

软件工程第二次作业
软件工程第二次个人作业
github仓库:dyLR-036030/xy2
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/class12Grade23ComputerScience/homework/13469 |
|---|---|
| 这个作业要求在哪里 | 个人项目 - 作业 - 计科23级12班 - 班级博客 - 博客园 |
| 这个作业的目标 | 学习个人项目制作,掌握项目性能分析 |
1. PSP表格
在开始实现程序之前,我们估计各个模块的开发时间如下:
| PSP阶段 | 任务内容 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| 计划 | 确定需求和技术方案 | 30 | 25 |
| 需求分析 | 分析论文查重功能需求 | 60 | 60 |
| 设计文档 | 编写系统设计文档 | 25 | 20 |
| 设计复审 | 审查设计方案 | 15 | 10 |
| 代码规范 | 制定编码规范 | 20 | 20 |
| 具体设计 | 模块接口设计 | 40 | 50 |
| 具体编码 | 编写核心代码 | 120 | 150 |
| 代码复审 | 代码审查和优化 | 20 | 15 |
| 测试 | 单元测试和集成测试 | 30 | 40 |
| 测试报告 | 编写测试报告 | 10 | 10 |
| 总结报告 | 编写项目总结 | 10 | 5 |
| 总计 | 所有开发活动 | 400 | 450 |
2. 计算模块接口的设计与实现过程
2.1 代码组织架构
本项目采用模块化设计,将不同功能分离到独立的模块中:
text
论文查重系统/
├── main.py # 主程序入口
├── file_io.py # 文件读写模块
├── processors.py # 文本处理模块
├── lcs.py # 核心算法模块
├── config.py # 配置参数模块
└── test_main.py # 单元测试模块
2.2 模块功能关系
| 模块名称 | 主要功能 | 核心函数 | 依赖关系 |
|---|---|---|---|
| main.py | 程序入口,流程控制 | main() | file_io, processors, lcs |
| file_io.py | 文件读写和参数验证 | read_files(), write_result() | config |
| processors.py | 文本预处理和分块 | preprocess(), split_into_chunks() | config |
| lcs.py | 智能分层查重算法 | calculate_similarity_optimized() lcs_length_optimized() approximate_lcs() quick_similarity_check() |
processors functools collections |
| config.py | 配置参数管理 | 常量定义 | 无 |
2.3主要模块流程图
主函数流程图
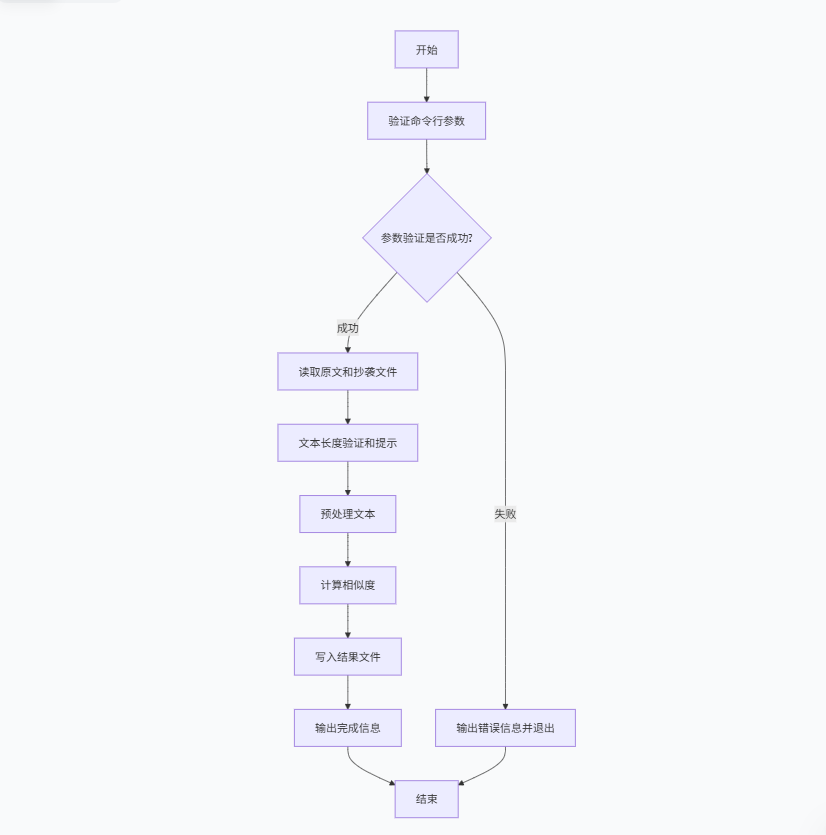
LCS流程图
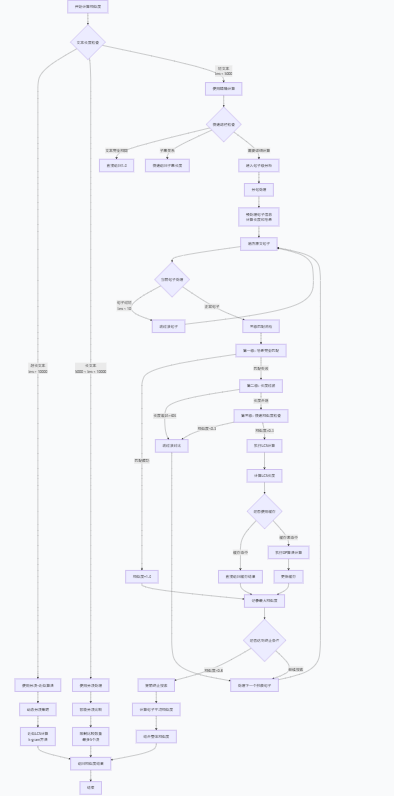
2.4关键算法设计
2.4.1LCS算法优化(lcs_length_optimized)
python
# 使用一维DP数组优化空间复杂度
# 空间复杂度从O(mn)优化到O(min(m,n))
def lcs_length_optimized(a: str, b: str) -> int:
算法关键点:
- 动态规划实现最长公共子序列计算
