

前端篇
用Vue.js开发微信小程序:开源框架mpvue解析
Flutter原理与实践
Picasso 开启大前端的未来
美团客户端响应式框架 EasyReact 开源啦
Logan:美团点评的开源移动端基础日志库
美团点评移动端基础日志库——Logan
MCI:移动持续集成在大众点评的实践
美团外卖Android Crash治理之路
美团外卖Android平台化的复用实践
美团外卖Android平台化架构演进实践
美团外卖Android Lint代码检查实践
Android动态日志系统Holmes
Android消息总线的演进之路:用LiveDataBus替代RxBus、EventBus
Android组件化方案及组件消息总线modular-event实战
Android自动化页面测速在美团的实践
Kotlin代码检查在美团的探索与实践
WMRouter:美团外卖Android开源路由框架
美团外卖客户端高可用建设体系
iOS 覆盖率检测原理与增量代码测试覆盖率工具实现
iOS系统中导航栏的转场解决方案与最佳实践
Category 特性在 iOS 组件化中的应用与管控
美团开源Graver框架:用“雕刻”诠释iOS端UI界面的高效渲染
美团外卖iOS App冷启动治理
美团外卖iOS多端复用的推动、支撑与思考
【基本功】深入剖析Swift性能优化
前端安全系列(一):如何防止XSS攻击?
前端安全系列(二):如何防止CSRF攻击?
Hades:移动端静态分析框架
Jenkins的Pipeline脚本在美团餐饮SaaS中的实践
MSON,让JSON序列化更快
Toast与Snackbar的那点事
WWDC案例解读:大众点评相机直接扫描支付是怎么实现的
beeshell —— 开源的 React Native 组件库
前端遇上Go: 静态资源增量更新的新实践
深入理解JSCore
深度学习及AR在移动端打车场景下的应用
美团点评金融平台Web前端技术体系
插件化、热补丁中绕不开的Proguard的坑
美团扫码付小程序的优化实践
用微前端的方式搭建类单页应用
构建时预渲染:网页首帧优化实践
美团扫码付的前端可用性保障实践
ARKit:增强现实技术在美团到餐业务的实践
用Vue.js开发微信小程序:开源框架mpvue解析
前言
mpvue 是一款使用 Vue.js 开发微信小程序的前端框架。使用此框架,开发者将得到完整的 Vue.js 开发体验,同时为 H5 和小程序提供了代码复用的能力。如果想将 H5 项目改造为小程序,或开发小程序后希望将其转换为 H5,mpvue 将是十分契合的一种解决方案。
目前, mpvue 已经在美团点评多个实际业务项目中得到了验证,因此我们决定将其开源,希望更多技术同行一起开发,应用到更广泛的场景里去。github 项目地址请参见 mpvue 。使用文档请参见 http://mpvue.com/。
为了帮助大家更好的理解 mpvue 的架构,接下来我们来解析框架的设计和实现思路。文中主要内容已经发表在《程序员》杂志2017年第9期小程序专题封面报道,内容略有修改。
小程序开发特点
微信小程序推荐简洁的开发方式,通过多页面聚合完成轻量的产品功能。小程序以离线包方式下载到本地,通过微信客户端载入和启动,开发规范简洁,技术封装彻底,自成开发体系,有 Native 和 H5 的影子,但又绝不雷同。
小程序本身定位为一个简单的逻辑视图层框架,官方并不推荐用来开发复杂应用,但业务需求却难以做到精简。复杂的应用对开发方式有较高的要求,如组件和模块化、自动构建和集成、代码复用和开发效率等,但小程序开发规范较大的限制了这部分能力。为了解决上述问题,提供更好的开发体验,我们创造了 mpvue,通过使用 Vue.js 来开发微信小程序。
mpvue是什么
mpvue 是一套定位于开发小程序的前端开发框架,其核心目标是提高开发效率,增强开发体验。使用该框架,开发者只需初步了解小程序开发规范、熟悉 Vue.js 基本语法即可上手。框架提供了完整的 Vue.js 开发体验,开发者编写 Vue.js 代码,mpvue 将其解析转换为小程序并确保其正确运行。此外,框架还通过 vue-cli 工具向开发者提供 quick start 示例代码,开发者只需执行一条简单命令,即可获得可运行的项目。
为什么做mpvue
在小程序内测之初,我们计划快速迭代出一款对标 H5 的产品实现,核心诉求是:快速实现、代码复用、低成本和高效率… 随后经历了多个小程序建设,结合业务场景、技术选型和小程序开发方式,我们整理汇总出了开发阶段面临的主要问题:
- 组件化机制不够完善
- 代码多端复用能力欠缺
- 小程序框架和团队技术栈无法有机结合
- 小程序学习成本不够低
组件机制:小程序逻辑和视图层代码彼此分离,公共组件提取后无法聚合为单文件入口,组件需分别在视图层和逻辑层引入,维护性差;组件无命名空间机制,事件回调必须设置为全局函数,组件设计有命名冲突的风险,数据封装不强。开发者需要友好的代码组织方式,通过 ES 模块一次性导入;组件数据有良好的封装。成熟的组件机制,对工程化开发至关重要。
多端复用:常见的业务场景有两类,通过已有 H5 产品改造为小程序应用或反之。从效率角度出发,开发者希望通过复用代码完成开发,但小程序开发框架却无法做到。我们尝试过通过静态代码分析将 H5 代码转换为小程序,但只做了视图层转换,无法带来更多收益。多端代码复用需要更成熟的解决方案。
引入 Vue.js:小程序开发方式与 H5 近似,因此我们考虑和 H5 做代码复用。沿袭团队技术栈选型,我们将 Vue.js 确定为小程序开发规范。使用 Vue.js 开发小程序,将直接带来如下开发效率提升:
- H5 代码可以通过最小修改复用到小程序
- 使用 Vue.js 组件机制开发小程序,可实现小程序和 H5 组件复用
- 技术栈统一后小程序学习成本降低,开发者从 H5 转换到小程序不需要更多学习
- Vue.js 代码可以让所有前端直接参与开发维护
为什么是 Vue.js?这取决于团队技术栈选型,引入新的选型与统一技术栈和提高开发效率相悖,有违开发工具服务业务的初衷。
mpvue 的演进
mpvue的形成,来源于业务场景和需求,最终方案的确定,经历了三个阶段。
第一阶段:我们实现了一个视图层代码转换工具,旨在提高代码首次开发效率。通过将H5视图层代码转换为小程序代码,包括 HTML 标签映射、Vue.js 模板和样式转换,在此目标代码上进行二次开发。我们做到了有限的代码复用,但组件化开发和小程序学习成本并未得到有效改善。
第二阶段:我们着眼于完善代码组件化机制。参照 Vue.js 组件规范设计了代码组织形式,通过代码转换工具将代码解析为小程序。转换工具主要解决组件间数据同步、生命周期关联和命名空间问题。最终我们实现了一个 Vue.js 语法子集,但想要实现更多特性或跟随 Vue.js 版本迭代,工作量变得难以估计,有永无止境之感。
第三阶段:我们的目标是实现对 Vue.js 语法全集的支持,达到使用 Vue.js 开发小程序的目的。并通过引入 Vue.js runtime 实现了对 Vue.js 语法的支持,从而避免了人肉语法适配。至此,我们完成了使用 Vue.js 开发小程序的目的。较好地实现了技术栈统一、组件化开发、多端代码复用、降低学习成本和提高开发效率的目标。
mpvue设计思路
Vue.js 和小程序都是典型的逻辑视图层框架,逻辑层和视图层之间的工作方式为:数据变更驱动视图更新;视图交互触发事件,事件响应函数修改数据再次触发视图更新,如图1所示。

鉴于 Vue.js 和小程序一致的工作原理,我们思考将小程序的功能托管给 Vue.js,在正确的时机将数据变更同步到小程序,从而达到开发小程序的目的。这样,我们可以将精力聚焦在 Vue.js 上,参照 Vue.js 编写与之对应的小程序代码,小程序负责视图层展示,所有业务逻辑收敛到 Vue.js 中,Vue.js 数据变更后同步到小程序,如图2所示。如此一来,我们就获得了以 Vue.js 的方式开发小程序的能力。为此,我们设计的方案如下:
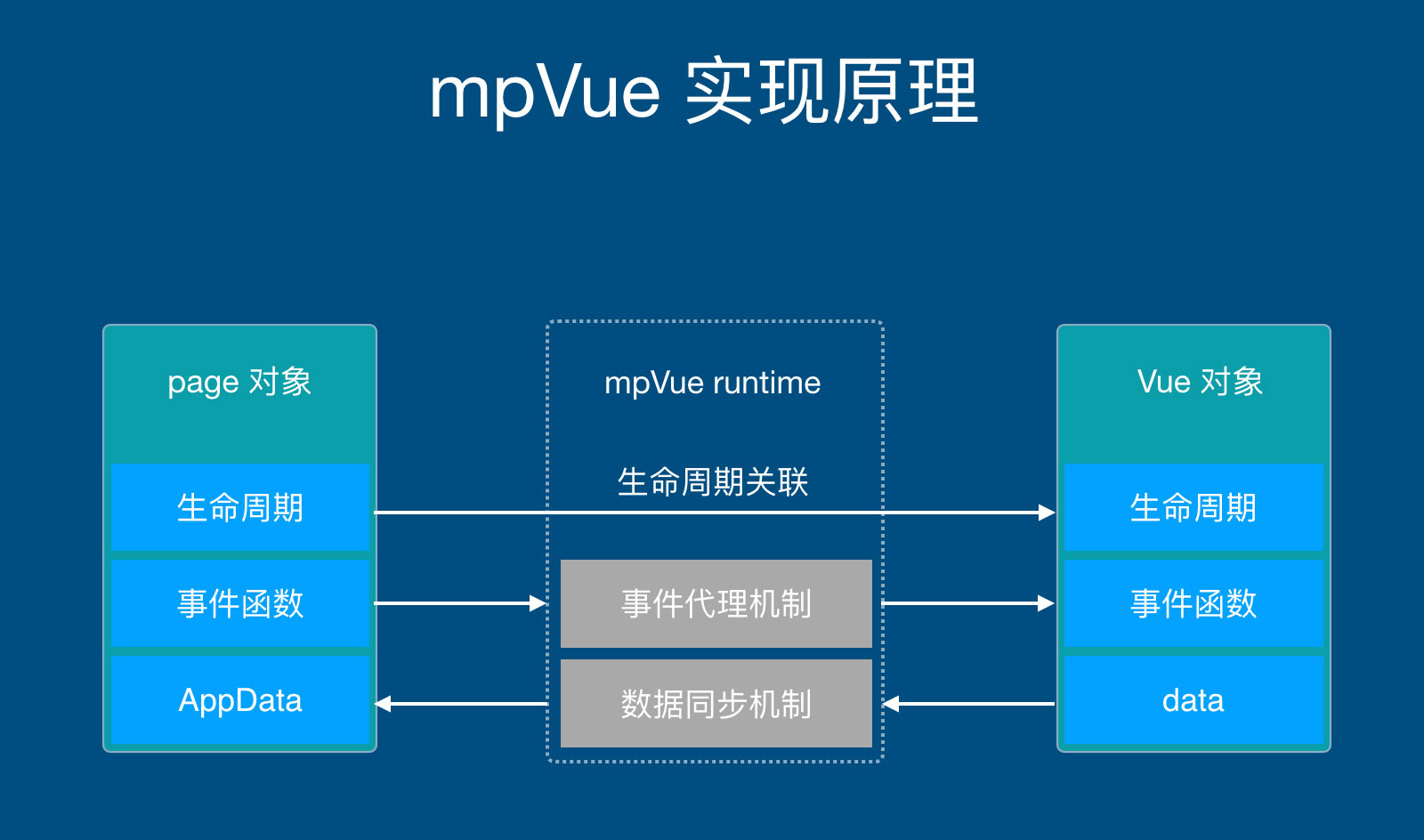
Vue代码
- 将小程序页面编写为 Vue.js 实现
- 以 Vue.js 开发规范实现父子组件关联
小程序代码
- 以小程序开发规范编写视图层模板
- 配置生命周期函数,关联数据更新调用
- 将 Vue.js 数据映射为小程序数据模型
并在此基础上,附加如下机制
- Vue.js 实例与小程序 Page 实例建立关联
- 小程序和 Vue.js 生命周期建立映射关系,能在小程序生命周期中触发 Vue.js 生命周期
- 小程序事件建立代理机制,在事件代理函数中触发与之对应的 Vue.js 组件事件响应
这套机制总结起来非常简单,但实现却相当复杂。在揭秘具体实现之前,读者可能会有这样一些疑问:
- 要同时维护 Vue.js 和小程序,是否需要写两个版本的代码实现?
- 小程序负责视图层展现,Vue.js的视图层是否还需要,如果不需要应该如何处理?
- 生命周期如何打通,数据同步更新如何实现?
上述问题包含了 mpvue 框架的核心内容,下文将仔细为你道来。首先,mpvue 为提高效率而生,本身提供了自动生成小程序代码的能力,小程序代码根据 Vue.js 代码构建得到,并不需要同时开发两套代码。
Vue.js 视图层渲染由 render 方法完成,同时在内存中维护着一份虚拟 DOM,mpvue 无需使用 Vue.js 完成视图层渲染,因此我们改造了 render 方法,禁止视图层渲染。熟悉源代码的读者,都知道 Vue runtime 有多个平台的实现,除了我们常见的 Web 平台,还有 Weex。从现在开始,我们增加了新的平台 mpvue。
生命周期关联:生命周期和数据同步是 mpvue 框架的灵魂,Vue.js 和小程序的数据彼此隔离,各自有不同的更新机制。mpvue 从生命周期和事件回调函数切入,在 Vue.js 触发数据更新时实现数据同步。小程序通过视图层呈现给用户、通过事件响应用户交互,Vue.js 在后台维护着数据变更和逻辑。可以看到,数据更新发端于小程序,处理自 Vue.js,Vue.js 数据变更后再同步到小程序。为实现数据同步,mpvue 修改了 Vue.js runtime 实现,在 Vue.js 的生命周期中增加了更新小程序数据的逻辑。
事件代理机制:用户交互触发的数据更新通过事件代理机制完成。在 Vue.js 代码中,事件响应函数对应到组件的 method, Vue.js 自动维护了上下文环境。然而在小程序中并没有类似的机制,又因为 Vue.js 执行环境中维护着一份实时的虚拟 DOM,这与小程序的视图层完全对应,我们思考,在小程序组件节点上触发事件后,只要找到虚拟 DOM 上对应的节点,触发对应的事件不就完成了么;另一方面,Vue.js 事件响应如果触发了数据更新,其生命周期函数更新将自动触发,在此函数上同步更新小程序数据,数据同步也就实现了。
mpvue如何使用
mpvue框架本身由多个npm模块构成,入口模块已经处理好依赖关系,开发者只需要执行如下代码即可完成本地项目创建。
# 安装 vue-cli
$ npm install --global vue-cli
# 根据模板项目创建本地项目,目前为内网地址
$ vue init mpvue/mpvue-quickstart my-project
# 安装依赖和启动自动构建
$ cd my-project
$ npm install
$ npm run dev
执行完上述命令,在当前项目的 dist 子目录将构建出小程序目标代码,使用小程序开发者工具载入 dist 目录即可启动本地调试和预览。示例项目遵循 Vue.js 模板项目规范,通过Vue.js 命令行工具vue-cli创建。代码组织形式与 Vue.js 官方实例保持一致,我们为小程序定制了 Vue.js runtime 和 webpack 加载器,此部分依赖也已经内置到项目中。
针对小程序开发中常见的两类代码复用场景,mpvue 框架为开发者提供了解决思路和技术支持,开发者只需要在此指导下进行项目配置和改造。我们内部实践了一个将 H5 转换为小程序的项目,下图为使用 mpvue 框架的转换效果:
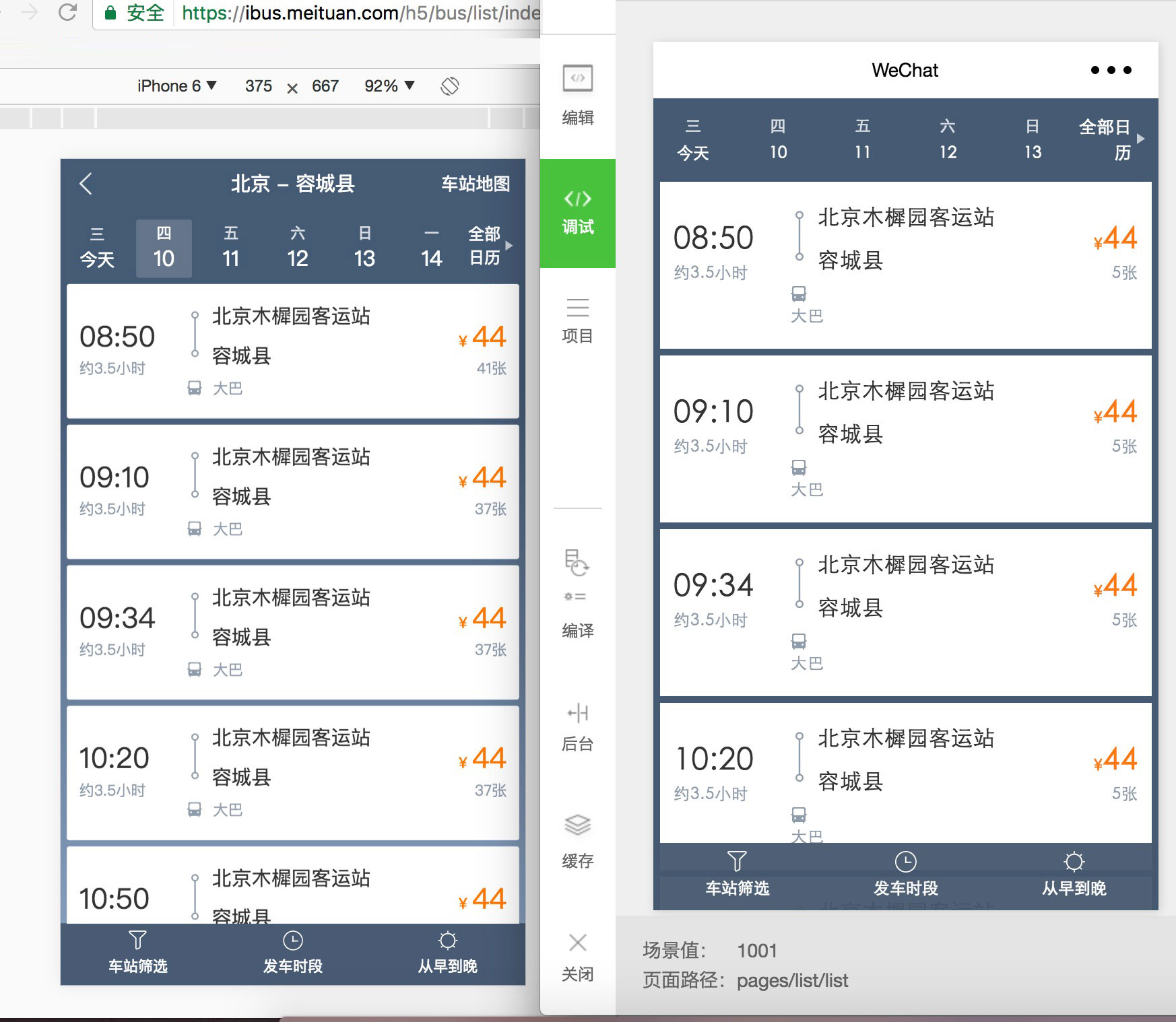
将小程序转换为H5:直接使用 Vue.js 规范开发小程序,代码本身与H5并无不同,具体代码差异会集中在平台 Api 部分。此外并不需明显改动,改造主要分如下几部分:
- 将小程序平台的 Vue.js 框架替换为标准 Vue.js
- 将小程序平台的 vue-loader 加载器替换为标准 vue-loader
- 适配和改造小程序与 H5 的底层 Api 差异
将H5转换为小程序:已经使用 Vue.js 开发完 H5,我们需要做的事情如下:
- 将标准 Vue.js 替换为小程序平台的 Vue.js 框架
- 将标准 vue-loader 加载器替换为小程序平台的 vue-loader
- 适配和改造小程序与 H5 的底层 Api 差异
根据小程序开发平台提供的能力,我们最大程度的支持了 Vue.js 语法特性,但部分功能现阶段暂时尚未实现。

项目转换注意事项:框架的目标是将小程序和 H5 的开发方式通过 Vue.js 建立关联,达到最大程度的代码复用。但由于平台差异的客观存在(主要集中在实现机制、底层Api 能力差异),我们无法做到代码 100% 复用,平台差异部分的改造成本无法避免。对于代码复用的场景,开发者需要重点思考如下问题并做好准备:
- 尽量使用平台无的语法特性,这部分特性无需转换和适配成本
- 避免使用不支持的语法特性,譬如 slot, filter 等,降低改造成本
- 如果使用特定平台 Api ,考虑抽象好适配层接口,通过切换底层实现完成平台转换
mpvue 最佳实践
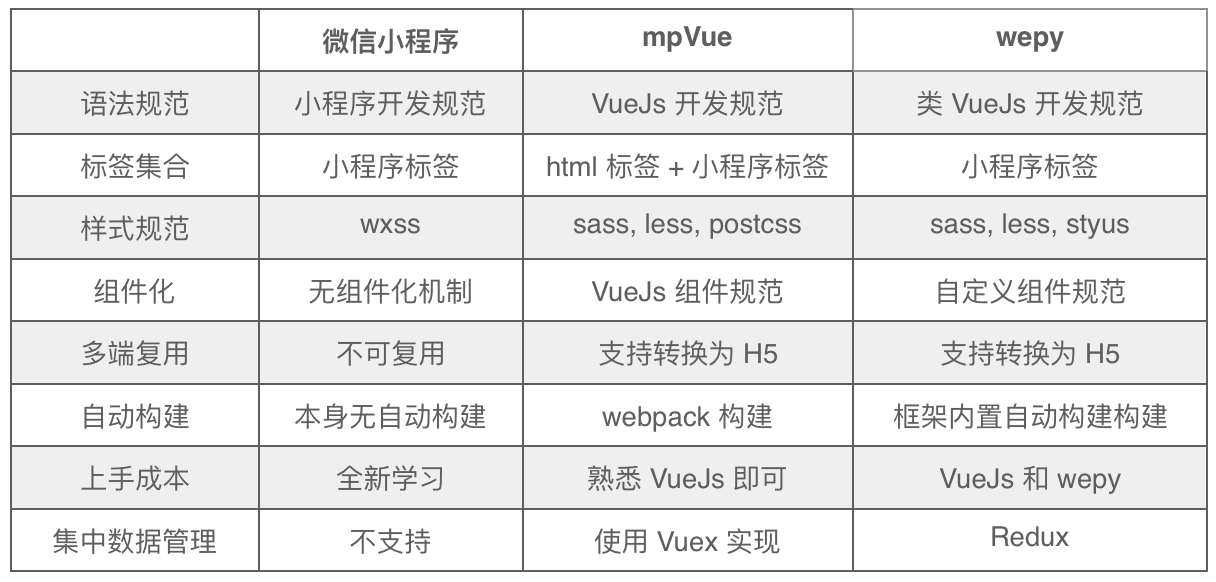
在表2中,我们对微信小程序、mpvue、WePY 这三个开发框架的主要能力和特点做了横向对比,帮助大家了解不同框架的侧重点,结合业务场景和开发习惯,确定技术方案。对于如何更好地使用 mpvue 进行小程序开发,我们总结了一些最佳实践。
- 使用 vue-cli 命令行工具创建项目,使用Vue 2.x 的语法规范进行开发
- 避免使用框架不支持的语法特性,部分 Vue.js语法在小程序中无法使用,尽量使用 mpvue 和 Vue.js 共有特性
- 合理设计数据模型,对数据的更新和操作做到细粒度控制,避免性能问题
- 合理使用组件化开发小程序,提高代码复用率
结语
mpvue 框架已经在业务项目中得到实践和验证,目前正在美团点评内部大范围使用。mpvue 来源于开源社区,饮水思源,我们也希望为开源社区贡献一份力量,为广大小程序开发者提供一套技术方案。mpvue 的初衷是让 Vue.js 的开发者以低成本接入小程序开发,做到代码的低成本迁移和复用,我们未来会继续扩展现有能力、解决开发者的诉求、优化使用体验、完善周边生态建设,帮助到更多的开发者。
最后,mpvue 基于 Vue.js 源码进行二次开发,新增加了小程序平台的实现,我们保留了跟随 Vue.js 版本升级的能力,由衷的感谢 Vue.js 框架和微信小程序给业界带来的便利。
Flutter原理与实践
Flutter是Google开发的一套全新的跨平台、开源UI框架,支持iOS、Android系统开发,并且是未来新操作系统Fuchsia的默认开发套件。自从2017年5月发布第一个版本以来,目前Flutter已经发布了近60个版本,并且在2018年5月发布了第一个“Ready for Production Apps”的Beta 3版本,6月20日发布了第一个“Release Preview”版本。
初识Flutter
Flutter的目标是使同一套代码同时运行在Android和iOS系统上,并且拥有媲美原生应用的性能,Flutter甚至提供了两套控件来适配Android和iOS(滚动效果、字体和控件图标等等)为了让App在细节处看起来更像原生应用。
在Flutter诞生之前,已经有许多跨平台UI框架的方案,比如基于WebView的Cordova、AppCan等,还有使用HTML+JavaScript渲染成原生控件的React Native、Weex等。
基于WebView的框架优点很明显,它们几乎可以完全继承现代Web开发的所有成果(丰富得多的控件库、满足各种需求的页面框架、完全的动态化、自动化测试工具等等),当然也包括Web开发人员,不需要太多的学习和迁移成本就可以开发一个App。同时WebView框架也有一个致命(在对体验&性能有较高要求的情况下)的缺点,那就是WebView的渲染效率和JavaScript执行性能太差。再加上Android各个系统版本和设备厂商的定制,很难保证所在所有设备上都能提供一致的体验。
为了解决WebView性能差的问题,以React Native为代表的一类框架将最终渲染工作交还给了系统,虽然同样使用类HTML+JS的UI构建逻辑,但是最终会生成对应的自定义原生控件,以充分利用原生控件相对于WebView的较高的绘制效率。与此同时这种策略也将框架本身和App开发者绑在了系统的控件系统上,不仅框架本身需要处理大量平台相关的逻辑,随着系统版本变化和API的变化,开发者可能也需要处理不同平台的差异,甚至有些特性只能在部分平台上实现,这样框架的跨平台特性就会大打折扣。
Flutter则开辟了一种全新的思路,从头到尾重写一套跨平台的UI框架,包括UI控件、渲染逻辑甚至开发语言。渲染引擎依靠跨平台的Skia图形库来实现,依赖系统的只有图形绘制相关的接口,可以在最大程度上保证不同平台、不同设备的体验一致性,逻辑处理使用支持AOT的Dart语言,执行效率也比JavaScript高得多。
Flutter同时支持Windows、Linux和macOS操作系统作为开发环境,并且在Android Studio和VS Code两个IDE上都提供了全功能的支持。Flutter所使用的Dart语言同时支持AOT和JIT运行方式,JIT模式下还有一个备受欢迎的开发利器“热刷新”(Hot Reload),即在Android Studio中编辑Dart代码后,只需要点击保存或者“Hot Reload”按钮,就可以立即更新到正在运行的设备上,不需要重新编译App,甚至不需要重启App,立即就可以看到更新后的样式。
在Flutter中,所有功能都可以通过组合多个Widget来实现,包括对齐方式、按行排列、按列排列、网格排列甚至事件处理等等。Flutter控件主要分为两大类,StatelessWidget和StatefulWidget,StatelessWidget用来展示静态的文本或者图片,如果控件需要根据外部数据或者用户操作来改变的话,就需要使用StatefulWidget。State的概念也是来源于Facebook的流行Web框架React,React风格的框架中使用控件树和各自的状态来构建界面,当某个控件的状态发生变化时由框架负责对比前后状态差异并且采取最小代价来更新渲染结果。
Hot Reload
在Dart代码文件中修改字符串“Hello, World”,添加一个惊叹号,点击保存或者热刷新按钮就可以立即更新到界面上,仅需几百毫秒:

Flutter通过将新的代码注入到正在运行的DartVM中,来实现Hot Reload这种神奇的效果,在DartVM将程序中的类结构更新完成后,Flutter会立即重建整个控件树,从而更新界面。但是热刷新也有一些限制,并不是所有的代码改动都可以通过热刷新来更新:
- 编译错误,如果修改后的Dart代码无法通过编译,Flutter会在控制台报错,这时需要修改对应的代码。
- 控件类型从
StatelessWidget到StatefulWidget的转换,因为Flutter在执行热刷新时会保留程序原来的state,而某个控件从stageless→stateful后会导致Flutter重新创建控件时报错“myWidget is not a subtype of StatelessWidget”,而从stateful→stateless会报错“type ‘myWidget’ is not a subtype of type ‘StatefulWidget’ of ‘newWidget’”。 - 全局变量和静态成员变量,这些变量不会在热刷新时更新。
- 修改了main函数中创建的根控件节点,Flutter在热刷新后只会根据原来的根节点重新创建控件树,不会修改根节点。
- 某个类从普通类型转换成枚举类型,或者类型的泛型参数列表变化,都会使热刷新失败。
热刷新无法实现更新时,执行一次热重启(Hot Restart)就可以全量更新所有代码,同样不需要重启App,区别是restart会将所有Dart代码打包同步到设备上,并且所有状态都会重置。
Flutter插件
Flutter使用的Dart语言无法直接调用Android系统提供的Java接口,这时就需要使用插件来实现中转。Flutter官方提供了丰富的原生接口封装:
- android_alarm_manager,访问Android系统的
AlertManager。 - android_intent,构造Android的Intent对象。
- battery,获取和监听系统电量变化。
- connectivity,获取和监听系统网络连接状态。
- device info,获取设备型号等信息。
- image_picker,从设备中选取或者拍摄照片。
- package_info,获取App安装包的版本等信息。
- path_provider,获取常用文件路径。
- quick_actions,App图标添加快捷方式,iOS的eponymous concept和Android的App Shortcuts。
- sensors,访问设备的加速度和陀螺仪传感器。
- shared_preferences,App KV存储功能。
- url_launcher,启动URL,包括打电话、发短信和浏览网页等功能。
- video_player,播放视频文件或者网络流的控件。
在Flutter中,依赖包由Pub仓库管理,项目依赖配置在pubspec.yaml文件中声明即可(类似于NPM的版本声明 Pub Versioning Philosophy),对于未发布在Pub仓库的插件可以使用git仓库地址或文件路径:
dependencies:
url_launcher: ">=0.1.2 <0.2.0"
collection: "^0.1.2"
plugin1:
git:
url: "git://github.com/flutter/plugin1.git"
plugin2:
path: ../plugin2/
以shared_preferences为例,在pubspec中添加代码:
dependencies:
flutter:
sdk: flutter
shared_preferences: "^0.4.1"
脱字号“^”开头的版本表示和当前版本接口保持兼容的最新版,^1.2.3 等效于 >=1.2.3 <2.0.0 而 ^0.1.2 等效于 >=0.1.2 <0.2.0,添加依赖后点击“Packages get”按钮即可下载插件到本地,在代码中添加import语句就可以使用插件提供的接口:
import 'package:shared_preferences/shared_preferences.Dart';
class _MyAppState extends State<MyAppCounter> {
int _count = 0;
static const String COUNTER_KEY = 'counter';
_MyAppState() {
init();
}
init() async {
var pref = await SharedPreferences.getInstance();
_count = pref.getInt(COUNTER_KEY) ?? 0;
setState(() {});
}
increaseCounter() async {
SharedPreferences pref = await SharedPreferences.getInstance();
pref.setInt(COUNTER_KEY, ++_count);
setState(() {});
}
...
Dart
Dart是一种强类型、跨平台的客户端开发语言。具有专门为客户端优化、高生产力、快速高效、可移植(兼容ARM/x86)、易学的OO编程风格和原生支持响应式编程(Stream & Future)等优秀特性。Dart主要由Google负责开发和维护,在2011年10启动项目,2017年9月发布第一个2.0-dev版本。
Dart本身提供了三种运行方式:
- 使用Dart2js编译成JavaScript代码,运行在常规浏览器中(Dart Web)。
- 使用DartVM直接在命令行中运行Dart代码(DartVM)。
- AOT方式编译成机器码,例如Flutter App框架(Flutter)。
Flutter在筛选了20多种语言后,最终选择Dart作为开发语言主要有几个原因:
- 健全的类型系统,同时支持静态类型检查和运行时类型检查。
- 代码体积优化(Tree Shaking),编译时只保留运行时需要调用的代码(不允许反射这样的隐式引用),所以庞大的Widgets库不会造成发布体积过大。
- 丰富的底层库,Dart自身提供了非常多的库。
- 多生代无锁垃圾回收器,专门为UI框架中常见的大量Widgets对象创建和销毁优化。
- 跨平台,iOS和Android共用一套代码。
- JIT & AOT运行模式,支持开发时的快速迭代和正式发布后最大程度发挥硬件性能。
在Dart中,有一些重要的基本概念需要了解:
- 所有变量的值都是对象,也就是类的实例。甚至数字、函数和
null也都是对象,都继承自Object类。 - 虽然Dart是强类型语言,但是显式变量类型声明是可选的,Dart支持类型推断。如果不想使用类型推断,可以用dynamic类型。
- Dart支持泛型,
List<int>表示包含int类型的列表,List<dynamic>则表示包含任意类型的列表。 - Dart支持顶层(top-level)函数和类成员函数,也支持嵌套函数和本地函数。
- Dart支持顶层变量和类成员变量。
- Dart没有public、protected和private这些关键字,使用下划线“_”开头的变量或者函数,表示只在库内可见。参考库和可见性。
DartVM的内存分配策略非常简单,创建对象时只需要在现有堆上移动指针,内存增长始终是线形的,省去了查找可用内存段的过程:
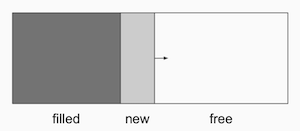
Dart中类似线程的概念叫做Isolate,每个Isolate之间是无法共享内存的,所以这种分配策略可以让Dart实现无锁的快速分配。
Dart的垃圾回收也采用了多生代算法,新生代在回收内存时采用了“半空间”算法,触发垃圾回收时Dart会将当前半空间中的“活跃”对象拷贝到备用空间,然后整体释放当前空间的所有内存:
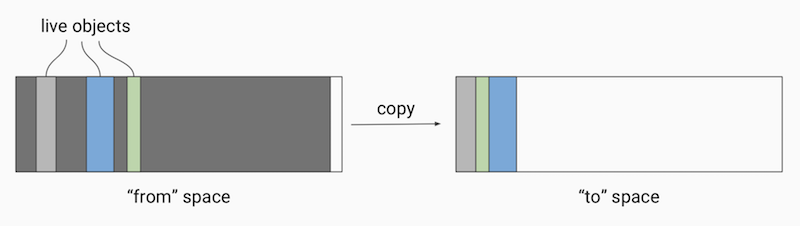
整个过程中Dart只需要操作少量的“活跃”对象,大量的没有引用的“死亡”对象则被忽略,这种算法也非常适合Flutter框架中大量Widget重建的场景。
Flutter Framework
Flutter的框架部分完全使用Dart语言实现,并且有着清晰的分层架构。分层架构使得我们可以在调用Flutter提供的便捷开发功能(预定义的一套高质量Material控件)之外,还可以直接调用甚至修改每一层实现(因为整个框架都属于“用户空间”的代码),这给我们提供了最大程度的自定义能力。Framework底层是Flutter引擎,引擎主要负责图形绘制(Skia)、文字排版(libtxt)和提供Dart运行时,引擎全部使用C++实现,Framework层使我们可以用Dart语言调用引擎的强大能力。
分层架构
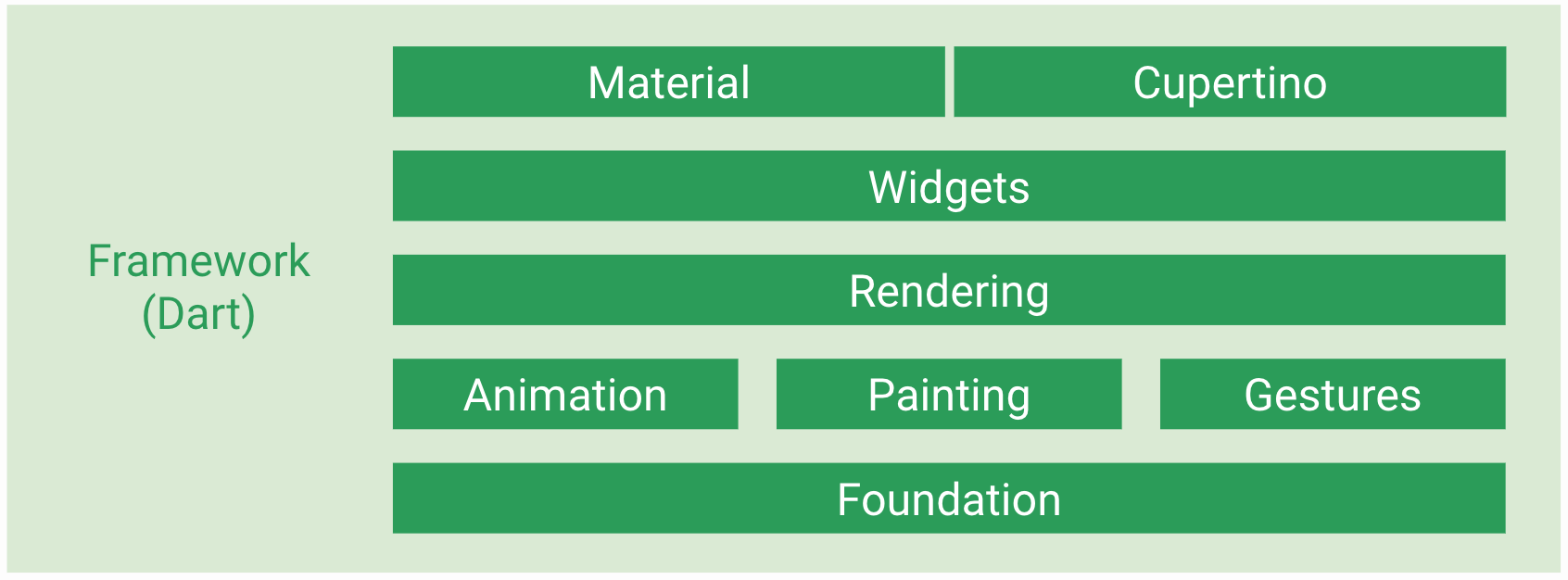
Framework的最底层叫做Foundation,其中定义的大都是非常基础的、提供给其他所有层使用的工具类和方法。绘制库(Painting)封装了Flutter Engine提供的绘制接口,主要是为了在绘制控件等固定样式的图形时提供更直观、更方便的接口,比如绘制缩放后的位图、绘制文本、插值生成阴影以及在盒子周围绘制边框等等。Animation是动画相关的类,提供了类似Android系统的ValueAnimator的功能,并且提供了丰富的内置插值器。Gesture提供了手势识别相关的功能,包括触摸事件类定义和多种内置的手势识别器。GestureBinding类是Flutter中处理手势的抽象服务类,继承自BindingBase类。Binding系列的类在Flutter中充当着类似于Android中的SystemService系列(ActivityManager、PackageManager)功能,每个Binding类都提供一个服务的单例对象,App最顶层的Binding会包含所有相关的Bingding抽象类。如果使用Flutter提供的控件进行开发,则需要使用WidgetsFlutterBinding,如果不使用Flutter提供的任何控件,而直接调用Render层,则需要使用RenderingFlutterBinding。
Flutter本身支持Android和iOS两个平台,除了性能和开发语言上的“native”化之外,它还提供了两套设计语言的控件实现Material & Cupertino,可以帮助App更好地在不同平台上提供原生的用户体验。
渲染库(Rendering)
Flutter的控件树在实际显示时会转换成对应的渲染对象(RenderObject)树来实现布局和绘制操作。一般情况下,我们只会在调试布局,或者需要使用自定义控件来实现某些特殊效果的时候,才需要考虑渲染对象树的细节。渲染库主要提供的功能类有:
abstract class RendererBinding extends BindingBase with ServicesBinding, SchedulerBinding, HitTestable { ... }
abstract class RenderObject extends AbstractNode with DiagnosticableTreeMixin implements HitTestTarget {
abstract class RenderBox extends RenderObject { ... }
class RenderParagraph extends RenderBox { ... }
class RenderImage extends RenderBox { ... }
class RenderFlex extends RenderBox with ContainerRenderObjectMixin<RenderBox, FlexParentData>,
RenderBoxContainerDefaultsMixin<RenderBox, FlexParentData>,
DebugOverflowIndicatorMixin { ... }
RendererBinding是渲染树和Flutter引擎的胶水层,负责管理帧重绘、窗口尺寸和渲染相关参数变化的监听。RenderObject渲染树中所有节点的基类,定义了布局、绘制和合成相关的接口。RenderBox和其三个常用的子类RenderParagraph、RenderImage、RenderFlex则是具体布局和绘制逻辑的实现类。
在Flutter界面渲染过程分为三个阶段:布局、绘制、合成,布局和绘制在Flutter框架中完成,合成则交由引擎负责。

控件树中的每个控件通过实现RenderObjectWidget#createRenderObject(BuildContext context) → RenderObject方法来创建对应的不同类型的RenderObject对象,组成渲染对象树。因为Flutter极大地简化了布局的逻辑,所以整个布局过程中只需要深度遍历一次:

渲染对象树中的每个对象都会在布局过程中接受父对象的Constraints参数,决定自己的大小,然后父对象就可以按照自己的逻辑决定各个子对象的位置,完成布局过程。子对象不存储自己在容器中的位置,所以在它的位置发生改变时并不需要重新布局或者绘制。子对象的位置信息存储在它自己的parentData字段中,但是该字段由它的父对象负责维护,自身并不关心该字段的内容。同时也因为这种简单的布局逻辑,Flutter可以在某些节点设置布局边界(Relayout boundary),即当边界内的任何对象发生重新布局时,不会影响边界外的对象,反之亦然:

布局完成后,渲染对象树中的每个节点都有了明确的尺寸和位置,Flutter会把所有对象绘制到不同的图层上:

因为绘制节点时也是深度遍历,可以看到第二个节点在绘制它的背景和前景不得不绘制在不同的图层上,因为第四个节点切换了图层(因为“4”节点是一个需要独占一个图层的内容,比如视频),而第六个节点也一起绘制到了红色图层。这样会导致第二个节点的前景(也就是“5”)部分需要重绘时,和它在逻辑上毫不相干但是处于同一图层的第六个节点也必须重绘。为了避免这种情况,Flutter提供了另外一个“重绘边界”的概念:

在进入和走出重绘边界时,Flutter会强制切换新的图层,这样就可以避免边界内外的互相影响。典型的应用场景就是ScrollView,当滚动内容重绘时,一般情况下其他内容是不需要重绘的。虽然重绘边界可以在任何节点手动设置,但是一般不需要我们来实现,Flutter提供的控件默认会在需要设置的地方自动设置。
控件库(Widgets)
Flutter的控件库提供了非常丰富的控件,包括最基本的文本、图片、容器、输入框和动画等等。在Flutter中“一切皆是控件”,通过组合、嵌套不同类型的控件,就可以构建出任意功能、任意复杂度的界面。它包含的最主要的几个类有:
class WidgetsFlutterBinding extends BindingBase with GestureBinding, ServicesBinding, SchedulerBinding,
PaintingBinding, RendererBinding, WidgetsBinding { ... }
abstract class Widget extends DiagnosticableTree { ... }
abstract class StatelessWidget extends Widget { ... }
abstract class StatefulWidget extends Widget { ... }
abstract class RenderObjectWidget extends Widget { ... }
abstract class Element extends DiagnosticableTree implements BuildContext { ... }
class StatelessElement extends ComponentElement { ... }
class StatefulElement extends ComponentElement { ... }
abstract class RenderObjectElement extends Element { ... }
...
基于Flutter控件系统开发的程序都需要使用WidgetsFlutterBinding,它是Flutter的控件框架和Flutter引擎的胶水层。Widget就是所有控件的基类,它本身所有的属性都是只读的。RenderObjectWidget所有的实现类则负责提供配置信息并创建具体的RenderObjectElement。Element是Flutter用来分离控件树和真正的渲染对象的中间层,控件用来描述对应的element属性,控件重建后可能会复用同一个element。RenderObjectElement持有真正负责布局、绘制和碰撞测试(hit test)的RenderObject对象。
StatelessWidget和StatefulWidget并不会直接影响RenderObject的创建,它们只负责创建对应的RenderObjectWidget,StatelessElement和StatefulElement也是类似的功能。
它们之间的关系如下图:

如果控件的属性发生了变化(因为控件的属性是只读的,所以变化也就意味着重新创建了新的控件树),但是其树上每个节点的类型没有变化时,element树和render树可以完全重用原来的对象(因为element和render object的属性都是可变的):

但是,如果控件树种某个节点的类型发生了变化,则element树和render树中的对应节点也需要重新创建:

外卖全品类页面实践
在调研了Flutter的各项特性和实现原理之后,外卖计划灰度上线Flutter版的全品类页面。对于将Flutter页面作为App的一部分这种集成模式,官方并没有提供完善的支持,所以我们首先需要了解Flutter是如何编译、打包并且运行起来的。
Flutter App构建过程
最简单的Flutter工程至少包含两个文件:

运行Flutter程序时需要对应平台的宿主工程,在Android上Flutter通过自动创建一个Gradle项目来生成宿主,在项目目录下执行flutter create .,Flutter会创建ios和android两个目录,分别构建对应平台的宿主项目,android目录内容如下:
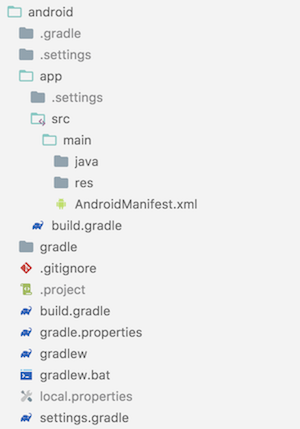
此Gradle项目中只有一个app module,构建产物即是宿主APK。Flutter在本地运行时默认采用Debug模式,在项目目录执行flutter run即可安装到设备中并自动运行,Debug模式下Flutter使用JIT方式来执行Dart代码,所有的Dart代码都会打包到APK文件中assets目录下,由libflutter.so中提供的DartVM读取并执行:
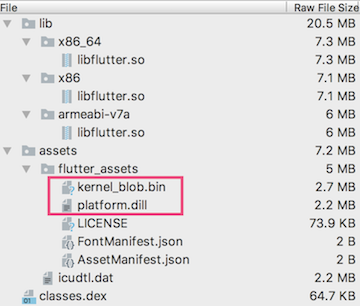
kernel_blob.bin是Flutter引擎的底层接口和Dart语言基本功能部分代码:
third_party/dart/runtime/bin/*.dart
third_party/dart/runtime/lib/*.dart
third_party/dart/sdk/lib/_http/*.dart
third_party/dart/sdk/lib/async/*.dart
third_party/dart/sdk/lib/collection/*.dart
third_party/dart/sdk/lib/convert/*.dart
third_party/dart/sdk/lib/core/*.dart
third_party/dart/sdk/lib/developer/*.dart
third_party/dart/sdk/lib/html/*.dart
third_party/dart/sdk/lib/internal/*.dart
third_party/dart/sdk/lib/io/*.dart
third_party/dart/sdk/lib/isolate/*.dart
third_party/dart/sdk/lib/math/*.dart
third_party/dart/sdk/lib/mirrors/*.dart
third_party/dart/sdk/lib/profiler/*.dart
third_party/dart/sdk/lib/typed_data/*.dart
third_party/dart/sdk/lib/vmservice/*.dart
flutter/lib/ui/*.dart
platform.dill则是实现了页面逻辑的代码,也包括Flutter Framework和其他由pub依赖的库代码:
flutter_tutorial_2/lib/main.dart
flutter/packages/flutter/lib/src/widgets/*.dart
flutter/packages/flutter/lib/src/services/*.dart
flutter/packages/flutter/lib/src/semantics/*.dart
flutter/packages/flutter/lib/src/scheduler/*.dart
flutter/packages/flutter/lib/src/rendering/*.dart
flutter/packages/flutter/lib/src/physics/*.dart
flutter/packages/flutter/lib/src/painting/*.dart
flutter/packages/flutter/lib/src/gestures/*.dart
flutter/packages/flutter/lib/src/foundation/*.dart
flutter/packages/flutter/lib/src/animation/*.dart
.pub-cache/hosted/pub.flutter-io.cn/collection-1.14.6/lib/*.dart
.pub-cache/hosted/pub.flutter-io.cn/meta-1.1.5/lib/*.dart
.pub-cache/hosted/pub.flutter-io.cn/shared_preferences-0.4.2/*.dart
kernel_blob.bin和platform.dill都是由flutter_tools中的bundle.dart中调用KernelCompiler生成。
在Release模式(flutter run --release)下,Flutter会使用Dart的AOT运行模式,编译时将Dart代码转换成ARM指令:
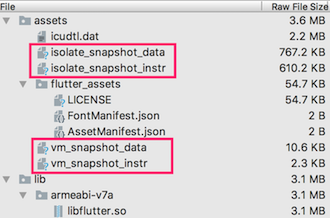
kernel_blob.bin和platform.dill都不在打包后的APK中,取代其功能的是(isolate/vm)_snapshot_(data/instr)四个文件。snapshot文件由Flutter SDK中的flutter/bin/cache/artifacts/engine/android-arm-release/darwin-x64/gen_snapshot命令生成,vm_snapshot_*是Dart虚拟机运行所需要的数据和代码指令,isolate_snapshot_*则是每个isolate运行所需要的数据和代码指令。
Flutter App运行机制
Flutter构建出的APK在运行时会将所有assets目录下的资源文件解压到App私有文件目录中的flutter目录下,主要包括处理字符编码的icudtl.dat,还有Debug模式的kernel_blob.bin、platform.dill和Release模式下的4个snapshot文件。默认情况下Flutter在Application#onCreate时调用FlutterMain#startInitialization来启动解压任务,然后在FlutterActivityDelegate#onCreate中调用FlutterMain#ensureInitializationComplete来等待解压任务结束。
Flutter在Debug模式下使用JIT执行方式,主要是为了支持广受欢迎的热刷新功能:

触发热刷新时Flutter会检测发生改变的Dart文件,将其同步到App私有缓存目录下,DartVM加载并且修改对应的类或者方法,重建控件树后立即可以在设备上看到效果。
在Release模式下Flutter会直接将snapshot文件映射到内存中执行其中的指令:

在Release模式下,FlutterActivityDelegate#onCreate中调用FlutterMain#ensureInitializationComplete方法中会将AndroidManifest中设置的snapshot(没有设置则使用上面提到的默认值)文件名等运行参数设置到对应的C++同名类对象中,构造FlutterNativeView实例时调用nativeAttach来初始化DartVM,运行编译好的Dart代码。
打包Android Library
了解Flutter项目的构建和运行机制后,我们就可以按照其需求打包成AAR然后集成到现有原生App中了。首先在andorid/app/build.gradle中修改:
| APK | AAR | |
|---|---|---|
| 修改android插件类型 | apply plugin: ‘com.android.application’ | apply plugin: ‘com.android.library’ |
| 删除applicationId字段 | applicationId “com.example.fluttertutorial” | |
| 建议添加发布所有配置功能,方便调试 | - | defaultPublishConfig ‘release’ publishNonDefault true |
简单修改后我们就可以使用Android Studio或者Gradle命令行工具将Flutter代码打包到aar中了。Flutter运行时所需要的资源都会包含在aar中,将其发布到maven服务器或者本地maven仓库后,就可以在原生App项目中引用。
但这只是集成的第一步,为了让Flutter页面无缝衔接到外卖App中,我们需要做的还有很多。
图片资源复用
Flutter默认将所有的图片资源文件打包到assets目录下,但是我们并不是用Flutter开发全新的页面,图片资源原来都会按照Android的规范放在各个drawable目录,即使是全新的页面也会有很多图片资源复用的场景,所以在assets目录下新增图片资源并不合适。
Flutter官方并没有提供直接调用drawable目录下的图片资源的途径,毕竟drawable这类文件的处理会涉及大量的Android平台相关的逻辑(屏幕密度、系统版本、语言等等),assets目录文件的读取操作也在引擎内部使用C++实现,在Dart层面实现读取drawable文件的功能比较困难。Flutter在处理assets目录中的文件时也支持添加多倍率的图片资源,并能够在使用时自动选择,但是Flutter要求每个图片必须提供1x图,然后才会识别到对应的其他倍率目录下的图片:
flutter:
assets:
- images/cat.png
- images/2x/cat.png
- images/3.5x/cat.png
new Image.asset('images/cat.png');
这样配置后,才能正确地在不同分辨率的设备上使用对应密度的图片。但是为了减小APK包体积我们的位图资源一般只提供常用的2x分辨率,其他分辨率的设备会在运行时自动缩放到对应大小。针对这种特殊的情况,我们在不增加包体积的前提下,同样提供了和原生App一样的能力:
- 在调用Flutter页面之前将指定的图片资源按照设备屏幕密度缩放,并存储在App私有目录下。
- Flutter中使用时通过自定义的
WMImage控件来加载,实际是通过转换成FileImage并自动设置scale为devicePixelRatio来加载。
这样就可以同时解决APK包大小和图片资源缺失1x图的问题。
Flutter和原生代码的通信
我们只用Flutter实现了一个页面,现有的大量逻辑都是用Java实现,在运行时会有许多场景必须使用原生应用中的逻辑和功能,例如网络请求,我们统一的网络库会在每个网络请求中添加许多通用参数,也会负责成功率等指标的监控,还有异常上报,我们需要在捕获到关键异常时将其堆栈和环境信息上报到服务器。这些功能不太可能立即使用Dart实现一套出来,所以我们需要使用Dart提供的Platform Channel功能来实现Dart→Java之间的互相调用。
以网络请求为例,我们在Dart中定义一个MethodChannel对象:
import 'dart:async';
import 'package:flutter/services.dart';
const MethodChannel _channel = const MethodChannel('com.sankuai.waimai/network');
Future<Map<String, dynamic>> post(String path, [Map<String, dynamic> form]) async {
return _channel.invokeMethod("post", {'path': path, 'body': form}).then((result) {
return new Map<String, dynamic>.from(result);
}).catchError((_) => null);
}
然后在Java端实现相同名称的MethodChannel:
public class FlutterNetworkPlugin implements MethodChannel.MethodCallHandler {
private static final String CHANNEL_NAME = "com.sankuai.waimai/network";
@Override
public void onMethodCall(MethodCall methodCall, final MethodChannel.Result result) {
switch (methodCall.method) {
case "post":
RetrofitManager.performRequest(post((String) methodCall.argument("path"), (Map) methodCall.argument("body")),
new DefaultSubscriber<Map>() {
@Override
public void onError(Throwable e) {
result.error(e.getClass().getCanonicalName(), e.getMessage(), null);
}
@Override
public void onNext(Map stringBaseResponse) {
result.success(stringBaseResponse);
}
}, tag);
break;
default:
result.notImplemented();
break;
}
}
}
在Flutter页面中注册后,调用post方法就可以调用对应的Java实现:
loadData: (callback) async {
Map<String, dynamic> data = await post("home/groups");
if (data == null) {
callback(false);
return;
}
_data = AllCategoryResponse.fromJson(data);
if (_data == null || _data.code != 0) {
callback(false);
return;
}
callback(true);
}),
SO库兼容性
Flutter官方只提供了四种CPU架构的SO库:armeabi-v7a、arm64-v8a、x86和x86-64,其中x86系列只支持Debug模式,但是外卖使用的大量SDK都只提供了armeabi架构的库。虽然我们可以通过修改引擎src根目录和third_party/dart目录下build/config/arm.gni,third_party/skia目录下的BUILD.gn等配置文件来编译出armeabi版本的Flutter引擎,但是实际上市面上绝大部分设备都已经支持armeabi-v7a,其提供的硬件加速浮点运算指令可以大大提高Flutter的运行速度,在灰度阶段我们可以主动屏蔽掉不支持armeabi-v7a的设备,直接使用armeabi-v7a版本的引擎。做到这点我们首先需要修改Flutter提供的引擎,在Flutter安装目录下的bin/cache/artifacts/engine下有Flutter下载的所有平台的引擎:

我们只需要修改android-arm、android-arm-profile和android-arm-release下的flutter.jar,将其中的lib/armeabi-v7a/libflutter.so移动到lib/armeabi/libflutter.so即可:
cd $FLUTTER_ROOT/bin/cache/artifacts/engine
for arch in android-arm android-arm-profile android-arm-release; do
pushd $arch
cp flutter.jar flutter-armeabi-v7a.jar # 备份
unzip flutter.jar lib/armeabi-v7a/libflutter.so
mv lib/armeabi-v7a lib/armeabi
zip -d flutter.jar lib/armeabi-v7a/libflutter.so
zip flutter.jar lib/armeabi/libflutter.so
popd
done
这样在打包后Flutter的SO库就会打到APK的lib/armeabi目录中。在运行时如果设备不支持armeabi-v7a可能会崩溃,所以我们需要主动识别并屏蔽掉这类设备,在Android上判断设备是否支持armeabi-v7a也很简单:
public static boolean isARMv7Compatible() {
try {
if (SDK_INT >= LOLLIPOP) {
for (String abi : Build.SUPPORTED_32_BIT_ABIS) {
if (abi.equals("armeabi-v7a")) {
return true;
}
}
} else {
if (CPU_ABI.equals("armeabi-v7a") || CPU_ABI.equals("arm64-v8a")) {
return true;
}
}
} catch (Throwable e) {
L.wtf(e);
}
return false;
}
灰度和自动降级策略
Horn是一个美团内部的跨平台配置下发SDK,使用Horn可以很方便地指定灰度开关:
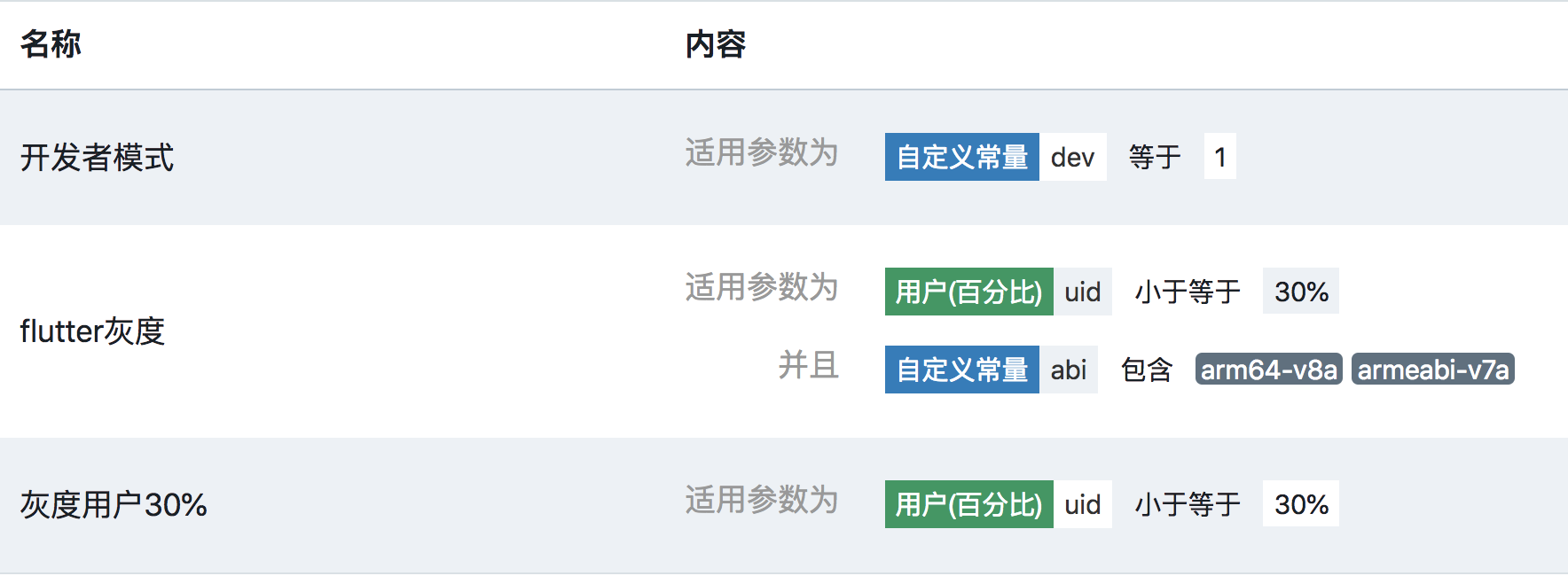
在条件配置页面定义一系列条件,然后在参数配置页面添加新的字段flutter即可:

