq 2.cat /dev/null > filename 3.echo "" > filename,echo > filename,此时会在文件中写入一个空行“\n" 4.cp /dev/null filename 5.> filename
(1)cat -A filename 从显示结果可以判断,dos格式的文件行尾为^M$,unix格式的文件行尾为$; (2)vim filename打开文件,执行 :set ff,如果文件为windows格式在显示为fileformat=dos,如果是unxi则显示为fileformat=unix。
yum install -y dos2unix dos2unix filename
sed -i "s/\r//" filename 或者 sed -i "s/^M//" filename
vi filename, 执行 :set ff=unix 设置文件为unix 执行 :wq,保存
- shell返回码,标识整个脚本的执行结果状态,用“exit 返回码”表示,1-255。
- 函数返回码,标识一个函数的执行结果状态,用“return 返回码”表示。
- 命令返回码,标识一个命令的执行结果状态,在命令执行后,紧跟着获取返回码,用"$?"获取
|
退出码的值
|
含义
|
例子
|
注释
|
|
0
|
成功
|
0为成功,非0(大于0)失败
|
|
|
1
|
通用错误
|
let var1 = 1/0
|
各种各样的错误都可能使用这个退出码, 比如除0错误
|
|
2
|
shell内建命令使用错误
|
很少看到, 通常情况下退出码都为1
|
|
|
126
|
命令调用不能执行
|
程序或命令的权限是不可执行的
|
|
|
127
|
command not found
|
估计是$PATH不对, 或者是拼写错误
|
|
|
128
|
exit的参数错误
|
exit 3.14159
|
exit只能以整数作为参数, 范围是0 - 255(见脚注)
|
|
128+n
|
信号n的致命错误
|
kill -9 脚本的$PPID
|
$? 返回137(128 + 9)
|
|
130
|
用Control-C来结束脚本
|
Control-C是信号2的致命错误, (130 = 128 + 2, 见上边)
|
|
|
255*
|
超出范围的退出状态
|
exit -1
|
exit命令只能够接受范围是0 - 255的整数作为参数
|
cls
- clear命令、这个命令将会刷新屏幕,本质上只是让终端显示页向后翻了一页,如果向上滚动屏幕还可以看到之前的操作信息。
- Ctrl+l(小写的L)、这是一个清屏的快捷键,清屏效果同clear命令一样。
- reset命令、这个命令将完全刷新终端屏幕,之前的终端输入操作信息将都会被清空,这样虽然比较清爽,但整个命令过程速度有点慢,使用较少。
#内核版本 [root@localhost ~]# uname -r 3.10.0-1160.el7.x86_64 #系统版本 [root@localhost ~]# cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core) #CPU架构 [root@localhost ~]# arch x86_64 #完整信息(系统版本,内核版本,CPU架构) [root@localhost ~]# uname -a Linux localhost.localdomain 3.10.0-1160.el7.x86_64 #1 SMP Mon Oct 19 16:18:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
cat /proc/cpuinfo | grep 'processor' | wc -l
cat /proc/cpuinfo| grep "cpu cores"| uniq
lscpu
1.cat /proc/meminfo | grep -i total 2.free -(k/m/g)
#磁盘工具命令
fdisk [选项] <磁盘> 更改分区表 fdisk [选项] -l <磁盘> 列出分区表 选项 -h 打印此帮助文本 -u[=<单位>] 显示单位:“cylinders”(柱面)或“sectors”(扇区,默认)
-f:同时列出文件系统名称
-p:列出该设备的完整文件名,而不是仅列出最后的名字
-h 以人类可读的方式显示(k,m,g)
-T 显示分区的文件系统类型
du -sh [目录或文件 ./*] -h:以人类可读的方式显示(k,m,g) -s:只显示总和,不要显示其下子目录和文件占用的磁盘空间大小
telnet ip port
退出:ctrl+] quit
最大内存,初始内存,新生代内存(官方建议最大内存3/8),单线程内存 2g: -Xmx2048m -Xms1024m -Xmn1024m -Xss2048k 1g: -Xmx1024m -Xms1024m -Xmn512m -Xss1024k
