redis
mem_fragmentation_ratio:内存碎片比率,该值是used_memory_rss / used_memory的比值。
mem_fragmentation_ratio一般大于1,且该值越大,内存碎片比例越大。mem_fragmentation_ratio<1,说明Redis使用了虚拟内存,如果内存不足应该及时处理,如增加Redis节点、增加Redis服务器的内存、优化应用等。一般来说,mem_fragmentation_ratio在1.03左右是比较健康的状态(对于jemalloc来说)
mem_allocator:Redis使用的内存分配,在编译时指定;可以是 libc 、jemalloc或者tcmalloc,默认是jemalloc;截图中使用的便是默认的jemalloc。
在减小内存碎片方面做的相对比较好。将内存空间划分为小、大、巨大三个范围;每个范围内又划分了许多小的内存块单位;当Redis存储数据时,会选择大小最合适的内存块进行存储。
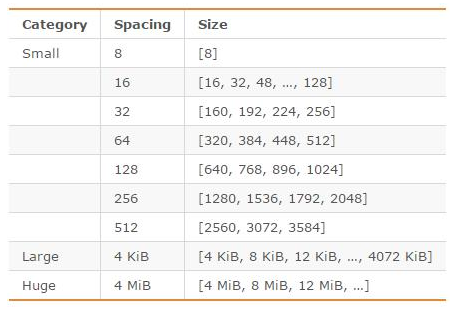
内存划分
- 数据
- 进程本身运行需要的内存
- 缓冲内存
- 内存碎片:如果Redis服务器中的内存碎片已经很大,可以通过安全重启的方式减小内存碎片:因为重启之后,Redis重新从备份文件中读取数据,在内存中进行重排,为每个数据重新选择合适的内存单元,减小内存碎片
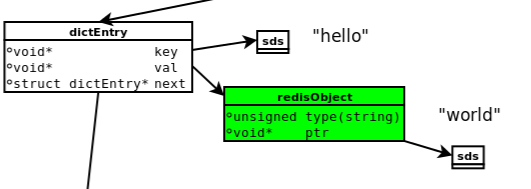

SDS simple dynamic string

SDS & C
- 获取长度 SDS O(1) C O(n)
- 缓存区溢出 C 字符串增加未申请空间 SDS 有长度可以自动分配内存
- 修改字符串时内存的重分配 C 需要先释放后重新申请 如果没有重新分配,增加,内存溢出,减少,内存泄露
- 存取二进制数据:SDS可以,C字符串不可以
编码转换在Redis写入数据时完成,且转换过程不可逆,只能从小内存编码向大内存编码转换
高可用
- 持久化
- 复制
- 哨兵
- 集群
RDB持久化
手动触发
- save 阻塞Redis服务器进程,直到RDB文件(经过压缩的二进制文件)创建完毕为止
- bgsave 子进程来负责创建RDB文件,只有fork子进程时会阻塞服务器
自动触发
- save m n 当m秒内发生n次变化时,会触发bgsave
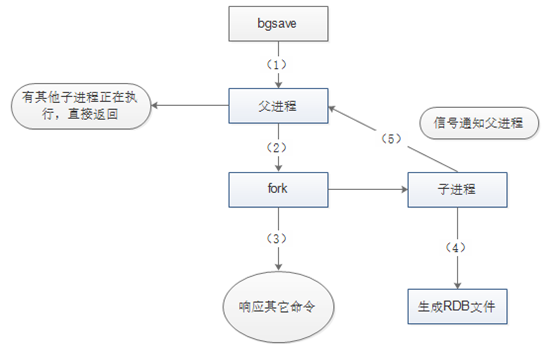
压缩:
Redis默认采用LZF算法对RDB文件进行压缩。虽然压缩耗时,但是可以大大减小RDB文件的体积,因此压缩默认开启
RDB文件的压缩并不是针对整个文件进行的,而是对数据库中的字符串进行的,且只有在字符串达到一定长度(20字节)时才会进行
启动时加载:
Redis会优先载入AOF文件来恢复数据;只有当AOF关闭时,才会在Redis服务器启动时检测RDB文件,并自动载入。服务器载入RDB文件期间处于阻塞状态,直到载入完成为止
AOF持久化
RDB持久化是将进程数据写入文件,而AOF持久化(即Append Only File持久化),则是将Redis执行的每次写命令记录到单独的日志文件中(有点像MySQL的binlog);当Redis重启时再次执行AOF文件中的命令来恢复数据。 与RDB相比,AOF的实时性更好,因此已成为主流的持久化方案
AOF的执行流程:
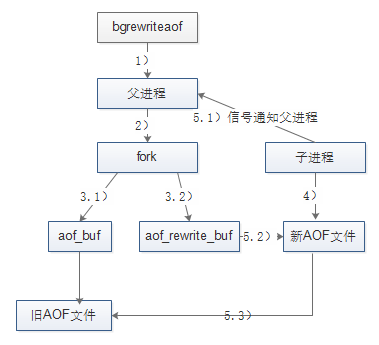
- 命令追加(append):将Redis的写命令追加到缓冲区aof_buf(主要是为了避免每次有写命令都直接写入硬盘,导致硬盘IO成为Redis负载的瓶颈);
- 文件写入(write)和文件同步(sync):根据不同的同步策略将aof_buf中的内容同步到硬盘;
- always:命令写入aof_buf后立即调用系统fsync操作同步到AOF文件,fsync完成后线程返回。每次有写命令都要同步到AOF文件,硬盘IO成为性能瓶颈
- no:命令写入aof_buf后调用系统write操作,不对AOF文件做fsync同步;同步由操作系统负责,通常同步周期为30秒。文件同步的时间不可控,且缓冲区中堆积的数据会很多,数据安全性无法保证
- everysec:命令写入aof_buf后调用系统write操作,write完成后线程返回;fsync同步文件操作由专门的线程每秒调用一次 (default)
- 文件重写(rewrite):定期重写AOF文件,达到压缩的目的
