


python 爬取 段子网 实例
今天开始了对之前操作的代码的更改跟改错。
上期的内容中间的日期,热度,点赞数量没有爬取出来,今天做了以下修改,成功的爬取到了我们想要的内容。
改错的内容:第二行出现空值问题,显示不出来 下面是运行出现的问题 第一个

这个第二个是我们修改过的代码 还有下面的运行结果
上边就是所作的修改,因为我们用常规方法没有获取到,所以选用了另外的一种 循环的方式,把三个代码分离出来。
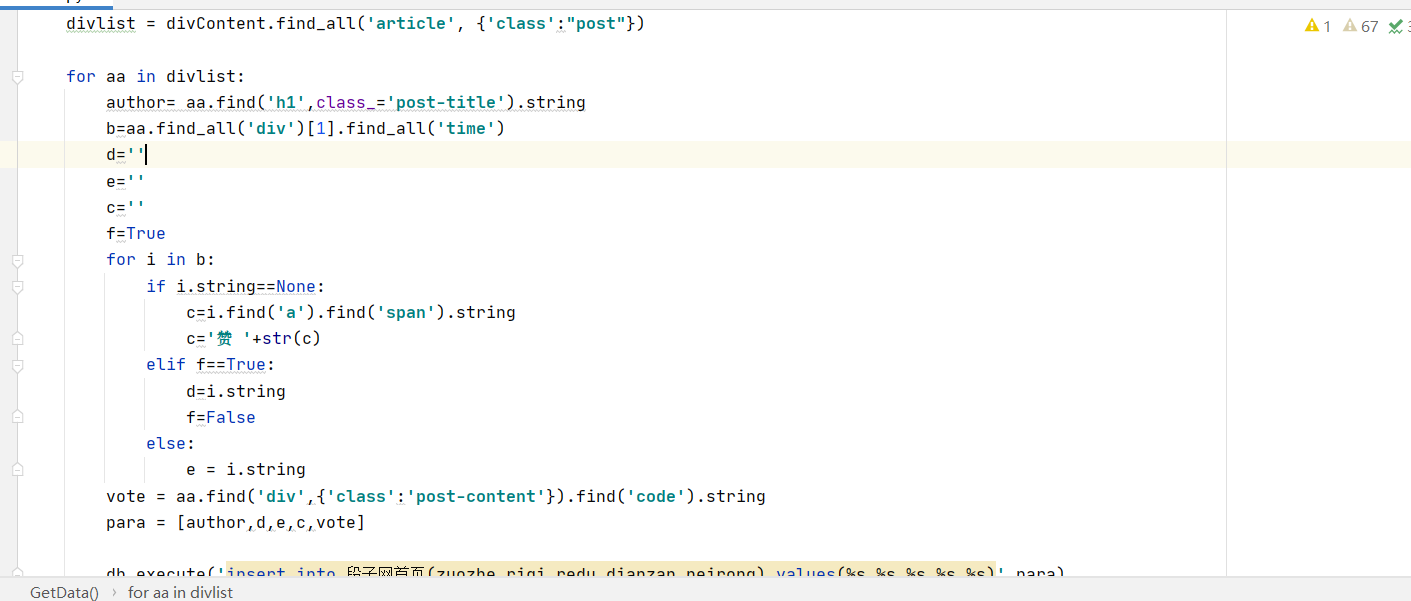
最终也是成功获取到了数据, 这里我直接连接数据库,所以我截取的是数据库的数据,就是我们抓取的
红色位置是上次所没有抓取到的内容
获取数据有很多种方式
-
往往不是我们抓取代码有问题
-
有可能是类型的问题
-
可能会出现某个标点符号
-
可能是标签的问题
反正有很多种。你应该多多去看一下前辈的代码,前面也学过,可能时间有点久,你忘记了,所以以后不管学到的那些代码,一定要保存起来,说不定哪一天会用的到。
虽然数据抓取到了,但是我们就该从抓取到的内容开始下手了,
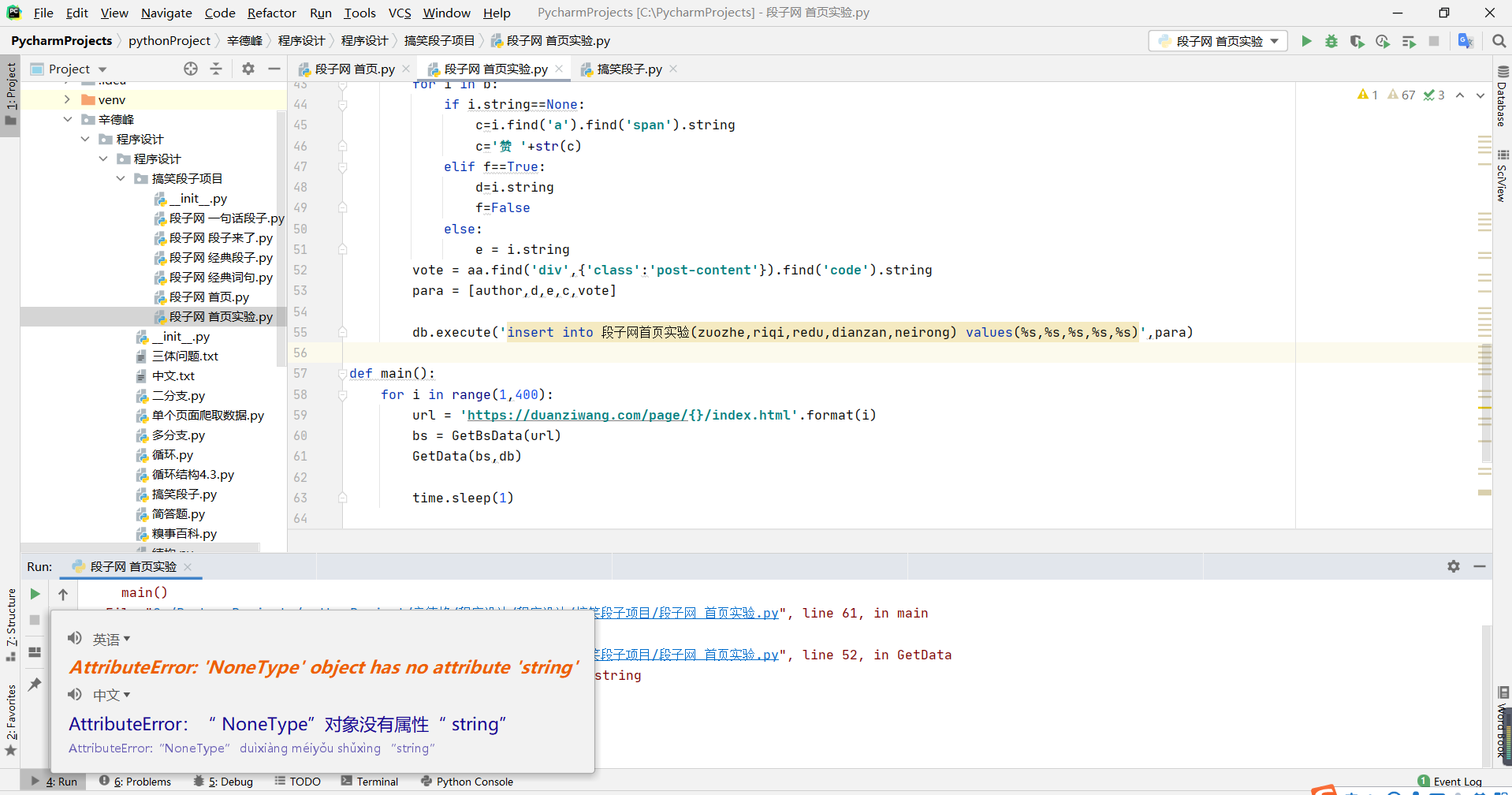
今天所做内容就是在抓取大量数据的时候所出现的问题,某一个标签在抓取的时候缺少一个属性,导致我们抓取的时候,直接报错,终止抓取,我们一起来看一下
这个是我把错误翻译了一下,方便你们阅读
这个是没有翻译版的