select NOW() #2022-10-12 13:55:32 ,ADDDATE(NOW(),1) #2022-10-13 13:55:32 ,CURRENT_DATE #2022-10-12 ,ADDDATE(CURRENT_DATE,interval 1 DAY) #2022-10-13 ,DATE_FORMAT(NOW(),'%Y-%m-%d %H:%i:%s') #2022-10-12 13:55:32 ,DATE_FORMAT(NOW(),'%Y-%m-%d 00:00:00') #2022-10-12 00:00:00 ,DATE_FORMAT(ADDDATE(NOW(),1),'%Y-%m-%d 00:00:00') #2022-10-13 00:00:00 from dual;
between formatDateTime(today(),'%Y-%m-%d 00:00:00') and formatDateTime(addDays(today(),1),'%Y-%m-%d 00:00:00')
语法:killall [选项] 进程名称 选项: -e | --exact : 进程需要和名字完全相符 -I | --ignore-case :忽略大小写 -r | --regexp :将进程名模式解释为扩展的正则表达式 -l | --list :列出所有的信号名称,HUP INT QUIT ILL TRAP ABRT IOT BUS FPE KILL USR1 SEGV USR2 PIPE ALRM TERM STKFLT CHLD CONT STOP TSTP TTIN TTOU URG XCPU XFSZ VTALRM PROF WINCH IO PWR SYS UNUSED -s | --signal :发送指定信号,值为 -l的输出结果,如-s KILL = -s 9 = -KILL = -9 强制杀掉进程 常用的是HUP(1,终端断线),INT(2,中断,同<Ctrl>+c),QUIT(3,退出,同<Ctrl>+\),KILL(9,强制终止), TERM(15,缺省信号,终止,正常结束),CONT(18,继续,同fg/bg命令),STOP(19,停止),TSTP(20,暂停,同<Ctrl>+Z)
#查看信号 语法1:kill [-l <信号编号>] -l <信号编号> 若不加<信号编号>选项,则 -l 参数会列出全部的信号名称 [root@localhost ~]# kill -l 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8 43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2 63) SIGRTMAX-1 64) SIGRTMAX [root@clickhouse1 ~]# kill -l SIGKILL 9 #杀掉进程 语法2:kill [-s <信号名称或编号>] 进程ID -s <信号名称或编号> 指定要送出的信号,值为 -l 的输出结果,如-s 9 = -s SIGKILL = -SIGKILL = -9 强制杀掉进程
语法:pkill [选项] 进程名称正则表达式 选项: -o:仅向找到的最小(oldest起始)进程号发送信号 -n:仅向找到的最大(newest结束)进程号发送信号 -x:匹配完成进程名 -<sig 信号名称或编号> 指定要送出的信号,信号与kill命令相同,但信号名称或编号直接在符号 - 之后,如 -SIGKILL = -9,不支持 -sig 9
语法:pgrep 选项 进程名称 选项: -o:仅显示找到的最小(起始)进程号; -n:仅显示找到的最大(结束)进程号; -l:同时显示进程ID与进程名称; 进程名称支持部分匹配,如pgrep java 与 pgrep jav
语法:pidof 选项 进程名称 选项: -s:一次只显示一个进程号 -c:只显示运行在root目录下的进程,这个选项只对root用户有效 -o:忽略指定进程号的进程 进程名称必须完整匹配,如pgrep java 不可以写成 pgrep jav
按大小排序 ls -hlS #从大到小 ls -hlSr #从小到大 按创建时间排序 ls -hlt #从新到旧 ls -hltr #从旧到新

交互命令

top命令在脚本中执行时,会报“TERM environment variable not set“,由于脚本中无法加载默认终端类型 方案:使用 -b 参数,即批次存档模式,搭配 -n(指定行数) 一起表示将结果输出到当前脚本内 top -bn 1 -p xxxx
示例:result=`top -bn 1 -p mysqld`
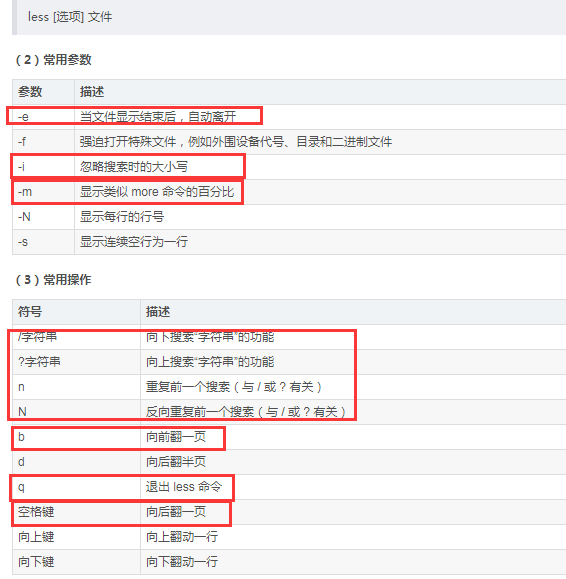
head/tail 前/后 10行 head/tail -n 10 前/后 10行 head/tail -n -10 从倒数第10行开始,取到头/尾 head/tail -n +10 从第10行开始,取到头/尾
nginx 启动nginx nginx -s reload|reopen|stop|quit #重新加载配置|重启|停止|退出 nginx nginx -t 测试配置是否有语法错误 nginx [-?hvVtq] [-s signal] [-c filename] [-p prefix] [-g directives] -?,-h : 打开帮助信息 -v : 显示版本信息并退出 -V : 显示版本和配置选项信息,然后退出 -t : 检测配置文件是否有语法错误,然后退出 -q : 在检测配置文件期间屏蔽非错误信息 -s signal : 给一个 nginx 主进程发送信号:stop(停止), quit(退出), reopen(重启), reload(重新加载配置文件) -p prefix : 设置前缀路径(默认是:/usr/local/Cellar/nginx/1.2.6/) -c filename : 设置配置文件(默认是:/usr/local/etc/nginx/nginx.conf) -g directives : 设置配置文件外的全局指令