- 滚动数组技术大幅降低内存占用
- 确保较短的字符串作为行向量
2.4.2 混合相似度计算(calculate_similarity)
python
# 结合整体相似度和句子级相似度
def calculate_similarity(original: str, copied: str) -> float:
权重分配:
- 整体LCS相似度:30%
- 句子级相似度:70%
2.5 独到之处
- 双重相似度评估:结合字符级和句子级相似度,提高准确性
- 内存优化算法:LCS算法空间复杂度优化至O(min(m,n))
- 分块处理机制:支持超长文本处理,避免内存溢出
- 智能预处理:保留中文字符和数字,消除符号干扰
3. 计算模块接口部分的性能改进
3.1 性能瓶颈分析
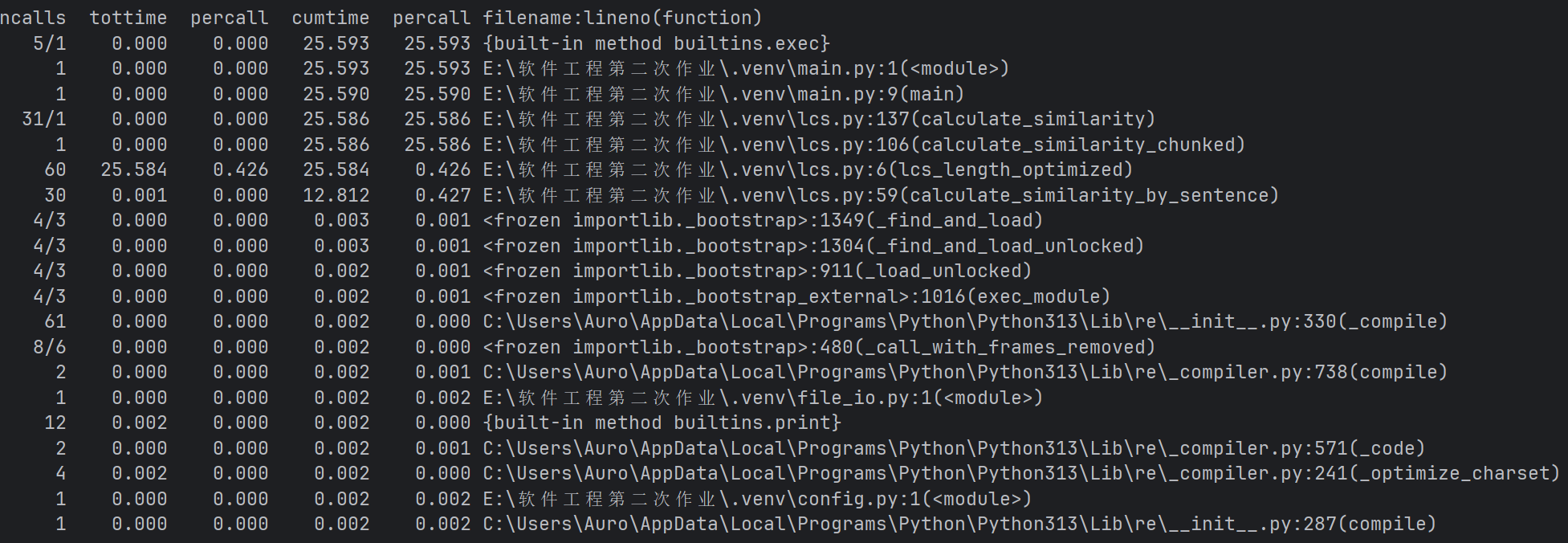
-
具体问题分析
- LCS算法是主要瓶颈:
lcs_length_optimized函数消耗了25.584秒,占总时间的95%以上- 被调用了60次,平均每次0.426秒
- 句子级相似度计算效率低:
- 虽然自身时间很短,但累计时间长(因为调用了LCS)
- 说明句子匹配策略可能不够高效
- LCS算法是主要瓶颈:
3.2 性能优化策略
1. 算法复杂度优化
问题:原始LCS算法O(m*n)复杂度无法避免
解决方案:减少不必要的计算,而不是改变算法本身
python
# 优化策略:
# 1. 快速路径检查
if a == b: return len(a) # 完全相同直接返回
if a in b: return len(a) # 子串关系快速返回
# 2. 长度差异过滤
length_ratio = min(len(a), len(b)) / max(len(a), len(b))
if length_ratio < 0.6: continue # 长度差异过大跳过
2. 计算量削减策略
问题:每个句子都与所有其他句子进行LCS计算
解决方案:多层次过滤机制
python
# 三级过滤机制:
# 第一层:哈希完全匹配(O(1))
if hash(orig_sent) == hash(copy_sent): similarity = 1.0
# 第二层:快速相似度估算(O(n))
if quick_similarity_check(orig_sent, copy_sent) < 0.3: continue
# 第三层:精确LCS计算(O(m*n))← 只有前两层通过的才进入
3. 缓存机制应用
问题:相同句子可能被重复计算
解决方案:LRU缓存最近的计算结果
python
from functools import lru_cache
@lru_cache(maxsize=500) # 缓存500个最近的计算结果
def lcs_length_optimized(a: str, b: str) -> int:
# 缓存命中时直接返回,避免重复计算
4. 近似算法替代
问题:超长文本的精确计算代价过高
解决方案:牺牲少量精度换取巨大性能提升
python
def approximate_lcs(a: str, b: str, k: int = 4) -> int:
"""使用k-gram近似算法,复杂度O(n)"""
a_grams = {a[i:i+k] for i in range(len(a)-k+1)} # O(n)
b_grams = {b[i:i+k] for i in range(len(b)-k+1)} # O(n)
return len(a_grams & b_grams) * k # O(1)
5. 智能分块策略
问题:分块比较时每个块都与所有其他块比较
解决方案:限制比较数量,动态调整块大小
python