因为在客户端做了ABI兜底策略,所以这里定义的ABI规则并没有启用。
Flutter目前仍然处于Beta阶段,灰度过程中难免发生崩溃现象,观察到崩溃后再针对机型或者设备ID来做降级虽然可以尽量降低影响,但是我们可以做到更迅速。外卖的Crash采集SDK同时也支持JNI Crash的收集,我们专门为Flutter注册了崩溃监听器,一旦采集到Flutter相关的JNI Crash就立即停止该设备的Flutter功能,启动Flutter之前会先判断FLUTTER_NATIVE_CRASH_FLAG文件是否存在,如果存在则表示该设备发生过Flutter相关的崩溃,很有可能是不兼容导致的问题,当前版本周期内在该设备上就不再使用Flutter功能。
除了崩溃以外,Flutter页面中的Dart代码也可能发生异常,例如服务器下发数据格式错误导致解析失败等等,Dart也提供了全局的异常捕获功能:
import 'package:wm_app/plugins/wm_metrics.dart';
void main() {
runZoned(() => runApp(WaimaiApp()), onError: (Object obj, StackTrace stack) {
uploadException("$obj\n$stack");
});
}
这样我们就可以实现全方位的异常监控和完善的降级策略,最大程度减少灰度时可能对用户带来的影响。
分析崩溃堆栈和异常数据
Flutter的引擎部分全部使用C/C++实现,为了减少包大小,所有的SO库在发布时都会去除符号表信息。和其他的JNI崩溃堆栈一样,我们上报的堆栈信息中只能看到内存地址偏移量等信息:
*** *** *** *** *** *** *** *** *** *** *** *** *** *** *** ***
Build fingerprint: 'Rock/odin/odin:7.1.1/NMF26F/1527007828:user/dev-keys'
Revision: '0'
Author: collect by 'libunwind'
ABI: 'arm64-v8a'
pid: 28937, tid: 29314, name: 1.ui >>> com.sankuai.meituan.takeoutnew <<<
signal 11 (SIGSEGV), code 1 (SEGV_MAPERR), fault addr 0x0
backtrace:
r0 00000000 r1 ffffffff r2 c0e7cb2c r3 c15affcc
r4 c15aff88 r5 c0e7cb2c r6 c15aff90 r7 bf567800
r8 c0e7cc58 r9 00000000 sl c15aff0c fp 00000001
ip 80000000 sp c0e7cb28 lr c11a03f9 pc c1254088 cpsr 200c0030
#00 pc 002d7088 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so
#01 pc 002d5a23 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so
#02 pc 002d95b5 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so
#03 pc 002d9f33 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so
#04 pc 00068e6d /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so
#05 pc 00067da5 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so
#06 pc 00067d5f /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so
#07 pc 003b1877 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so
#08 pc 003b1db5 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so
#09 pc 0000241c /data/data/com.sankuai.meituan.takeoutnew/app_flutter/vm_snapshot_instr
单纯这些信息很难定位问题,所以我们需要使用NDK提供的ndk-stack来解析出具体的代码位置:
ndk-stack -sym PATH [-dump PATH]
Symbolizes the stack trace from an Android native crash.
-sym PATH sets the root directory for symbols
-dump PATH sets the file containing the crash dump (default stdin)
如果使用了定制过的引擎,必须使用engine/src/out/android-release下编译出的libflutter.so文件。一般情况下我们使用的是官方版本的引擎,可以在flutter_infra页面直接下载带有符号表的SO文件,根据打包时使用的Flutter工具版本下载对应的文件即可。比如0.4.4 beta版本:
$ flutter --version # version命令可以看到Engine对应的版本 06afdfe54e
Flutter 0.4.4 • channel beta • https://github.com/flutter/flutter.git
Framework • revision f9bb4289e9 (5 weeks ago) • 2018-05-11 21:44:54 -0700
Engine • revision 06afdfe54e
Tools • Dart 2.0.0-dev.54.0.flutter-46ab040e58
$ cat flutter/bin/internal/engine.version # flutter安装目录下的engine.version文件也可以看到完整的版本信息 06afdfe54ebef9168a90ca00a6721c2d36e6aafa
06afdfe54ebef9168a90ca00a6721c2d36e6aafa
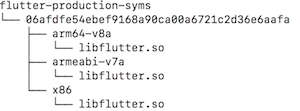
拿到引擎版本号后在 https://console.cloud.google.com/storage/browser/flutter_infra/flutter/06afdfe54ebef9168a90ca00a6721c2d36e6aafa/ 看到该版本对应的所有构建产物,下载android-arm-release、android-arm64-release和android-x86目录下的symbols.zip,并存放到对应目录:
执行ndk-stack即可看到实际发生崩溃的代码和具体行数信息:
ndk-stack -sym flutter-production-syms/06afdfe54ebef9168a90ca00a6721c2d36e6aafa/armeabi-v7a -dump flutter_jni_crash.txt
********** Crash dump: **********
Build fingerprint: 'Rock/odin/odin:7.1.1/NMF26F/1527007828:user/dev-keys'
pid: 28937, tid: 29314, name: 1.ui >>> com.sankuai.meituan.takeoutnew <<<
signal 11 (SIGSEGV), code 1 (SEGV_MAPERR), fault addr 0x0
Stack frame #00 pc 002d7088 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so: Routine minikin::WordBreaker::setText(unsigned short const*, unsigned int) at /b/build/slave/Linux_Engine/build/src/out/android_release/../../flutter/third_party/txt/src/minikin/WordBreaker.cpp:55
Stack frame #01 pc 002d5a23 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so: Routine minikin::LineBreaker::setText() at /b/build/slave/Linux_Engine/build/src/out/android_release/../../flutter/third_party/txt/src/minikin/LineBreaker.cpp:74
Stack frame #02 pc 002d95b5 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so: Routine txt::Paragraph::ComputeLineBreaks() at /b/build/slave/Linux_Engine/build/src/out/android_release/../../flutter/third_party/txt/src/txt/paragraph.cc:273
Stack frame #03 pc 002d9f33 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so: Routine txt::Paragraph::Layout(double, bool) at /b/build/slave/Linux_Engine/build/src/out/android_release/../../flutter/third_party/txt/src/txt/paragraph.cc:428
Stack frame #04 pc 00068e6d /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so: Routine blink::ParagraphImplTxt::layout(double) at /b/build/slave/Linux_Engine/build/src/out/android_release/../../flutter/lib/ui/text/paragraph_impl_txt.cc:54
Stack frame #05 pc 00067da5 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so: Routine tonic::DartDispatcher<tonic::IndicesHolder<0u>, void (blink::Paragraph::*)(double)>::Dispatch(void (blink::Paragraph::*)(double)) at /b/build/slave/Linux_Engine/build/src/out/android_release/../../topaz/lib/tonic/dart_args.h:150
Stack frame #06 pc 00067d5f /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so: Routine void tonic::DartCall<void (blink::Paragraph::*)(double)>(void (blink::Paragraph::*)(double), _Dart_NativeArguments*) at /b/build/slave/Linux_Engine/build/src/out/android_release/../../topaz/lib/tonic/dart_args.h:198
Stack frame #07 pc 003b1877 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so: Routine dart::NativeEntry::AutoScopeNativeCallWrapperNoStackCheck(_Dart_NativeArguments*, void (*)(_Dart_NativeArguments*)) at /b/build/slave/Linux_Engine/build/src/out/android_release/../../third_party/dart/runtime/vm/native_entry.cc:198
Stack frame #08 pc 003b1db5 /data/app/com.sankuai.meituan.takeoutnew-1/lib/arm/libflutter.so: Routine dart::NativeEntry::LinkNativeCall(_Dart_NativeArguments*) at /b/build/slave/Linux_Engine/build/src/out/android_release/../../third_party/dart/runtime/vm/native_entry.cc:348
Stack frame #09 pc 0000241c /data/data/com.sankuai.meituan.takeoutnew/app_flutter/vm_snapshot_instr
Dart异常则比较简单,默认情况下Dart代码在编译成机器码时并没有去除符号表信息,所以Dart的异常堆栈本身就可以标识真实发生异常的代码文件和行数信息:
FlutterException: type '_InternalLinkedHashMap<dynamic, dynamic>' is not a subtype of type 'num' in type cast
#0 _$CategoryGroupFromJson (package:wm_app/lib/all_category/model/category_model.g.dart:29)
#1 new CategoryGroup.fromJson (package:wm_app/all_category/model/category_model.dart:51)
#2 _$CategoryListDataFromJson.<anonymous closure> (package:wm_app/lib/all_category/model/category_model.g.dart:5)
#3 MappedListIterable.elementAt (dart:_internal/iterable.dart:414)
#4 ListIterable.toList (dart:_internal/iterable.dart:219)
#5 _$CategoryListDataFromJson (package:wm_app/lib/all_category/model/category_model.g.dart:6)
#6 new CategoryListData.fromJson (package:wm_app/all_category/model/category_model.dart:19)
#7 _$AllCategoryResponseFromJson (package:wm_app/lib/all_category/model/category_model.g.dart:19)
#8 new AllCategoryResponse.fromJson (package:wm_app/all_category/model/category_model.dart:29)
#9 AllCategoryPage.build.<anonymous closure> (package:wm_app/all_category/category_page.dart:46)
<asynchronous suspension>
#10 _WaimaiLoadingState.build (package:wm_app/all_category/widgets/progressive_loading_page.dart:51)
#11 StatefulElement.build (package:flutter/src/widgets/framework.dart:3730)
#12 ComponentElement.performRebuild (package:flutter/src/widgets/framework.dart:3642)
#13 Element.rebuild (package:flutter/src/widgets/framework.dart:3495)
#14 BuildOwner.buildScope (package:flutter/src/widgets/framework.dart:2242)
#15 _WidgetsFlutterBinding&BindingBase&GestureBinding&ServicesBinding&SchedulerBinding&PaintingBinding&RendererBinding&WidgetsBinding.drawFrame (package:flutter/src/widgets/binding.dart:626)
#16 _WidgetsFlutterBinding&BindingBase&GestureBinding&ServicesBinding&SchedulerBinding&PaintingBinding&RendererBinding._handlePersistentFrameCallback (package:flutter/src/rendering/binding.dart:208)
#17 _WidgetsFlutterBinding&BindingBase&GestureBinding&ServicesBinding&SchedulerBinding._invokeFrameCallback (package:flutter/src/scheduler/binding.dart:990)
#18 _WidgetsFlutterBinding&BindingBase&GestureBinding&ServicesBinding&SchedulerBinding.handleDrawFrame (package:flutter/src/scheduler/binding.dart:930)
#19 _WidgetsFlutterBinding&BindingBase&GestureBinding&ServicesBinding&SchedulerBinding._handleDrawFrame (package:flutter/src/scheduler/binding.dart:842)
#20 _rootRun (dart:async/zone.dart:1126)
#21 _CustomZone.run (dart:async/zone.dart:1023)
#22 _CustomZone.runGuarded (dart:async/zone.dart:925)
#23 _invoke (dart:ui/hooks.dart:122)
#24 _drawFrame (dart:ui/hooks.dart:109)
Flutter和原生性能对比
虽然使用原生实现(左)和Flutter实现(右)的全品类页面在实际使用过程中几乎分辨不出来:
但是我们还需要在性能方面有一个比较明确的数据对比。
我们最关心的两个页面性能指标就是页面加载时间和页面渲染速度。测试页面加载速度可以直接使用美团内部的Metrics性能测试工具,我们将页面Activity对象创建作为页面加载的开始时间,页面API数据返回作为页面加载结束时间。从两个实现的页面分别启动400多次的数据中可以看到,原生实现(AllCategoryActivity)的加载时间中位数为210ms,Flutter实现(FlutterCategoryActivity)的加载时间中位数为231ms。考虑到目前我们还没有针对FlutterView做缓存和重用,FlutterView每次创建都需要初始化整个Flutter环境并加载相关代码,多出的20ms还在预期范围内:
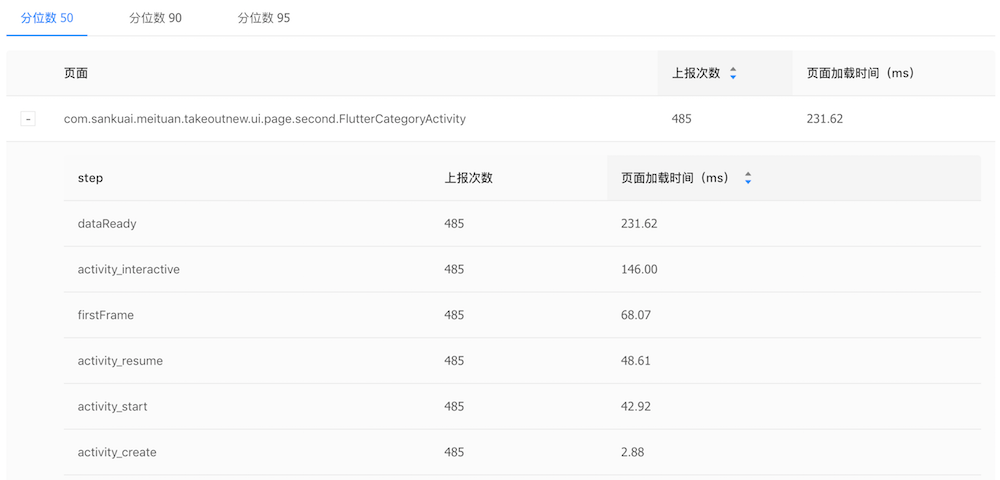
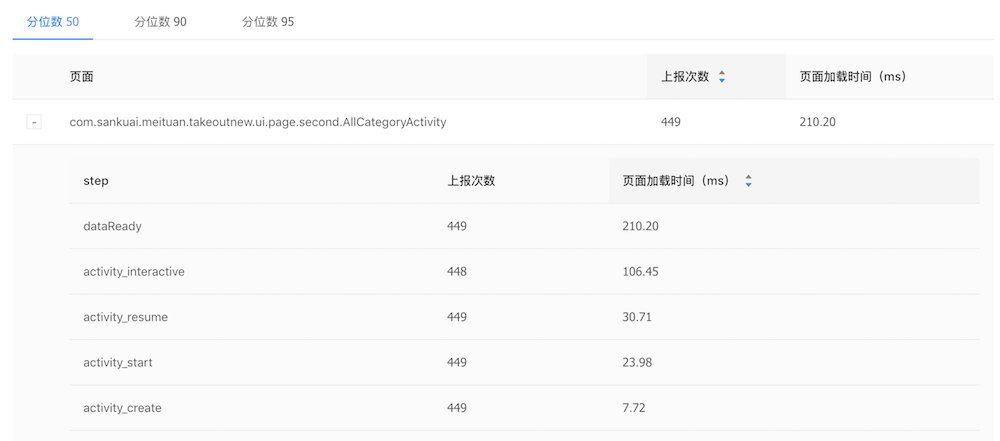
因为Flutter的UI逻辑和绘制代码都不在主线程执行,Metrics原有的FPS功能无法统计到Flutter页面的真实情况,我们需要用特殊方法来对比两种实现的渲染效率。Android原生实现的界面渲染耗时使用系统提供的FrameMetrics接口进行监控:
public class AllCategoryActivity extends WmBaseActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.N) {
getWindow().addOnFrameMetricsAvailableListener(new Window.OnFrameMetricsAvailableListener() {
List<Integer> frameDurations = new ArrayList<>(100);
@Override
public void onFrameMetricsAvailable(Window window, FrameMetrics frameMetrics, int dropCountSinceLastInvocation) {
frameDurations.add((int) (frameMetrics.getMetric(TOTAL_DURATION) / 1000000));
if (frameDurations.size() == 100) {
getWindow().removeOnFrameMetricsAvailableListener(this);
L.w("AllCategory", Arrays.toString(frameDurations.toArray()));
}
}
}, new Handler(Looper.getMainLooper()));
}
super.onCreate(savedInstanceState);
// ...
}
}
Flutter在Framework层只能取到每帧中UI操作的CPU耗时,GPU操作都在Flutter引擎内部实现,所以需要修改引擎来监控完整的渲染耗时,在Flutter引擎目录下的src/flutter/shell/common/rasterizer.cc文件中添加:
void Rasterizer::DoDraw(std::unique_ptr<flow::LayerTree> layer_tree) {
if (!layer_tree || !surface_) {
return;
}
if (DrawToSurface(*layer_tree)) {
last_layer_tree_ = std::move(layer_tree);
#if defined(OS_ANDROID)
if (compositor_context_->frame_count().count() == 101) {
std::ostringstream os;
os << "[";
const std::vector<TimeDelta> &engine_laps = compositor_context_->engine_time().Laps();
const std::vector<TimeDelta> &frame_laps = compositor_context_->frame_time().Laps();
size_t i = 1;
for (auto engine_iter = engine_laps.begin() + 1, frame_iter = frame_laps.begin() + 1;
i < 101 && engine_iter != engine_laps.end(); i++, engine_iter++, frame_iter++) {
os << (*engine_iter + *frame_iter).ToMilliseconds() << ",";
}
os << "]";
__android_log_write(ANDROID_LOG_WARN, "AllCategory", os.str().c_str());
}
#endif
}
}
即可得到每帧绘制时真正消耗的时间。测试时我们将两种实现的页面分别打开100次,每次打开后执行两次滚动操作,使其绘制100帧,将这100帧的每帧耗时记录下来:
for (( i = 0; i < 100; i++ )); do
openWMPage allcategory
sleep 1
adb shell input swipe 500 1000 500 300 900
adb shell input swipe 500 1000 500 300 900
adb shell input keyevent 4
done
将测试结果的100次启动中每帧耗时取平均値,得到每帧平均耗时情况(横坐标轴为帧序列,纵坐标轴为每帧耗时,单位为毫秒):
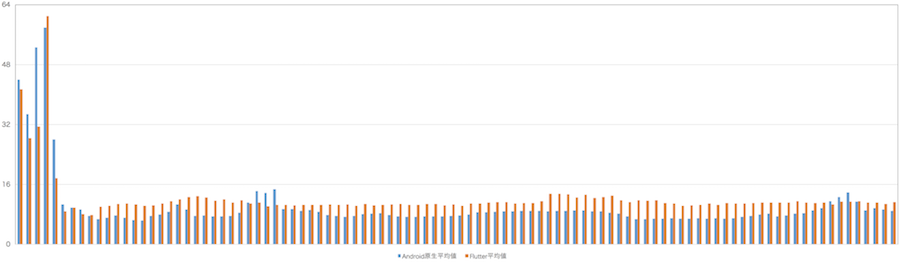
Android原生实现和Flutter版本都会在页面打开的前5帧超过16ms,刚打开页面时原生实现需要创建大量View,Flutter也需要创建大量Widget,后续帧中可以重用大部分控件和渲染节点(原生的RenderNode和Flutter的RenderObject),所以启动时的布局和渲染操作都是最耗时的。
10000帧(100次×100帧每次)中Android原生总平均値为10.21ms,Flutter总平均値为12.28ms,Android原生实现总丢帧数851帧8.51%,Flutter总丢帧987帧9.87%。在原生实现的触摸事件处理和过度绘制充分优化的前提下,Flutter完全可以媲美原生的性能。
总结
Flutter目前仍处于早期阶段,也还没有发布正式的Release版本,不过我们看到Flutter团队一直在为这一目标而努力。虽然Flutter的开发生态不如Android和iOS原生应用那么成熟,许多常用的复杂控件还需要自己实现,有的甚至会比较困难(比如官方尚未提供的ListView.scrollTo(index)功能),但是在高性能和跨平台方面Flutter在众多UI框架中还是有很大优势的。
开发Flutter应用只能使用Dart语言,Dart本身既有静态语言的特性,也支持动态语言的部分特性,对于Java和JavaScript开发者来说门槛都不高,3-5天可以快速上手,大约1-2周可以熟练掌握。在开发全品类页面的Flutter版本时我们也深刻体会到了Dart语言的魅力,Dart的语言特性使得Flutter的界面构建过程也比Android原生的XML+JAVA更直观,代码量也从原来的900多行减少到500多行(排除掉引用的公共组件)。Flutter页面集成到App后APK体积至少会增加5.5MB,其中包括3.3MB的SO库文件和2.2MB的ICU数据文件,此外业务代码1300行编译产物的大小有2MB左右。
Flutter本身的特性适合追求iOS和Android跨平台的一致体验,追求高性能的UI交互效果的场景,不适合追求动态化部署的场景。Flutter在Android上已经可以实现动态化部署,但是由于Apple的限制,在iOS上实现动态化部署非常困难,Flutter团队也正在和Apple积极沟通。
Picasso 开启大前端的未来
Picasso是大众点评移动研发团队自研的高性能跨平台动态化框架,经过两年多的孕育和发展,目前在美团多个事业群已经实现了大规模的应用。
Picasso源自我们对大前端实践的重新思考,以简洁高效的架构达成高性能的页面渲染目标。在实践中,甚至可以把Native技术向Picasso技术的迁移当做一种性能优化手段;与此同时,Picasso在跨越小程序端和Web端方面的工作已经取得了突破性进展,有望在四端(Android、iOS、H5、微信小程序)统一大前端实践的基础之上,达成高性能大前端实践,同时配合Picasso布局DSL强表达能力和Picasso代码生成技术,可以进一步提升生产力。
客户端动态化
2007年,苹果公司第一代iPhone发布,它的出现“重新定义了手机”,并开启了移动互联网蓬勃发展的序幕。Android、iOS等移动技术,打破了Web应用开发技术即将一统江湖的局面,之后海量的应用如雨后春笋般涌现出来。移动开发技术给用户提供了更好的移动端使用和交互体验,但其“静态”的开发模式却给需要快速迭代的互联网团队带来了沉重的负担。
客户端“静态”开发模式
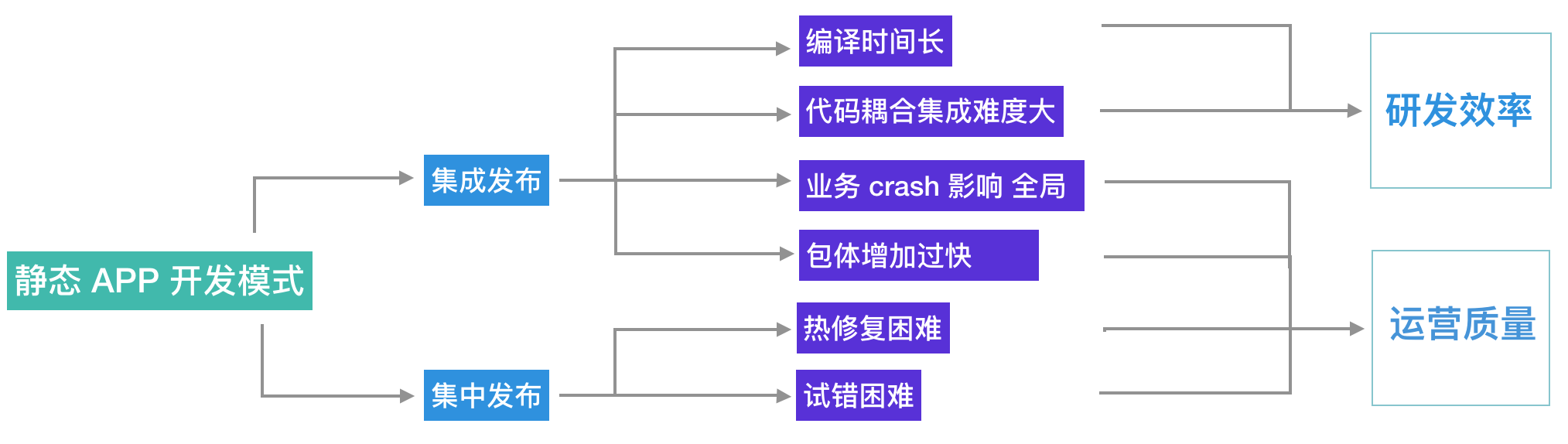
客户端开发技术与Web端开发技术相比,天生带有“静态”的特性,我们可以从空间和时间两个维度来看。
从空间上看需要集成发布,美团App承载业务众多,是跨业务合流,横向涉及开发人员最多的公司,虽然开发人员付出了巨大的心血完成了业务间的组件化解耦拆分,但依然无可避免的造成了以下问题:
- 编译时间过长。 随着代码复杂度的增加,集成编译的时间越来越长。研发力量被等待编译大量消耗,集成检查也变成了一个巨大的挑战。
- App包体增长过快。 这与迅猛发展的互联网势头相符,但与新用户拓展和业务迭代进化形成了尖锐矛盾。
- 运行时耦合严重。 在集成发布的包体内,任何一个功能组件产生的Crash、内存泄漏等异常行为都会导致整个App可用性下降,带来较大的损失。
- 集成难度大。 业务线间代码复用耦合,业务层、框架层、基础服务层错综复杂,需要拆分出相当多的兼容层代码,影响整体开发效率。
从时间上看需要集中发布,线上Bug修复须发版或热修复,成本高昂。新功能的添加也必须等待统一的发版周期,这对快速成长的业务来说是不可接受的。App开发还面临严重的长尾问题,无法为使用老版本的用户提供最新的功能,严重损害了用户和业务方的利益。
这种“静态”的开发模式,会对研发效率和运营质量产生负面影响。对于传统的桌面应用软件开发而言,静态的研发模式也许是相对可以接受的。但对于业务蓬勃发展的移动互联网行业来说,静态开发模式和敏捷迭代发布需求的矛盾日益突出。
客户端动态化的趋势
如何解决客户端“静态”开发模式带来的问题?
业界最早给出的答案是使用Web技术
但Web技术与Native平台相比存在性能和交互体验上的差距。在一些性能和交互体验可以妥协的场景,Web技术可以在定制容器、离线化等技术的支持下,承载运营性质的需要快速迭代试错的页面。
另一个业界给出的思路是优化Web实现
利用移动客户端技术的灵活性与高性能,再造一个“标准Web浏览器”,使得“Web技术”同时具有高性能、良好的交互体验以及Web技术的动态性。这次技术浪潮中Facebook再次成为先驱,推出了React Native技术(简称RN)。不过RN的设计取向有些奇怪,RN不兼容标准Web,甚至不为Android、iOS双端行为对齐做努力。产生的后果就是所有“吃螃蟹”的公司都需要做二次开发才能基本对齐双端的诉求。同时还需要尽最大努力为RN的兼容性问题、稳定性问题甚至是性能问题买单。
而我们给出的答案是Picasso
Picasso另辟蹊径,在实现高性能动态化能力的同时,还以较强的适应能力,以动态页面、动态模块甚至是动态视图的形式融入到业务开发代码体系中,赢得了许多移动研发团队的认同。
Picasso框架跨Web端和小程序端的实践也已经取得了突破性进展,除了达成四端统一的大前端融合目标,Picasso的布局理念有望支持四端的高性能渲染,同时配合Picasso代码生成技术以及Picasso的强表达能力,生产力在大前端统一的基础之上得到了进一步的提升。
Picasso动态化原理
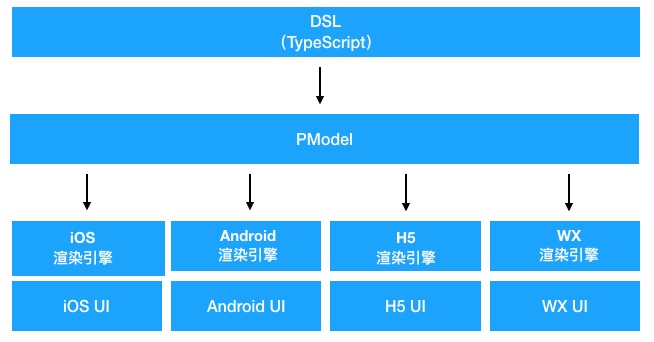
Picasso应用程序开发者使用基于通用编程语言的布局DSL代码编写布局逻辑。布局逻辑根据给定的屏幕宽高和业务数据,计算出精准适配屏幕和业务数据的布局信息、视图结构信息和文本、图片URL等必要的业务渲染信息,我们称这些视图渲染信息为PModel。PModel作为Picasso布局渲染的中间结果,和最终渲染出的视图结构一一对应;Picasso渲染引擎根据PModel的信息,递归构建出Native视图树,并完成业务渲染信息的填充,从而完成Picasso渲染过程。需要指出的是,渲染引擎不做适配计算,使用布局DSL表达布局需求的同时完成布局计算,既所谓“表达即计算”。
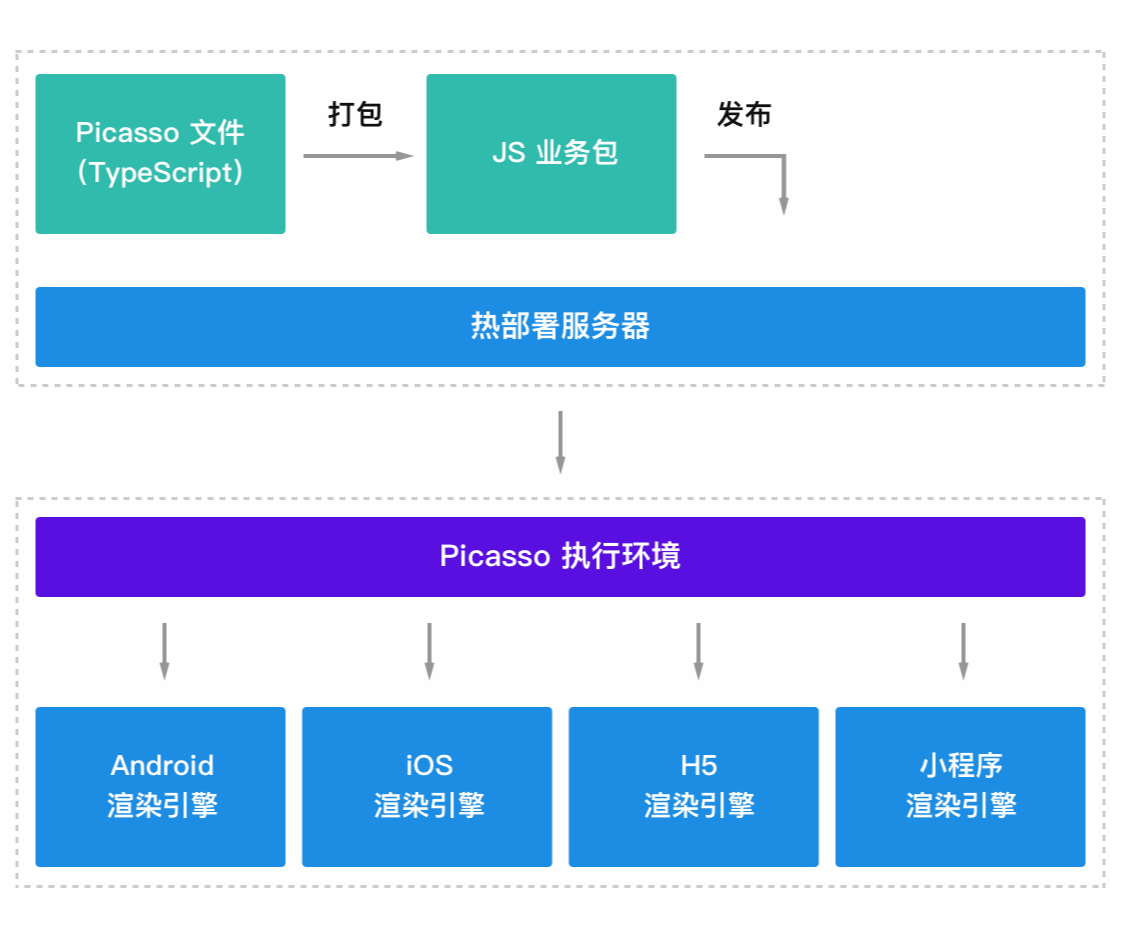
从更大的图景上看,Picasso开发人员用TypeScript在VSCode中编写Picasso应用程序;提交代码后可以通过Picasso持续集成系统自动化的完成Lint检查和打包,在Picasso分发系统进行灰度发布,Picasso应用程序最终以JavaScript包的形式下发到客户端,由Picasso SDK解释执行,达成客户端业务逻辑动态化的目的。
在应用程序开发过程中,TypeScript的静态类型系统,搭配VSCode以及Picasso Debug插件,可以获得媲美传统移动客户端开发IDE的智能感知和断点调试的开发体验。Picasso CI系统配合TypeScript的类型系统,可以避免低级错误,助力多端和多团队的配合;同时可以通过“兼容计算”有效的解决能力支持的长尾问题。
Picasso布局DSL
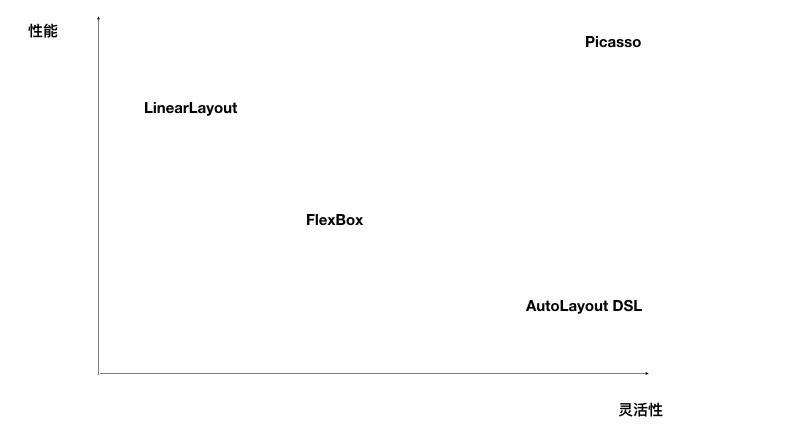
Picasso针对移动端主流的布局引擎和系统做了系统的对比分析,这些系统包括:
- Android开发常用的LinearLayout。
- 前端及Picasso同类动态化框架使用的FlexBox。
- 苹果公司主推的AutoLayout。
其中苹果官方推出的AutoLayout缺乏一个好用的DSL,所以我们直接将移动开发者社区贡献的AutoLayout DSL方案列入对比。
首先从性能上看,AutoLayout系统是表现最差的,随着需求复杂度的增加“布局计算”耗时成指数级的增长。FlexBox和LinearLayout相比较AutoLayout而言会在性能表现上有较大优势。但是LinearLayout和FlexBox会让开发者为了布局方面需要的概念增加不必要的视图层级,进而带来渲染性能问题。
从灵活性上看,LinearLayout和FlexBox布局有很强的概念约束。一个强调线性排布,一个强调盒子模式、伸缩等概念,这些模型在布局需求和模型概念不匹配时,就不得不借助编程语言进行干预。并且由于布局系统的隔离,这样的干预并不容易做,一定程度上影响了布局的灵活性和表达能力。而配合基于通用编程语言设计的DSL加上AutoLayout的布局逻辑,可以获得理论上最强的灵活性。但是这三个布局系统都在试图解决“用声明式的方式表达布局逻辑的问题”,基于编程语言的DSL的引入让布局计算引擎变得多余。
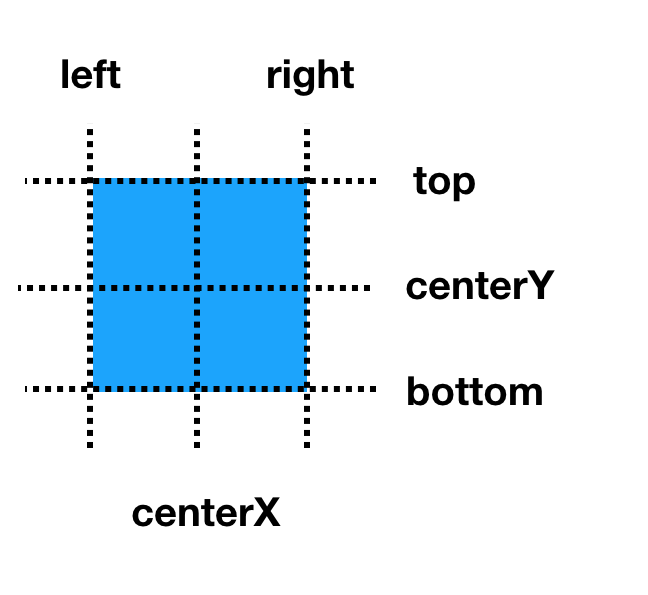
Picasso布局DSL的核心在于:
- 基于通用编程语言设计。
- 支持锚点概念(如上图)。
使用锚点概念可以简单清晰的设置非同一个坐标轴方向的两个锚点“锚定”好的视图位置。同时锚点可以提供描述“相对”位置关系语义支持。事实上,针对布局的需求更符合人类思维的描述是类似于“B位于A的右边,间距10,顶对齐”,而不应该是“A和B在一个水平布局容器中……”。锚点概念通过极简的实现消除了需求描述和视图系统底层实现之间的语义差距。
下面举几个典型的例子说明锚点的用法:
1 居中对齐:
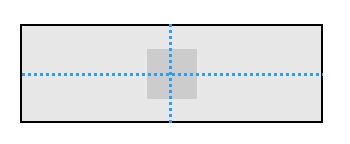
view.centerX = bgView.width / 2
view.centerY = bgView.height /2
2 右对齐:

view.right = bgView.width - 10
view.centerY = bgView.height / 2
3 相对排列:
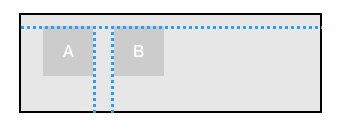
viewB.top = viewA.top
viewB.left = viewA.right + 10
4 “花式”布局:
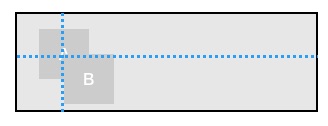
viewB.top = viewA.centerY
viewB.left = viewA.centerX
Picasso锚点布局逻辑具有理论上最为灵活的的表达能力,可以做到“所想即所得”的表达布局需求。但是有些时候我们会发现在特定的场景下这样的表达能力是“过剩的”。类似于下图的布局需求,需要水平排布4个视图元素、间距10、顶对齐;可能会有如下的锚点布局逻辑代码:
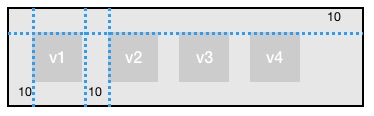
v1.top = 10
v1.left = 10
v2.top = v1.top
v3.top = v2.top
v4.top = v3.top
v2.left = v1.right + 10
v3.left = v2.right + 10
v4.left = v3.right + 10
显然这样的代码不是特别理想,其中有较多可抽象的重复的逻辑,针对这样的需求场景,Picasso提供了hlayout布局函数,完美的解决了水平排布的问题:
hlayout([v1, v2, v3, v4],
{ top: 10, left: 10, divideSpace: 10 })
有心人可以发现,这和Android平台经典的LinearLayout如出一辙。对应hlayout函数的还有vlayout,这一对几乎完整实现Android LinearLayout语义的兄弟函数,实现逻辑不足300行,这里强调的重点其实不在于两个layout函数,而是Picasso布局DSL无限制的抽象表达能力。如果业务场景中需要类似于Flexbox或其他的概念模型,业务应用方都可以按需快速的做出实现。
在性能方面,Picasso锚点布局系统避免了“声明式到命令式”的计算过程,完全无需布局计算引擎的介入,达成了“需求表达即计算”的效果,具有理论上最佳性能表现。
由此可见,Picasso布局DSL,无论在性能潜力和表达能力方面都优于以上布局系统。Picasso布局DSL的设计是Picasso得以构建高性能四端动态化框架的基石。
同时得益于Picasso布局DSL的表达能力和扩展能力,Picasso在自动化生成布局代码方面也具有得天独厚的优势,生成的代码更具有可维护性和扩展性。伴随着Picasso的普及,当前前端研发过程中“视觉还原”的过程会成为历史,前端开发者的经历也会从“复制”视觉稿的重复劳动中解脱出来。

Picasso高性能渲染
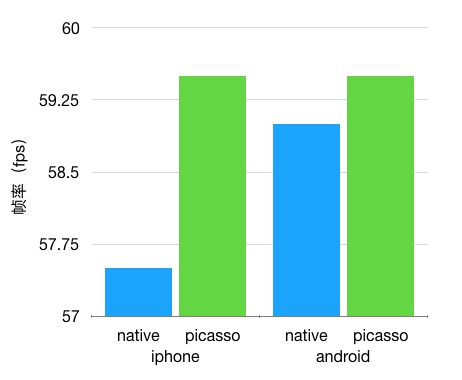
业界对于动态化方案的期待一直是“接近原生性能”,但是Picasso却做到了等同于原生的渲染效率,在复杂业务场景可以达成超越原生技术基本实践的效果。就目前Picasso在美团移动团队实践来看,同一个页面使用Picasso技术实现会获得更好的性能表现。
Picasso实现高性能的基础是宿主端高效的原生渲染,但实现“青出于蓝而胜于蓝”的效果却有些反直觉,在这背后是有理论上的必然性的:
-
Picasso的锚点布局让 布局表达和布局计算同时发生。避免了冗余反复的布局计算过程。
-
Picasso的布局理念使 视图层级扁平。所有的视图都各自独立,没有为了布局逻辑表达所产生的冗余层级。
-
Picasso设计支持了 预计算的过程。原本需要在主线程进行计算的部分过程可以在后台线程进行。
在常规的原生业务编码中,很难将这些优化做到最好,因为对比每个小点所带来的性能提升而言,应用逻辑复杂度的提升是不能接受的。而Picasso渲染引擎,将传统原生业务逻辑开发所能做的性能优化做到了“统一复用”,实现了一次优化,全线受益的目标。
Picasso在美团内部的应用
Picasso跨平台高性能动态化框架在集团内部发布后,得到了广泛关注,集团内部对于客户端动态化的方向也十分认可,积极的在急需敏捷发布能力的业务场景展开Picasso应用实践;经过大概两年多的内部迭代使用,Picasso的可靠性、性能、业务适应能力受到的集团内部的肯定,Picasso动态化技术得到了广泛的应用。
通过Picasso的桥接能力,基于Picasso的上层应用程序仍然可以利用集团内部移动技术团队积累的高质量基础建设,同时已经形成初步的公司内部大生态,多个部门已经向Picasso生态贡献了动画能力、动态模块能力、复用Web容器桥接基建能力、大量业务组件和通用组件。
Picasso团队除了持续维护Picasso SDK,Picasso持续集成系统、包括基于VSCode的断点调试,Liveload等核心开发工具链,还为集团提供了统一的分发系统,为集团内部大前端团队开展Picasso动态化实践奠定了坚实的基础。
到发稿时,集团内部Picasso应用领先的BG已经实现Picasso动态化技术覆盖80%以上的业务开发,相信经过更长时间的孵化,Picasso会成为美团移动开发技术的“神兵利器”,助力公司技术团队实现高速发展。
列举Picasso在美团的部分应用案例:
Picasso开启大前端未来
Picasso在实践客户端动态化的方向取得了成功,解决了传统客户端“静态”研发模式导致的种种痛点。总结下来:
- 如果想要 敏捷发布,使用Picasso。
- 如果想要 高交付质量,使用Picasso。
- 如果想要 优秀用户体验,使用Picasso。
- 如果想要 高性能表现,使用Picasso。
- 如果想要 自动化生成布局代码,使用Picasso。
- 如果想要 高效生产力,使用Picasso。
至此Picasso并没有停止持续创新的脚步,目前Picasso在Web端和微信小程序端的适配工作已经有了突破性进展,正如Picasso在移动端取得的成就一样,Picasso会在完成四端统一(Android、iOS、Web、小程序)的同时,构建出更快、更强的大前端实践。
业界对大前端融合的未来有很多想象和憧憬,Picasso动态化实践已经开启大前端未来的一种新的可能。
美团客户端响应式框架 EasyReact 开源啦

前言
EasyReact 是一款基于响应式编程范式的客户端开发框架,开发者可以使用此框架轻松地解决客户端的异步问题。
目前 EasyReact 已在美团和大众点评客户端的部分业务中实践,并且持续迭代了一年多的时间。近日,我们决定开源这个项目的 iOS Objective-C 语言部分,希望能够帮助更多的开发者不断探索更广泛的业务场景,也欢迎更多的社区的开发者跟我们一起加强 EasyReact 的功能。Github 的项目地址,参见 https://github.com/meituan-dianping/EasyReact。
背景
美团 iOS 客户端团队在业界比较早地使用响应式来解决项目问题,为此我们引入了 ReactiveCocoa 这个函数响应式框架(相关实践,参考之前的 系列博客)。随着业务的急速扩张和团队拆分变更,ReactiveCocoa 在解决异步问题的同时也带来了新的挑战,总结起来有以下几点:
- 高学习门槛
- 易出错
- 调试困难
- 风格不统一
既然响应式编程带来了这么多的麻烦,是否我们应该摒弃响应式编程,用更通俗易懂的面向对象编程来解决问题呢?这要从移动端开发的特点说起。
移动端开发特点
客户端程序本身充满异步的场景。客户端的主要逻辑就是从视图中处理控件事件,通过网络获取后端内容再展示到视图上。这其中事件的处理和网络的处理都是异步行为。
一般客户端程序发起网络请求后程序会异步的继续执行,等待网络资源的获取。通常我们还会需要设置一定的标志位和显示一些加载指示器来让视图进行等待。但是当网络进行获取的时候,通知、UI 事件、定时器都对状态产生改变就会导致状态的错乱。我们是否也遇到过:忙碌指示器没有正确隐藏掉,页面的显示的字段被错误的显示成旧的值,甚至一个页面几个部分信息不同步的情况?
单个的问题看似简单,但是客户端飞速发展的今年,很多公司包括美团在内的客户端代码行数早已突破百万。业务逻辑愈发复杂,使得维护状态本身就成了一个大问题。响应式编程正是解决这个问题的一种手段。
响应式编程的相关概念
响应式编程是基于数据流动编程的一种编程范式。做过 iOS 客户端开发的同学一定了解过 KVO 这一系列的 API。
KVO 帮助我们将属性的变更和变更后的处理分离开,大大简化了我们的更新逻辑。响应式编程将这一优势体现得更加淋漓尽致,可以简单的理解成一个对象的属性改变后,另外一连串对象的属性都随之发生改变。
响应式的最简单例子莫过于电子表格,Excel 和 Numbers 中单元格公式就是一个响应的例子。我们只需要关心单元格和单元格的关系,而不需要关心当一个单元格发生变化,另外的单元格需要进行怎样的处理。“程序”的书写被提前到事件发生之前,所以响应式编程是一种声明式编程。它帮助我们将更多的精力集中在描述数据流动的关系上,而不是关注数据变化时处理的动作。
单纯的响应式编程,比如电子表格中的公式和 KVO 是比较容易理解的,但是为了在 Objective-C 语言中支持响应式特性,ReactiveCocoa 使用了函数响应式编程的手段实现了响应式编程框架。而函数式编程正是造成大家学习路径陡峭的主要原因。在函数式编程的世界中, 一切又都复杂起来了。这些复杂的概念,如 Immutable、Side effect、High-order Function、Functor、Applicative、Monad 等等,让很多开发者望而却步。
防不胜防的错误
函数式编程主要使用高阶函数来解决问题,映射到 Objective-C 语言中就是使用 Block 来进行主要的处理。由于 Objective-C 使用自动引用计数(ARC)来管理内存,一旦出现循环引用,就需要程序员主动破除循环引用。而 Block 闭包捕获变量最容易形成循环引用。无脑的 weakify-strongify 会引起提早释放,而无脑的不使用 weakify-strongify 则会引起循环引用。即便是“老手”在使用的过程中,也难免出错。
另外,ReactiveCocoa 框架为了方便开发者更快的使用响应式编程,Hook 了很多 Cocoa 框架中的功能,例如 KVO、Notification Center、Perform Selector。一旦其它框架在 Hook 的过程中与之形成冲突,后续问题的排查就变得十分困难。
调试的困难性
函数响应式编程使用高阶函数还带来了另外一个问题,那就是大量的嵌套闭包函数导致的调用栈深度问题。在 ReactiveCocoa 2.5 版本中,进行简单的 5 次变换,其调用栈深度甚至达到了 50 层(见下图)。
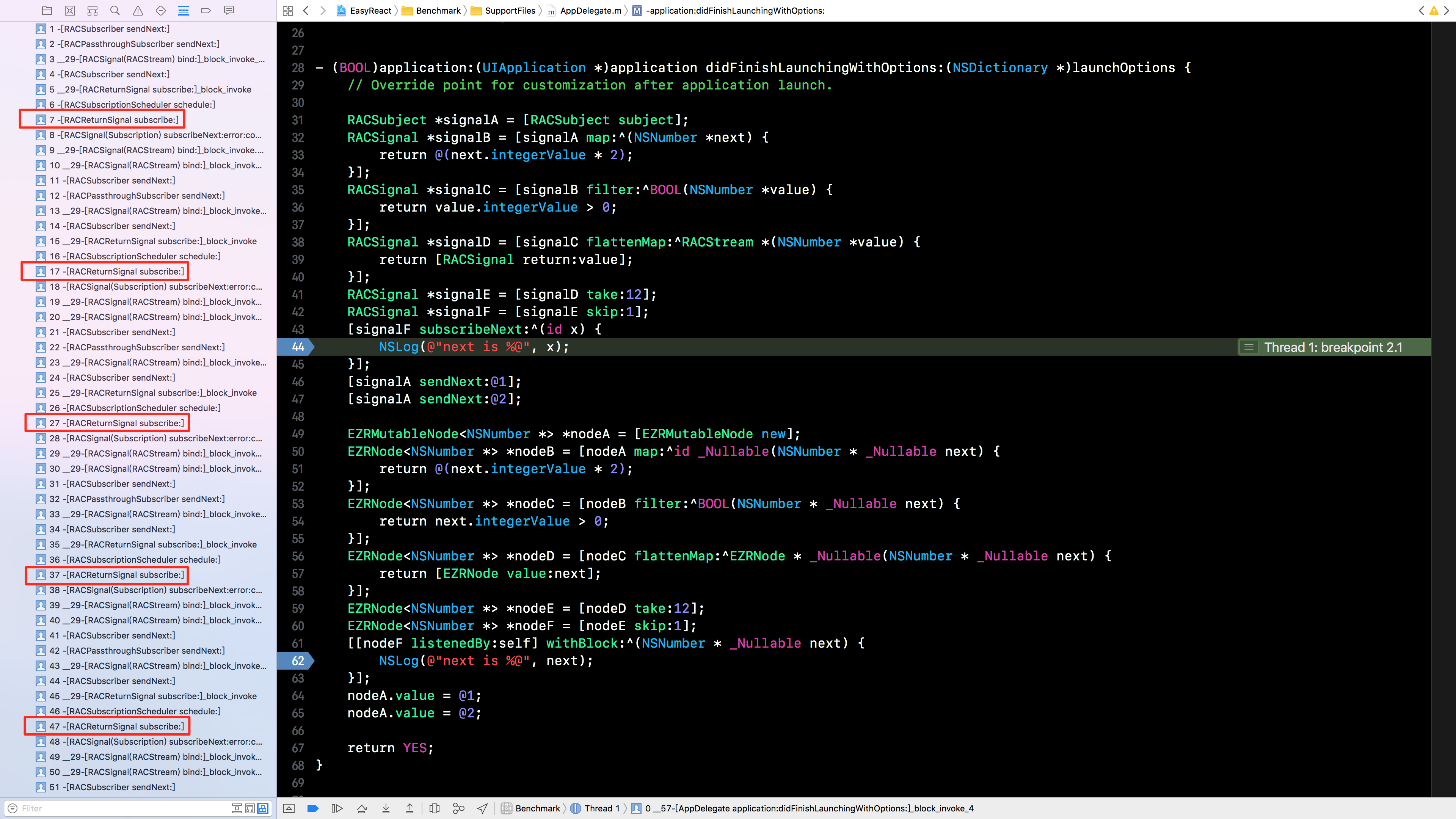
仔细观察调用栈,我们发现整个调用栈的内容极为相似,难以从中发现问题所在。
另外异步场景更是给调试增加了新的难度。很多时候,数据的变化是由其他队列派发过来的,我们甚至无法在调用栈中追溯数据变化的来源。
风格差异化
业内很多人使用 FRP 框架来解决 MVVM 架构中的绑定问题。在业务实践中很多操作是高度相似且可被泛化的,这也意味着,可以被脚手架工具自动生成。
但目前业内知名的框架并没有提供相应的工具,最佳实践也无法“模板化”地传递下去。这就导致了对于 MVVM 和响应式编程,大家有了各自不同的理解。
EasyReact的初心
EasyReact 的诞生,其初心是为了解决 iOS 工程实现 MVVM 架构但没有对应的框架支撑,而导致的风格不统一、可维护性差、开发效率低等多种问题。而 MVVM 中最重要的一个功能就是绑定,EasyReact 就是为了让绑定和响应式的代码变得 Easy 起来。
它的目标就是让开发者能够简单的理解响应式编程,并且简单的将响应式编程的优势利用起来。
EasyReact 依赖库介绍
EasyReact 先是基于 Objective-C 开发。而 Objective-C 是一门古老的编程语言,在 2014 年苹果公司推出 Swift 编程语言之后,Objective-C 已经基本不再更新,而 Swift支持的 Tuple 类型和集合类型自带的 map、filter 等方法会让代码更清晰易读。 在 EasyReact Objective-C 版本的开发中,我们还衍生了一些周边库以支持这些新的代码技巧和语法糖。这些周边库现已开源,并且可以独立于 EasyReact 使用。
EasyTuple

EasyTuple 使用宏构造出类似 Swift 的 Tuple 语法。使用 Tuple 可以让你在需要传递一个简单的数据架构的时,不必手动为其创建对应的类,轻松的交给框架解决。
EasySequence

EasySequence 是一个给集合类型扩展的库,可以清晰的表达对一个集合类型的迭代操作,并且通过巧妙的手法可以让这些迭代操作使用链式语法拼接起来。同时 EasySequence 也提供了一系列的 线程安全 和 weak 内存管理的集合类型用以补充系统容器无法提供的功能。
EasyFoundation