find /usr/local/study/*.txt | xargs ls -l
- 可以包含通配符,但通配符需要单引号或双引号包裹,或转义字符\*表示,否则会报错:路径必须在表达式之前(paths must precede expression)
- 可以包含空格,但空格需要单引号或双引号包裹,或转义字符 \空格 表示,因为命令无法识别空格属于文件名还是用来区分多个参数
如 abc.txt,则 -name abc.txt 或 "abc*" 或 abc\*
如果没有引号,Linux是直接将 * 替换为当前目录下的所有文件,所以会报错。 即如果find命令需要接受的是通配符*,需要通过引号或者转义才能真正表达*。 [root@localhost dir2]# ls txt11.txt txt12txt.txt txt1.txt [root@localhost dir2]# echo * txt11.txt txt12txt.txt txt1.txt [root@localhost dir2]# find . -name *.txt find: 路径必须在表达式之前: txt12txt.txt 用法: find [-H] [-L] [-P] [-Olevel] [-D help|tree|search|stat|rates|opt|exec] [path...] [expression] [root@localhost dir2]# find . -name "*.txt" ./txt1.txt ./txt11.txt ./txt12txt.txt [root@localhost dir2]# find . -name \*.txt ./txt1.txt ./txt11.txt ./txt12txt.txt
如 /data/log/abc.txt,则 -path "*abc*",或者 "*abc.txt"
find . -mtime +7 -exec rm -rf {} \; find . -mtime +7 | xargs rm -rf
windows find /c "string" linux wc -l grep -c "string"
- exec格式为 "-exec COMMAND {} \;",xargs格式为 "xargs COMMAND"(关于xargs -i/I参数参考下文)
- exec实际上每一条结果执行一次,效率较低,xargs默认批次执行,效率高(默认批次为5000,可以通过 -n num指定)
- xargs默认批次可能引起参数过长错误(如果文件名超长,文件个数超多)
- xargs不支持文件名包含空格,因为xargs无法区分是文件名的空格,还是多个文件的分隔符,exec没有空格问题
- 管道是将前面命令的输出作为后面命令的标准输入,传递的是结果本身,文件名,文件内容等
- xargs是将前面命令的输出,作为后面命令的参数,传递的是结果代表的对象,如文件
find / -name '*test*.txt' | xagrs -i mv {} /test,而不能 xagrs -i {} mv {} /test
find / -name '*test*.txt' | xagrs -I {} mv {} /test --> find / -name '*test*.txt' | xagrs -I abcd mv abcd /test
- xargs后如果没有明确指定,默认为 -i,且 {} 在最后(-i 与 {} 都可以省略),find dir1 -name "*.txt" | xargs grep "sth" 相等于 find dir1 -name "*.txt" | xargs -i grep "sth" {}
- 如果参数不是在命令最后,则需要明确使用 -i/I 来指定(不可以省略),如 find dir1 -name "*.txt" | xargs -i mv {} dir2/ 或 find dir1 -name "*.txt" | xargs -I {} mv {} dir2/
命令格式: find 搜索路径 [选项] 搜索内容 选项: -atime[+|-]时间:按照文件访问时间搜索 -mtime[+|-]时间:按照文件数据(如内容)修改时间搜索 -ctime[+|-]时间:按照文件状态(如权限)修改时间搜索
-c: --create: 建立压缩档案 -x:--extract, --get : 解压 -t:--list : 列出tar归档文件中包含的文件或目录 -r:--append : 向压缩归档文件末尾追加文件 -u:--update : 更新原压缩包中的文件 这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用其中一个。下面的参数是根据需要在压缩或解压档案时可选的。 -C: --directory=DIR : 执行归档动作前变更工作目录到 目标DIR -z:--gzip : 有gzip属性的 -v:--verbose : 显示所有过程 如果要指定文件名,参数 -f 是必须的 -f: --file=ARCHIVE : 使用档案名字,切记,这个参数是最后一个参数,后面只能接档案名。