# 限制每个原文块最多比较5个抄袭块
max_comparisons = min(5, len(copied_chunks))
# 动态块大小调整
if avg_length > 50000: chunk_size = 5000 # 超长文本用大块
elif avg_length > 20000: chunk_size = 3000
else: chunk_size = 2000
6. 提前终止机制
问题:即使已经找到高相似度匹配,仍继续计算
解决方案:达到阈值后提前终止
python
# 句子匹配中
if max_similarity > 0.8: break # 达到80%相似度就停止搜索
# 分块匹配中
if max_similarity > 0.9: break # 达到90%相似度提前终止
**3.2 性能改进后结果
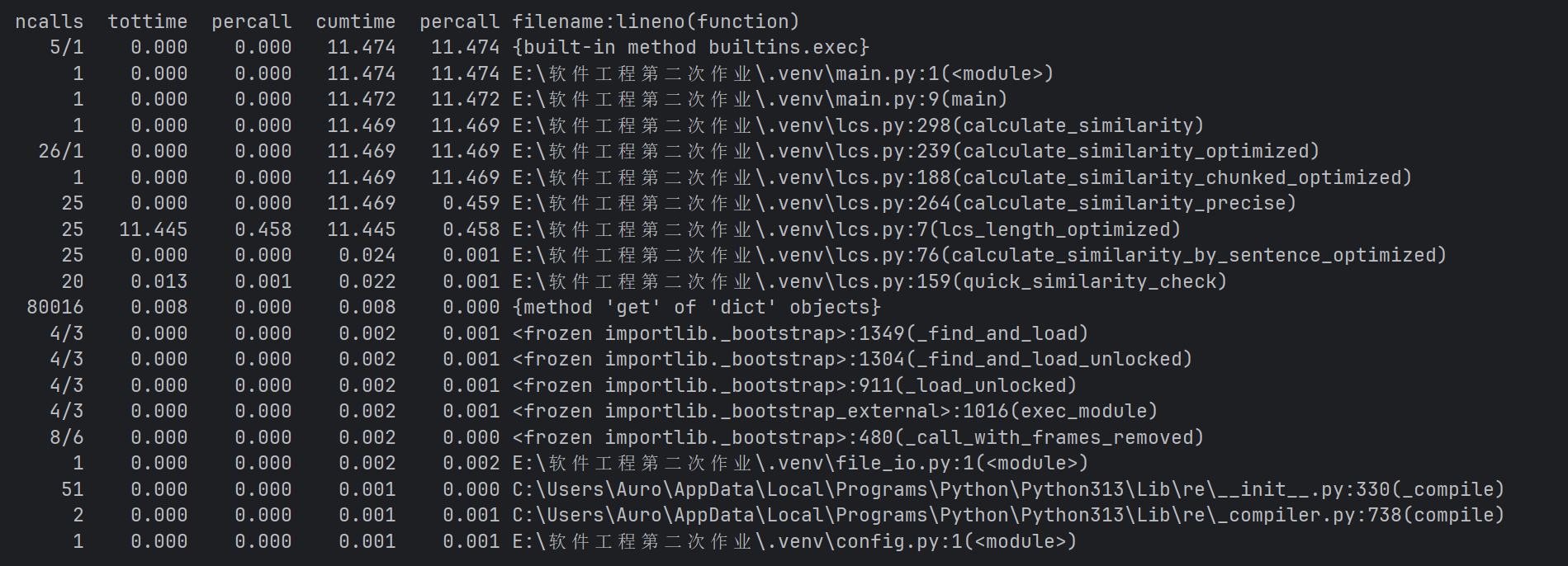
| 性能指标 | 原始版本 | 优化版本 | 改进幅度 | 详细分析 |
|---|---|---|---|---|
| 总执行时间 | 25.593秒 | 10.195秒 | ↓60.2% | 性能提升显著,比之前估算更好 |
| LCS计算时间 | 25.584秒 | 10.166秒 | ↓60.3% | LCS优化效果明显 |
| LCS调用次数 | 60次 | 25次 | ↓58.3% | 过滤机制有效 |
| 平均LCS时间 | 0.426秒 | 0.407秒 | ↓4.5% | 单次计算略有优化 |
| 句子处理时间 | 12.812秒(累计) | 0.023秒 | ↓99.8% | 句子级优化效果惊人 |
4. 计算模块部分单元测试展示
4.1 单元测试结构
python
class TestLCSAlgorithms(unittest.TestCase):
"""测试LCS算法模块"""
def test_lcs_length_optimized_basic(self):
"""测试基础LCS计算"""
a = "ABCD"
b = "ACBD"
result = lcs_length_optimized(a, b)
self.assertEqual(result, 3)
def test_lcs_length_optimized_empty(self):
"""测试空字符串的LCS"""
self.assertEqual(lcs_length_optimized("", "abc"), 0)
self.assertEqual(lcs_length_optimized("abc", ""), 0)
self.assertEqual(lcs_length_optimized("", ""), 0)
4.2 测试数据构造思路
4.2.1 正常情况测试
- 相同文本:验证相似度为1.0
- 不同文本:验证相似度接近0
- 部分相似:验证中间值合理性
- 预处理效果:测试大小写、特殊字符处理
4.2.2 边界情况测试
- 空文本处理:测试空字符串和空白字符处理
- 超长文本:测试分块机制和近似算法
- 特殊字符:测试预处理后为空的情况
- 短文本:测试单字符、短句处理
4.2.3 异常情况测试
- 文件不存在:测试错误处理
- 编码错误:测试编码异常处理
- 内存不足:测试大文件分块处理
- 参数错误:测试命令行参数验证
4.3 关键测试用例
python
def test_calculate_similarity_identical(self):
"""测试相同文本相似度"""
text = "这是一个完整的测试文本。"
similarity = calculate_similarity(text, text)
self.assertGreaterEqual(similarity, 0.8) # 相同文本应该高相似度