EasyFoundation 是上述 EasyTuple 和 EasySequence 以及未来底层依赖库的一个统一封装。
用 EasyReact 解决之前的问题
EasyReact 因业务的需要而诞生,首要的任务就是解决业务中出现的那几点问题。我们来看看建设至今,那几个问题是否已经解决:
响应式编程的学习门槛
前面已经分析过,单纯的响应式编程并不是特别的难以理解,而函数式编程才是造成高学习门槛的原因。因此 EasyReact 采用大家都熟知的面向对象编程进行设计, 想要了解代码,相对于函数式编程变得容易很多。
另外响应式编程基于数据流动,流动就会产生一个有向的流动网络图。在函数式编程中,网络图是使用闭包捕获来建立的,这样做非常不利于图的查找和遍历。而 EasyReact 选择在框架中使用图的数据结构,将数据流动的有向网络图抽象成有向有环图的节点和边。这样使得框架在运行过程中可以随时查询到节点和边的关系,详细内容可以参见 框架概述。
另外对于已经熟悉了 ReactiveCocoa 的同学来说,我们也在数据的流动操作上基本实现了 ReactiveCocoa API。详细内容可以参见 基本操作。更多的功能可以向我们提功能的 ISSUE,也欢迎大家能够提 Pull Request 来共同建设 EasyReact。
避免不经意的错误
前面提到过 ReactiveCocoa 易造成循环引用或者提早释放的问题,那 EasyReact 是怎样解决这个问题的呢?因为 EasyReact 中的节点和边以及监听者都不是使用闭包来进行捕获,所以刨除转换和订阅中存在的副作用(转换 block 或者订阅 block 中导致的闭包捕获),EasyReact 是可以自动管理内存的。详细内容可以参见 内存管理。
除了内存问题,ReactiveCocoa 中的 Hook Cocoa 框架问题,在 EasyReact 上通过规避手段来进行处理。EasyReact 在整个计划中只是用来完成最基本的数据流驱动的部分,所以本身与 Cocoa 和 CocoaTouch 框架无关,一定程度上避免了与系统 API 和其他库 Hook 造成冲突。这并不是指 Easy 系列不去解决相应的部分,而是 Easy 系列希望以更规范和加以约束的方式来解决相同问题,后续 Easy 系列的其他开源项目中会有更多这些特定需求的解决方案。
EasyReact 的调试
EasyReact 利用对象的持有关系和方法调用来实现响应式中的数据流动,所以可方便的在调用栈信息中找出数据的传递关系。在 EasyReact 中,进行与前面 ReactiveCocoa 同样的 5 次简单变换,其调用栈只有 15 层(见下图)。
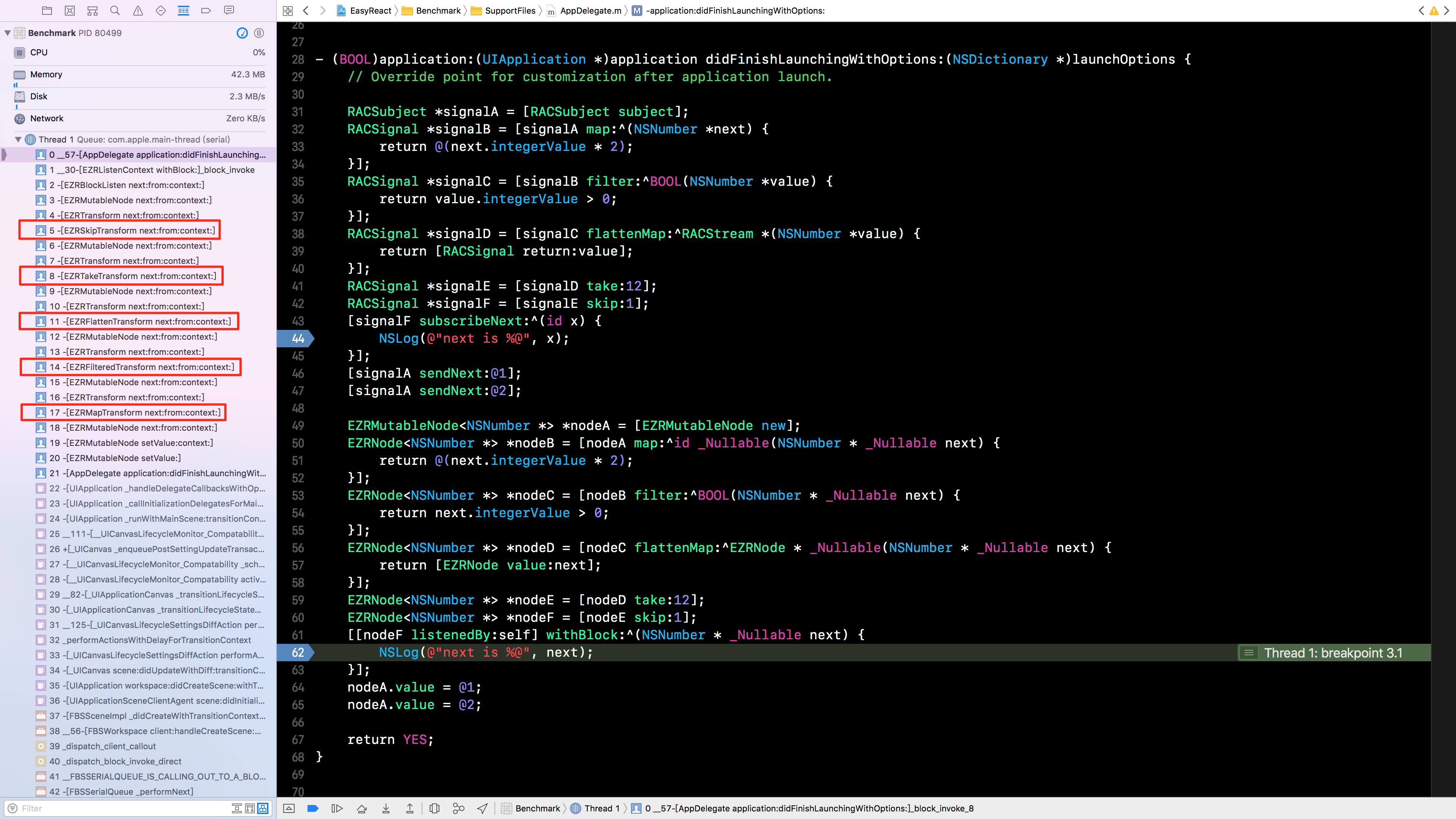
经过观察不难发现,调用栈的顺序恰好就是变换的行为。这是因为我们将每种操作定义成一个边的类型,使得调用栈可以通过类名进行简单的分析。
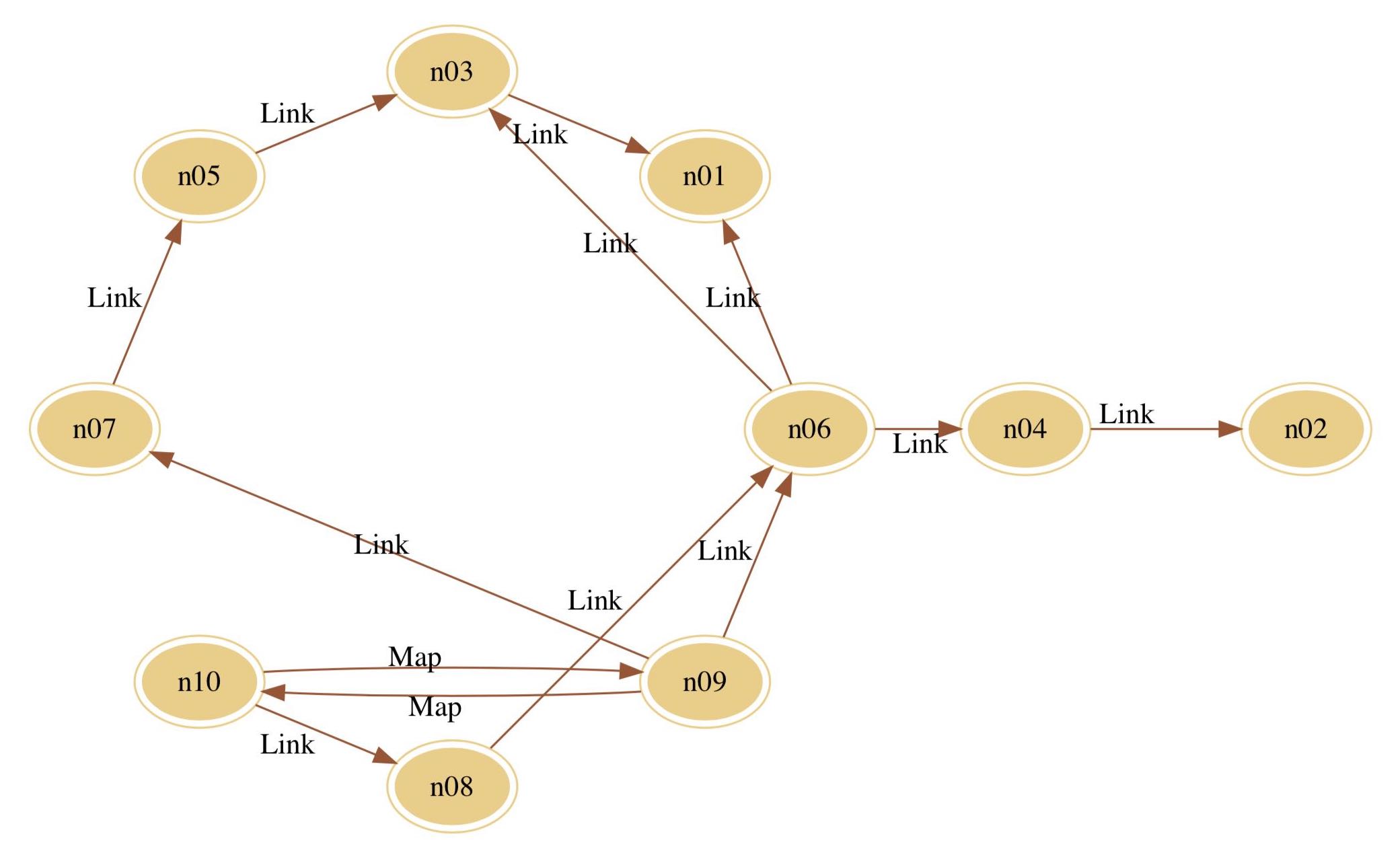
为了方便调试,我们提供了一个 - [EZRNode graph] 方法。任意一个节点调用这个方法都可以得到一段 GraphViz 程序的 DotDSL 描述字符串,开发者可以通过 GraphViz 工具观察节点的关系,更好的排查问题。
使用方式如下:
-
macOS 安装 GraphViz 工具
brew install graphviz -
打印
-[EZRNode graph]返回的字符串或者 Debug 期间在 lldb 调用-[EZRNode graph]获取结果字符串,并输出保存至文件如test.dot -
使用工具分析生成图像
circo -Tpdf test.dot -o test.pdf && open test.pdf
结果示例:
另外我们还开发了一个带有录屏并且可以动态查看应用程序中所有节点和边的调试工具,后期也会开源。开发中的工具是这样的:

响应式编程风格上的统一
EasyReact 帮助我们解决了不少难题,遗憾的是它也不是“银弹”。在实际的项目实施中,我们发现仅仅通过 EasyReact 仍然很难让大家在开发的过程中风格上统一起来。当然它从写法上要比 ReactiveCocoa 上统一了一些,但是构建数据流仍然有着多种多样的方式。
所以我们想到通过一个上层的业务框架来统一风格,这也就是后续衍生项目 EasyMVVM 诞生的原因,不久后我们也会将 EasyMVVM 进行开源。
EasyReact 和其他框架的对比
EasyReact 从诞生之初,就不可避免要和已有的其他响应式编程框架做对比。下表对几大响应式框架进行了一个大概的对比:
| 项目 | EasyReact | ReactiveCocoa | ReactiveX |
|---|---|---|---|
| 核心概念 | 图论和面向对象编程 | 函数式编程 | 函数式编程和泛型编程 |
| 传播可变性 | ✓ | ✗ | ✗ |
| 基本变换 | ✓ | ✓ | ✓ |
| 组合变换 | ✓ | ✓ | ✓ |
| 高阶变换 | ✓ | ✓ | ✓ |
| 遍历节点 / 信号 | ✓ | ✗ | ✗ |
| 多语言支持 | Objective-C (其他语言开源计划中) | Objective-C、Swift | 大量语言 |
| 性能 | 较快 | 慢 | 快 |
| 中文文档支持 | ✓ | ✗ | ✗ |
| 调试工具 | 静态拓扑图展示和动态调试工具(开源计划中) | Instrument | ✗ |
性能方面,我们也和同样是 Objective-C 语言的 ReactiveCocoa 2.5 版本做了相应的 Benchmark。
测试环境
编译平台: macOS High Sierra 10.13.5
IDE: Xcode 9.4.1
真机设备: iPhone X 256G iOS 11.4(15F79)
测试对象
- listener、map、filter、flattenMap 等单阶操作
- combine、zip、merge 等多点聚合操作
- 同步操作
其中测试的规模为:
- 节点或信号个数 10 个
- 触发操作次数 1000 次
例如 Listener 方法有 10 个监听者,重复发送值 1000 次。
统计时间单位为 ns。
测试数据
重复上面的实验 10 次,得到数据平均值如下:
| name | listener | map | filter | flattenMap | combine | zip | merge | syncWith |
|---|---|---|---|---|---|---|---|---|
| EasyReact | 1860665 | 30285707 | 7043007 | 7259761 | 6234540 | 63384482 | 19794457 | 12359669 |
| ReactiveCocoa | 4054261 | 74416369 | 45095903 | 44675757 | 209096028 | 143311669 | 13898969 | 53619799 |
| RAC:EasyReact | 217.89% | 245.71% | 640.29% | 615.39% | 3353.83% | 226.10% | 70.22% | 433.83% |
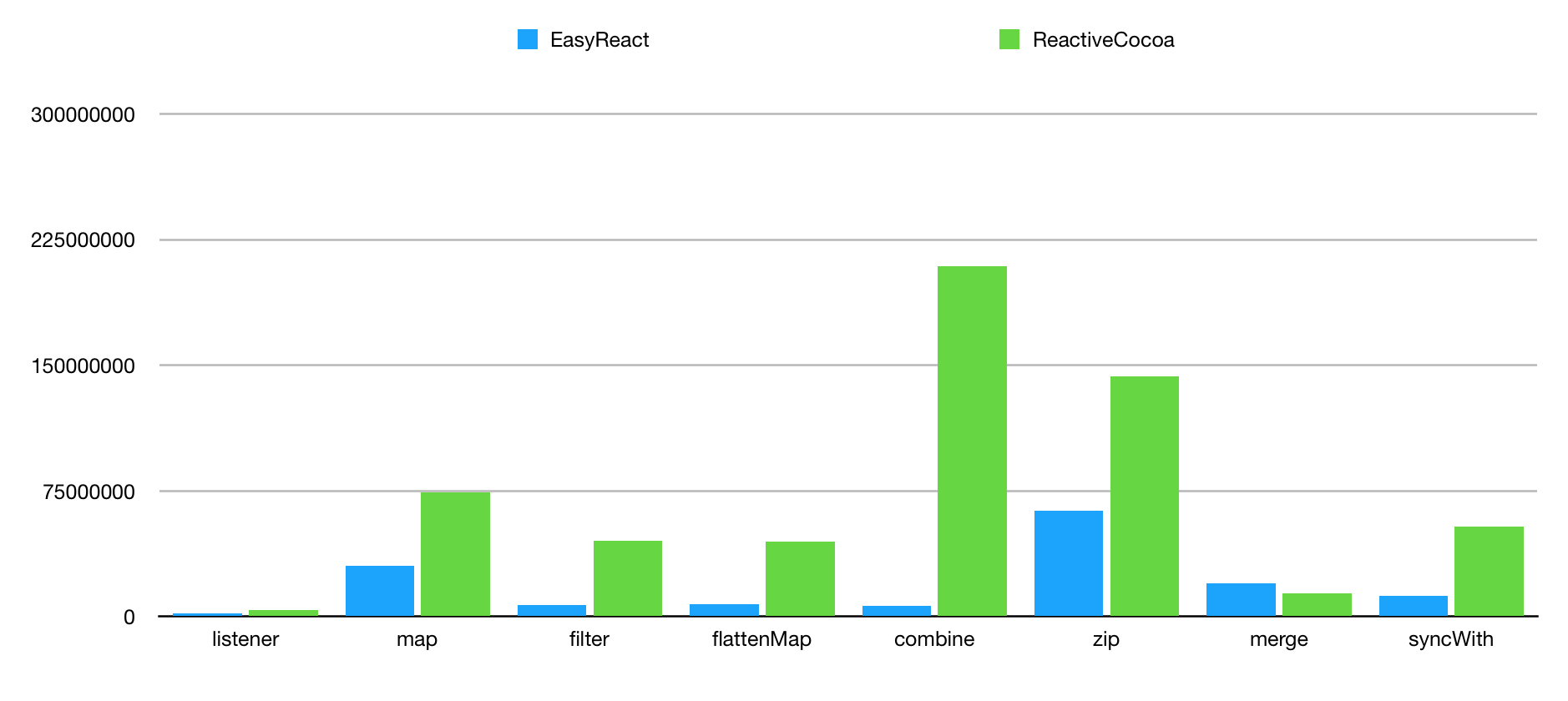
结果总结
ReactiveCocoa 平均耗时是 EasyReact 的 725.41%。
EasyReact 的 Swift 版本即将开源,届时会和 RxSwift 进行 Benchmark 比较。
EasyReact的最佳实践
通常我们创建一个类,里面会包含很多的属性。在使用 EasyReact 时,我们通常会把这些属性包装为 EZRNode 并加上一个泛型。如:
// SearchService.h
#import <Foundation/Foundation.h>
#import <EasyReact/EasyReact.h>
@interface SearchService : NSObject
@property (nonatomic, readonly, strong) EZRMutableNode<NSString *> *param;
@property (nonatomic, readonly, strong) EZRNode<NSDictionary *> *result;
@property (nonatomic, readonly, strong) EZRNode<NSError *> *error;
@end
这段代码展示了如何创建一个 WiKi 查询服务,该服务接收一个 param 参数,查询后会返回 result 或者 error。以下是实现部分:
// SearchService.m
@implementation SearchService
- (instancetype)init {
if (self = [super init]) {
_param = [EZRMutableNode new];
EZRNode *resultNode = [_param flattenMap:^EZRNode * _Nullable(NSString * _Nullable searchParam) {
NSString *queryKeyWord = [searchParam stringByAddingPercentEncodingWithAllowedCharacters:[NSCharacterSet URLQueryAllowedCharacterSet]];
NSURL *url = [NSURL URLWithString:[NSString stringWithFormat:@"https://en.wikipedia.org/w/api.php?action=query&titles=%@&prop=revisions&rvprop=content&format=json&formatversion=2", queryKeyWord]];
EZRMutableNode *returnedNode = [EZRMutableNode new];
[[NSURLSession sharedSession] dataTaskWithURL:url completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {
if (error) {
returnedNode.value = error;
} else {
NSError *serializationError;
NSDictionary *resultDictionary = [NSJSONSerialization JSONObjectWithData:data options:0 error:&serializationError];
if (serializationError) {
returnedNode.value = serializationError;
} else if (!([resultDictionary[@"query"][@"pages"] count] && !resultDictionary[@"query"][@"pages"][0][@"missing"])) {
NSError *notFoundError = [NSError errorWithDomain:@"com.example.service.wiki" code:100 userInfo:@{NSLocalizedDescriptionKey: [NSString stringWithFormat:@"keyword '%@' not found.", searchParam]}];
returnedNode.value = notFoundError;
} else {
returnedNode.value = resultDictionary;
}
}
}];
return returnedNode;
}];
EZRIFResult *resultAnalysedNode = [resultNode if:^BOOL(id _Nullable next) {
return [next isKindOfClass:NSDictionary.class];
}];
_result = resultAnalysedNode.thenNode;
_error = resultAnalysedNode.elseNode;
}
return self;
}
@end
在调用时,我们只需要通过 listenedBy 方法关注节点的变化:
self.service = [SearchService new];
[[self.service.result listenedBy:self] withBlock:^(NSDictionary * _Nullable next) {
NSLog(@"Result: %@", next);
}];
[[self.service.error listenedBy:self] withBlock:^(NSError * _Nullable next) {
NSLog(@"Error: %@", next);
}];
self.service.param.value = @"mipmap"; //should print search result
self.service.param.value = @"420v"; // should print error, keyword not found.
使用 EasyReact 后,网络请求的参数、结果和错误可以很好地被分离。不需要像命令式的写法那样在网络请求返回的回调中写一堆判断来分离结果和错误。
因为节点的存在先于结果,我们能对暂时还没有得到的结果构建连接关系,完成整个响应链的构建。响应链构建之后,一旦有了数据,数据便会自动按照我们预期的构建来传递。
在这个例子中,我们不需要显式地来调用网络请求,只需要给响应链中的 param 节点赋值,框架就会主动触发网络请求,并且请求完成之后会根据网络返回结果来分离出 result 和 error 供上层业务直接使用。
对于开源,我们是认真的
EasyReact 项目自立项以来,就励志打造成一个通用的框架,团队也一直以开源的高标准要求自己。整个开发的过程中我们始终保证测试覆盖率在一个高的标准上,对于接口的设计也力求完美。在开源的流程,我们也学习借鉴了 Github 上大量优秀的开源项目,在流程、文档、规范上力求标准化、国际化。
文档
除了 中文 README 和 英文 README 以外,我们还提供了中文的说明性质文档:
和英文的说明性质文档:
后续帮助理解的文章,也会陆续上传到项目中供大家学习。
另外也为开源的贡献提供了标准的 中文贡献流程 和 英文贡献流程,其中对于 ISSUE 模板、Commit 模板、Pull Requests 模板和 Apache 协议头均有提及。
如果你仍然对 EasyReact 有所不解或者流程代码上有任何问题,可以随时通过提 ISSUE 的方式与我们联系,我们都会尽快答复。
行为驱动开发
为了保证 EasyReact 的质量,我们在开发的过程中使用 行为驱动开发。当每个新功能的声明部分确定后,我们会先编写大量的测试用例,这些用例模拟使用者的行为。通过模拟使用者的行为,以更加接近使用者的想法,去设计这个新功能的 API。同时大量的测试用例也保证了新的功能完成之时,一定是稳定的。
测试覆盖率
EasyReact 系列立项之时,就以高质量、高标准的开发原则来要求开发组成员执行。开源之后所有项目使用 codecov.io 服务生成对应的测试覆盖率报告,Easy 系列的框架覆盖率均保证在 95% 以上。
| name | listener |
|---|---|
| EasyReact | |
| EasyTuple | |
| EasySequence | |
| EasyFoundation |
持续集成
为了保证项目质量,所有的 Easy 系列框架都配有持续集成工具 Travis CI。它确保了每一次提交,每一次 Pull Request 都是可靠的。
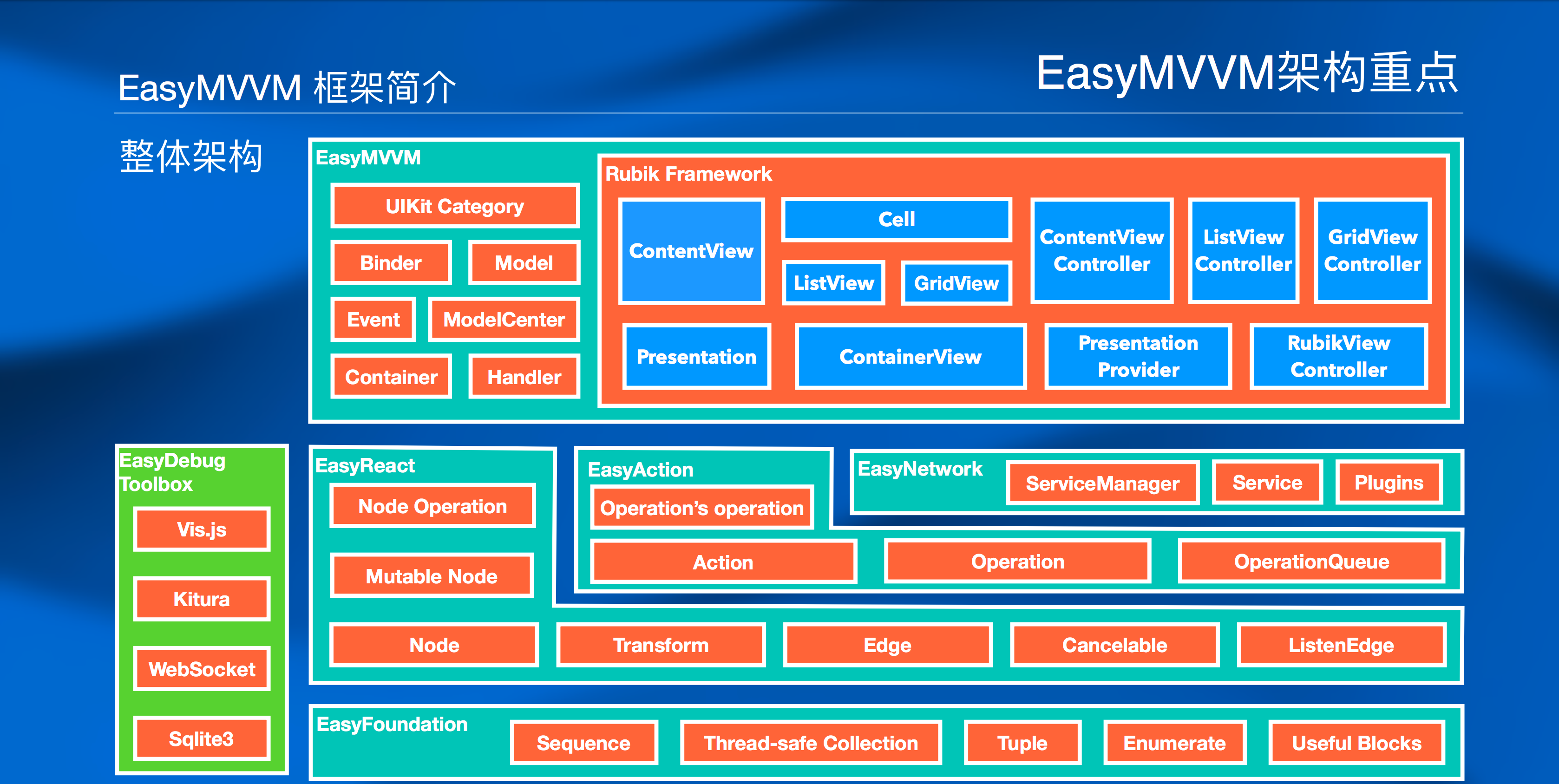
展望
目前开源的框架组件只是建立起响应式编程的基石,Easy 系列的初心是为 MVVM 架构提供一个强有力的框架工具。下图是 Easy 系列框架的架构简图:
未来开源计划
未来我们还有提供更多框架能力,开源给大家:
| 名称 | 描述 |
|---|---|
| EasyDebugToolBox | 动态节点状态调试工具 |
| EasyOperation | 基于行为和操作抽象的响应式库 |
| EasyNetwork | 响应式的网络访问库 |
| EasyMVVM | MVVM 框架标准和相关工具 |
| EasyMVVMCLI | EasyMVVM 项目脚手架工具 |
跨平台与多语言
EasyReact 的设计基于面向对象,所以很容易在各个语言中实现,我们也正在积极的在 Swift、Java、JavaScript 等主力语言中实现 EasyReact。
另外动态化作为目前行业的趋势,Easy 系列自然不会忽视。在 EasyReact 基于图的架构下,我们可以很轻松的让一个 Objective-C 的上游节点通过一个特殊的桥接边连接到一个 JavaScript 节点,这样就可以让部分的逻辑动态下发过来。
结语
数据传递和异步处理,是大部分业务的核心。EasyReact 从架构上用响应式的方式来很好的解决了这个问题。它有效地组织了数据和数据之间的联系, 让业务的处理流程从命令式编程方式,变成以数据流为核心的响应式编程方式。用先构建数据流关系再响应触发的方法,让业务方更关心业务的本质。使广大开发者从琐碎的命令式编程的状态处理中解放出来,提高了生产力。EasyReact 不仅让业务逻辑代码更容易维护,也让出错的几率大大下降。
Logan:美团点评的开源移动端基础日志库

前言
Logan是美团点评集团移动端基础日志组件,这个名称是Log和An的组合,代表个体日志服务。同时Logan也是“金刚狼”大叔的名号,当然我们更希望这个产品能像金刚狼大叔一样犀利。
Logan已经稳定迭代了一年多的时间。目前美团点评绝大多数App已经接入并使用Logan进行日志收集、上传、分析。近日,我们决定开源Logan生态体系中的存储SDK部分(Android/iOS),希望能够帮助更多开发者合理的解决移动端日志存储收集的相关痛点,也欢迎更多社区的开发者和我们一起共建Logan生态。Github的项目地址参见:https://github.com/Meituan-Dianping/Logan
背景
随着业务的不断扩张,移动端的日志也会不断增多。但业界对移动端日志并没有形成相对成体系的处理方式,在大多数情况下,还是针对不同的日志进行单一化的处理,然后结合这些日志处理的结果再来定位问题。然而,当用户达到一定量级之后,很多“疑难杂症”却无法通过之前的定位问题的方式来进行解决。移动端开发者最头疼的事情就是“为什么我使用和用户一模一样的手机,一模一样的系统版本,仿照用户的操作却复现不出Bug”。特别是对于Android开发者来说,手机型号、系统版本、网络环境等都非常复杂,即使拿到了一模一样的手机也复现不出Bug,这并不奇怪,当然很多时候并不能完全拿到真正完全一模一样的手机。相信很多同学见到下面这一幕都似曾相识:
用(lao)户(ban):我发现我们App的XX页面打不开了,UI展示不出来,你来跟进一下这个问题。
你:好的。
于是,我们检查了用户反馈的机型和系统版本,然后找了一台同型号同版本的手机,试着复现却发现一切正常。我们又给用户打个电话,问问他到底是怎么操作的,再问问网络环境,继续尝试复现依旧未果。最后,我们查了一下Crash日志,网络日志,再看看埋点日志(发现还没报上来)。
你内心OS:奇怪了,也没产生Crash,网络也是通的,但是为什么UI展示不出来呢?
几个小时后……
用(lao)户(ban):这问题有结果了吗?
你:我用了各种办法复现不出来……暂时查不到是什么原因导致的这个问题。
用(lao)户(ban):那怪我咯?
你:……
如果把一次Bug的产生看作是一次“凶案现场”,开发者就是破案的“侦探”。案发之后,侦探需要通过各种手段搜集线索,推理出犯案过程。这就好比开发者需要通过查询各种日志,分析这段时间App在用户手机里都经历了什么。一般来说,传统的日志搜集方法存在以下缺陷:
- 日志上报不及时。由于日志上报需要网络请求,对于移动App来说频繁网络请求会比较耗电,所以日志SDK一般会积累到一定程度或者一定时间后再上报一次。
- 上报的信息有限。由于日志上报网络请求的频次相对较高,为了节省用户流量,日志通常不会太大。尤其是网络日志等这种实时性较高的日志。
- 日志孤岛。不同类型的日志上报到不同的日志系统中,相对孤立。
- 日志不全。日志种类越来越多,有些日志SDK会对上报日志进行采样。
面临挑战
美团点评集团内部,移动端日志种类已经超过20种,而且随着业务的不断扩张,这一数字还在持续增加。特别是上文中提到的三个缺陷,也会被无限地进行放大。
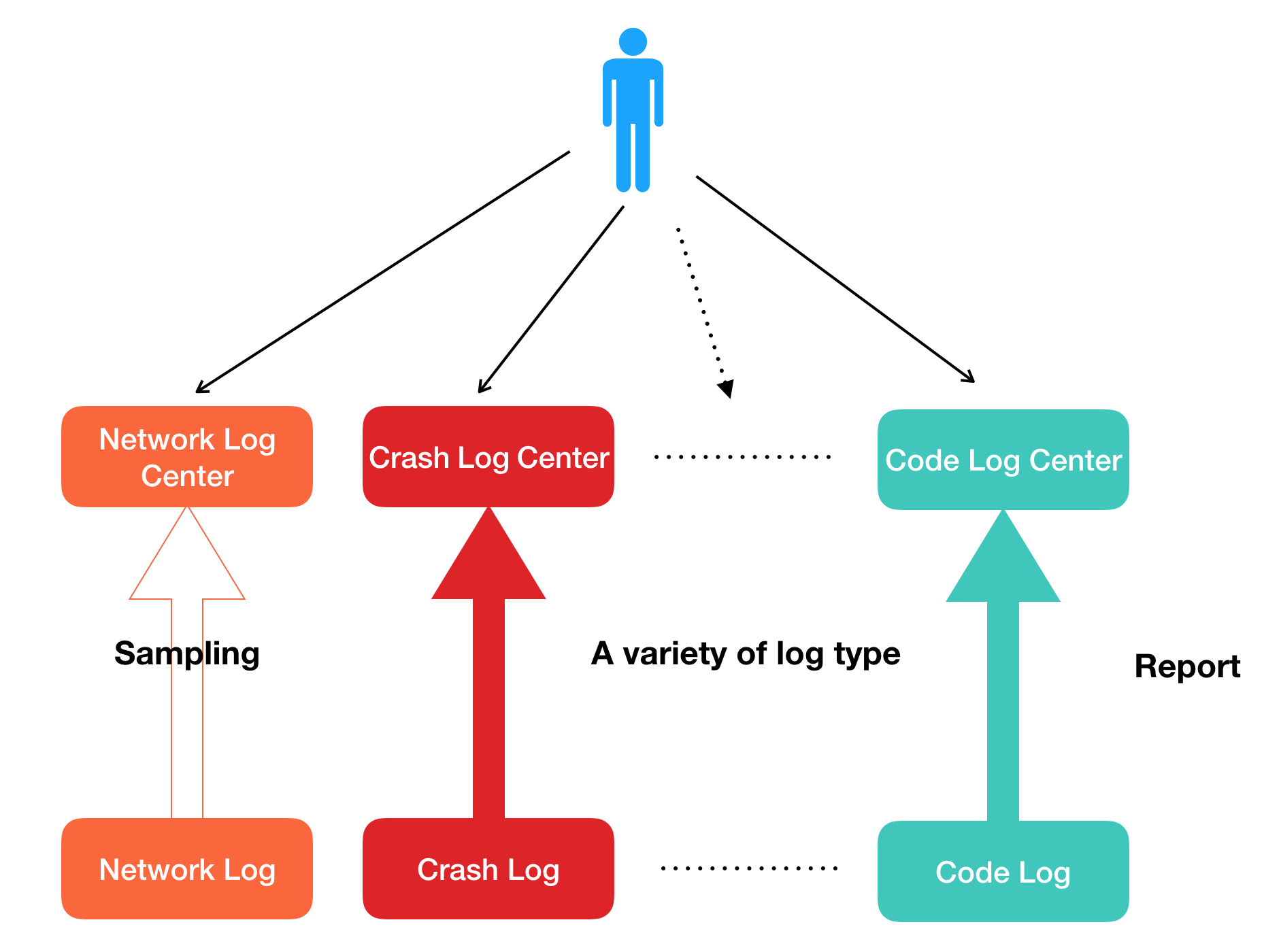
查问题是个苦力活,不一定所有的日志都上报在一个系统里,对于开发者来说,可能需要在多个系统中查看不同种类的日志,这大大增加了开发者定位问题的成本。如果我们每天上班都看着疑难Bug挂着无法解决,确实会很难受。这就像一个侦探遇到了疑难的案件,当他用尽各种手段收集线索,依然一无所获,那种心情可想而知。我们收集日志复现用户Bug的思路和侦探破案的思路非常相似,通过搜集的线索尽可能拼凑出相对完整的犯案场景。如果按照这个思路想下去,目前我们并没有什么更好的方法来处理这些问题。
不过,虽然侦探破案和开发者查日志解决问题的思路很像,但实质并不一样。我们处理的是Bug,不是真实的案件。换句话说,因为我们的“死者”是可见的,那么就可以从它身上获取更多信息,甚至和它进行一次“灵魂的交流”。换个思路想,以往的操作都是通过各种各样的日志拼凑出用户出现Bug的场景,那可不可以先获取到用户在发生Bug的这段时间产生的所有日志(不采样,内容更详细),然后聚合这些日志分析出(筛除无关项)用户出现Bug的场景呢?
个案分析
新的思路重心从“日志”变为“用户”,我们称之为“个案分析”。简单来说,传统的思路是通过搜集散落在各系统的日志,然后拼凑出问题出现的场景,而新的思路是从用户产生的所有日志中聚合分析,寻找出现问题的场景。为此,我们进行了技术层面的尝试,而新的方案需要在功能上满足以下条件:
- 支持多种日志收集,统一底层日志协议,抹平日志种类带来的差异。
- 日志本地记录,在需要时上报,尽可能保证日志不丢失。
- 日志内容要尽可能详细,不采样。
- 日志类型可扩展,可由上层自定义。
我们还需要在技术上满足以下条件:
- 轻量级,包体尽量小
- API易用
- 没有侵入性
- 高性能
最佳实践
在这种背景下,Logan横空出世,其核心体系由四大模块构成:
- 日志输入
- 日志存储
- 后端系统
- 前端系统
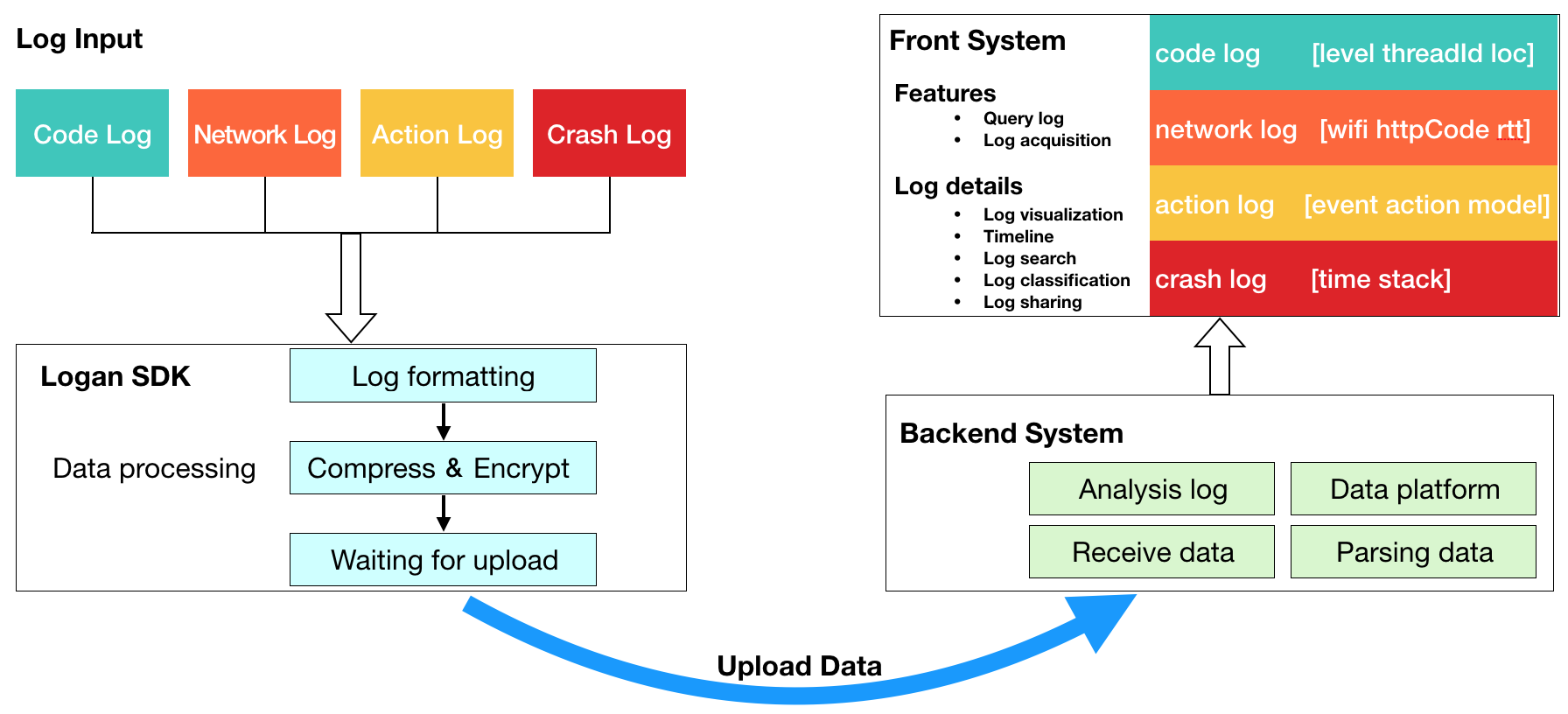
日志输入
常见的日志类型有:代码级日志、网络日志、用户行为日志、崩溃日志、H5日志等。这些都是Logan的输入层,在不影响原日志体系功能的情况下,可将内容往Logan中存储一份。Logan的优势在于:日志内容可以更加丰富,写入时可以携带更多信息,也没有日志采样,只会等待合适的时机进行统一上报,能够节省用户的流量和电量。
以网络日志为例,正常情况下网络日志只记录端到端延时、发包大小、回包大小字段等等,同时存在采样。而在Logan中网络日志不会被采样,除了上述内容还可以记录请求Headers、回包Headers、原始Url等信息。
日志存储
Logan存储SDK是这个开源项目的重点,它解决了业界内大多数移动端日志库存在的几个缺陷:
- 卡顿,影响性能
- 日志丢失
- 安全性
- 日志分散
Logan自研的日志协议解决了日志本地聚合存储的问题,采用“先压缩再加密”的顺序,使用流式的加密和压缩,避免了CPU峰值,同时减少了CPU使用。跨平台C库提供了日志协议数据的格式化处理,针对大日志的分片处理,引入了MMAP机制解决了日志丢失问题,使用AES进行日志加密确保日志安全性。Logan核心逻辑都在C层完成,提供了跨平台支持的能力,在解决痛点问题的同时,也大大提升了性能。
为了节约用户手机空间大小,日志文件只保留最近7天的日志,过期会自动删除。在Android设备上Logan将日志保存在沙盒中,保证了日志文件的安全性。
详情请参考:美团点评移动端基础日志库——Logan
后端系统
后端是接收和处理数据中心,相当于Logan的大脑。主要有四个功能:
- 接收日志
- 日志解析归档
- 日志分析
- 数据平台
接收日志
客户端有两种日志上报的形式:主动上报和回捞上报。主动上报可以通过客服引导用户上报,也可以进行预埋,在特定行为发生时进行上报(例如用户投诉)。回捞上报是由后端向客户端发起回捞指令,这里不再赘述。所有日志上报都由Logan后端进行接收。
日志解析归档
客户端上报的日志经过加密和压缩处理,后端需要对数据解密、解压还原,继而对数据结构化归档存储。
日志分析
不同类型日志由不同的字段组合而成,携带着各自特有信息。网络日志有请求接口名称、端到端延时、发包大小、请求Headers等信息,用户行为日志有打开页面、点击事件等信息。对所有的各类型日志进行分析,把得到的信息串连起来,最终汇集形成一个完整的个人日志。
数据平台
数据平台是前端系统及第三方平台的数据来源,因为个人日志属于机密数据,所以数据获取有着严格的权限审核流程。同时数据平台会收集过往的Case,抽取其问题特征记录解决方案,为新Case提供建议。
前端系统
一个优秀的前端分析系统可以快速定位问题,提高效率。研发人员通过Logan前端系统搜索日志,进入日志详情页查看具体内容,从而定位问题,解决问题。
目前集团内部的Logan前端日志详情页已经具备以下功能:
- 日志可视化。所有的日志都经过结构化处理后,按照时间顺序展示。
- 时间轴。数据可视化,利用图形方式进行语义分析。
- 日志搜索。快速定位到相关日志内容。
- 日志筛选。支持多类型日志,可选择需要分析的日志。
- 日志分享。分享单条日志后,点开分享链接自动定位到分享的日志位置。
Logan对日志进行数据可视化时,尝试利用图形方式进行语义分析简称为时间轴。
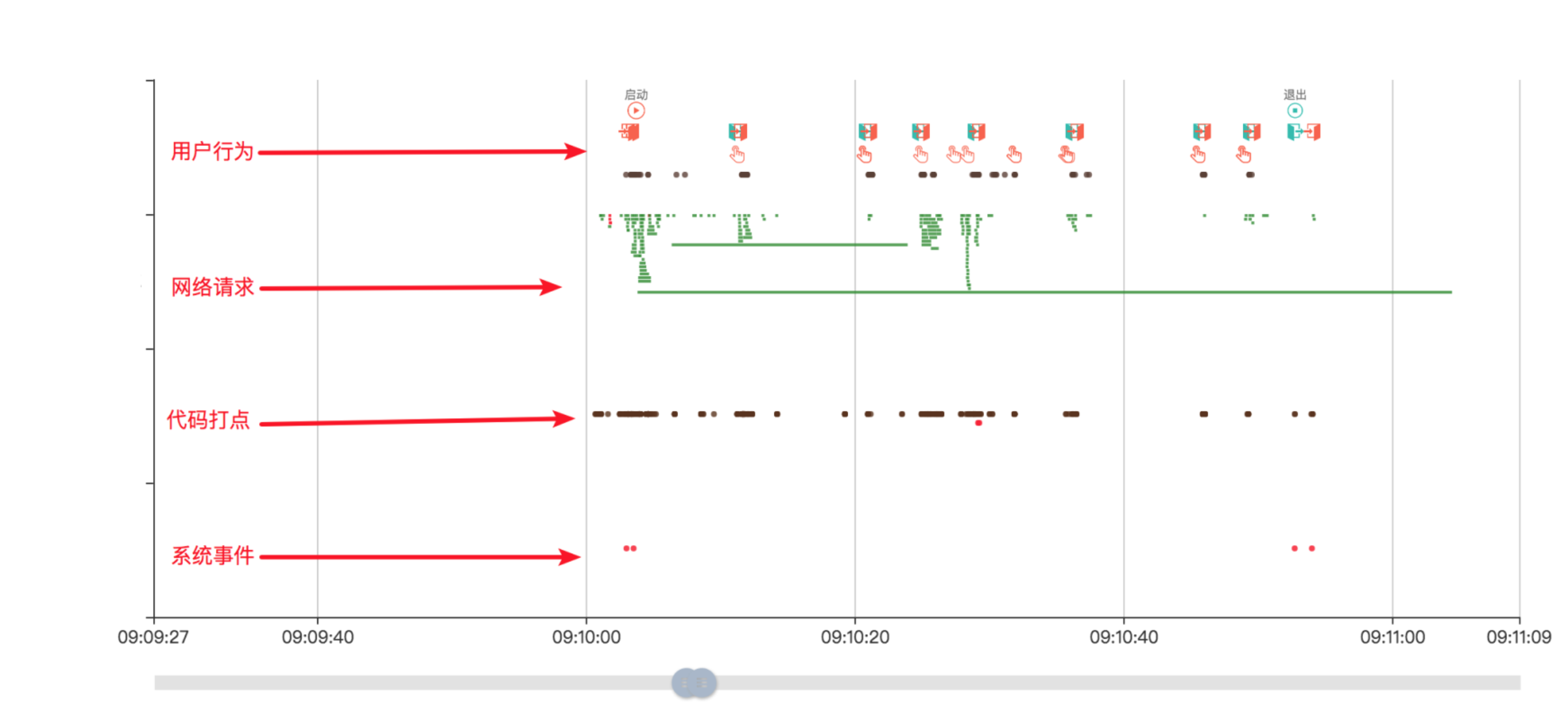
每行代表着一种日志类型。同一日志类型有着多种图形、颜色,他们标识着不同的语义。
例如时间轴中对代码级日志进行了日志类别的区分:
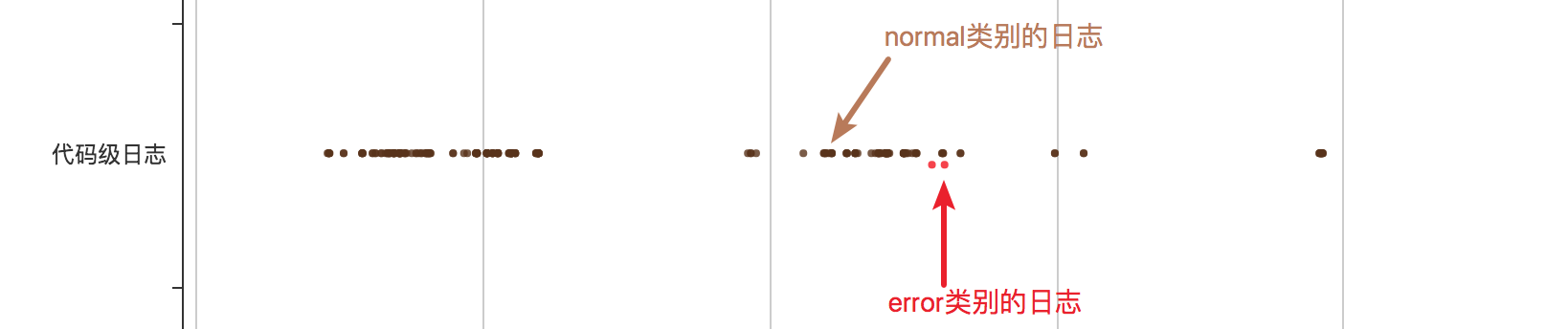
利用颜色差异,可以轻松区分出错误的日志,点击红点即可直接跳转至错误日志详情。
个案分析流程
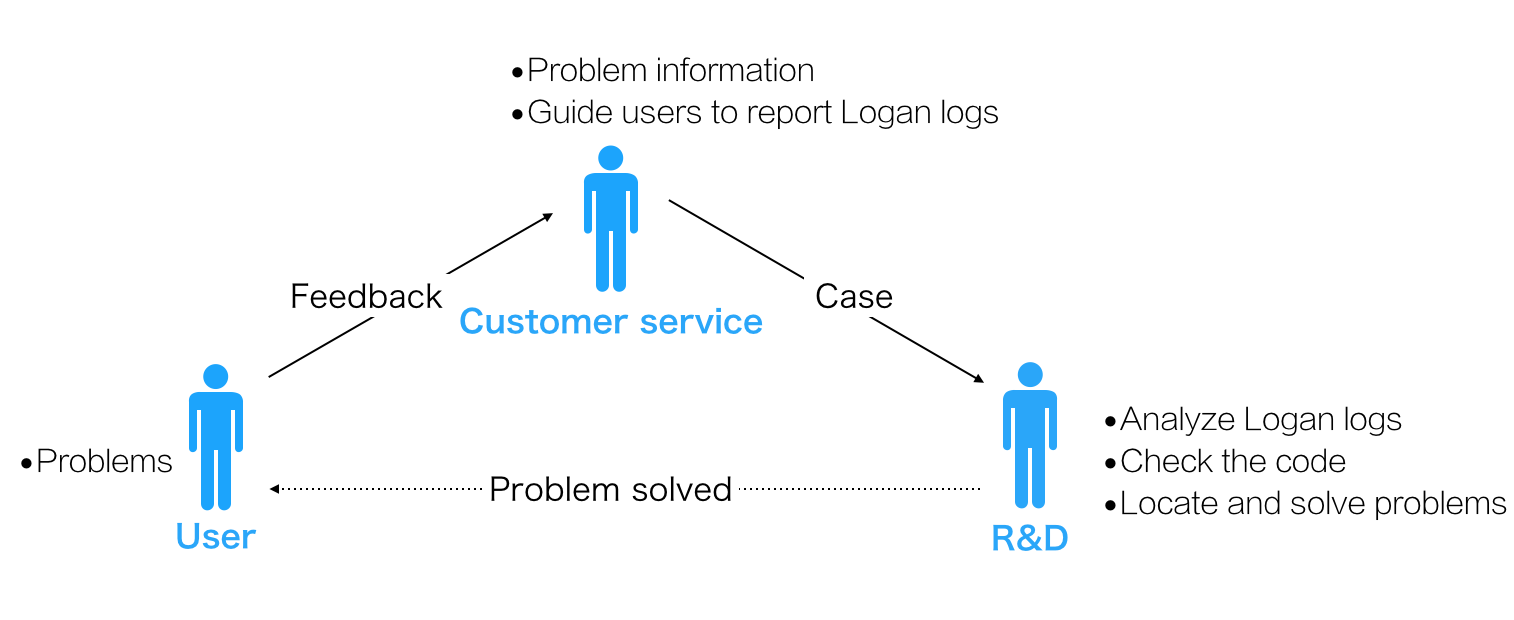
- 用户遇到问题联系客服反馈问题。
- 客服收到用户反馈。记录Case,整理问题,同时引导用户上报Logan日志。
- 研发同学收到Case,查找Logan日志,利用Logan系统完成日志筛选、时间定位、时间轴等功能,分析日志,进而还原Case“现场”。
- 最后,结合代码定位问题,修复问题,解决Case。
定位问题
结合用户信息,通过Logan前端系统查找用户的日志。打开日志详情,首先使用时间定位功能,快速跳转到出问题时的日志,结合该日志上下文,可得到当时App运行情况,大致推断问题发生的原因。接着利用日志筛选功能,查找关键Log对可能出问题的地方逐一进行排查。最后结合代码,定位问题。
当然,在实际上排查中问题比这复杂多,我们要反复查看日志、查看代码。这时还可能要借助一下Logan高级功能,如时间轴,通过时间轴可快速找出现异常的日志,点击时间轴上的图标可跳转到日志详情。通过网络日志中的Trace信息,还可以查看该请求在后台服务详细的响应栈情况和后台响应值。
未来规划
- 机器学习分析。首先收集过往的Case及解决方案,提取分析Case特征,将Case结构化后入库,然后通过机器学习快速分析上报的日志,指出日志中可能存在的问题,并给出解决方案建议;
- 数据开放平台。业务方可以通过数据开放平台获取数据,再结合自身业务的特性研发出适合自己业务的工具、产品。
平台支持
| Platform | iOS | Android | Web | Mini Programs |
|---|---|---|---|---|
| Support | ✓ | ✓ | ✓ | ✓ |
目前Logan SDK已经支持以上四个平台,本次开源iOS和Android平台,其他平台未来将会陆续进行开源,敬请期待。
测试覆盖率
由于Travis、Circle对Android NDK环境支持不够友好,Logan为了兼容较低版本的Android设备,目前对NDK的版本要求是16.1.4479499,所以我们并没有在Github仓库中配置CI。开发者可以本地运行测试用例,测试覆盖率可达到80%或者更高。
开源计划
在集团内部已经形成了以Logan为中心的个案分析生态系统。本次开源的内容有iOS、Android客户端模块、数据解析简易版,小程序版本、Web版本已经在开源的路上,后台系统,前端系统也在我们开源计划之中。
未来我们会提供基于Logan大数据的数据平台,包含机器学习、疑难日志解决方案、大数据特征分析等高级功能。
最后,我们希望提供更加完整的一体化个案分析生态系统,也欢迎大家给我们提出建议,共建社区。
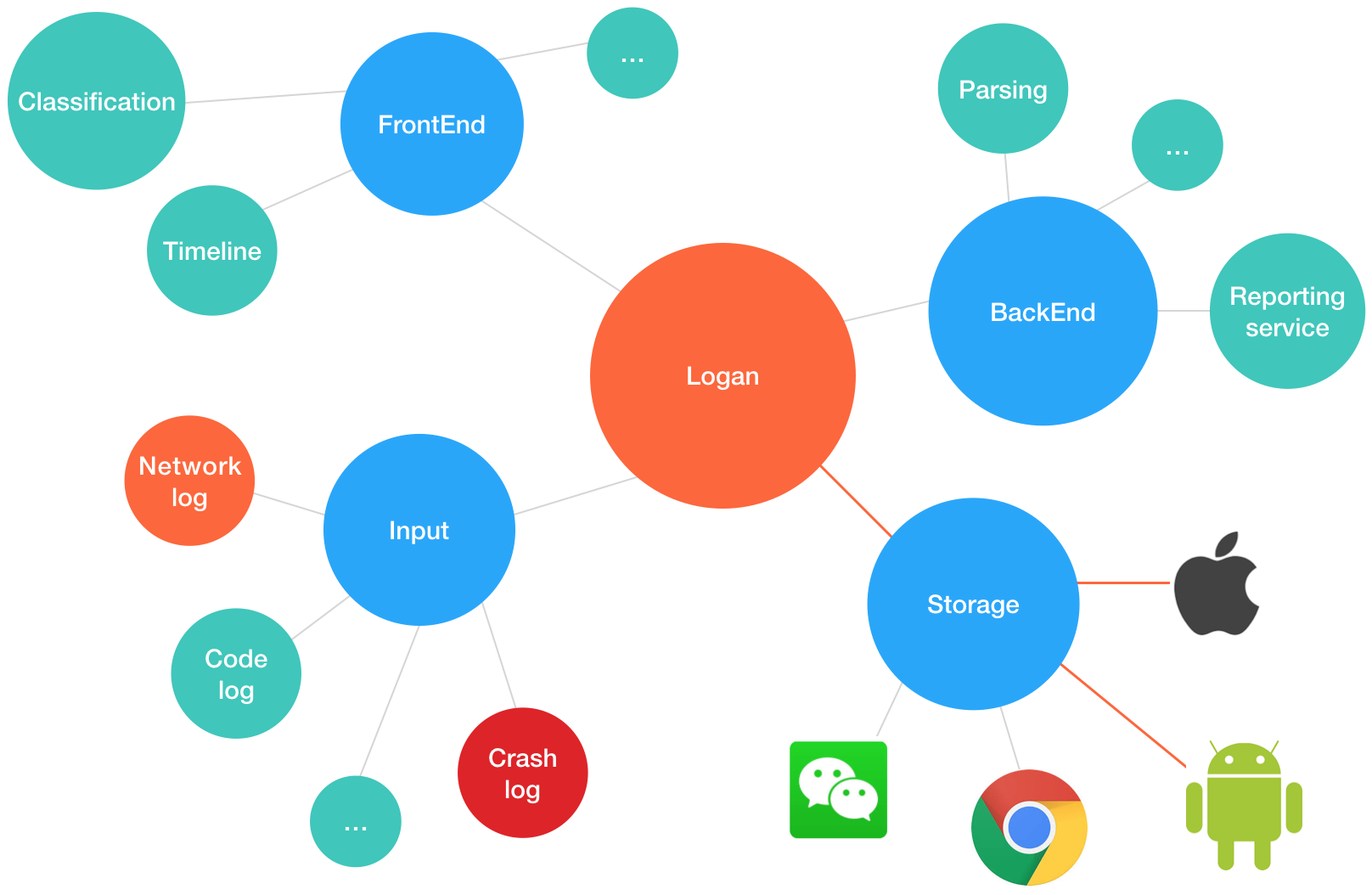
| Module | Open Source | Processing | Planning |
|---|---|---|---|
| iOS | ✓ | ||
| Android | ✓ | ||
| Web | ✓ | ||
| Mini Programs | ✓ | ||
| Back End | ✓ | ||
| Front End | ✓ |
美团点评移动端基础日志库——Logan
背景
对于移动应用来说,日志库是必不可少的基础设施,美团点评集团旗下移动应用每天产生的众多种类的日志数据已经达到几十亿量级。为了解决日志模块普遍存在的效率、安全性、丢失日志等问题,Logan基础日志库应运而生。
现存问题
目前,业内移动端日志库大多都存在以下几个问题:
- 卡顿,影响性能
- 日志丢失
- 安全性
- 日志分散
首先,日志模块作为底层的基础库,对上层的性能影响必须尽量小,但是日志的写操作是非常高频的,频繁在Java堆里操作数据容易导致GC的发生,从而引起应用卡顿,而频繁的I/O操作也很容易导致CPU占用过高,甚至出现CPU峰值,从而影响应用性能。
其次,日志丢失的场景也很常见,例如当用户的App发生了崩溃,崩溃日志还来不及写入文件,程序就退出了,但本次崩溃产生的日志就会丢失。对于开发者来说,这种情况是非常致命的,因为这类日志丢失,意味着无法复现用户的崩溃场景,很多问题依然得不到解决。
第三点,日志的安全性也是至关重要的,绝对不能随意被破解成明文,也要防止网络被劫持导致的日志泄漏。
最后一点,对于移动应用来说,日志肯定不止一种,一般会包含端到端日志1、代码日志、崩溃日志、埋点日志这几种,甚至会更多。不同种类的日志都具有各自的特点,会导致日志比较分散,查一个问题需要在各个不同的日志平台查不同的日志,例如端到端日志还存在日志采样,这无疑增加了开发者定位问题的成本。
面对美团点评几十亿量级的移动端日志处理场景,这些问题会被无限放大,最终可能导致日志模块不稳定、不可用。然而,Logan应运而生,漂亮地解决了上述问题。
简介
Logan,名称是Log和An的组合,代表个体日志服务的意思,同时也是金刚狼大叔的大名。通俗点说,Logan是美团点评移动端底层的基础日志库,可以在本地存储各种类型的日志,在需要时可以对数据进行回捞和分析。
Logan具备两个核心能力:本地存储和日志捞取。作为基础日志库,Logan已经接入了集团众多日志系统,例如端到端日志、用户行为日志、代码级日志、崩溃日志等。作为移动应用的幕后英雄,Logan每天都会处理几十亿量级的移动端日志。
设计
作为一款基础日志库,在设计之初就必须考虑如何解决日志系统现存的一些问题。
卡顿,影响性能
I/O是比较耗性能的操作,写日志需要大量的I/O操作,为了提升性能,首先要减少I/O操作,最有效的措施就是加缓存。先把日志缓存到内存中,达到一定大小的时候再写入文件。为了减少写入本地的日志大小,需要对数据进行压缩,为了增强日志的安全性,需要对日志进行加密。然而这样做的弊端是:
- 对Android来说,对日志加密压缩等操作全部在Java堆里面。由于日志写入是一个高频的动作,频繁地堆内存操作,容易引发Java的GC,导致应用卡顿;
- 集中压缩会导致CPU短时间飙高,出现峰值;
- 由于日志是内存缓存,在杀进程、Crash的时候,容易丢失内存数据,从而导致日志丢失。
Logan的解决方案是通过Native方式来实现日志底层的核心逻辑,也就是C编写底层库。这样做不光能解决Java GC问题,还做到了一份代码运行在Android和iOS两个平台上。同时在C层实现流式的压缩和加密数据,可以减少CPU峰值,使程序运行更加顺滑。而且先压缩再加密的方式压缩率比较高,整体效率较高,所以这个顺序不能变。
日志丢失
加缓存之后,异常退出丢失日志的问题就必须解决,Logan为此引入了MMAP机制。MMAP是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对应关系。MMAP机制的优势是:
- MMAP使用逻辑内存对磁盘文件进行映射,操作内存就相当于操作文件;
- 经过测试发现,操作MMAP的速度和操作内存的速度一样快,可以用MMAP来做数据缓存;
- MMAP将日志回写时机交给操作系统控制。如内存不足,进程退出的时候操作系统会自动回写文件;
- MMAP对文件的读写操作不需要页缓存,只需要从磁盘到用户主存的一次数据拷贝过程,减少了数据的拷贝次数,提高了文件读写效率。
引入MMAP机制之后,日志丢失问题得到了有效解决,同时也提升了性能。不过这种方式也不能百分百解决日志丢失的问题,MMAP存在初始化失败的情况,这时候Logan会初始化堆内存来做日志缓存。根据我们统计的数据来看,MMAP初始化失败的情况仅占0.002%,已经是一个小概率事件了。
安全性
日志文件的安全性必须得到保障,不能随意被破解,更不能明文存储。Logan采用了流式加密的方式,使用对称密钥加密日志数据,存储到本地。同时在日志上传时,使用非对称密钥对对称密钥Key做加密上传,防止密钥Key被破解,从而在网络层保证日志安全。
日志分散
针对日志分散的情况,为了保证日志全面,需要做本地聚合存储。Logan采用了自研的日志协议,对于不同种类的日志都会按照Logan日志协议进行格式化处理,存储到本地。当需要上报的时候进行集中上报,通过Logan日志协议进行反解,还原出不同日志的原本面貌。同时Logan后台提供了聚合展示的能力,全面展示日志内容,根据协议综合各种日志进行分析,使用时间轴等方式展示不同种日志的重要信息,使得开发者只需要通过Logan平台就可以查询到某一段时间App到底产生了哪些日志,可以快速复现问题场景,定位问题并处理。
关于Logan平台是如何展示日志的,下文会再进行说明。
架构
首先,看一下Logan的整体架构图:
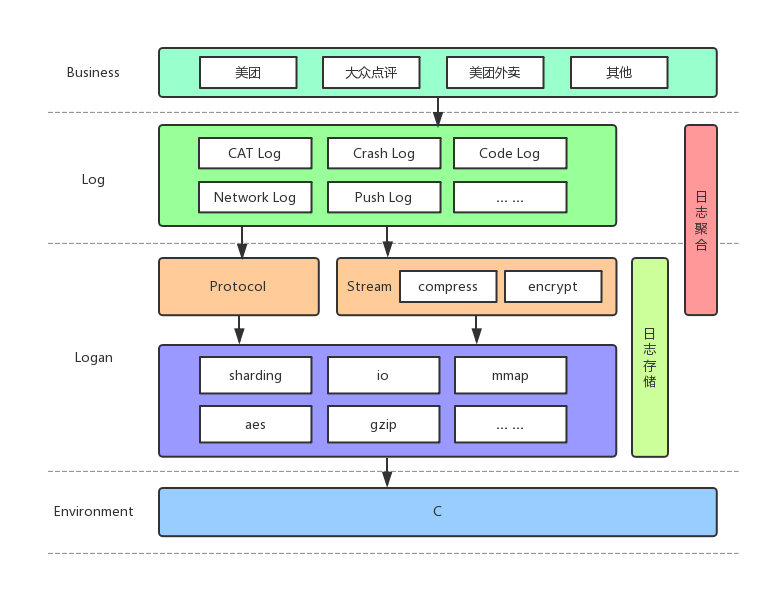
Logan自研的日志协议解决了日志本地聚合存储的问题,采用先压缩再加密的顺序,使用流式的加密和压缩,避免了CPU峰值,同时减少了CPU使用。跨平台C库提供了日志协议数据的格式化处理,针对大日志的分片处理,引入了MMAP机制解决了日志丢失问题,使用AES进行日志加密确保日志安全性,并且提供了主动上报接口。Logan核心逻辑都在C层完成,提供了跨平台支持的能力,在解决痛点问题的同时,也大大提升了性能。
日志分片
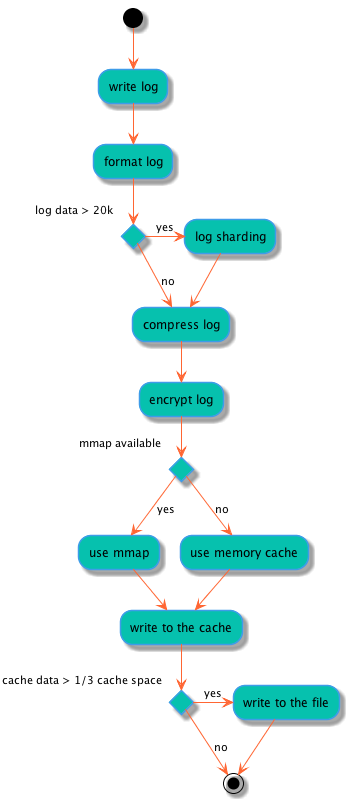
Logan作为日志底层库,需要考虑上层传入日志过大的情况。针对这样的场景,Logan会做日志分片处理。以20k大小做分片,每个切片按照Logan的协议进行存储,上报到Logan后台的时候再做反解合并,恢复日志本来的面貌。
那么Logan是如何进行日志写入的呢?下图为Logan写日志的流程:
性能
为了检测Logan的性能优化效果,我们专门写了测试程序进行对比,读取16000行的日志文本,间隔3ms,依次调用写日志函数。
首先对比Java实现和C实现的内存状况:
Java:

C:

可以看出Java实现写日志,GC频繁,而C实现并不会出现这种情况,因为它不会占用Java的堆内存。那么再对比一下Java实现和C实现的CPU使用情况:
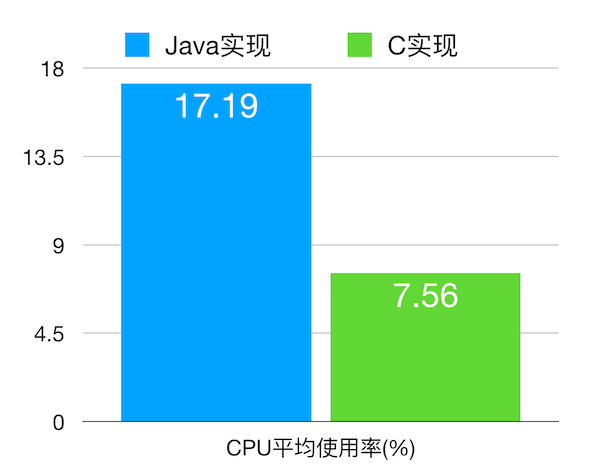
C实现没有频繁的GC,同时采用流式的压缩和加密避免了集中压缩加密可能产生的CPU峰值,所以CPU平均使用率会降低,如上图所示。
特色功能
日志回捞
开发者可能都会遇到类似的场景:某个用户手机上装了App,出现了崩溃或者其它问题,日志还没上报或者上报过程中被网络劫持发生日志丢失,导致有些问题一直查不清原因,或者没法及时定位到问题,影响处理进程。依托集团PushSDK强大的推送能力,Logan可以确保用户的本地日志在发出捞取指令后及时上传。通过网络类型和日志大小上限选择,可以为用户最大可能的节省移动流量。
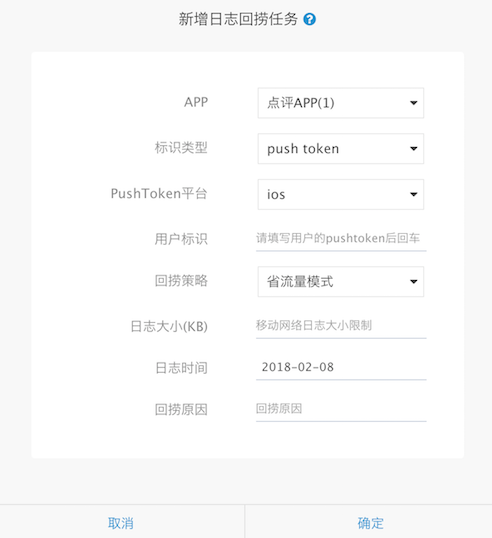
回馈机制可以确保捞取日志任务的进度得到实时展现。

日志回捞平台有着严格的审核机制,确保开发者不会侵犯用户隐私,只关注问题场景。
主动上报
Logan日志回捞,依赖于Push透传。客户端被唤醒接收Push消息,受到一些条件影响:
- Android想要后台唤醒App,需要确保Push进程在后台存活;
- iOS想要后台唤醒APP,需要确保用户开启后台刷新开关;
- 网络环境太差,Android上Push长连建立不成功。
如果无法唤醒App,只有在用户再次进入App时,Push通道建立后才能收到推送消息,以上是导致Logan日志回捞会有延迟或收不到的根本原因,从分析可以看出,Logan系统回捞的最大瓶颈在于Push系统。那么能否抛开Push系统得到Logan日志呢?先来看一下使用日志回捞方式的典型场景:
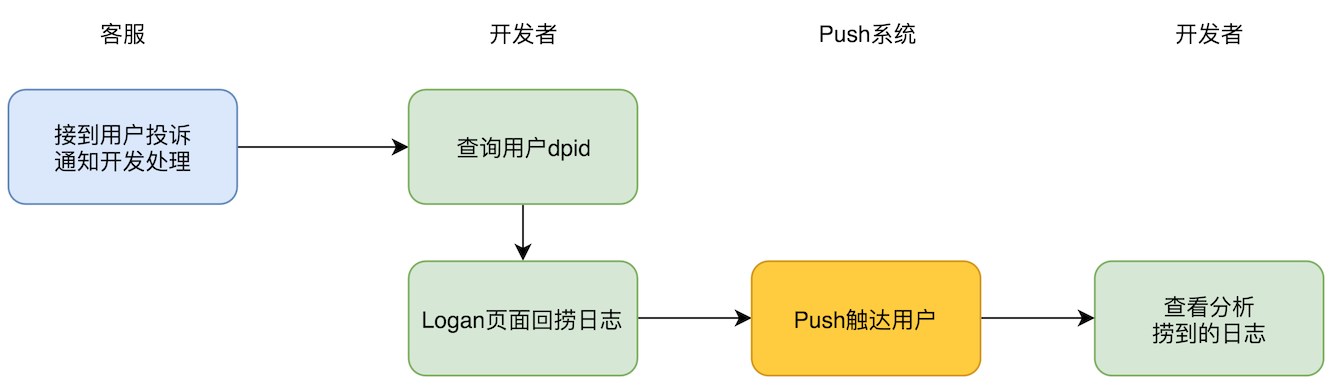
其中最大的障碍在于Push触达用户。那么主动上报的设计思路是怎样的呢?
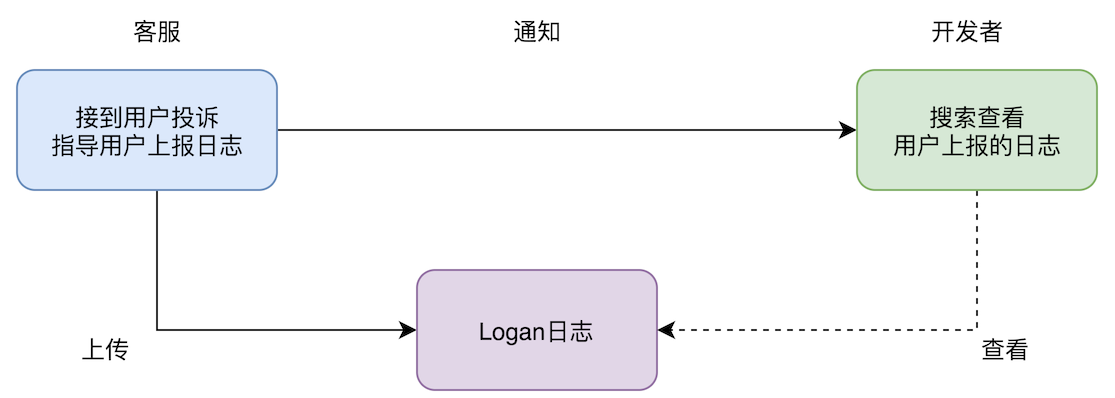
通过在App中主动调用上报接口,用户直接上报日志的方式,称之为Logan的主动上报。主动上报的优势非常明显,跳过了Push系统,让用户在需要的时候主动上报Logan日志,开发者再也不用为不能及时捞到日志而烦恼,在用户投诉之前就已经拿到日志,便于更高效地分析解决问题。
线上效果
Logan基础日志库自2017年9月上线以来,运行非常稳定,大大提高了集团移动开发工程师分析日志、定位线上问题的效率。
Logan平台时间轴日志展示:
Logan日志聚合详情展示:
作为基础日志库,Logan目前已经接入了集团众多日志系统:
- CAT端到端日志
- 埋点日志
- 用户行为日志
- 代码级日志
- 网络内部日志
- Push日志
- Crash崩溃日志
现在,Logan已经接入美团、大众点评、美团外卖、猫眼等众多App,日志种类也更加丰富。
展望未来
H5 SDK
目前,Logan只有移动端版本,支持Android/iOS系统,暂不支持H5的日志上报。对于纯JS开发的页面来说,同样有日志分散、问题场景复现困难等痛点,也迫切需要类似的日志底层库。我们计划统一H5和Native的日志底层库,包括日志协议、聚合等,Logan的H5 SDK也在筹备中。
日志分析
Logan平台的日志展示方式,我们还在探索中。未来计划对日志做初步的机器分析与处理,能针对某些关键路径给出一些分析结果,让开发者更专注于业务问题的定位与分析,同时希望分析出用户的行为是否存在风险、恶意请求等。
思考题
本文给大家讲述了美团点评移动端底层基础日志库Logan的设计、架构与特色,Logan在解决了许多问题的同时,也会带来新的问题。日志文件不能无限大,目前Logan日志文件最大限制为10M,遇到大于10M的情况,应该如何处理最佳?是丢掉前面的日志,还是丢掉追加的日志,还是做分片处理呢?这是一个值得深思的问题。
MCI:移动持续集成在大众点评的实践
一、背景
美团是全球最大的互联网+生活服务平台,为3.2亿活跃用户和500多万的优质商户提供一个连接线上与线下的电子商务服务。秉承“帮大家吃得更好,生活更好”的使命,我们的业务覆盖了超过200个品类和2800个城区县网络,在餐饮、外卖、酒店旅游、丽人、家庭、休闲娱乐等领域具有领先的市场地位。
随着各业务的蓬勃发展,大众点评移动研发团队从当初各自为战的“小作坊”已经发展成为可以协同作战的、拥有千人规模的“正规军”。我们的移动项目架构为了适应业务发展也发生了天翻地覆的变化,这对移动持续集成提出更高的要求,而整个移动研发团队也迎来了新的机遇和挑战。
二、问题与挑战
当前移动客户端的组件库超过600个,多个移动项目的代码量达到百万行级别,每天有几百次的发版集成需求。保证近千名移动研发人员顺利进行开发和集成,这是我们部门的重要使命。但是,前进的道路从来都不是平坦的,在通向目标的大道上,我们还面临着很多问题与挑战,主要包括以下几个方面:
项目依赖复杂
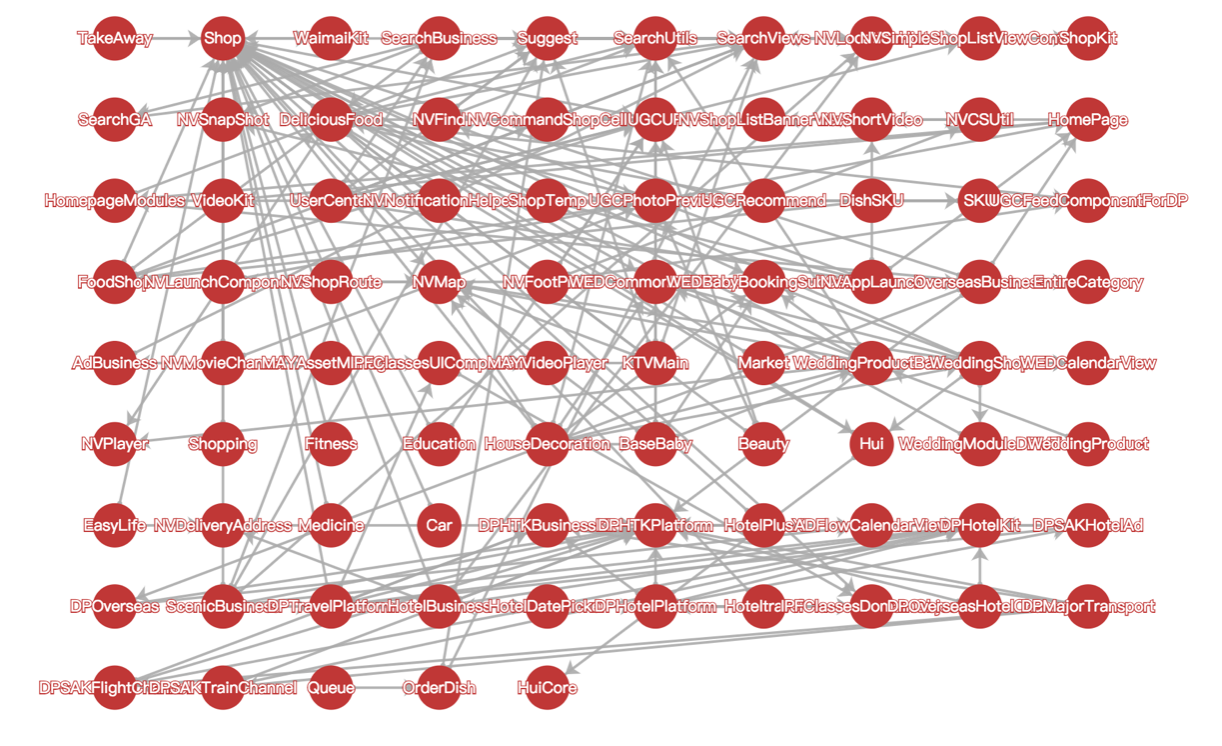
上图仅仅展示了我们移动项目中一小部分组件间的依赖关系,可以想象一下,这600多个组件之间的依赖关系,就如同一个城市复杂的道路交通网让人眼花缭乱。这种组件间错综复杂的依赖关系也必然会导致两个严重的问题,第一,如果某个业务需要修改代码,极有可能会影响到其它业务,牵一发而动全身,进而会让很多研发同学工作时战战兢兢,做项目更加畏首畏尾;第二,管理这些组件间繁琐的依赖关系也是一件令人头疼的事情,现在平均每个组件的依赖数有70多个,最多的甚至达到了270多个,如果依靠人工来维护这些依赖关系,难如登天。
研发流程琐碎
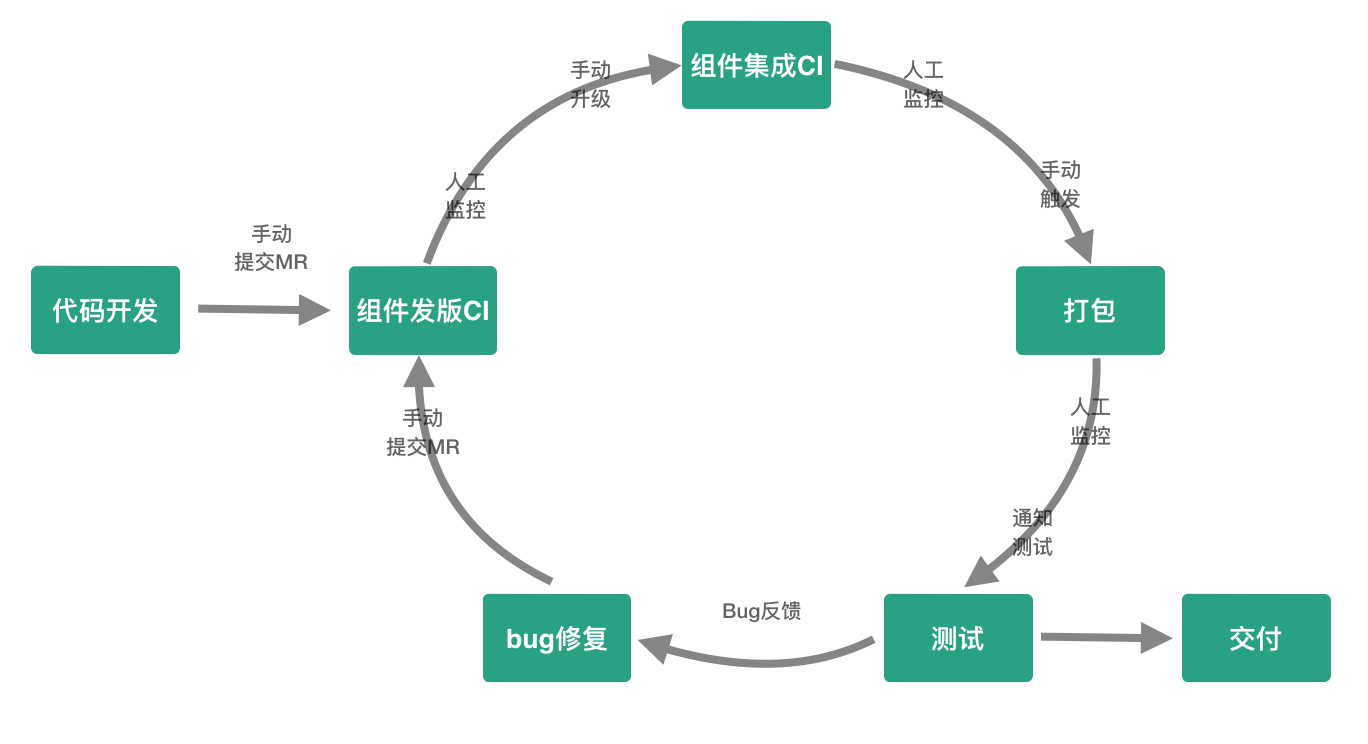
移动研发要完成一个完整功能需求,除了代码开发以外,需要经历组件发版、组件集成、打包、测试。如果测试发现Bug需要进行修复,然后再次经历组件发版、组件集成、打包、测试,直到测试通过交付产品。研发同学在整个过程中需要手动提交MR、手动升级组件、手动触发打包以及人工实时监控流程的状态,如此研发会被频繁打断来跟踪处理过程的衔接,势必严重影响开发专注度,降低研发生产力。
构建速度慢
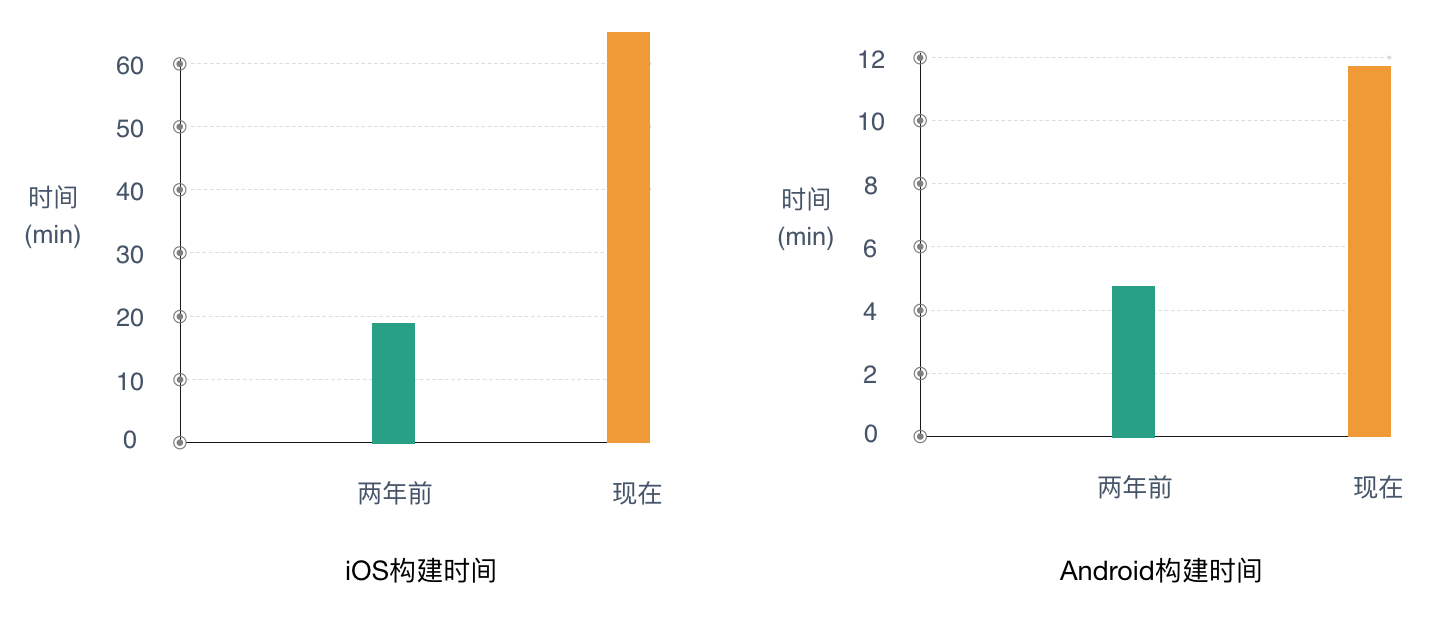
目前大众点评的iOS项目构建时间,从两年前的20分钟已经增长到现在的60分钟以上,Android项目也从5分钟增长到11分钟,移动项目构建时间的增长,已经严重影响了移动端开发集成的效率。而且随着业务的快速扩张,项目代码还在持续不断的增长。为了适应业务的高速发展,寻求行之有效的方法来加快移动项目的构建速度,已经变得刻不容缓。
App质量保证
评价App的性能质量指标有很多,例如:CPU使用率、内存占用、流量消耗、响应时间、线上Crash率、包体等等。其中线上Crash直接影响着用户体验,当用户使用App时如果发生闪退,他们很有可能会给出“一星”差评;而包体大小是影响新用户下载App的重要因素,包体过大用户很有可能会对你的App失去兴趣。因此,降低App线上Crash率以及控制App包体大小是每个移动研发都要追求的重要目标。
项目依赖复杂、研发流程琐碎、构建速度慢、App质量保证是每个移动项目在团队、业务发展壮大过程中都会遇到的问题,本文将根据大众点评移动端多年来积累的实践经验,一步步阐述我们是如何在实战中解决这些问题的。
三、MCI架构
MCI(Mobile continuous integration)是大众点评移动端团队多年来实践总结出来的一套行之有效的架构体系。它能实际解决移动项目中依赖复杂、研发流程琐碎、构建速度慢的问题,同时接入MCI架构体系的移动项目能真正有效实现App质量的提升。
MCI完整架构体系如下图所示:
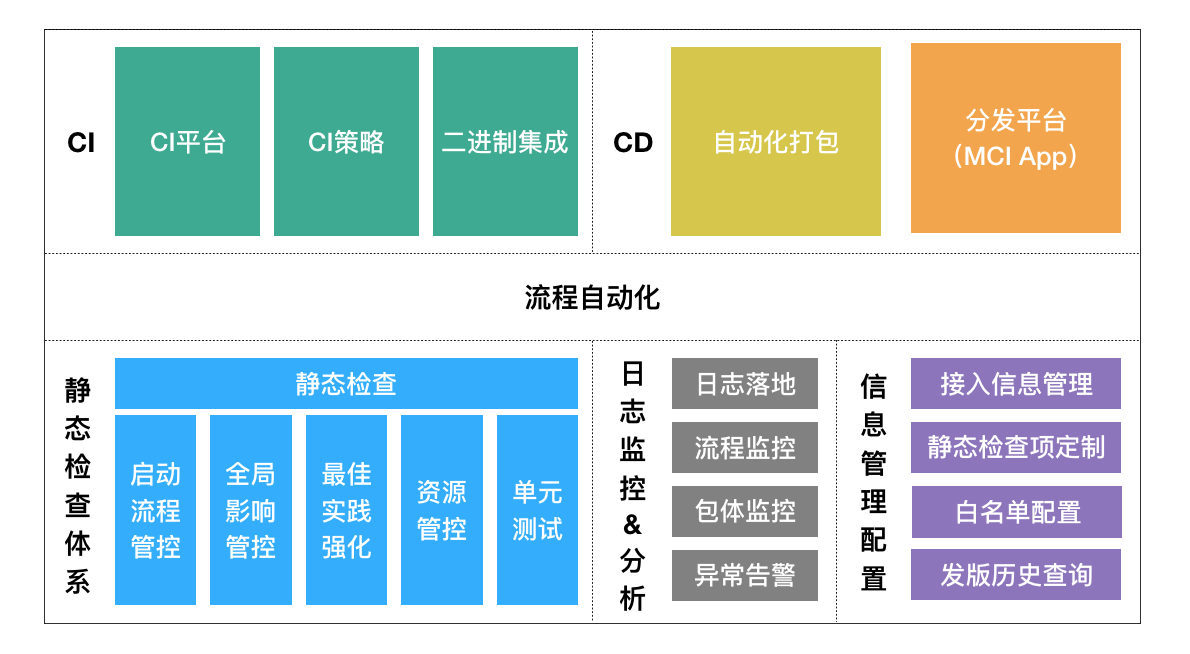
MCI架构体系包含移动CI平台、流程自动化建设、静态检查体系、日志监控&分析、信息管理配置,另外MCI还采取二进制集成等措施来提升MCI的构建速度。
构建移动CI平台
我们通过构建移动CI平台,来保证移动研发在项目依赖极其复杂的情况下,也能互不影响完成业务研发集成;其次我们设计了合理的CI策略,来帮助移动研发人员走出令人望而生畏的依赖关系管理的“泥潭”。
流程自动化建设
在构建移动CI平台的基础上,我们对MCI流程进行自动化建设来解决研发流程琐碎问题,从而解放移动研发生产力。
提升构建速度
在CI平台保证集成正确性的情况下,我们通过依赖扁平化以及优化集成方式等措施来提升MCI的构建速度,进一步提升研发效率。
静态检查体系
我们建立一套完整自研的静态检查体系,针对移动项目的特点,MCI上线全方位的静态检查来促进App质量的提升。
日志监控&分析
我们对MCI体系的完整流程进行日志落地,方便问题的追溯与排查,同时通过数据分析来进一步优化MCI的流程以及监控移动App项目的健康状况。
信息管理配置
最后,为了方便管理接入MCI的移动项目,我们建设了统一的项目信息管理配置平台。
接下来,我们将依次详细探讨MCI架构体系是如何一步步建立,进而解决我们面临的各种问题。
四、构建移动CI平台
4.1 搭建移动CI平台
我们对目前业内流行的CI系统,如:Travis CI、 CircleCI、Jenkins、Gitlab CI调研后,针对移动项目的特点,综合考虑代码安全性、可扩展性及页面可操作性,最终选择基于Gitlab CI搭建移动持续集成平台,当然我们也使用Jenkins做一些辅助性的工作。MCI体系的CI核心架构如下图所示:
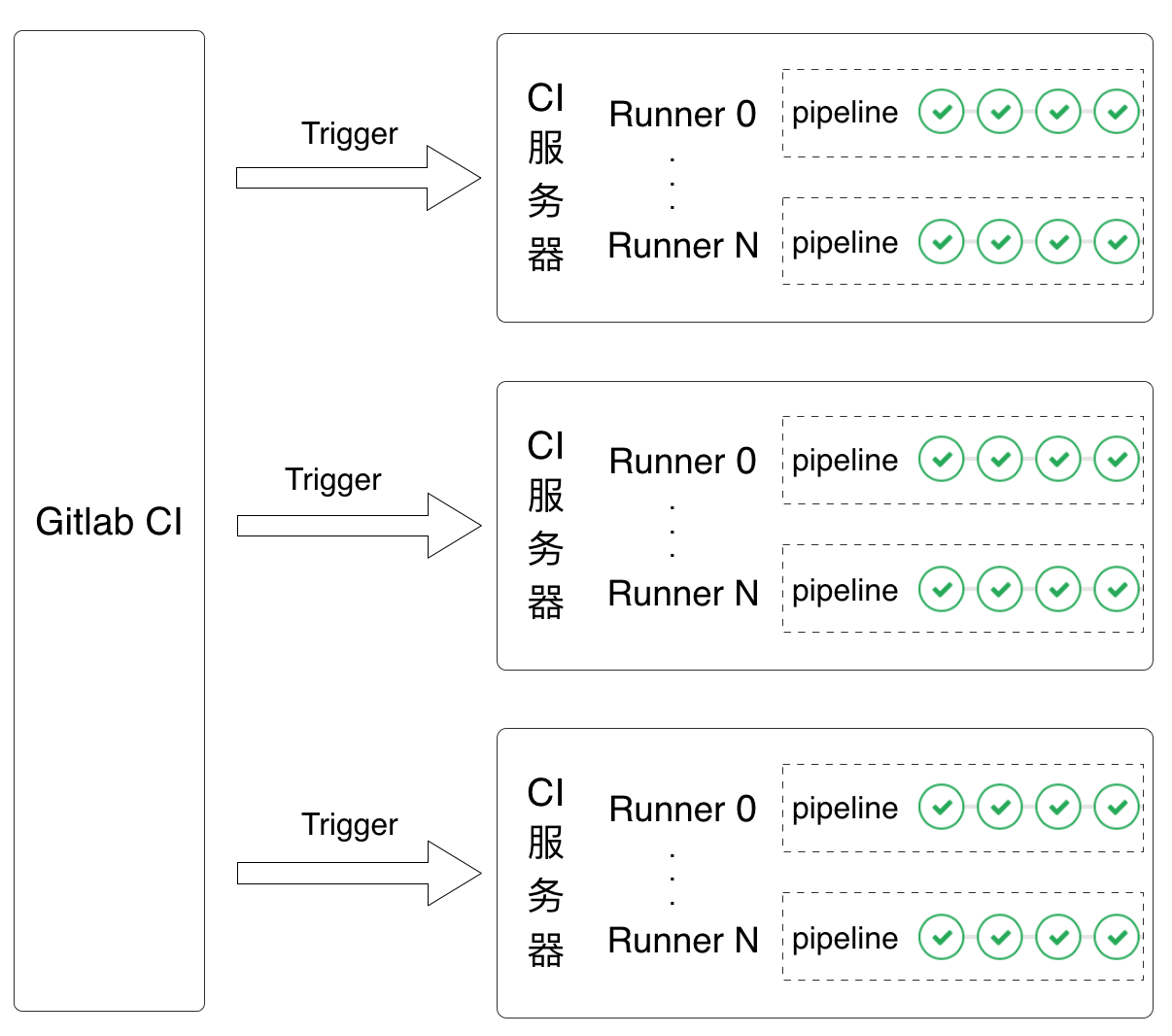
名词解释:
- Gitlab CI:Gitlab CI是GitLab Continuous Integration(Gitlab持续集成)的简称。
- Runner:Runner是Gitlab CI提供注册CI服务器的接口。
- Pipeline:可以理解为流水线,包含CI不同阶段的不同任务。
- Trigger:触发器,Push代码或者提交Merge Request等操作会触发相应的触发器以进入下一流程。
该架构的优势是可扩展性强、可定制、支持并发。首先CI服务器可以任意扩展,除了专用的服务器可以作为CI服务器,普通个人PC机也可以作为CI服务器(缺点是性能比服务器差,任务执行时间较长);其次每个集成任务的Pipeline是支持可定制的,托管在MCI的集成项目可以根据自身需求定制与之匹配的Pipeline;最后,每个集成项目的任务执行是可并发的,因此各业务线间可以互不干扰的进行组件代码集成。
4.2 CI流程设计
一次完整的组件集成流程包含两个阶段:组件库发版和向目标App工程集成。如下图所示:
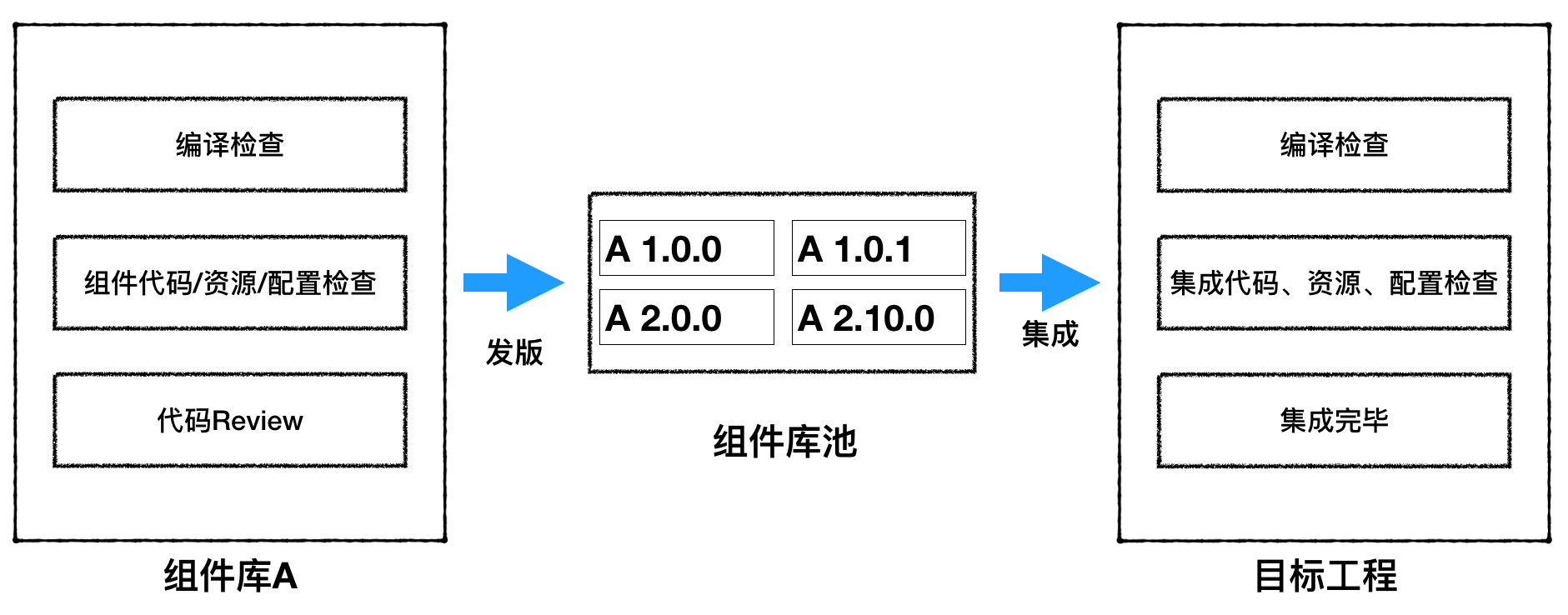
第一阶段,在日常功能开发完毕后,研发提PR到指定分支,在对代码进行Review、组件库编译及静态检查无误后,自动发版进入组件池中。所有进入组件池中的组件均可以在不同App项目中复用。
第二阶段,研发根据需要将组件合入指定App工程。组件A本身的正确性已经在第一阶段的组件库发版中验证,第二阶段是检查组件A的改变是否对目标App中原有依赖它的其它组件造成影响。所以首先需要分析组件A被目标App中哪些组件所依赖,目标App工程按照各自的准入标准,对合入的组件库进行编译和静态分析,待检查无误后,最终合入发布分支。
通过组件发版和集成两阶段的CI流程,组件将被正确集成到目标项目中。而对于存在问题的组件则会阻挡在项目之外,因此不会影响其它业务的正常开发和发版集成,各业务研发流程独立可控。
4.3 设计合理的CI策略
组件的发版和集成能否通过CI检查,取决于组件当前的依赖以及组件本身是否与目标项目兼容。移动研发需要对组件当前依赖有足够的了解才能顺利完成发版集成,为了减小组件依赖管理的复杂度,我们设计了合理的发版集成策略来帮助移动研发走出繁琐的版本依赖管理的困境。
组件集成策略
每个组件都有自己的依赖项,不同组件可能会依赖同一个组件,组件向目标项目集成过程中会面临如下一些问题:
- 版本集成冲突:组件在集成过程中某个依赖项与目标项目中现有依赖的版本号存在冲突。
- App测试包不稳定:组件依赖项的版本发生变化导致在不同时刻打出不同依赖项的App测试包。
频繁的版本集成冲突会导致业务协同开发集成效率低下,App测试包的不稳定性会给研发追踪问题带来极大的困扰。问题的根源在于目标项目使用每个组件的依赖项来进行集成。因此我们通过在集成项目中显示指定组件版本号以及禁止动态依赖的方式,保证了App测试包的稳定性和可靠性,同时也解决了组件版本集成冲突问题。
组件发版策略
组件向组件池发版也一样会涉及依赖项的管理,简单粗暴的方法是指定所有依赖项的版本号,这样做的好处是直观明了,但研发需要对不同版本依赖项的功能有足够的了解。正如组件集成策略中所述,集成项目中每个组件的版本都是显示指定并且唯一确定的,组件中指定依赖项的版本号在集成项目中并不起作用。所以我们在组件发版时采用自动依赖组件池中最新版本的方式。这样设计的好处在于:
- 避免移动研发对版本依赖关系的处理。
- 给基础组件的变更迭代提供了强有力的推动机制。
当基础组件库的接口和设计发生较大变化时,可以强有力的推动业务层组件做相应适配,保证了在高度解耦的项目架构下保持高度的敏捷性。但这种能力不能滥用,需要根据业务迭代周期合理安排,并做好提前通知动员工作。
五、流程自动化建设
研发流程琐碎的主要原因是研发需要人工参与持续集成中每一步过程,一旦我们把移动研发从持续集成过程中解放出来,自然就能提高研发生产力。我们通过项目集成发布流程自动化以及优化测试包分发来优化MCI流程。
项目集成流程托管
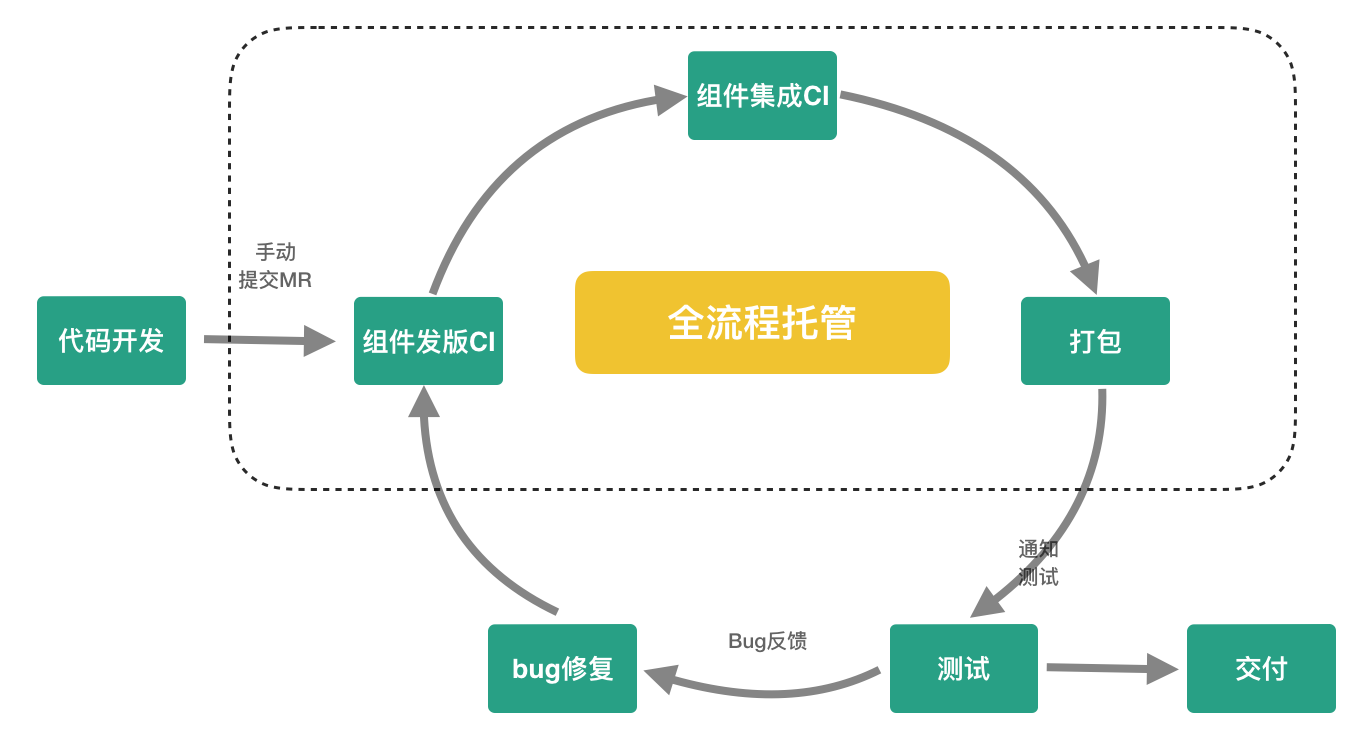
研发流程中的组件发版、组件集成与App打包都是持续集成中的标准化流程,我们通过流程托管工具来完成这几个步骤的自动衔接,研发同学只需关注代码开发与Bug修复。
流程托管工具实现方案如下:
- 自动化流程执行:通过托管队列实现任务自动化顺序执行,webhook实现流程状态的监听。
- 关键节点通知:在关键性节点流程执行成功后发送通知,让研发对流程状态了然于胸。
- 流程异常通知:一旦持续集成流程执行异常,例如项目编译失败、静态检查没通过等,第一时间通知研发及时处理。
打包发布流程托管
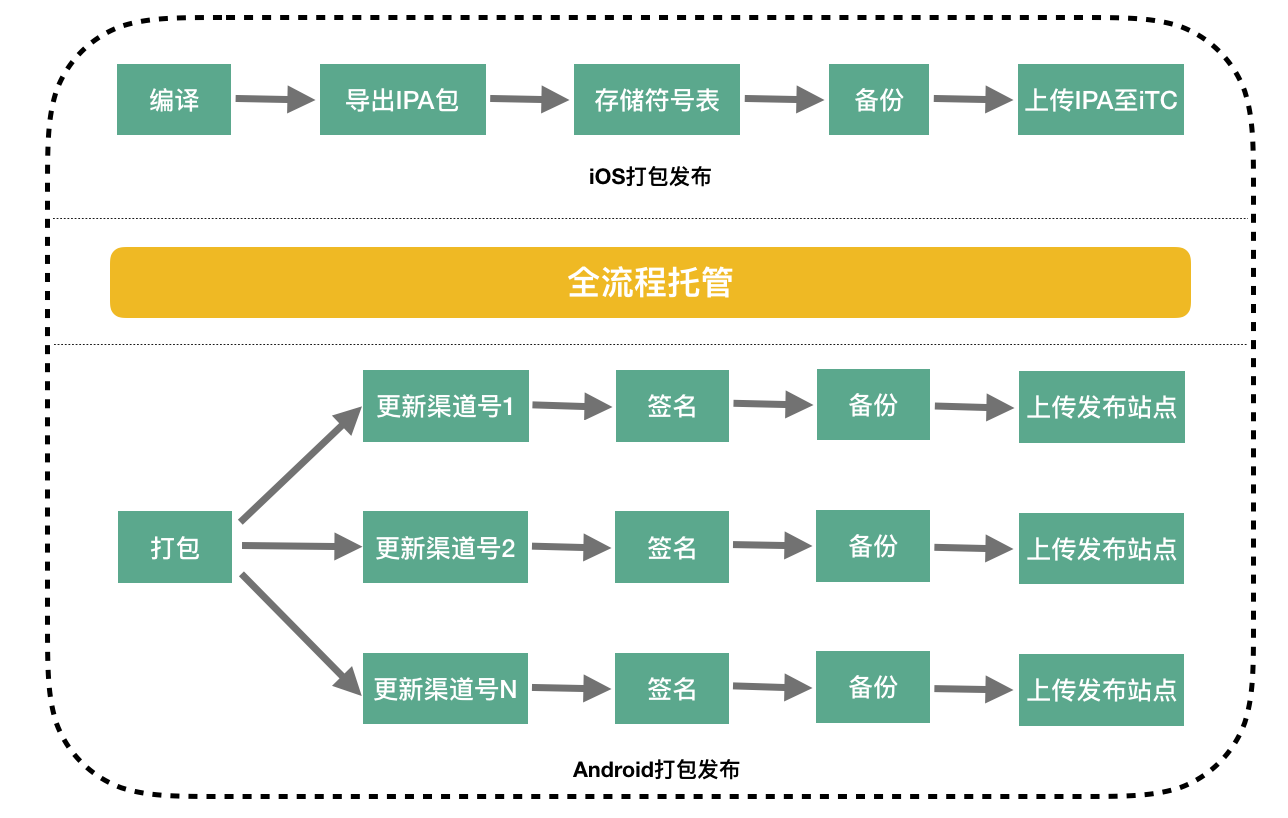
无论iOS还是Android,在发布App包到市场前都需要做一系列处理,例如iOS需要导出ipa包进行备份,保存符号表来解析线上Crash,以及上传ipa包到iTC(iTunes Connect);而Android除了包备份,保存Mapping文件解析线上Crash外,还要发布App包到不同的渠道,整个打包发布流程更加复杂繁琐。
在没有MCI流程托管以前,每到App发布日,研发同学就如临大敌守在打包机器前,披荆斩棘,过五关斩六将,直到所有App包被“运送”到指定地点,搞得十分疲惫。如同项目集成流程托管一样,我们把整个打包发布流程做了全流程托管,无人值守的自动打包发布方式解放了研发同学,研发同学再也不用每次都披星戴月,早出晚归,跪键盘了(捂脸)。
包分发流程建设