- zip -r temp.zip temp/ 递归压缩
- zip -q -r temp.zip temp/ 安静递归,不显示信息
- zip temp.zip temp.log 文件压缩
- -l 显示压缩文件内所包含的文件。
- -n 解压缩时不要覆盖原有的文件。
- -o 不必先询问用户,unzip执行后覆盖原有文件。
- -P<密码> 使用zip的密码选项。
- -q 执行时不显示任何信息。
- [.zip文件] 指定.zip压缩文件。
- [文件] 指定 要处理.zip压缩文件中的哪些文件,空格分隔
- -d<目录> 指定文件解压缩后所要存储的目录。
- -x<文件> 指定不要处理.zip压 缩文件中的哪些文件,空格分隔
- -1只列出文件名
- -l列出详细信息
- 压缩 gzip -rv dir gzip -v file1 file2
- 解压 gzip -rdv dir
-d或--decompress或----uncompress 解开压缩文件。 -c或--stdout或--to-stdout 把内容输出到标准设备,不改变原始文件。 gzip -cv file > file.gz; -c 还可用于检索压缩日志文件, gzip -dc *.log.gz | grep -a sth -f或--force 强行压缩文件。不理会文件名称或硬连接是否存在以及该文件是否为符号连接。 -q或--quiet 不显示警告信息。 -r或--recursive 递归处理,将指定目录下的所有文件及子目录一并处理。 -v或--verbose 显示指令执行过程。 -l或--list 查看压缩文件信息,包括压缩前后大小,压缩率 -num 用指定的数字num调整压缩的速度,-1或--fast表示最快压缩方法(低压缩比),-9或--best表示最慢压缩方法(高压缩比)。系统缺省值为6。
jq -c '{time:.time,ip:.ip,ora_get_line:.ora_get_line}' pisces_leadsafe.txt | grep 10.66.110.131 | grep 2018111714
[root@localhost ~]# netstat -antp Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:33071 0.0.0.0:* LISTEN 2105/mysqld tcp 0 0 0.0.0.0:7379 0.0.0.0:* LISTEN 1090/redis-server 0 tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1244/sshd [root@localhost ~]# netstat -antp | awk -F '[ /]+' 'NR>2 {count[$6]++} END {for(state in count) print state,"\t\t",count[state] }' LISTEN 16 CLOSE_WAIT 2 ESTABLISHED 273 FIN_WAIT2 1 TIME_WAIT 1
[root@localhost ~]# netstat -antp | grep -i established | awk -F '[ /]+' '{count[$8]++} END {for(app in count) print app,"\t\t",count[app] }' java 124 mysqld 109 clickhouse-ser 6 sshd: 1 redis-server 31
- -<行数> 或 -l : 指定每多少行切成一个小文件
- -a, --suffix-length=N 后缀长度,默认为2(字母则 aa ab ac, 数字则 00 01 02)
- -b<字节> : 指定每多少字节切成一个小文件
- --help : 在线帮助
- --version : 显示版本信息
- -C<字节> : 与参数"-b"相似,但是在切 割时将尽量维持每行的完整性
- [输出文件名前缀] : 设置切割后文件的前置文件名, split会自动在前置文件名后再加上编号
- -d 后缀名为数字,默认为字母(aa,ab,ac),默认从0开始
- --numeric-suffixes[=FROM] 后缀为数字,可以指定from基础数字
指定了用户名,命令执行后需要输入用户密码 scp local_file remote_username@remote_ip:remote_folder scp local_file remote_username@remote_ip:remote_file 第1个仅指定了远程的目录,文件名字不变,第2个指定了文件名 不指定用户名,命令执行后需要输入用户名和密码 scp local_file remote_ip:remote_folder scp local_file remote_ip:remote_file 第3个仅指定了远程的目录,文件名字不变,第4个指定了文件名
scp -r local_folder remote_username@remote_ip:remote_folder scp -r local_folder remote_ip:remote_folder 第1个指定了用户名,命令执行后需要输入用户密码; 第2个没有指定用户名,命令执行后需要输入用户名和密码