- AOF重写是把Redis进程内的数据转化为写命令,同步到新的AOF文件;不会对旧的AOF文件进行任何读取、写入操作(过期的数据不再写入文件,无效的命令不再写入文件,多条命令可以合并为一个)
主从复制
- 连接建立阶段(在主从节点之间建立连接,为数据同步做好准备)
-
保存主节点信息
-
建立socket连接
-
发送ping命令
-
身份验证
-
发送从节点端口信息
-
- 数据同步阶段(节点数据的初始化)
- 在数据同步阶段之前,从节点是主节点的客户端,主节点不是从节点的客户端;而到了这一阶段及以后,主从节点互为客户端
- 命令传播阶段(延迟与不一致)
- 在这个阶段主节点将自己执行的写命令发送给从节点,从节点接收命令并执行,从而保证主从节点数据的一致性
- 主从节点还维持着心跳机制
全量复制:用于初次复制或其他无法进行部分复制的情况,将主节点中的所有数据都发送给从节点,是一个非常重型的操作。
部分复制:用于网络中断等情况后的复制,只将中断期间主节点执行的写命令发送给从节点,与全量复制相比更加高效。需要注意的是,如果网络中断时间过长,导致主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制。
心跳机制
- 每隔指定的时间,主节点会向从节点发送PING命令,这个PING命令的作用,主要是为了让从节点进行超时判断
- 从节点会向主节点发送REPLCONF ACK命令,频率是每秒1次
- (1)实时监测主从节点网络状态:该命令会被主节点用于复制超时的判断。
- (2)检测命令丢失:从节点发送了自身的offset,主节点会与自己的offset对比,如果从节点数据缺失(如网络丢包),主节点会推送缺失的数据(这里也会利用复制积压缓冲区)。注意,offset和复制积压缓冲区,不仅可以用于部分复制,也可以用于处理命令丢失等情形;区别在于前者是在断线重连后进行的,而后者是在主从节点没有断线的情况下进行的。
- (3)辅助保证从节点的数量和延迟:
redis sentinel
- 哨兵哨兵节点是特殊的redis节点,不存储数据
- 哨兵节点的数量应不止一个
- 哨兵节点的数量应该是奇数,便于哨兵通过投票做出“决策”
哨兵的原理
(1)定时任务:每个哨兵节点维护了3个定时任务。定时任务的功能分别如下:通过向主从节点发送info命令获取最新的主从结构;通过发布订阅功能获取其他哨兵节点的信息;通过向其他节点发送ping命令进行心跳检测,判断是否下线。
(2)主观下线:在心跳检测的定时任务中,如果其他节点超过一定时间没有回复,哨兵节点就会将其进行主观下线。顾名思义,主观下线的意思是一个哨兵节点“主观地”判断下线;与主观下线相对应的是客观下线。
(3)客观下线:哨兵节点在对主节点进行主观下线后,会通过sentinel is-master-down-by-addr命令询问其他哨兵节点该主节点的状态;如果判断主节点下线的哨兵数量达到一定数值,则对该主节点进行客观下线。
需要特别注意的是,客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
(4)选举领导者哨兵节点:当主节点被判断客观下线以后,各个哨兵节点会进行协商,选举出一个领导者哨兵节点,并由该领导者节点对其进行故障转移操作。
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;Raft算法的基本思路是先到先得:即在一轮选举中,哨兵A向B发送成为领导者的申请,如果B没有同意过其他哨兵,则会同意A成为领导者。选举的具体过程这里不做详细描述,一般来说,哨兵选择的过程很快,谁先完成客观下线,一般就能成为领导者。
(5)故障转移:选举出的领导者哨兵,开始进行故障转移操作,该操作大体可以分为3个步骤:
- 在从节点中选择新的主节点:选择的原则是,首先过滤掉不健康的从节点;然后选择优先级最高的从节点(由slave-priority指定);如果优先级无法区分,则选择复制偏移量最大的从节点;如果仍无法区分,则选择runid最小的从节点。
- 更新主从状态:通过slaveof no one命令,让选出来的从节点成为主节点;并通过slaveof命令让其他节点成为其从节点。
- 将已经下线的主节点(即6379)设置为新的主节点的从节点,当6379重新上线后,它会成为新的主节点的从节点。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号