对于QA和研发而言,上面的场景是否似曾相识。Bug是QA与研发之间沟通的桥梁,但由于缺乏统一的包管理和分发,这种模糊的沟通导致难以快速定位和追溯发生问题的包。为了减少QA和研发之间的无效沟通以及优化包分发流程,我们亟需一个平台来统一管理分发公司内部的App包,于是MCI App应运而生。
MCI App提供如下功能:
- 查看下载安装不同类型不同版本的App。
- 查看App包的基础信息(打包者、打包耗时、包版本、代码提交commit点等)。
- 查看App包当前版本集成的所有组件库信息。
- 查看App包体占用情况。
- 查询App发版时间计划。
- 分享安装App包下载链接。
未来MCI App还会支持查询项目集成状态以及App发布提醒、问题反馈,整合移动研发全流程。
六、提升构建速度
移动项目在构建过程中最为耗时的两个步骤分别为组件依赖计算和工程编译。
组件依赖计算
组件依赖计算是根据项目中指定的集成组件计算出所有相关的依赖项以及依赖版本,当项目中集成组件较多的时候,递归计算依赖项以及依赖版本是一件非常耗时的操作,特别是还要处理相关的依赖冲突。
工程编译
工程编译时间是跟项目工程的代码量成正比的,集团业务在快速发展,代码量也在快速的膨胀。
为了提升项目构建速度,我们通过依赖扁平化的方法来彻底去掉组件依赖计算耗时,以及通过优化项目集成方式的手段来减少工程编译时间。
依赖扁平化
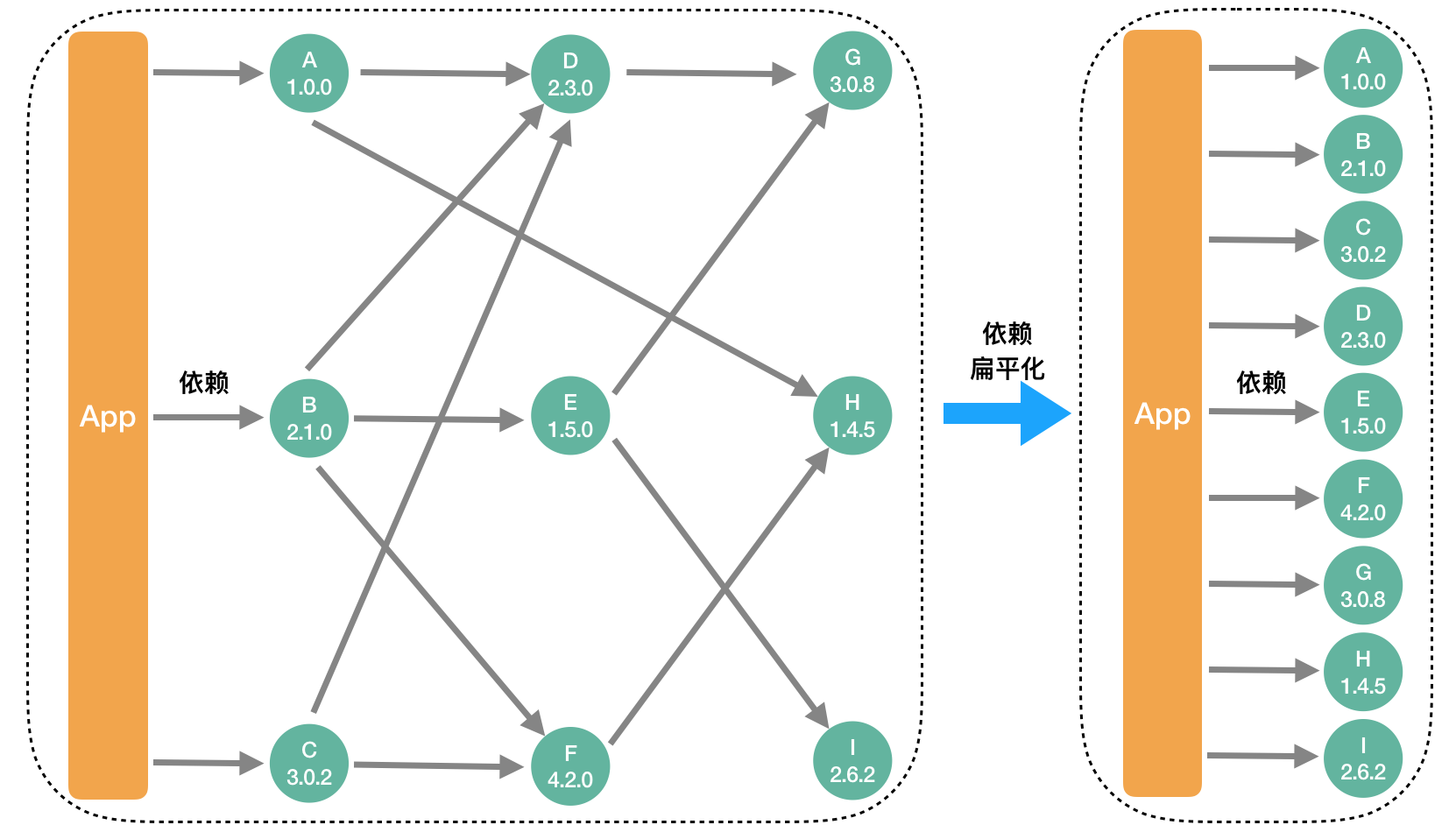
依赖扁平化的核心思想是事先把依赖项以及依赖版本号进行显示指定,这样通过固定依赖项以及依赖版本就彻底去掉了组件依赖计算的耗时,极大的提高了项目构建速度。与此同时,依赖扁平化还额外带来了下面的好处:
- 减轻研发依赖关系维护的负担。
- App项目更加稳定,不会因为依赖项的自动升级出现问题。
优化集成方式
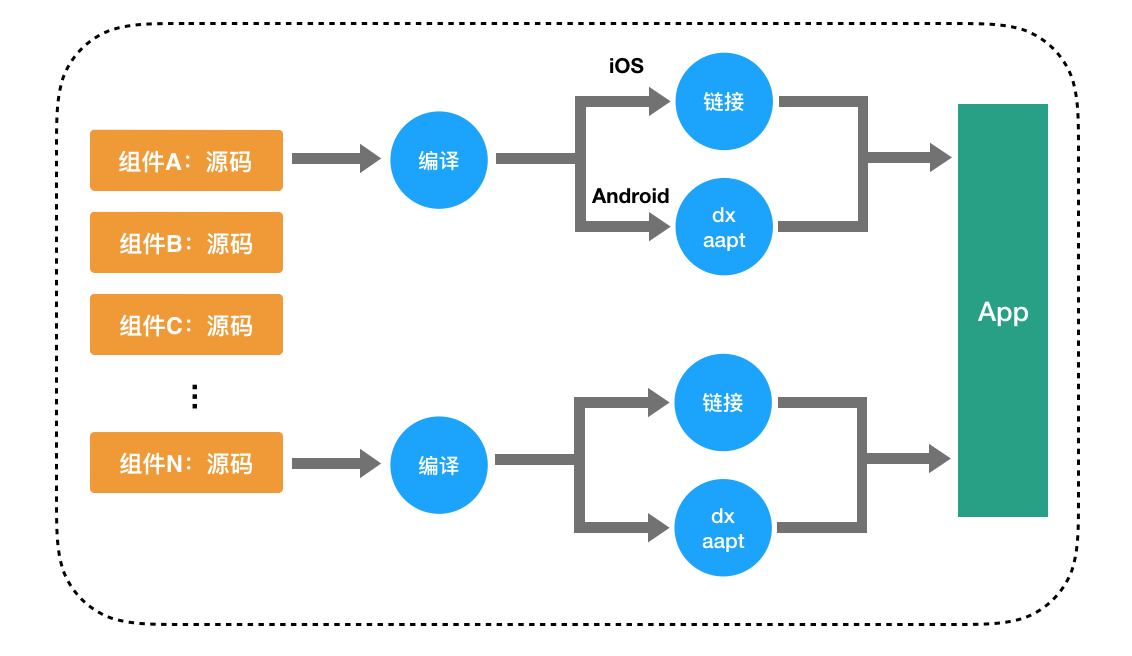
通常组件代码都是以源码方式集成到目标工程,这种集成方式的最大缺点是编译速度慢,对于上百万行代码的App,如果采用源码集成的方式,工程编译时间将超过40分钟甚至更长,这个时间,显然会令人崩溃。
使用源码集成
使用二进制集成
实际上组件代码还可以通过二进制的方式集成到目标工程:
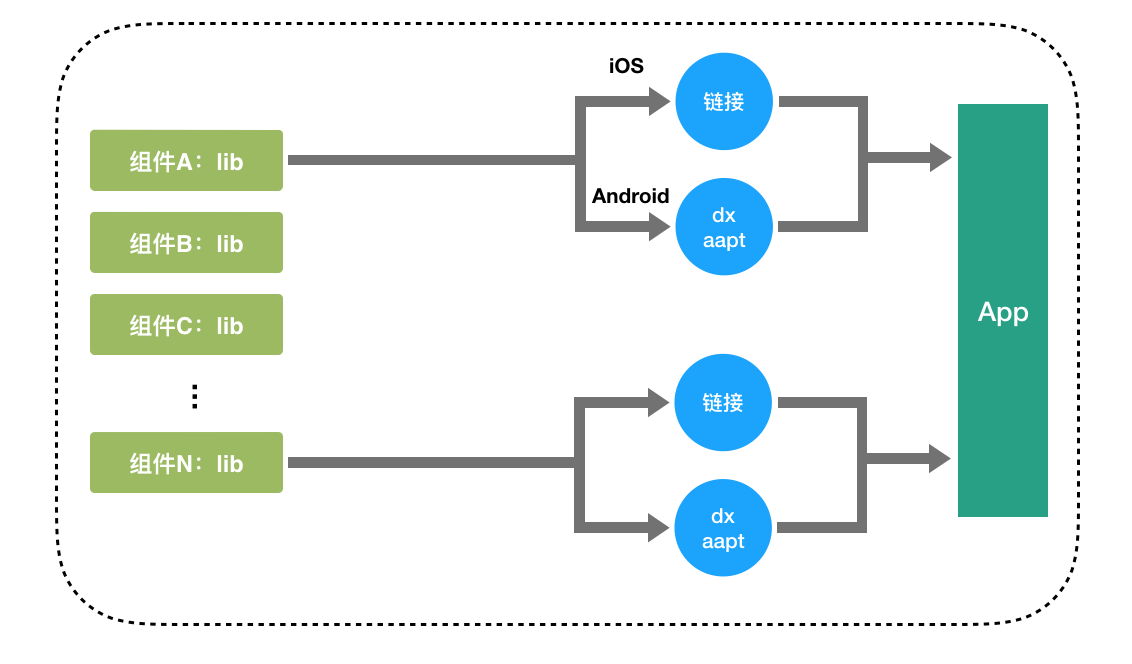
相比源码方式集成,组件的二进制包都是预先编译好的,在集成过程中只需要进行链接无需编译,因此二进制集成的方式可以大幅提升项目编译速度。
二进制集成优化
为了进一步提高二进制集成效率,我们还做了几件小事:
(1)多线程下载
尽管二进制集成的方式能减少工程编译时间,但二进制包还是得从远端下载到CI服务器上。我们修改了默认单线程下载的策略,通过多线程下载二进制包提升下载效率。
(2)二进制包缓存
研发在MCI上触发不同的集成任务,这些集成任务间除了升级的组件,其它使用的组件二进制包大部分是相同的,因此我们在CI服务器上对组件二进制包进行缓存以便不同任务间进行共享,进一步提升项目构建速度。
二进制集成成果
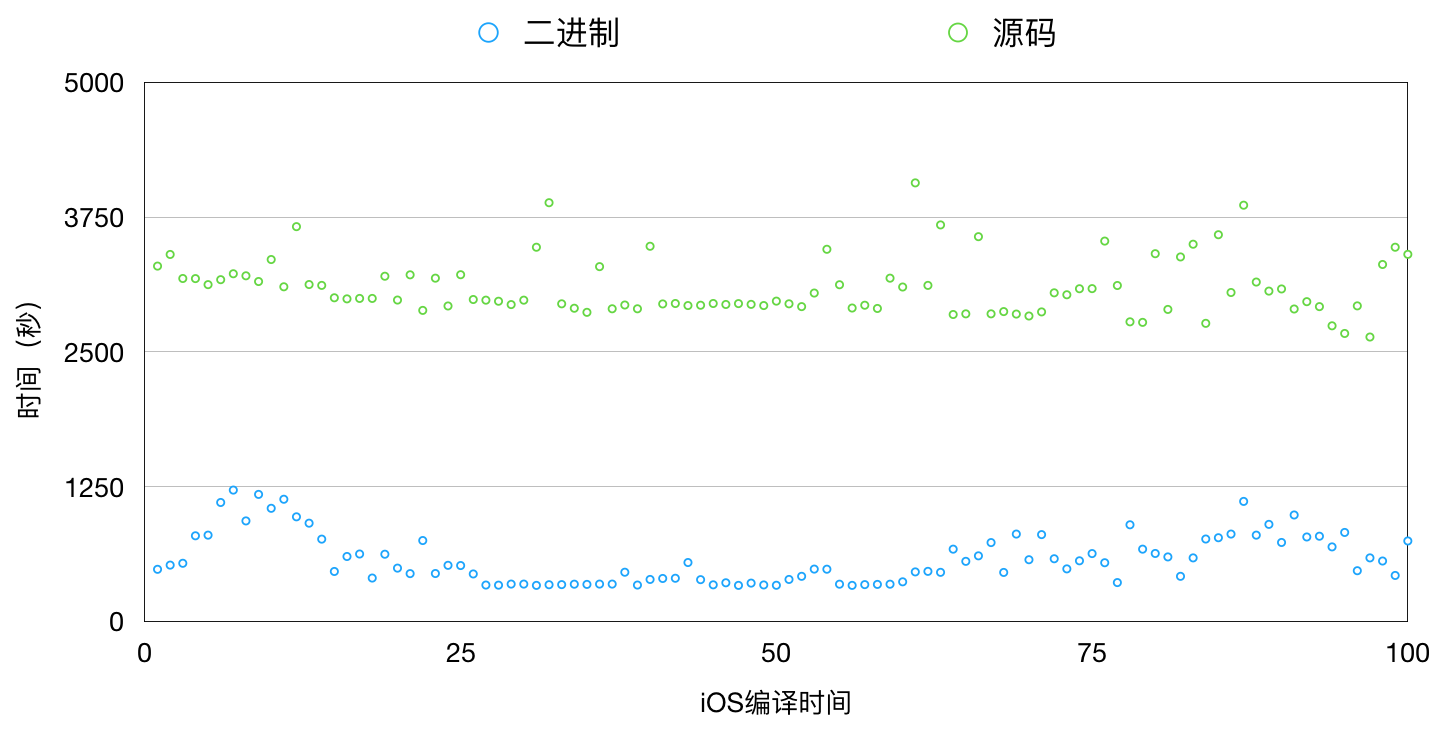
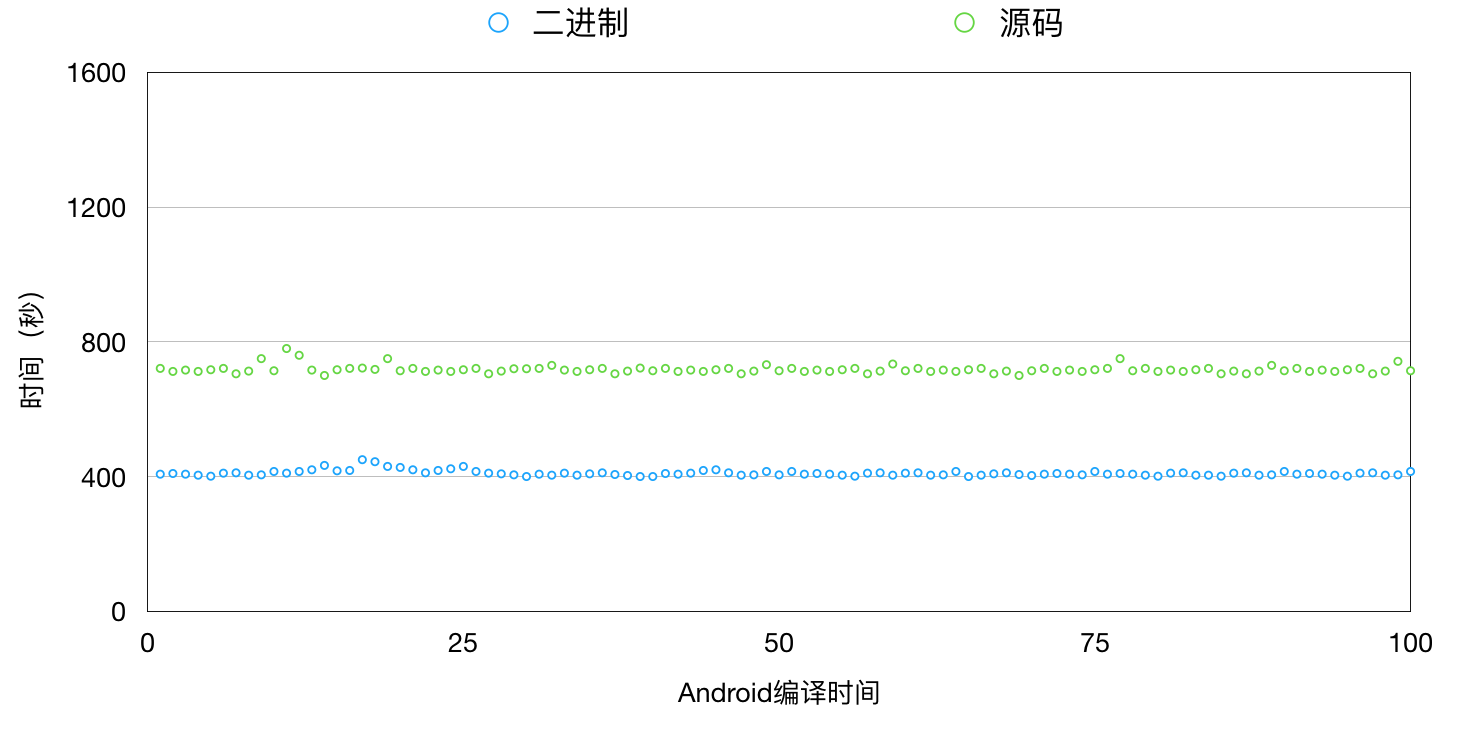
我们在MCI中采用二进制集成并且经过一系列优化后,iOS项目工程的编译时间比原来减少60%,Android项目也比原来减少接近50%,极大地提升了项目构建效率。
七、静态检查体系
除了完成日常需求开发,提高代码质量是每个研发的必修课。如果每一位移动研发在平时开发中能严格遵守移动编程规范与最佳实践,那很多线上问题完全可以提前避免。事实上仅仅依靠研发自觉性,难以长期有效的执行,我们需要把这些移动编程规范和最佳实践切实落地成为静态检查强制执行,才能有效的将问题扼杀在摇篮之中。
静态检查基础设施
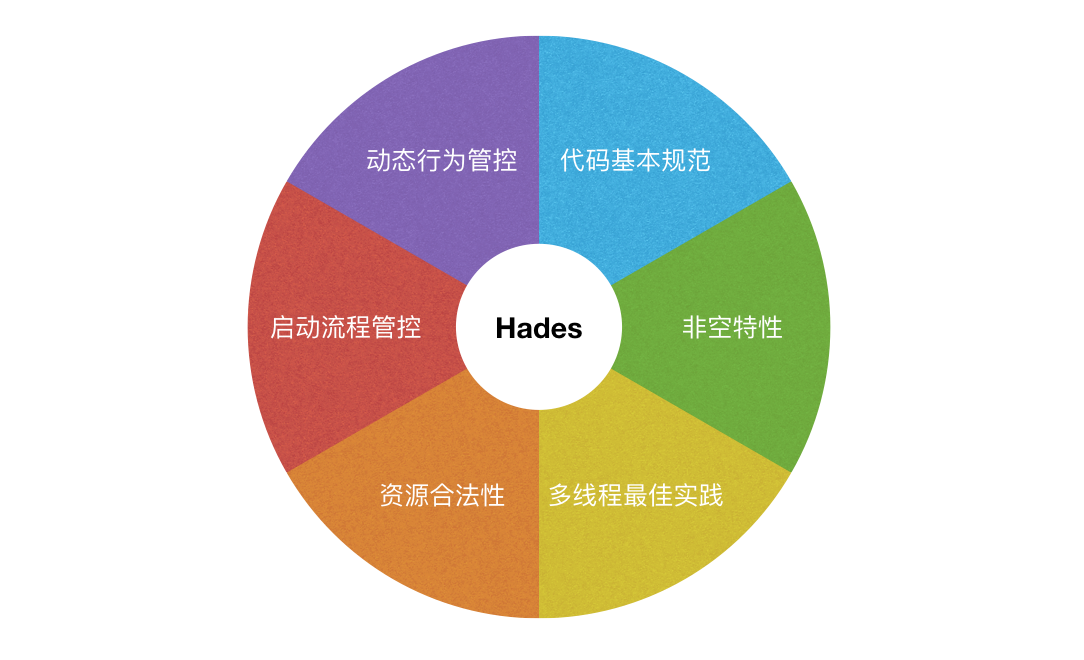
静态检查最简单的方式是文本匹配,这种方式检查逻辑简单,但存在局限性。比如编写的静态检查代码维护困难,再者文本匹配能力有限对一些复杂逻辑的处理无能为力。现有针对Objective-C和Java的静态分析工具也有不少,常见的有:OCLint、FindBugs、CheckStyle等等,但这些工具定制门槛较高。为了降低静态检查接入成本,我们自主研发了一个适应MCI需求的静态分析框架–Hades。
Hades的特点:
- 完全代码语义理解
- 具备全局分析能力
- 支持增量分析
- 接入成本低
Hades的核心思想是对源码生成的AST(Abstract Syntax Tree)进行结构化数据的语义表达,在此基础上我们就可以建立一系列静态分析工具和服务。作为一个静态分析框架,Hades并不局限于Lint工具的制作,我们也希望通过这种结构化的语义表达来对代码有更深层次的理解。因此,我们可以借助文档型数据库(如:CouchDB、MongoDB等)建立项目代码的语义模型数据库,这样我们能够通过JS的Map-Reduce建立视图从而快速检索我们需要查找的内容。关于Hades的技术实现原理我们将在后续的技术Blog中进行详细阐述,敬请期待。
MCI静态检查现状
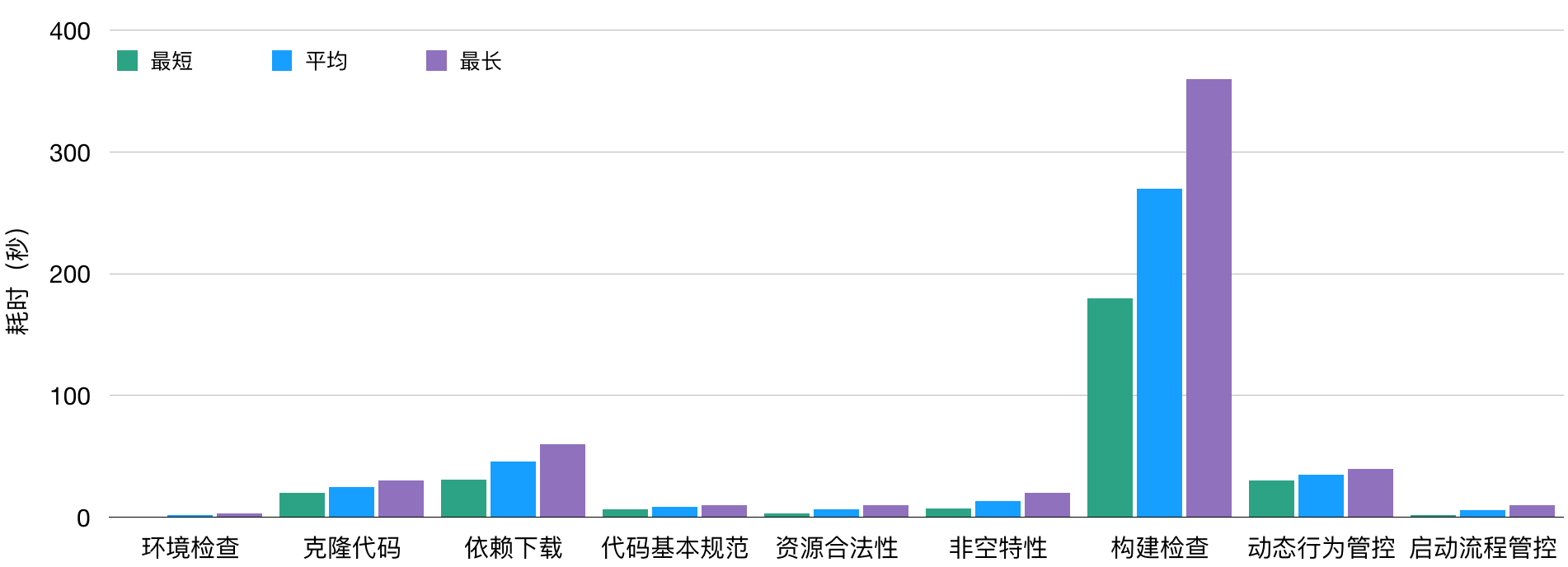
目前MCI已经上线了覆盖代码基本规范、非空特性、多线程最佳实践、资源合法性、启动流程管控、动态行为管控等20多项静态检查,这些静态检查切实有效地促进了App代码质量的提高。
八、日志监控&分析
MCI作为大众点评移动端持续集成的重要平台,稳定高效是要达成的第一目标,日志监控是推动MCI走向稳定高效的重要手段。我们对MCI全流程的日志进行落地,方便问题追溯与排查,以下是部分线上监控项。
流程时间监控分析
通过监控分析MCI流程中每一步的执行时间,我们可以进行针对性的优化以提高集成速度。
异常流程监控分析
我们会对异常流程进行监控并且通知流程发起者,同时我们会对失败次数较多的Job分析原因。一部分CI环境或者网络问题MCI可以自动解决,而其它由于代码错误引起的异常MCI会引导移动研发进行问题的排查与解决。
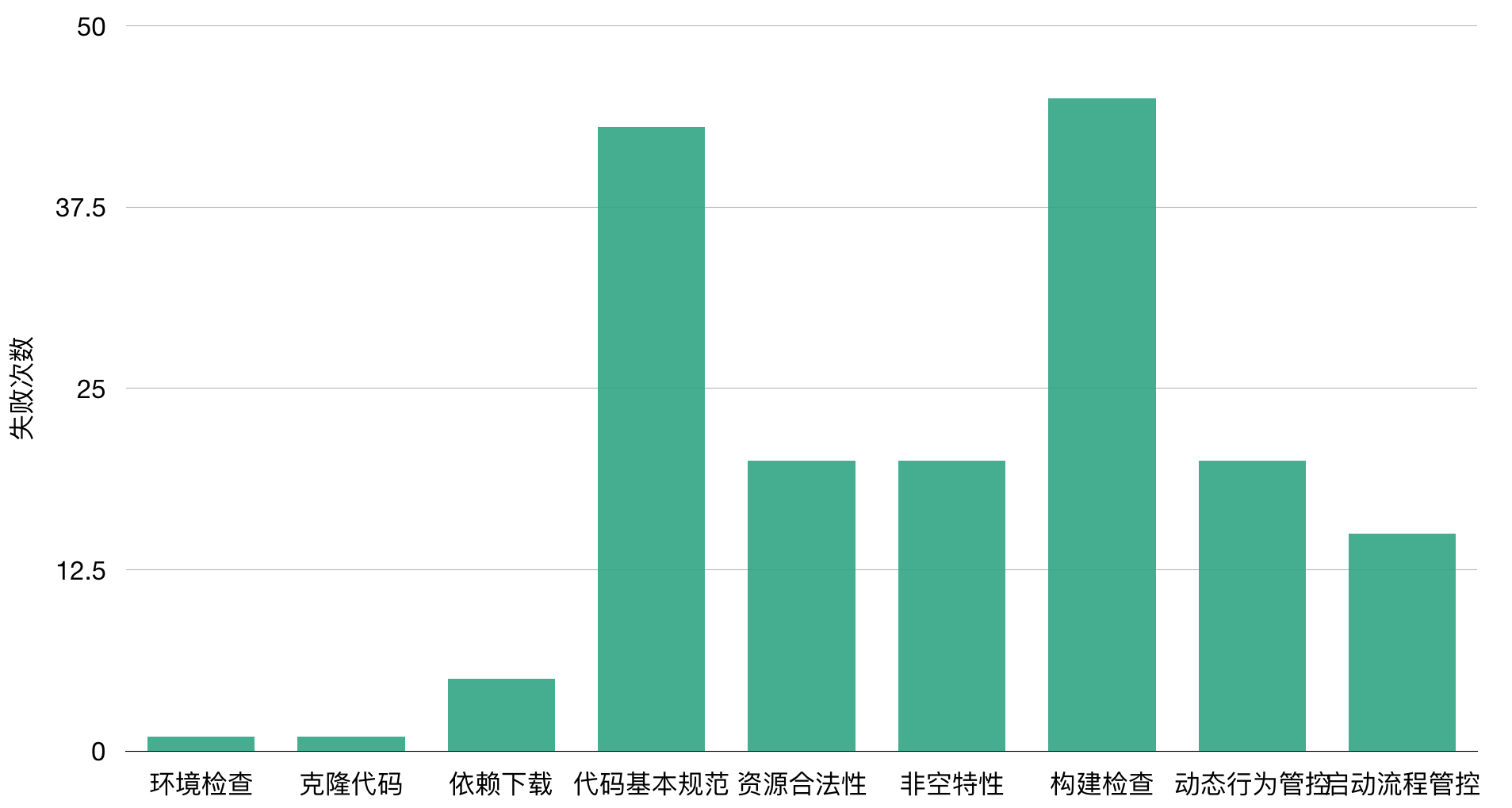
包体监控分析
我们对包体总大小、可执行文件以及图片进行全方面的监控,包体变化的趋势一目了然,对于包体的异常变化我们可以第一时间感知。
除此之外,我们还对MCI集成成功率、二进制覆盖率等方面做了监控,做到对MCI全流程了然于胸,让MCI稳定高效的运行。
九、信息管理配置
目前MCI平台已经接入公司多个移动项目,为了接入MCI的项目进行统一方便的信息管理,我们建设了MCI信息管理平台——摩卡(Mocha)。Mocha平台的功能包含项目信息管理、配置静态检查项以及组件发版集成查询。
项目信息管理
Mocha平台负责注册接入MCI项目的基本信息,包含项目地址、项目负责人等,同时对各个项目的成员进行权限管理。
配置静态检查项
MCI支持不同项目自定义不同的静态检查项,在Mocha平台上可以完成项目所需静态检查项的定制,同时支持静态检查白名单的配置审核。
组件发版集成查询
Mocha平台支持组件历史发版集成的记录查询,方便问题的排查与追溯。
作为移动集成项目的可视化配置系统,Mocha平台是MCI的一个重要补充。它使得移动项目接入MCI变得简单快捷,未来Mocha平台还会加入更多的配置项。
十、总结与展望
本文从大众点评移动项目业务复杂度出发,详细介绍了构建稳定高效的移动持续集成系统的思路与最佳实践方案,解决项目依赖复杂所带来的问题,通过依赖扁平化以及二进制集成提升构建速度。在此基础上,通过自研的静态检查基础设施Hades降低静态检查准入的门槛,帮助提升App质量;最后MCI提供的全流程托管能力能显著提高移动研发生产力。
目前MCI为iOS、Android原生代码的项目集成已经提供了相当完善的支持。此外,MCI还支持Picasso项目的持续集成,Picasso是大众点评自研的高性能跨平台动态化框架,专注于横跨iOS、Android、Web、小程序四端的动态化UI构建。当然移动端原生项目的持续集成和动态化项目的持续集成有共通也有很多不同之处。未来MCI将在移动工程化领域进一步探索,为移动端业务蓬勃发展保驾护航。
美团外卖Android Crash治理之路
Crash率是衡量一个App好坏的重要指标之一,如果你忽略了它的存在,它就会愈演愈烈,最后造成大量用户的流失,进而给公司带来无法估量的损失。本文讲述美团外卖Android客户端团队在将App的Crash率从千分之三做到万分之二过程中所做的大量实践工作,抛砖引玉,希望能够为其他团队提供一些经验和启发。
面临的挑战和成果
面对用户使用频率高,外卖业务增长快,Android碎片化严重这些问题,美团外卖Android App如何持续的降低Crash率,是一项极具挑战的事情。通过团队的全力全策,美团外卖Android App的平均Crash率从千分之三降到了万分之二,最优值万一左右(Crash率统计方式:Crash次数/DAU)。
美团外卖自2013年创建以来,业务就以指数级的速度发展。美团外卖承载的业务,从单一的餐饮业务,发展到餐饮、超市、生鲜、果蔬、药品、鲜花、蛋糕、跑腿等十多个大品类业务。目前美团外卖日完成订单量已突破2000万,成为美团点评最重要的业务之一。美团外卖客户端所承载的业务模块越来越多,产品复杂度越来越高,团队开发人员日益增加,这些都给App降低Crash率带来了巨大的挑战。
Crash的治理实践
对于Crash的治理,我们尽量遵守以下三点原则:
- 由点到面。一个Crash发生了,我们不能只针对这个Crash的去解决,而要去考虑这一类Crash怎么去解决和预防。只有这样才能使得这一类Crash真正被解决。
- 异常不能随便吃掉。随意的使用try-catch,只会增加业务的分支和隐蔽真正的问题,要了解Crash的本质原因,根据本质原因去解决。catch的分支,更要根据业务场景去兜底,保证后续的流程正常。
- 预防胜于治理。当Crash发生的时候,损失已经造成了,我们再怎么治理也只是减少损失。尽可能的提前预防Crash的发生,可以将Crash消灭在萌芽阶段。
常规的Crash治理
常规Crash发生的原因主要是由于开发人员编写代码不小心导致的。解决这类Crash需要由点到面,根据Crash引发的原因和业务本身,统一集中解决。常见的Crash类型包括:空节点、角标越界、类型转换异常、实体对象没有序列化、数字转换异常、Activity或Service找不到等。这类Crash是App中最为常见的Crash,也是最容易反复出现的。在获取Crash堆栈信息后,解决这类Crash一般比较简单,更多考虑的应该是如何避免。下面介绍两个我们治理的量比较大的Crash。
NullPointerException
NullPointerException是我们遇到最频繁的,造成这种Crash一般有两种情况:
- 对象本身没有进行初始化就进行操作。
- 对象已经初始化过,但是被回收或者手动置为null,然后对其进行操作。
针对第一种情况导致的原因有很多,可能是开发人员的失误、API返回数据解析异常、进程被杀死后静态变量没初始化导致,我们可以做的有:
- 对可能为空的对象做判空处理。
- 养成使用@NonNull和@Nullable注解的习惯。
- 尽量不使用静态变量,万不得已使用SharedPreferences来存储。
- 考虑使用Kotlin语言。
针对第二种情况大部分是由于Activity/Fragment销毁或被移除后,在Message、Runnable、网络等回调中执行了一些代码导致的,我们可以做的有:
- Message、Runnable回调时,判断Activity/Fragment是否销毁或被移除;加try-catch保护;Activity/Fragment销毁时移除所有已发送的Runnable。
- 封装LifecycleMessage/Runnable基础组件,并自定义Lint检查,提示使用封装好的基础组件。
- 在BaseActivity、BaseFragment的onDestory()里把当前Activity所发的所有请求取消掉。
IndexOutOfBoundsException
这类Crash常见于对ListView的操作和多线程下对容器的操作。
针对ListView中造成的IndexOutOfBoundsException,经常是因为外部也持有了Adapter里数据的引用(如在Adapter的构造函数里直接赋值),这时如果外部引用对数据更改了,但没有及时调用notifyDataSetChanged(),则有可能造成Crash,对此我们封装了一个BaseAdapter,数据统一由Adapter自己维护通知, 同时也极大的避免了The content of the adapter has changed but ListView did not receive a notification,这两类Crash目前得到了统一的解决。
另外,很多容器是线程不安全的,所以如果在多线程下对其操作就容易引发IndexOutOfBoundsException。常用的如JDK里的ArrayList和Android里的SparseArray、ArrayMap,同时也要注意有一些类的内部实现也是用的线程不安全的容器,如Bundle里用的就是ArrayMap。
系统级Crash治理
众所周知,Android的机型众多,碎片化严重,各个硬件厂商可能会定制自己的ROM,更改系统方法,导致特定机型的崩溃。发现这类Crash,主要靠云测平台配合自动化测试,以及线上监控,这种情况下的Crash堆栈信息很难直接定位问题。下面是常见的解决思路:
- 尝试找到造成Crash的可疑代码,看是否有特异的API或者调用方式不当导致的,尝试修改代码逻辑来进行规避。
- 通过Hook来解决,Hook分为Java Hook和Native Hook。Java Hook主要靠反射或者动态代理来更改相应API的行为,需要尝试找到可以Hook的点,一般Hook的点多为静态变量,同时需要注意Android不同版本的API,类名、方法名和成员变量名都可能不一样,所以要做好兼容工作;Native Hook原理上是用更改后方法把旧方法在内存地址上进行替换,需要考虑到Dalvik和ART的差异;相对来说Native Hook的兼容性更差一点,所以用Native Hook的时候需要配合降级策略。
- 如果通过前两种方式都无法解决的话,我们只能尝试反编译ROM,寻找解决的办法。
我们举一个定制系统ROM导致Crash的例子,根据Crash平台统计数据发现该Crash只发生在vivo V3Max这类机型上,Crash堆栈如下:
java.lang.RuntimeException: An error occured while executing doInBackground()
at android.os.AsyncTask$3.done(AsyncTask.java:304)
at java.util.concurrent.FutureTask.finishCompletion(FutureTask.java:355)
at java.util.concurrent.FutureTask.setException(FutureTask.java:222)
at java.util.concurrent.FutureTask.run(FutureTask.java:242)
at android.os.AsyncTask$SerialExecutor$1.run(AsyncTask.java:231)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1112)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:587)
at java.lang.Thread.run(Thread.java:818)
Caused by: java.lang.NullPointerException: Attempt to invoke interface method 'int java.util.List.size()' on a null object reference
at android.widget.AbsListView$UpdateBottomFlagTask.isSuperFloatViewServiceRunning(AbsListView.java:7689)
at android.widget.AbsListView$UpdateBottomFlagTask.doInBackground(AbsListView.java:7665)
at android.os.AsyncTask$2.call(AsyncTask.java:292)
at java.util.concurrent.FutureTask.run(FutureTask.java:237)
... 4 more
我们发现原生系统上对应系统版本的AbsListView里并没有UpdateBottomFlagTask类,因此可以断定是vivo该版本定制的ROM修改了系统的实现。我们在定位这个Crash的可疑点无果后决定通过Hook的方式解决,通过源码发现AsyncTask$SerialExecutor是静态变量,是一个很好的Hook的点,通过反射添加try-catch解决。因为修改的是final对象所以需要先反射修改accessFlags,需要注意ART和Dalvik下对应的Class不同,代码如下:
public static void setFinalStatic(Field field, Object newValue) throws Exception {
field.setAccessible(true);
Field artField = Field.class.getDeclaredField("artField");
artField.setAccessible(true);
Object artFieldValue = artField.get(field);
Field accessFlagsFiled = artFieldValue.getClass().getDeclaredField("accessFlags");
accessFlagsFiled.setAccessible(true);
accessFlagsFiled.setInt(artFieldValue, field.getModifiers() & ~Modifier.FINAL);
field.set(null, newValue);
}
private void initVivoV3MaxCrashHander() {
if (!isVivoV3()) {
return;
}
try {
setFinalStatic(AsyncTask.class.getDeclaredField("SERIAL_EXECUTOR"), new SafeSerialExecutor());
Field defaultfield = AsyncTask.class.getDeclaredField("sDefaultExecutor");
defaultfield.setAccessible(true);
defaultfield.set(null, AsyncTask.SERIAL_EXECUTOR);
} catch (Exception e) {
L.e(e);
}
}
美团外卖App用上述方法解决了对应的Crash,但是美团App里的外卖频道因为平台的限制无法通过这种方式,于是我们尝试反编译ROM。 Android ROM编译时会将framework、app、bin等目录打入system.img中,system.img是Android系统中用来存放系统文件的镜像 (image),文件格式一般为yaffs2或ext。但Android 5.0开始支持dm-verity后,system.img不再提供,而是提供了三个文件system.new.dat,system.patch.dat,system.transfer.list,因此我们首先需要通过上述的三个文件得到system.img。但我们将vivo ROM解压后发现厂商将system.new.dat进行了分片,如下图所示:
经过对system.transfer.list中的信息和system.new.dat 1 2 3 … 文件大小对比研究,发现一些共同点,system.transfer.list中的每一个block数*4KB 与对应的分片文件的大小大致相同,故大胆猜测,vivo ROM对system.patch.dat分片也只是单纯的按block先后顺序进行了分片处理。所以我们只需要在转化img前将这些分片文件合成一个system.patch.dat文件就可以了。最后根据system.img的文件系统格式进行解包,拿到framework目录,其中有framework.jar和boot.oat等文件,因为Android4.4之后引入了ART虚拟机,会预先把system/framework中的一些jar包转换为oat格式,所以我们还需要将对应的oat文件通过ota2dex将其解包获得dex文件,之后通过dex2jar和jd-gui查看源码。
OOM
OOM是OutOfMemoryError的简称,在常见的Crash疑难排行榜上,OOM绝对可以名列前茅并且经久不衰。因为它发生时的Crash堆栈信息往往不是导致问题的根本原因,而只是压死骆驼的最后一根稻草。
导致OOM的原因大部分如下:
- 内存泄漏,大量无用对象没有被及时回收导致后续申请内存失败。
- 大内存对象过多,最常见的大对象就是Bitmap,几个大图同时加载很容易触发OOM。
内存泄漏
内存泄漏指系统未能及时释放已经不再使用的内存对象,一般是由错误的程序代码逻辑引起的。在Android平台上,最常见也是最严重的内存泄漏就是Activity对象泄漏。Activity承载了App的整个界面功能,Activity的泄漏同时也意味着它持有的大量资源对象都无法被回收,极其容易造成OOM。
常见的可能会造成Activity泄漏的原因有:
- 匿名内部类实现Handler处理消息,可能导致隐式持有的Activity对象无法回收。
- Activity和Context对象被混淆和滥用,在许多只需要Application Context而不需要使用Activity对象的地方使用了Activity对象,比如注册各类Receiver、计算屏幕密度等等。
- View对象处理不当,使用Activity的LayoutInflater创建的View自身持有的Context对象其实就是Activity,这点经常被忽略,在自己实现View重用等场景下也会导致Activity泄漏。
对于Activity泄漏,目前已经有了一个非常好用的检测工具:LeakCanary,它可以自动检测到所有Activity的泄漏情况,并且在发生泄漏时给出十分友好的界面提示,同时为了防止开发人员的疏漏,我们也会将其上报到服务器,统一检查解决。另外我们可以在debug下使用StrictMode来检查Activity的泄露、Closeable对象没有被关闭等问题。
大对象
在Android平台上,我们分析任一应用的内存信息,几乎都可以得出同样的结论:占用内存最多的对象大都是Bitmap对象。随着手机屏幕尺寸越来越大,屏幕分辨率也越来越高,1080p和更高的2k屏已经占了大半份额,为了达到更好的视觉效果,我们往往需要使用大量高清图片,同时也为OOM埋下了祸根。
对于图片内存优化,我们有几个常用的思路:
- 尽量使用成熟的图片库,比如Glide,图片库会提供很多通用方面的保障,减少不必要的人为失误。
- 根据实际需要,也就是View尺寸来加载图片,可以在分辨率较低的机型上尽可能少地占用内存。除了常用的BitmapFactory.Options#inSampleSize和Glide提供的BitmapRequestBuilder#override之外,我们的图片CDN服务器也支持图片的实时缩放,可以在服务端进行图片缩放处理,从而减轻客户端的内存压力。 分析App内存的详细情况是解决问题的第一步,我们需要对App运行时到底占用了多少内存、哪些类型的对象有多少个有大致了解,并根据实际情况做出预测,这样才能在分析时做到有的放矢。Android Studio也提供了非常好用的Memory Profiler,堆转储和分配跟踪器功能可以帮我们迅速定位问题。
AOP增强辅助
AOP是面向切面编程的简称,在Android的Gradle插件1.5.0中新增了Transform API之后,编译时修改字节码来实现AOP也因为有了官方支持而变得非常方便。
在一些特定情况下,可以通过AOP的方式自动处理未捕获的异常:
- 抛异常的方法非常明确,调用方式比较固定。
- 异常处理方式比较统一。
- 和业务逻辑无关,即自动处理异常后不会影响正常的业务逻辑。典型的例子有读取Intent Extras参数、读取SharedPreferences、解析颜色字符串值和显示隐藏Window等等。
这类问题的解决原理大致相同,我们以Intent Extras为例详细介绍一下。读取Intent Extras的问题在于我们非常常用的方法 Intent#getStringExtra 在代码逻辑出错或者恶意攻击的情况下可能会抛出ClassNotFoundException异常,而我们平时在写代码时又不太可能给所有调用都加上try-catch语句,于是一个更安全的Intent工具类应运而生,理论上只要所有人都使用这个工具类来访问Intent Extras参数就可以防止此类型的Crash。但是面对庞大的旧代码仓库和诸多的业务部门,修改现有代码需要极大成本,还有更多的外部依赖SDK基本不可能使用我们自己的工具类,此时就需要AOP大展身手了。
我们专门制作了一个Gradle插件,只需要配置一下参数就可以将某个特定方法的调用替换成另一个方法:
WaimaiBytecodeManipulator {
replacements(
"android/content/Intent.getIntExtra(Ljava/lang/String;I)I=com/waimai/IntentUtil.getInt(Landroid/content/Intent;Ljava/lang/String;I)I",
"android/content/Intent.getStringExtra(Ljava/lang/String;)Ljava/lang/String;=com/waimai/IntentUtil.getString(Landroid/content/Intent;Ljava/lang/String;)Ljava/lang/String;",
"android/content/Intent.getBooleanExtra(Ljava/lang/String;Z)Z=com/waimai/IntentUtil.getBoolean(Landroid/content/Intent;Ljava/lang/String;Z)Z",
...)
}
}
上面的配置就可以将App代码(包括第三方库)里所有的Intent.getXXXExtra调用替换成IntentUtil类中的安全版实现。当然,并不是所有的异常都只需要catch住就万事大吉,如果真的有逻辑错误肯定需要在开发和测试阶段及时暴露出来,所以在IntentUtil中会对App的运行环境做判断,Debug下会将异常直接抛出,开发同学可以根据Crash堆栈分析问题,Release环境下则在捕获到异常时返回对应的默认值然后将异常上报到服务器。
依赖库的问题
Android App经常会依赖很多AAR, 每个AAR可能有多个版本,打包时Gradle会根据规则确定使用的最终版本号(默认选择最高版本或者强制指定的版本),而其他版本的AAR将被丢弃。如果互相依赖的AAR中有不兼容的版本,存在的问题在打包时是不能发现的,只有在相关代码执行时才会出现,会造成NoClassDefFoundError、NoSuchFieldError、NoSuchMethodError等异常。如图所示,order和store两个业务库都依赖了platform.aar,一个是1.0版本,一个是2.0版本,默认最终打进APK的只有platform 2.0版本,这时如果order库里用到的platform库里的某个类或者方法在2.0版本中被删除了,运行时就可能发生异常,虽然SDK在升级时会尽量做到向下兼容,但很多时候尤其是第三方SDK是没法得到保证的,在美团外卖Android App v6.0版本时因为这个原因导致热修复功能丧失,因此为了提前发现问题,我们接入了依赖检查插件Defensor。
