
java的数据类型
-
基本类型
-
byte,short,char,int,long,float,double,boolean
-
引用和值都是存储在栈内存中
-
基本数据类型是没有方法和属性的
-
-
引用类型
-
除过基本类型以外的其他类型:String,数组,自定义的对象等等。
-
引用类的引用是存储在栈中的,而数据是存储在堆中的。
-
引用类型都是有属性和方法的。因为任何引用类型都是集成自Object类的。
-
包装类:java中对8中基本数据类型准备的引用类型。
| 基本类型 | 包装类 |
|---|---|
| byte | Byte |
| char | Character |
| short | Short |
| int | Integer |
| long | Long |
| flot | Float |
| double | Double |
| boolean | Boolean |
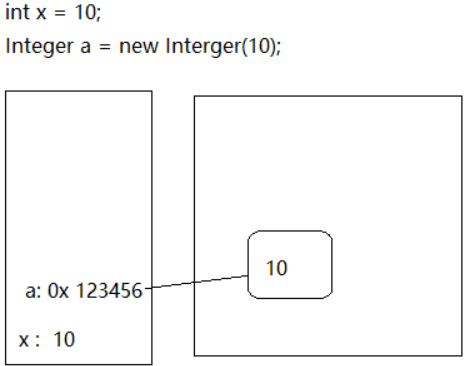
申明和赋值得方式:
// 基本类型
int x = 10;
// 包装类
Integer a = new Integer(10);
使用上的区别
基本类型和引用类型上面的例子中的赋值方式和申明方式是不同。
本质上有很大的区别
-
在内存中的情况:
-
比较方式
所有的基本数据类型都可以使用"=="来比较数据。但是引用类型(包装类)“==” 比较的只是内存地址。
所以两个Integer使用"=="比较可能会存在问题。要使用方法equals方法进行比较:
public class Test {
public static void main(String[] args) {
int x = 10;
int y = 10;
System.out.println(x == y);// true
Integer a = new Integer(314);
Integer b = new Integer(314);
System.out.println(a == b);// false ==判断地址
System.out.println(a.equals(b));// true equals判断内容
}
}
equals方法本身是在Object类中定义的。而Object类中的equals本身就是使用 “==”。
Integer类里面的equals方法已经被重写,比较的就是两个具体的数值而不是地址。
(所有的基本类型的包装类的equals都被重写了)
-
包装类的方法。
所有的包装类都是有方法的,我们就以Integer为例子:
常量:
static int MAX_VALUE 一个持有最大值一个 int可以有2 31 -1。 static int MIN_VALUE 的常量保持的最小值的 int可以具有,-2 31。
构造方法:
Integer(int value) 构造一个新分配的 Integer对象,该对象表示指定的 int值。 Integer(String s) 构造一个新分配 Integer对象,表示 int由指示值 String参数。
// 构造Integer
int x = 2;
Integer a = new Integer(x);
String str = "123";
Integer b = new Integer(str);
tips: 在new Integer(String str) 在这个构造方法内部,其实使用了Integer.parseInt()。也就是说str必须是数字形式,否则就会出现java.lang.NumberFormatException。
其他的一些API:
byte byteValue() 返回此值 Integer为 byte的基本收缩转换后。 static int compare(int x, int y) 比较两个 int数字值。
double doubleValue() 返回此值 Integer为 double一个宽元转换后。 boolean equals(Object obj) 将此对象与指定的对象进行比较。 float floatValue() 返回此值 Integer为 float一个宽元转换后。
int intValue() 将 Integer的值作为 int 。 long longValue() 返回此值 Integer为 long一个宽元转换后。
static int max(int a, int b) 返回两个 int的较大值,就像调用 Math.max一样 。 static int min(int a, int b) 返回两个 int的较小值,就像调用 Math.min一样 。
static int parseInt(String s) 将字符串参数解析为带符号的十进制整数。
short shortValue() 返回此值 Integer为 short的基本收缩转换后。
static int sum(int a, int b) 根据+运算符将两个整数相加。
static Integer valueOf(int i) 返回一个 Integer指定的 int值的 Integer实例。 static Integer valueOf(String s) 返回一个 Integer对象,保存指定的值为 String 。
public class Test2 {
public static void main(String[] args) {
// 构造Integer
int x = 2;
Integer a = new Integer(x);
String str = "123";
Integer b = new Integer(str);
// 将一个Integer转换为其他的基本数值类型
Integer i = new Integer(158);
// 如果数值本身已经超过了要转换的目标类型的范围则转换后的数据是不正确的。
byte b1 = i.byteValue();
short i2 = i.shortValue();
int i1 = i.intValue();
long l = i.longValue();
float v = i.floatValue();
double v1 = i.doubleValue();
// 比价大小
int result = Integer.compare(100, 101);
System.out.println(result);
int max = Integer.max(100, 101);
System.out.println(max);
int min = Integer.min(100,101);
System.out.println(min);
int sum = Integer.sum(100,101);
System.out.println(sum);
// valueOf
int age = 18;
// 将int转换为Integer对象
Integer integer = Integer.valueOf(age);
String customerId = "15";
// 将字符串转为Integer对象
Integer cid = Integer.valueOf(customerId);
}
}
基本类型和包装类的转换--自动转换
JDK1.5开始,就可以自动拆装箱
public class Test3 {
public static void main(String[] args) {
int x = 10;
Integer a = new Integer(100);
// 自动拆箱(将Integer对象中的数值取出赋值给y变量)
int y = a;
// 自动装箱(将x变量包装为一个Integer对象)
Integer b = x;
}
}
使用API进行转换:
// 基本类型包装成包装类型
// x也是可以是数字形式的字符串
Integer ix = new Integer(x);
Integer iy = Integer.valueOf(x);
// 拆箱
int z = a.intValue();
当一个方法的参数需要是int时,可以使用Integer代替。相反依然。
异常
java中的异常的体系:
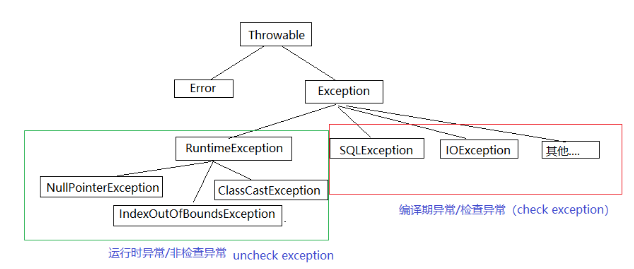
运行时异常:
所有的运行时异常都是RuntimeException的子类。所有的方法都是默认直接申明了运行时异常。
任何位置写的运行时异常,都不需要写try....catch处理。
public static void method()throws RuntimeException{
// 不需要try....catch处理
int x = 10 / 5;
}
所以写程序的时候最要注意的就是运行时异常。
常见的例子:
User user = userDAO.queryById(ID);
// User user = new User();
// user.setPass("123123");
// 为了防止空指针异常出现,必须先判断user是否是null。
if(user!=null && user.getPass().equeals(pass)){
.....
