
hadoop02
1.配置文件
hadoop的默认配置文件都在$HADOOP_HOME/share下,先读取这个默认值,再读取etc中用户配置的值,用户配置的值将覆盖默认值
cd $HADOOP_HOME/share
mkdir -p /data/test find -name "*-default.xml" -exec cp {} /data/test \;
在hdfs-default.xml中查找dfs.blocksize,可以看到值为128M
<property> <name>dfs.blocksize</name> <value>134217728</value> <description> The default block size for new files, in bytes. You can use the following suffix (case insensitive): k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.), Or provide complete size in bytes (such as 134217728 for 128 MB). </description> </property>
2.namenode
2.1持久化存储
name的元数据保存在内存里,同时也会持久化到fsimage映像文件和edits日志文件,每隔一定时间保存一次内存中目录树的所有信息为fsimage映像文件,默认fsimage映像文件为两份。edit日志中是从上一次保存fsimage后再进行事务操作的日志。这两个文件所在的目录为$HADOOP_HOME/tmp/dfs/name/current。
使用XML格式查看fsimage文件
hdfs oiv -i fsimage_0000000000000003865 -o /data/test/fs.xml -p XML
使用XML格式查看edit文件
hdfs oev -i edits_0000000000000004038-0000000000000004039 -o /data/test/eidt.xml -p XML
namenode启动集群的流程:
-->加载name目录下的fsimage文件
-->加载edit日志文件
-->保存检查点:终止之前正在使用的edit文件,创建一个空的edit日志文件,然后将所有为合并的edit日志文件和fsimage文件进行合并,产生一个新的fsimage
-->安全模式:处于安全模式下,等待datanode节点的心跳反馈,当收到99.9%的块的至少一个副本后,退出安全模式,开始转为正常状态。
非第一次启动集群时默认99.9%的块是可用的,且最小副本级别为1才会退出安全模式,处于安全模式的集群是不允许操作的。第一次启动集群时fsimage和edit都是没有的,是不进安全模式的。
安全模式相关的主要配置在hdfs-site.xml文件中,主要有下面几个属性:
1.dfs.namenode.replication.min 最小的文件block副本数量,默认为1 2.dfs.namenode.safemode.threshold-pct: 副本数达到最小要求的block占系总系统block数的百分比,当实际比例超过该配置后,才能离开安全模式。默认为99.9% 3.dfs.namenode.safemode.min.extension: 离开安全模式的最小可用datanode数量要求,默认为0. 4.dfs.namenode.safemode.extension: 在满足退出安全模式的条件后,再经过extension配置的时间才能退出安全模式。单位为毫秒,默认为1.
查看namenode是否处于安全模式
hdfs dfsadmin -safemode get
管理员可以随时让Namenode进入或者离开安全模式,这项功能在维护和升级集群时非常关键
#进入安全模式 hdfs dfsadmin -safemode enter #离开安全模式 hdfs dfsadmin -safemode leave
滚动edit日志
1.强制滚动 hdfs dfsadmin -rollEdits 2.可以等到edit.inprogress满64m生成edits文件 3.可以等操作数量打到100万次 4.时间到了,默认1小时 注意:在2 3 4时发生滚动,会进行checkpoint
2.2Namenode和Datanode的通信(心跳机制)
namenode启动后,会主动开启一个IPC服务,等待datanode的链接,在datanode链接后,会默认每隔3秒互相链接一次。当namenode长时间没有收到datanode信息时,会认为datanode挂了。
超时时间默认为10分钟30秒
属性:dfs.namenode.heartbeat.recheck-interval 的默认值为5分钟 recheck的时间单位为毫秒 属性:dfs.heartbeat.interval 的默认值为3秒 超时时间计算公式:2*recheck+10*heartbeat
2.3SecondayNamenode的工作机制(检查点机制)
SecondayNamenode是辅助namenode进行fsimage和editlog的合并工作,减小editlog文件大小,以缩短下次namenode的重启时间,能尽快退出安全模式。
两个文件的合并周期,称之为检查点机制(checkpoint),是可以通过hdfs-default.xml配置文件进行修改的
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
<description>两次检查点相隔的时间,默认为1个小时</description>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>txid执行的次数达到100w次,执行checkpoint</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>60秒检查一次txid的执行次数</description>
</property>
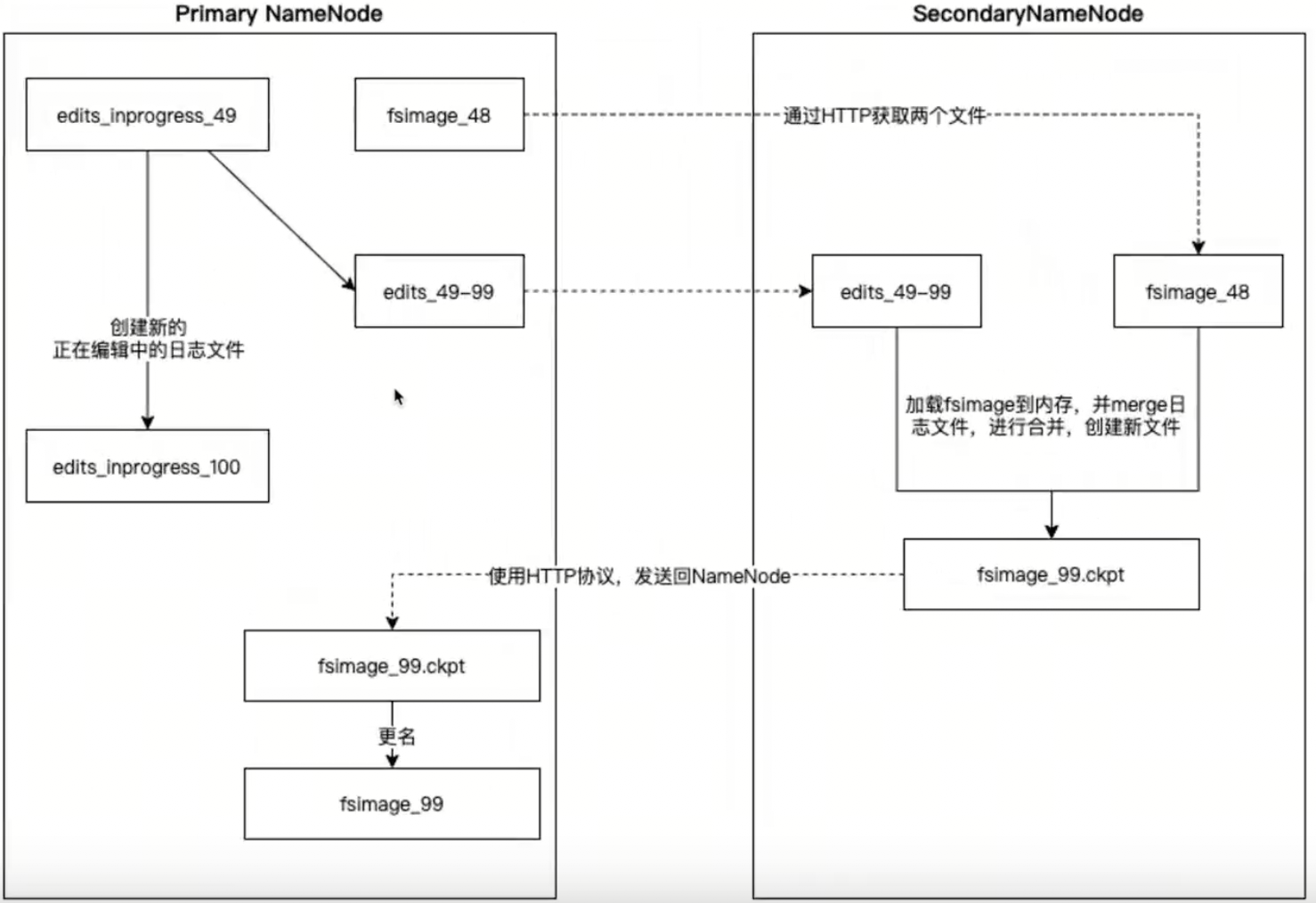
SecondayNamenode是辅助Namenode进行fsimage和editlog的合并工作的流程图:
SecondayNamenode请求Namenode停止正在编辑的edits_inprogress_x文件,Namenode会创建新的正在编辑的edits_inprogress_x文件,并生成edits_x文件,同时更新seed_txid文件。
SecondayNamenode通过http协议获取Namenode上的fsimage和editlog文件,将fsimage读进内存中,并逐步分析editlog文件里的数据,进行合并操作。然后写进新的fsimage_x.ckpt文件中。
SecondayNamenode将新文件fsimage_x.ckpt通过http协议发送回Namenode,Namenode将fsimage_x.ckpt更名为fsimage_x
2.4HDFS的读取机制
2.4.1读流程
hdfs dfs -get /file1 ./file1
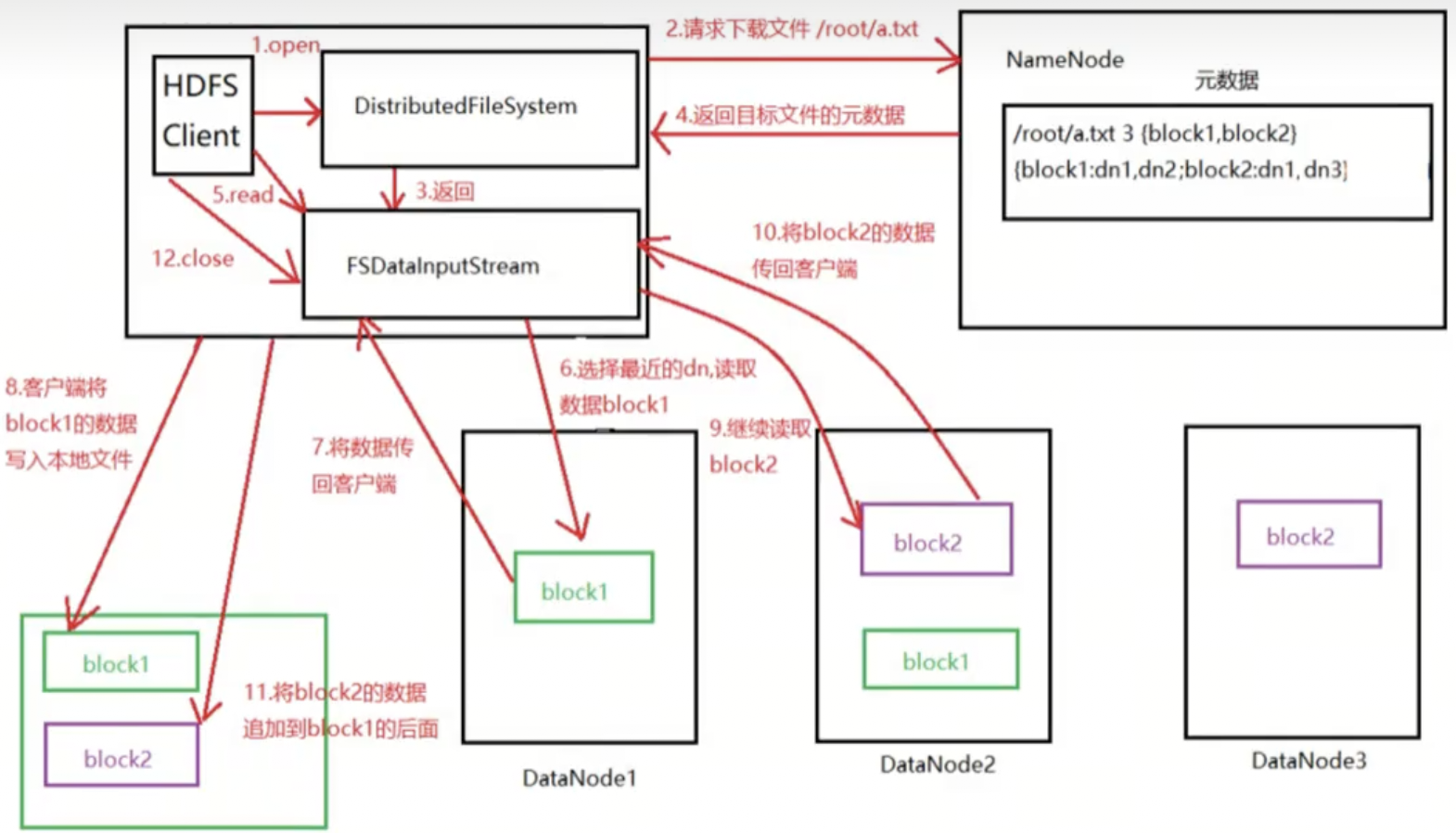
1)客户端通过调用FileSystem对象的open()方法来打开希望读取的文件,对于HDFS来说,这个对象是DistributedFileSystem,它通过使用远程过程调用(RPC)来调用NameNode,以确定文件起始块的位置。
2)对于每一个块,NameNode返回存有该块副本的DataNode地址,并根据距离客户端的远近来排序
3)DistributedFileSystem实例会返回一个FSDataInputStream对象(支持文件定位功能)给客户端以便读取数据,接着客户端对这个输入流调用read()方法
4)FSDataInputStream随即链接距离最近的文件中第一个块所在的DataNode,通过对数据流反复调用read()方法,可以将数据从DataNode传输到客户端
5)当读取到块的末端时,FSDataInputStream关闭与该DataNode的链接,然后寻找下一个块的最佳DataNode
6)客户端从流中读取数据时,块是按照开打FSDataInputStream与DataNode的新建链接顺序读取的。它也会根据需要询问NameNode来检索下一批数据库的DataNode的位置。一旦客户端完成读取,就对FSDataInputStream调用close方法
注意:在读取数据的时候,如果FSDataInputStream与DataNode通信时遇到错误,会尝试从这个块的最近的DataNode读取数据,并且记住那个故障的DataNode,保证后续不会反复读取该节点上后续的块。FSDataInputStream也会通过校验和确认从DataNode发来的数据是否完成。如果发现有损坏的块,FSDataInputStream会从其他的块读取副本,并且将损坏的块通知给NameNode
2.4.2写操作
hdfs dfs -put ./file2 /file2
注意:
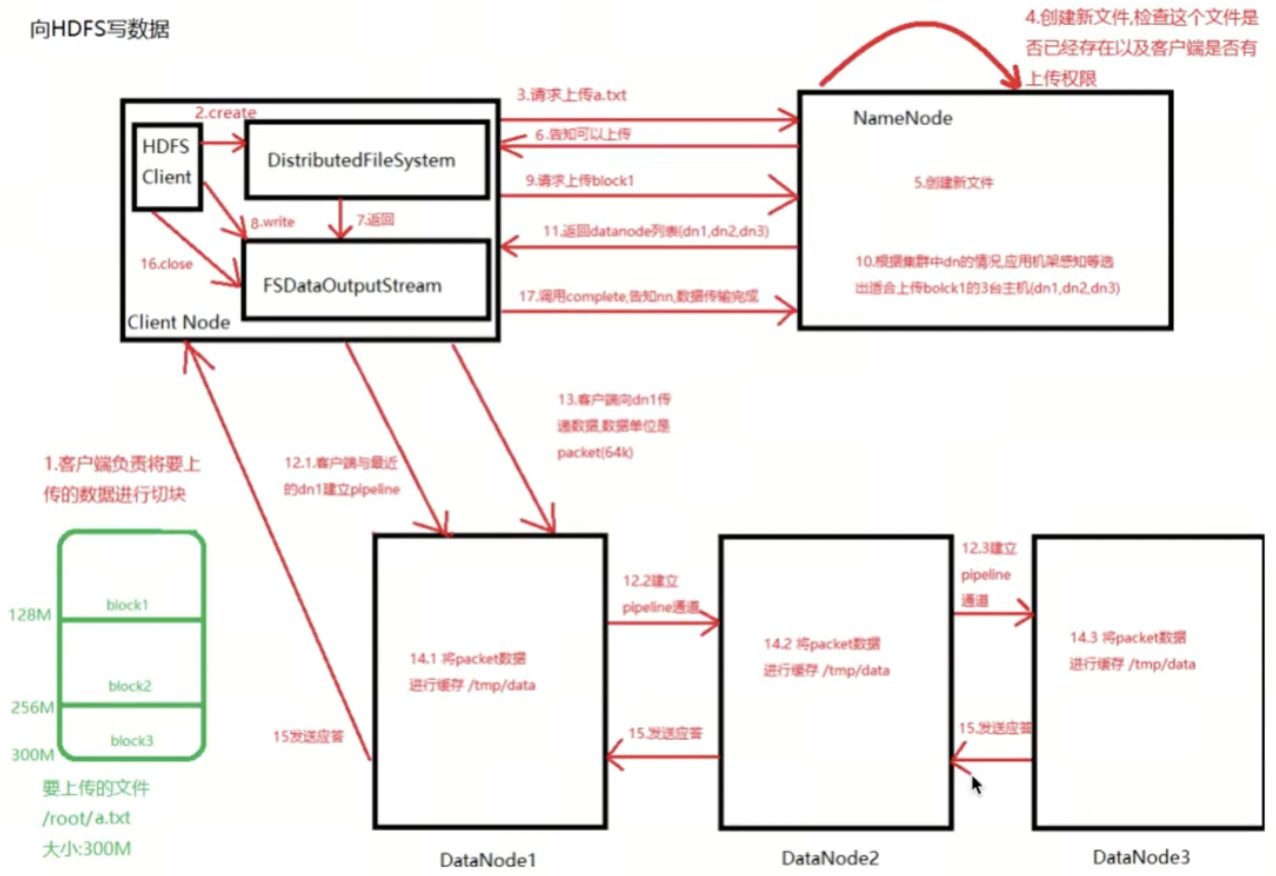
1)如果任何datanode在写入数据期间发生故障,则执行以下操作:
首先关闭管道,把确认队列中的所有数据包都添加回数据队列的最前端,以确保故障节点下游的datanode不会漏掉任何一个数据包
