使用SPLUNK进行简单Threat Hunting
通过订阅网上公开的恶意ip库(威胁情报),与SIEM平台中网络流量日志进行匹配,获得安全事件告警。
比如,这里有一个malware urls数据下载的网站,每天更新一次:
https://urlhaus.abuse.ch/browse/
下载urlhaus里恶意url数据,https://urlhaus.abuse.ch/downloads/text/, 稍微整理一下,做成一个csv格式的文件,方便导入splunk:

添加nslookup file:
Settings >> Lookups » Lookup table files » Add new

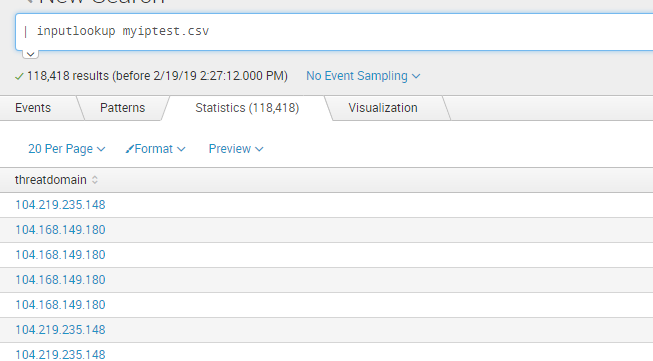
用rest command查看lookup file 添加是否正确:
| inputlookup myiptest.csv
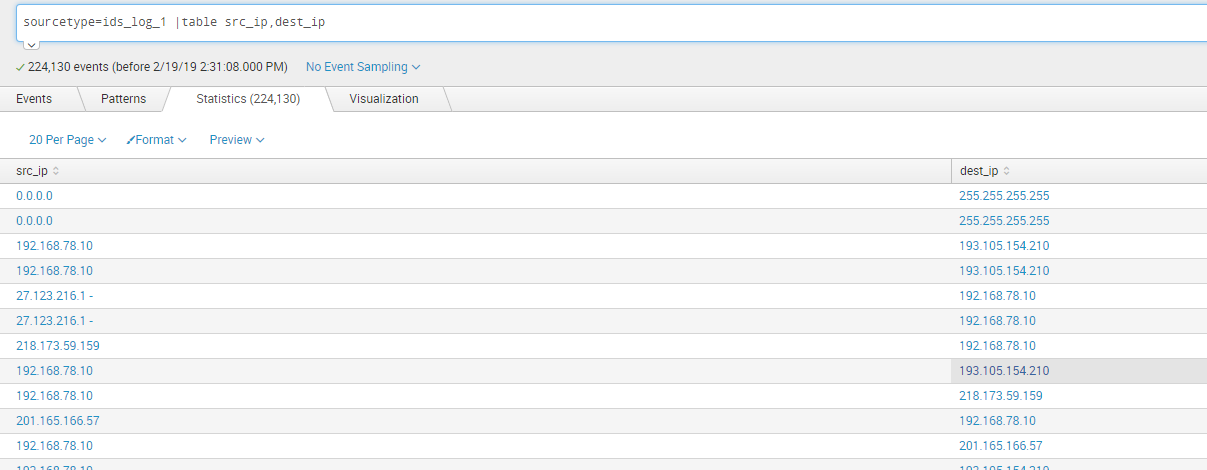
假设现在有ids日志,此日志包含经过ids的内外网连接,其中src_ip为内网ip,dest_ip为外网目的ip:
sourcetype=ids_log_1 |table src_ip,dest_ip
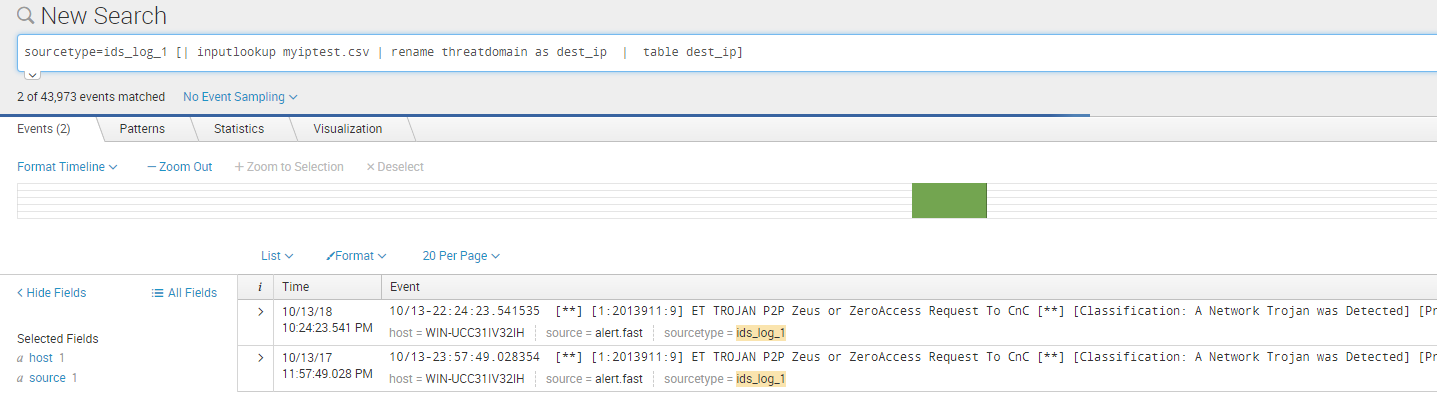
现在对ids的dest_ip字段和myiptest.csv的threatdomain 字段进行匹配:
sourcetype=ids_log_1 [| inputlookup myiptest.csv | rename threatdomain as dest_ip | table dest_ip]
命中两条记录:
现在完成一次搜索,然后继续将这个流程自动化,这里涉及到Splunk Summary Index的概念:
Summary index的工作机制其实很简单,它本质上和其他索引没有区别,只不过里面存储的数据是定期运行的saved search的统计结果。通过定期运行的saved search,SPLUNK可以将一个较短时间间隔特定事件的统计结果存储到summary index中,通过合理的统计时段和搜索运行计划配置,所有时间段的事件统计结果都将无一疏漏地纪录下来。这样在需要统计过去一年这样长时段的事件时,通过summary index就可以很快速的把所有统计结果汇总,从而得到最终的结果。这正所谓积硅步以致千里,聚细流以成江海。
From http://splunk.10data.com/如何使用summary-index-加速搜索和生成报表/
创建一个summary index:

添加一个saved search, 可以60分钟执行一次,每次执行60分钟到now的数据:
Settings>>Searches, reports, and alerts » Add new
http://localhost:8000/en-US/manager/search/data/indexes/_new
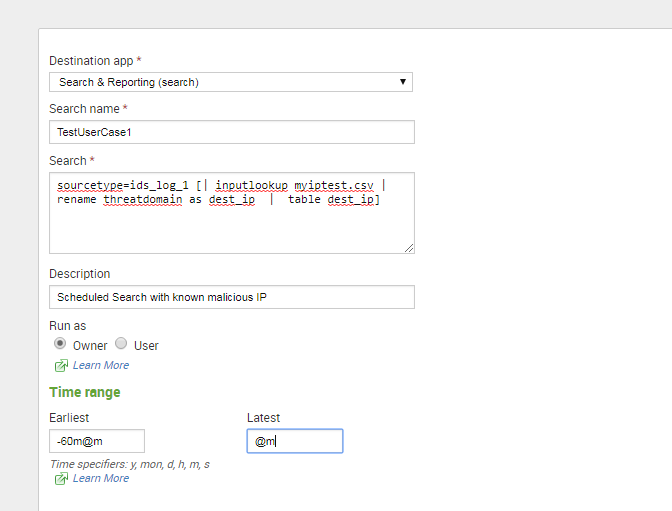
选择使用summary indexing, 写入刚才创建的security_event_hub index里面:
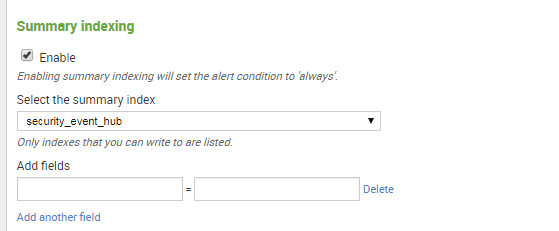
保存完成,坐等安全告警:
index="security_event_hub"
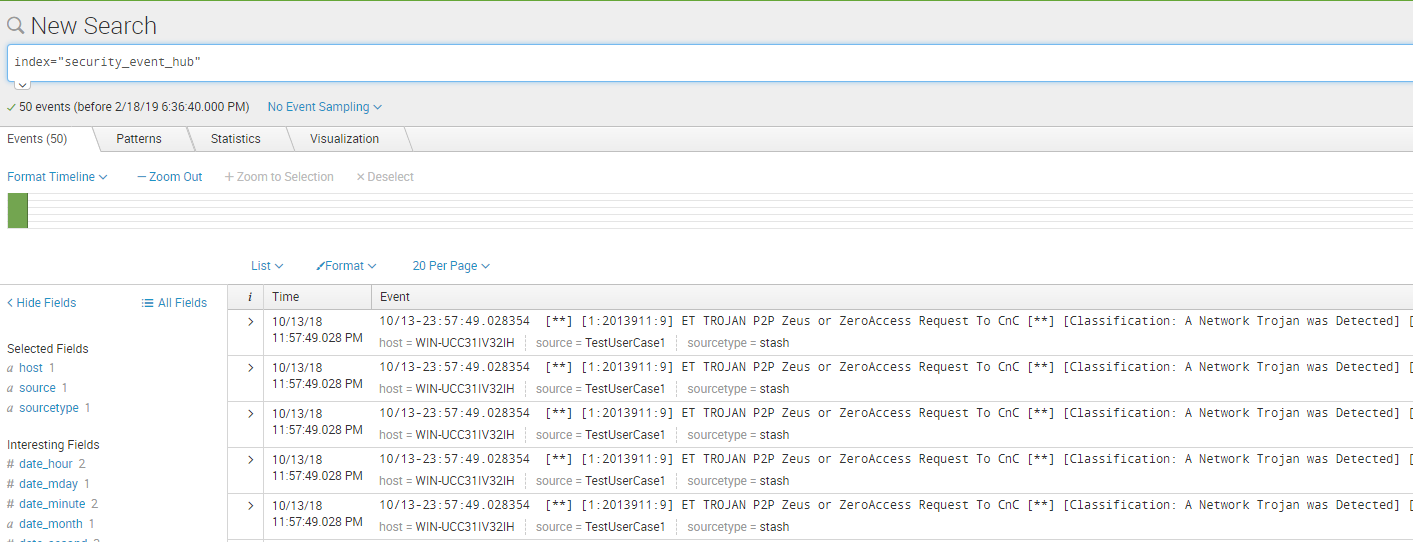
最后可以将安全告警推送到工单系统,新的告警在工单系统中解决掉,这就完成一整个Use Case流程。
附代码举例:
Splunk Rest api 添加Lookup file :
#!/usr/bin/python -u
import urllib
import httplib2
from xml.dom import minidom
import time
import json
# The same python implementation for curl function
'''
import requests
from xml.dom import minidom
userName = 'admin'
password = 'xiaoxiaoleo'
baseurl = '127.0.0.1:8089'
session = requests.Session()
session.auth = (userName, password)
#auth = session.post('https://' + baseurl, verify=False)
data = {'username':userName, 'password':password}
req = session.post('https://' + baseurl + '/services/auth/login', data=data, verify=False)
session_key = minidom.parseString(req.text).getElementsByTagName('sessionKey')[0].childNodes[0].nodeValue
print(session_key)
headers = {"Content-Type": "application/xml", 'Authorization': 'Splunk %s' % session_key}
def addlookup():
data = {'name': 'haha.csv','eai:data' : 'C:\\Program Files\\Splunk\\var\\run\\splunk\\lookup_tmp\\abuse_20190215T1418.csv'}
req = requests.post('https://127.0.0.1:8089/servicesNS/nobody/search/data/lookup-table-files/geo_attr_us_states.csv', headers=headers, data=data, verify=False)
print(req.text)
if __name__ == '__main__':
addlookup()
获取urlhaus.abuse.ch的ip地址列表并写入csv:
import json
import requests
from datetime import datetime, timedelta
search_command = ''
def get_abusechrul():
domain_list = []
url_list = []
req = requests.get('https://urlhaus.abuse.ch/downloads/text/')
body = req.text
for i in body.split('\r\n'):
if i.startswith('#'):
continue
domain = i.split("//")[-1].split("/")[0].split(':')[0]
url = i.replace("http://", "")
url = url.replace("https://", "")
url_list.append(url)
domain_list.append(domain)
return domain_list, url_list
def generate_csv(source_name, domain_list, url_list):
now = datetime.utcnow() + timedelta(hours=8)
timestamp = now.strftime('%Y%m%dT%H%M.csv')
filename = '%s_%s' % (source_name, timestamp)
with open(filename, "wb") as csv_file:
csv_file.write('threatdomain' + '\n')
csv_file.writelines('91.189.91.26' + '\n')
for line in domain_list:
csv_file.write(line + '\n')
if __name__ == '__main__':
domain_list, url_list = get_abusechrul()
generate_csv('abuse', domain_list,url_list)
#print cmd1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号