}
所以我们写程序的时候,一定要考虑运行时异常的出现的问题。要通过逻辑判断,避免运行时异常的出现。
编译期异常:SQLException,IOException,ServletException.....
当程序要访问程序以外的任何资源的时候,就要处理编译期异常。比如:访问数据库,访问网络,访问磁盘文件等等。
编译期异常必须处理,比如我们之前项目中写的DAO中对数据库的CRUD的一些方法,必须申明异常或者使用try....catch处理。否则编译无法通过。
int page = 1;
try{
page = Integer.parseInt(request.getPaxxxxx);
}catch(NumberFormatException e){}
异常处理
[1]使用try...catch结构处理
try{
// 可能出现异常的程序
}catch(Exception e){
// 处理异常的程序
}
[2]使用throws申明异常
pulbic void method()throws Exception{
// 可能出现异常的程序
}
自定义异常
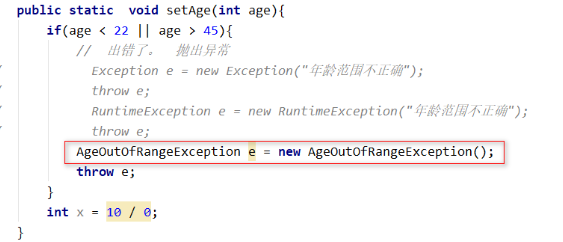
问题:我们要设置一个员工的年龄,这个年龄的范围是在22~45之间的。如果不在这个范围就是出错。
public static void setAge(int age){
if(age < 22 || age > 45){
// 出错了。 抛出异常
}
}
上面的程序无法被动的抛出异常,需要我们手动抛出。
使用 throw 手动的抛出一个异常对象:
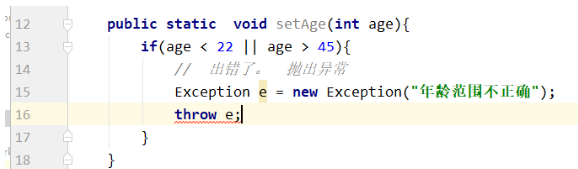
出错的是因为Exception本身是编译期异常,所以一旦抛出,必须处理。
所以一般我们都是使用运行时异常:
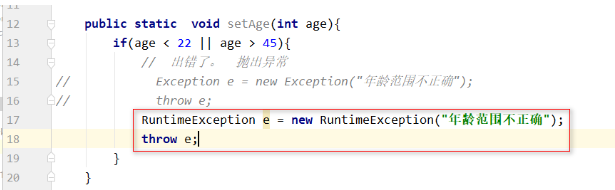
调用方法的时候,处理异常:
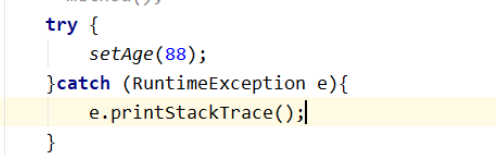
这种处理方案明显是笼统的。这也是为什么会有空指针异常,索引越界异常等等各种不同的异常类型。
java中就是通过不同的异常类型类表示不同的异常问题。
java提供了大量的异常类型,但是依然有可能会出现我们的需要的异常没有的情况。比如上面的情况?
当java中没有我需要的异常的时候,我们就需要自定义异常:
自定义异常写法:写一个类,继承RuntimeException 或者 Exception 即可。
继承RuntimeException就是运行时异常。继承Exception就是编译期异常。
/**
* 年龄越界的自定义异常
*/
public class AgeOutOfRangeException extends RuntimeException {
}
修改上面的程序:
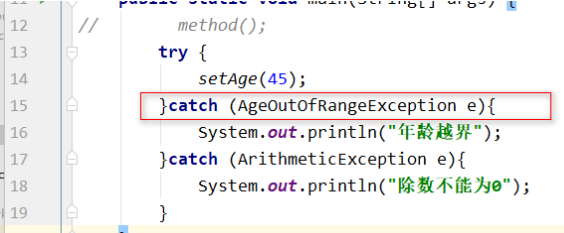
处理:
关于自定义异常的构造方法:
RuntimeException的构造方法:
package java.lang;
public class RuntimeException extends Exception {
static final long serialVersionUID = -7034897190745766939L;
/**
* 无参数的构造方法
*/
public RuntimeException() {
super();
}
/**
* 设置错误信息的构造方法
*/
public RuntimeException(String message) {
super(message);
}
/**
* 设置错误信息,并且可以传入一个其他的Throwable对象
* 将一个其他的异常包裹成当前的异常
*/
public RuntimeException(String message, Throwable cause) {
super(message, cause);
}
/**
* 将一个其他的异常包裹成当前的异常
*/
public RuntimeException(Throwable cause) {
super(cause);
}
protected RuntimeException(String message, Throwable cause,
boolean enableSuppression,
boolean writableStackTrace) {
super(message, cause, enableSuppression, writableStackTrace);
}
}
Throwable中的几个比较重要的方法:
String getMessage() 返回此throwable的详细消息字符串。
void printStackTrace() 将此throwable和其追溯打印到标准错误流。
void printStackTrace(PrintStream s) 将此throwable和其追溯打印到指定的打印流。 void printStackTrace(PrintWriter s) 将此throwable和其追溯打印到指定的打印作者。
我们的自定义的异常中,一般都会实现几个构造方法:
public class AgeOutOfRangeException extends RuntimeException {
// 无参构造
public AgeOutOfRangeException() {
}
// 可是设置信息的构造
public AgeOutOfRangeException(String message) {
super(message);
}
// 可以设置信息和包裹其他异常的构造
public AgeOutOfRangeException(String message, Throwable cause) {
super(message, cause);
}
// 可以包裹一个其他异常信息的构造
public AgeOutOfRangeException(Throwable cause) {
super(cause);
}
}
实际开发中的异常处理
实际的项目一般都分为好几层。底层的异常不能直接给吞掉,必须向上抛出。在servlet层面统一处理。
为某一类错误专门自定义一个异常类型:
public class QIdianSQLException extends RuntimeException {
public QIdianSQLException() {
}
public QIdianSQLException(String message) {
super(message);
}
public QIdianSQLException(String message, Throwable cause) {
super(message, cause);
}
public QIdianSQLException(Throwable cause) {
super(cause);
}
}
在DAO中将编译期异常包裹成自定义的异常向上抛出:
public class UserDAOImpl implements UserDAO {
@Override
public int save() {
try{
System.out.println("保存用户");
throw new SQLException();// 手动抛出异常(编译期异常)
}catch (SQLException e){
// 记录异常
// e.printStackTrace();
// 打包成运行时异常,抛出
throw new QIdianSQLException(e);