为存储在另一正常datanode的当前数据块定制一个新标识,并将该标识传送给namenode,以便故障datanode在恢复后可以删除存储的部分数据库
从管道中删除故障datanode,基于两个正常datanode构建一条新管道,余下数据块写入管道中正常的datanode
namenode注意到块副本不足时,会在一个新的Datanode节点创建一个新的副本
2)在一个块被写入期间可能会有多个datanode同时发生故障,但概率非常低。只要写入了dfs.namenode.replication.min的副本数(默认1),写操作就会成功,并且这个块可以在集群中异步复制,直到达到其目标副本数dfs.replication的数据(默认为3)
3)client运行write操作后,写完的block才是可见的,正在写的block对client是不可见的,仅仅有调用sync方法。client才确保该文件的写操作已经全部完毕。当client调用close方法时,会默认调用sync方法。
3.java操作hdfs
3.1获取hdfs操作对象
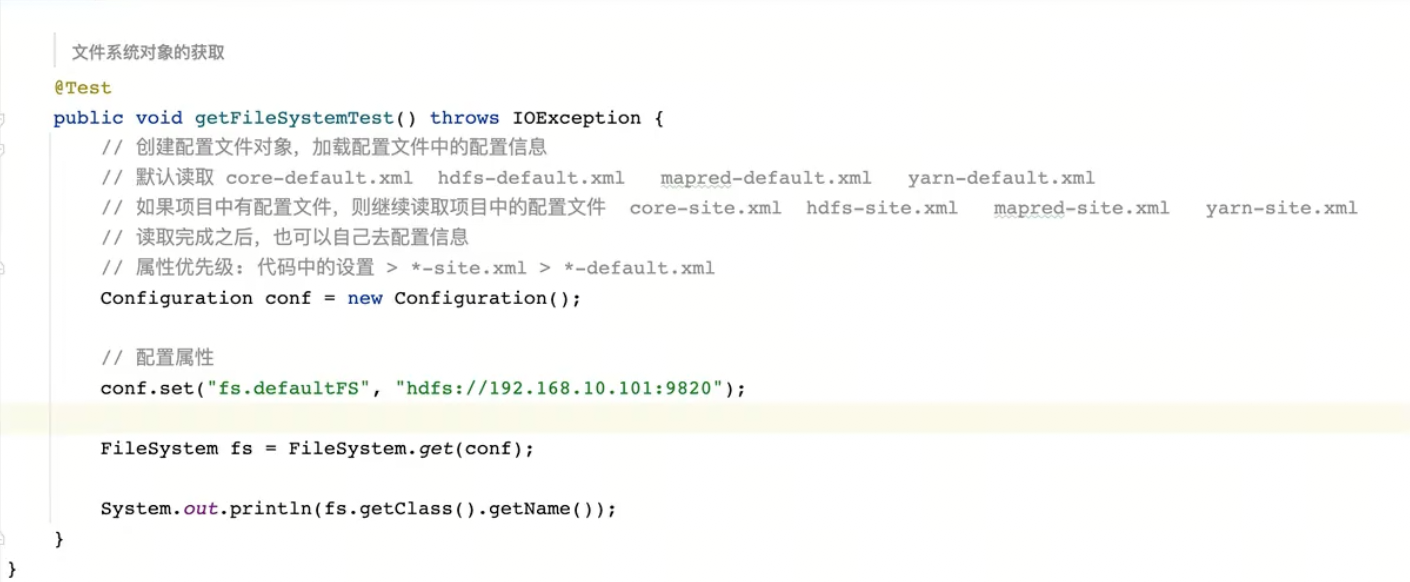
hdfs操作对象初始化,使用@before,每次@test的时候都会先进行这个初始化,在@test完成之后会执行@after关闭文件系。另外还需要设置hadoop的用户,否则会报错权限不足
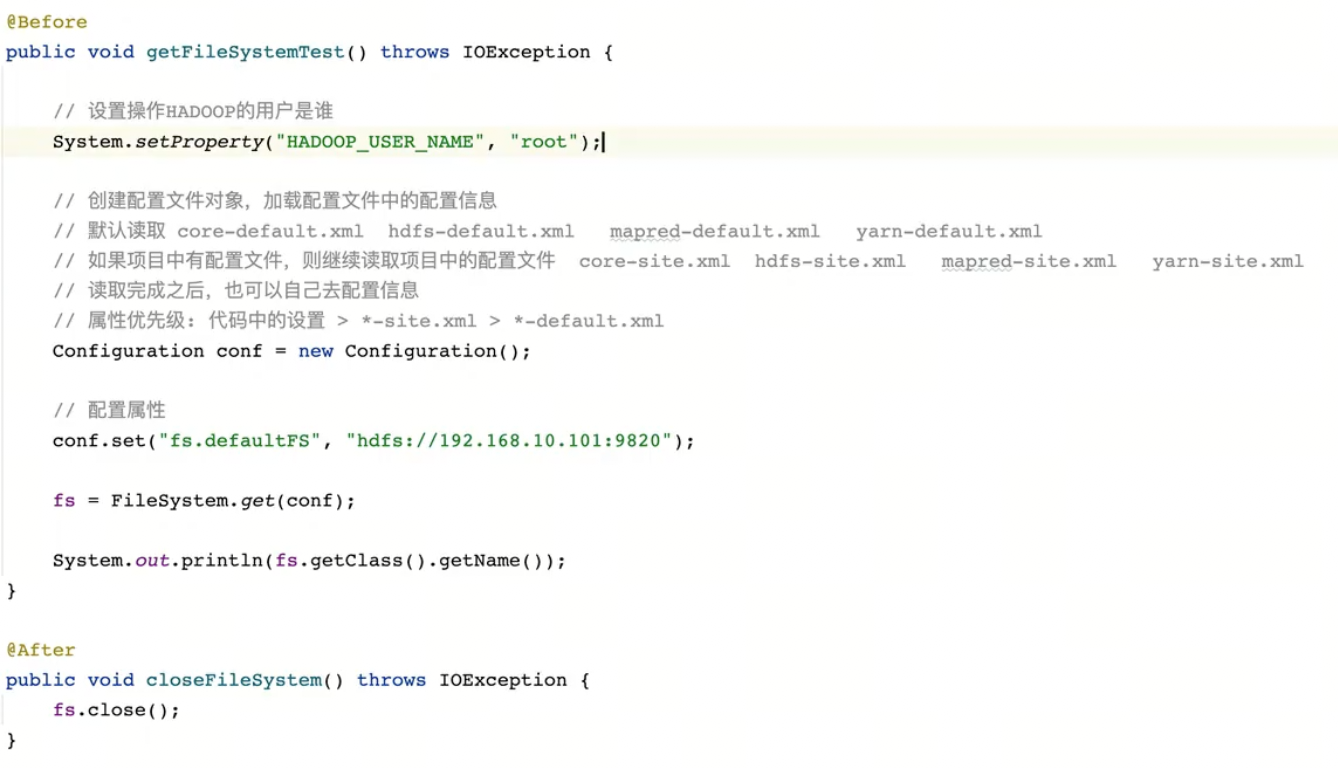
文件上传与下载

文件常用操作
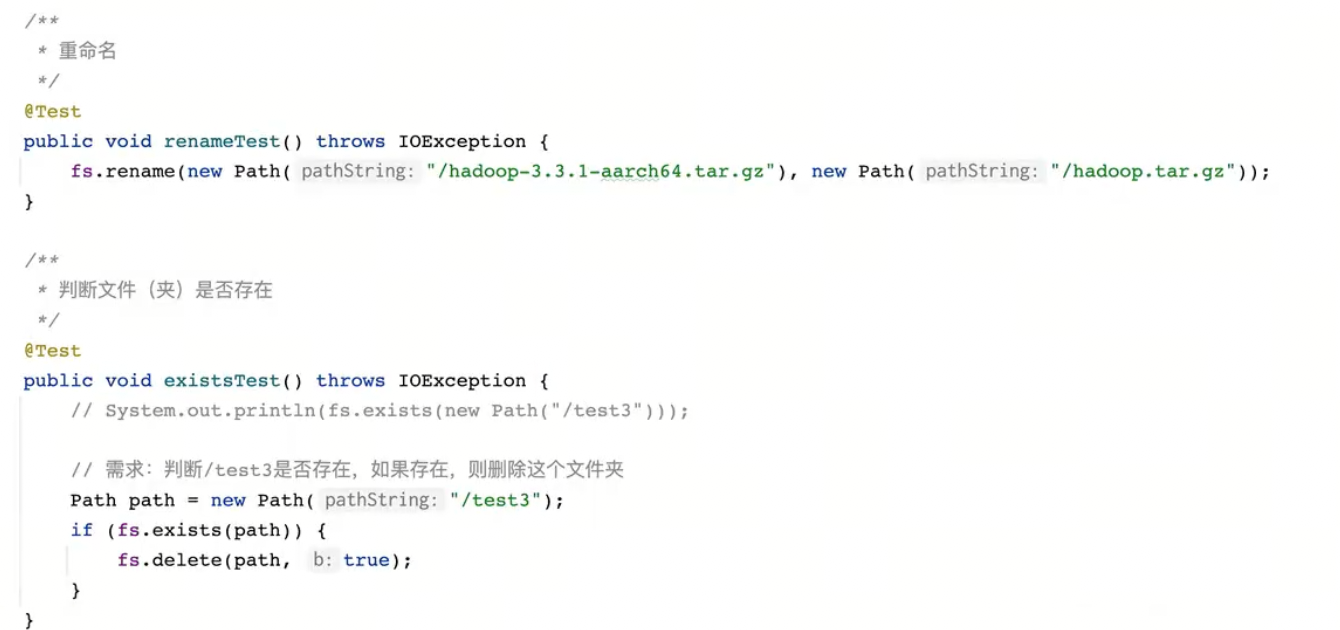
文件夹的创建与文件(夹)的删除

重命名与判断文件(夹)是否存在
文件流的写(上传)
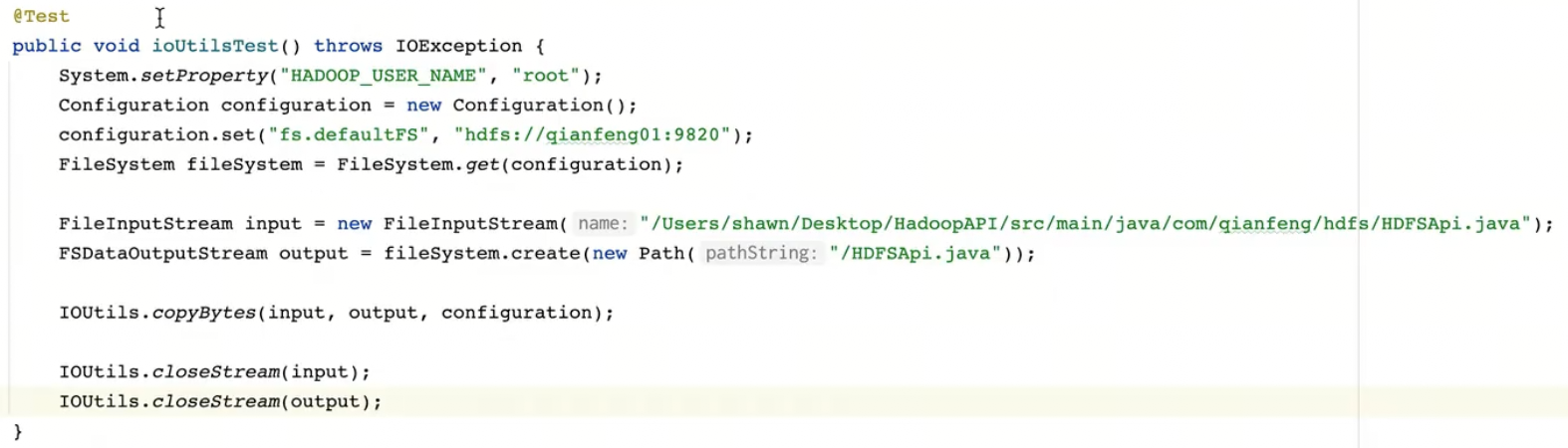
文件流的读(下载)

文件状态信息查看

4.HDFS高级命令
4.1磁盘检测fsck
检查文件系统健康状态
#检查文件(夹)的健康状态 hdfs fsck /test #files每个文件的情况 #blocks每个块的情况 #locations每个块副本对应的服务器是哪个 #-list-corruptfileblocks损坏的块 hdfs fsck /test -files -blocks -locations -list-corruptfileblocks
删除一个block测试一下
#在三台服务器上均删除这个block cd /data/tools/hadoop/tmp/dfs/data/current/BP-1633818422-10.12.20.15-1712540485460/current/finalized #查找block find ./ -name "*blk_1073741861_1037*" cd ./subdir0/subdir0 #删除块及meta文件 rm -rf blk_1073741861*
查看
hdfs fsck /test -files -blocks
会报错MISSING 1 blocks of total size 26013021 B,此时如果重启会在安全模式出不来,因为有一个块没有至少一个副本可用。
需要先将损坏的资源move掉 ,损坏的资源会从原来的位置test/planiverse-app.tar移动到/lost+found/test/planiverse-app.tar
hdfs fsck -move
然后删除有问题的块,执行delete操作之后原来的文件资源就被删除了
hdfs fsck /test -delete
最后将移动的文件再移动回来
hdfs dfs -mv /lost+found/test/planiverse-app.tar /test
文件损坏问题解决。
4.2节点动态上线
如之前安装jdk hadoop 免密登录 修改hosts
在hadoop01修改workers文件
vim $HADOOP_HOME/etc/hadoop/workers
hadoop01
hadoop02
hadoop03
hadoop04
然后分发给其他节点
scp workers hadoop02:$PWD scp workers hadoop03:$PWD scp workers hadoop04:$PWD
将配置文件发送给hadoop04
cd $HADOOP_HOME/etc scp -r hadoop hadoop04:$PWD
配置文件全部准备完成,在hadoop04启动datanode进程
hdfs --daemon start datanode
在新加入节点后,还没有做数据的上传,所以新节点的磁盘使用率为0。可以使用balancer来给各节点做负载均衡,在使用balancer时,需要设置一个threshold(阈值),默认是阈值是10,表示10%的阈值,假设集群中所有datanode节点的总使用占全部磁盘的40%,那么就确保每一个datanode的磁盘使用率在30%-40%之间
在主节点上执行,需要在业务低峰的时候操作,涉及到较大的io操作
hdfs balancer -threshold 10
4.3动态下线
下线需要在配置文件hdfs-site.xml中配置dfs.hosts.exclude参数,将其值设置为/data/tools/hadoop/etc/hadoop/exclude,但是hdfs-site.xml文件需要重启后生效,所在在启动之前需要先配这个参数,然后后续需要哪个下线就在exclude中填写
修改hdfs-site.xml配置文件
<property>
<name>dfs.hosts.exclude</name>
<value>/data/tools/hadoop/etc/hadoop/exclude</value>
</property>
创建exclude文件
touch /data/tools/hadoop/etc/hadoop/exclude
重启hdfs集群
stop-dfs.sh start-dfs.sh
编辑exclude文件添加需要下线的节点hadoop04
echo "hadoop04" > /data/tools/hadoop/etc/hadoop/exclude
注意:下线之后的节点数量,不能少于副本数量,如副本因子为3,在线的节点数量小于等于3的,此时是无法下线的。如果需要下线的话,需要修改副本数如2之后再下线。
在namenode节点刷新节点
hdfs dfsadmin -refreshNodes
此时打开webui http://10.12.20.15:9870/ 可以在datanode处看到下线的节点的状态,表示正在退役中,正在把节点的数据拷贝到其他节点中

过了一段时间后,状态变成,表示退役完成
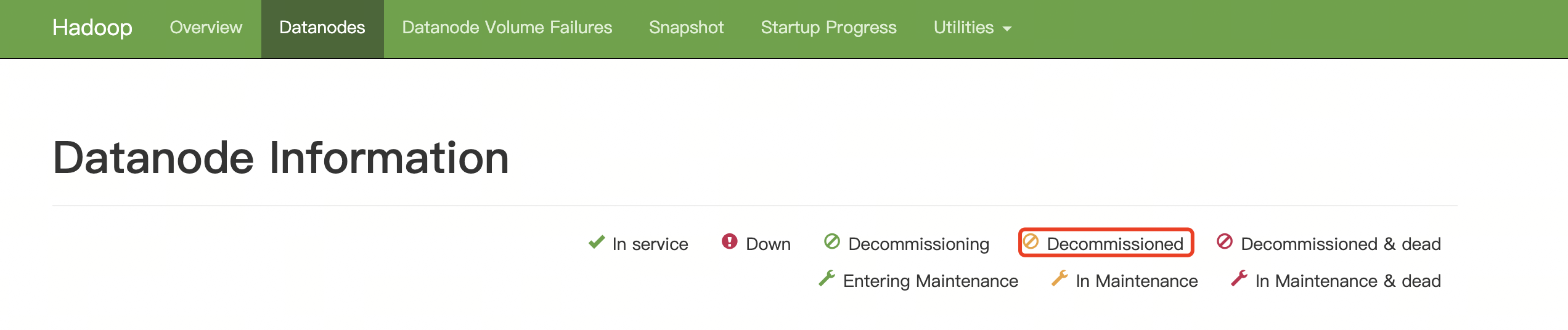
此时在hadoop04上停止datanode进程
hdfs --daemon stop datanode
在这个节点下线后,其他节点的数据如果不均衡的话使用balancer命令平衡一下
hdfs balancer
注意:如果这个节点需要永久下线,可以修改worker文件从中删除这个节点(每个节点都需要在woker文件中删除),再修改exclude文件,从中删除这个节点,如果是暂时下线这个节点,则只需要在exclude中删除这个节点就可以拉。
4.4磁盘平衡
balancer是实现datanode之间的负载均衡,在一个datanode节点中可能存在多个磁盘,此时需要磁盘平衡
循环策略 round-robin:这种策略会将新的block军爷的分布在可用磁盘上。默认使用这个策略。弊端:如果新加一个磁盘,那这个磁盘永远占用率会比之前的低,或者某个磁盘删除大量数据,也会导致每个磁盘的数据量不均衡
可用空间策略 avaliable space:这种策略会将新的block按照磁盘占用百分比,写入更多可用空间吃磁盘上。弊端:如果新加一个磁盘,那新的数据都往这一个磁盘中写,数据量大写入io大会造成排队,而其他磁盘io闲置。
hadoop 3中新增了一个Didk Balancer工具,用来平衡DataNode中的数据在不同磁盘之间分布的。
举例:在hadoop02挂载一个新的磁盘/mnt/disk,并在hadoop02的hdfs-site.xml中新增dfs.datanode.data.dir,将多个磁盘写入并用逗号“,”进行分隔
vim /$HADOOP_HOME/etc/hadoop/hdfs-site.xml <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data,/mnt/disk</value> </property>
在hadoop02重新启动hadoop
hdfs --daemon stop datanode
hdfs --daemon start datanode
此时,使用的是默认的循环策略,往两个盘轮询写入数据
要使用磁盘平衡策略,需要先生成平衡计划再执行平衡操作
在hadoop02上执行生成平衡计划命令
#在需要平衡磁盘的节点上执行,生成平衡计划。默认平衡的阈值为10%,此处设置为5 hdfs diskbalancer -plan hadoop02 -thresholdPercentage 5
会生成一个/system/diskbalancer/xxxx/hadoop02.plan.json文件
在hadoop02上执行平衡操作
hdfs diskbalancer -execute /system/diskbalancer/xxxx/hadoop02.plan.json
查看平衡操作
#-execute开始执行平衡操作的时候,hdfs会启动一个线程来完成这个操作。 #我们可以使用-query来查看这个进程 hdfs diskbalancer -query hadoop02 #出现如下的Result:PLAN_UNDER_PROGRESS 说明正在执行中,如果是Result:PLAN_DONE则说明磁盘平衡结束了
磁盘平衡结束后,可以使用du -sh来查看各个磁盘的使用情况。
4.5分布式拷贝
distcp 分布式拷贝,可以实现将一个分布式集群的数据拷贝到另外一个分布式集群。应用场景:数据迁移,异地容灾。
distcp命令的拷贝过程本质依然是MapReduce实现文件分发,错误处理和恢复,报告生成。以文件或目录的列表作为MapTask的输入,每个MapTask都会拷贝源文件列表中指定路径下的文件。
使用distcp命令做分布式拷贝有如下有点:
1)可以使用bandwidth参数为每一个MapTask限流,控制MapTask并发数量以控制整个拷贝任务的带宽。防止出现拷贝任务将带宽占满,影响其他的业务;
2)支持多种拷贝模式:
overwrite:覆盖写,无条件覆盖目标文件
update:增量写,如果目标文件的名称和大小与源文件不同,则覆盖;如果目标文件的名称和大小与源文件相同,则跳过
delete:删除写,删除目标路径存在而原路径中不存在的文件
不加参数的默认拷贝如果拷贝文件,第一次/src/拷贝到/dst/ dst中是a.txt,第二次拷贝/src/到/dst时,dst中会有a.txt src/a.txt。而加了参数之后,多次拷贝拷贝的都是文件不会拷贝src文件夹。
distcp的使用
distcp最基础的使用,就是直接在两个集群之间进行文件的拷贝,namenode01和namenode02分别是两个集群的namenode节点的ip
hadoop distcp hdfs://namenode01:9820/test hdfs://namenode02:9820/test
拷贝多个源路径,将集群1上的两个文件test1 test2复制到集群2的test上
hadoop distcp hdfs://namenode01:9820/test1 hdfs://namenode01:9820/test2 hdfs://namenode02:9820/test
如果源路径太多,可以将其做成文件
#在hdfs上创建一个文件,用了存储源路径 #例如在hdfs://namenode01:9820/distcp/src文件中写 hdfs://namenode01:9820/src1 hdfs://namenode01:9820/src2 hdfs://namenode01:9820/src3 #执行拷贝操作 hadoop distcp -f hdfs://namenode01:9820/distcp/src hdfs://namenode02:9820/dst
4.6归档
HDFS在使用时有一个缺点,不适合小文件存储,因为每一个小文件都会占用一个块来存储,而每个块会有固定大学的元数据需要保存在namenode的内存中,如果hdfs中有大量的小文件的话,会带来非常大的内存开销,此时可以用archives来处理这个问题。archives就是归档的意思,它可以将hdfs的多个文件归档成一个扩展名为.har的文件,而且归档之后文件还可以透明的访问每一个文件,并且可以作为MapReduce任务的输入。
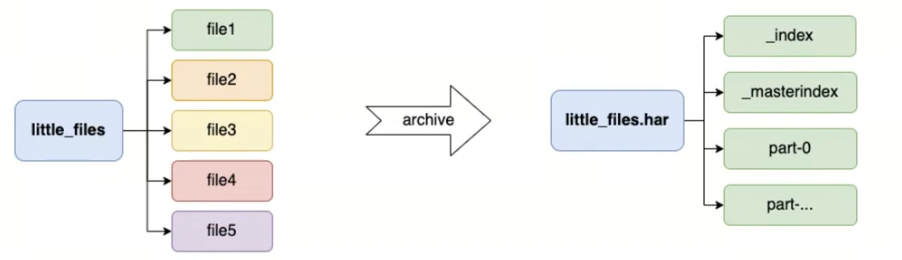
归档的用法:hadoop archive -archive -archiveName name -p <parent> [-r <replication factor>] <src> * <dest>
-archiveName: 指定归档文件的名称,需要以.har结尾
-p: 指定需要归档的文件的父级路径
-r: 指定归档文件的副本因子,默认是3
<src>:指定所有需要归档的文件
<dest>:指定归档后的文件存放的位置
将little_files/{file1,file2,file3}归档到/archives下的files.har
hadoop archive -archiveName files.har -p /little_files -r 3 file1 file2 file3 /archives
将整个文件夹打包到/archives/files2.har
hadoop archive -archiveName files2.har -p /little_files /archives
查看归档
如果要查看一个归档文件中都有什么文件,需要使用har://来查看
hdfs dfs -ls -R har:///archives/files.har #可以看到结果 -rw-r--r-- 3 root supergroup 19 2024-04-19 15:07 har:///archives/files.har/file2 -rw-r--r-- 3 root supergroup 27 2024-04-19 15:07 har:///archives/files.har/file3 -rw-r--r-- 3 root supergroup 10 2024-04-19 15:07 har:///archives/files.har/file1
解归档
归档文件在hdfs的映射是一个文件夹,可以透明的访问其中的文件。如果需要将归档文件中的小文件解出来的话,直接进行拷贝即可。但是需要注意归档文件的URI是har://
hdfs dfs -mkdir /unarchive #拷贝归档文件中指定文件到指定目录 hdfs dfs -cp har:///archives/files.har/file1 har:///archives/files.har/file2 /unarchive #拷贝归档文件中所有文件到指定目录 hdfs dfs -cp har:///archives/files.har/* /unarchive
归档特性总结
1)归档文件本身不支持压缩
2)创建归档的时候使用到的小文件和目录都不会自动删除,如果需要删除,需要手动删除
3)归档文件是不可变的,如果想要在归档文件中新增小文件或者删除小文件,需要重新创建归档文件
4)归档文件只是用来减少小文件带来的Namenode过高的内存占用,对于MapReduce来说并没有优化,并不会减少分片的数量,也就无法减少MapTask的数量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号