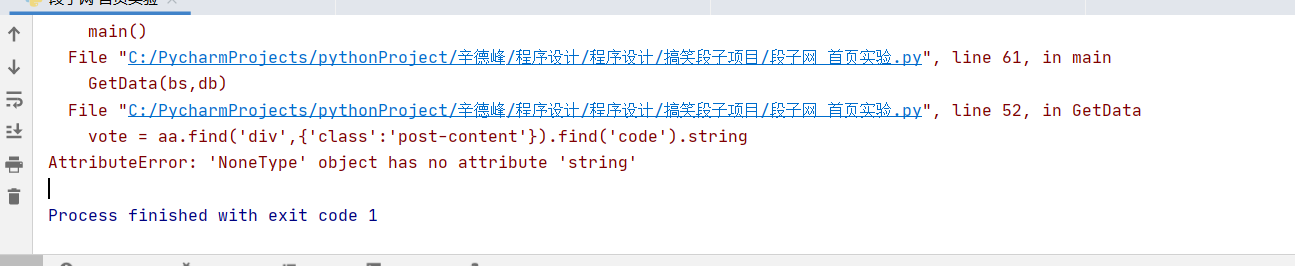
我们一起来看一下,他所说的就是在爬取过程中缺少了一个属性:string
string :简单的说字符串String就是使用引号定义的一组可以包含数字,字母,符号(非特殊系统符号)的集合
我们缺少他的话,说明下面没有我们所需要的内容,你就要去找一下了
还好我是连接数据库去抓取的,所以我可以根据数据库去确定他的错误位置,
当你连接数据库去抓取的话,当他们报错的话,会终止程序的,但是万幸的是我用的循环抓取方式,每抓取一个就会存储一个,所以我们抓取的数据不会丢,但是常规来说的话,是不会用这一种方式,因为工作以后抓取的代码都是很大的量,不会去一遍一遍的抓取,存储,他只会当抓取完成,会一并存储,当有一个地方出现问题,他就会停止,并且所有数据都会消失。
所以说练习的话最好采用我这一种方式,当出现问题,也不会丢失数据。
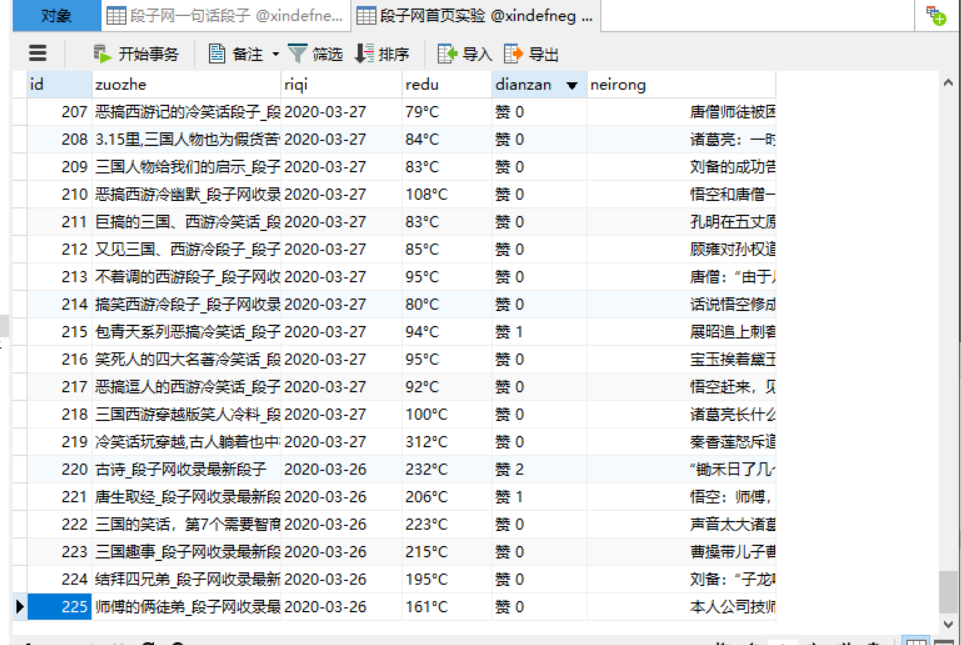
我们一起来看一下错误,根据数据库的数据,225条 我找到了他的位置
因为我抓取的网页,每页数据是10条,所以225就是第22页的第5个,但是我们数据库第5个出来了,我们就从第6个来看一下。
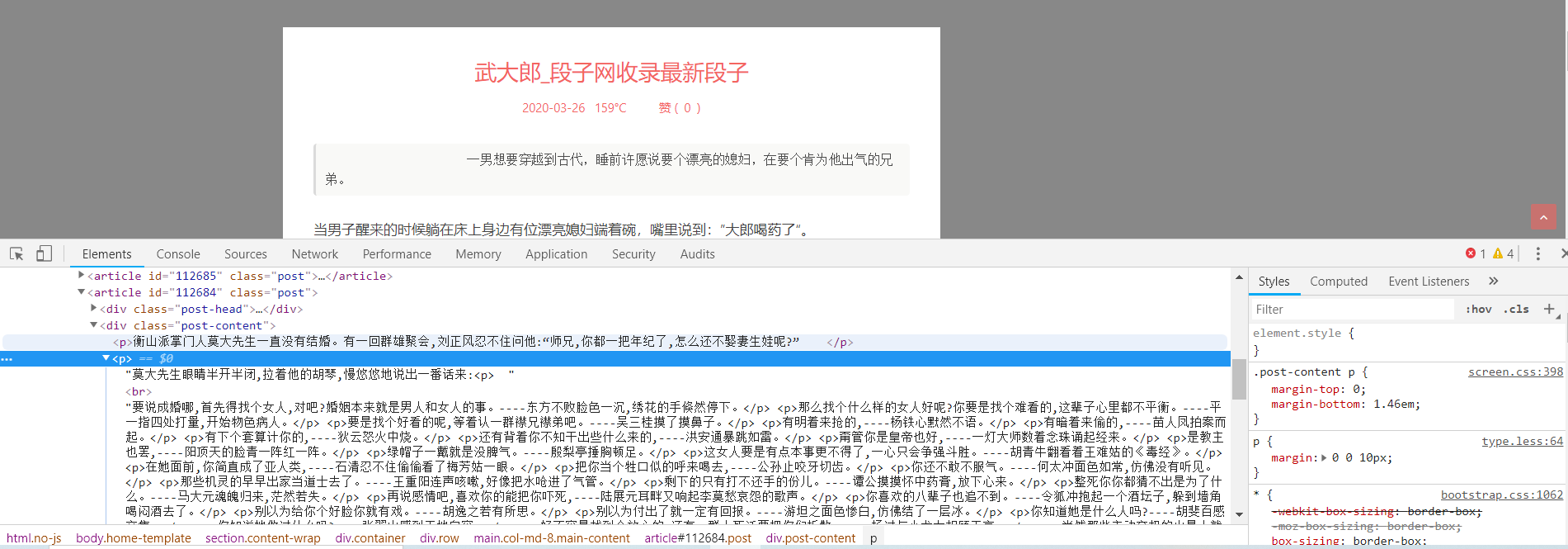
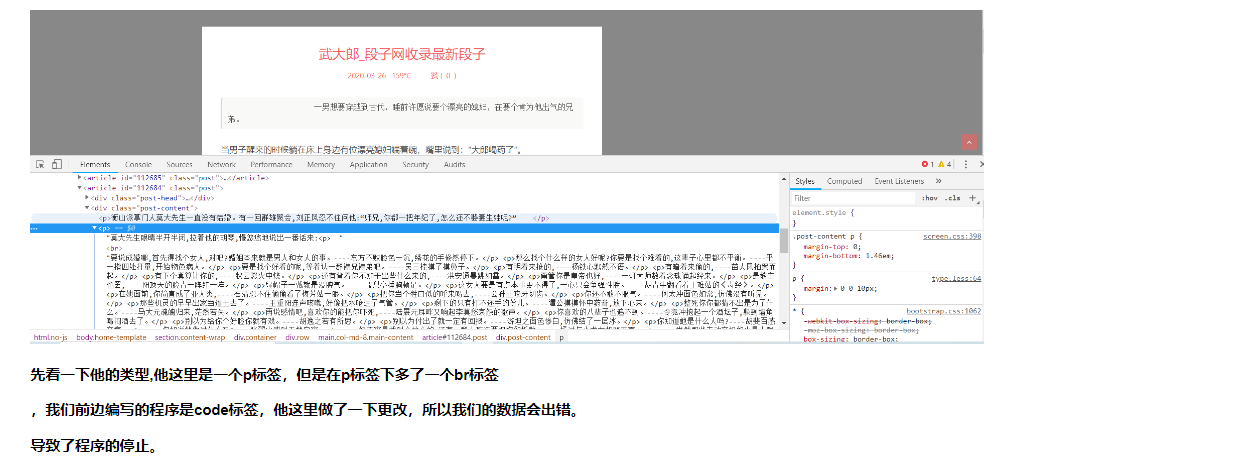