}
}
}
调用层处理:
public static void main(String[] args) {
UserDAO userDAO = new UserDAOImpl();
try {
userDAO.save();
}catch (QIdianSQLException e){
System.out.println(e.getMessage());// 唤醒程序员...改bug
}
}
有一定的规模的企业,都是有自己的开发手册和开发平台。这些平台中一般都会包含一套自定义异常。
集合
java集合的家谱图
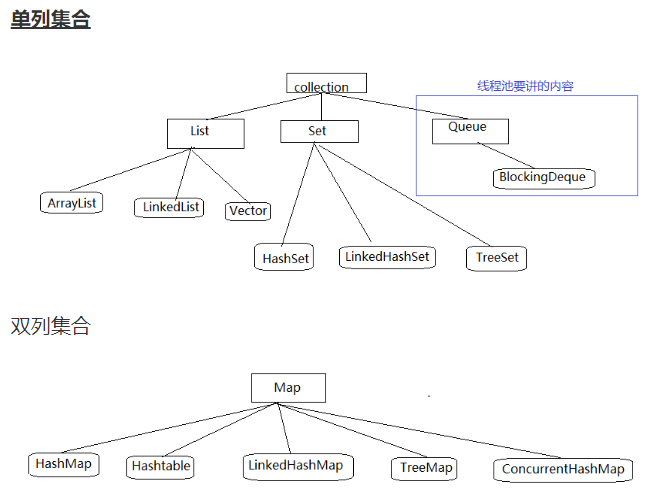
Collection--单列集合的最顶层接口
什么是集合?我们学过了ArrayList,所以集合就是可以存储一组,一堆数据的对象。
Collection规定了单列集合应该拥有的一些基本的方法。
API:
-
boolean add(E e) 给集合中添加一个元素e,如果集合因为这个添加操作而发生改变就返回true,否则返回false。
-
boolean addAll(Collection<? extends E> c) 将指定集合中的所有元素添加到此集合(可选操作)。
-
void clear() 从此集合中删除所有元素(可选操作)。
-
boolean contains(Object o) 如果此集合包含指定的元素,则返回 true 。
-
boolean containsAll(Collection<?> c) 如果此集合包含指定 集合中的所有元素,则返回true。
-
boolean equals(Object o) 将指定的对象与此集合进行比较以获得相等性。
-
boolean isEmpty() 如果此集合不包含元素,则返回 true 。
-
Iterator<E> iterator() 返回此集合中的元素的迭代器。
-
boolean remove(Object o) 从该集合中删除指定元素的单个实例(如果存在)(可选操作)。
-
boolean removeAll(Collection<?> c) 删除指定集合中包含的所有此集合的元素(可选操作)。
-
int size() 返回此集合中的元素数。
-
Object[] toArray() 返回一个包含此集合中所有元素的数组。
List接口--Collection的子接口(有序可重复)
所有的List接口的实现类,都可以通过索引获取元素。
List特有的API:
-
void add(int index, E element) 将指定的元素插入此列表中的指定位置(可选操作)。
-
boolean addAll(int index, Collection<? extends E> c) 将指定集合中的所有元素插入到此列表中的指定位置(可选操作)。
-
E get(int index) 返回此列表中指定位置的元素。
-
int indexOf(Object o) 返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1。
-
int lastIndexOf(Object o) 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。
-
E remove(int index) 删除该列表中指定位置的元素(可选操作)。
-
E set(int index, E element) 用指定的元素(可选操作)替换此列表中指定位置的元素。
-
List<E> subList(int fromIndex, int toIndex) 返回此列表中指定的 fromIndex (含)和 toIndex之间的视图。
ArrayList--List接口的实现类(底层通过数组实现)
ArrayList实现了List和Collection中的所有方法。
常用的API:
public class ArrayListTest {
public static void main(String[] args) {
ArrayList al = new ArrayList();
al.add("唐三藏");
al.add("孙悟空");
al.add("八戒");
al.add("沙僧");
al.add("白骨精");
al.add("小丸子");
// 再来一个集合
ArrayList al1 = new ArrayList();
al1.add("卡卡西");
al1.add("佐助");
al1.add("卡卡西");
// 加入其他集合
al.addAll(al1); //将新的子集加入到原来的集合中
System.out.println(al);
System.out.println(al.isEmpty());
System.out.println(al.contains("小丸子"));
System.out.println(al.indexOf("卡卡西"));
System.out.println(al.lastIndexOf("卡卡西"));
Object result = al.remove(7);
System.out.println("删除元素:"+result);
System.out.println(al);
boolean r = al.remove("卡卡西");
System.out.println(al);
al.set(6,"旗木卡卡西");
System.out.println(al);
List list = al.subList(2, 5);// 前闭后开的区间
System.out.println(list);
}
}
特殊的API:
准备一个实体类:
class Student{
private int age;
private String name;
public Student(int age,String name){
this.age = age;
this.name = name;
}
public String toString(){
return name+":"+age;
}
}
看测试:
public class ArrayListTest2 {
public static void main(String[] args) {
List<Student> sts = new ArrayList<>();
sts.add(new Student(18,"佐助"));
sts.add(new Student(18,"鸣人"));
sts.add(new Student(28,"卡卡西"));
sts.add(new Student(6,"小丸子"));
// 根据对象获取元素的位置 (indexOf,lastIndex())
int index = sts.indexOf(new Student(28,"卡卡西"));// -1
System.out.println(index);
// 根据元素删除
boolean result = sts.remove(new Student(6,"小丸子"));
System.out.println(result);// false
// 判断这个元素是否在整个集合中
result = sts.contains(new Student(18,"鸣人")); // false
System.out.println(result);
}
}
上面程序的测试结果,根我们预期的结果是不一致的。
稍微查看一下源码:
public class ArrayList extends AbstractList...imp{
//.....