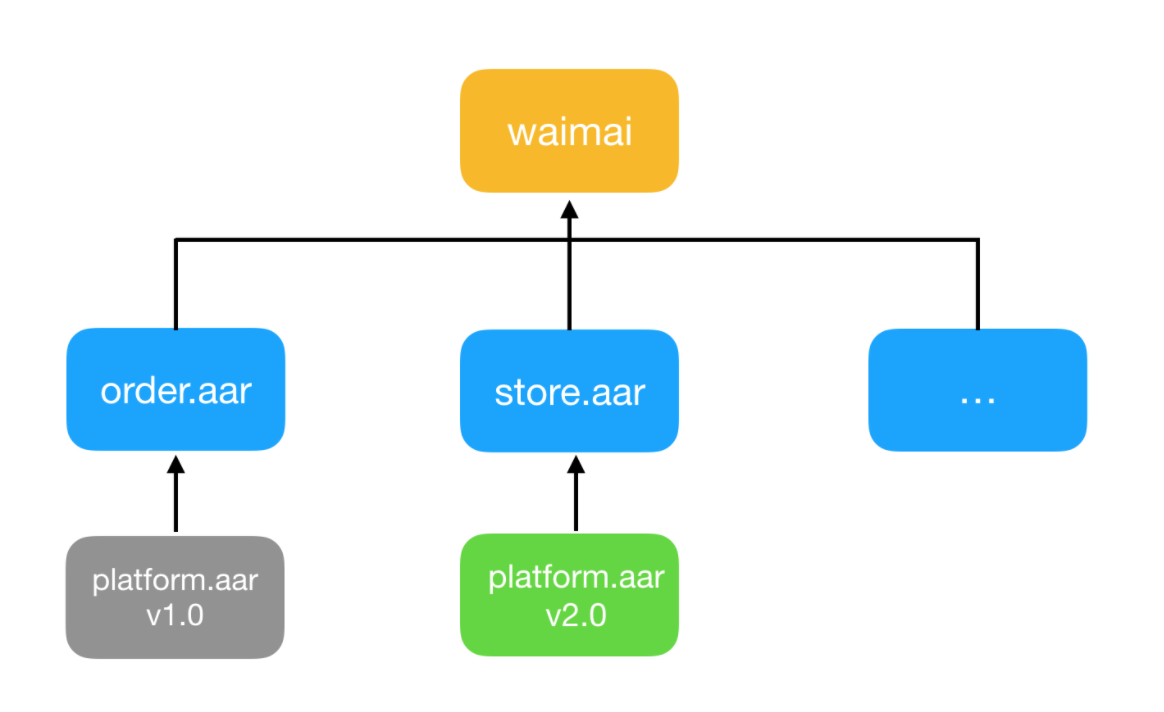
Defensor在编译时通过DexTask获取到所有的输入文件(也就是被编译过的class文件),然后检查每个文件里引用的类、字段、方法等是否存在。
除此之外我们写了一个Gradle插件SVD(strict version dependencies)来对那些重要的SDK的版本进行统一管理。插件会在编译时检查Gradle最终使用的SDK版本是否和配置中的一致,如果不一致插件会终止编译并报错,并同时会打印出发生冲突的SDK的所有依赖关系。
Crash的预防实践
单纯的靠约定或规范去减少Crash的发生是不现实的。约定和规范受限于组织架构和具体执行的个人,很容易被忽略,只有靠工程架构和工具才能保证Crash的预防长久的执行下去。
工程架构对Crash率的影响
在治理Crash的实践中,我们往往忽略了工程架构对Crash率的影响。Crash的发生大部分原因是源于程序员的不合理的代码,而程序员工作中最直接的接触的就是工程架构。对于一个边界模糊,层级混乱的架构,程序员是更加容易写出引起Crash的代码。在这样的架构里面,即使程序员意识到导致某种写法存在问题,想要去改善这样不合理的代码,也是非常困难的。相反,一个层级清晰,边界明确的架构,是能够大大减少Crash发生的概率,治理和预防Crash也是相对更容易。这里我们可以举几个我们实践过的例子阐述。
业务模块的划分
原来我们的Crash基本上都是由个别同学关注解决的,团队里的每个同学都会提交可能引起Crash的代码,如果负责Crash的同学因为某些事情,暂时没有关注App的Crash率,那么造成Crash的同学也不会知道他的代码引起了Crash。
对于这个问题,我们的做法是App的业务模块化。业务模块化后,每个业务都有都有唯一包名和对应的负责人。当某个模块发生了Crash,可以根据包名提交问题给这个模块的负责人,让他第一时间进行处理。业务模块化本身也是工程架构优先需要考虑的事情之一。
页面跳转路由统一处理页面跳转
对外卖App而言,使用过程中最多的就是页面间的跳转,而页面间跳转经常会造成ActivityNotFoundException,例如我们配了一个scheme,但对方的scheme路径已经发生了变化;又例如,我们调用手机上相册的功能,而相册应用已被用户自己禁用或移除了。解决这一类Crash,其实也很简单,只需要在startActivity增加ActivityNotFoundException异常捕获即可。但一个App里,启动Activity的地方,几乎是随处可见,无法预测哪一处会造成ActivityNotFoundException。
我们的做法是将页面的跳转,都通过我们封装的scheme路由去分发。这样的好处是,通过scheme路由,在工程架构上所有业务都是解耦,模块间不需要相互依赖就可以实现页面的跳转和基本类型参数的传递;同时,由于所有的页面跳转都会走scheme路由,我们只需要在scheme路由里一处加上ActivityNotFoundException异常捕获即可解决这种类型的Crash。路由设计示意图如下:
网络层统一处理API脏数据
客户端的很大一部分的Crash是因为API返回的脏数据。比如当API返回空值、空数组或返回不是约定类型的数据,App收到这些数据,就极有可能发生空指针、数组越界和类型转换错误等Crash。而且这样的脏数据,特别容易引起线上大面积的崩溃。
最早我们的工程的网络层用法是:页面监听网络成功和失败的回调,网络成功后,将JSON数据传递给页面,页面解析Model,初始化View,如图所示。这样的问题就是,网络虽然请求成功了,但是JSON解析Model这个过程可能存在问题,例如没有返回数据或者返回了类型不对的数据,而这个脏数据导致问题会出现在UI层,直接反应给用户。
根据上图,我们可以看到由于网络层只承担了请求网络的职责,没有承担数据解析的职责,数据解析的职责交给了页面去处理。这样使得我们一旦发现脏数据导致的Crash,就只能在网络请求的回调里面增加各种判断去兼容脏数据。我们有几百个页面,补漏完全补不过来。通过几个版本的重构,我们重新划分了网络层的职责,如图所示:
从图上可以看出,重构后的网络层负责请求网络和数据解析,如果存在脏数据的话,在网络层就会发现问题,不会影响到UI层,返回给UI层的都是校验成功的数据。这样改造后,我们发现这类的Crash率有了极大的改善。
大图监控
上面讲到大对象是导致OOM的主要原因之一,而Bitmap是App里最常见的大对象类型,因此对占用内存过大的Bitmap对象的监控就很有必要了。
我们用AOP方式Hook了三种常见图片库的加载图片回调方法,同时监控图片库加载图片时的两个维度:
- 加载图片使用的URL。外卖App中除静态资源外,所有图片都要求发布到专用的图片CDN服务器上,加载图片时使用正则表达式匹配URL,除了限定CDN域名之外还要求所有图片加载时都要添加对应的动态缩放参数。
- 最终加载出的图片结果(也就是Bitmap对象)。我们知道Bitmap对象所占内存和其分辨率大小成正比,而一般情况下在ImageView上设置超过自身尺寸的图片是没有意义的,所以我们要求显示在ImageView中的Bitmap分辨率不允许超过View自身的尺寸(为了降低误报率也可以设定一个报警阈值)。
开发过程中,在App里检测到不合规的图片时会立即高亮出错的ImageView所在的位置并弹出对话框提示ImageView所在的Activity、XPath和加载图片使用的URL等信息,如下图,辅助开发同学定位并解决问题。在Release环境下可以将报警信息上报到服务器,实时观察数据,有问题及时处理。
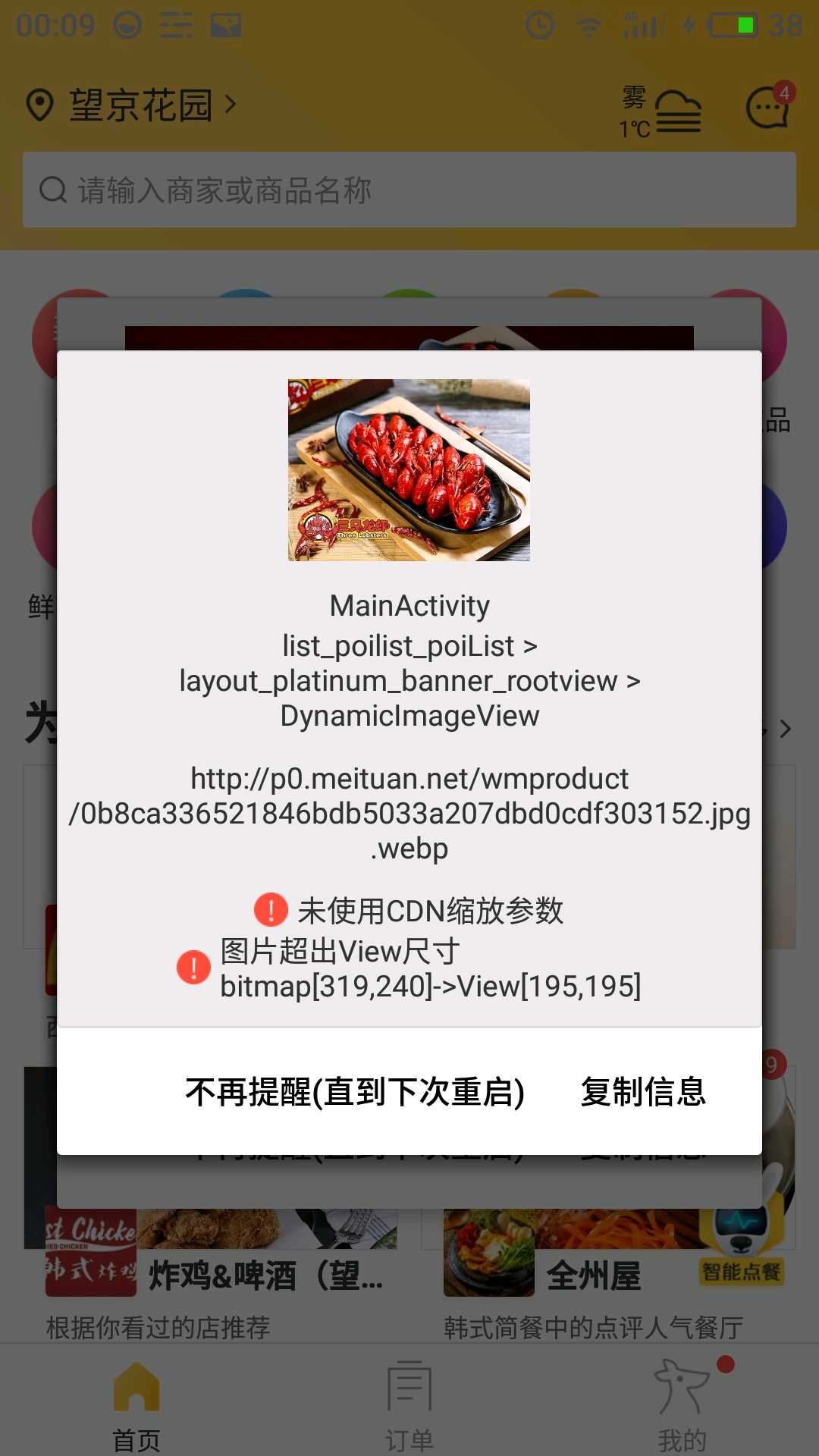
Lint检查
我们发现线上的很多Crash其实可以在开发过程中通过Lint检查来避免。Lint是Google提供的Android静态代码检查工具,可以扫描并发现代码中潜在的问题,提醒开发人员及早修正,提高代码质量。
但是Android原生提供的Lint规则(如是否使用了高版本API)远远不够,缺少一些我们认为有必要的检测,也不能检查代码规范。因此我们开始开发自定义Lint,目前我们通过自定义Lint规则已经实现了Crash预防、Bug预防、提升性能/安全和代码规范检查这些功能。如检查实现了Serializable接口的类,其成员变量(包括从父类继承的)所声明的类型都要实现Serializable接口,可以有效的避免NotSerializableException;强制使用封装好的工具类如ColorUtil、WindowUtil等可以有效的避免因为参数不正确产生的IllegalArgumentException和因为Activity已经finish导致的BadTokenException。
Lint检查可以在多个阶段执行,包括在本地手动检查、编码实时检查、编译时检查、commit时检查,以及在CI系统中提Pull Request时检查、打包时检查等,如下图所示。更详细的内容可参考《美团外卖Android Lint代码检查实践》。
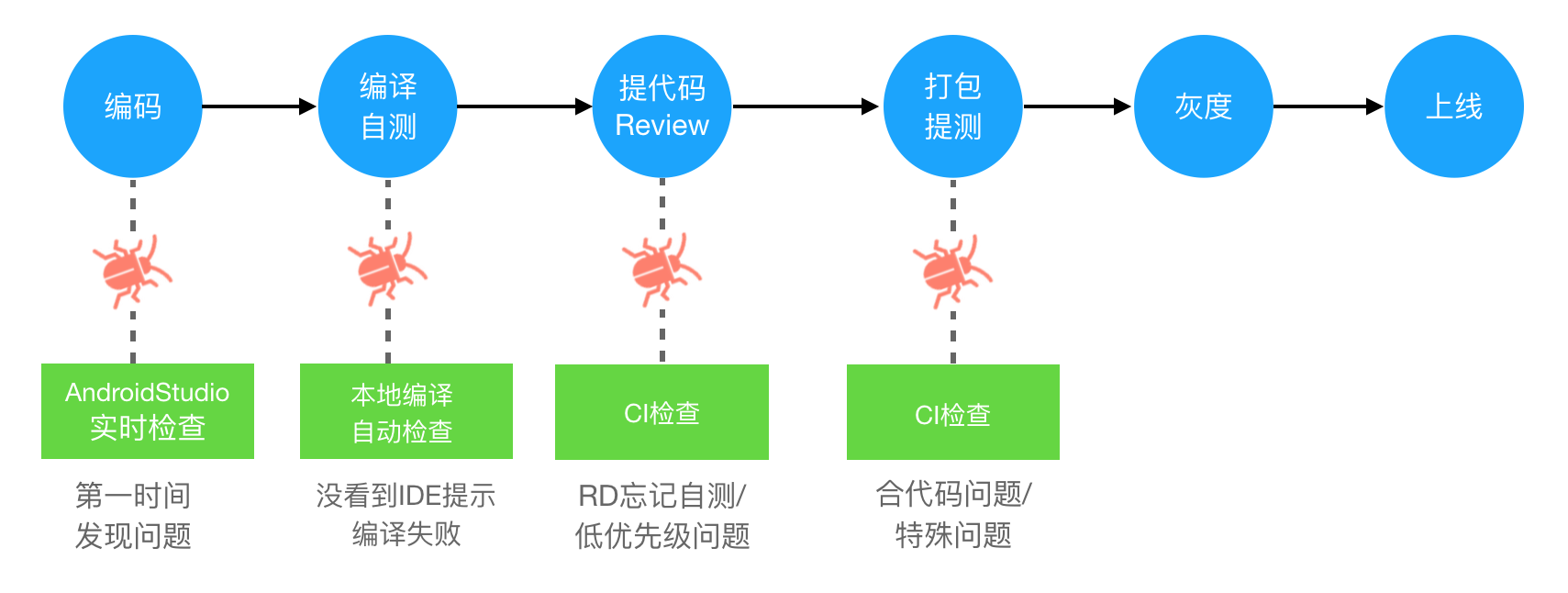
资源重复检查
在之前的文章《美团外卖Android平台化架构演进实践》中讲述了我们的平台化演进过程,在这个过程中大家很大的一部分工作是下沉,但是下沉不完全就会导致一些类和资源的重复,类因为有包名的限制不会出现问题。但是一些资源文件如layout、drawable等如果同名则下层会被上层覆盖,这时layout里view的id发生了变化就可能导致空指针的问题。为了避免这种问题,我们写了一个Gradle插件通过hook MergeResource这个Task,拿到所有library和主库的资源文件,如果检查到重复则会中断编译过程,输出重复的资源名及对应的library name,同时避免有些资源因为样式等原因确实需要覆盖,因此我们设置了白名单。同时在这个过程中我们也拿到了所有的的图片资源,可以顺手做图片大小的本地监控,如下图所示:
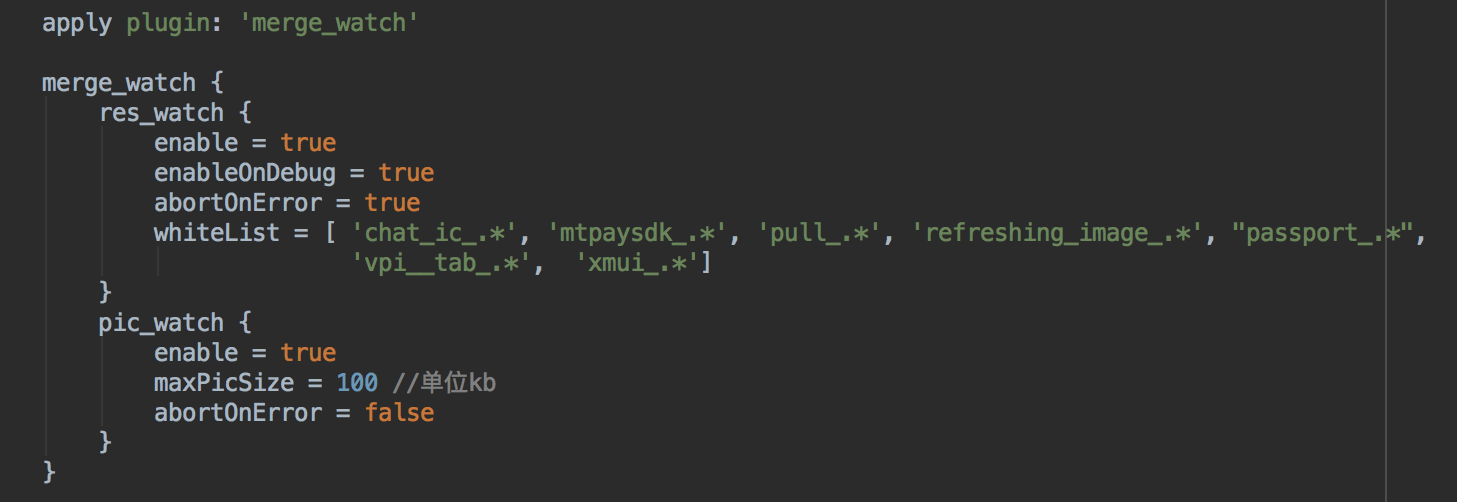
Crash的监控&止损的实践
监控
在经过前面提到的各种检查和测试之后,应用便开始发布了。我们建立了如下图的监控流程,来保证异常发生时能够及时得到反馈并处理。首先是灰度监控,灰度阶段是增量Crash最容易暴露的阶段,如果这个阶段没有很好的把握住,会使得增量变存量,从而导致Crash率上升。如果条件允许的话,可以在灰度期间制定一些灰度策略去提高这个阶段Crash的暴露。例如分渠道灰度、分城市灰度、分业务场景灰度、新装用户的灰度等等,尽量覆盖所有的分支。灰度结束之后便开始全量,在全量的过程中我们还需要一些日常Crash监控和Crash率的异常报警来防止突发情况的发生,例如因为后台上线或者运营配置错误导致的线上Crash。除此之外还需要一些其他的监控,例如,之前提到的大图监控,来避免因为大图导致的OOM。具体的输出形式主要有邮件通知、IM通知、报表。
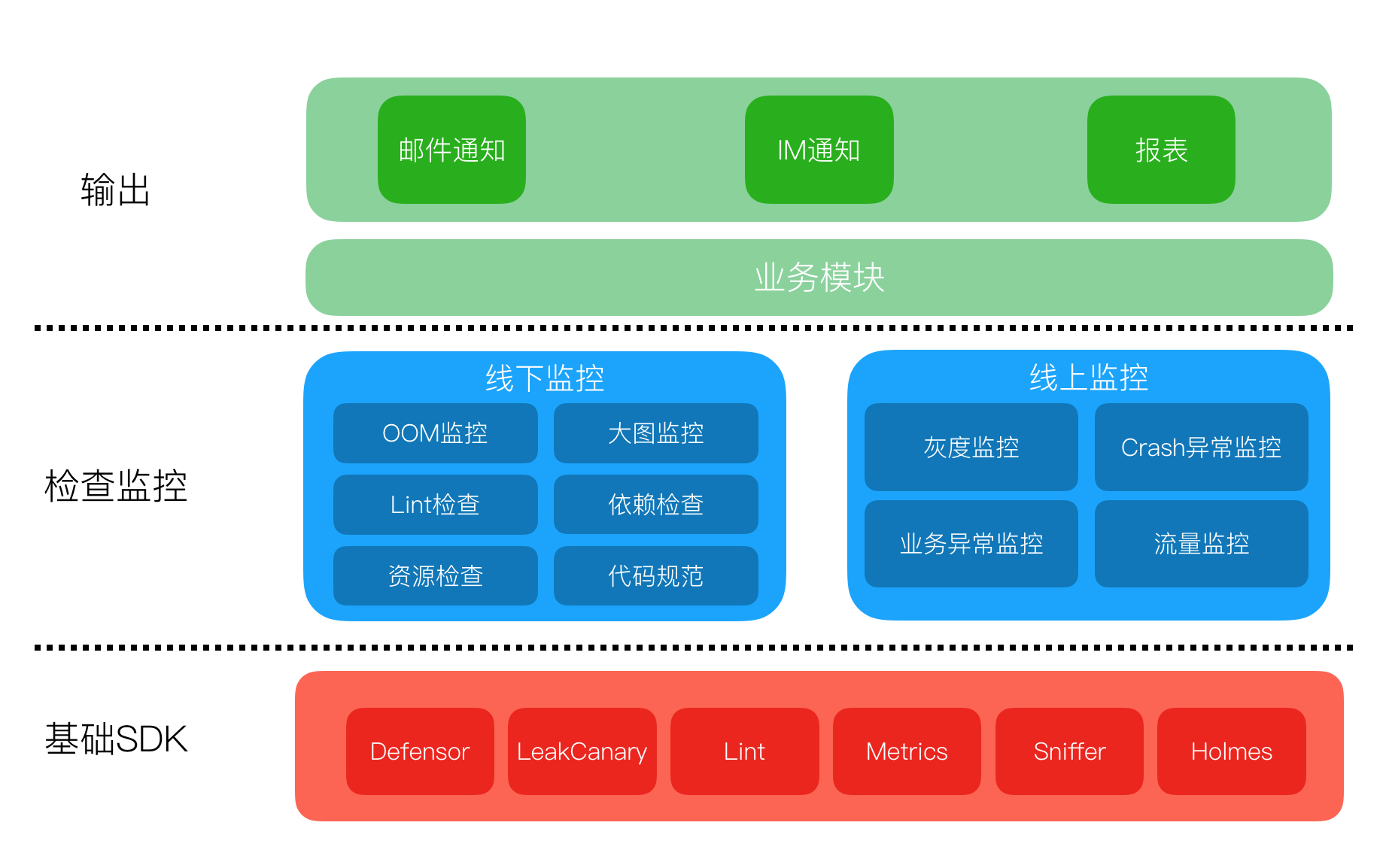
止损
尽管我们在前面做了那么多,但是Crash还是无法避免的,例如,在灰度阶段因为量级不够,有些Crash没有被暴露出来;又或者某些功能客户端比后台更早上线,而这些功能在灰度阶段没有被覆盖到;这些情况下,如果出现问题就需要考虑如何止损了。
问题发生时首先需要评估重要性,如果问题不是很严重而且修复成本较高可以考虑在下个版本再修复,相反如果问题比较严重,对用户体验或下单有影响时就必须要修复。修复时首先考虑业务降级,主要看该部分异常的业务是否有兜底或者A/B策略,这样是最稳妥也是最有效的方式。如果业务不能降级就需要考虑热修复了,目前美团外卖Android App接入的热修复框架是自研的Robust,可以修复90%以上的场景,热修成功率也达到了99%以上。如果问题发生在热修复无法覆盖的场景,就只能强制用户升级。强制升级因为覆盖周期长,同时影响用户的体验,只在万不得已的情况下才会使用。
展望
Crash的自我修复
我们在做新技术选型时除了要考虑是否能满足业务需求、是否比现有技术更优秀和团队学习成本等因素之外,兼容性和稳定性也非常重要。但面对国内非富多彩的Android系统环境,在体量百万级以上的的App中几乎不可能实现毫无瑕疵的技术方案和组件,所以一般情况下如果某个技术实现方案可以达到0.01‰以下的崩溃率,而其他方案也没有更好的表现,我们就认为它是可以接受的。但是哪怕仅仅十万分之一的崩溃率,也代表还有用户受到影响,而我们认为Crash对用户来说是最糟糕的体验,尤其是涉及到交易的场景,所以我们必须本着每一单都很重要的原则,尽最大努力保证用户顺利执行流程。
实际情况中有一些技术方案在兼容性和稳定性上做了一定妥协的场景,往往是因为考虑到性能或扩展性等方面的优势。这种情况下我们其实可以再多做一些,进一步提高App的可用性。就像很多操作系统都有“兼容模式”或者“安全模式”,很多自动化机械机器都配套有手动操作模式一样,App里也可以实现备用的降级方案,然后设置特定条件的触发策略,从而达到自动修复Crash的目的。
举例来讲,Android 3.0中引入了硬件加速机制,虽然可以提高绘制帧率并且降低CPU占用率,但是在某些机型上还是会有绘制错乱甚至Crash的情况,这时我们就可以在App中记录硬件加速相关的Crash问题或者使用检测代码主动检测硬件加速功能是否正常工作,然后主动选择是否开启硬件加速,这样既可以让绝大部分用户享受硬件加速带来的优势,也可以保障硬件加速功能不完善的机型不受影响。
还有一些类似的可以做自动降级的场景,比如:
- 部分使用JNI实现的模块,在SO加载失败或者运行时发生异常则可以降级为Java版实现。
- RenderScript实现的图片模糊效果,也可以在失败后降级为普通的Java版高斯模糊算法。
- 在使用Retrofit网络库时发现OkHttp3或者HttpURLConnection网络通道失败率高,可以主动切换到另一种通道。
这类问题都需要根据具体情况具体分析,如果可以找到准确的判定条件和稳定的修复方案,就可以让App稳定性再上一个台阶。
特定Crash类型日志自动回捞
外卖业务发展迅速,即使我们在开发时使用各种工具、措施来避免Crash的发生,但Crash还是不可避免。线上某些怪异的Crash发生后,我们除了分析Crash堆栈信息之外,还可以使用离线日志回捞、下发动态日志等工具来还原Crash发生时的场景,帮助开发同学定位问题,但是这两种方式都有它们各自的问题。离线日志顾名思义,它的内容都是预先记录好的,有时候可能会漏掉一些关键信息,因为在代码中加日志一般只是在业务关键点,在大量的普通方法中不可能都加上日志。动态日志(Holmes)存在的问题是每次下发只能针对已知UUID的一个用户的一台设备,对于大量线上Crash的情况这种操作并不合适,因为我们并不能知道哪个发生Crash的用户还会再次复现这次操作,下发配置充满了不确定性。
我们可以改造Holmes使其支持批量甚至全量下发动态日志,记录的日志等到发生特定类型的Crash时才上报,这样一来可以减少日志服务器压力,同时也可以极大提高定位问题的效率,因为我们可以确定上报日志的设备最后都真正发生了该类型Crash,再来分析日志就可以做到事半功倍。
总结
业务的快速发展,往往不可能给团队充足的时间去治理Crash,而Crash又是App最重要的指标之一。团队需要由一个个Crash个例,去探究每一个Crash发生的最本质原因,找到最合理解决这类Crash的方案,建立解决这一类Crash的长效机制,而不能饮鸩止渴。只有这样,随着版本的不断迭代,我们才能在Crash治理之路上离目标越来越近。
参考资料
- Crash率从2.2%降至0.2%,这个团队是怎么做到的?
- Android运行时ART加载OAT文件的过程分析
- Android动态日志系统Holmes
- Android Hook技术防范漫谈
- 美团外卖Android Lint代码检查实践
美团外卖Android平台化的复用实践
美团外卖平台化复用主要是指多端代码复用,正如美团外卖iOS多端复用的推动、支撑与思考文章所述,多端包含有两层意思:其一是相同业务的多入口,指美团外卖业务需要在美团外卖App(下文简称外卖App)和美团App外卖频道(下文简称外卖频道)同时上线;其二是指平台上各个业务线,美团外卖不同业务线都依赖外卖基础服务,比如登陆、定位等。
多入口及多业务线给美团外卖平台化复用带来了巨大的挑战,此前我们的一篇博客《美团外卖Android平台化架构演进实践》(下文简称《架构演进实践》)也提到了这个问题,本文将在“代码复用”这一章节的基础上,进一步介绍平台化复用工作面临的挑战以及相应的解决方案。
美团外卖平台化复用背景
美团外卖App和美团App外卖频道业务基本一样,但由于历史原因,两端代码差异较大,造成同样的子业务需求在一端上线后,另一端几乎需要重新实现,严重浪费开发资源。在《架构演进实践》一文中,将美团外卖Android客户端平台化架构分为平台层、业务层和宿主层,我们希望能够在平台化架构中实现平台层和业务层的多端复用,从而节省子业务需求开发资源,实现多端部署。
难点总结
两端业务虽然基本一致,但是仍旧存在差异,UI、基础服务、需求差异等。这些差异存在于美团外卖平台化架构中的平台层和业务层各个模块中,给平台化复用带来了巨大的挑战。我们总结了两端代码的差异点,主要包括以下几个方面:
- 基础服务的差异:包括基础Activity、网络库、图片库等底层库的差异。
- 组件的实现差异:包括基础数据Model、下拉刷新、页面跳转等基础组件的差异。
- 页面的差异:包括两端的UI、交互、业务和版本发布时间不一致等差异。
前期探索
前期,我们尝试通过一些设计方案来绕过上述差异,从而实现两端的代码复用。我们选择了二级频道页(下文统称金刚页)进行方案尝试,设计如下:
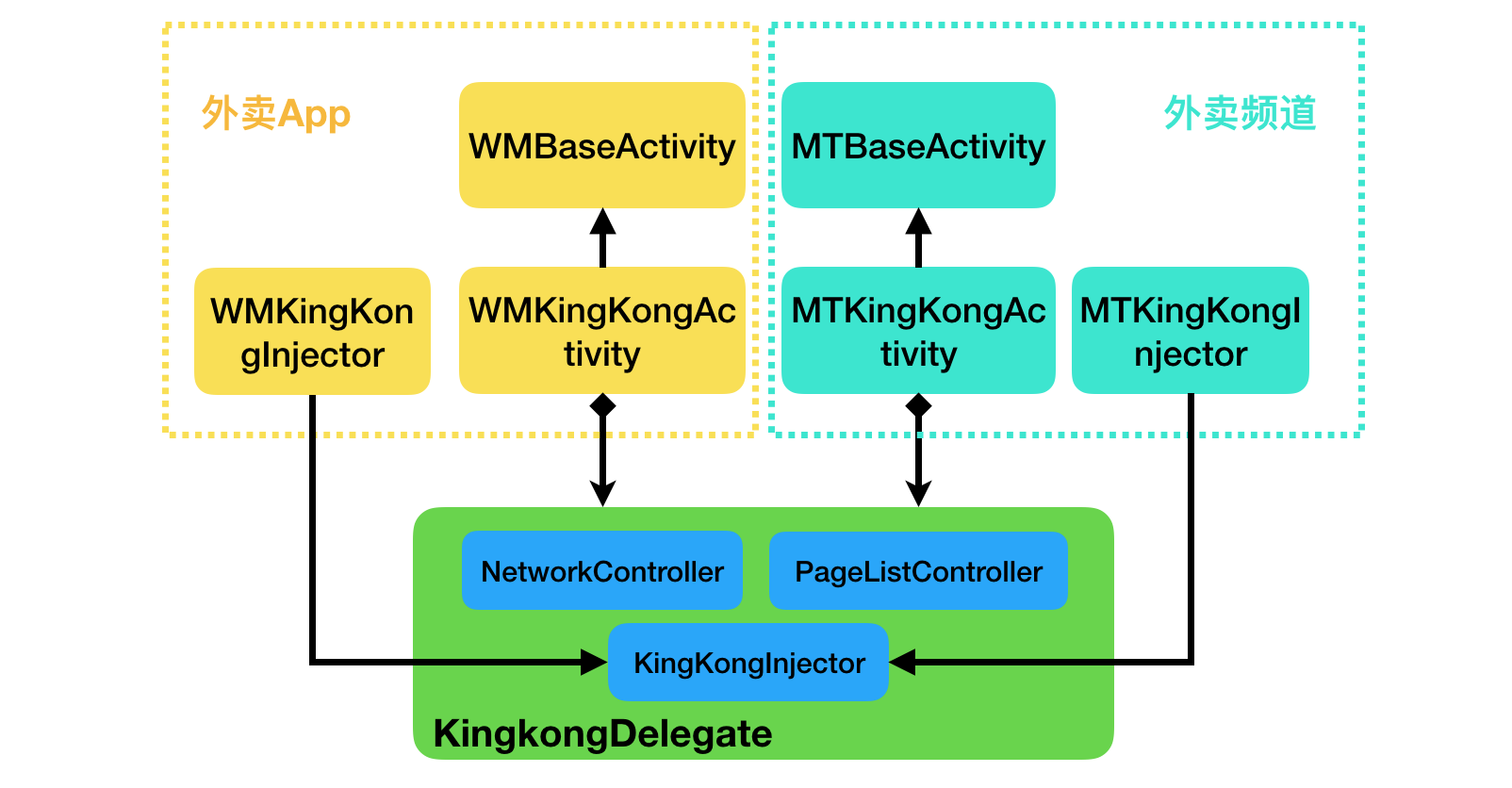
其中,KingKongDelegate是Activity生命周期实现的代理类,包含onCreate、onResume等Activity生命周期回调方法。在外卖App和外卖频道两端分别基于各自的基础Activity实现WMKingKongAcitivity和MTKingKongActivity,分别会通过调用KingKongDelegate的方法对Activity的生命周期进行分发。
KingKongInjector是两端差异部分的接口集合,包括页面跳转(两端页面差异)、获取页面刷新间隔时间、默认资源等,在外卖App和外卖频道分别有对应的接口实现WMKingKongInjector和MTKingKongInjector。
NetworkController则是用Retrofit实现统一的网络请求封装,PageListController是对列表分页加载逻辑以及页面空白、网络加载失败等异常逻辑处理。
在金刚页设计方案中,我们采用了“代理+继承”的方式,实现了用统一的网络库实现网络请求,定义了统一的基础数据Model,统一了部分基础服务以及基础数据。通过KingKongDelegate屏蔽了两端基础Acitivity的差异,同时,通过KingKongInjector实现了两端差异部分的处理。但是我们发现这种设计方案存在以下问题:
- 虽然这样可以解决网络库和图片的差异,但是不能屏蔽两端基础Activity的差异。
- KingKongInjector提供了一种解决两端差异的处理方式,但是KingKongInjector会存在很多不相关的方法集合,不易控制其边界。此外,多个子模块需要调用KingKongInjector,会导致KingKongInjector不便管理。
- 由于两端Model不同,需要实现这个模块使用的统一Model,但是并未和其他页面使用的相同含义的Model统一。
平台化复用方案设计
通过代码复用初步尝试总结,我们总结出平台化复用,需要考虑四件事情:
- 差异化的统一管理。
- 基础服务的复用。
- 基础组件的复用。
- 页面的复用。
整体设计
我们在实现平台化架构的基础上,经过不断的探索,最终形成适合外卖业务的平台化复用设计:整体分为基础服务层-基础组件层-业务层-宿主层。设计图如下:
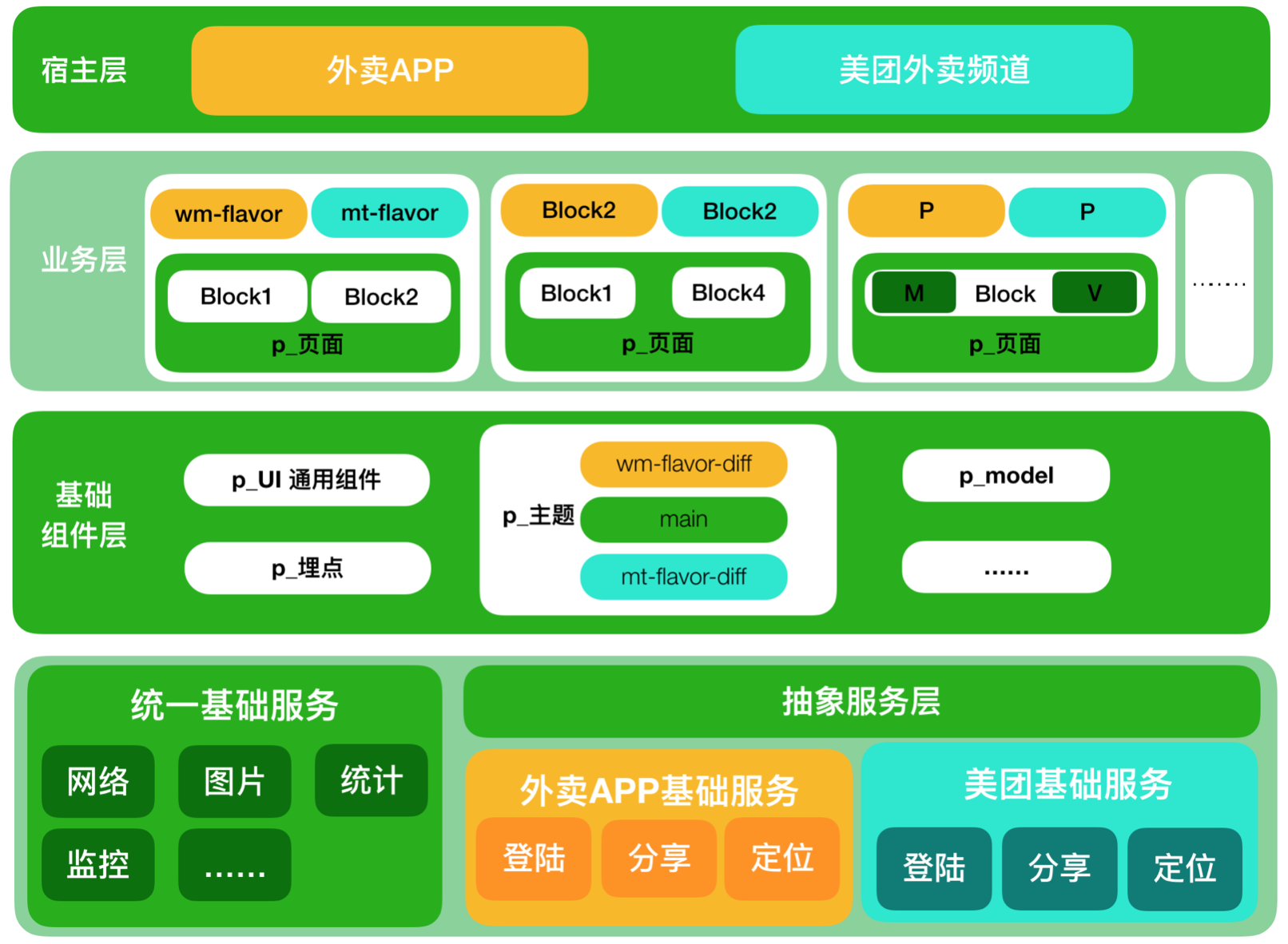
- 基础服务层:包含多端统一的基础服务和有差异的基础服务,其中统一的基础服务包括网络库、图片库、统计、监控等。对于登录、分享、定位等外卖App和外卖频道两端有差异的部分,我们通过抽象服务层来屏蔽两端的差异。
- 基础组件层:包括统一的两端Model、埋点、下拉刷新、权限、Toast、A/B测试、Utils等两端复用的基础组件。
- 业务层:包括外卖的具体业务模块,目前可以分为列表页模块(如首页、金刚页等)、商家模块(如商家页、商品详情页等)和订单模块(如下单页、订单状态页等)。这些业务模块的特点是:模块间复用可能性小,模块内的复用可能性大。
- 宿主层:主要是初始化服务,例如Application的初始化、dex加载和其他各种必要的组件的初始化。
分层架构能够实现各层功能的职责分离,同时,我们要求上层不感知下层的多端差异。在各层中进行组件划分,同样,我们也要求实现调用组件方不感知组件的多端差异。通过这样的设计,能够使得整体架构更加清晰明朗,复用率提高的同时,不影响架构的复杂度和灵活度。
差异化管理
需要多端复用的业务相对于普通业务而言,最大的挑战在于差异化管理。首先多端的先天条件就决定了多端复用业务会存在差异;其次,多端复用的业务有个性化的需求。在多端复用的差异化管理方案中,我们总结了以下两种方案:
- 差异分支管理方案。
- pins工程+Flavor管理的方案。
差异分支管理
分支管理常用于多个需求在一端上线后,需要在另一端某一个时间节点跟进的场景,如下图所示:
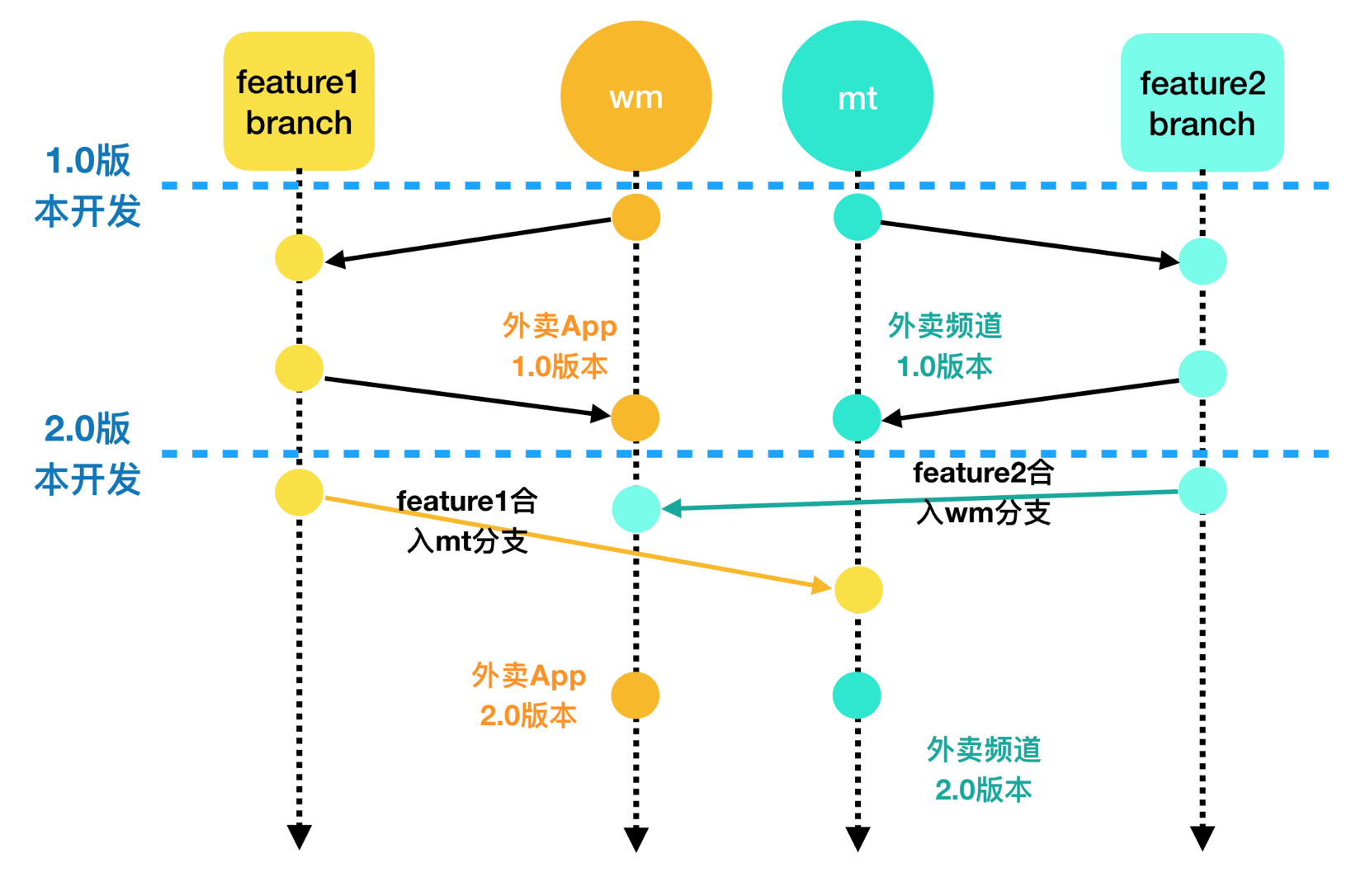
两端开发1.0版本时,分别要在wm分支(外卖App对应分支)开发feature1和mt分支(外卖频道对应分支)开发feature2。开发2.0版本时,feature1需要在外卖频道上线,feature2需要在外卖App上线,则分别将feature1分支代码合入mt分支,feature2代码合入wm分支。这样通过拉取新需求分支管理的方式,满足了需求的差异化管理。但是这种实现方式存在两个问题:
- 两端需求差异太多的话,就会存在很多分支,造成分支管理困难。
- 不支持细粒度的差异化管理,比如模块内部的差异化管理。
pins工程+Flavor的差异化管理
在Android官网《配置构建变体》章节中介绍了Product Flavor(下文简称Flavor)可以用于实现full版本以及demo版本的差异化管理,通过配置Gradle,可以基于不同的Flavor生成不同的apk版本。因此,模块内部的差异化管理是通过Flavor来实现,其原理如下图所示:
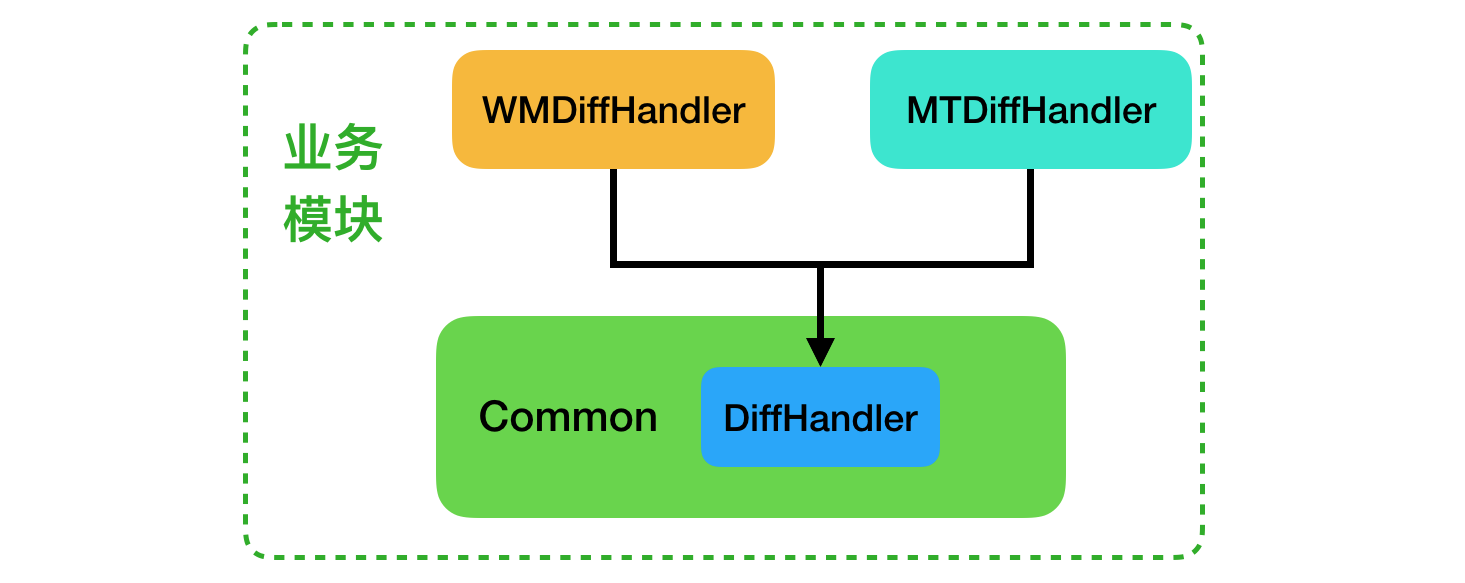
其中Common是两端复用的代码,DiffHandler是两端差异部分接口,WMDiffHandler是外卖App对应的Flavor下的DiffHandler实现,MTDiffHandler是外卖频道对应Flavor下的DiffHandler实现。通过两端分别依赖不同Flavor代码实现模块内差异化管理。
对于需求在两端版本差异化管理,也可以通过配置Flavor来实现,如下图所示:
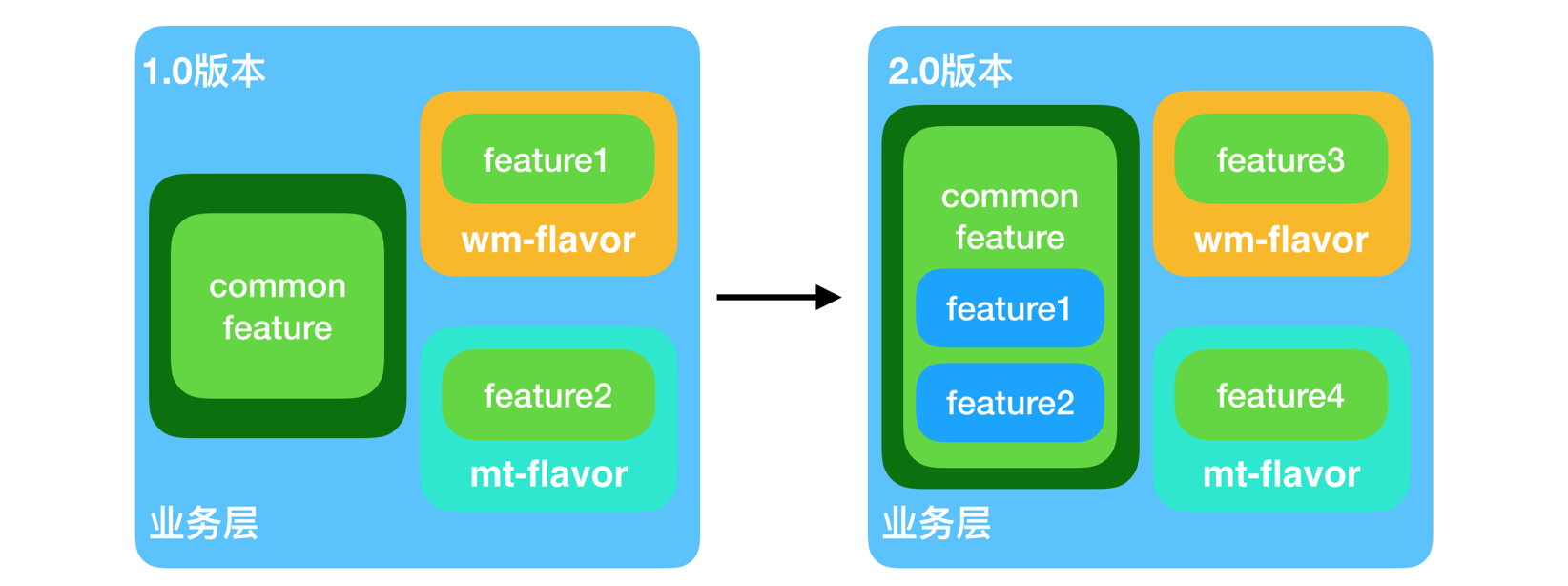
在1.0版本时,feature1只在外卖App上线,feature2只在外卖频道上线。当2.0版本时,如果feature1、feature2需要同时在两端上线,只需要将对应业务代码移动到共用SourceSet即可实现feature1、feature2代码复用。
综合两种差异代码实现来看,我们选择使用Flavor方式来实现代码差异化管理。其优势如下:
- 一个功能模块只需要维护一套代码。
- 差异代码在业务库不同Flavor中实现,方便追溯代码实现历史以及做差异实现对比。
- 对于上层来说,只会依赖下层代码的不同Flavor版本;下层对上层暴露接口也基本一样,上层不用关心下层差异实现。
- 需求版本差异,也只需先在上线一端对应的Flavor中实现,当需要复用时移动到共用的SourceSet下面,就能实现需求代码复用。
从Android工程结构来看,使用Flavor只能在module内复用,但是以module为粒度的复用对于差异化管理来说约束太重。这意味着同个module内不同模块的差异代码同时存在于对应Flavor目录下,或者说需要将每个子模块都创建成不同的module,这样管理代码是非常不便的。《微信Android模块化架构重构实践》一文中提到了一个重要的概念pins工程,pins工程能在module之内再次构建完整的多子工程结构。我们通过创造性的使用pins工程+Flavor的方案,将差异化的管理单元从module降到了pins工程。而pins工程可以定义到最小的业务单元,例如一个Java文件。整体的设计实现如下: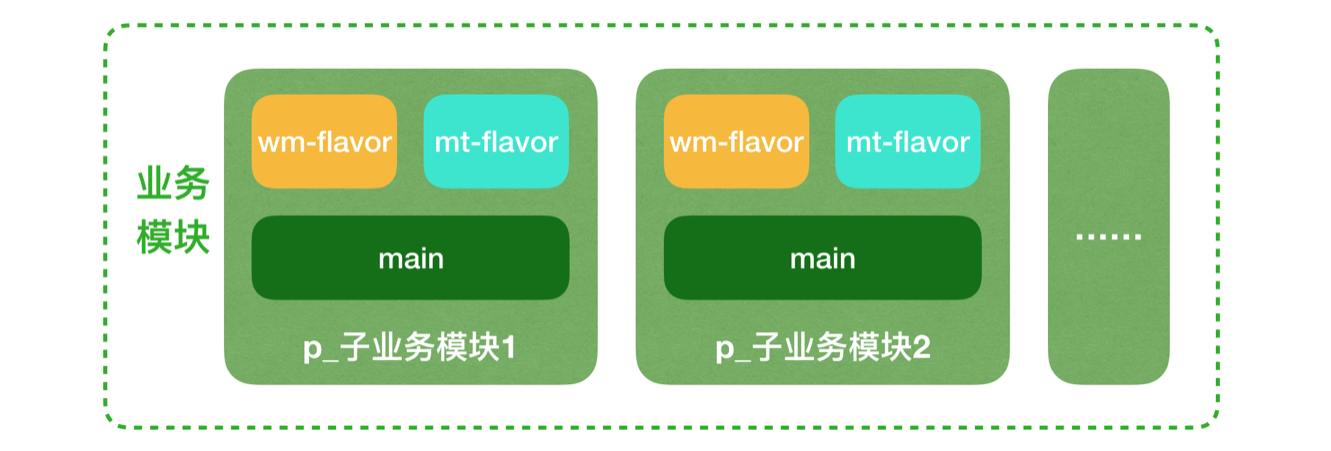
具体的配置过程,首先需要在Android Studio工程里首先要定义两个Flavor:wm、mt。
productFlavors {
wm {}
mt {}
}
然后使用pins工程结构,把每个子业务作为一个pins工程,实现如下Gradle配置:
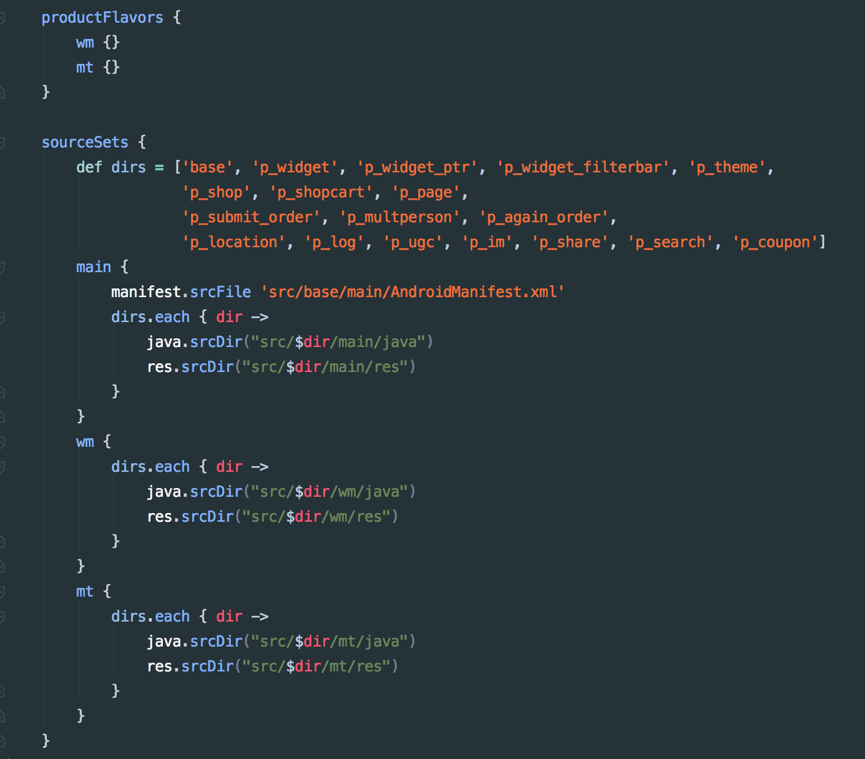
最终的工程目录结构如下:
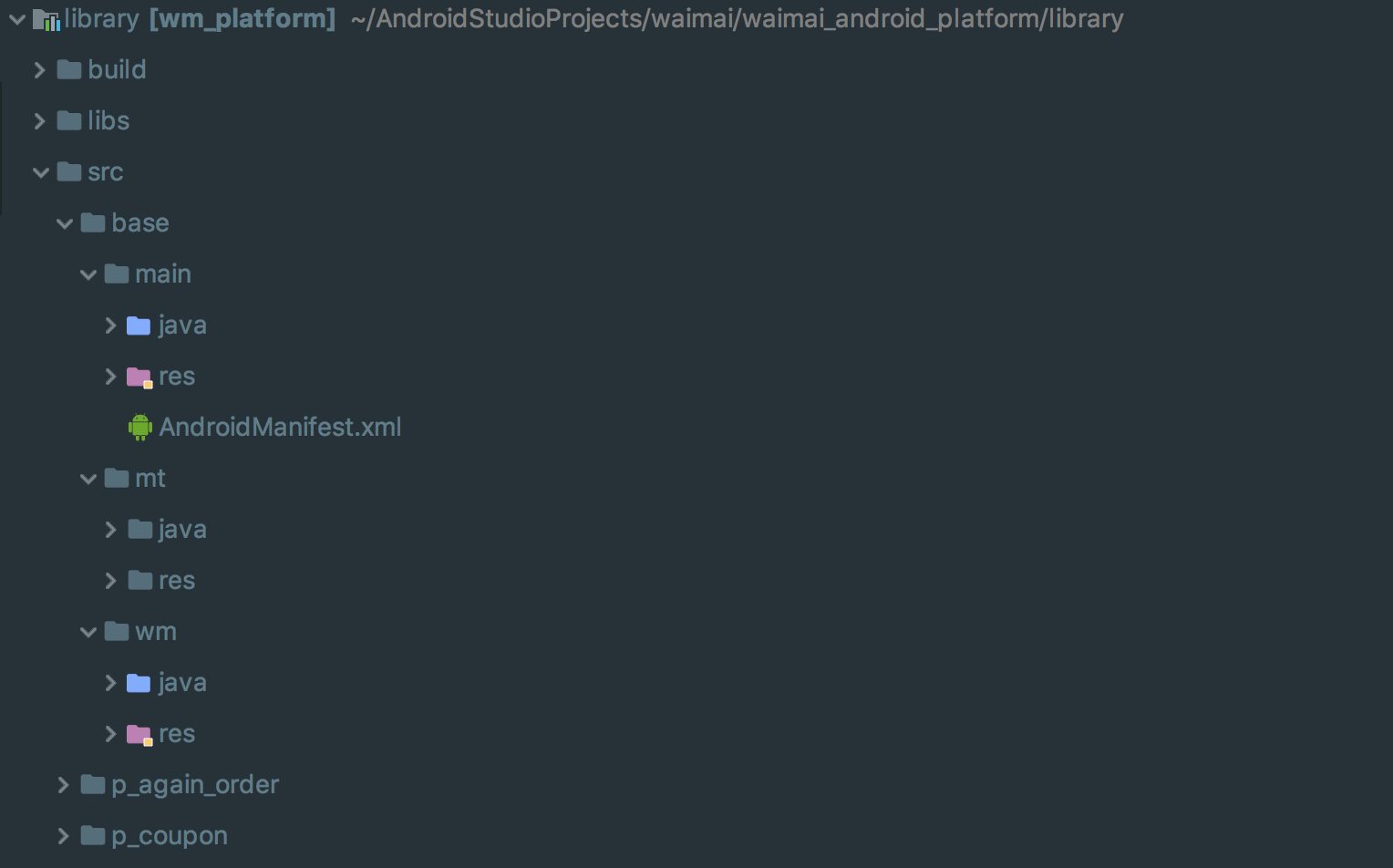
以名为base的pins工程为例,src/base/main是该工程的两端共用代码,src/base/wm是该工程的外卖App使用的代码,src/base/mt是外卖频道使用的代码。同时,我们做了代码检查,除了base pins工程可以依赖以外,其他pins不存在直接依赖关系。通过这样实现了module内部更细粒度的工程依赖,同时配合Gradle配置可以实现只编译部分pins工程,使整体代码更加灵活。
通过pins工程+Flavor的差异化管理方式,我们既实现了需求级别的差异化管理,也实现了模块内的功能差异化管理。同时,pins工程更好的控制了代码粒度以及代码边界,也将差异代码控制在比module更小的粒度。
基础服务的复用
对于一个App来说,基础服务的重要性不言而喻,所以在平台化复用中,往往基础服务的差异最大。由于基础服务的使用范围比较广,如果基础服务的差异得不到有效的处理,让上层感知到差异,就会增加架构层与层之间的耦合,上层本身实现业务的难度也会加大。下文里讲解一个我们在实践过程中遇到的例子,来阐述我们的主要解决思路。
在前期探索章节中,我们提到金刚页由于两端基础Activity差异,以致于要使用代理类来实现Activity生命周期分发。通过采用统一接口以及Flavor方式,我们可以统一两端基础Activity组件,如下图所示:
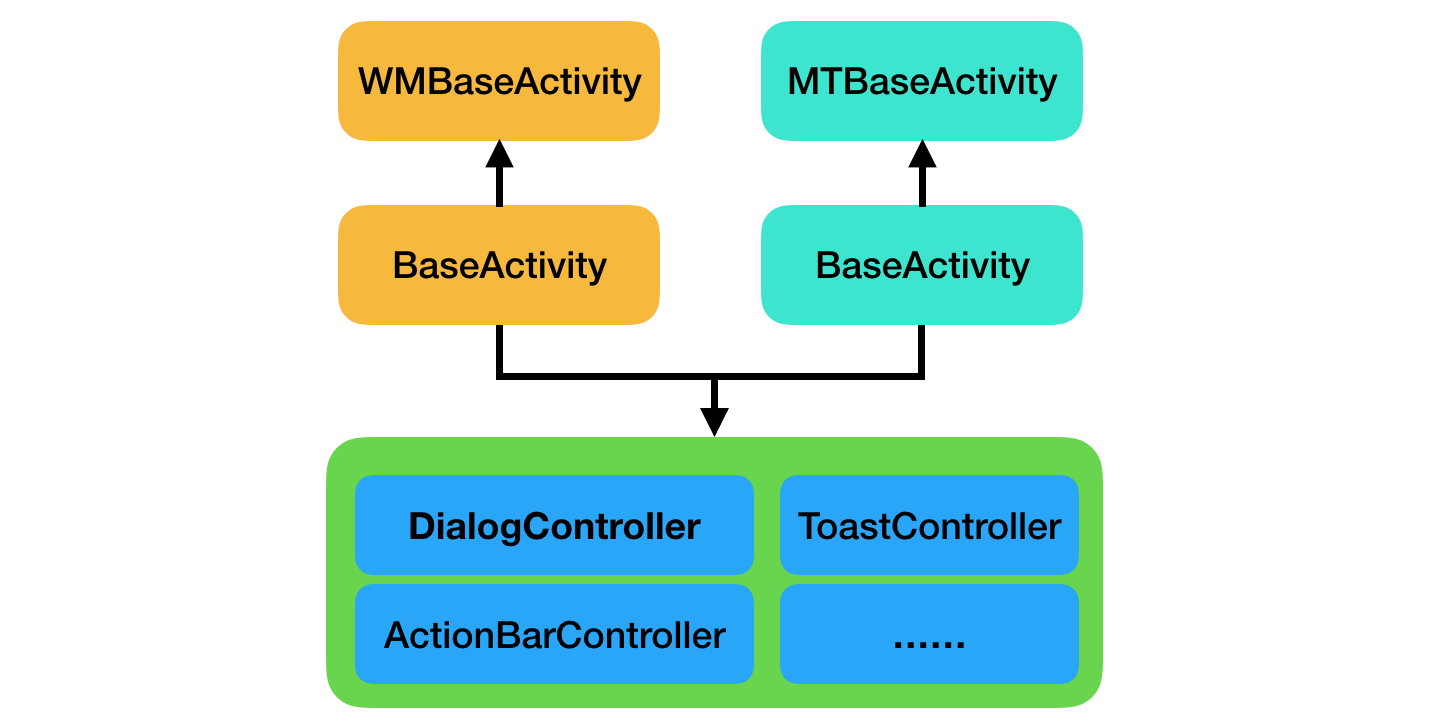
分别将两端WMBaseActivity和MTBaseActivity的差异接口统一成DialogController、ToastController以及ActionBarController等通用接口,然后在wm、mt两个Flavor目录下分别定义全限定名完全相同的BaseActivity,分别继承MTBaseActivity和MTBaseActivity并实现统一接口,接口实现尽量保持一致。对于上层来说,如果继承BaseActivity,其可调用的接口完全一致,从而达到屏蔽两端基础Activity差异的目的。
对于一些通用基础组件,由于使用范围比较广,如果不统一或者差异较大,会造成业务层代码实现差异较大,不利于代码复用。所以我们采用的策略是外卖App向外卖频道看齐。代码复用前,外卖App主要使用的网络库是Volley,统一切换为外卖频道使用的MTRetrofit;外卖使用的图片库是Fresco,统一切换为外卖频道使用的MTPicasso;其他统一的组件还包括动态加载框架、WebView加载组件、网络监控Cat、线上监控Holmes、日志回捞Logan以及降级限流等。两端代码复用时,修复问题、监控数据能力方面保持统一。
对于登录、定位等通用基础服务,我们的原则是能统一尽量统一,这样可以有效的减少多端复用中来带的多端维护成本,多份变成一份。而对于无法统一的服务,抽象出统一的服务接口,让上层不感知差异,从而减少上层的复用成本。
组件复用
组件化可以大大的提高一个App的复用率。对于平台化复用的业务而言,也是一样。多个模块之间也是会经常使用相同的功能,例如下拉刷新、分页加载、埋点、样式等功能。将这些常用的功能抽离成组件供上层业务层调用,将可以大大提高复用效果。可以说组件化是平台化复用的必要条件之一。
面对外卖App包含复杂众多的业务功能,一个功能可以被拆分成组件的基本原则是不同业务库中不同业务的共用的业务功能或行为功能。然后按照业务实现中相关性的远近,自上而下的依赖性将抽离出来的组件划分为基础通用组件、基础业务组件、UI公共组件。
基础通用组件指那些变化不大,与业务无关的组件,例如页面加载下拉刷新组件(p_refresh),日志记录相关组件(p_log),异常兜底组件(p_exception)。基础业务组件指以业务为基础的组件:评论通用组件(p_ugc),埋点组件(p_judas),搜索通用组件(p_search),红包通用组件(p_coupon)等。UI公共组件指公用View或者UI样式组件,与View 相关的通用组件(p_widget),与UI样式相关的通用组件(p_theme)。
对于抽离出来的基础组件,多端之间的差异怎么处理呢? 例如兜底组件,外卖兜底样式以黄色为主调,而外卖频道中以绿色小团为主调,如图所示:

我们首先将这个组件划分为一个pins工程,对于多端的差异,在pins工程里面利用Flavor管理多端之间的差异。这样的方案,首先组件是一个独立的模块,其次多端的差异在组件内部被统一处理了,上层业务不用感知组件的实现差异。而由于基础服务层已经将差异化管理了,组件层也不用感知基础服务的差异,减少了组件层的复用成本。
页面复用
对两端同一个页面来说,绝大部分的功能模块是可复用的,但是也存在不一致的功能模块。以外卖App和美团外卖频道首页为例,中部流量区等业务基本相同,但是顶部导航栏样式功能和中部流量区布局在两端不一样,如下图所示:
针对上述问题,我们页面复用的实现思路是页面模块化:先将页面功能按照业务相似性以及两端差异拆分成高内聚低耦合的功能单元Block,然后两端页面使用拆分的功能单元Block像搭积木似的搭建页面,单个的单元Block可以采用MVP模式实现。美团点评内部酒旅的Ripper和到店综合Shield页面模块化开发框架也是采用这样的思路。由于我们要实现两端复用,还要考虑页面之间的差异。对于两端页面差异,我们统一使用上文中提到的Flavor机制在业务单元内对两端差异化管理,业务单元所在页面不感知业务单元的差异性。对于不同的差异,单元Block可以在MVP不同层做差异化管理。
以首页为例,首页Block化复用架构如下图。两端首页头部导航栏UI展示、数据、功能不一样,导航栏整个功能就以一个Flavor在两端分别实现;商家列表中部流量区部分虽然整体UI布局不一样,但是里面单个功能Block业务逻辑、整个数据一样,继续将中部流量区里面的业务Block化;下方的商家列表项两端一样的功能,用一个公有的Block实现。在各个单元Block已经实现的基础上,两端首页搭建成首页Fragment。
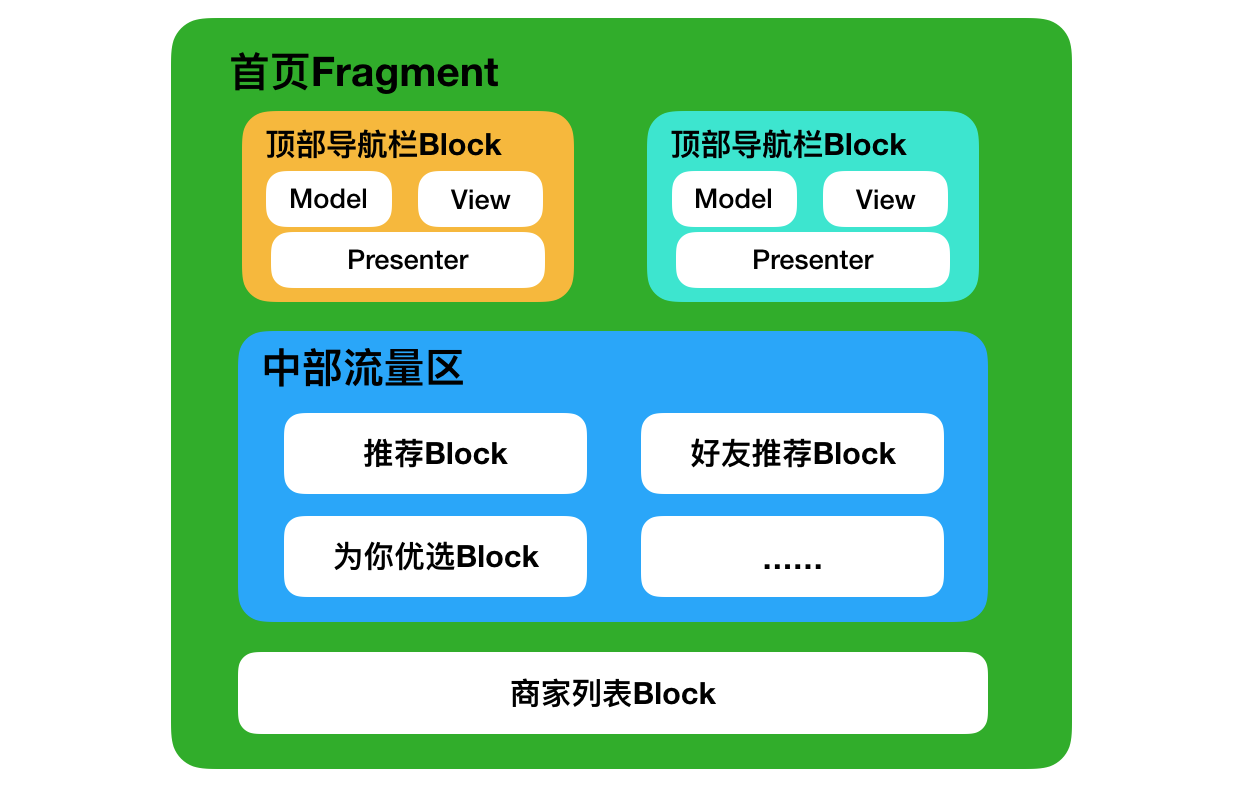
页面模块化后,将两端不同的差异在各个单元Block以Flavor方式处理,业务单元Block所在页面不用关心各个Block实现差异,不仅实现了页面的复用,各个模块功能职责分离,还提高了可维护性。
总结
美团外卖业务需要在外卖平台和美团平台同时部署,因此,在美团外卖平台化架构过程中就产生了平台化复用的问题。而怎么去实现平台化复用呢?笔者认为需要从不同粒度去考虑:基础服务、组件、页面。对于基础服务,我们需要尽可能的统一,不能统一的就抽象服务层。组件级别,需要分块分层,将依赖梳理好。页面的复用,最重要的是页面模块化和页面内模块做到职责分离。平台化复用最大的难点在于:差异的管理和屏蔽。本文提出使用pins工程+Flavor的方案,可以使得差异代码的管理得到有效的解决。同时利用分层策略,每层都自己处理好自己的差异,使得上层不用关心下层的差异。平台化复用不能单纯的追求复用率,同时要考虑到端的个性化。
到目前为止,我们实现了绝大部分外卖App和外卖频道代码复用,整体代码复用率达到88.35%,人效提升70%以上。未来,我们可能会在外卖平台、美团平台、大众点评平台三个平台进行代码复用,其场景将会更加复杂。当然,我们在做平台化复用的时候,要合理地进行评估,复用带来的“成本节约”和为了复用带来的“成本增加”之间的比率。另外,平台化复用视角不应该局限于业务页面的复用,对于监控、测试、研发工具、运维工具等也可以进行复用,这也是平台化复用理念的核心价值所在。
参考资料
美团外卖Android平台化架构演进实践
美团外卖自2013年创建以来,业务一直高速发展。目前美团外卖日完成订单量已突破1800万,成为美团点评最重要的业务之一。美团外卖的用户端入口,从单一的外卖独立App,拓展为外卖、美团、点评等多个App入口。美团外卖所承载的业务,也从单一的餐饮业务,发展到餐饮、超市、生鲜、果蔬、药品、鲜花、蛋糕、跑腿等十多个大品类业务。业务的快速发展对客户端架构不断提出新的挑战。
平台化背景
很早之前,外卖作为孵化中的项目只有美团外卖App(下文简称外卖App)一个入口,后来外卖作为一个子频道接入到美团App(下文简称外卖频道),两端业务并行迭代开发。早期为了快速上线,开发同学直接将外卖App的代码拷贝出一份到外卖频道,做了简单的适配就很快接入到美团App了。
早期外卖App和外卖频道由两个团队分别维护,而在随后一段时间里,两端代码体系差异越来越来大。最后演变成了从网络、图片等基础库到UI控件、类的命名等都不尽相同的两套代码。尽管后来两个团队合并到一起,但历史的差异已经形成,为了优先满足业务需求,很长一段时间内,我们只能在两套代码的基础上不断堆积更多的功能。维护两套代码的成本可想而知,而业务的迅猛发展又使得这一问题越发不可忍受。
在我们探索解决两端代码复用的同时,业务的发展又对我们提出新的挑战。随着团队成员扩充了数倍,商超生鲜等垂直品类的拆分,以及异地研发团队的建立,外卖客户端的平台化被提上日程。而在此之前,外卖App和外卖频道基本保持单工程开发,这样的模式显然是无法支持多团队协作开发的。因此,我们需要快速将代码重构为支持平台化的多工程模式,同时还要考虑业务模块的解耦,使得新业务可以拷贝现有的代码快速上线。此外,在实施平台化的过程中,两端代码复用的问题还没有解决,如果两端的代码没有统一而直接做平台化业务拆库,必然会导致问题的复杂化。
在这样的背景下,可以看出我们面临的问题相较于其他平台型App更为特殊和复杂:既要解决外卖业务平台化的问题,又要解决外卖App和外卖频道两端代码复用的问题。
屡次探索
在实施平台化和两端代码复用的道路上并非一帆风顺,很多方案只有在尝试之后才知道问题所在。我们多次遇到这样的情况:设计方案完成后,团队已经全身心投入到开发之中,但是由于业务形态发生变化,原有的设计也被迫更改。在不断的探索和实践过程中,我们经历了多个中间阶段。虽然有不少失败的案例,但是也积累了很多架构设计上的宝贵经验,整个团队对业务和架构也有了更深的理解。
搜索库拆分实践
早期美团外卖App和美团外卖频道两个团队的合并,带来的最大痛点是代码复用,而非平台化,而在很长的一段时间内,我们也没有想过从平台化的角度去解决两端代码复用的问题。然而代码复用的一些失败尝试,给后续平台化的架构带来了不少宝贵的经验。当时是怎么解决代码复用问题的呢?我们通过和产品、设计同学的沟通,约定了未来的需求,会从需求内容、交互、样式上,两端尽可能的保持一致。经过多次讨论后,团队发起了两端代码复用的技术方案尝试,我们决定将搜索模块从主工程拆分出来,并实现两端代码复用。然而两端的搜索模块代码底层差异很大,BaseActivity和BaseFragment不统一,UI样式不统一,数据Model不统一,图片、网络、埋点不统一,并且两端发版周期也不一致。针对这些问题的解决方案是:
- 通过代理屏蔽Activity和Fragment基类不统一的问题;
- 两端主工程style覆盖搜索库的UI样式;
- 搜索库使用独立的数据Model,上层去做数据适配;
- 其他差异通通抛出接口让上层实现;
- 和PM沟通尽量使产品需求和发版周期一致。
架构大致如图:
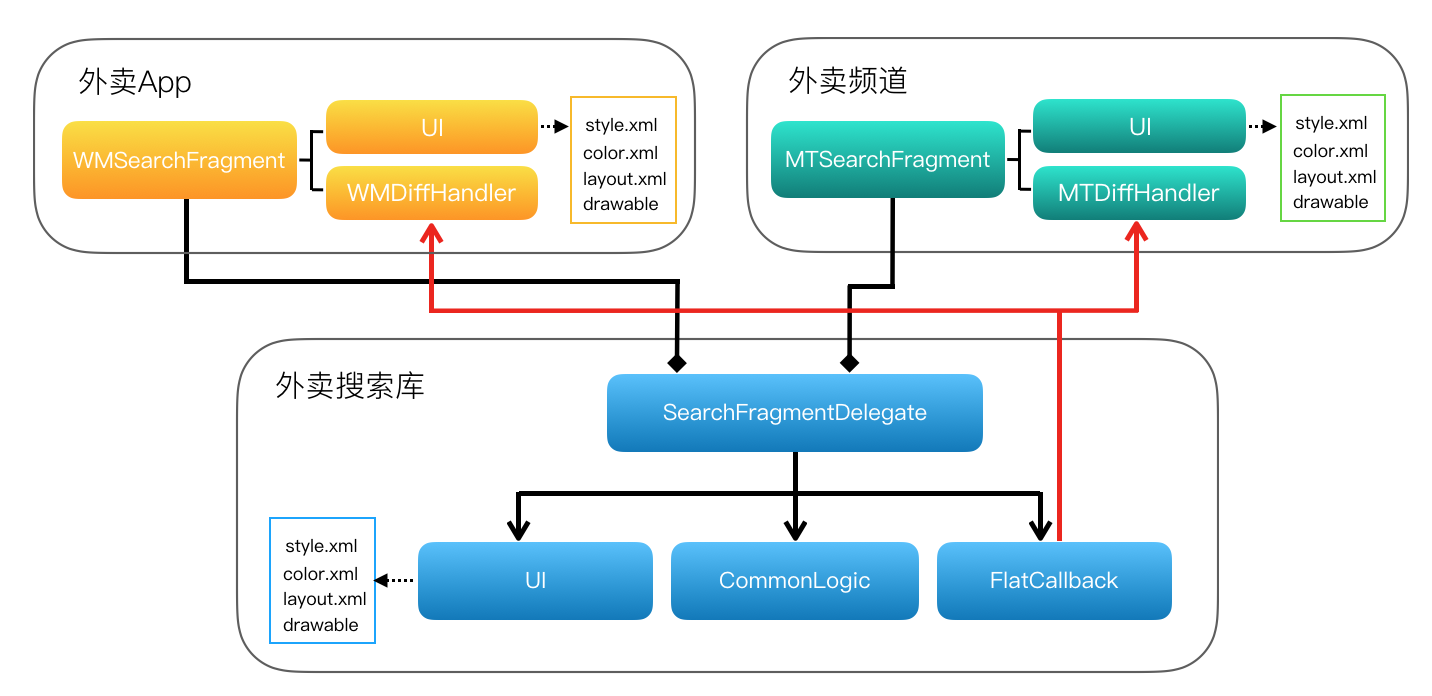
虽然搜索库在短期内拆分为独立的工程,并实现了绝大部分的两端代码复用,但是好景不长,仅仅更新过几个版本后,由于需求和版本发布周期的差异,搜索库开始变为两个分支,并且两个分支的差异越来越大,最后代码无法合并而不得不永久维护两个搜索库。搜索库事实上是一次失败的拆分,其中的问题总结起来有三个:
- 在两端底层差异巨大的情况下自上而下的强行拆分,导致大量实现和适配留在了两端主工程实现,这样的设计层级混乱,边界模糊,并且极大的增加了业务开发的复杂性;
- 寄希望于两端需求和发版周期完全一致这个想法不切实际,如果在架构上不为两端的差异性预留可伸缩的空间,复用最终是难以持续的;
- 约定或规范,受限于组织架构和具体执行的个人,不确定性太高。
页面组件化实践
在经历过搜索库的失败拆分后,大家认为目前还不具备实现模块整体拆分和复用的条件,因此我们走向了另一个方向,即实现页面的组件化以达成部分组件复用的目标。页面组件化的设计思路是:
- 将页面拆分为粒度更小的组件,组件内部除了包含UI实现,还包含数据层和逻辑层;
- 组件提供个性化配置满足两端差异需求,如果无法满足再通过代理抛到上层处理。
页面组件化是一个良好的设计,但它主要适用于解决Activity巨大化的问题。由于底层差异巨大的情况,使得页面组件化很难实现大规模的复用,复用效率低。另一方面,页面组件化也没有为2端差异性预留可伸缩的空间。
MVP分层复用实践
我们还尝试过运用设计模式解决两端代码复用的问题。想法是将代码分为易变的和稳定的两部分,易变部分在两端上层实现差异化处理,稳定部分可以在下层实现复用。方案的主要设计思路是:
- 借鉴Clean MVP架构,根据职责将代码拆分为Presenter,Data Repository,Use Case,View,Model等角色;
- UI、动画、数据请求等逻辑在下层仅保留接口,在上层实现并注入到下层;
- 对于两端不一致的数据Model,通过转换器适配为下层统一的模型。
架构大致如图:
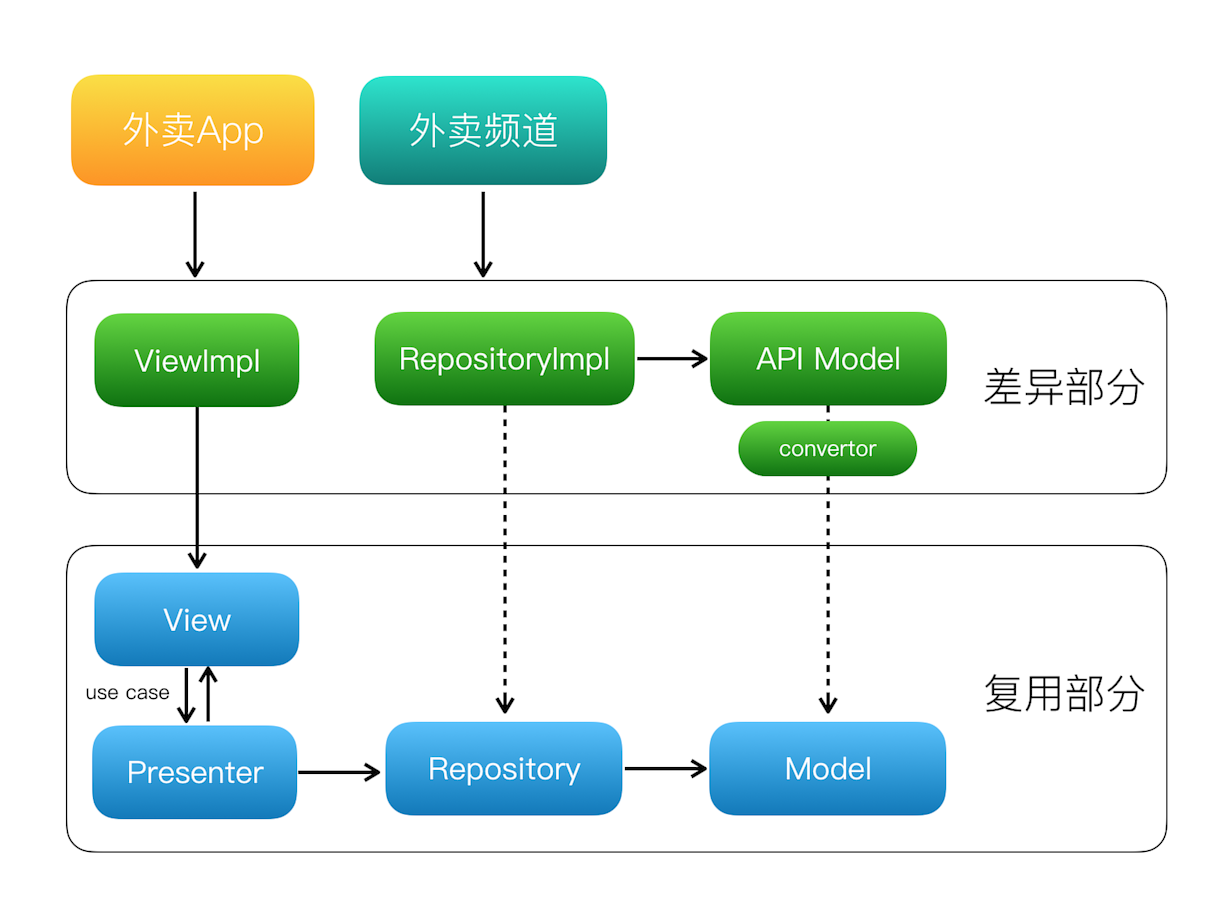
这是一种灵活、优雅的设计,能够实现部分代码的复用,并能解决两端基础库和UI等差异。这个方案在首页和二级频道页的部分模块使用了一段时间,但是因为学习成本较高等原因推广比较缓慢。另外,这个时期平台化已被提上日程,业务痛点决定了我们必须快速实施模块整体的拆分和复用,而优雅的设计模式并不适合解决这一类问题。即使从复用性的角度来看,这样的设计也会使得业务开发变得更为复杂、调试困难,对于新人来说难以胜任,最终推广落地困难。
中间层实践
通过多次实践,我们认识到要实现两端代码复用,基础库的统一是必然的工作,是其他一切工作的基础。否则必然导致复杂和难以维护的设计,最终导致两端复用无法快速推进下去。
计算机界有一句名言:“计算机科学领域的任何问题都可以通过增加一个中间层来解决。”(原始版本出自计算机科学家David Wheeler)我们当然有想过通过中间层设计屏蔽两端的基础库差异。例如网络库,外卖App基于Volley实现,外卖频道基于Retrofit实现。我们曾经在Volley和Retrofit之上封装了一层网络框架,对外暴露统一的接口,上层可以切换底层依赖Volley或是Retrofit。但这个中间层并没有上线,最终我们将两端的网络库统一成了Retrofit。这里面有多个原因:首先Retrofit本身就是较高层次的封装,并且拥有优雅的设计模式,理论上我们很难封装一套扩展性更强的接口;其次长期来看底层网络框架变更的风险极低,并且适配网络层的各种插件也是一件费时费力的事情,因此保持网络中间层的性价比极低;此外将两端的网络请求都替换为中间层接口,显然工作量远大于只保留一端的依赖。
通过实践我们认识到,中间层设计是一把双刃剑。如果基础框架本身的扩展性足够强,中间层设计就显得多此一举,甚至丧失了原有框架的良好特性。
平台化实践
好的架构源于不停地衍变,而非设计。对于外卖Android客户端的平台化架构构建也是经历了同样的过程。我们从考虑如何解决代码复用的问题,逐渐的衍变成如何去解决代码复用和平台化的两个问题。而实际上外卖平台化正是解决两端代码复用的一剂良药。我们通过建立外卖平台,将现有的外卖业务降级为一个频道,将外卖业务以aar的形式分别接入到外卖平台和美团平台,这样在解决外卖平台化的同时,代码复用的问题也将得到完美的解决。
平台化架构
经过了整整一年的艰苦奋斗,形成了如图所示的美团外卖Android客户端平台化架构:
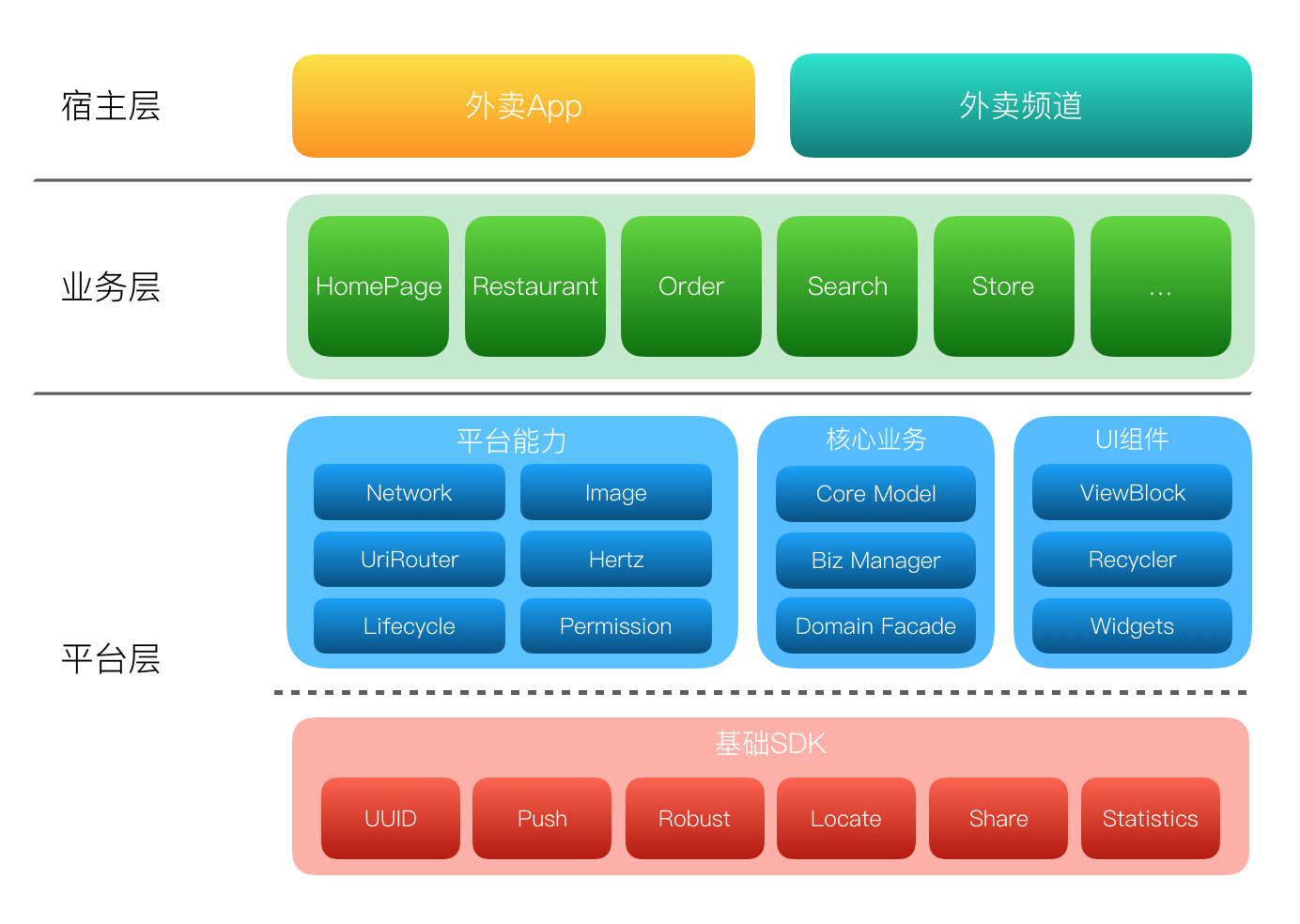
从底层到高层依次为平台层、业务层和宿主层。
- 平台层的内容包括,承载上层的数据通信和页面跳转;提供外卖核心服务,例如商品管理、订单管理、购物车管理等;提供配置管理服务;提供统一的基础设施能力,例如网络、图片、监控、报警、定位、分享、热修、埋点、Crash上报等;提供其他管理能力,例如生命周期管理、组件化等。
- 业务层的内容包括,外卖业务和垂直业务。
- 宿主层的内容包括,Waimai App壳和美团外卖频道Waimai-channel壳,这一层用于Application的初始化、dex加载和其他各种必要的组件或基础库的初始化。
在构建平台化架构的过程中,我们遇到这样一个问题,如何长久的维持我们平台化架构的层级边界。试想,如果所有的代码都在一个工程里面开发,通过包名、约定去规范层级边界,任何一个紧急的需求都可能破坏层级边界。维持层级边界的最好办法是什么?我们的经验是工程隔离。平台化的每一层都去做工程隔离,业务层的每个业务都建立自己的工程库,实现工程隔离。同时,配套编译脚本,检查业务库之间是否存在相互依赖关系。工程隔离的好处是显而易见的:
- 每个工程都可以独立编译、独立打包;
- 每个工程内部的修改,不会影响其他工程;
- 业务库工程可以快速拆分出来,集成到其他App中。
但工程隔离带来的另一个问题是,同层间的业务库需要通信怎么办?这时候就需要提供业务库通信框架来解决这个问题。
业务库通信框架
在拆分外卖商家业务库的时候,我们就发这样一个案例:在商家页有一个业务,当发现当前商家是打烊的,就会弹出一个浮层,推荐相似的商家列表,而在我们之前划分的外卖子业务库里面,相似商家列表应该是属于页面库里面的内容。那怎么让商家业务库访问到页面库里面的代码呢。如果我们将商家库去依赖页面库,那我们的层级边界就会被打破,我们的依赖关系也会变得复杂。因此我们需要在架构中提供同层间的通信框架,它去解决不打破层级边界的情况下,完成同层间的通信。
汇总同层间通信的场景,大致上可以划分为:页面的跳转、基本数据类型的传递(包括可序列化的共有类对象的传递)、模块内部自定义方法和类的调用。针对上述情况,在我们的架构里面提供了二种平级间的通信方式:scheme路由和美团自建的ServiceLoaders sdk。scheme路由本质上是利用Android的scheme原理进行通信,ServiceLoader本质上是利用的Java反射机制进行通信。
scheme路由的调用如图所示:
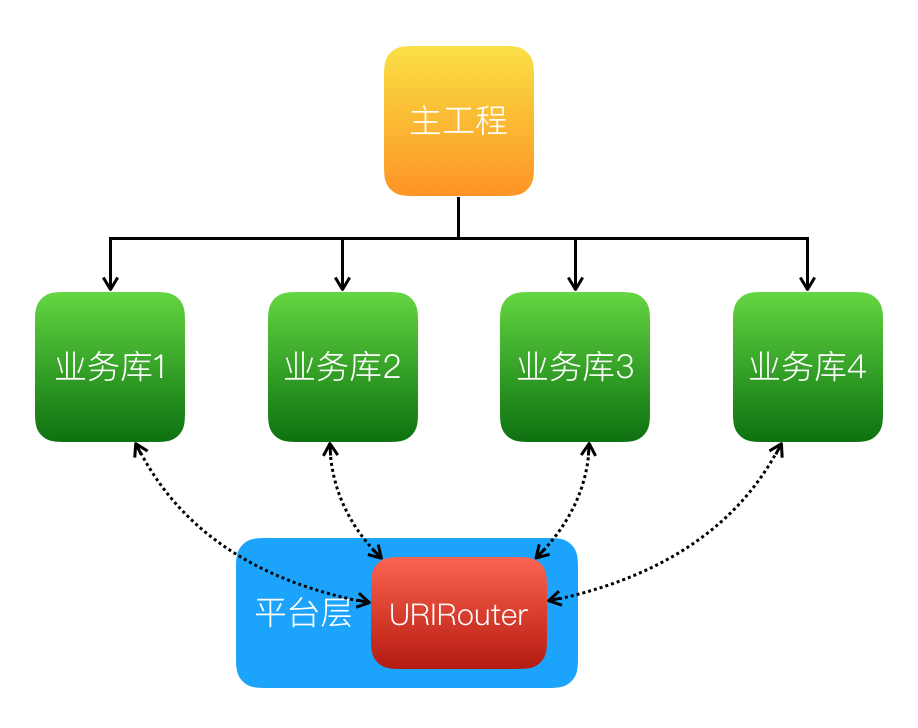
最终效果:所有业务页面的跳转,都需要通过平台层的scheme路由去分发。通过scheme路由,所有业务都得到解耦,不再需要相互依赖而可以实现页面的跳转和基本数据类型的传递。
serviceloader的调用如图所示:
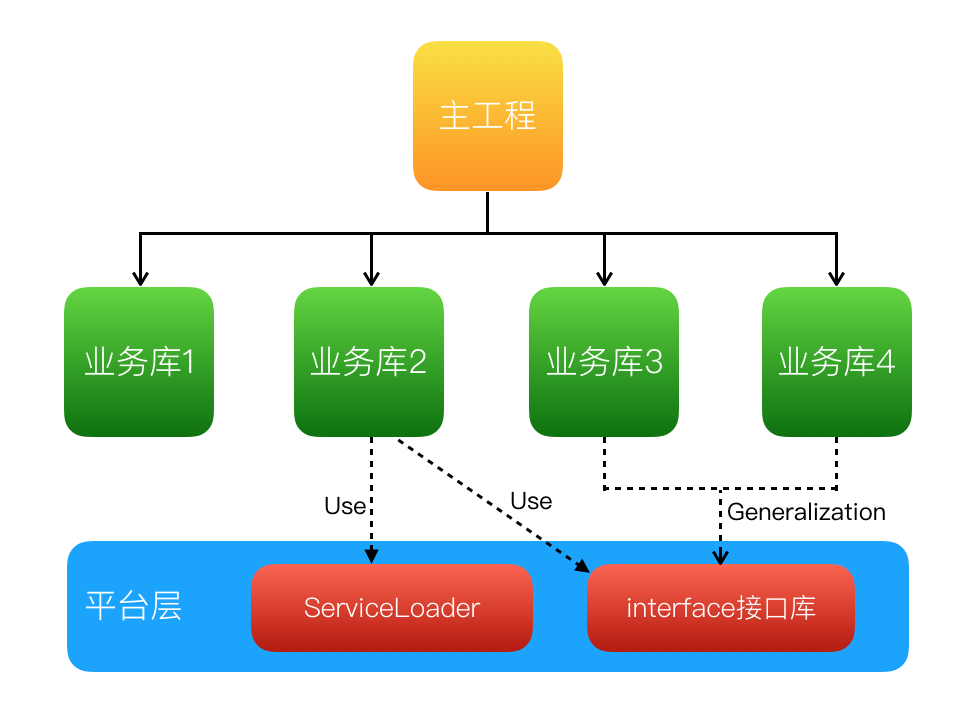
提供方和使用方通过平台层的一个接口作为双方交互的约束。使用方通过平台层的ServiceLoader完成提供方的实现对象获取。这种方式可以解决模块内部自定义方法和类的调用,例如我们之前提到了商家库需要调用页面库代码的问题就可以通过ServiceLoader解决。
外卖内核模块设计
在实践的过程中,我们也遇到业务本身上就不好划分层级边界的业务。大家可以从美团外卖三层架构图上,看出外卖业务库,像商家、订单等,是和外卖的垂类业务库是同级的。而实际上外卖业务的子业务是否应该和垂类业务保持同层是一个目前无法确定的事情。
目前,外卖接入的垂类业务商超业务,是隶属于外卖业务的子频道,它依然依赖着外卖的核心model、核心服务,包括商品管理、订单管理、购物车管理等,因此目前它和外卖业务的商家、订单这样的子业务库同层是没有问题的。但随着商超业务的发展,商超业务未来可能会建设自己的商品管理、订单管理、购物车管理的服务,那么到时商超业务就会上升到和外卖业务一样同层的业务。这时候,外卖核心管理服务,处在平台层,就会导致架构的层级边界变得不再清晰。
我们的解决办法是通过设计一个属于外卖业务的内核模块来适应未来的变化,内核模块的设计如图:
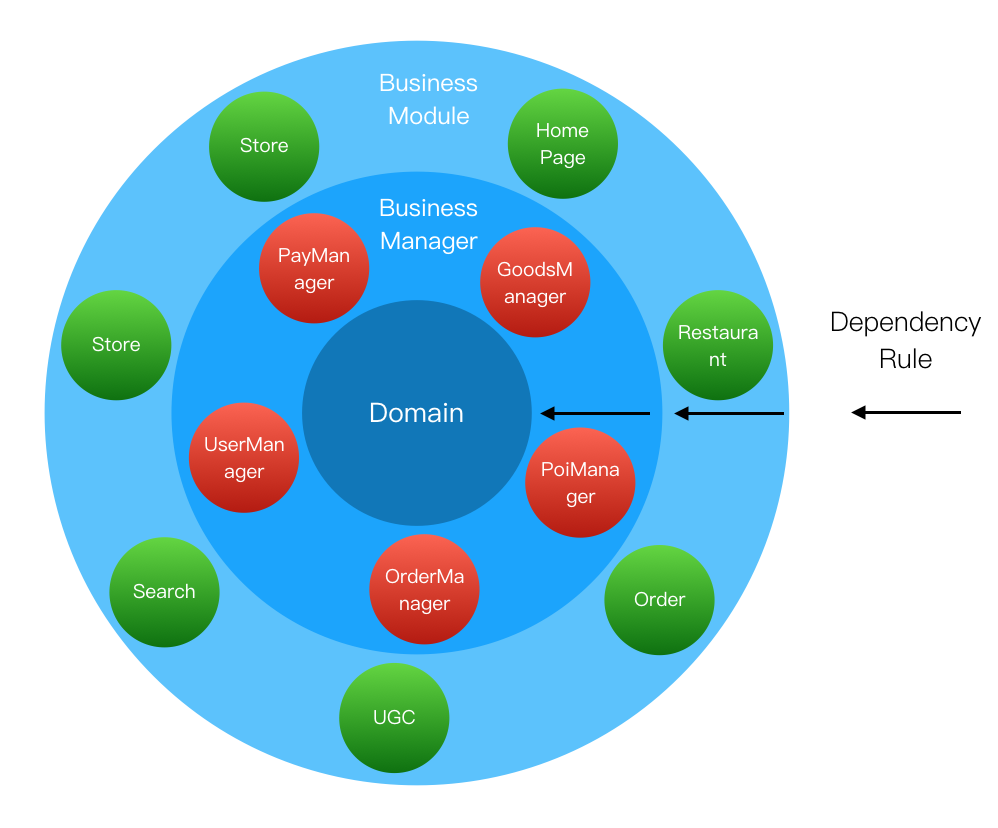
- 内圈为基础模型类,这些模型类构成了外卖核心业务(从门店→点菜→购物车→订单)的基础;
- 中间圈为依赖基础模型类构建的基础服务(CRUD);
- 最外圈为外卖的各维度业务,向内依赖基础模型圈和外卖基础服务圈。
如果未来确定外卖平台需要接入更多和外卖平级的业务,且最内圈都完全不一样,我们将把外卖内核模块上移,在外卖业务子库下建立对内核模块的依赖;如果未来只是有更多的外卖子业务的接入,那就继续保留我们现在的架构;如果未来接入的业务基础模型类一样,但自己的业务服务需要分化,那么我们将对保留内核模块最核心的内圈,并抽象出服务层由外卖和商超上层自己实现真正的服务。
业务库拆分
在拆分业务库的时候,我们面临着这样的问题:业务之间的关系是较为复杂的,如何去拆分业务库,才是较为合理的呢?一开始我们准备根据外卖业务核心流程:页面→商家→下单,去拆分外卖业务。但是随着外卖子频道业务的快速发展,子频道业务也建立了自己的研发团队,在页面、商家、下单等环节,也开始建立自己的页面。如果我们仍然按照外卖下单的流程去拆分库,那在同一个库之间,就会有外卖团队和外卖子频道团队共同开发的情况,这样职责边界很不清晰,在实际的开发过程中,肯定会出现理不清的情况。
我们都知道软件工程领域有所谓的康威定律:
Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations. - Melvin Conway(1967)
翻译成中文的大概意思是:设计系统的组织,其产生的设计等同于组织之内、组织之间的沟通结构。
在康威定理的指导下:我们认为技术架构应该反映出团队的组织结构,同时,组织结构的变迁,也应该导致技术架构的演进。美团外卖平台下包含外卖业务和垂直品类业务,对于在我们团队中已经有了组织结构,优先组织结构,去拆出独立的业务库,方便子业务库的同学内部沟通协作,减少他们跨组织沟通的成本。同时,我们将负责外卖业务的大团队,再进一步细化成页面小组、商家小组和订单小组,由这些小组的同学去在外卖业务下完成更细维度的外卖子业务库拆分。根据组织结构划分的业务库,天然的存在业务边界,每个同学都会按照自己业务的目标去继续完善自己的业务库。这样的拆库对内是高内聚,对外是低耦合的,有效的降低了内外沟通协作的成本。
工程内代码隔离
在实现工程隔离之后,我们发现工程内部的代码还是可以相互引用的。工程内部如果也不能实现代码的隔离,那么工程内部的边界就是模糊的。我们希望工程内至少能够实现页面级别的代码隔离,因为Activity是组成一个App的页面单元,围绕这个Activity,通常会有大量的代码及资源文件,我们希望这些代码和资源文件是被集中管理的。
通常我们想到的做法是以module工程为单位的相互隔离,但在module是相对比较重的一个约束,难道每个Activity都要建一个module吗?这样代码结构会变得很复杂,而且针对一些大的业务体,又会形成巨大化的module。
那我们又想到规范代码,用包名去人为约定,但靠包名约束的代码,边界模糊,时不时的紧急需求,就把包名约定打破了,而且资源文件的摆放也是任意的,迁移成本高。
那怎么去解决工程内部的边界问题呢?《微信的模块化架构重构实践》一文中提到了一个重要的概念p(pins)工程,p工程可谓是工程内约束代码边界的重要法宝。通过在Gradle里面配置sourceSets,就可以改变工程内的代码结构目录,完成代码的隔离,配置示例:
sourceSets {
main {
def dirs = ['p_widget', 'p_theme',
'p_shop', 'p_shopcart',
'p_submit_order','p_multperson','p_again_order',
'p_location', 'p_log','p_ugc','p_im','p_share']
dirs.each { dir ->
java.srcDir("src/$dir/java")
res.srcDir("src/$dir/res")
}
}
}
效果如图所示:
从图上可以可以看出,这个业务库被以页面为单元拆分成了多个p工程,每个p工程的边界都是清楚的,实现了工程内的代码隔离。工程内代码隔离带来的好处显而易见:
- p工程实现了最小粒度的代码边界约束;
- 工程内模块职责清晰;
- 业务模块可以被快速的拆分出来。
代码复用
p工程满足了工程内代码隔离的需求,但是别忘了,我们每个模块在外卖两个终端上(外卖App&美团App)上可能存在差异,如果能在模块内部实现两端差异,我们的目标才算达成。基于上述考虑,我们想到了使用Gradle提供的productFlavors来实现两端的差异化。为此,我们需要定义两个flavor:wm和mt。
productFlavors {
wm {}
mt {}
}
但是,这样生成的p工程是并列的,也就是说,各个p工程中所有的差异化代码都需要被存放在这两个flavor对应的SourceSet下,这岂不是跟模块间代码隔离的理念相违背?理想的结构是在p工程内部进行flavor划分,由p工程内部包容差异化,继续改成Gradle脚本如下:
productFlavors {
wm {}
mt {}
}
sourceSets {
def dirs = ['p_restaurant', 'p_goods_detail', 'p_comment', 'p_compose_order',
'p_shopping_cart', 'p_base', 'p_product_set']
main {
manifest.srcFile 'src/p_restaurant/main/AndroidManifest.xml'
dirs.each { dir ->
java.srcDir("src/${dir}/main/java")
res.srcDir("src/${dir}/main/res")
}
}
wm {
dirs.each { dir ->
java.srcDir("src/${dir}/wm/java")
res.srcDir("src/${dir}/wm/res")
}
}
mt {
dirs.each { dir ->
java.srcDir("src/${dir}/mt/java")
res.srcDir("src/${dir}/mt/res")
}
}
}
最终工程结构变成如下:
通过p工程和flavor的灵活应用,我们最终将业务库配置成以p工程为维度的模块单元,并在p工程内部兼容两端的共性及差异,代码复用被很好的解决了。同时,两端差异的问题是归属在p工程内部自己处理的,并没有建立中间层,或将差异抛给上层壳工程去完成,这样的设计遵守了边界清晰,向下依赖的原则。
但是,工程内隔离也存在与工程隔离一样的问题:同层级p工程需要通信怎么办?我们在拆分商家库的时候,就面临这这样的问题,商品活动页和商品详情页,可以根据页面维度,去拆分成2个p工程,这两个页面都会用到同一个商品样式的item。如何让同层间商品活动页p工程和商品详情页p工程访问到商品样式item呢?在实际拆库的实践中,我们逐渐的探索出三级工程结构。三级工程结构不仅可以解决工程内p工程通信的问题,而且可以保持架构的灵活性。
三级工程结构
三级工程结构,指的是工程→module→p工程的三级结构。我们可以将任何一个非常复杂的业务工程内部划分成若干个独立单元的module工程,同时独立单元的module工程,我们可以继续去划分它内部的独立p工程。因为module是具备编译时的代码隔离的,边界是不容易被打破的,它可以随时升级为一个工程。需要通信的p工程依赖module的主目录,base目录,通过base目录实现通信。工程和module具有编译上隔离代码的能力,p工程具有最小约束代码边界的能力,这样的设计可以使得工程内边界清晰,向下依赖。设计如图所示:
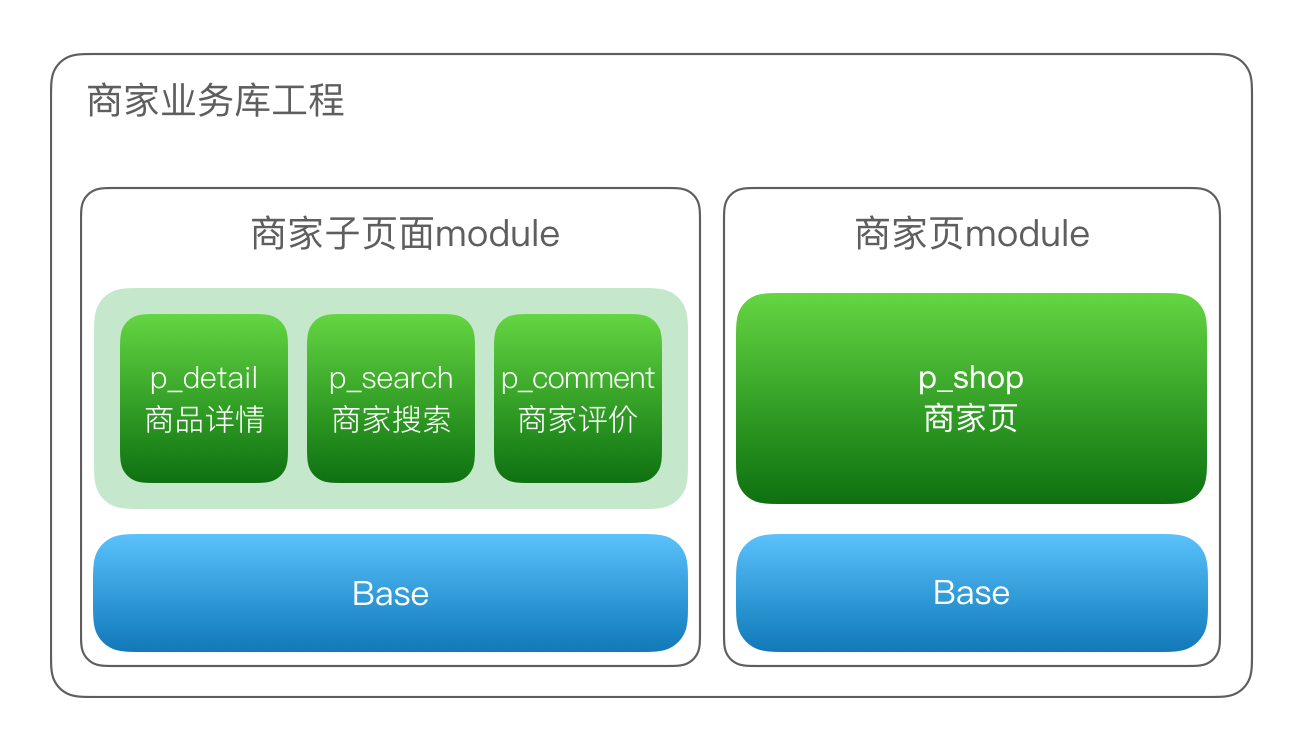
三级工程结构的最大好处就是,每级都可按照需要灵活的升级或降级,这样灵活的升降级,可以随时适应团队组织结构的变化,保持架构拆分合并的灵活性,从而动态的满足了康威定理。
工程化建设
平台化一个直观的结果就是产生了很多子库,如何对这些子库进行有效的工程化管理将是一个影响团队研发效率的问题。目前为止,我们从以下两个方面做了改进。
一键切源码
主工程集成业务库时,有两种依赖模式:aar依赖和源码依赖。默认是aar依赖,但是在平时开发时,经常需要从aar依赖切换到源码依赖,比如新需求开发、bugfix及排查问题等。正常情况我们需要在各个工程的build.
中将compile aar手动改为compile project,如果业务库也需要依赖平台库源码,也要做类似的操作。如下图所示:
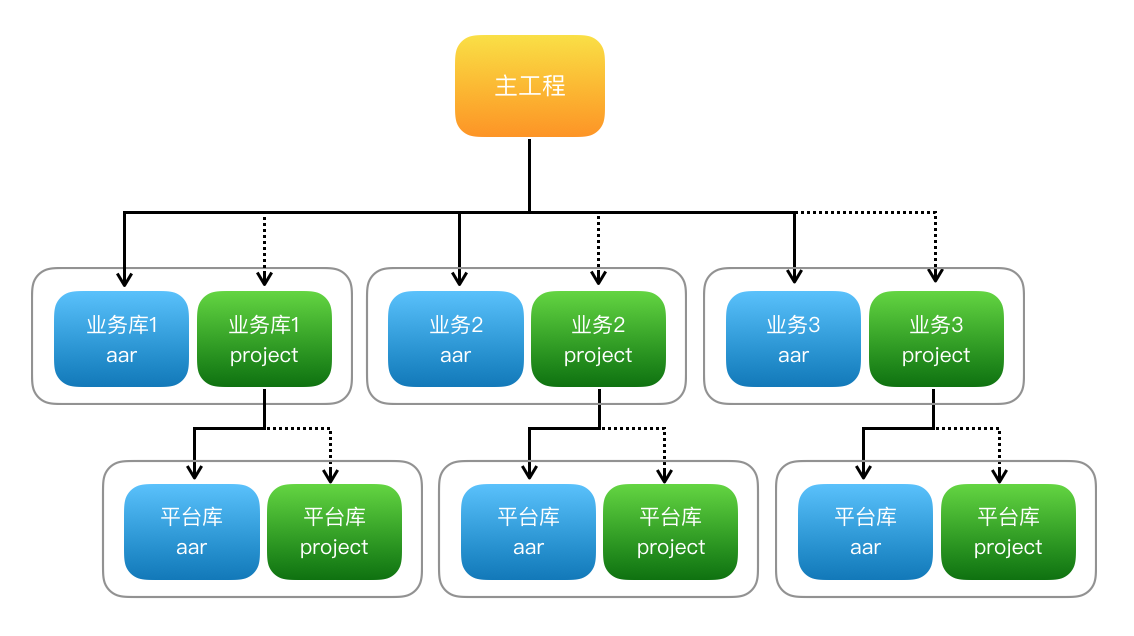
这样手动操作会带来两个问题:
- build.gradle改动频繁,如果开发人员不小心push上去了,将会造成各种冲突。
- 当业务库越来越多时,这种改动的成本就越来越大了。
鉴于这种需求具备通用性,我们开发了一个Gradle插件,通过主工程的一个配置文件(被git ignore),可一键切换至源码依赖。例如需要源码依赖商家库,那么只需要在主工程中将该库的源码依赖开关打开即可。商家库还依赖平台库,默认也是aar依赖,如果想改成源码依赖,也只需把开关打开即可。
一键打包
业务库增多以后,构建流程也变得复杂起来,我们交付的产物有两种:外卖App的apk和外卖频道的aar。外卖App的情况会简单一些,在Jenkins上关联各个业务库指定分支的源码,直接打包即可。而外卖频道的情况则比较复杂,因为受到美团平台的一些限制,频道打包不能直接关联各个业务库的源码,只能依赖aar。按照传统做法,需要逐个打业务库的aar,然后统一在频道工程中集成,最后再打频道aar,这样效率实在太低。为此,我们改进了频道的打包流程。如下图所示:
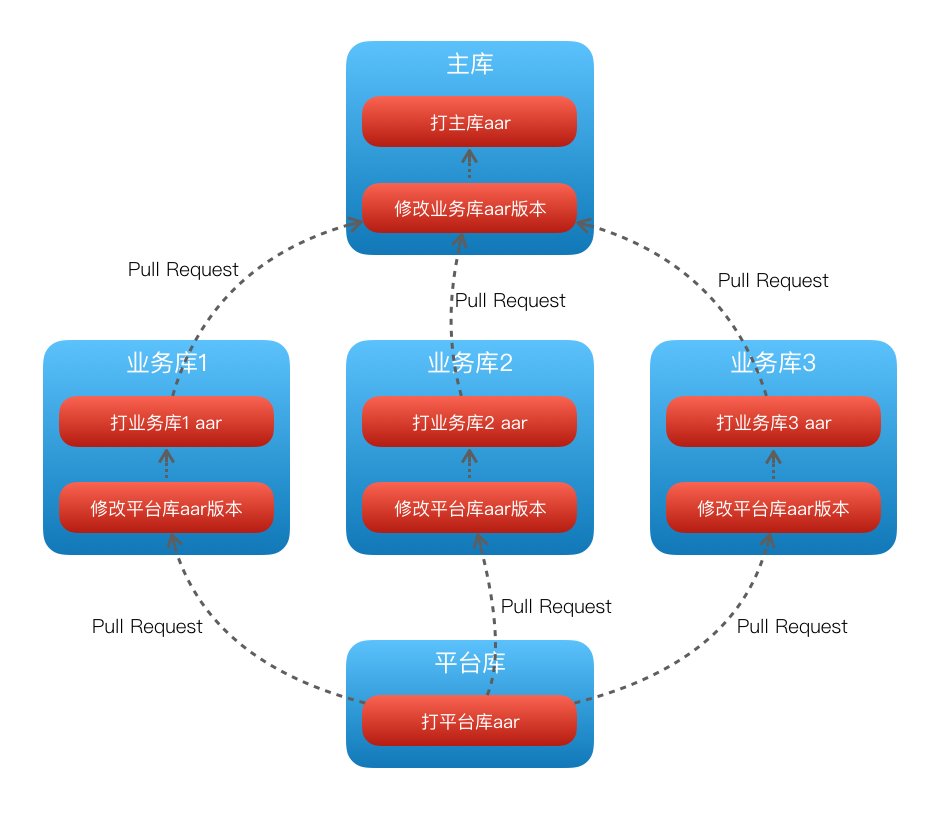
先打平台库aar,打完后自动提PR到各个业务库去修改平台库的版本号,接着再逐个触发业务库去打aar,业务库打完aar之后再自动提PR到频道主库去修改业务库的版本号,等全部业务库aar打完后最后再自动触发打频道主库的aar,至此一键打包完毕。
平台化总结
从搜索库拆分的第一次尝试算起,外卖Android客户端在架构上的持续探索和实践已经经历了2年多的时间。起初为了解决两端代码复用的问题,我们尝试过自上而下的强行拆分和复用,但很快就暴露出层次混乱、边界模糊带来的问题,并且认识到如果不能提供两端差异化的解决方案,代码复用是很难持续的。后来我们又尝试过运用设计模式约束边界,先实现解耦再进行复用,但在推广落地过程中认识到复杂的设计很难快速推进下去。
在平台化开始的时候,团队已经形成了设计简单、边界清晰的架构理念。我们将整体结构划分为宿主层、业务层、平台层,并严格约束层次间的依赖关系。在业务模块拆分的过程中,我们借鉴微信的工程结构方案,按照三级工程结构划分业务边界,实现灵活的代码隔离,并降低了后续模块迁出和迁入成本,使得架构动态满足康威定律。
在两端代码复用的问题上,我们认识到要实现可持续的代码复用,必须自下向上的逐步统一两端底层的基础依赖,同时又能容易的支持两端上层业务的差异化处理。使用Flavor管理两端的差异代码,尽量减少向上依赖,在具体实施时应用之前积累的解耦设计的经验,从而满足了架构的可伸缩性。
没有一个方案能获得每个人的赞同。在平台化的实施过程中,团队成员多次对方案选型发生过针锋相对的讨论。这时我们会抛开技术方案,回到问题本身,去重新审视业务的痛点,列出要解决的问题,再回过头来看哪一个方案能够解决问题。虽然我们并不常常这么做,但某些时刻也会强制决策和实施,遇到问题再复盘和调整。
任何一种设计理念都有其适用场景。我们在不断关注业内一些优秀的架构和设计理念,以及公司内部美团App、点评App团队的平台化实践经验,学习和借鉴了许多优秀的设计思想,但也由于盲目滥用踩过不少坑。我们认识到架构的选择正如其他技术问题一样,应该是面向问题的,而不是面向技术本身。架构的演进必须在理论和实践中交替前行,脱离了其中一个谈论架构,都将是个悲剧。
展望
平台化之后,各业务团队的协作关系和开发流程都发生了很大转变。在如何提升平台支持能力,如何保持架构的稳定性,如何使得各业务进一步解耦等问题上,我们又将面对新的问题和挑战。其中有三个问题是亟待我们解决的:
- 要确保在长期的业务迭代中架构不被破坏,除了流程规范之外,还需要在本地编译、远程提交、代码合并、打包提测等各个阶段建立更健全的检查工具来约束,而目前这些工具链还并不完善。
- 插件化架构是平台型App集成的最好方式,不仅使得子业务具备动态发布的能力,还可以解决令人头疼的编译速度问题。目前美团平台已经在部分业务上较好的实现了插件化集成,外卖正在跟进。
- 统一页面级开发的标准化框架,可以解决代码的可维护性、可测试性,和更细粒度的可复用性,并且有利于各种自动化方案的实施。目前我们正在部分业务尝试,后续会持续推进。
参考资料
- MVP + Clean Architecture
- 58同城沈剑:好的架构源于不停地衍变,而非设计
- 每个架构师都应该研究下康威定理
- 微服务架构的理论基础 - 康威定律
- 架构的本质是管理复杂性,微服务本身也是架构演化的结果
- 微信Android模块化架构重构实践
- 配置构建变体
- 美团App 插件化实践
美团外卖Android Lint代码检查实践
概述
Lint是Google提供的Android静态代码检查工具,可以扫描并发现代码中潜在的问题,提醒开发人员及早修正,提高代码质量。除了Android原生提供的几百个Lint规则,还可以开发自定义Lint规则以满足实际需要。
为什么要使用Lint
在美团外卖Android App的迭代过程中,线上问题频繁发生。开发时很容易写出一些问题代码,例如Serializable的使用:实现了Serializable接口的类,如果其成员变量引用的对象没有实现Serializable接口,序列化时就会Crash。我们对一些常见问题的原因和解决方法做分析总结,并在开发人员组内或跟测试人员一起分享交流,帮助相关人员主动避免这些问题。
为了进一步减少问题发生,我们逐步完善了一些规范,包括制定代码规范,加强代码Review,完善测试流程等。但这些措施仍然存在各种不足,包括代码规范难以实施,沟通成本高,特别是开发人员变动频繁导致反复沟通等,因此其效果有限,相似问题仍然不时发生。另一方面,越来越多的总结、规范文档,对于组内新人也产生了不小的学习压力。
有没有办法从技术角度减少或减轻上述问题呢?
我们调研发现,静态代码检查是一个很好的思路。静态代码检查框架有很多种,例如FindBugs、PMD、Coverity,主要用于检查Java源文件或class文件;再例如Checkstyle,主要关注代码风格;但我们最终选择从Lint框架入手,因为它有诸多优势:
- 功能强大,Lint支持Java源文件、class文件、资源文件、Gradle等文件的检查。
- 扩展性强,支持开发自定义Lint规则。
- 配套工具完善,Android Studio、Android Gradle插件原生支持Lint工具。
- Lint专为Android设计,原生提供了几百个实用的Android相关检查规则。
- 有Google官方的支持,会和Android开发工具一起升级完善。
在对Lint进行了充分的技术调研后,我们根据实际遇到的问题,又做了一些更深入的思考,包括应该用Lint解决哪些问题,怎么样更好的推广实施等,逐步形成了一套较为全面有效的方案。
Lint API简介
为了方便后文的理解,我们先简单看一下Lint提供的主要API。
主要API
Lint规则通过调用Lint API实现,其中最主要的几个API如下:
- Issue:表示一个Lint规则。
- Detector:用于检测并报告代码中的Issue,每个Issue都要指定Detector。
- Scope:声明Detector要扫描的代码范围,例如
JAVA_FILE_SCOPE、CLASS_FILE_SCOPE、RESOURCE_FILE_SCOPE、GRADLE_SCOPE等,一个Issue可包含一到多个Scope。 - Scanner:用于扫描并发现代码中的Issue,每个Detector可以实现一到多个Scanner。
- IssueRegistry:Lint规则加载的入口,提供要检查的Issue列表。
举例来说,原生的ShowToast就是一个Issue,该规则检查调用Toast.makeText()方法后是否漏掉了Toast.show()的调用。其Detector为ToastDetector,要检查的Scope为JAVA_FILE_SCOPE,ToastDetector实现了JavaPsiScanner,示意代码如下:
public class ToastDetector extends Detector implements JavaPsiScanner {
public static final Issue ISSUE = Issue.create(
"ShowToast",
"Toast created but not shown",
"...",
Category.CORRECTNESS,
6,
Severity.WARNING,
new Implementation(
ToastDetector.class,
Scope.JAVA_FILE_SCOPE));
// ...
}
IssueRegistry的示意代码如下:
public class MyIssueRegistry extends IssueRegistry {
@Override
public List<Issue> getIssues() {
return Arrays.asList(
ToastDetector.ISSUE,
LogDetector.ISSUE,
// ...
);
}
}
Scanner
Lint开发过程中最主要的工作就是实现Scanner。Lint中包括多种类型的Scanner如下,其中最常用的是扫描Java源文件和XML文件的Scanner。
- JavaScanner / JavaPsiScanner / UastScanner:扫描Java源文件
- XmlScanner:扫描XML文件
- ClassScanner:扫描class文件
- BinaryResourceScanner:扫描二进制资源文件
- ResourceFolderScanner:扫描资源文件夹
- GradleScanner:扫描Gradle脚本
- OtherFileScanner:扫描其他类型文件
值得注意的是,扫描Java源文件的Scanner先后经历了三个版本。
- 最开始使用的是JavaScanner,Lint通过Lombok库将Java源码解析成AST(抽象语法树),然后由JavaScanner扫描。
- 在Android Studio 2.2和lint-api 25.2.0版本中,Lint工具将Lombok AST替换为PSI,同时弃用JavaScanner,推荐使用JavaPsiScanner。 PSI是JetBrains在IDEA中解析Java源码生成语法树后提供的API。相比之前的Lombok AST,PSI可以支持Java 1.8、类型解析等。使用JavaPsiScanner实现的自定义Lint规则,可以被加载到Android Studio 2.2+版本中,在编写Android代码时实时执行。
- 在Android Studio 3.0和lint-api 25.4.0版本中,Lint工具将PSI替换为UAST,同时推荐使用新的UastScanner。 UAST是JetBrains在IDEA新版本中用于替换PSI的API。UAST更加语言无关,除了支持Java,还可以支持Kotlin。
本文目前仍然基于PsiJavaScanner做介绍。根据UastScanner源码中的注释,可以很容易的从PsiJavaScanner迁移到UastScanner。
Lint规则
我们需要用Lint检查代码中的哪些问题呢?
开发过程中,我们比较关注App的Crash、Bug率等指标。通过长期的整理总结发现,有不少发生频率很高的代码问题,其原理和解决方案都很明确,但是在写代码时却很容易遗漏且难以发现;而Lint恰好很容易检查出这些问题。
Crash预防
Crash率是App最重要的指标之一,避免Crash也一直是开发过程中比较头疼的一个问题,Lint可以很好的检查出一些潜在的Crash。例如:
- 原生的NewApi,用于检查代码中是否调用了Android高版本才提供的API。在低版本设备中调用高版本API会导致Crash。
- 自定义的SerializableCheck。实现了Serializable接口的类,如果其成员变量引用的对象没有实现Serializable接口,序列化时就会Crash。我们制定了一条代码规范,要求实现了Serializable接口的类,其成员变量(包括从父类继承的)所声明的类型都要实现Serializable接口。
- 自定义的ParseColorCheck。调用
Color.parseColor()方法解析后台下发的颜色时,颜色字符串格式不正确会导致IllegalArgumentException,我们要求调用这个方法时必须处理该异常。
Bug预防
有些Bug可以通过Lint检查来预防。例如:
- SpUsage:要求所有SharedPrefrence读写操作使用基础工具类,工具类中会做各种异常处理;同时定义SPConstants常量类,所有SP的Key都要在这个类定义,避免在代码中分散定义的Key之间冲突。
- ImageViewUsage:检查ImageView有没有设置ScaleType,加载时有没有设置Placeholder。
- TodoCheck:检查代码中是否还有TODO没完成。例如开发时可能会在代码中写一些假数据,但最终上线时要确保删除这些代码。这种检查项比较特殊,通常在开发完成后提测阶段才检查。
性能/安全问题
一些性能、安全相关问题可以使用Lint分析。例如: - ThreadConstruction:禁止直接使用new Thread()创建线程(线程池除外),而需要使用统一的工具类在公用线程池执行后台操作。 - LogUsage:禁止直接使用android.util.Log,必须使用统一工具类。工具类中可以控制Release包不输出Log,提高性能,也避免发生安全问题。
代码规范
除了代码风格方面的约束,代码规范更多的是用于减少或防止发生Bug、Crash、性能、安全等问题。很多问题在技术上难以直接检查,我们通过封装统一的基础库、制定代码规范的方式间接解决,而Lint检查则用于减少组内沟通成本、新人学习成本,并确保代码规范的落实。例如:
- 前面提到的SpUsage、ThreadConstruction、LogUsage等。
- ResourceNaming:资源文件命名规范,防止不同模块之间的资源文件名冲突。
代码检查的实施
当检查出代码问题时,如何提醒开发者及时修正呢?
早期我们将静态代码检查配置在Jenkins上,打包发布AAR/APK时,检查代码中的问题并生成报告。后来发现虽然静态代码检查能找出来不少问题,但是很少有人主动去看报告,特别是报告中还有过多无关紧要的、优先级很低的问题(例如过于严格的代码风格约束)。
因此,一方面要确定检查哪些问题,另一方面,何时、通过什么样的技术手段来执行代码检查也很重要。我们结合技术实现,对此做了更多思考,确定了静态代码检查实施过程中的主要目标:
- 重点关注高优先级问题,屏蔽低优先级问题。正如前面所说,如果代码检查报告中夹杂了大量无关紧要的问题,反而影响了关键问题的发现。
- 高优问题的解决,要有一定的强制性。当检查发现高优先级的代码问题时,给开发者明确直接的报错,并通过技术手段约束,强制要求开发者修复。
- 某些问题尽可能做到在第一时间发现,从而减少风险或损失。有些问题发现的越早越好,例如业务功能开发中使用了Android高版本API,通过Lint原生的NewApi可以检查出来。如果在开发期间发现,当时就可以考虑其他技术方案,实现困难时可以及时和产品、设计人员沟通;而如果到提代码、提测,甚至发版、上线时才发现,可能为时已晚。
优先级定义
每个Lint规则都可以配置Sevirity(优先级),包括Fatal、Error、Warning、Information等,我们主要使用Error和Warning,如下。
- Error级别:明确需要解决的问题,包括Crash、明确的Bug、严重性能问题、不符合代码规范等,必须修复。
- Warning级别:包括代码编写建议、可能存在的Bug、一些性能优化等,适当放松要求。
执行时机
Lint检查可以在多个阶段执行,包括在本地手动检查、编码实时检查、编译时检查、commit检查,以及在CI系统中提Pull Request时检查、打包发版时检查等,下面分别介绍。
手动执行
在Android Studio中,自定义Lint可以通过Inspections功能(Analyze - Inspect Code)手动运行。
在Gradle命令行环境下,可直接用./gradlew lint执行Lint检查。
手动执行简单易用,但缺乏强制性,容易被开发者遗漏。
编码阶段实时检查
编码时检查即在Android Studio中写代码时在代码窗口实时报错。其好处很明显,开发者可以第一时间发现代码问题。但受限于Android Studio对自定义Lint的支持不完善,开发人员IDE的配置不同,需要开发者主动关注报错并修复,这种方式不能完全保证效果。
IDEA提供了Inspections功能和相应的API来实现代码检查,Android原生Lint就是通过Inspections集成到了Android Studio中。对于自定义Lint规则,官方似乎没有给出明确说明,但实际研究发现,在Android Studio 2.2+版本和基于JavaPsiScanner开发的条件下(或Android Studio 3.0+和JavaPsiScanner/UastScanner),IDE会尝试加载并实时执行自定义Lint规则。
技术细节:
-
在Android Studio 2.x版本中,菜单
Preferences - Editor - Inspections - Android - Lint - Correctness - Error from Custom Lint Check(avaliable for Analyze|Inspect Code)中指出,自定义Lint只支持命令行或手动运行,不支持实时检查。Error from Custom Rule When custom (third-party) lint rules are integrated in the IDE, they are not available as native IDE inspections, so the explanation text (which must be statically registered by a plugin) is not available. As a workaround, run the lint target in Gradle instead; the HTML report will include full explanations.
-
在Android Studio 3.x版本中,打开Android工程源码后,IDE会加载工程中的自定义Lint规则,在设置菜单的Inspections列表里可以查看,和原生Lint效果相同(Android Studio会在打开源文件时触发对该文件的代码检查)。
-
分析自定义Lint的
IssueRegistry.getIssues()方法调用堆栈,可以看到Android Studio环境下,是由org.jetbrains.android.inspections.lint.AndroidLintExternalAnnotator调用LintDriver加载执行自定义Lint规则。参考代码: https://github.com/JetBrains/android/tree/master/android/src/org/jetbrains/android/inspections/lint
在Android Studio中的实际效果如图:
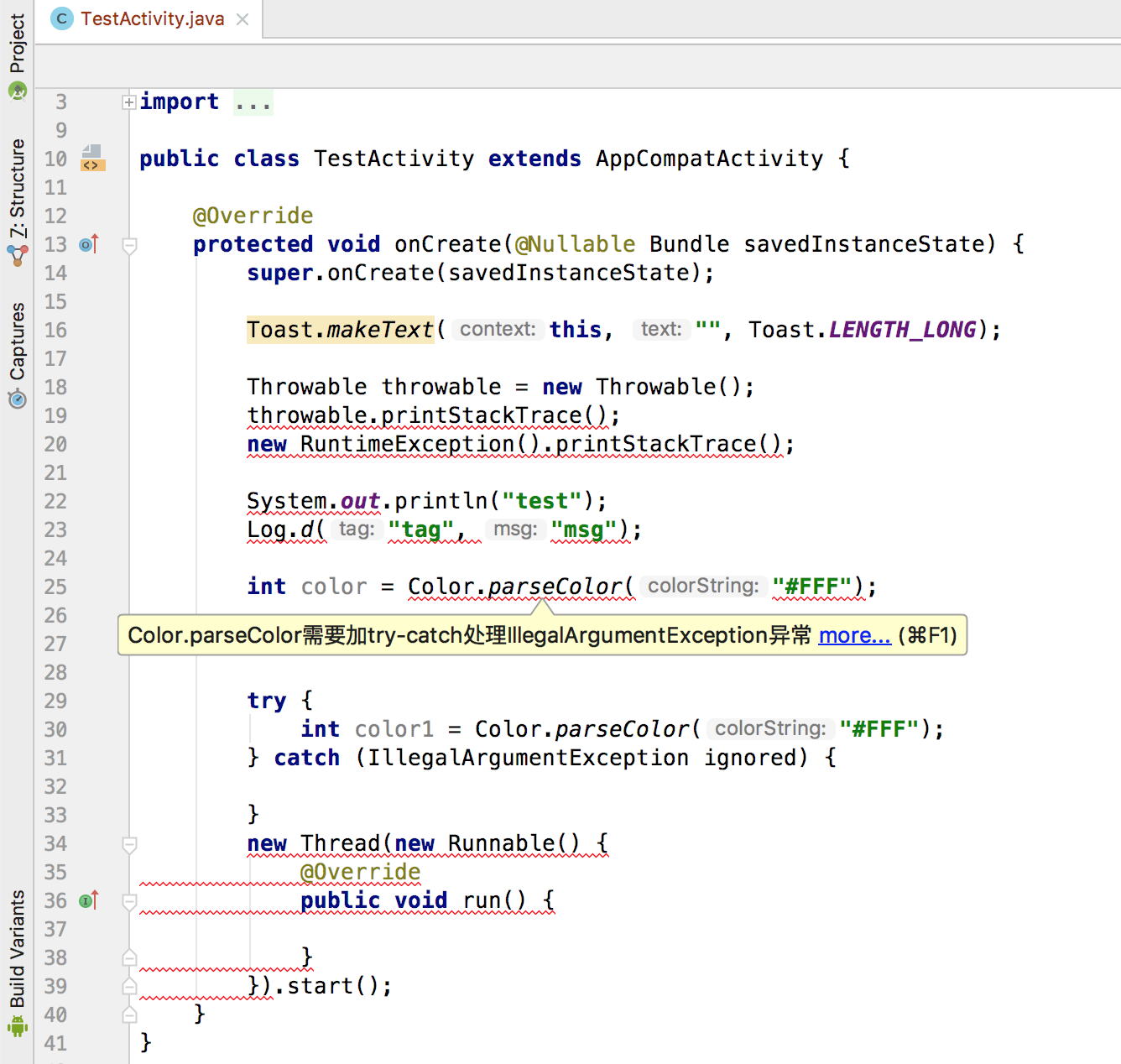
本地编译时自动检查
配置Gradle脚本可实现编译Android工程时执行Lint检查。好处是既可以尽早发现问题,又可以有强制性;缺点是对编译速度有一定的影响。
编译Android工程执行的是assemble任务,让assemble依赖lint任务,即可在编译时执行Lint检查;同时配置LintOptions,发现Error级别问题时中断编译。
在Android Application工程(APK)中配置如下,Android Library工程(AAR)把applicationVariants换成libraryVariants即可。
android.applicationVariants.all { variant ->
variant.outputs.each { output ->
def lintTask = tasks["lint${variant.name.capitalize()}"]
output.assemble.dependsOn lintTask
}
}
LintOptions的配置:
android.lintOptions {
abortOnError true
}
本地commit时检查
利用git pre-commit hook,可以在本地commit代码前执行Lint检查,检查不通过则无法提交代码。这种方式的优势在于不影响开发时的编译速度,但发现问题相对滞后。
技术实现方面,可以编写Gradle脚本,在每次同步工程时自动将hook脚本从工程拷贝到.git/hooks/文件夹下。
提代码时CI检查
作为代码提交流程规范的一部分,发Pull Request提代码时用CI系统检查Lint问题是一个常见、可行、有效的思路。可配置CI检查通过后代码才能被合并。
CI系统常用Jenkins,如果使用Stash做代码管理,可以在Stash上配置Pull Request Notifier for Stash插件,或在Jenkins上配置Stash Pull Request Builder插件,实现发Pull Request时触发Jenkins执行Lint检查的Job。
在本地编译和CI系统中做代码检查,都可以通过执行Gradle的Lint任务实现。可以在CI环境下给Gradle传递一个StartParameter,Gradle脚本中如果读取到这个参数,则配置LintOptions检查所有Lint问题;否则在本地编译环境下只检查部分高优先级Lint问题,减少对本地编译速度的影响。
Lint生成报告的效果如图所示:
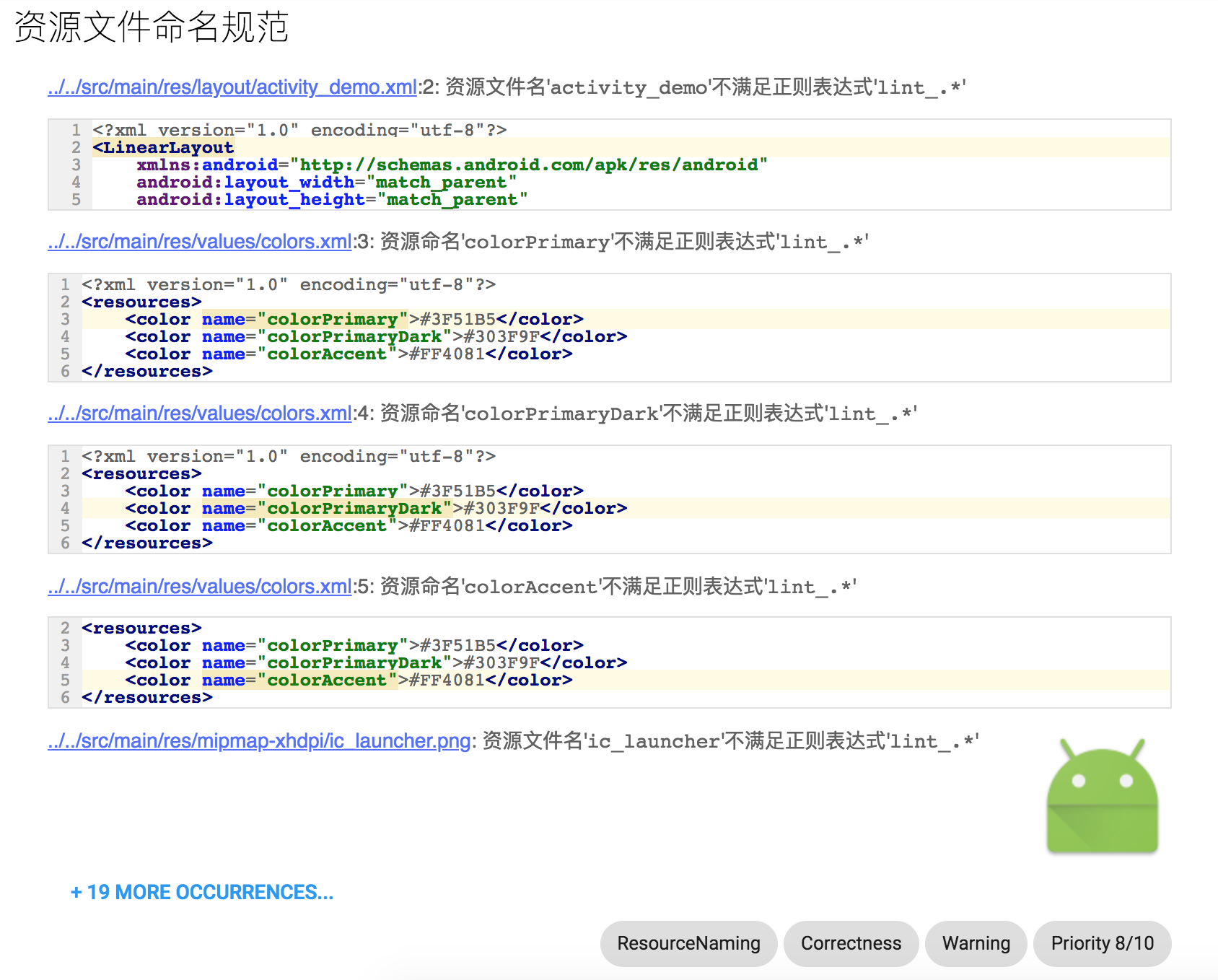
打包发布时检查
即使每次提代码时用CI系统执行Lint检查,仍然不能保证所有人的代码合并后一定没有问题;另外对于一些特殊的Lint规则,例如前面提到的TodoCheck,还希望在更晚的时候检查。
于是在CI系统打包发布APK/AAR用于测试或发版时,还需要对所有代码再做一次Lint检查。
最终确定的检查时机
综合考虑多种检查方式的优缺点以及我们的目标,最终确定结合以下几种方式做代码检查:
- 编码阶段IDE实时检查,第一时间发现问题。
- 本地编译时,及时检查高优先级问题,检查通过才能编译。
- 提代码时,CI检查所有问题,检查通过才能合代码。
- 打包阶段,完整检查工程,确保万无一失。
配置文件支持
为了方便代码管理,我们给自定义Lint创建了一个独立的工程,该工程打包生成一个AAR发布到Maven仓库,而被检查的Android工程依赖这个AAR(具体开发过程可以参考文章末尾链接)。
自定义Lint虽然在独立工程中,但和被检查的Android工程中的代码规范、基础组件等存在较多耦合。
例如我们使用正则表达式检查Android工程的资源文件命名规范,每次业务逻辑变动要新增资源文件前缀时,都要修改Lint工程,发布新的AAR,再更新到Android工程中,非常繁琐。另一方面,我们的Lint工程除了在外卖C端Android工程中使用,也希望能直接用在其他端的其他Android工程中,而不同工程之间存在差异。
于是我们尝试使用配置文件来解决这一问题。以检查Log使用的LogUsage为例,不同工程封装了不同的Log工具类,报错时提示信息也应该不一样。定义配置文件名为custom-lint-config.json,放在被检查Android工程的模块目录下。在Android工程A中的配置文件是:
{
"log-usage-message": "请勿使用android.util.Log,建议使用LogUtils工具类"
}
而Android工程B的配置文件是:
{
"log-usage-message": "请勿使用android.util.Log,建议使用Logger工具类"
}
从Lint的Context对象可获取被检查工程目录从而读取配置文件,关键代码如下:
import com.android.tools.lint.detector.api.Context;
public final class LintConfig {
private LintConfig(Context context) {
File projectDir = context.getProject().getDir();
File configFile = new File(projectDir, "custom-lint-config.json");
if (configFile.exists() && configFile.isFile()) {
// 读取配置文件...
}
}
}
配置文件的读取,可以在Detector的beforeCheckProject、beforeCheckLibraryProject回调方法中进行。LogUsage中检查到错误时,根据配置文件定义的信息报错。
public class LogUsageDetector extends Detector implements Detector.JavaPsiScanner {
// ...
private LintConfig mLintConfig;
@Override
public void beforeCheckProject(@NonNull Context context) {
// 读取配置
mLintConfig = new LintConfig(context);
}
@Override
public void beforeCheckLibraryProject(@NonNull Context context) {
// 读取配置
mLintConfig = new LintConfig(context);
}
@Override
public List<String> getApplicableMethodNames() {
return Arrays.asList("v", "d", "i", "w", "e", "wtf");
}
@Override
public void visitMethod(JavaContext context, JavaElementVisitor visitor, PsiMethodCallExpression call, PsiMethod method) {
if (context.getEvaluator().isMemberInClass(method, "android.util.Log")) {
// 从配置文件获取Message
String msg = mLintConfig.getConfig("log-usage-message");
context.report(ISSUE, call, context.getLocation(call.getMethodExpression()), msg);
}
}
}
模板Lint规则
Lint规则开发过程中,我们发现了一系列相似的需求:封装了基础工具类,希望大家都用起来;某个方法很容易抛出RuntimeException,有必要做处理,但Java语法上RuntimeException并不强制要求处理从而经常遗漏……
这些相似的需求,每次在Lint工程中开发同样会很繁琐。我们尝试实现了几个模板,可以直接在Android工程中通过配置文件配置Lint规则。
如下为一个配置文件示例:
{
"lint-rules": {
"deprecated-api": [{
"method-regex": "android\\.content\\.Intent\\.get(IntExtra|StringExtra|BooleanExtra|LongExtra|LongArrayExtra|StringArrayListExtra|SerializableExtra|ParcelableArrayListExtra).*",
"message": "避免直接调用Intent.getXx()方法,特殊机型可能发生Crash,建议使用IntentUtils",
"severity": "error"
},
{
"field": "java.lang.System.out",
"message": "请勿直接使用System.out,应该使用LogUtils",
"severity": "error"
},
{
"construction": "java.lang.Thread",
"message": "避免单独创建Thread执行后台任务,存在性能问题,建议使用AsyncTask",
"severity": "warning"
},
{
"super-class": "android.widget.BaseAdapter",
"message": "避免直接使用BaseAdapter,应该使用统一封装的BaseListAdapter",
"severity": "warning"
}],
"handle-exception": [{
"method": "android.graphics.Color.parseColor",
"exception": "java.lang.IllegalArgumentException",
"message": "Color.parseColor需要加try-catch处理IllegalArgumentException异常",
"severity": "error"
}]
}
}
示例配置中定义了两种类型的模板规则:
- DeprecatedApi:禁止直接调用指定API
- HandleException:调用指定API时,需要加try-catch处理指定类型的异常
问题API的匹配,包括方法调用(method)、成员变量引用(field)、构造函数(construction)、继承(super-class)等类型;匹配字符串支持glob语法或正则表达式(和lint.xml中ignore的配置语法一致)。
实现方面,主要是遍历Java语法树中特定类型的节点并转换成完整字符串(例如方法调用android.content.Intent.getIntExtra),然后检查是否有模板规则与其匹配。匹配成功后,DeprecatedApi规则直接输出message报错;HandleException规则会检查匹配到的节点是否处理了特定Exception(或Exception的父类),没有处理则报错。
按Git版本检查新增文件
随着Lint新规则的不断开发,我们又遇到了一个问题。Android工程中存在大量历史代码,不符合新增Lint规则的要求,但也没有导致明显问题,这时接入新增Lint规则要求修改所有历史代码,成本较高而且有一定风险。例如新增代码规范,要求使用统一的线程工具类而不允许直接用Handler以避免内存泄露等。
我们尝试了一个折中的方案:只检查指定git commit之后新增的文件。在配置文件中添加配置项,给Lint规则配置git-base属性,其值为commit ID,只检查此次commit之后新增的文件。
实现方面,执行git rev-parse --show-toplevel命令获取git工程根目录的路径;执行git ls-tree --full-tree --full-name --name-only -r <commit-id>命令获取指定commit时已有文件列表(相对git根目录的路径)。在Scanner回调方法中通过Context.getLocation(node).getFile()获取节点所在文件,结合git文件列表判断是否需要检查这个节点。需要注意的是,代码量较大时要考虑Lint检查对电脑的性能消耗。
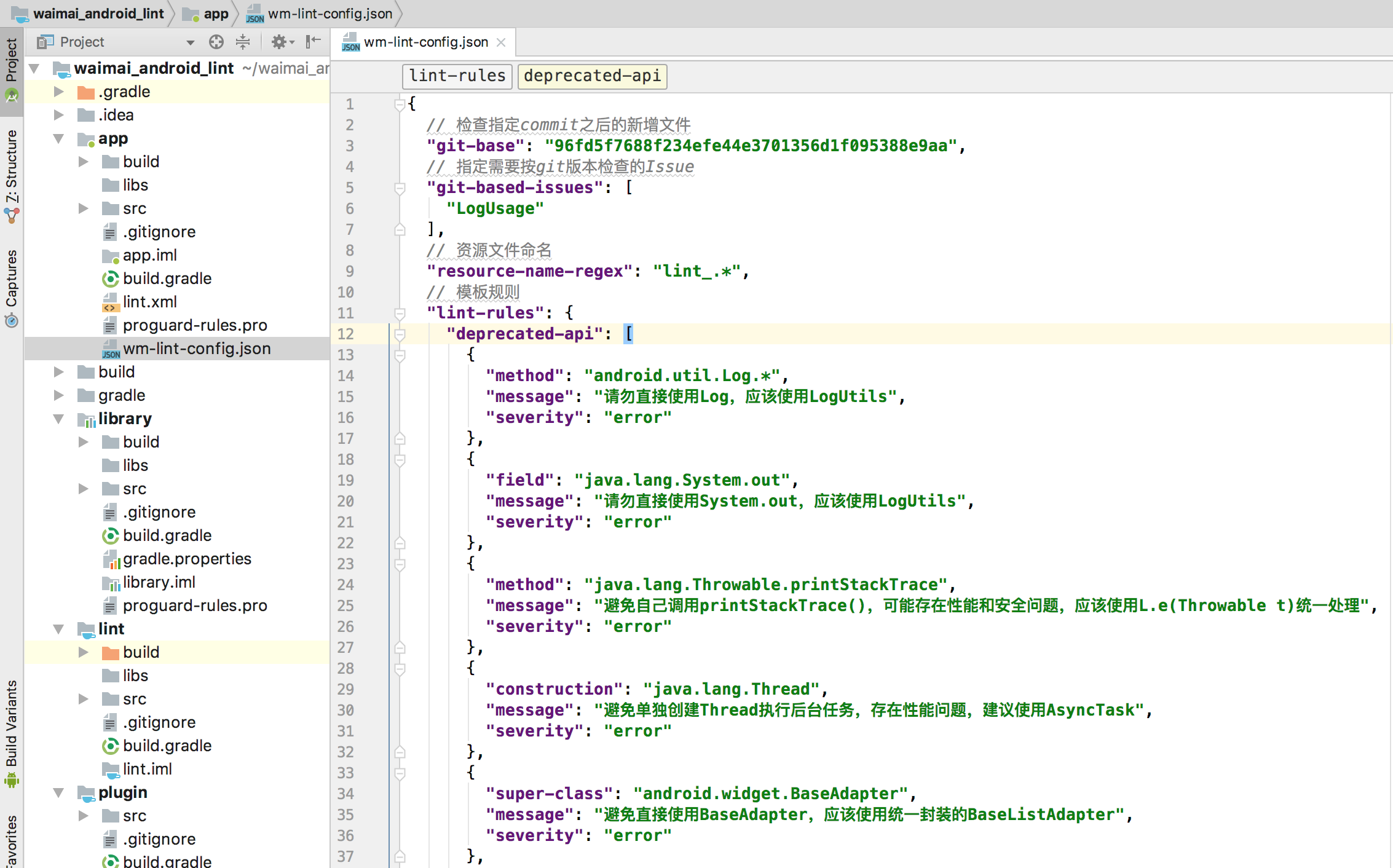
总结
经过一段时间的实践发现,Lint静态代码检查在解决特定问题时的效果非常好,例如发现一些语言或API层面比较明确的低级错误、帮助进行代码规范的约束。使用Lint前,不少这类问题恰好对开发人员来说又很容易遗漏(例如原生的NewApi检查、自定义的SerializableCheck);相同问题反复出现;代码规范的执行,特别是有新人参与开发时,需要很高的学习和沟通成本,还经常出现新人提交代码时由于没有遵守代码规范反复被要求修改。而使用Lint后,这些问题都能在第一时间得到解决,节省了大量的人力,提高了代码质量和开发效率,也提高了App的使用体验。
参考资料与扩展阅读
- 使用 Lint 改进您的代码 | Android Studio
- Android Plugin DSL Reference:LintOptions
- Android自定义Lint实践
- Lint工具的源码分析(3)
- Android Studio Release Notes
- Git - Documentation
Lint和Gradle相关技术细节还可以阅读个人博客:
Android动态日志系统Holmes
背景
美团是全球领先的一站式生活服务平台,为6亿多消费者和超过450万优质商户提供连接线上线下的电子商务网络。美团的业务覆盖了超过200个丰富品类和2800个城区县网络,在餐饮、外卖、酒店旅游、丽人、家庭、休闲娱乐等领域具有领先的市场地位。平台大,责任也大。在移动端,如何快速定位并解决线上问题提高用户体验给我们带来了极大挑战。线上偶尔会发生某一个页面打不开、新活动抢单按钮点击没响应、登录不了、不能下单等现象,由于Android碎片化、网络环境、机型ROM、操作系统版本、本地环境复杂多样,这些个性化的使用场景很难在本地复现,加上问题反馈的时候描述的往往都比较模糊,快速定位并解决问题难度不小。为此,我们开发了动态日志系统Holmes,希望它能像大侦探福尔摩斯那样帮我们顺着线上bug的蛛丝马迹,发现背后真相。
现有的解决办法
- 发临时包用户安装
- QA尝试去复现问题
- 在线debug调试工具
- 预先手动埋点回捞
现有办法的弊端
- 临时发包:用户配合过程繁琐,而且解决问题时间很长
- QA复现:尝试已有机型发现个性化场景很难复现
- 在线debug:网络环境不稳定,代码混淆调试成本很高,占用用户过多时间用户难以接受
- 手动埋点:覆盖范围有限,无法提前预知,而且由于业务量大、多地区协作开发、业务类型多等造成很难统一埋点方案,并且在排查问题时大量的手动埋点会产生很多冗余的上报数据,寻找一条有用的埋点信息犹如大海捞针
目标诉求
- 快速拿到线上日志
- 不需要大量埋点甚至不埋点
- 精准的问题现场日志
实现
针对难定位的线上问题,动态日志提供了一套快速定位问题的方案。预先在用户手机自动产生方法执行的日志信息,当需要排查用户问题时,通过信令下发精准回捞用户日志,再现用户操作路径;动态日志系统也支持动态下发代码,从而实现动态分析运行时对象快照、动态增加埋点等功能,能够分析复杂使用场景下的用户问题。
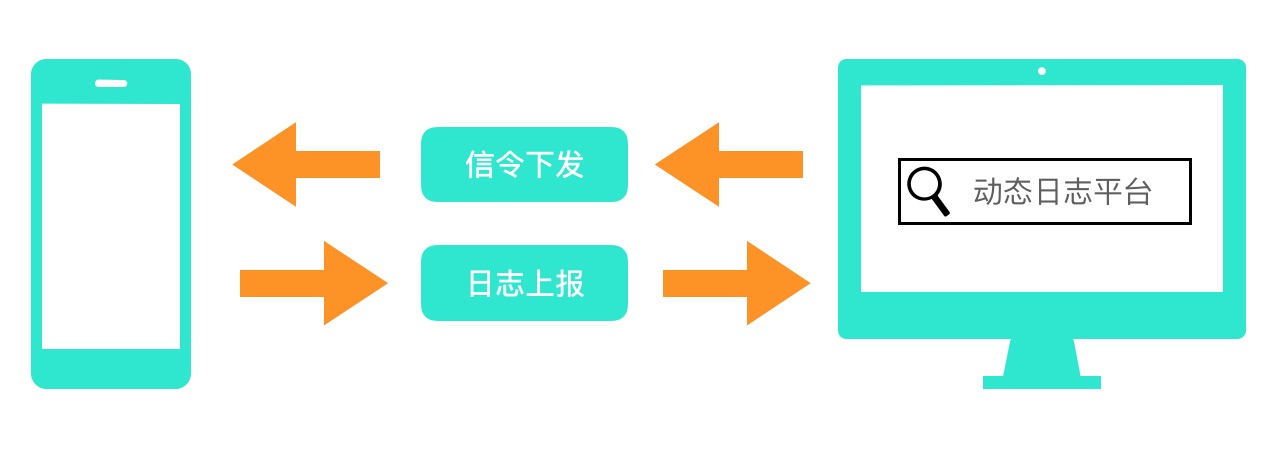
自动埋点
自动埋点是线上App自动产生日志,怎么样自动产生日志呢?我们对方法进行了插桩来记录方法执行路径(调用堆栈),在方法的开头插入一段桩代码,当方法运行的时候就会记录方法签名、进程、线程、时间等形成一条完整的执行信息(这里我们叫TraceLog),将TraceLog存入DB等待信令下发回捞数据。
public void onCreate(Bundle bundle) {
//插桩代码
if (Holmes.isEnable(....)) {
Holmes.invoke(....);
return;
}
super.onCreate(bundle);
setContentView(R.layout.main);
}
历史数据
Tracelog形成的是代码的历史执行路径,一旦线上出现问题就可以回捞用户历史数据来排查问题,并且Tracelog有以下几个优点:
- Tracelog是自动产生的无需开发者手动埋点
- 插桩覆盖了所有的业务代码,而且这里Tracelog不受Proguard内联方法的限制,插桩在Proguard之前所以方法被内联之后桩代码也会被内联,这样就会记录下来对照原始代码的完整执行路径信息
- 回捞日志可以基于一个方法为中心点向前或者向后采集日志(例如:点击下单按钮无响应只需要回捞点击下单按钮事件之后的代码执行路径来分析问题),这样可以避免上报一堆无用日志,减少我们排查问题的时间和降低复杂度
Tracelog工作的流程
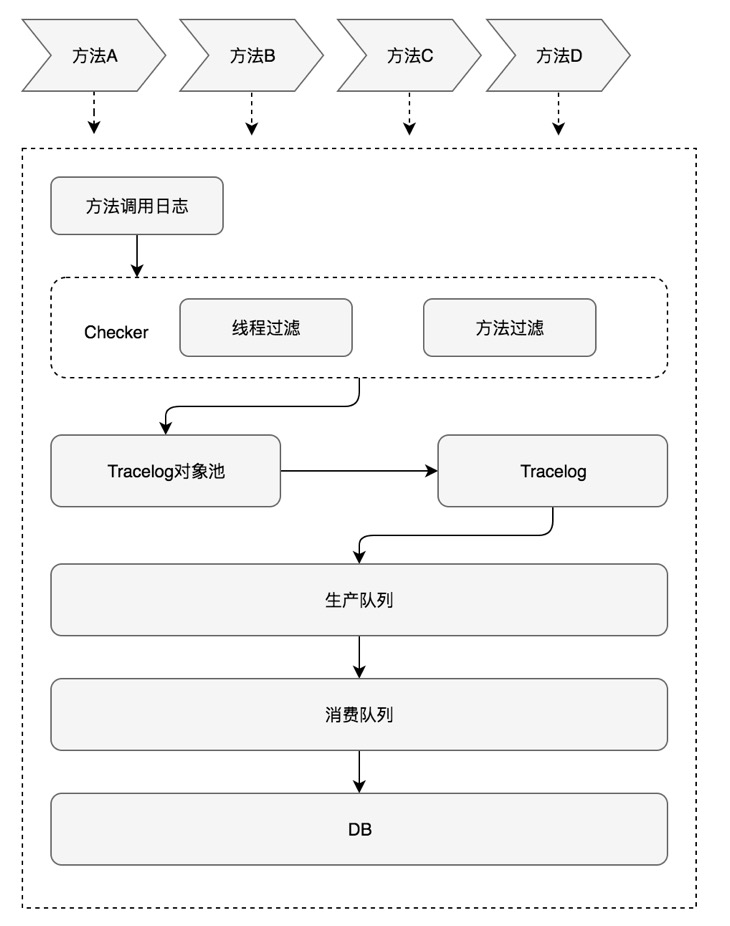
方法运行产生方法调用日志首先会经过checker进行检测,checker包含线程检测和方法检测(减少信息干扰),线程检测主要过滤类似于定时任务这种一直在不断的产生日志的线程,方法检测会在一定时间内检测方法调用的频率,过滤掉频繁调用的方法,方法如果不会被过滤就会进行异步处理,其次向对象池获取一个Tracelog对象,Tracelog对象进入生产队列组装时间、线程、序列号等信息,完成后进入消费队列,最后消费队列到达固定数量之后批量处理存入DB。
Tracelog数据展示
日志回捞到Trace平台上按时间顺序排列展示结果:
问题总结
我们的平台部署实施了几个版本,总结了很多的案例。经过实战的考验发现多数的场景下用户回捞Tracelog分析问题只能把问题的范围不断的缩小,但是很多的问题确定了是某一个方法的异常,这个时候是需要知道方法的执行信息比如:入参、当前对象字段、返回值等信息来确定代码的执行逻辑,只有Tracelog在这里的感觉就好比只差临门一脚了,怎么才能获取方法运行时产生的内存快照呢?这正是体现动态日志的动态性能力。
动态下发
对目标用户下发信令,动态执行一段代码并将结果上报,我们利用Lua脚本在方法运行的时候去获取对象的快照信息。为什么选择Lua?Lua运行时库非常小并且可以调用Java代码而且语言精简易懂。动态执行Lua有三个重要的时机:立即执行、方法前执行、方法后执行。
- 立即执行:接受到信令之后就会立马去执行并上报结果
- 方法前执行:在某一个方法执行之前执行Lua脚本,动态获取入参、对象字段等信息
- 方法后执行:在某一个方法执行之后执行Lua脚本,动态获取返回值、入参变化、对象字段变化等信息
在方法后执行Lua脚本遇到了一些问题,我们只在方法前插桩,如果在方法后也插桩这样能解决在方法后执行的问题,但是这样增加代码体积和影响proguard内联方法数,如何解决这个问题如下:
我们利用反射执行当前方法,当进入方法前面的插桩代码不会直接执行本方法的方法体会在桩代码里通过反射调用自己,这样就做到了一个动态AOP的功能就可以在方法之后执行脚本,同样这种方法也存在一个问题,就是会出现死循环,解决这个问题的办法只需要在执行反射的时候标记是反射调用进来的就可以避免死循环的问题。
我们还可以让脚本做些什么呢?除了可以获取对象的快照信息外,还增加了DB查询、上报普通文本、ShardPreferences查询、获取Context对象、查询权限、追加埋点到本地、上传文件等综合能力,而且Lua脚本的功能远不仅如此,可以利用Lua脚本调用Java的方法来模拟代码逻辑,从而实现更深层次的动态能力。
动态下发数据展示
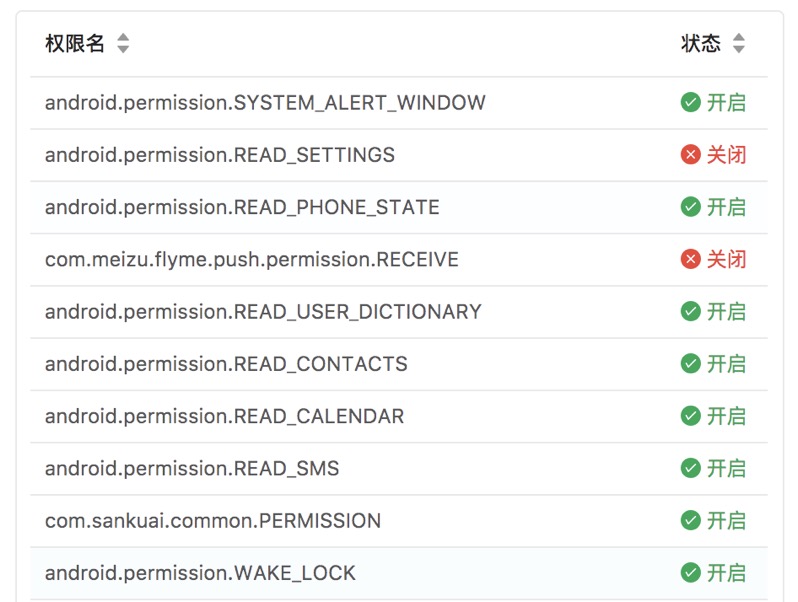
技术挑战
动态日志在开发的过程当中遇到了很多的技术难点,我们在实施方案的时候遇到很多的问题,下面来回顾一下问题及解决方案。
数据量大的问题
-
主线程卡顿
- 1. 由于同时会有多个线程产生日志,所以要考虑到线程同步安全的问题。使用synchronized或者lock可以保证同步安全问题,但是同时也带来多线程之间锁互斥的问题,造成主线程等待并卡顿,这里使用CAS技术方案来实现自定义数据结构,保证线程同步安全的情况下并解决了多线程之间锁互斥的问题。
- 2. 由于数据产生太多,所以在存储DB的时候就会产生大量的IO,导致CPU占用时间过长从而影响其他线程使用CPU的时间。针对这个问题,首先是采取线程过滤和方法过滤来减少产生无用的日志,并且降低处理线程的级别不与主线程争抢CPU时间,然后对数据进行批量处理来减少IO的频率,并在数据库操作上将原来的Delete+insert的操作改为update+insert。Tracelog固定存储30万条数据(大约美团App使用6次以上的记录),如果满30万就删除早期的一部分数据再写入新的数据。操作越久,delete操作越多,CPU资源占比越大。经过数据库操作的实际对比发现,直接改为满30万之后使用update来更新数据效率会更高一些(这里就不做太多的详细说明)。我们的优化成果从起初的CPU占比40%多降低到了20%左右再降到10%以内,这是在中低端的机器上测试的结果。
-
创建对象过多导致频繁GC
- 日志产生就会生成一个Tracelog对象,大量的日志会造成频繁的GC,针对这个问题我们使用了对象池来使对象复用,从而减少创建对象减低GC频率,对象池是类似于android.os.Message.obtain()的工作原理。
-
干扰日志太多影响分析问题
- 我们已经过滤掉了大部分的干扰日志,但还是会有一些代码执行比较频繁的方法会产生干扰日志。例如:自定义View库、日志类型的库、监控类型的库等,这些方法的日志会影响我们DB的存储空间,造成保留不了太多的正常方法执行路径,这种情况下很有可能会出现开发这关心的日志其实已经被冲掉了。怎么解决这个问题那?在插桩的时候可让开发者配置一些过滤或者识别的规则来认定是否要处理这个方法,在插桩的方法上增加一个二进制的参数,然后根据配置的规则会在相应的位上设置成0或者1,方法执行的时候只需要一个异或操作就能知道是否需要记录这个方法,这样增加的识别判断几乎对原来的方法执行耗时不会产生任何影响,使用这种方案产生的日志就是开发者所期望的日志,经过几番测试之后我们的日志也能保留住用户6次以上的完整行为,而且CPU的占用时间也降低到了5%以内。
性能影响
对每一个方法进行插桩记录日志,会对代码会造成方法耗时的影响吗?最终我们在中低端机型上分别测试了方法的耗时和CPU的使用占比。
- 方法耗时影响的测试,100万次耗时平均值在55~65ms之间,方法执行一次的耗时就微乎其微了
-
CPU的耗时测试在5%以内,如下图所示:
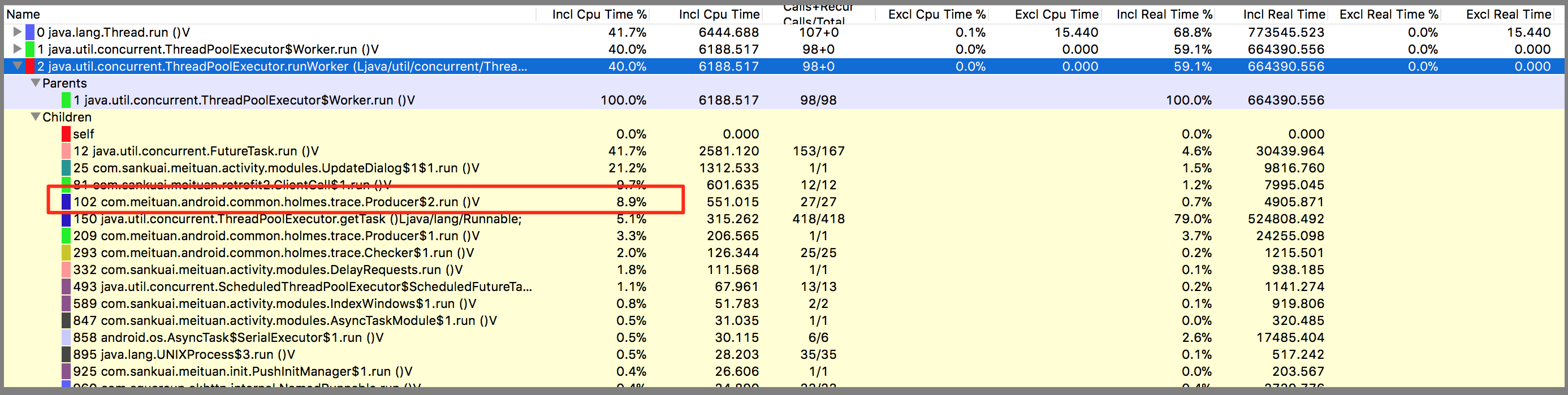
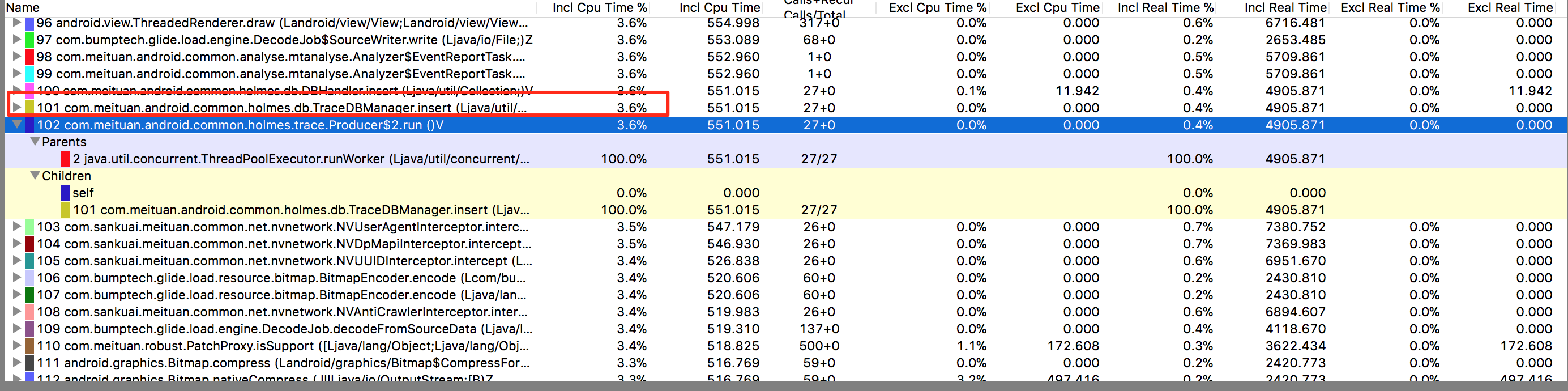
-
内存的使用测试在56kB左右,如下图:
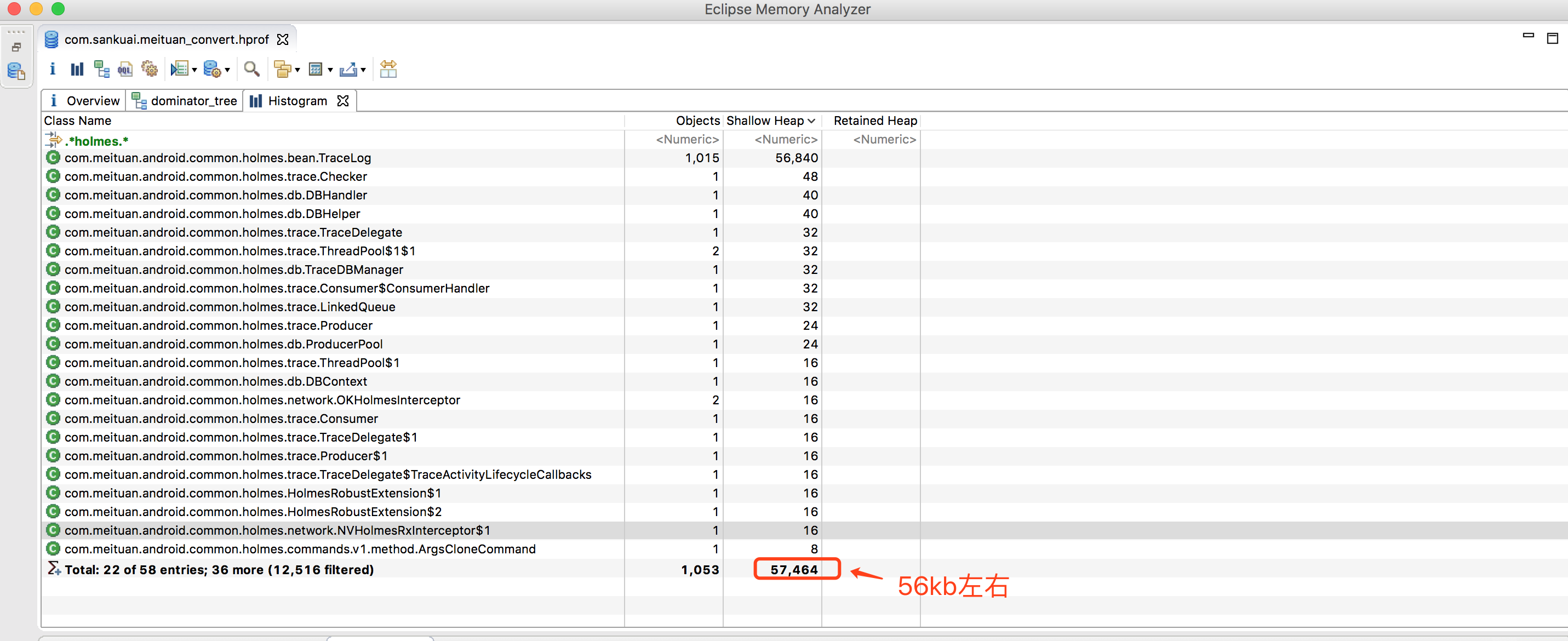
对象快照
在方法运行时获取对象快照保留现场日志,提取对象快照就需要对一个对象进行深度clone(为了防止在还没有完整记录下来信息之前对象已经被改变,影响最终判断代码执行的结果),在Java中clone对象有以下几种方法:
- 实现一个clone接口
- 实现一个序列化接口
- 使用Gson序列化
clone接口和序列化接口都有同样的一个问题,有可能这个对象没有实现相应的接口,这样是无法进行深度clone的,而且实现clone接口也做不到深度clone,Java序列化有IO问题执行效率很低。最后可能只有Gson序列化这个方法还可行,但是Gson也有很多的坑,如果一个对象中有和父类一样的字段,那么Gson在做序列的时候把父类的字段覆盖掉;如果两个对象有相互引用的场景,那么在Gson序列化的时候直接会死循环。
怎么解决以上的这些问题呢?最后我们参照一些开源库的方案和Java系统的一些API,开发出了一个深度clone的库,再加上自己定义数据对象和使用Gson来解决对象快照的问题。深度clone实现主要利用了Java系统API,先创建出来一个目标对象的空壳对象,然后利用反射将原对象上的所有字段都复制到这个空壳对象上,最后这个空壳对象会形成跟原有对象完全一样的东西,同时对Android增加的一些类型进行了特殊处理,在提高速度上对基本类型、集合、map等系统自带类型做了快速处理,clone完成的对象直接进行快照处理。
总结
动态日志对业务开发零成本,对用户使用无打扰。在排查线上问题时,方法执行路径可能直接就会反映出问题的原因,至少也能缩小问题代码的范围,最终锁定到某一个方法,这时再使用动态下发Lua脚本,最终确定问题代码的位置。动态日志的动态下发功能也可以做为一种基础的能力,提供给其他需要动态执行代码或动态获取数据的基础库,例如:遇到一些难解决的崩溃场景,除了正常的栈信息外,同时也可以根据不同的崩溃类型,动态采集一些其他的辅助信息来帮助排查问题。
Android消息总线的演进之路:用LiveDataBus替代RxBus、EventBus
背景
对于Android系统来说,消息传递是最基本的组件,每一个App内的不同页面,不同组件都在进行消息传递。消息传递既可以用于Android四大组件之间的通信,也可用于异步线程和主线程之间的通信。对于Android开发者来说,经常使用的消息传递方式有很多种,从最早使用的Handler、BroadcastReceiver、接口回调,到近几年流行的通信总线类框架EventBus、RxBus。Android消息传递框架,总在不断的演进之中。
从EventBus说起
EventBus是一个Android事件发布/订阅框架,通过解耦发布者和订阅者简化Android事件传递。EventBus可以代替Android传统的Intent、Handler、Broadcast或接口回调,在Fragment、Activity、Service线程之间传递数据,执行方法。
EventBus最大的特点就是:简洁、解耦。在没有EventBus之前我们通常用广播来实现监听,或者自定义接口函数回调,有的场景我们也可以直接用Intent携带简单数据,或者在线程之间通过Handler处理消息传递。但无论是广播还是Handler机制远远不能满足我们高效的开发。EventBus简化了应用程序内各组件间、组件与后台线程间的通信。EventBus一经推出,便受到广大开发者的推崇。
现在看来,EventBus给Android开发者世界带来了一种新的框架和思想,就是消息的发布和订阅。这种思想在其后很多框架中都得到了应用。