先看一下他的类型,他这里是一个p标签,但是在p标签下多了一个br标签
,我们前边编写的程序是code标签,他这里做了一下更改,所以我们的数据会出错。
导致了程序的停止。
既然问题找到了,我们就要去攻克它,
但是今天时间有限,因为今天有新的任务,就是把网页做一下分析,导致了这个问题搁浅到这,
但是问题找到了,明天就可以直接找他的解决办法了,所以方便了很多,加个*记录一下明天更改
**********************************
所谓的网页分析就是你需要的东西在那个地方,要怎样下手,
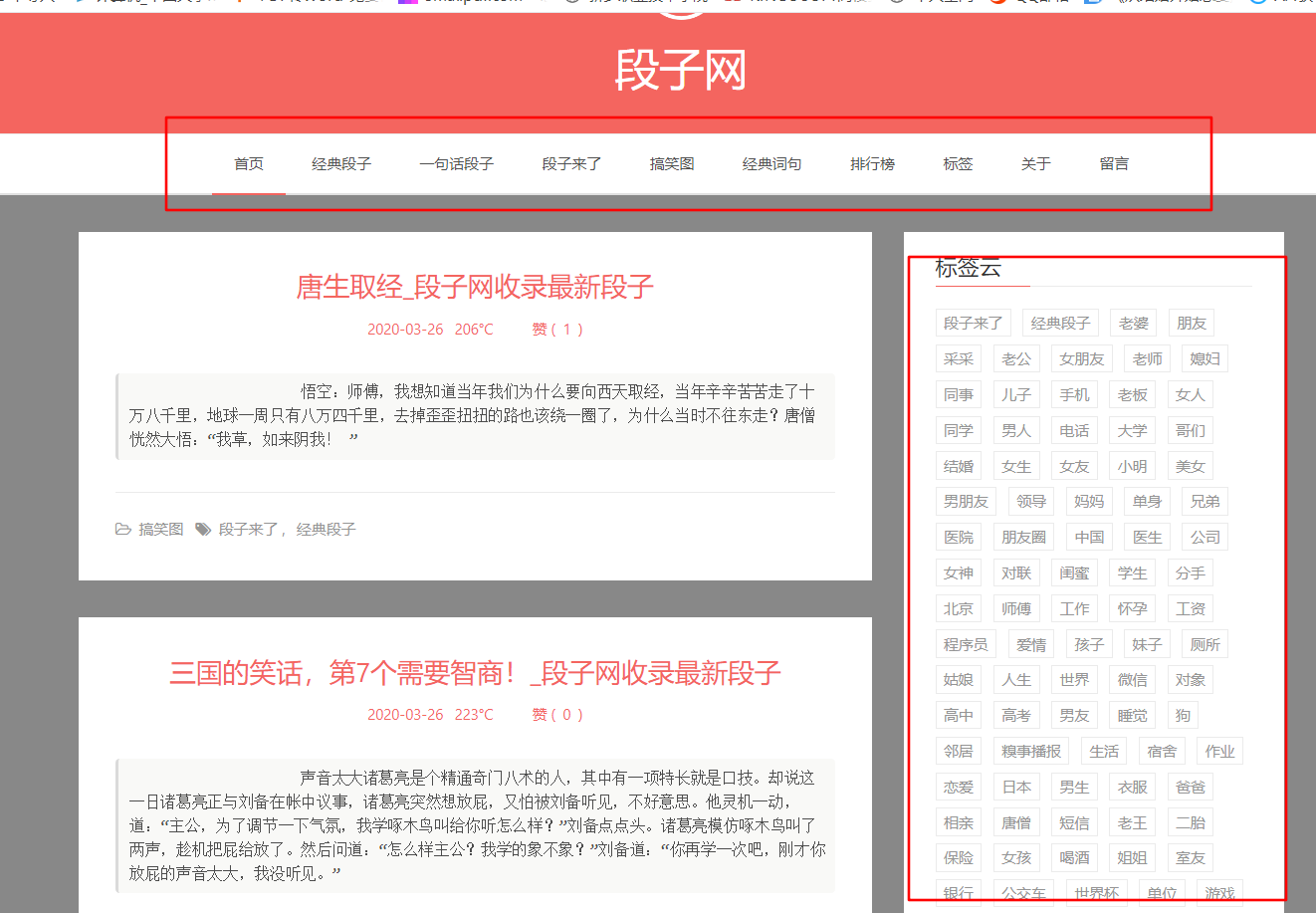
先分析网页的组成
-
标题栏:首页,经典段子,一句话段子,段子来了等
-
标签页: 老婆,朋友,采采,老公等
-
用户投稿:1+1+1+1+1+1+1
因为我们是一个团队去爬取一个网页,所以各有分工,其他人的工作等我整理之后在补充上来
我的工作就是爬取用户数据,所以我把网页细分了一下
示例:标签栏
因为每个页面的数据要单独存放,所以我们要先分析一共有几个,我们要创建相应的数据库,跟数据表
-
经典段子
-
一句话段子
-
首页
-
段子来了
时间有限,就先做了这四个,
这是相应的数据表
因为没有创建自动化抓取,所以我们要把程序也分开,但是要把他们都一一对应。
要不然会出问题的
程序 1= 数据1= 数据表 1
程序 2= 数据2= 数据表 2
程序 3= 数据3= 数据表 3