public int indexOf(Object o) {
if (o == null) {// 如果传入的对象为null;找到weinull的元素,返回索引
for (int i = 0; i < size; i++)
if (elementData[i]==null)// 这里使用==比较
return i;
} else {
for (int i = 0; i < size; i++)
// 使用传入的对象的equals和每一个元素进行比较,如果为true,就返回这个元素的索引
// 这里的o就是我们传入的student对象。
// 我们的student使用Object实现的equals,就是使用“==”,那么就是比较地址
if (o.equals(elementData[i]))
return i;
}
return -1;
}
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
}
通过查看源码发现所有的要在集合中查找或者比较某一个元素的方法都是通过集合中元素的equals比较的。
如果集合中的元素的equals就是原生的集成自Object的,那么就是通过“==”比较的。如果我们希望通过属性比较,我们就要重写equals方法。
所以我们来重写Student类的equals方法再测试:
class Student{
private int age;
private String name;
public Student(int age,String name){
this.age = age;
this.name = name;
}
public String toString(){
return name+":"+age;
}
// 重写equals
public boolean equals(Object obj){
if(this == obj){
return true;
}
// 类型如果不同,直接返回false
if(!(obj instanceof Student)){
return false;
}
// 判断属性
Student st = (Student) obj;
// if(this.age == st.age){
// if(this.name.equals(st.name)){
// return true;
// }
// }
return this.age == st.age?this.name.equals(st.name):false;
}
}
在测试之前的方法,就有预期值了。
面试题:什么情况下要重写hashcode和equals方法。如何重写这些方法?
LinkedList--List接口的实现类(底层使用双向链表实现)
LinkedList和ArrayList最大的区别就是底层使用实现不同
ArrayList可以使用的API,LinkedList都可以用。
由于实现的不同,LinkedList增加一些特殊的API:
-
void addFirst(E e) 在该列表开头插入指定的元素。
-
void addLast(E e) 将指定的元素追加到此列表的末尾。
-
E element() 检索但不删除此列表的头(第一个元素)。
-
E getFirst() 返回此列表中的第一个元素。
-
E getLast() 返回此列表中的最后一个元素。
-
boolean offer(E e) 将指定的元素添加为此列表的尾部(最后一个元素)。
-
boolean offerFirst(E e) 在此列表的前面插入指定的元素。
-
boolean offerLast(E e) 在该列表的末尾插入指定的元素。
-
E peek() 检索但不删除此列表的头(第一个元素)。
-
E peekFirst() 检索但不删除此列表的第一个元素,如果此列表为空,则返回 null 。
-
E peekLast() 检索但不删除此列表的最后一个元素,如果此列表为空,则返回 null 。
-
E poll() 检索并删除此列表的头(第一个元素)。
-
E pollFirst() 检索并删除此列表的第一个元素,如果此列表为空,则返回 null 。
-
E pollLast() 检索并删除此列表的最后一个元素,如果此列表为空,则返回 null 。
-
E pop() 从此列表表示的堆栈中弹出一个元素。
-
void push(E e) 将元素推送到由此列表表示的堆栈上。
-
E removeFirst() 从此列表中删除并返回第一个元素。
-
E removeLast() 从此列表中删除并返回最后一个元素。
上面这些特殊的API都是和“首元素”,“尾元素”相关。
看例子:
//给集合的第一个位置插入元素,重复10000次
long time1 = System.currentTimeMillis();
ArrayList al = new ArrayList();
for(int i = 0;i < 200000;i++){
al.add(0,i);
}
long time2 = System.currentTimeMillis();
LinkedList ll = new LinkedList();
for(int i = 0;i < 200000;i++){
ll.add(0,i);
}
long time3 = System.currentTimeMillis();
System.out.println("ArrayList使用的时间是:"+(time2 - time1) +"ms");// 3156ms
System.out.println("LinkedList使用的时间是:"+(time3 - time2) +"ms");// 9ms
同样的是给第一个位置插入元素,为什么LinkedList这么快?
主要就是底层的实现不同:LinkedList底层是使用链表实现的:
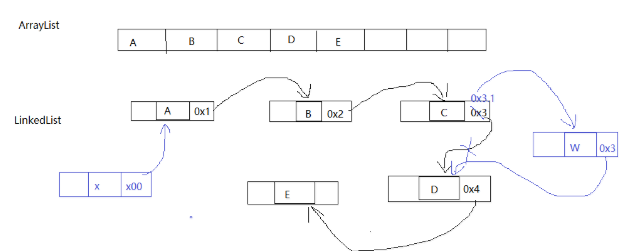
LinkedList使用链表实现。一个LinkedList对象只维护链表的表头和表尾元素。
LinkedList使用双向链表实现,所以给链表中增删元素速度特别快。因为不像ArrayList一样要扩容,要移动元素。
LinekdList随机访问(获取集合中的某个元素)略慢一些。因为无论找第几个元素,都是从头元素开始往后找,找到位置。
面试题: ArrayList和LinkedList的区别?
Vector--List接口的实现类(和ArrayList几乎一致,底层使用数组实现)
Vector用的时候和ArrayList的API没有什么区别。
非常重要的不同点就是Vector的所有的操作元素的方法都是使用synchronized修饰的。

上面的方法是一个实例方法,synchronized可以锁定这个方法的调用者。
当一个Vector对象,被某一个人使用的时候,其他的人不能使用这个Vector对象。这个被称作线程安全。同步
就是我们说过的,你在宿舍上厕所,一定要锁门。
正因为上锁,导致Vector的效率是偏低的,所以我们平时都不适用,但是面试的时候的用。
迭代器 Iterator<E> iterator()
准备集合:
ArrayList<String> al = new ArrayList();
al.add("唐三藏");
al.add("孙悟空");
al.add("八戒");
al.add("沙僧");
al.add("白骨精");
al.add("小丸子");
al.add("卡卡西");
al.add("佐助");
al.add("卡卡西");
问题:遍历ArrayList或者LinkedList或者Vector,方式几乎是统一的。
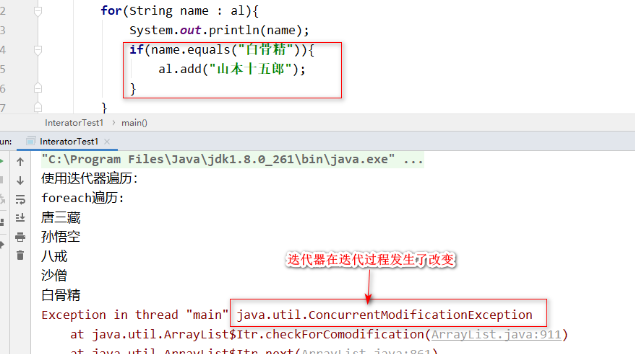
System.out.println("foreach遍历:");
for(String name : al){
System.out.println(name);
}
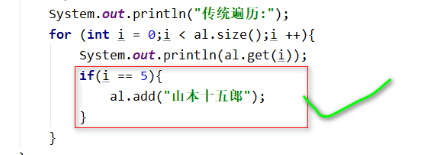
System.out.println("传统遍历:");
for (int i = 0;i < al.size();i ++){
System.out.println(al.get(i));
}
在Collection接口中有一个方法:
-
Iterator<E> iterator() 返回此集合中的元素的迭代器。
Collection定义的方法任何一个List的实现类都实现了这个方法,这个方法返回一个Iterator对象。
Iterator接口中的API:
-
boolean hasNext() 如果迭代具有更多元素,则返回 true 。
-
E next() 返回迭代中的下一个元素。
迭代器是用来迭代集合中的元素的,所有的Collection都实现了迭代器。
当然所有的List其实都不需要迭代器。因为本身就有索引,可以通过索引遍历。
先看迭代器如何使用:其实foreach的方式,就是迭代器实现,所有的实现interator方法的集合都可以使用foreach遍历。
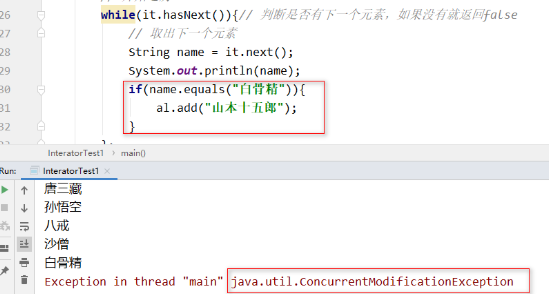
// 获取一个迭代器对象
Iterator<String> it = al.iterator();
// 开始遍历
while(it.hasNext()){// 判断是否有下一个元素,如果没有就返回false
// 取出下一个元素
String name = it.next();
System.out.println(name);
};
使用迭代器不得不知道的问题:
在遍历集合的同时就要修改这个集合中的元素(比如删除或者增加元素)不能用foreach 或迭代器。
传统循环遍历:
foreach:
迭代器遍历:
Set--Collection的子接口(无序不重复)
请问List和Set有什么区别?