yum install -y epel-releaseyum install -y iftop
CentOS/RHEL 5 : rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-5.noarch.rpm CentOS/RHEL 6 : rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-6.noarch.rpm CentOS/RHEL 7 : rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
语法 iftop [option] -i设定监测的网卡,如:# iftop -i eth1 -B 以bytes为单位显示流量(默认是bits),如:# iftop -B -n 使host信息默认直接都显示IP,如:# iftop -n -F net/mask显示特定网段的进出流量,如# iftop -F 10.10.1.0/24或# iftop -F 10.10.1.0/255.255.255.0
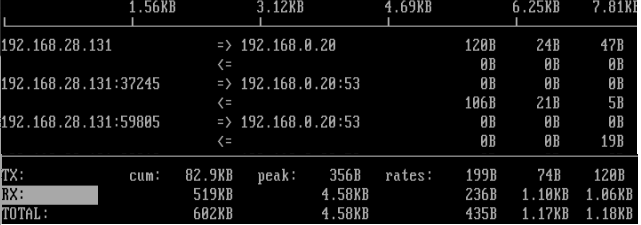
界面上面显示的是类似刻度尺的刻度范围,为显示流量图形的长条作标尺用的。 中间的<= =>这两个左右箭头,表示的是流量的方向。 TX:发送流量 RX:接收流量 TOTAL:总流量 Cum:运行iftop到目前时间的总流量 peak:流量峰值 rates:分别表示过去 2s 10s 40s 的平均流量
按h切换是否显示帮助; --IP显示 按n切换显示本机的IP或主机名; ------端口显示-------- ***按p切换是否显示端口信息; ***按N切换显示端口号或端口服务名称; --流量控制 ***按T切换是否显示每个连接的总流量; 按t切换显示格式为2行/1行/只显示发送流量/只显示接收流量; 按b切换是否显示平均流量图形条; ------过滤------ ***按l打开屏幕过滤功能,输入要过滤的字符,比如ip,按回车后,屏幕就只显示这个IP相关的流量信息; ------排序------ 按1或2或3可以根据右侧显示的三列流量数据进行排序; 按<根据左边的本机名或IP排序; 按>根据远端目标主机的主机名或IP排序; --翻页 按j或按k可以向上或向下滚动屏幕显示的连接记录; --刷新控制 ***按P切换暂停/继续显示; ***按q退出监控。
Linux系统颜色默认表示的文件类型
蓝色表示目录; 绿色表示可执行文件; 红色表示压缩文件; 浅蓝色表示链接文件; 灰色表示其它文件; 红色闪烁表示链接的文件有问题了(如丢失); 黄色是设备文件,包括block, char, fifo。
CentOS配置JDK
export JAVA_HOME=/usr/local/jdk1.8.0_181 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin export PATH=$PATH:${JAVA_PATH}
#mysql 临时密码 grep 'temporary password' /var/log/mysqld.log #具体日志路径以/etc/my.cnf为准 #第一次登陆修改密码 mysql -uroot -p ALTER USER 'root'@'localhost' IDENTIFIED BY 'xxxx'; #初始化时root账号只有localhost #开启远程登录 use mysql; update user set host='%' where user='root'; flush privileges;
#--prefix指定安装的路径,组件文件统一存放,方便日后卸载删除 ./configure --prefix=/usr/local/xxx #-j 4指定并行编译任务数,适用多核CPU,一般配置为cpu核数的2倍 make -j 4 && make install
config,configure 会根据指定的相关参数,生成 Makefile,即自动化编译、构建脚本 如果指定 --prefix=(必须小写)安装目录,则生成的 Makefile 文件中预设 prefix(小写,与参数一致) 变量为指定的目录 make,根据 Makefile 完成编译和构建,生成可执行程序和相关库文件 make install,根据 Makefile 完成安装,其中包括 prefix 安装目录, 此时也可以指定 prefix 参数更换安装目录:make prefix= install(大小写与Makefile中变量一致) 有些组件如redis,源码包含 Makefile 文件,但没有 config/configure 脚本,同时 Makefile 中已经指定默认安装目录的变量为 PREFIX(大写),值为 /usr/local/, 所以在 make 编译构建后,make install 安装阶段,如果要调整安装目录,则需要指定 make PREFIX= install(必须大写) 总结:安装目录在 Makefile 中通过变量指定,而变量名可以通过 config/configure 脚本指定,最后在 make install 阶段调整安装目录的变量名大小写必须与 Makefile 中一致!