程序 4= 数据4= 数据表 4
程序:

这就是今天所学习的东西,不太完整,等我后期整理会发布完整版的。
第三天
先来看一下上期,我标注的那个问题,今天又看了一下代码, 就直接发现了问题的所在
首先上一次是直接抓取的是 code标签 ,我的四个程序都发现了此类的问题,我就去一个一个看了看,发现我更改了一下抓取方式
我之前的话是直接抓取到了,文本类型的哪一个根目录,我就想了一下,看下面有没有类似的,如果没有类似的话,我们就可以直接从哪一个标签的上一个标签抓取,没有必要直接抓取到根目录,这是我看到的一共两种方式
第一种: div标签下面有一个p标签,而且在p标签下面还有一个br标签

第二种: div标签下面有一个pre标签 在pre标签下还有一个code

因为在他的下面就只有(p标签或者pre标签)所以我们就没有必要去筛选他到底是神魔类型,可以直接抓取他的上层目录,因为他们就只有div标签下有变动,但是两个的div标签都一样,所以我们就直接抓取他的div标签
div标签为
('div',{'class':'post-content'})
所以我把程序更改成这样,
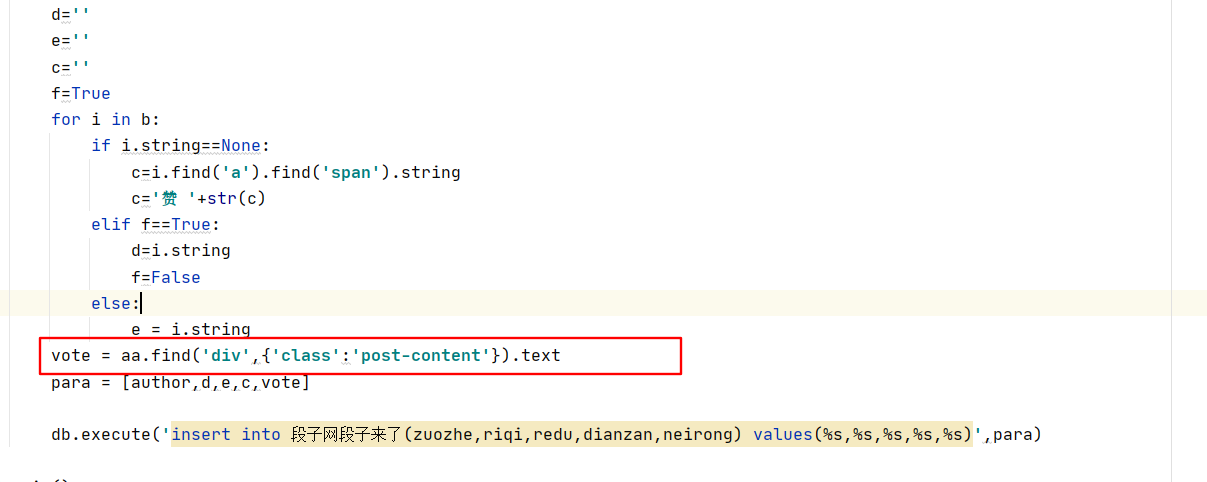
我直接把根目录直接删除掉了,他现在抓取的意思就是抓取div标签下的 文本类型
我运行下来也不会出现类似的问题了。
下面就是我今天抓取的内容,来看一下吧
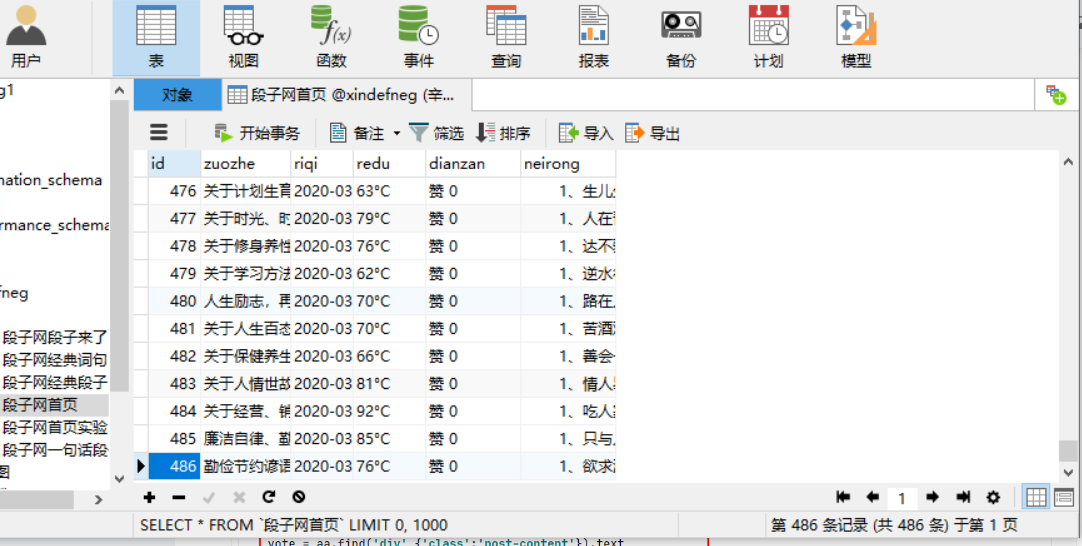