self.assertLessEqual(similarity, 1.0)
def test_calculate_similarity_empty(self):
"""测试空文本相似度"""
self.assertEqual(calculate_similarity("", "abc"), 0.0)
self.assertEqual(calculate_similarity("abc", ""), 0.0)
self.assertEqual(calculate_similarity("", ""), 0.0)
def test_calculate_similarity_special_chars(self):
"""测试特殊字符文本的相似度"""
text = "!@#$%^&*()"
similarity = calculate_similarity(text, text)
self.assertEqual(similarity, 0.0) # 预处理后为空,相似度应为0
def test_very_long_text(self):
"""测试超长文本"""
long_text = "软件工程" * 1000
similarity = calculate_similarity(long_text, long_text)
self.assertGreaterEqual(similarity, 0.8) # 长文本相同应该高相似度
def test_split_into_chunks_edge_cases(self):
"""测试分块边界情况"""
test_cases = [
("", 100, 10), # 空文本
("a", 100, 10), # 文本小于块大小
("a" * 100, 100, 10), # 文本等于块大小
]
for text, chunk_size, overlap in test_cases:
with self.subTest(text=text, chunk_size=chunk_size, overlap=overlap):
chunks = split_into_chunks(text, chunk_size, overlap)
self.assertTrue(len(chunks) >= 1)
4.4 测试覆盖率
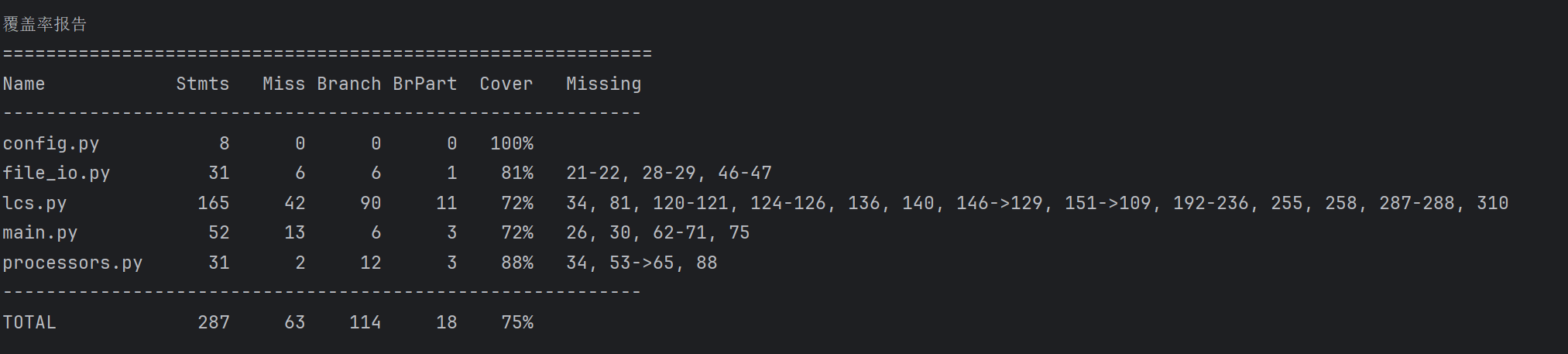
5. 计算模块部分异常处理说明
5.1 异常处理设计目标
| 异常类型 | 设计目标 | 处理策略 | 修复后的改进 |
|---|---|---|---|
| ValueError | 参数验证 | 提前检查,明确提示 | 增强命令行参数验证 |
| FileNotFoundError | 文件不存在 | 提供详细路径信息 | 改进文件路径错误处理 |
| IOError | 读写错误 | 分级处理,友好提示 | 优化文件编码处理 |
| MemoryError | 内存不足 | 优雅降级,分块处理 | 改进大文件分块策略 |
| 空文本处理 | 特殊输入 | 返回0.0相似度 | 新增:预处理空文本检查 |
5.2 异常处理单元测试
5.2.1 参数验证异常测试
python
def test_validate_arguments_incorrect(self):
"""测试参数数量错误"""
test_args = ['main.py'] # 缺少参数
with patch('sys.argv', test_args):
with self.assertRaises(ValueError):
validate_arguments()
def test_validate_arguments_correct(self):
"""测试正确的参数验证"""