/bin : commandsin this dir are all system installed user commands 系统预装系统程序,纯净系统中默认安装,所有用户都可以使用 例如:cat、cp、df、gzip、kill、ls、mkdir、more、rm、tar等。 /sbin: commands in this dir are all system installed super user commands 系统预装系统程序,纯净系统中默认安装,只有超级用户可以使用 例如:fdisk、ifconfig、 reboot、 shutdown等。 /usr/bin: user commands for applications 用户安装系统程序,纯净系统中非默认安装,所有用户都可以使用,后期安装 例如c++、g++、gcc、du、free、gzip、less、locale、make、man、passwd、wget等。 /usr/sbin:super user commands for applications 用户安装系统程序,纯净系统中非默认安装,只有超级用户可以使用,后期安装 例如:dhcpd、httpd、netconfig、swap、tcpd、tcpdump等。 /usr/local/bin 用户安装第三方程序,所有用户都可以使用 例如:MySQL /usr/local/sbin 用户安装第三方程序,只有超级用户可以使用 例如:nginx
主目录:/root、/home/username 用户可执行文件:/bin、/usr/bin、/usr/local/bin 系统可执行文件:/sbin、/usr/sbin、/usr/local/sbin 其他挂载点:/media、/mnt 配置:/etc 临时文件:/tmp 内核和Bootloader:/boot 服务器数据:/var、/srv 系统信息:/proc、/sys 共享库:/lib、/usr/lib、/usr/local/lib
D 不可中断睡眠 (通常是在IO操作) 收到信号不唤醒和不可运行, 进程必须等待直到有中断发生 R 正在运行或可运行(在运行队列排队中) S 可中断睡眠 (休眠中, 受阻, 在等待某个条件的形成或接受到信号) T 已停止的 进程收到SIGSTOP, SIGSTP, SIGTIN, SIGTOU信号后停止运行 W 正在换页(2.6.内核之前有效) X 死进程 (未开启) Z 僵尸进程 进程已终止, 但进程描述符存在, 直到父进程调用wait4()系统调用后释放BSD风格的 < 高优先级(not nice to other users) N 低优先级(nice to other users) L 页面锁定在内存(实时和定制的IO) s 一个信息头 l 多线程(使用 CLONE_THREAD,像NPTL的pthreads的那样) + 在前台进程组
语法: route [-p] [command [destination] [mask netmask] [gateway] [metric] [if interface] --添加临时路由 route add 10.29.8.10 mask 255.255.255.255 192.168.137.1 --删除临时路由 route delete 10.29.8.10 mask 255.255.255.255 192.168.137.1 --添加永久路由 route add -p 10.29.8.10 mask 255.255.255.255 192.168.137.1 --删除永久路由 route add -p 10.29.8.10 mask 255.255.255.255 192.168.137.1
mysql> help(或 ?)
List of all MySQL commands:
ego (\G) Send command to mysql server, display result vertically.
go (\g) Send command to mysql server.