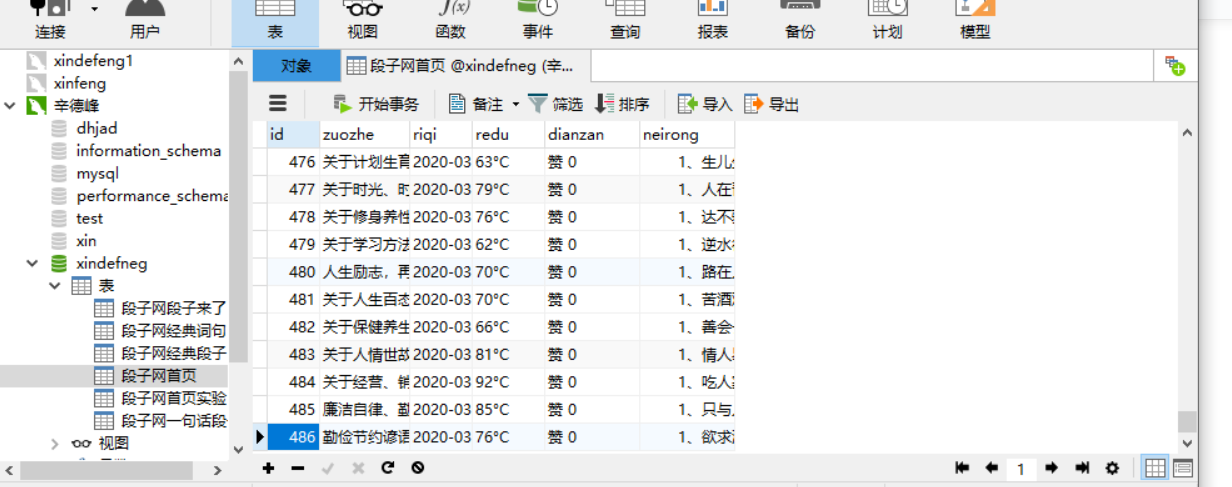
之前到225报错了,所以我直接把他删了,然后又新创了一个数据表,现在可以看到,抓取到了486,不是我不想抓,是因为他只有折磨多,说到这我们这个问题就完美解决了,通俗来讲就是,用不着就不要了,加上行业语言就是,直接抓他父辈。管他儿子干嘛。
但是到了这里说一下为神魔只抓取了486条数据,细心一点的朋友可能就直接提出来了,他不是有11226页数据么,来我们来看一下
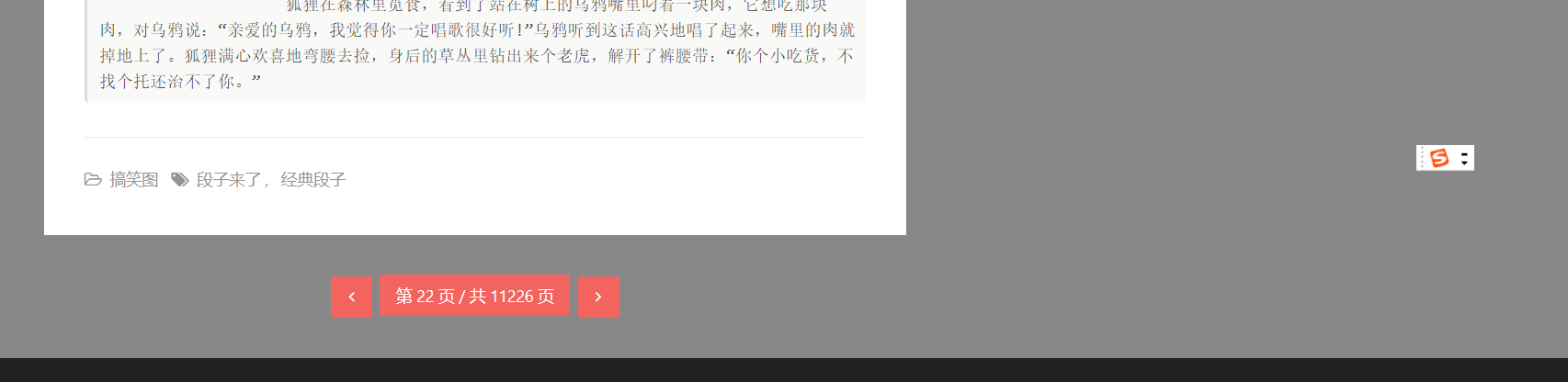
他确实是11226页数据,这就牵扯到了,今天遇到的另外一个问题,照常先来看一下问题代码


问题代码:AttributeError: 'NoneType' object has no attribute 'find_all'
按照他所说的就是没有这个属性
可以看到我设置的是抓取从1-600页数据,我从数据库直接查到的 数据问题点出在第50页,(前面有说过怎么查这里就不再细说)
我们来看一下50页的网页
因为他50页是推广,我就看了一下51页的主页

后边都一样,都是推广,他是就50页有数据,其他的都是假的,真想说一句:真他妈的坑爹,问题不少吧,数据还折磨少,白浪费时间,这个问题自然无法解决,但是也让我们明白了一个道理
在选择网页的时候,一定要看一看他的网页数据是不是完整的额,如果你仔细筛选的话,就不会出现今天这个问题了