发布/订阅模式
订阅发布模式定义了一种“一对多”的依赖关系,让多个订阅者对象同时监听某一个主题对象。这个主题对象在自身状态变化时,会通知所有订阅者对象,使它们能够自动更新自己的状态。
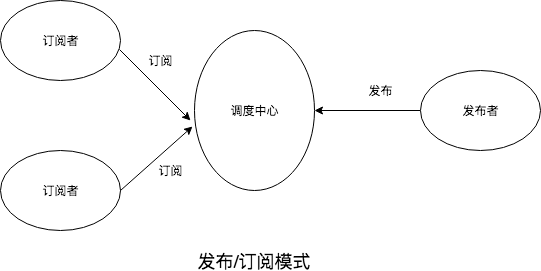
RxBus的出现
RxBus不是一个库,而是一个文件,实现只有短短30行代码。RxBus本身不需要过多分析,它的强大完全来自于它基于的RxJava技术。响应式编程(Reactive Programming)技术这几年特别火,RxJava是它在Java上的实作。RxJava天生就是发布/订阅模式,而且很容易处理线程切换。所以,RxBus凭借区区30行代码,就敢挑战EventBus江湖老大的地位。
RxBus原理
在RxJava中有个Subject类,它继承Observable类,同时实现了Observer接口,因此Subject可以同时担当订阅者和被订阅者的角色,我们使用Subject的子类PublishSubject来创建一个Subject对象(PublishSubject只有被订阅后才会把接收到的事件立刻发送给订阅者),在需要接收事件的地方,订阅该Subject对象,之后如果Subject对象接收到事件,则会发射给该订阅者,此时Subject对象充当被订阅者的角色。
完成了订阅,在需要发送事件的地方将事件发送给之前被订阅的Subject对象,则此时Subject对象作为订阅者接收事件,然后会立刻将事件转发给订阅该Subject对象的订阅者,以便订阅者处理相应事件,到这里就完成了事件的发送与处理。
最后就是取消订阅的操作了,RxJava中,订阅操作会返回一个Subscription对象,以便在合适的时机取消订阅,防止内存泄漏,如果一个类产生多个Subscription对象,我们可以用一个CompositeSubscription存储起来,以进行批量的取消订阅。
RxBus有很多实现,如:
AndroidKnife/RxBus(https://github.com/AndroidKnife/RxBus) Blankj/RxBus(https://github.com/Blankj/RxBus)
其实正如前面所说的,RxBus的原理是如此简单,我们自己都可以写出一个RxBus的实现:
基于RxJava1的RxBus实现:
public final class RxBus {
private final Subject<Object, Object> bus;
private RxBus() {
bus = new SerializedSubject<>(PublishSubject.create());
}
private static class SingletonHolder {
private static final RxBus defaultRxBus = new RxBus();
}
public static RxBus getInstance() {
return SingletonHolder.defaultRxBus;
}
/*
* 发送
*/
public void post(Object o) {
bus.onNext(o);
}
/*
* 是否有Observable订阅
*/
public boolean hasObservable() {
return bus.hasObservers();
}
/*
* 转换为特定类型的Obserbale
*/
public <T> Observable<T> toObservable(Class<T> type) {
return bus.ofType(type);
}
}
基于RxJava2的RxBus实现:
public final class RxBus2 {
private final Subject<Object> bus;
private RxBus2() {
// toSerialized method made bus thread safe
bus = PublishSubject.create().toSerialized();
}
public static RxBus2 getInstance() {
return Holder.BUS;
}
private static class Holder {
private static final RxBus2 BUS = new RxBus2();
}
public void post(Object obj) {
bus.onNext(obj);
}
public <T> Observable<T> toObservable(Class<T> tClass) {
return bus.ofType(tClass);
}
public Observable<Object> toObservable() {
return bus;
}
public boolean hasObservers() {
return bus.hasObservers();
}
}
引入LiveDataBus的想法
从LiveData谈起
LiveData是Android Architecture Components提出的框架。LiveData是一个可以被观察的数据持有类,它可以感知并遵循Activity、Fragment或Service等组件的生命周期。正是由于LiveData对组件生命周期可感知特点,因此可以做到仅在组件处于生命周期的激活状态时才更新UI数据。
LiveData需要一个观察者对象,一般是Observer类的具体实现。当观察者的生命周期处于STARTED或RESUMED状态时,LiveData会通知观察者数据变化;在观察者处于其他状态时,即使LiveData的数据变化了,也不会通知。
LiveData的优点
- UI和实时数据保持一致 因为LiveData采用的是观察者模式,这样一来就可以在数据发生改变时获得通知,更新UI。
- 避免内存泄漏 观察者被绑定到组件的生命周期上,当被绑定的组件销毁(destroy)时,观察者会立刻自动清理自身的数据。
- 不会再产生由于Activity处于stop状态而引起的崩溃
例如:当Activity处于后台状态时,是不会收到LiveData的任何事件的。
- 不需要再解决生命周期带来的问题 LiveData可以感知被绑定的组件的生命周期,只有在活跃状态才会通知数据变化。
- 实时数据刷新 当组件处于活跃状态或者从不活跃状态到活跃状态时总是能收到最新的数据。
- 解决Configuration Change问题 在屏幕发生旋转或者被回收再次启动,立刻就能收到最新的数据。
谈一谈Android Architecture Components
Android Architecture Components的核心是Lifecycle、LiveData、ViewModel 以及 Room,通过它可以非常优雅的让数据与界面进行交互,并做一些持久化的操作,高度解耦,自动管理生命周期,而且不用担心内存泄漏的问题。
- Room 一个强大的SQLite对象映射库。
- ViewModel 一类对象,它用于为UI组件提供数据,在设备配置发生变更时依旧可以存活。
- LiveData 一个可感知生命周期、可被观察的数据容器,它可以存储数据,还会在数据发生改变时进行提醒。
- Lifecycle 包含LifeCycleOwer和LifecycleObserver,分别是生命周期所有者和生命周期感知者。
Android Architecture Components的特点
- 数据驱动型编程 变化的永远是数据,界面无需更改。
- 感知生命周期,防止内存泄漏。
- 高度解耦 数据,界面高度分离。
- 数据持久化 数据、ViewModel不与UI的生命周期挂钩,不会因为界面的重建而销毁。
重点:为什么使用LiveData构建数据通信总线LiveDataBus
使用LiveData的理由
- LiveData具有的这种可观察性和生命周期感知的能力,使其非常适合作为Android通信总线的基础构件。
- 使用者不用显示调用反注册方法。
由于LiveData具有生命周期感知能力,所以LiveDataBus只需要调用注册回调方法,而不需要显示的调用反注册方法。这样带来的好处不仅可以编写更少的代码,而且可以完全杜绝其他通信总线类框架(如EventBus、RxBus)忘记调用反注册所带来的内存泄漏的风险。
为什么要用LiveDataBus替代EventBus和RxBus
- LiveDataBus的实现及其简单 相对EventBus复杂的实现,LiveDataBus只需要一个类就可以实现。
- LiveDataBus可以减小APK包的大小 由于LiveDataBus只依赖Android官方Android Architecture Components组件的LiveData,没有其他依赖,本身实现只有一个类。作为比较,EventBus JAR包大小为57kb,RxBus依赖RxJava和RxAndroid,其中RxJava2包大小2.2MB,RxJava1包大小1.1MB,RxAndroid包大小9kb。使用LiveDataBus可以大大减小APK包的大小。
- LiveDataBus依赖方支持更好 LiveDataBus只依赖Android官方Android Architecture Components组件的LiveData,相比RxBus依赖的RxJava和RxAndroid,依赖方支持更好。
- LiveDataBus具有生命周期感知 LiveDataBus具有生命周期感知,在Android系统中使用调用者不需要调用反注册,相比EventBus和RxBus使用更为方便,并且没有内存泄漏风险。
LiveDataBus的设计和架构
LiveDataBus的组成
- 消息 消息可以是任何的Object,可以定义不同类型的消息,如Boolean、String。也可以定义自定义类型的消息。
- 消息通道 LiveData扮演了消息通道的角色,不同的消息通道用不同的名字区分,名字是String类型的,可以通过名字获取到一个LiveData消息通道。
- 消息总线 消息总线通过单例实现,不同的消息通道存放在一个HashMap中。
- 订阅 订阅者通过getChannel获取消息通道,然后调用observe订阅这个通道的消息。
- 发布 发布者通过getChannel获取消息通道,然后调用setValue或者postValue发布消息。
LiveDataBus原理图
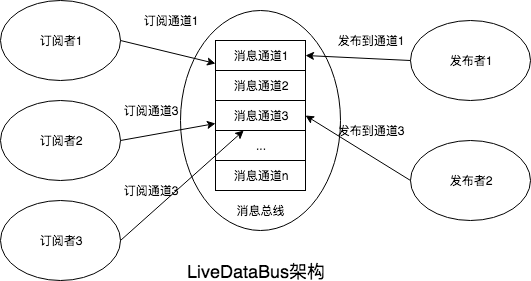
LiveDataBus的实现
第一个实现:
public final class LiveDataBus {
private final Map<String, MutableLiveData<Object>> bus;
private LiveDataBus() {
bus = new HashMap<>();
}
private static class SingletonHolder {
private static final LiveDataBus DATA_BUS = new LiveDataBus();
}
public static LiveDataBus get() {
return SingletonHolder.DATA_BUS;
}
public <T> MutableLiveData<T> getChannel(String target, Class<T> type) {
if (!bus.containsKey(target)) {
bus.put(target, new MutableLiveData<>());
}
return (MutableLiveData<T>) bus.get(target);
}
public MutableLiveData<Object> getChannel(String target) {
return getChannel(target, Object.class);
}
}
短短二十行代码,就实现了一个通信总线的全部功能,并且还具有生命周期感知功能,并且使用起来也及其简单:
注册订阅:
LiveDataBus.get().getChannel("key_test", Boolean.class)
.observe(this, new Observer<Boolean>() {
@Override
public void onChanged(@Nullable Boolean aBoolean) {
}
});
发送消息:
LiveDataBus.get().getChannel("key_test").setValue(true);
我们发送了一个名为”key_test”,值为true的事件。
这个时候订阅者就会收到消息,并作相应的处理,非常简单。
问题出现
对于LiveDataBus的第一版实现,我们发现,在使用这个LiveDataBus的过程中,订阅者会收到订阅之前发布的消息。对于一个消息总线来说,这是不可接受的。无论EventBus或者RxBus,订阅方都不会收到订阅之前发出的消息。对于一个消息总线,LiveDataBus必须要解决这个问题。
问题分析
怎么解决这个问题呢?先分析下原因:
当LifeCircleOwner的状态发生变化的时候,会调用LiveData.ObserverWrapper的activeStateChanged函数,如果这个时候ObserverWrapper的状态是active,就会调用LiveData的dispatchingValue。
在LiveData的dispatchingValue中,又会调用LiveData的considerNotify方法。
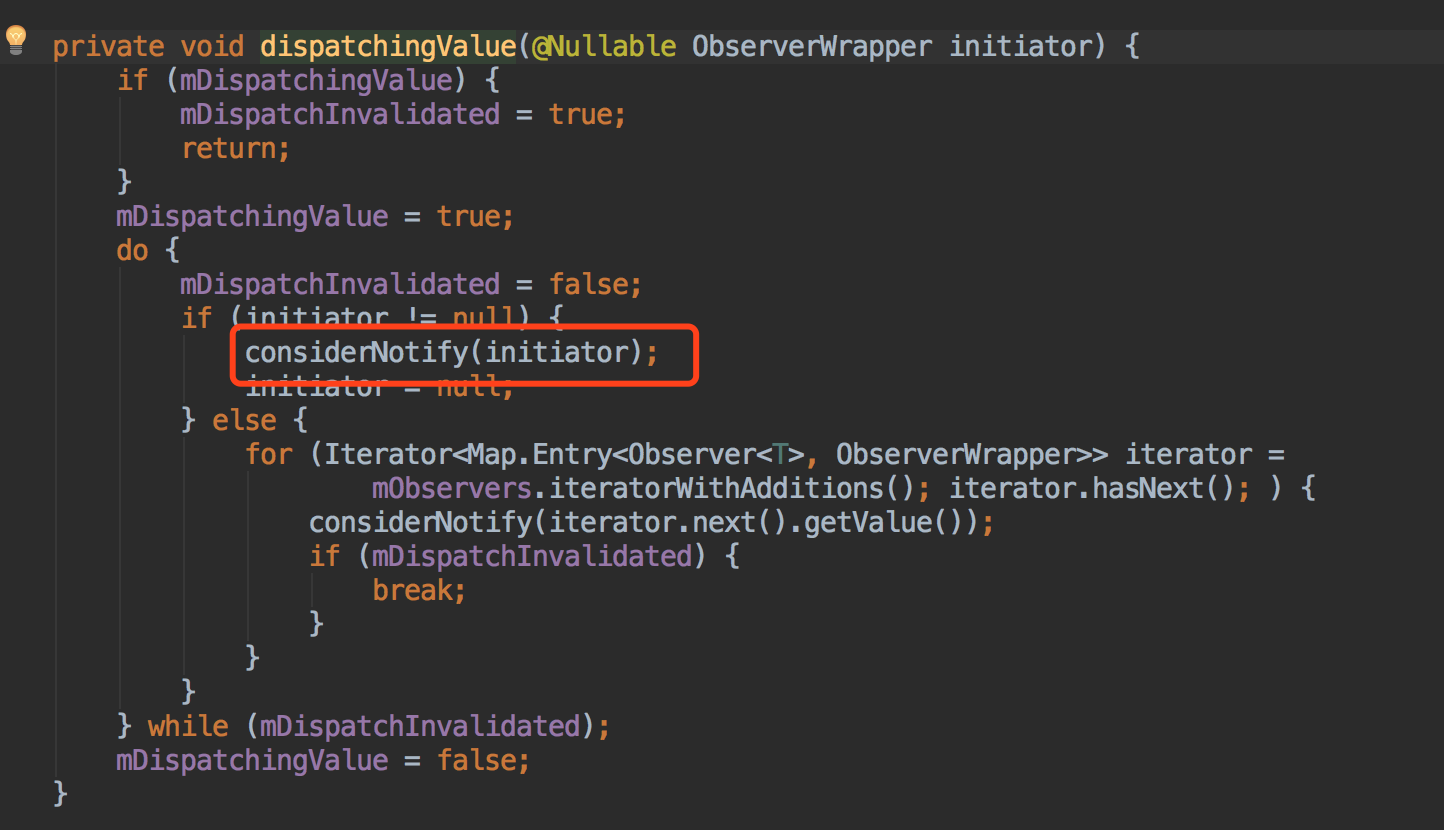
在LiveData的considerNotify方法中,红框中的逻辑是关键,如果ObserverWrapper的mLastVersion小于LiveData的mVersion,就会去回调mObserver的onChanged方法。而每个新的订阅者,其version都是-1,LiveData一旦设置过其version是大于-1的(每次LiveData设置值都会使其version加1),这样就会导致LiveDataBus每注册一个新的订阅者,这个订阅者立刻会收到一个回调,即使这个设置的动作发生在订阅之前。
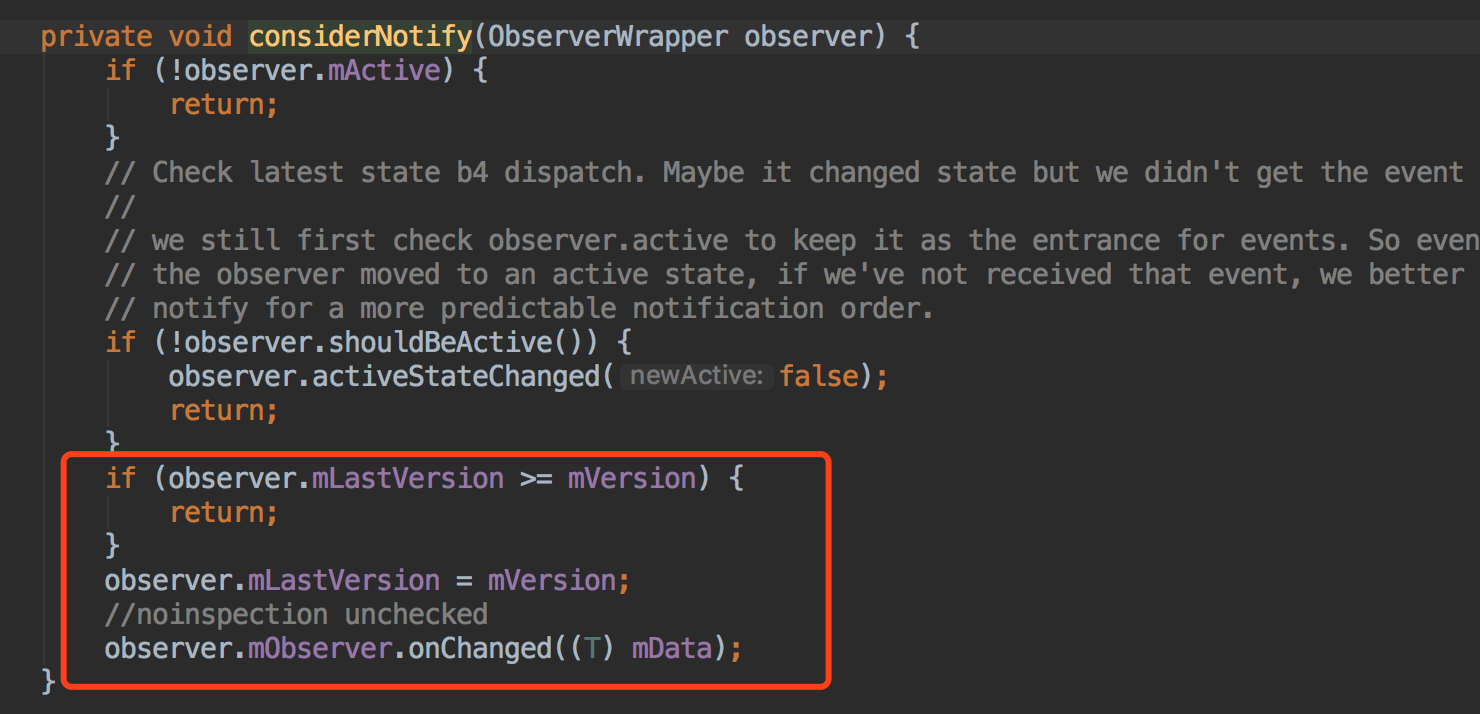
问题原因总结
对于这个问题,总结一下发生的核心原因。对于LiveData,其初始的version是-1,当我们调用了其setValue或者postValue,其vesion会+1;对于每一个观察者的封装ObserverWrapper,其初始version也为-1,也就是说,每一个新注册的观察者,其version为-1;当LiveData设置这个ObserverWrapper的时候,如果LiveData的version大于ObserverWrapper的version,LiveData就会强制把当前value推送给Observer。
如何解决这个问题
明白了问题产生的原因之后,我们来看看怎么才能解决这个问题。很显然,根据之前的分析,只需要在注册一个新的订阅者的时候把Wrapper的version设置成跟LiveData的version一致即可。
那么怎么实现呢,看看LiveData的observe方法,他会在步骤1创建一个LifecycleBoundObserver,LifecycleBoundObserver是ObserverWrapper的派生类。然后会在步骤2把这个LifecycleBoundObserver放入一个私有Map容器mObservers中。无论ObserverWrapper还是LifecycleBoundObserver都是私有的或者包可见的,所以无法通过继承的方式更改LifecycleBoundObserver的version。
那么能不能从Map容器mObservers中取到LifecycleBoundObserver,然后再更改version呢?答案是肯定的,通过查看SafeIterableMap的源码我们发现有一个protected的get方法。因此,在调用observe的时候,我们可以通过反射拿到LifecycleBoundObserver,再把LifecycleBoundObserver的version设置成和LiveData一致即可。
对于非生命周期感知的observeForever方法来说,实现的思路是一致的,但是具体的实现略有不同。observeForever的时候,生成的wrapper不是LifecycleBoundObserver,而是AlwaysActiveObserver(步骤1),而且我们也没有机会在observeForever调用完成之后再去更改AlwaysActiveObserver的version,因为在observeForever方法体内,步骤3的语句,回调就发生了。
那么对于observeForever,如何解决这个问题呢?既然是在调用内回调的,那么我们可以写一个ObserverWrapper,把真正的回调给包装起来。把ObserverWrapper传给observeForever,那么在回调的时候我们去检查调用栈,如果回调是observeForever方法引起的,那么就不回调真正的订阅者。
LiveDataBus最终实现
public final class LiveDataBus {
private final Map<String, BusMutableLiveData<Object>> bus;
private LiveDataBus() {
bus = new HashMap<>();
}
private static class SingletonHolder {
private static final LiveDataBus DEFAULT_BUS = new LiveDataBus();
}
public static LiveDataBus get() {
return SingletonHolder.DEFAULT_BUS;
}
public <T> MutableLiveData<T> with(String key, Class<T> type) {
if (!bus.containsKey(key)) {
bus.put(key, new BusMutableLiveData<>());
}
return (MutableLiveData<T>) bus.get(key);
}
public MutableLiveData<Object> with(String key) {
return with(key, Object.class);
}
private static class ObserverWrapper<T> implements Observer<T> {
private Observer<T> observer;
public ObserverWrapper(Observer<T> observer) {
this.observer = observer;
}
@Override
public void onChanged(@Nullable T t) {
if (observer != null) {
if (isCallOnObserve()) {
return;
}
observer.onChanged(t);
}
}
private boolean isCallOnObserve() {
StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
if (stackTrace != null && stackTrace.length > 0) {
for (StackTraceElement element : stackTrace) {
if ("android.arch.lifecycle.LiveData".equals(element.getClassName()) &&
"observeForever".equals(element.getMethodName())) {
return true;
}
}
}
return false;
}
}
private static class BusMutableLiveData<T> extends MutableLiveData<T> {
private Map<Observer, Observer> observerMap = new HashMap<>();
@Override
public void observe(@NonNull LifecycleOwner owner, @NonNull Observer<T> observer) {
super.observe(owner, observer);
try {
hook(observer);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void observeForever(@NonNull Observer<T> observer) {
if (!observerMap.containsKey(observer)) {
observerMap.put(observer, new ObserverWrapper(observer));
}
super.observeForever(observerMap.get(observer));
}
@Override