List和Set都是Collection的子接口。List是有序可重复的。Set是无序不重复。
API说明:
-
boolean add(E e) 如果指定的元素不存在,则将其指定的元素添加(可选操作)。
-
boolean addAll(Collection<? extends E> c) 将指定集合中的所有元素添加到此集合(如果尚未存在)(可选操作)。
-
void clear() 从此集合中删除所有元素(可选操作)。
-
boolean contains(Object o) 如果此集合包含指定的元素,则返回 true 。
-
boolean containsAll(Collection<?> c) 返回 true如果此集合包含所有指定集合的元素。
-
boolean equals(Object o) 将指定的对象与此集合进行比较以实现相等。
-
boolean isEmpty() 如果此集合不包含元素,则返回 true 。
-
Iterator<E> iterator() 返回此集合中元素的迭代器。
-
boolean remove(Object o) 如果存在,则从该集合中删除指定的元素(可选操作)。
-
int size() 返回此集合中的元素数(其基数)。
HashSet--Set接口的实现类(一个集合中最多只能有一个null)
构造方法:
-
HashSet() 构造一个新的空集合; 背景HashMap实例具有默认初始容量(16)和负载因子(0.75)。
-
HashSet(Collection<? extends E> c) 构造一个包含指定集合中的元素的新集合。
-
HashSet(int initialCapacity) 构造一个新的空集合; 背景HashMap实例具有指定的初始容量和默认负载因子(0.75)。
-
HashSet(int initialCapacity, float loadFactor) 构造一个新的空集合; 背景HashMap实例具有指定的初始容量和指定的负载因子。
API:
所有的API都是实现了接口中的方法。
看测试程序:
public class HashSetTest1 {
public static void main(String[] args) {
HashSet<String> names = new HashSet<>();
// 添加元素
names.add("吃鸡全靠苟");
names.add("一枪死不了");
names.add("最强莽夫");
// 相同的元素是无法加入的
names.add("一枪死不了");
System.out.println(names);
// addAll
ArrayList al = new ArrayList();
al.add("全程就是莽");
al.add("程咬金");
names.addAll(al);
System.out.println(names);
// 判断元素是否在集合中
System.out.println(names.contains("程咬金"));
System.out.println(names.isEmpty());
// 使用foreach遍历
System.out.println("----foreach遍历--");
for (String n : names){
System.out.println(n);
}
System.out.println("---- 迭代器便利 ----");
Iterator<String> it = names.iterator();
while(it.hasNext()){
String name = it.next();
System.out.println(name);
};
}
}
不可重复性
HashSet的元素无序:不保证元素的顺序恒久不变。
HashSet的元素是不能重复的:相同的元素不能加入集合。一个集合中最多只能有一个null。
HashSet如何保证元素不重复?
public class HashSetTest2 {
public static void main(String[] args) {
HashSet<String> names = new HashSet<>();
names.add("吃鸡全靠苟");
names.add("一枪死不了");
names.add("最强莽夫");
names.add("一枪死不了");// 不能加入
System.out.println(names);
HashSet<Integer> ages = new HashSet<>();
ages.add(18);
ages.add(28);
ages.add(38);
ages.add(18); // 不能加入
System.out.println(ages);
}
}
String和所有的基本类型都是实现了不能重复的效果。
如果HashSet存储我们自定义的类型呢?
public class User {
private int id;
private String name;
}
HashSet<User> users = new HashSet<>();
users.add(new User(1,"吃鸡全靠苟"));
users.add(new User(2,"吃鸡全靠莽"));
users.add(new User(3,"全服第一莽"));
users.add(new User(2,"吃鸡全靠莽"));// 成功加入集合
System.out.println(users);
上面的例子中我们可以猜到,HashSet比较元素是否相同是通过equals比较的。
我们上面的案例中两个"吃鸡全靠莽"都是new出来的。所以地址肯定不一样。由于我们没有重写User的equals方法,所以默认其实就是使用”==“比较的。所以两个对象是不一样的。所以可以加入HasHset。
我们重写User的equals方法:
public boolean equals(Object obj){
if(this == obj){
return true;
}
if(!(obj instanceof User)){
return false;// obj不是user类型的
}
User u = (User) obj;
if(this.id==u.getId()){
if(this.name == u.getName()){
return true;
}
if(this.name!=null && this.name.equals(u.getName())){
return true;
}
}
return false;
}
添加equals方法之后,会发现,重复的元素依然重复。
其实HashSet的比较是这样的:任何一个元素要加入集合,先拿这个元素的HashCode和其他元素的HashCode进行比较,如果HashCode相同,再比较equals,如果equals也返回true,就表示相同,否则就认为不相同。
如果HashCode不同,则不比较equals,直接加入集合。
所以HashSet里面的元素也需要重写hashCode方法。
String和基本类型的包装类都已经重写过了这些方法,所以使用时没有任何问题。
hashCode和quals一样都是在Object中申明和实现的。
Object中的hashCode是本地方法。本地方法中的hashCode计算是通过获取对象在内存中的对象头中的数据,进行一系列数据运算得到的。每一个对象头的数据都是不一样的,计算的hashCode是不同的。
我们自己的重写:(equals相同的对象,我们希望hashCode也相同)
public int hashCode(){
// 我们也应该通过id和name进行计算
// 字符序列相同的字符串的hashCode也是相同的。
return this.id*10 + this.name.hashCode()*3;
}
再测试,就会发现后面相同的元素是不能加入集合的。
面试题:HashSet是如何保证元素不重复?