但是其他的还好,其他的都是持续到底,先来看一下今天抓取的数据吧



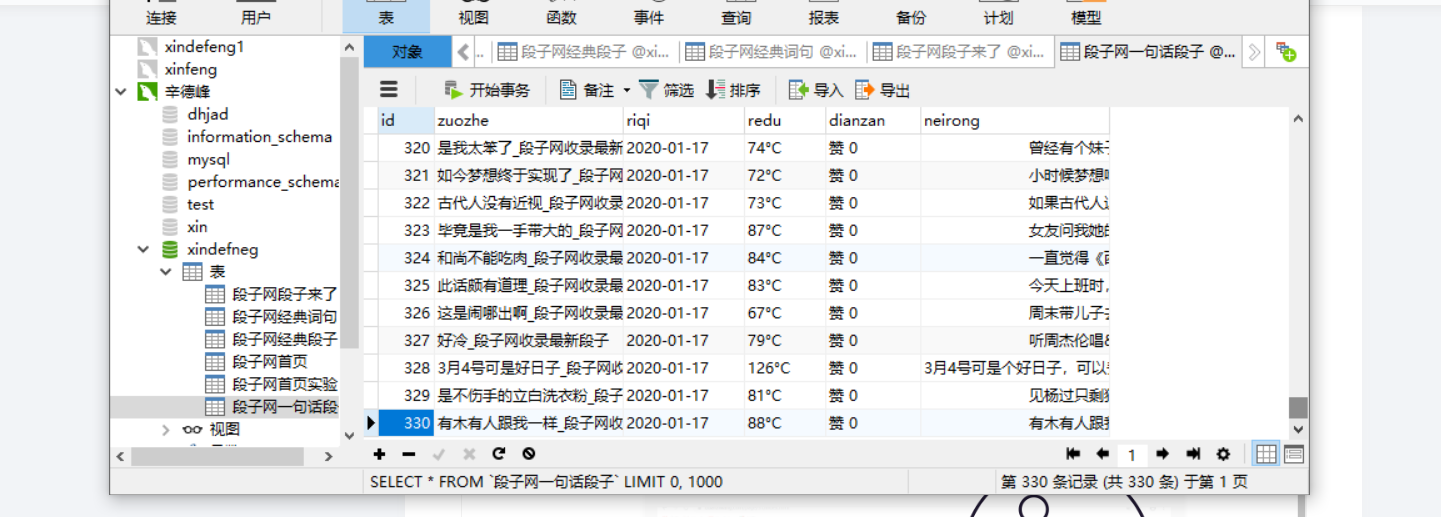
今天还有一个问题就是在抓取数据传输数据库的时候,出现的,说的是neirong哪一个字段名太短
网页数据太长存储不下,来我们看一下我们的设计表

我设计的已经够多了,8000还能出现这个问题,我真是服了,在百度找了好久,虽然有几家类似的,但是解决办法也各不一样最后找到解决办法还是问的同事,然后我感觉我的知识太少了,原来就是一个类型的问题,是这一个类型储存的数据到达限度了,
换了一个类型就是直接解决了我换的是
这是两个类型你们可以保存一下
1.longtext字段类型:longtext字段类型的字节限制为2147483647字节。
2.mediumtext字段类型:mediumtext字段类型的字节限制为16777215字节。
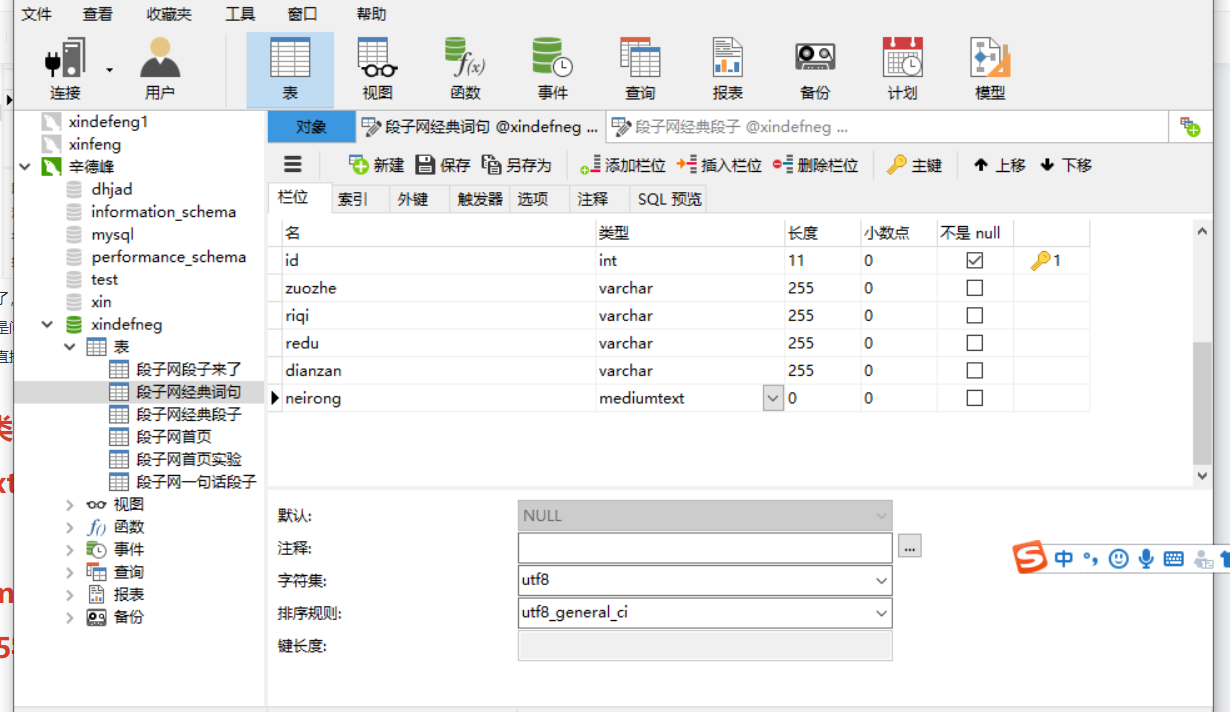
这是我更改过的
第四天
今天所写内容,对于我来讲,还没有完全熟悉我自己也在学习,完全是在老师跟同学的帮助下才进一步做的优化,主要当时只学习了代码,但是没有达到完全运用的程度,当然看的话肯定都能看得懂。用当下流行的话就是, 脑子:我会了 然后手不服气了,手:来来来,你来
所以我只能大致的给你们讲一下他的作用:
还是先看程序