mysql> select user,host from user where user='root'\g +------+------+ | user | host | +------+------+ | root | % | +------+------+ 1 row in set (0.00 sec) mysql> select user,host from user where user='root'\G *************************** 1. row *************************** user: root host: % 1 row in set (0.00 sec) mysql> select user,host from user where user='root'\G; *************************** 1. row *************************** user: root host: % 1 row in set (0.00 sec) ERROR: No query specified
//请求结果保存 pm.test("get request", function () { if(pm.response.to.have.status(200)) { var jsonData = pm.response.json(); pm.environment.set("serial", jsonData["DeviceList"][0]["ID"]); } });
//MD5加密 var password = pm.environment.get("password"); var md5Password = CryptoJS.MD5(password).toString(); pm.environment.set("md5Password",md5Password);
//AES加密 const aesKey = CryptoJS.enc.Utf8.parse('this-is-aes-key') // 加密函数 function encryptWithAES(word) { let srcs = CryptoJS.enc.Utf8.parse(word) let encrypted = CryptoJS.AES.encrypt(srcs, aesKey, { mode: CryptoJS.mode.ECB, padding: CryptoJS.pad.Pkcs7 }) return encrypted.ciphertext.toString().toUpperCase() } // 原始请求体数据 var requestData = pm.request.body.raw; // 加密请求体数据 var encryptedRequestData = encryptWithAES(requestData, aesKey); // 更新请求体数据 pm.request.body.raw = {"param": encryptedRequestData}; console.log(pm.request.body.raw)
正向代理与反向代理
维基百科: Unlike a forward proxy, which is an intermediary for its associated clients to contact any server, a reverse proxy is an intermediary for its associated servers to be contacted by any client。 翻译: 正向代理是【所要代理的客户端】与【其他所有服务器(重点:所有)】之间的代理者, 而反向代理是【其他所有客户端(重点:所有)】与【所要代理的服务器】之间的代理者。
- 一个对客户端(我们自己)负责,为正
- 一个对所代理的服务器(我们的目标)负责,为反。
- 正向代理是代理我们发出请求的客户端,隐藏真实客户端(我们自己)
- 反向代理是代理我们访问的服务器,隐藏真实服务端(我们的目标)
java执行java文件(语法:java ClassName,与class文件同目录),而非jar包(语法:java -jar something.jar)
1.编辑源文件如HelloWorld.java(java要求文件名与类名一致) 2.编译 javac HelloWorld.java,输出 HelloWorld.class 3.执行 java HelloWorld(类名,java会从当前目录class文件查找类的入口函数,但不能指定clsss文件名) 特别注意:环境变量 CLASSPATH 需要包括当前目录(.),示例如下 export JAVA_HOME=/usr/local/jdk1.8.0_181 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin export PATH=$PATH:${JAVA_PATH}
1./usr/share/zoneinfo/洲/国家 的时区文件拷贝或软连接到 /etc/localtime 2.tzselect,可视化依次选择 洲/国家(当前会话生效,重启后时效) 3.timedatectl set-timezone 洲/国家,CentOS7以上版本新增 特别注意:只有 timedatectl 可以同时更改系统时区、硬件时区、java虚拟机时区 java启动时指定时区 1.-Duser.timezone=Asia/Shanghai 2.-Duser.timezone=GMT+08 建议使用方案1,因为中国使用过夏令时,[Asia/Shanghai]可以兼容,而[MT+08]某些场景下会触发bug
docker镜像库加速(截至20230915验证正常,按照下载顺序排列)
cat > /etc/docker/daemon.json <<-EOF { "registry-mirrors":["https://docker.mirrors.ustc.edu.cn","https://dockerproxy.com","http://hub-mirror.c.163.com","https://docker.m.daocloud.io"], "data-root":"/data/docker/" } EOF systemctl daemon-reload && systemctl restart docker
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'mysql_exporter'@'%' IDENTIFIED BY 'Mysql.exporter.123' WITH MAX_USER_CONNECTIONS 3;