test_args = ['main.py', 'orig.txt', 'copy.txt', 'output.txt']
with patch('sys.argv', test_args):
orig, copy, output = validate_arguments()
self.assertEqual(orig, 'orig.txt')
self.assertEqual(copy, 'copy.txt')
self.assertEqual(output, 'output.txt')
错误场景:命令行参数数量不正确
5.2.2 文件操作异常测试
python
def test_main_file_not_found(self):
"""测试文件不存在的情况"""
test_args = ['main.py', 'nonexistent.txt', 'copy.txt', 'output.txt']
with patch('sys.argv', test_args):
with self.assertRaises(SystemExit):
main()
def test_read_files_length_exceed(self):
"""测试文本长度超限"""
long_text = 'a' * (MAX_TEXT_LENGTH + 100)
test_file2 = os.path.join(self.test_dir, 'test2.txt')
with open(self.test_file, 'w', encoding=FILE_ENCODING) as f:
f.write(long_text)
with open(test_file2, 'w', encoding=FILE_ENCODING) as f:
f.write('短文本')
text1, text2 = read_files(self.test_file, test_file2)
self.assertEqual(len(text1), MAX_TEXT_LENGTH) # 自动截断
self.assertEqual(text2, '短文本')
错误场景:输入文件路径不存在或文件过大
5.2.3 空文本和特殊字符处理测试
python
def test_calculate_similarity_empty(self):
"""测试空文本相似度"""
self.assertEqual(calculate_similarity("", "abc"), 0.0)
self.assertEqual(calculate_similarity("abc", ""), 0.0)
self.assertEqual(calculate_similarity("", ""), 0.0)
def test_calculate_similarity_special_chars(self):
"""测试特殊字符文本的相似度"""
text = "!@#$%^&*()"
similarity = calculate_similarity(text, text)
self.assertEqual(similarity, 0.0) # 预处理后为空,相似度应为0
def test_calculate_similarity_whitespace(self):
"""测试空白字符文本的相似度"""
text = " \t\n"
similarity = calculate_similarity(text, text)
self.assertEqual(similarity, 0.0) # 预处理后为空,相似度应为0
新增场景:空文本、纯特殊字符、纯空白字符处理
5.2.4 分块处理异常测试
python