之前我们的自增长都是在数据库里面直接设置成功,但在老师的要求下,把它更改成在pcthon里面写程序的时候,直接把它写出来具体的我也没有多说的必要,因为我每行代码加的都有备注,
我所标注的内容是整个自增长的过程,他是在网页抓取到数据然后把抓取到的标题直接设置成自增长。
这里有个知识点来看一下:
global :在全局都能使用,没有位置限制
看一下他的成果:

这就是所作的这个自增长的内容,完全是程序运行过程中,它自动添加进去的,但是不要忘记虽然是自动抓取的,但是你也要连接数据库,才能把东西放进去,第二个图就是连接数据库,这里你可能看不懂,当时当我把所有代码发出来的时候你都能看懂了,
这个就是更改过的传输数据库的代码这里用到了一个元素 k 是我们下面的内容,这里只是一个调用。

这一共两个表,我先放出来
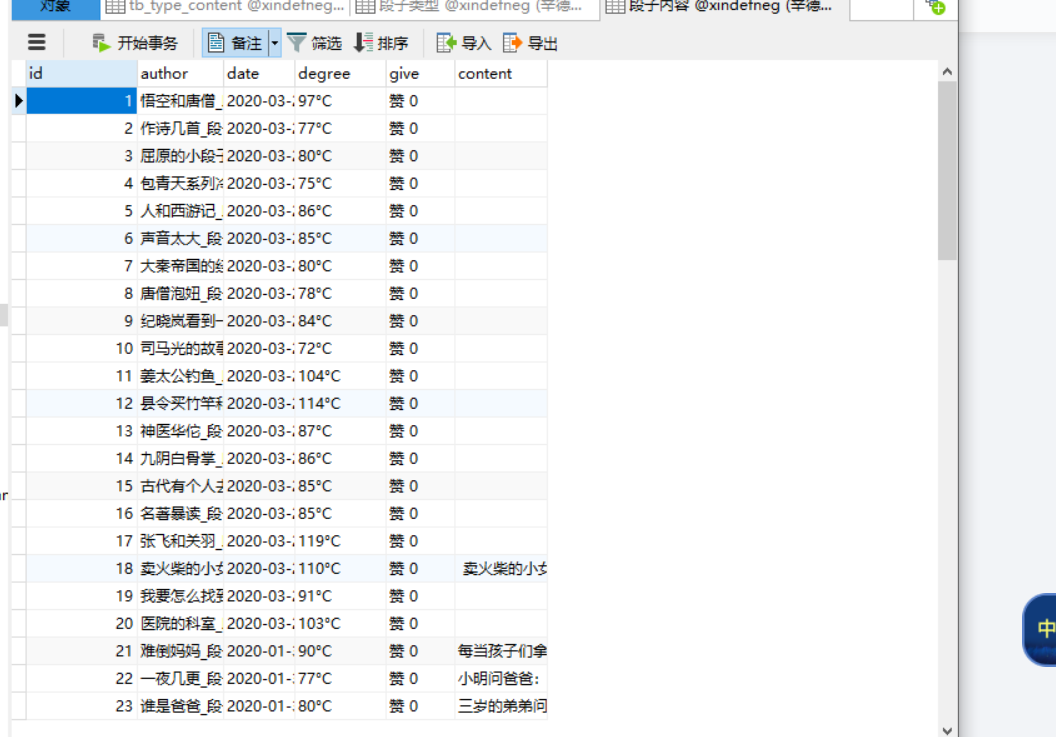
这个表就是把我们之前所抓取的所有标签的内容,全部总和到一起,然后还不是混乱的状态,后边调用的时候,能直接分开,因为我们每个内容都加着标签,相互之间都有链接,
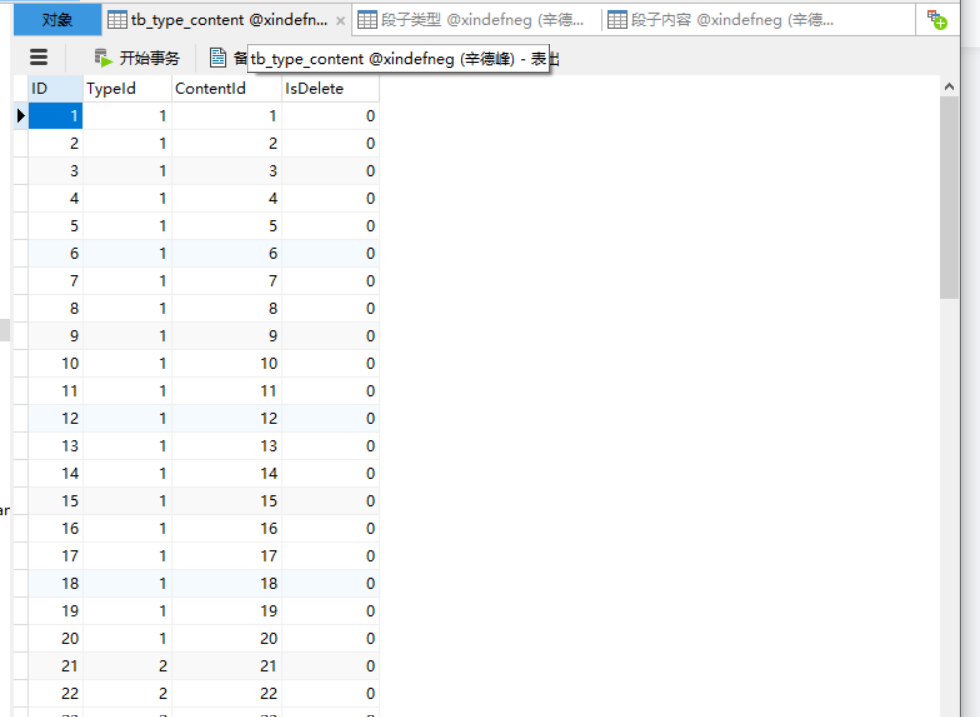
这一个就是我们的关联表了,就是把数据类型跟数据内容两个表联系起来,然后把它们的关联方式做成一个单独的表关联起来,这个表也是在程序中直接运行并自动生成的,方便我们以后调取的时候方便,也为了把工作交接的时候,人家也能直接看懂。这个是以后工作以后要用到的