docker run -d \ --name mysqld_exporter \ --restart always \ -p 9105:9104 \ -e TZ=Asia/Shanghai \ -v /etc/localtime:/etc/localtime \ -v /usr/local/mysqld_exporter/my.cnf:/cfg/.my.cnf \ prom/mysqld-exporter --config.my-cnf=/cfg/.my.cnf
docker run -d \ --name mysqld_exporter \ --restart always \ -p 9105:9104 \ -e TZ=Asia/Shanghai \ -v /etc/localtime:/etc/localtime \ -e DATA_SOURCE_NAME="user:pwd@(ip:port)/" \ prom/mysqld-exporter
- 配置文件 /cfg/.my.cnf 为官方指定,所以需要通过虚拟路径挂载到本地路径,然后使用 --config.my-cnf 指定
- 服务端口号9104为官方指定,所以 -p 指定的内部端口号必须是9104
- 密码不能包含 #
window bat
- rem
- ::
echo= echo, echo; echo+ echo/ echo[ echo] echo: echo. echo\
echo hello world > nul
语法:CHOICE [/C choices] [/N] [/CS] [/T timeout /D choice] [/M text] /C choices 指定要创建的选项列表。默认列表是 "YN"。此时命令行显示:【Y,N】 /N 在提示符中隐藏选项列表。提示信息依然显示。此时命令行不显示【Y,N】 /CS 允许选择分大小写的选项。在默认情况下,这个工具是不分大小写的。 /T timeout 做出默认选择之前,暂停的秒数。可接受的值是从 0到 9999。如果指定了 0,就不会有暂停,默认选项会得到选择。 /D choice 在 nnnn 秒之后指定默认选项。字符必须在用 /C 选项指定的一组选择中; 同时,必须用 /T 指定 nnnn。 /M text 指定提示之前要显示的消息。如果没有指定,工具只显示提示。此时命令行显示:text【Y,N】
if expression (statements1) ^ else if expression (statements2) ^ else (statements3)
非: if not expression 与: (推荐)嵌套if if expression1 (if expression2 (statements)) 省略括号if expression1 if expression2 (statements)(此时如果有else分支,则else就近匹配) 或: (推荐)多个if对同一变量赋值(此时如果有else分支,请注意变量初始化,否则需要判断变量是否定义) 嵌套if
@echo off set str="this is a test" REM 检测变量%str%是否等于test,如果相等,显示OK,否则显示NO if "%str%"=="test" (echo OK) else echo NO pause>nul
EQU - 等于 NEQ - 不等于 LSS - 小于 LEQ - 小于或等于 GTR - 大于 GEQ - 大于或等于
@echo off set str1="ok" set str2="no" if defined str1 echo str1已经被定义 if defined str2 echo str2已经被定义 if defined str3 (echo str3已经被定义) else echo str3 没有被定义 pause>nul
@ECHO OFF XCOPY F:\test.bat D:\ IF ERRORLEVEL 1 ECHO 文件拷贝失败 IF ERRORLEVEL 0 ECHO 成功拷贝文件 以上,不能先判断0,后判断1
windows bat 变量延迟
- 为什么要使用变量延迟?
- 因为要让复合语句内部的变量实时感知到变量值的变化。
- 在哪些场合需要使用变量延迟语句?
- 在复合语句内部,如果某个变量的值发生了改变,并且改变后的值需要在复合语句内部的其他地方被用到,那么,就需要使用变量延迟语句。
- 怎样使用变量延迟?
- 使用 setlocal enabledelayedexpansion 语句:
- 在获取变化的变量值语句之前使用setlocal enabledelayedexpansion,并把原本使用百分号对闭合的变量引用改为使用感叹号对来闭合,即 !var!
- 使用 call 语句:
- 在原来命令的前部加上 call 命令,并把变量引用的单层百分号对改为双层百分号,即 %%var%%
- 在复合语句中,整个复合语句是一条完整的语句,而无论这个复合语句占用了多少行的位置,常见的复合语句有
- for语句
- if……else语句
- 用 连接符&、||和&&连接的语句
- 用管道符号|连接的语句
- 用括号括起来的,由多条语句组合而成的语句块;
- 在非复合语句中,如果该语句占据了一行的位置,则该行代码为一条完整的语句。
@echo off set num=0 for /f %%i in ('dir /a-d /b *.exe') do ( set /a num+=1 echo num 当前的值是 %num% ) echo 当前目录下共有 %num% 个exe文件 dir /a-d /b *.txt|findstr "test">nul&&( echo 存在含有 test 字符串的文本本件 ) || echo 不存在含有 test 字符串的文本文件 if exist test.ini ( echo 存在 test.ini 文件 ) else echo 不存在 test.ini 文件 pause
- 首先,把一条完整的语句读入内存中(不管这条语句有多少行,它们都会被一起读入),
- 然后,识别出哪些部分是命令关键字,哪些是开关、哪些是参数,哪些是变量引用……
- 如果代码语法有误,则给出错误提示或退出批处理环境;
- 如果顺利通过,接下来,就把该条语句中所有被引用的变量及变量两边的百分号对,用这条语句被读入内存之就已经赋予该变量的具体值来替换……
- 当所有的预处理工作完成之后,批处理才会执行每条完整语句内部每个命令的原有功能。
set num=0&&echo %num%
是一条复合语句,它的含义是:把0赋予变量num,成功后,显示变量num的值。
- 在适当位置使用 setlocal enabledelayedexpansion 语句;
- 在适当的位置使用 call 语句。
set num=0
echo %num%

 浙公网安备 33010602011771号
浙公网安备 33010602011771号