
Python学习第45天(setDaemon、GIL)
昨天其实已经看了部分setDaemon的内容了,但是其实内容并不全。
首先,先补充一下昨天没有说完的知识内容吧
import time import threading def listen(num): print('listen is coming at %s'%time.ctime()) time.sleep(3) print('listen is ending at %s'%time.ctime()) def game(num): print('game is coming at %s'%time.ctime()) time.sleep(5) print('game is ending at %s'%time.ctime()) if __name__ == '__main__': t1 = threading.Thread(target = listen , args = (1,)) # t1.setDaemon(True) t1.start() t1.join() t2 = threading.Thread(target = game , args = (2,)) t2.setDaemon(True) t2.start() print('ending time is %s'%time.ctime())
关于上面这种情况,t1join了主线程之后,主线程会等待t1完成之后再输出结束语,但是t2用了setDaemon,所以主线程不会等待t2的执行结束,一旦主线程执行完毕,t2就不再继续执行下去了。
输出的结果:
listen is coming at Tue Apr 7 23:38:45 2020
listen is ending at Tue Apr 7 23:38:48 2020
game is coming at Tue Apr 7 23:38:48 2020
ending time is Tue Apr 7 23:38:48 2020
然后是关于线程的调用方式,昨天我们实现了其中的一种,就是使用threading模块内的Thread类进行实例化实现线程的生成
如下,直接调用:
import threading import time def sayhi(num): #定义每个线程要运行的函数 print("running on number:%s" %num) time.sleep(3) if __name__ == '__main__': t1 = threading.Thread(target=sayhi,args=(1,)) #生成一个线程实例 t2 = threading.Thread(target=sayhi,args=(2,)) #生成另一个线程实例 t1.start() #启动线程 t2.start() #启动另一个线程 print(t1.getName()) #获取线程名 print(t2.getName())
还有一种就是通过类的继承来实现,创建一个类,继承threading.Thread
这个过程中必须要注意的一点就是,继承这个类之后必须要重新写run()方法,也就是我们在t1.start()的时候会调用到的方法
如下:
import threading import time class MyThread(threading.Thread): def __init__(self,num): threading.Thread.__init__(self) self.num = num def run(self):#定义每个线程要运行的函数 print("running on number:%s" %self.num) time.sleep(3) if __name__ == '__main__': t1 = MyThread(1) t2 = MyThread(2) t1.start() t2.start() print("ending......")
然后我们在昨天通过使用了t1.join()使所有线程在执行完所有的线程之后才会执行最后的ending输出
那么今天可以通过:threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果
来实现这一功能
import time import threading def listen(num): print('listen is coming at %s'%time.ctime()) time.sleep(3) print('listen is ending at %s'%time.ctime()) def game(num): print('game is coming at %s'%time.ctime()) time.sleep(5) print('game is ending at %s'%time.ctime()) if __name__ == '__main__': t1 = threading.Thread(target = listen , args = (1,)) # t1.setDaemon(True) t1.start() t2 = threading.Thread(target = game , args = (2,)) t2.start() print(threading.activeCount()) while threading.activeCount() == 1: print('ending time is %s'%time.ctime())
大致就是这样。
然后今天引入了两个非常重要的概念和一个Python中最要命的bug,幸好我知道的晚,不然我就不学了
并发:一个系统具有处理多个任务的能力,cpu的切换功能,实现多任务的处理
并行:一个系统具有同时处理多个任务的能力,反映到实际过程中,就是多核电脑,不同核心同时进行任务执行
同步、异步:
同步:当程序执行到需要进行外部数据输入的时候,程序会等待外部数据输入
异步:就是不等了,先去干别的,等你数据输入之后我再返回执行
据说上面这两组概念非常重要,基本程序员面试都会问,我也是惊呆了
下面就是GIL的概念,先不说是啥,我们引入一个问题
首先我们在开启多线程的过程中,目的是为了使程序能够更高效更快速的运行
比如昨天的listen和game同时开始,本来要8秒,最后5秒完成了
但是下面的这个案例,请看:
首先是不使用多线程:
import time import threading def add(): sum_a = 0 for i in range(1,100000): sum_a += i return sum_a def cheng(): sum_b = 1 for i in range(1,100000): sum_b *= i return sum_b if __name__ == '__main__': start_time = time.time() add() cheng() print('用时:%s'%(time.time() - start_time))
输出结果:用时:3.7846882343292236
然后我们使用多线程进行运算:
import time import threading def add(): sum_a = 0 for i in range(1,100000): sum_a += i return sum_a def cheng(): sum_b = 1 for i in range(1,100000): sum_b *= i return sum_b if __name__ == '__main__': start_time = time.time() t1 = threading.Thread(target = add) t1.start() t1.join() t2 = threading.Thread(target = cheng) t2.start() t2.join() print('用时:%s'%(time.time() - start_time))
输出结果:用时:4.229001998901367
发现了为啥用了多线程反而还慢了呢,其实刚才测试失败了,引用了别人的测试结果,反正就是这么个意思,为啥呢
引出了Python最大的一个bug,也不能算,人家也是为了程序安全,只是我这种low货才这么认为
造成上面的原因,先看下图:
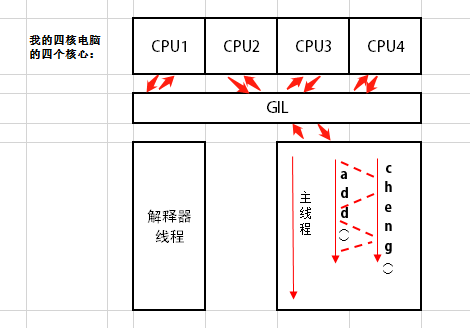
大致就是上面这个意思,其实内部,不论用户你是几个线程,都要通过GIL传入到cpu,最终就只有一个线程了,然后add和cheng之间来回切换进行运算,这部分还没学完,叫竞争吧好像,明天进行补充,也就是说由于两个来回切换花费的时间导致了最终会使用更多的时间
图里面每次箭头的发生都会涉及到数据的暂存
说到这里想起昨天漏了的一个知识点,寄存器。
首先,我们的cpu运行速度老快了,导致运行慢的原因多数是因为等待数据的读取过程,下面是从不同位置读取数据的速度对比
数据库(磁盘):骑自行车
内存:开汽车(蛮贵的那种好车,大多数浏览网页的缓存)
cpu:速度至少是第一宇宙速度
然后,电脑为了解决等待数据读取过程中的时间损耗,就在cpu边上或者里面开了一个很小的空间,用于暂时存放一些非常重要的数据,这个位置就是寄存器
这样做就不会拖cpu的后腿了
今天就是这些内容了,没有想到最近这么多的理论知识,我的脑子也是不走了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号