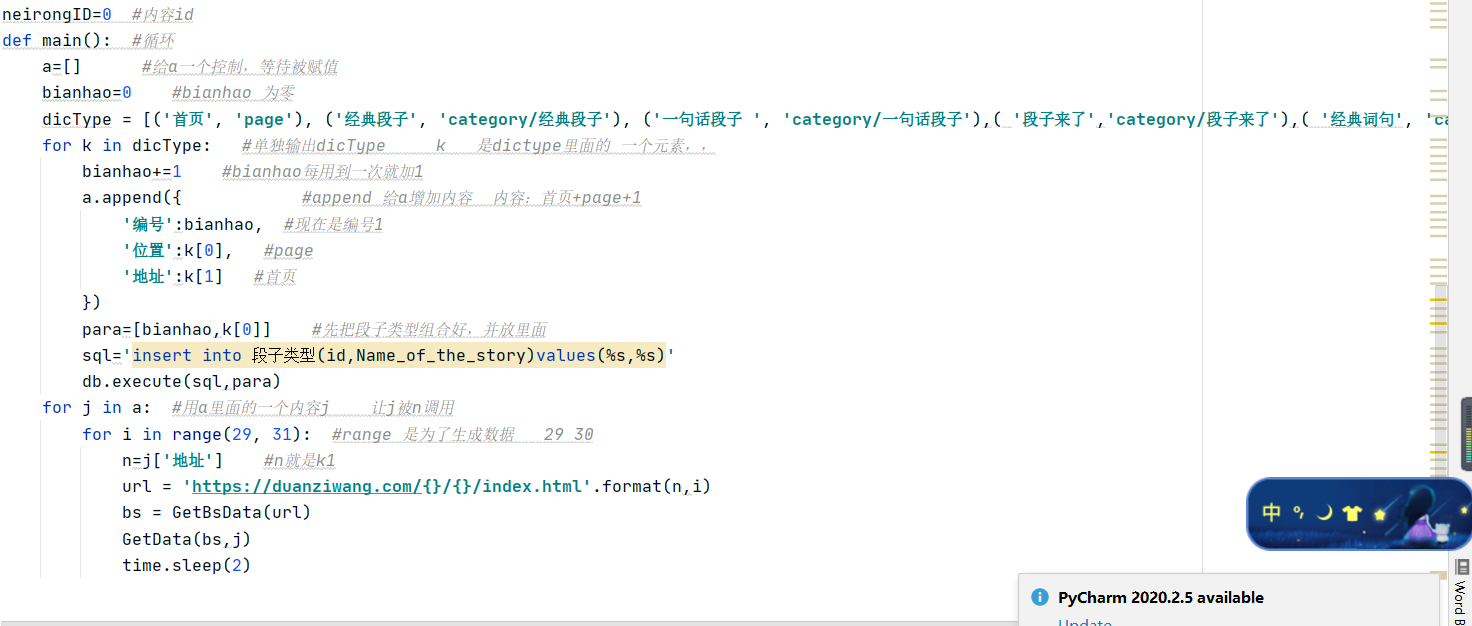
这一张就是我们网址所有的循环的了,之前的话是我们单个标签抓取的,所以我们只需要循环后缀的页数就行了,更改之后就是,我们把标签的元素也加入了进去,让标签也是一个循环,就是我们不需要一个一个标签去单独抓取了,直接把它们放到一起,让他们组合调用,一块抓取,这里面定义的元素比较多,大家一定要仔细看看,我上面都有备注,你们可以借鉴一下,写备注的时候还是自己写自己的备注,毕竟每个人的方式不一样,写自己的,后边你再去看的话,也能看得懂。,这一个项目到这也就结束了,下面我把所有的代码给大家分享一下,
import time
|
这个是最后优化后的代码,
还有数据表的设计类型
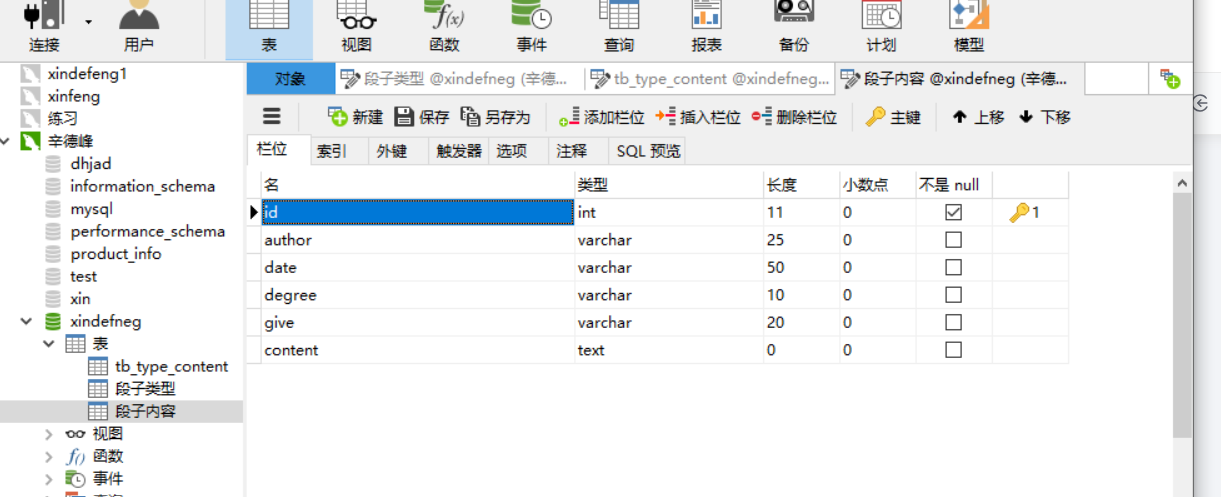
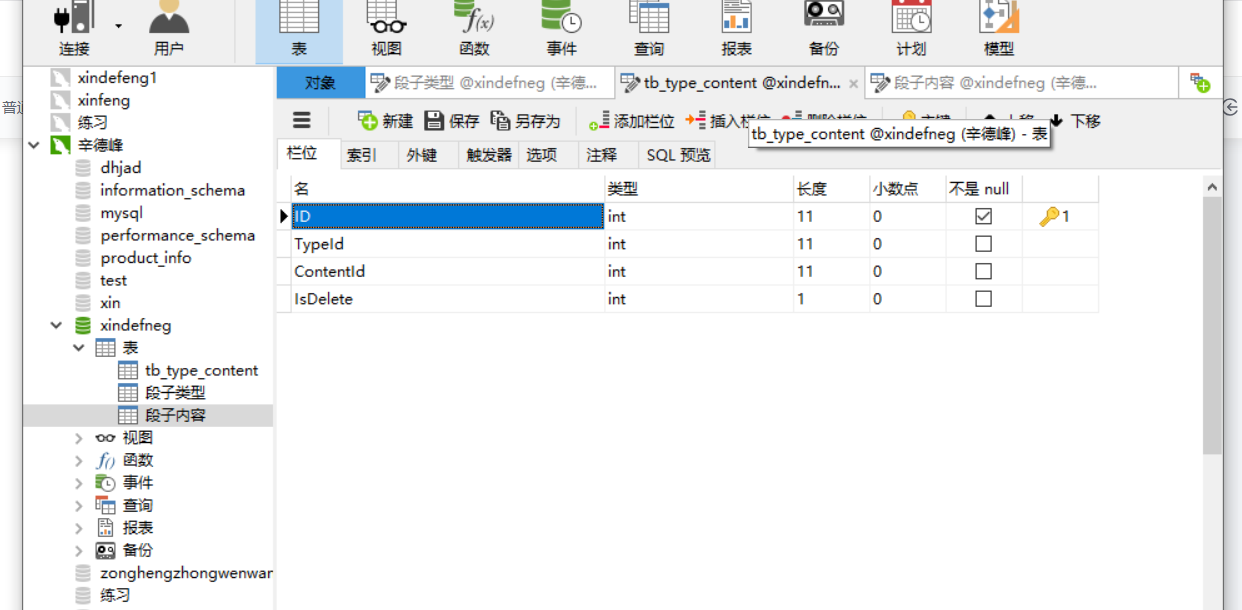
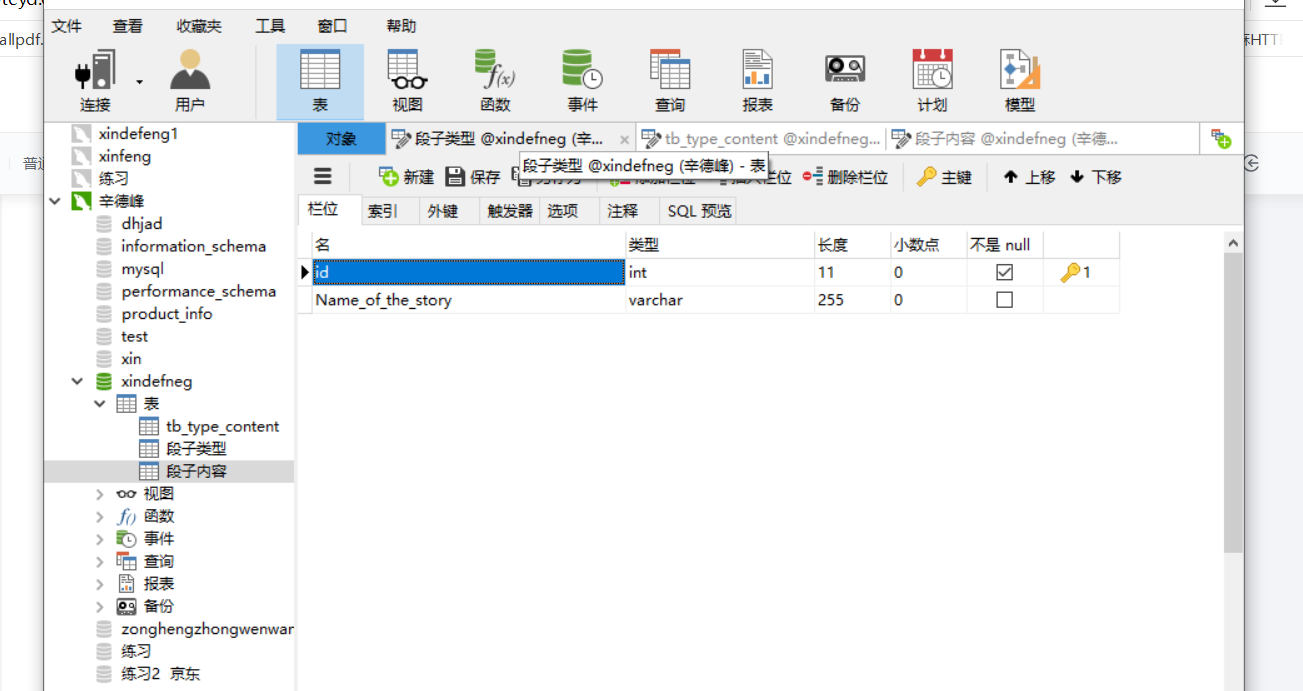
到这也就完全结束,再见了大家
|
项目组人员 |
辛德峰 马草原,张帅军,樊彪 李金洋,张金亮,曹贺朋 |
|
|
参与指导 |
张一凡 : |
百科宝典 最多知识,简直就是一个行动的知识库 |
|
指导教师 |
安老师: 安建勇 吴老师: 吴莹 |
|


 浙公网安备 33010602011771号
浙公网安备 33010602011771号