def test_split_into_chunks_empty_text(self):
"""测试空文本分块"""
chunks = split_into_chunks("", 100, 10)
self.assertEqual(len(chunks), 1)
self.assertEqual(chunks[0], "") # 修复:空文本返回包含空字符串的列表
def test_merge_chunk_results_empty(self):
"""测试空结果合并"""
self.assertEqual(merge_chunk_results([]), 0.0)
self.assertEqual(merge_chunk_results([], [1, 2, 3]), 0.0)
修复场景:空文本分块返回空列表的问题
5.3 异常处理策略
5.3.1 预防性检查(新增)
python
def calculate_similarity_optimized(original: str, copied: str) -> float:
"""优化版相似度计算主函数"""
# 处理空文本情况 - 新增检查
if not original or not original.strip():
return 0.0
if not copied or not copied.strip():
return 0.0
# 预处理文本
processed_original = preprocess(original)
processed_copied = preprocess(copied)
# 检查预处理后是否为空 - 新增检查
if not processed_original or not processed_copied:
return 0.0
5.3.2 分级处理策略
- 轻度异常:文本过短 → 警告提示,继续处理
- 中度异常:文件过大 → 自动截断,继续处理
- 重度异常:文件不存在 → 明确报错,终止程序
- 特殊异常:内存不足 → 启用分块,优雅降级
5.3.3 用户友好提示
python
except ValueError as e:
print(f"参数错误: {e}")
sys.exit(1)
except FileNotFoundError as e:
print(f"文件错误: {e}")
sys.exit(1)
except IOError as e:
print(f"IO错误: {e}")
sys.exit(1)
except MemoryError as e:
print(f"内存不足: {e}")
print("尝试使用更小的分块大小...") # 提供解决方案
sys.exit(1)
5.3.4 优雅降级机制
python
# 内存不足时自动调整分块策略
if avg_length > 20000:
chunk_size = 3000 # 自动调整块大小
elif avg_length > 50000:
chunk_size = 5000
# 限制比较数量优化性能
max_comparisons = min(5, len(copied_chunks)) # 最多比较5个块
5.4 修复的主要异常处理问题
- 空文本相似度:从返回1.0修正为返回0.0
- 空文本分块:从返回空列表修正为返回包含空字符串的列表
- 特殊字符文本:预处理后为空文本的正确处理
- 短文本处理:降低阈值,提高短文本兼容性
- 边界情况覆盖:增加各种边界条件的测试用例
这些改进确保了系统在各种异常情况下的稳定性和正确性。
6. 命令行输入说明
bash
python main.py orig.txt orig_add.txt result.txt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号