表象:任何一个元素要加入集合,先拿这个元素的HashCode和其他元素的HashCode进行比较,如果HashCode相同,再比较equals,如果equals也返回true,就表示相同,否则就认为不相同。
如果HashCode不同,则不比较equals,直接加入集合。
只有hashCode和equals都相同的元素,才是相同的。
LinkedHashSet--Set接口的实现类(通过一个双向链表记录元素的插入顺序)
面试题:java中有没有有顺序的Set? 有,分别是LinkedHashSet和TreeSet。 下一个问题:这两个set是如何保证元素顺序的? LinekedHashSet通过一个双向链表记录元素的插入顺序。 TreeSet可以在创建的时候指定一个比较器对象,然后TreeSet就会根据这个比较器进行排序。或者加入TreeSet的元素实现接口Comparable,实现comparaTo方法,TreeSet就根据comparaTo比较元素大小进行排序。
API:
没有任何特殊的方法。和HashSet使用方式没有任何区别。
public class LinkedHashSetTest1 {
public static void main(String[] args) {
HashSet<User> users = new HashSet<>();
users.add(new User(2,"吃鸡全靠莽"));
users.add(new User(1,"吃鸡全靠苟"));
users.add(new User(3,"全服第一莽"));
System.out.println(users);
// 遍历
for(User u : users){
System.out.println(u);
}
}
}
关于set的一些形象的理解:
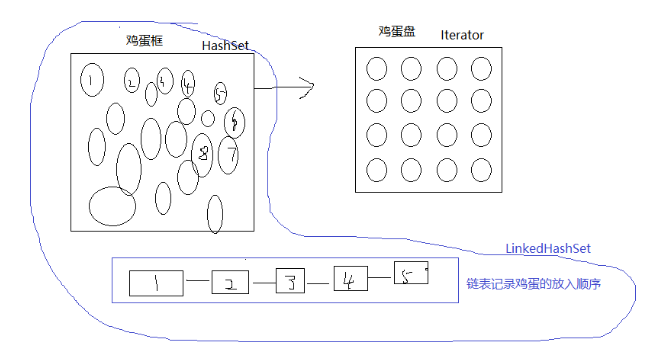
TreeSet--Set接口的实现类(必须给元素排序)
构造方法
-
TreeSet() 构造一个新的空树组,根据其元素的自然排序进行排序(跟HashSet一致)。
-
TreeSet(Collection<? extends E> c) 构造一个包含指定集合中的元素的新树集,根据其元素的 自然排序进行排序 。
-
TreeSet(Comparator<? super E> comparator) 构造一个新的空的树集,根据指定的比较器进行排序。
-
TreeSet(SortedSet<E> s) 构造一个包含相同元素的新树,并使用与指定排序集相同的顺序。
①实现一个比较器 Comparator<e>
我们在构造方法中发现了一个接口: Comparator。
API:
int compare(T o1, T o2) 比较其两个参数的顺序。
在Comparator中只有一个方法需要我们自己实现,其他的方法要么是静态方法,要么是默认方法。
所以我们可以自己实现一个比较器。
比如:自定义一个User的比较器
public class UserComparator implements Comparator<User> {
@Override
public int compare(User user1, User user2) {
//return user1.getId() > user2.getId()?1:user1.getId() == user2.getId()?0:-1;
if(user1.getId() > user2.getId()){
return 1;
}
if(user1.getId() == user2.getId()){
return 0;
}
return -1;
}
}
有了这个比较器,我们在创建一个TreeSet的时候,就可以设置这个比较器。
public static void main(String[] args) {
UserComparator comparator = new UserComparator();
// 创建TreeSet的时候,传入一个用户的比较器
TreeSet<User> users = new TreeSet<>(comparator);
users.add(new User(2,"吃鸡全靠莽"));
users.add(new User(1,"吃鸡全靠苟"));
users.add(new User(3,"全服第一莽"));
System.out.println(users);
// 遍历
for(User u : users){
System.out.println(u);
}
}
在创建TreeSet的时候,传入对应的比较器,TreeSet就知道应该如何排序。
②自然顺序排序 实现Comparable接口
不使用比较器测试程序:
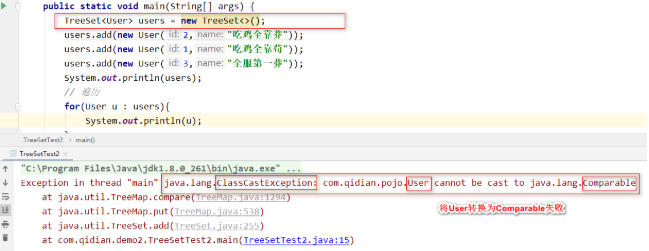
我们自己没有做任何转换,说明在TreeSet内部尝试将User对象转换为Comparable。
TreeSet必须要给元素排序,要排序,就必须要比较元素的大小,要么指定比较器。要么这个元素本身是可以比较大小的。
元素本身要实现比较大小,就要实现接口Comparable。
Comparable接口中只有一个方法:
-
int compareTo(T o) 将此对象与指定的对象进行比较以进行排序。
所以,在没有指定比较器的情况下,TreeSet要求我们的User实现Comparable接口。
public class User implements Comparable{
private int id;
private String name;
// 如果当前对象大于o,就返回1,如果小于o就返回-1,否则返回0
public int compareTo(Object o) {
if(!(o instanceof User)){
throw new ClassCastException("比较对象 ["+o.toString()+"]不是User类型");
}
User u = (User) o;
return this.id > u.getId()?1:this.id == u.getId()?0:-1;
}
//......
