IO多路复用
IO多路复用
阻塞IO(block):
blocking IO的特点就是在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了。
非阻塞IO(nonblocking):
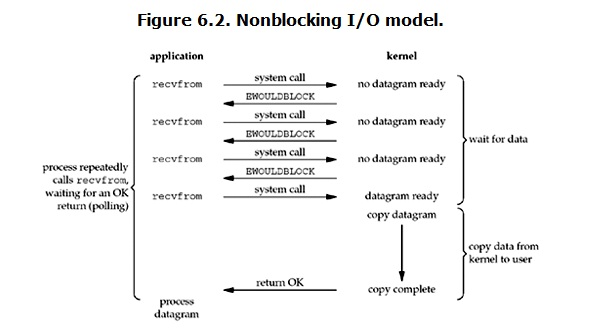
1.用户进程发送接收数据
2.内核返回error还没有数据,进程先忙其他一段时间接着继续发
3.重复第二步
4.内核把数据拷贝用户内存,用户进程拷贝数据返回。
所以,在非阻塞式IO中,用户进程其实是需要不断的主动询问kernel数据准备好了没有。
但是非阻塞IO模型绝不被推荐。
我们不能否则其优点:能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在“”同时“”执行)。
但是也难掩其缺点:
#1. 循环调用recv()将大幅度推高CPU占用率;这也是我们在代码中留一句time.sleep(2)的原因,否则在低配主机下极容易出现卡机情况
#2. 任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
此外,在这个方案中recv()更多的是起到检测“操作是否完成”的作用,实际操作系统提供了更为高效的检测“操作是否完成“作用的接口,例如select()多路复用模式,可以一次检测多个连接是否活跃。
同步IO:
非同步IO:
多路复用IO:
select/poll 单个process可以处理多个IO操作
1.用户进程调用select,程序阻塞
2.内核会监控所有select的socket
3.当任何一个socket中的数据准备好了,select就会返回。
4.用户进程调用read拷贝数据
这种方法跟blocking差不多
优点:这种可以同时处理多个连接,如果连接数比较高的话,有较好的的优化. 支持跨平台
缺点:当连接数比较少的其性能还不如blocking+multiThreading;两次拷贝耗时、轮询所有fd耗时,支持的文件描述符太小


 浙公网安备 33010602011771号
浙公网安备 33010602011771号