}
在测试,就正常了。
TreeSet是有顺序的,所有有一些特殊的API:
-
E ceiling(E e) 返回此集合中最小元素大于或等于给定元素,如果没有此元素,则返回 null 。
-
E floor(E e) 返回此集合中最大的元素小于或等于给定元素,如果没有这样的元素,则返回 null 。
-
E first() 返回此集合中当前的第一个(最低)元素。
-
E last() 返回此集合中当前的最后(最高)元素。
-
E lower(E e) 返回这个集合中最大的元素严格小于给定的元素,如果没有这样的元素,则返回 null 。
-
E pollFirst() 检索并删除第一个(最低)元素,或返回 null如果该集合为空。
-
E pollLast() 检索并删除最后一个(最高)元素,如果此集合为空,则返回 null 。
-
NavigableSet<E> subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive) 返回该集合的部分的视图,其元素的范围从 fromElement到 toElement 。
-
SortedSet<E> subSet(E fromElement, E toElement) 返回此集合的部分的视图,其元素的范围从 fromElement (含)到 toElement ,排他。
单列集合的总结

Map--双列集合的最顶层接口
家谱:
所有的key都是存储在一个数组中的,value随意。
key和value的关系就好比:一个身份证对应一个人一样。
MAP接口中的API:
-
void clear() 从该地图中删除所有的映射(可选操作)。
-
boolean containsKey(Object key) 如果此映射包含指定键的映射,则返回 true 。
-
boolean containsValue(Object value) 如果此地图将一个或多个键映射到指定的值,则返回 true 。
-
Set<Map.Entry<K,V>> entrySet() 返回此地图中包含的映射的Set视图。
-
V get(Object key) 返回到指定键所映射的值,或 null如果此映射包含该键的映射。
-
boolean isEmpty() 如果此地图不包含键值映射,则返回 true 。
-
Set<K> keySet() 返回此地图中包含的键的Set视图。
-
V put(K key, V value) 将指定的值与该映射中的指定键相关联(可选操作)。
-
void putAll(Map<? extends K,? extends V> m) 将指定地图的所有映射复制到此映射(可选操作)。
-
V remove(Object key) 如果存在(从可选的操作),从该地图中删除一个键的映射。
-
int size() 返回此地图中键值映射的数量。
-
Collection<V> values() 返回此地图中包含的值的Collection视图。
①HashMap--Map接口的实现类(无序不重复 允许null值null键 不同步)
构造方法:
-
HashMap() 构造一个空的 HashMap ,默认初始容量(16)和默认负载系数(0.75)。
-
HashMap(int initialCapacity) 构造一个空的 HashMap具有指定的初始容量和默认负载因子(0.75)。
-
HashMap(int initialCapacity, float loadFactor) 构造一个空的 HashMap具有指定的初始容量和负载因子。
-
HashMap(Map<? extends K,? extends V> m) 构造一个新的 HashMap与指定的相同的映射 Map 。
特有的API:
没有自己特有的API,都是Map接口定义好的。
看一个使用案例:
public class HashMapTest1 {
public static void main(String[] args) {
// 创建一个空的HashMap
HashMap<Integer, User> userMap = new HashMap<>();
// 添加映射关系
userMap.put(1,new User(1,"一枪打不死"));
userMap.put(2,new User(2,"吃鸡全靠苟"));
userMap.put(3,new User(3,"从头莽到尾"));
// 输出
System.out.println(userMap);
}
}

-
put(key,value) 给集合中添加或者修改一个键值对。
// 创建一个空的HashMap HashMap<Integer, User> userMap = new HashMap<>(); // 添加映射关系 userMap.put(1,new User(1,"一枪打不死")); userMap.put(2,new User(2,"吃鸡全靠苟")); userMap.put(3,new User(3,"从头莽到尾")); // 修改原来key为3的value userMap.put(3,new User(3,"吃鸡全靠莽"));
HashMap中的key是不可能重复的。一旦出现相同的key,就是覆盖之前的value。HashMap的key可以有一个null。
其他的API:
public class HashMapTest1 {
public static void main(String[] args) {
// 创建一个空的HashMap
HashMap<Integer, User> userMap = new HashMap<>();
// 添加映射关系
userMap.put(1,new User(1,"一枪打不死"));
userMap.put(2,new User(2,"吃鸡全靠苟"));
userMap.put(3,new User(3,"从头莽到尾"));
// 修改原来key为3的value
userMap.put(3,new User(3,"吃鸡全靠莽"));
// 输出
System.out.println(userMap);
// 获取元素个数
System.out.println(userMap.size());
// 清空集合
// userMap.clear();
// System.out.println(userMap.size());
// 检查key是否存在
boolean b = userMap.containsKey(2);
System.out.println(b);
// 检查指定的value是否存在(要求value中的元素也要重写equals)
b = userMap.containsValue(new User(3, "吃鸡全靠莽"));
System.out.println(b);
// 通过key获取value
System.out.println(userMap.get(2));
System.out.println(userMap.get(20)); // null
// 判断集合的元素个数是否为空
System.out.println(userMap.isEmpty());
// 加入子集合
HashMap<Integer,User> us = new HashMap<>();
us.put(15,new User(15,"从头苟到尾"));
us.put(16,new User(16,"大家一起苟"));
userMap.putAll(us);
System.out.println(userMap);
// 通过key删除元素
User removeUser = userMap.remove(16);
System.out.println(removeUser);
System.out.println(userMap);
}
}
HashMap的遍历:
单列集合。可以使用传统的for循环,或者foreach或者迭代器。
双列集合无法直接使用for遍历,于是map提供了方便遍历的一些API:
-
Set<K> keySet() 返回此地图中包含的键的Set视图。
-
Collection<V> values() 返回此地图中包含的值的Collection视图。
-
Set<Map.Entry<K,V>> entrySet() 返回此地图中包含的映射的Set视图。
public class HashMapTest2 {
public static void main(String[] args) {
// 创建一个空的HashMap
HashMap<Integer, User> userMap = new HashMap<>();
// 添加映射关系
userMap.put(1,new User(1,"一枪打不死"));
userMap.put(2,new User(2,"吃鸡全靠苟"));
userMap.put(3,new User(3,"从头莽到尾"));
userMap.put(15,new User(15,"从头苟到尾"));
userMap.put(16,new User(16,"大家一起苟"));
System.out.println(userMap);
// 利用keyset遍历
/*
keySet方法会返回一个set,这个set中存储着这个map中所有的key。
这里返回的set是HashSet,LinkedHashSet还是什么?实际上是一个HashMap的一个内部类KeySet。
但是我们不需要关心这个set是什么,我们只要知道它实现set接口即可。
我们也是使用Set接口类型来接收这个返回值的。
只要是set就可以使用foreach遍历或者使用迭代器遍历
* */
Set<Integer> keys = userMap.keySet();
for (Integer key : keys){
// 通过key获取对应的value(user对象)
User u = userMap.get(key);
System.out.println(key+":"+u);
}
System.out.println("-------------");
// 使用values遍历map
// values方法会返回一个Collection类型的对象,这个集合中存储着所有的value。
// 这个返回的Collection无论是list还是set都无所谓。
// 只要是Collection就可以使用foreach或者迭代器遍历
// 这里的问题就是无法获取对应的key。
Collection<User> values = userMap.values();
Iterator<User> it = values.iterator();
while(it.hasNext()){
User user = it.next();
System.out.println(user);
};
System.out.println("-----------------");
// 使用entrySet方法遍历
// entrySet方法返回一个Set,这个set内部的元素是Map.Entry类型的。一个Entry就表示一个键值对。
Set<Map.Entry<Integer, User>> entries = userMap.entrySet();
for (Map.Entry<Integer,User> entry : entries){
System.out.println(entry.getKey()+":"+entry.getValue());
}
}
}
HashMap的key:
HashMap的特点:
key是不能重复的(和HashSet完全一致)。
key是没有顺序(和HashSet完全一致)。
HashMap的泛型是两个 :

这里的泛型可以是任何数据类型(基本类型除外)。
我们也可以使用自定义类型。比如我们自己定义一个key:
public class QidianKey {
private int id;
private String keyName;
}
使用我们自定义的key创建map:
public class HashMapTest3 {
public static void main(String[] args) {
// 创建一个空的HashMap
// 可以使用我自定义的引用类型(一般都是使用基本的类型的包装类型或者String)
HashMap<QidianKey, User> userMap = new HashMap<>();
// 添加映射关系
userMap.put(new QidianKey(1,"壹"),new User(1,"一枪打不死"));
userMap.put(new QidianKey(2,"贰"),new User(2,"吃鸡全靠苟"));
userMap.put(new QidianKey(3,"叁"),new User(3,"从头莽到尾"));
userMap.put(new QidianKey(4,"肆"),new User(15,"从头苟到尾"));
// 覆盖之前的”一枪打不死“
userMap.put(new QidianKey(1,"壹"),new User(16,"大家一起苟"));// 无法覆盖
System.out.println(userMap);
}
}
HashSet不能有重复的元素,判断元素重复就是判断hashCode和equals的值。
HasetMap不能有重复的key,判断key是否重复,就是判断key的hashCode和equals的值。
如果我们使用自定义的元素作为HashMap的key,那么我们就要重写这个自定义类型的hashCode和equals。
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
QidianKey qidianKey = (QidianKey) o;
if (id != qidianKey.id) return false;
return keyName != null ? keyName.equals(qidianKey.keyName) : qidianKey.keyName == null;
}
@Override
public int hashCode() {
int result = id;
result = 31 * result + (keyName != null ? keyName.hashCode() : 0);
return result;
}
重写之后再测试,就会发现,后面重复的key就会覆盖之前的value。
HashSet的底层是使用HashMap实现的
翻源码:
HashSet的构造方法:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
// 成员变量,HashMap
private transient HashMap<E,Object> map;
// 这里准备一个空对象
private static final Object PRESENT = new Object();
// 构造方法
public HashSet() {
// 在内部创建了一个HashMap
map = new HashMap<>();
}
//...
}
查看add方法:
// 接收的参数e就是我们要加入HashSet的元素。
public boolean add(E e) {
// 将这个e作为HashMap的key,空对象作为HashMap的Value。
return map.put(e, PRESENT)==null;
}
接下来的操作都是HashMap的操作了。根据HashSet已经无关了。
其实我们给HashSet中存储一对的元素,结果大概是这样的:
最终就是我们存储到set中的元素会作为HashMap的key存储在内存中。而这个HashMap的value都是同一个空对象。
[1]构造过程
HashMap map = new HashMap();
源码:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
// -----------常量---都是它需要的默认值
// 初始化容量(16)
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 最大容量()
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 树化阈值
static final int TREEIFY_THRESHOLD = 8;
// 链表化的阈值
static final int UNTREEIFY_THRESHOLD = 6;
// 最小树化容量
static final int MIN_TREEIFY_CAPACITY = 64;
// ---------属性----
// 节点数组 (就是存储元素的数组)
transient Node<K,V>[] table;
// 负载因子
final float loadFactor;
// 无参构造
public HashMap() {
// 设置当前这个map对象的负载因子为默认的负载因子
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
}
结论:当我们创建一个HashMap的时候,仅仅是创建了一个HashMap对象,并且设置负载因子为默认值。
一个需要说明的构造过程:
// 理论上:设置一个初始的容量创建HashMap
HashMap map = new HashMap(20);
源码:
public HashMap(int initialCapacity) {
// 我们设置的容量20
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 通过this调用另外一个构造方法
public HashMap(int initialCapacity, float loadFactor) {
// 如果你设置了一个小于零的容量, 直接抛出异常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 如果容量大于最大容量,则直接将容量设置为最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 判断负载因子是否合法
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
// tableSizeFor(20) 规范数组容量数据
this.threshold = tableSizeFor(initialCapacity);
}
// cap = 20 --> 32
// 将你设置的容量修改为 比你设置的数字大的第一个2的整次幂数。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
结论:当我们创建HashMap的时候,设置的容量,并不一定会被使用,HashMap会自动将设置的容量修改为比设置的容量大的第一个2的整次幂数。
[2]添加元素的过程
map.put(1,"壹");
源码:
public V put(K key, V value) {
// 一对参数
return putVal(hash(key), key, value, false, true);
}
// 根据传入的key计算hash值
static final int hash(Object key) {
int h;
// 根据这个key得到一个唯一的hash值
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// 将数据放入集合
/**
* Implements Map.put and related methods.
* @param hash key的hash值
* @param key the key
* @param value the value to put
* @param 是否更新现有的value值
* @param 如果是false,表示是创建模式
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// 申明了Node数组tab,Node元素 p ,还有两个整形变量
// n表示数组的长度 i表述元素应该存储的索引位置
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 判断存储数据的数组是否为空,如果为空就准备创建
if ((tab = table) == null || (n = tab.length) == 0){
// 创建或者扩容数组,并且返回数组的长度赋值给n
n = (tab = resize()).length;
}
// 通过数组的长度和key的hash计算这个元素应该在数组的什么位置
if ((p = tab[i = (n - 1) & hash]) == null){
// 数组的这个位置上是没有元素的,就立刻创建一个新的node
tab[i] = newNode(hash, key, value, null);
}else {
// 申明Node类型e, k
Node<K,V> e; K k;
// 判断传入的key是否和当前位置上的元素的key完全相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;// 记录当前位置上的元素p到e中。
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 遍历链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {